Artikelserie: BI Tools im Vergleich – Qlik Sense
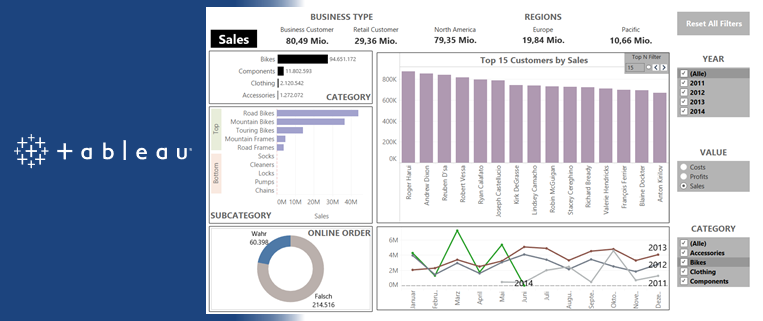
Dies ist ein Artikel der Artikel-Serie “BI Tools im Vergleich – Einführung und Motivation“, zu der auch die vorab sehr lesenswerten einführenden Worte und die Ausführungen zur Datenbasis gehören. Auf Grundlage derselben Daten wurde analog zu diesem Artikel hier auch ein Artikel über Microsoft Power BI und einen zu Tableau.
Übrigens gibt es auch Erweiterungen für Qlik Sense, die Process Mining ermöglichen. Eine dieser Erweiterungen ist die von MEHRWERK Process Mining.
Lizenzmodell
Neben Qlik Sense gibt es auch das lang bewährte Qlik View, dass auf der gleichen In-Memory-Kerntechnologie basiert. Qlik Sense wurde im Jahr 2014 vom schwedischen Softwareunternehmen Qlik Tech herausgebracht und bei Qlik Sense liegt auch der Fokus der Weiterentwicklung. Es handelt sich um Self-Service-BI und eine Plattform für Visual Data Analysis. Dabei gibt es die Möglichkeit einer On Premise Server Version (interne Cloud) oder auf die Server von Qlik zu setzen und somit gänzlich auf die Qlik Sense Cloud zu setzen, also die Qlik Sense Cloud als SaaS-Lösung. Dazu gibt es noch Qlik Sense Desktop, das für kleinere Projekte ausreichen kann und ganz ohne die Cloud auskommt, jedoch Ergebnisse bei Bedarf in die Cloud publishen kann. Ähnlich wie bei Tableau und anders als derzeitig bei Power BI, wird für das Editieren von Apps/Dashboards jedoch kein Qlik Sense Desktop benötigt, denn das Erstellen, Bearbeiten und Verwalten von Qlik Sense Reports darf komplett in der Cloud (vom Browser aus) stattfinden.
Der Kunde hat die Wahl zwischen den Lizenzmodellen von Qlik Sense Business (SaaS) und Qlik Sense Enterprise (SaaS oder On Premise). Die Enterprise Variante ist dann noch mal in Enterprise Professional, Enterprise Analyzer und Enterprise Analyzer Capacity eingeteilt, es stehen also insgesamt drei Lizenzen zur Auswahl. Der Preis für Qlik Sense Business beträgt monatlich derzeitig $30 pro Anwender. Das offizielle Preismodell sieht für Enterprise Professionell $70 für einen Benutzer pro Monat vor und für Enterprise Analyzer $40 pro Benutzer pro Monat. Zum Kennenlernen der Business Version gibt eine kostenlose 30-Tage-Testversion.
Die Version Qlik Sense Desktop ist in der Funktionalität an der SaaS Lösung Qlik Sense Enterprise angepasst und steht ihr in nichts Essenziellem nach. Die Desktop Version kann nur auf Windows-Computern ausgeführt werden und die Verwendung mehrerer Bildschirme oder Tablets wird nicht unterstützt. Außerdem werden Sicherheitsfunktionen nicht unterstützt und es gibt keine Funktion zum automatischen Speichern. Mehr zu den Unterschieden hier.
Community & Features von anderen Entwicklern
Wie relevant die Community für Visualisierungstools ist, wurde bereits in den vorherigen Blogartikeln zu Power BI und Tableau beschrieben. Auch Qlik besitzt eine offizielle Community Seite, in der u. a. Diskussionen, Blogs und Support angeboten werden. Auch hier finden sich zu den meisten Problemstellungen eine Menge Lösungsansätze. Zudem bietet Qlik auf den offiziellen Webseiten auch sehr viele Lernvideos an, mit denen sich Neulinge einarbeiten und fortgeschrittene Anwender auch noch einiges erfahren können.
Neben den zahlreichen Visualisierungen können auch weitere Diagramme hinzugefügt werden. Im Qlik Sense Desktop werden bei Arbeitsblatt im Reiter Benutzerdefinierte Objekte zwei Bundles mitgeliefert. Hier können auch Erweiterungen importiert werden. Ein bekanntes Bundle ist die Vizlib, welches hier unterschiedliche Packages zur Verfügung stellt. Diese Erweiterungen können einfach importiert werden, indem die heruntergeladenen Verzeichnisse in den Qlik Sense Extensions Ordner eingefügt werden. Wem auch die Erweiterungen nicht ausreichen, der kann sogenannte Widgets erstellen. Diese werden in HTML und CSS geschrieben, daher ist ein gewisses Grundverständnis vorausgesetzt. Diese Widgets können auf Qlik Sense Funktionalitäten zugreifen und diese per Klick ausführen. So kann bspw. ein Button zum Entfernen aller gesetzten Filter erstellt werden.
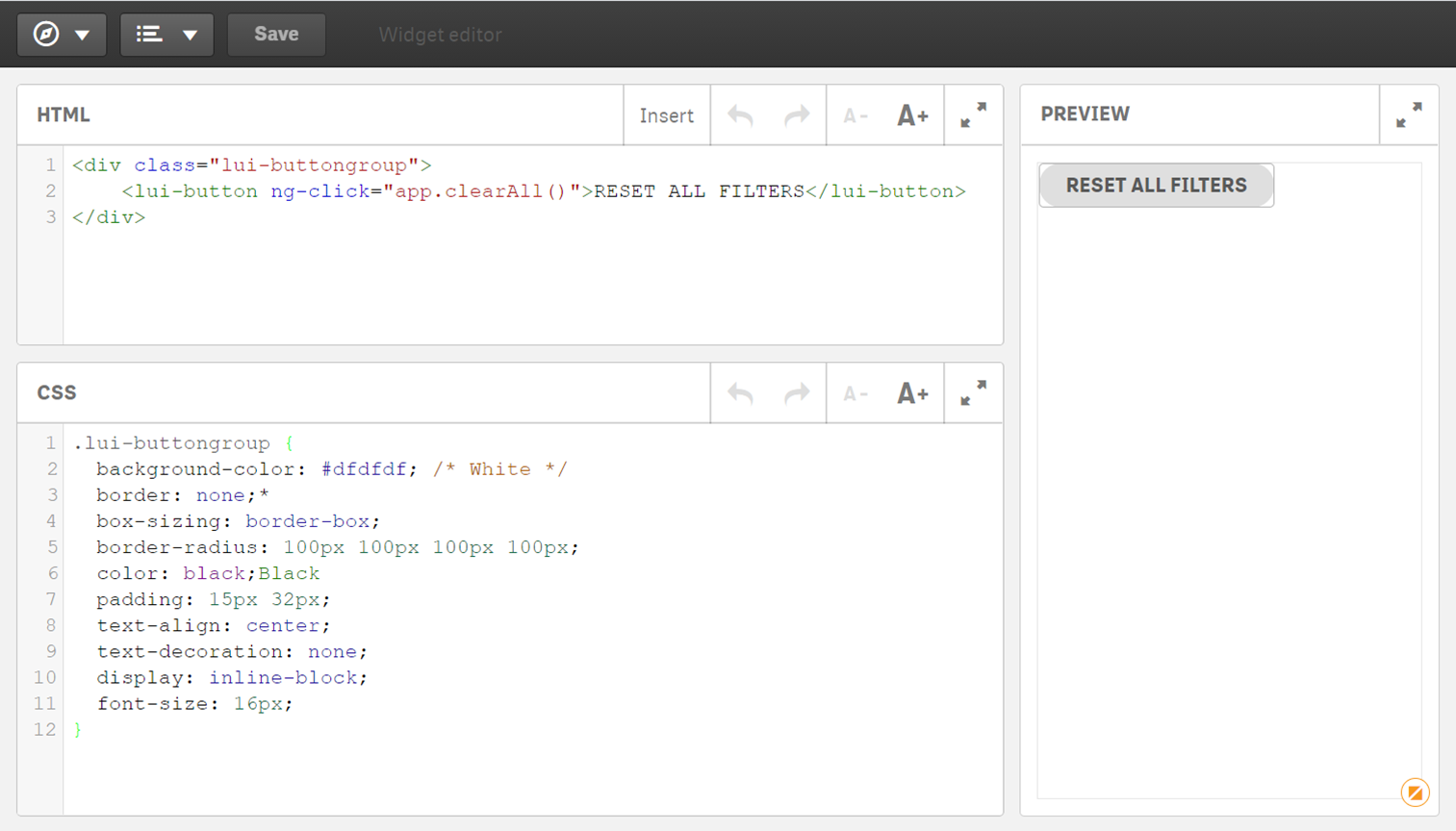
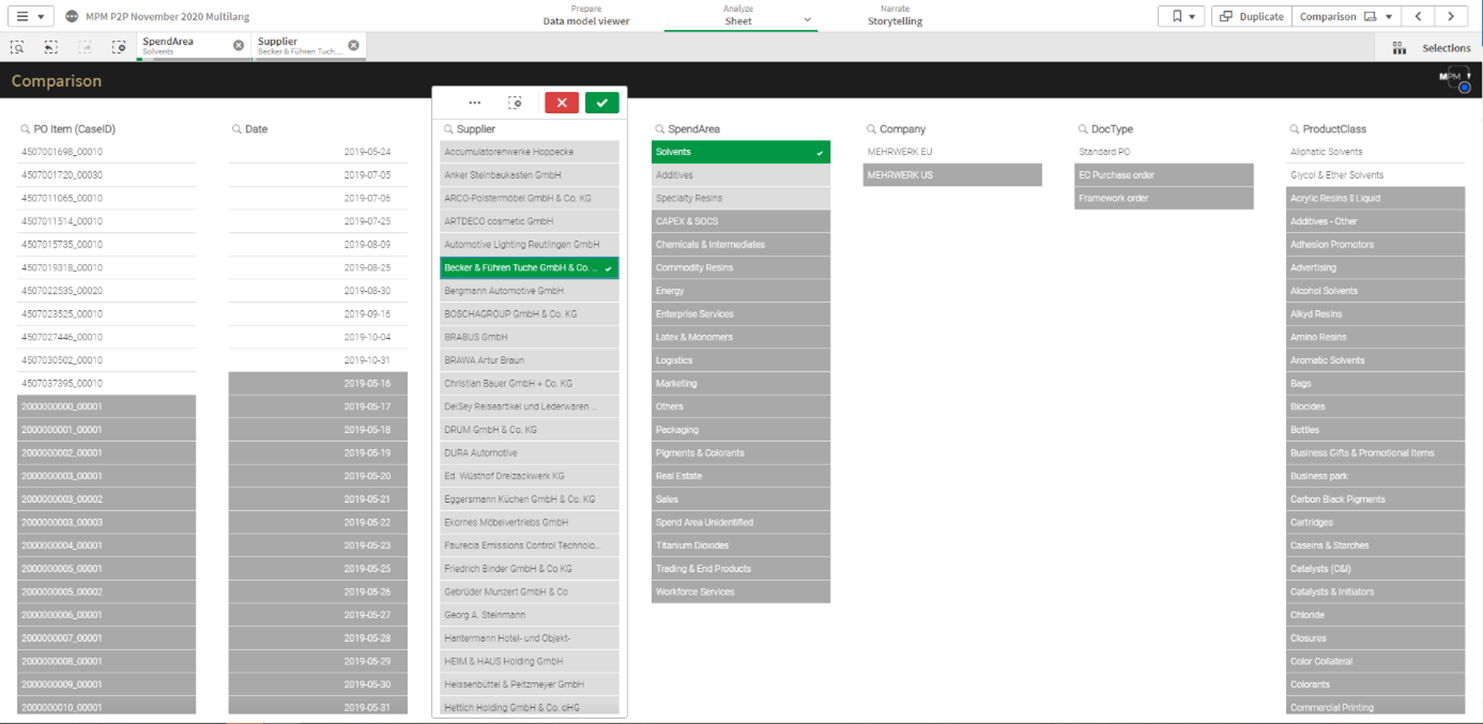
Erstellung von Filtern in Qlik Sense
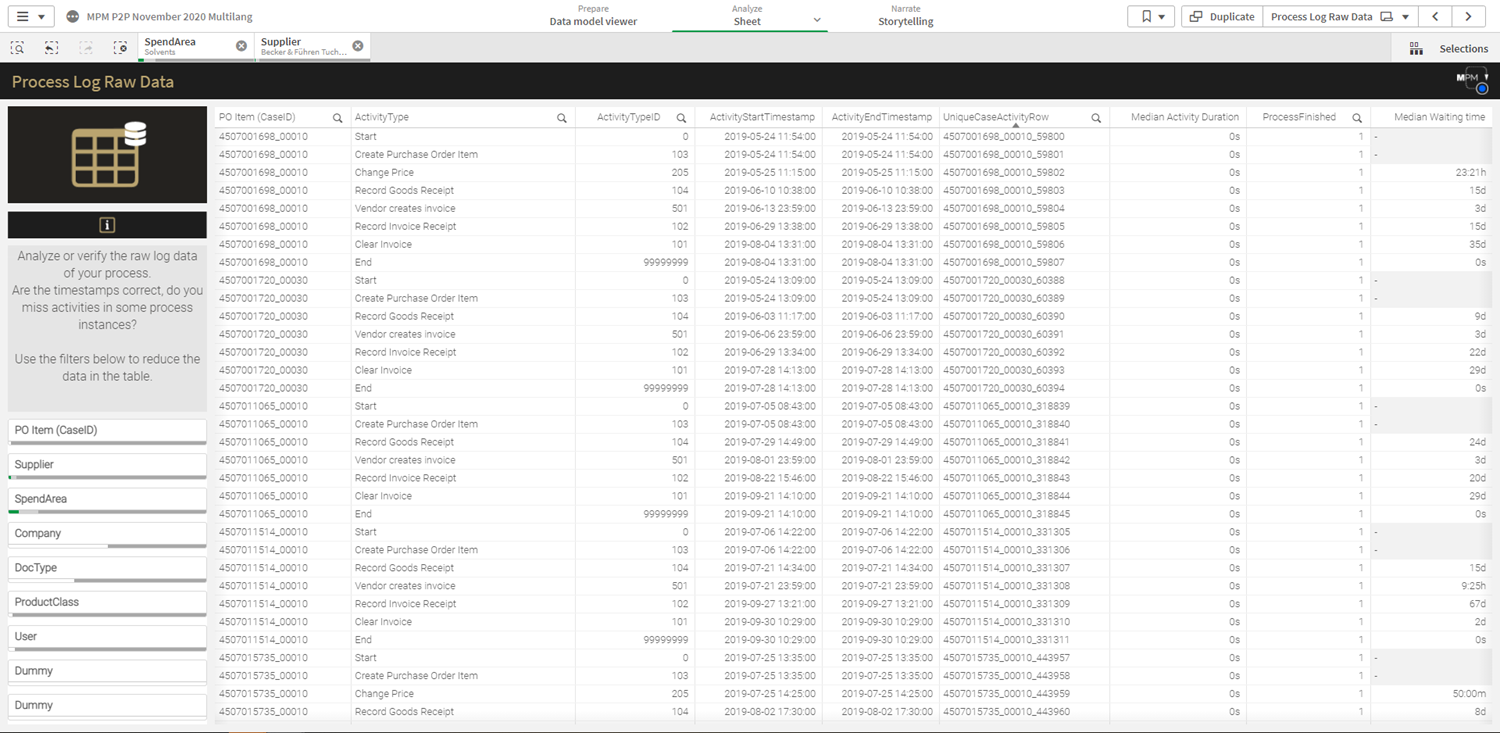
Daten laden & transformieren
Flexibler als die meisten Vergleichstools ist Qlik in der Verknüpfung von Datenquellen. Es werden Hunderte von Datenquellen angeboten, durch die der Anwender Zugriff auf seine Daten erhalten kann. Die von Qlik entwickelte Associate Engine beschleunig die Verarbeitung von verknüpften Daten. Die Anbindung von Cloudanwendungen steht hier im Vordergrund, aber es werden natürlich auch klassische Datenbanken, Textfiles usw. angeboten.
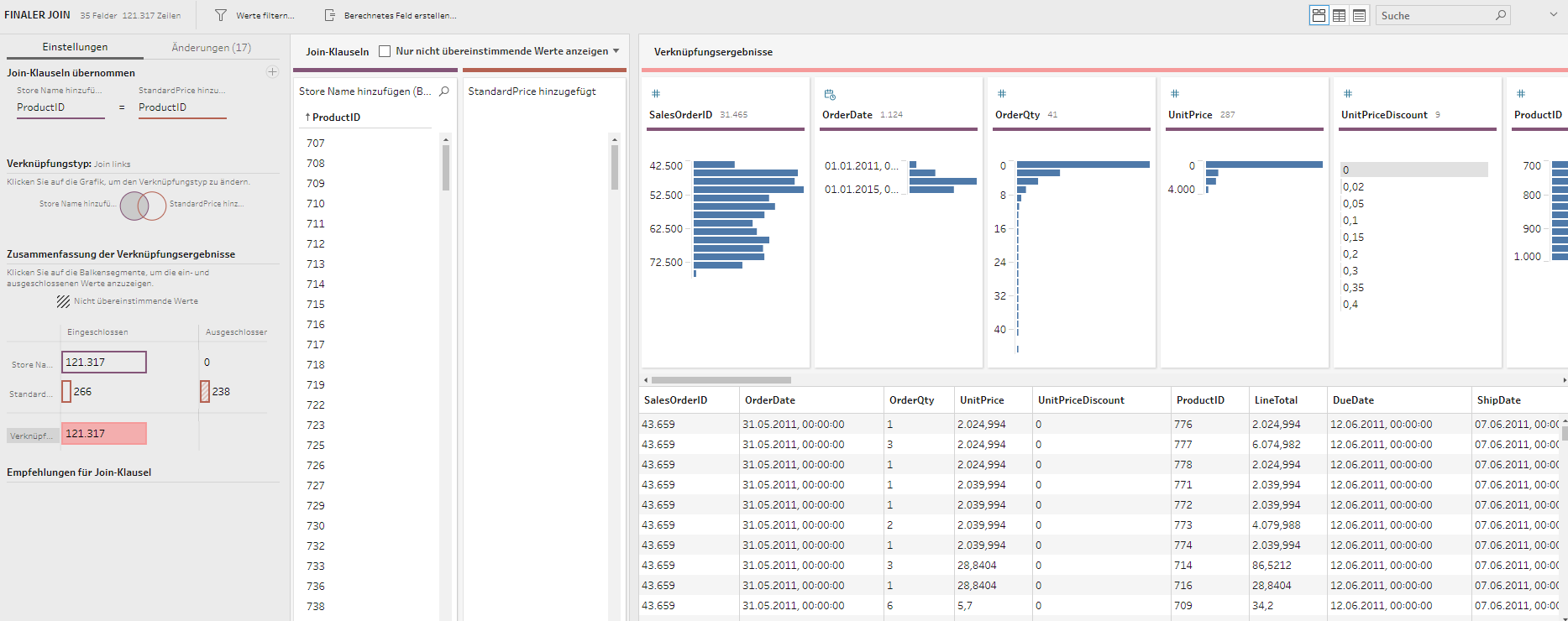
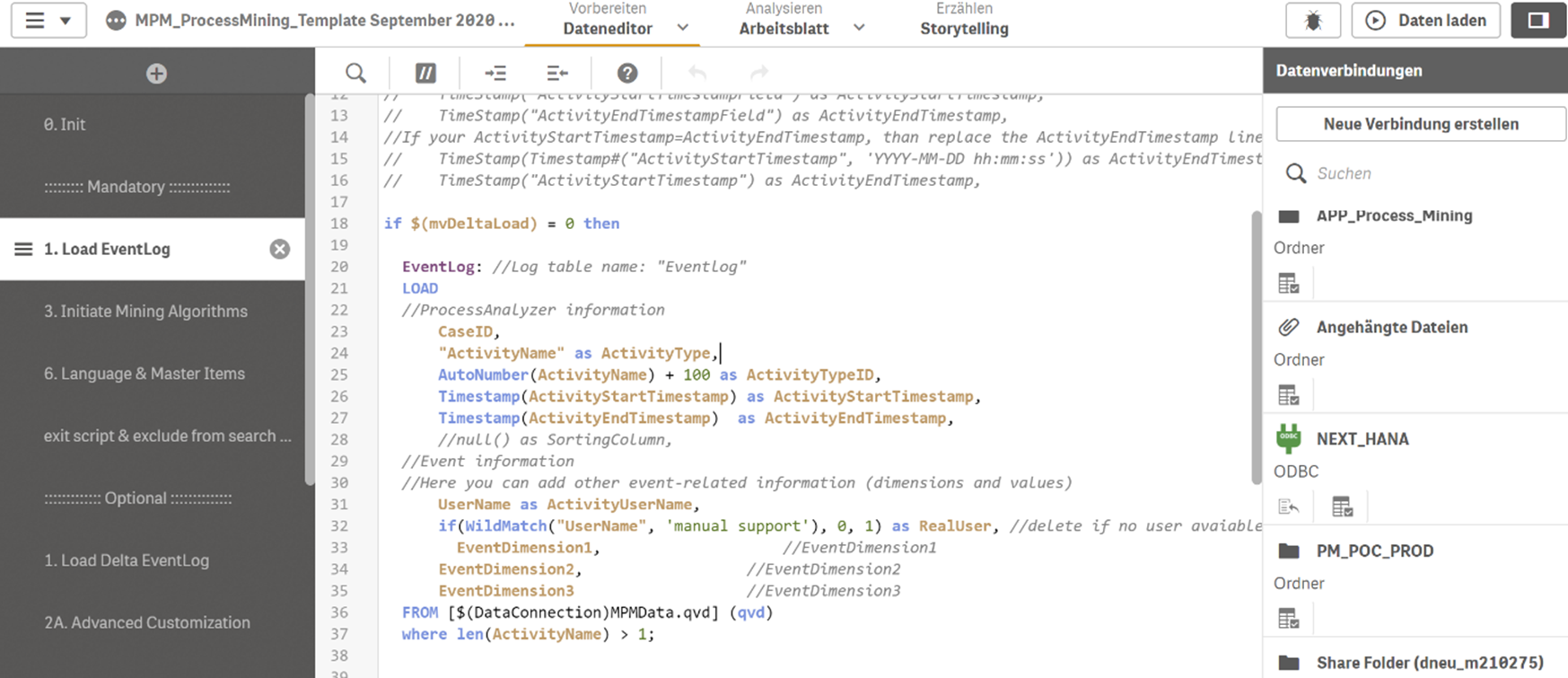
Nachdem die Daten geladen sind, befindet sich im Dateneditor unter dem Reiter auto generated selection eine automatisch generierte Query für den Ladevorgang. Dieses „Datenladeskript“ kann angelegt, bearbeitet und ausgeführt werden. Im Reiter „Main“ befinden sich hier vordefinierte Variableneinstellungen, wie z. B. SET ThousandSep=’.’; wobei auch diese angepasst und erweitert werden können. Zudem gibt es die Möglichkeit, das Datenmodell mit allen Tabellenverbindungen anzeigen zu lassen. Die große Qlik-Community und die Tutorials ermöglicht es jedem Nutzer, die vielen Möglichkeiten mit Qlik Script zügig aus dem Internet zu erlernen.
Daten laden & transformieren: AdventureWorks2017Dataset
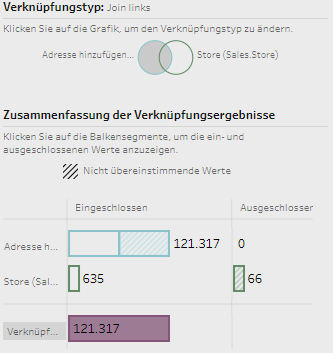
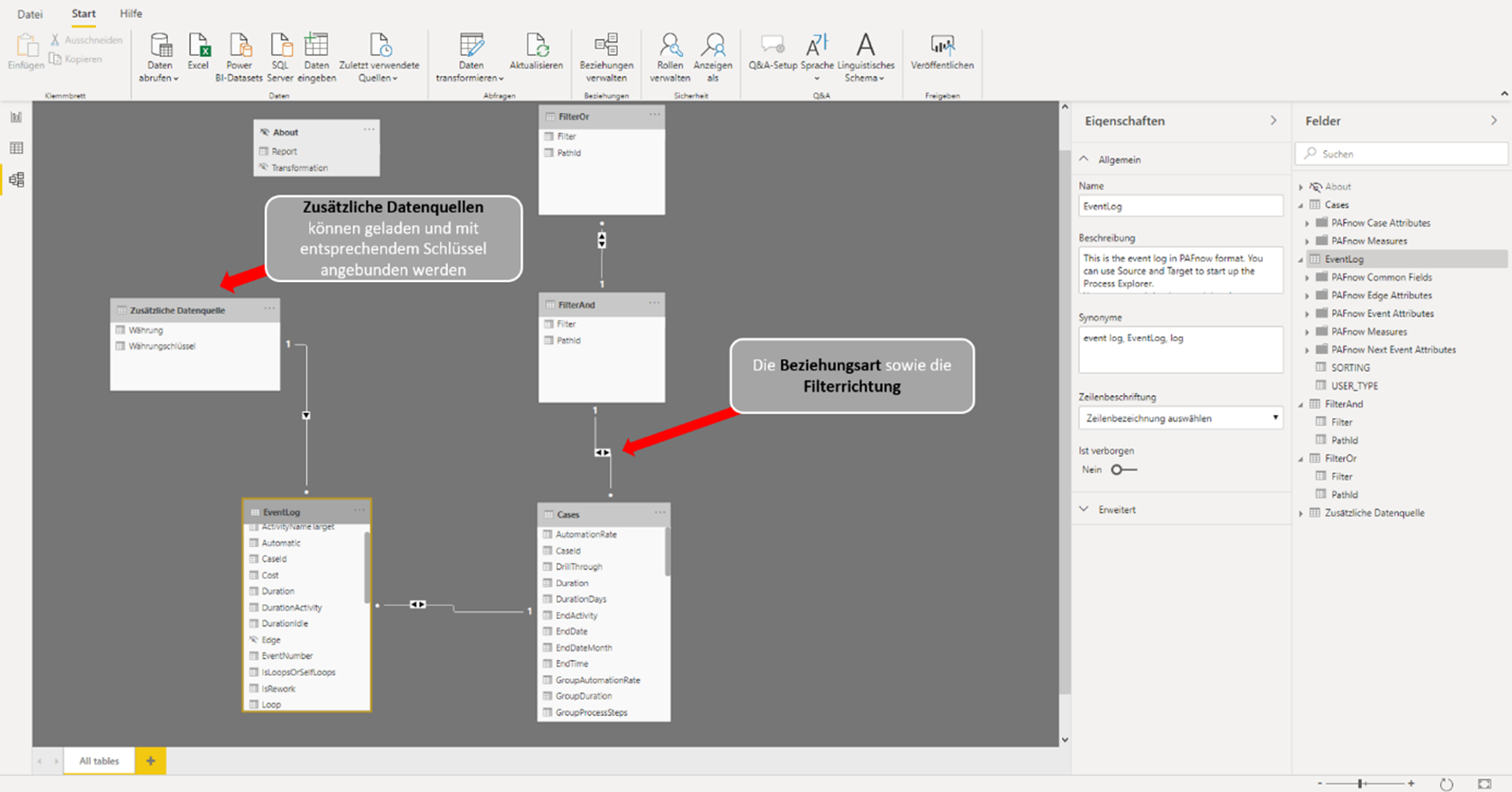
Im Reiter Datenmanager werden die empfohlenen Verknüpfungen angezeigt. Diese sind für Einsteiger sehr nützlich. Im Verlauf der Analysen musste jedoch nachjustiert werden. Wenn die ID-Spalten zum Verknüpfen z. B. unterschiedliche Bezeichnungen haben, tut sich der Algorithmus schon mal schwer.
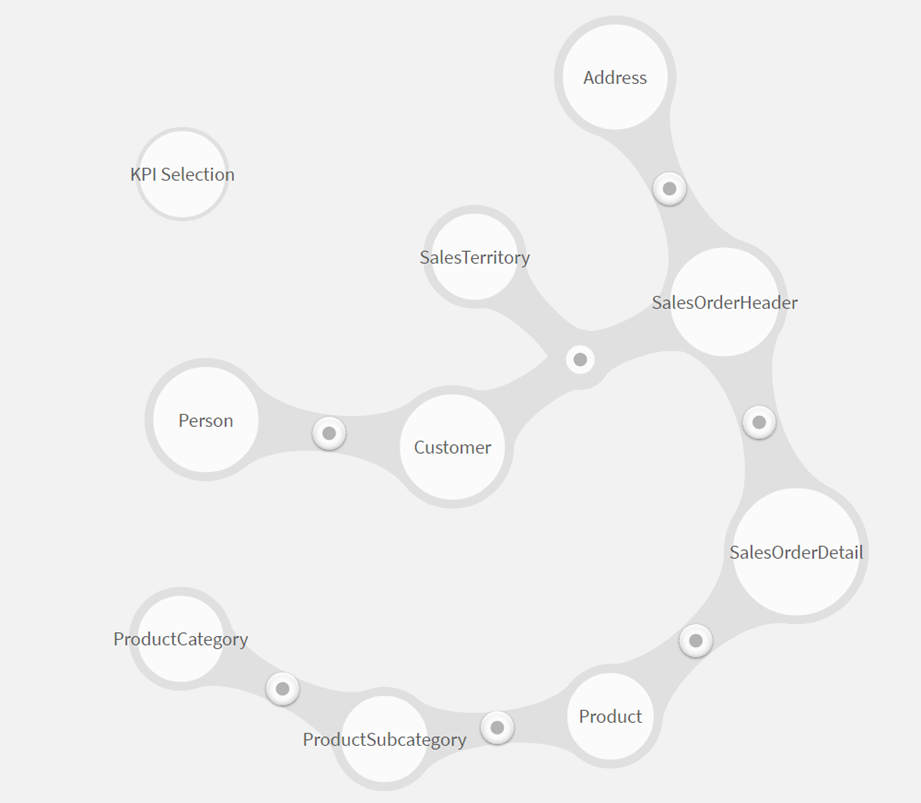
Abbildung eines Datenmodels in Qlik Sense. Zusehen sind die Verbindungen zwischen den Tabellen der Datenbank “AdventureWorks2016”.
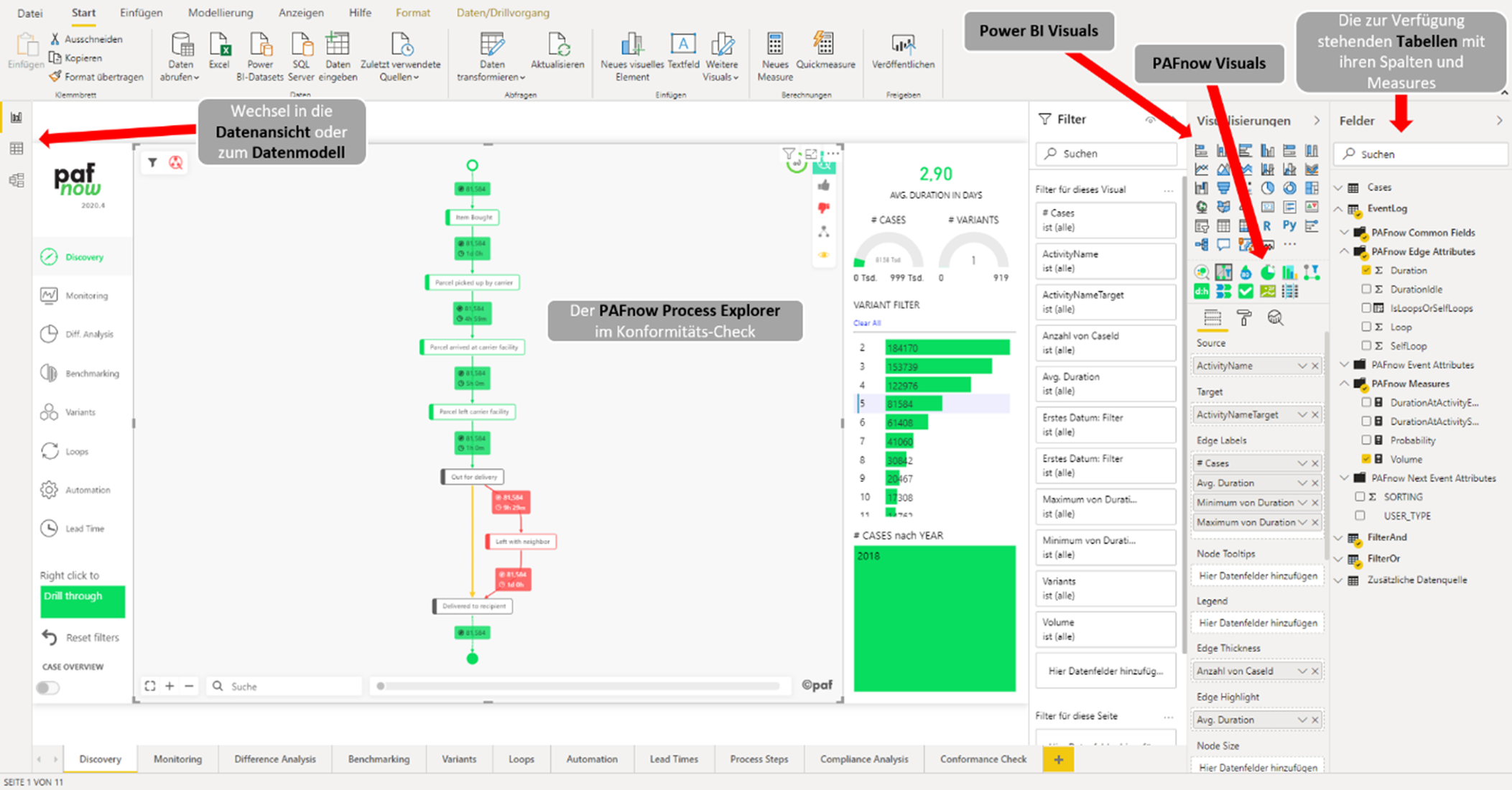
Eine vom Tool vordefinierte Detailansicht in Form einer Visualisierung (siehe Screenshot) ermöglicht einen schnellen und einfachen Qualitätscheck der gerade erst geladenen Daten. Hier können die Verbindungen angepasst und neue erstellt werden. Hier können erste Datentransformation durchgeführt werden, z. B. die Ersetzung von Daten oder NULL-Werten.
Datentransformationen mit einfachen Eingabemasken – Hier: Ersetzen von Werten in Tabellen-Spalten.
Zudem können Felder hinzugefügt, also berechnet werden (ähnlich wie in Power BI und Tableau als neues Measure). Z. B. können Textwerte mit dem Operator „&“ verbunden und somit z. B. Vor- und Nachname ganz intuitiv in eine Spalte zusammengefügt werden. Außerdem gibt es mathematische Operatoren für Berechnungen und ein SQL-artiges „like“, um Zeichenfolgen mit Mustern zu vergleichen. Auch an dieser Stelle können Formeln eingegeben werden. Die Formeln umfassen hier: String-, Datums-, numerische, Bedingungs-, mathematische, Verteilungsfunktionen usw. Zu beachten ist hier, dass die Daten neu geladen werden müssen, um die berechneten Spalten zu updaten. Der Umgang mit den Formeln aber erscheint mir einfacher als z. B. mit DAX in Power BI.
Daten visualisieren
Dank einer benutzerfreundlichen Oberfläche sind auch Analysen ohne großes Vorwissen und per Drag and Drop möglich. Individuelle Dashboards sind in wenigen Schritten möglich und erfordern keine besonderen Tricks oder Kniffe um gleich zum Erfolg zu kommen. Die Datenvisualisierung erfolgt in sogenannten Apps, in denen die Dashboards (Seiten in der App) liegen. Diese können von Qlik Sense Desktop nach Qlik Cloud hochgeladen werden und von dort aus mit anderen Usern geteilt werden.
Qlik Sense enthält von Hause aus eine große Anzahl an Visualisierungsmöglichkeiten. „Entdecken Sie neue Einblicke in ihre Daten“ heißt es bei der Funktion namens Einblicke (Insights), denn hier wird der Zugriff auf die Qlik Cognitive Engine gewährt. Dabei kann der Anwender eine Frage an den sogenannten Insight Advisor in natürlicher Sprache formulieren, woraus dann AI-gestützte Dashboard-Vorschläge generiert werden. Auch wenn diese Funktion noch nicht vollkommen ausgereift erscheint, ist dies sicherlich ein Schritt in die Business Intelligence der Zukunft.
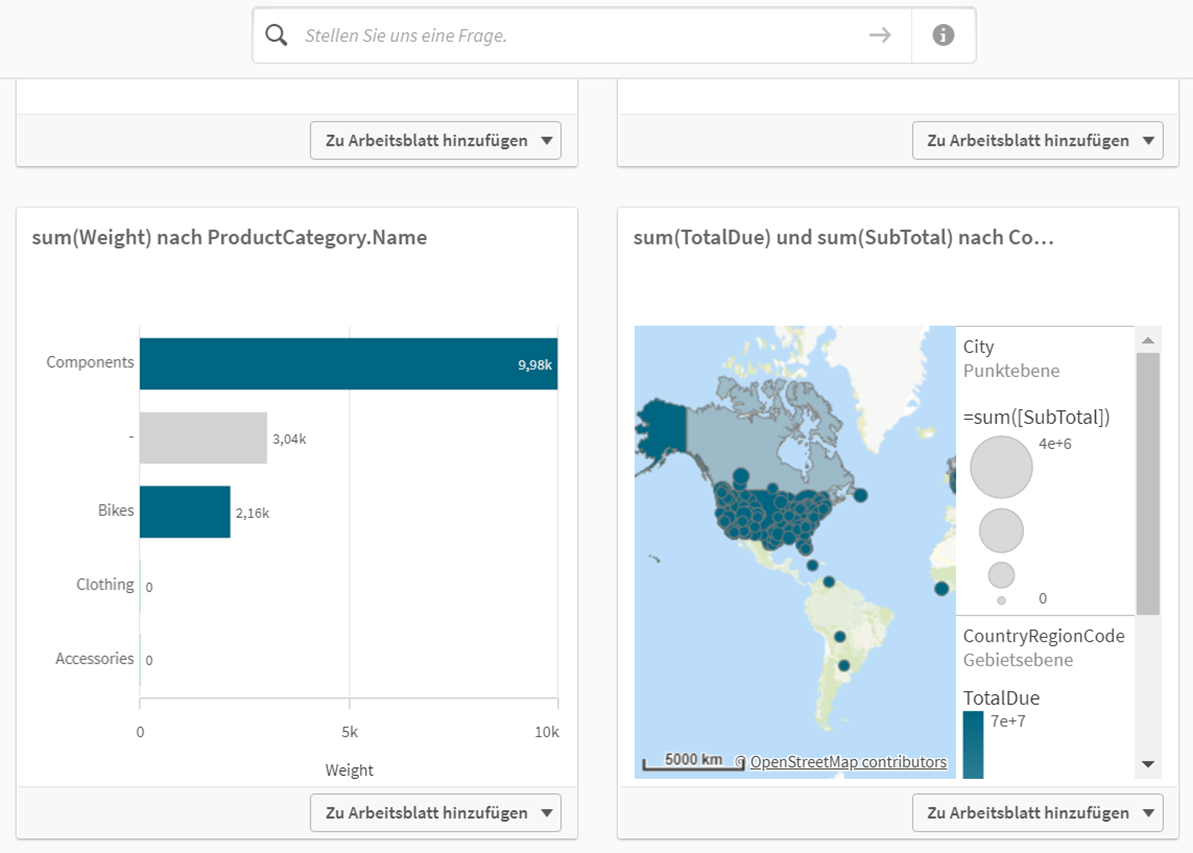
Qlik Sense Insights – Einblicke gewinnen mit Stichworten in menschlicher Sprache. Funktioniert mal besser, mal schlechter. Die Titel der Diagramme sind (in Qlik Sense stets per default) die Formeln der Darstellung. Diese lassen sich leicht umbenennen.
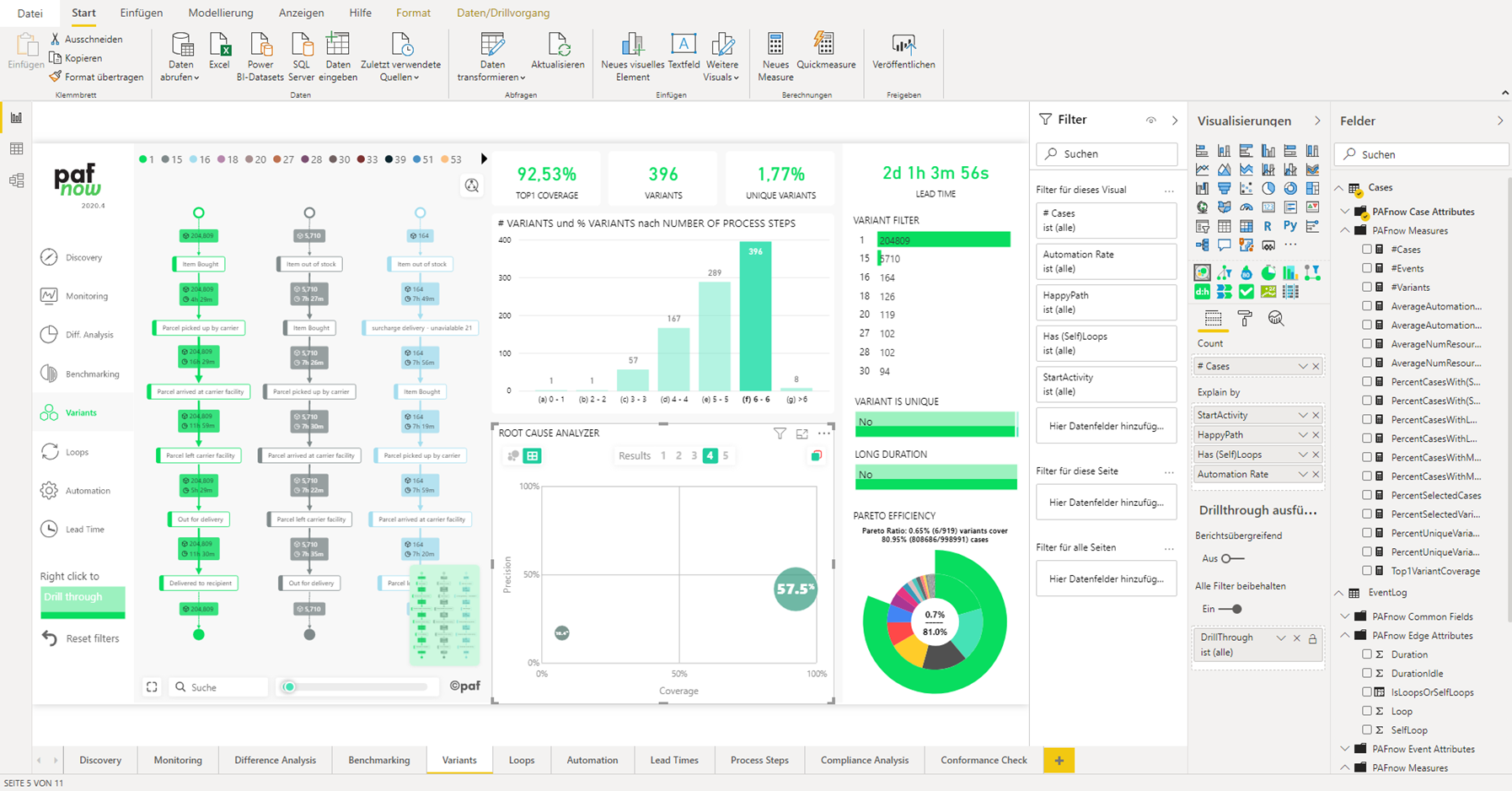
Diese Diagrammvorschläge können einen guten ersten Eindruck über verschiedene Dimensionen und Kennzahlen geben und die Diagramme können direkt zu den Arbeitsblättern hinzugefügt werden. Es können auch Fragen gestellt werden, die Berechnungen zur Grundlage haben. So wird im folgenden Beispiel die Korrelation zwischen zwei Kennzahlen ermittelt.
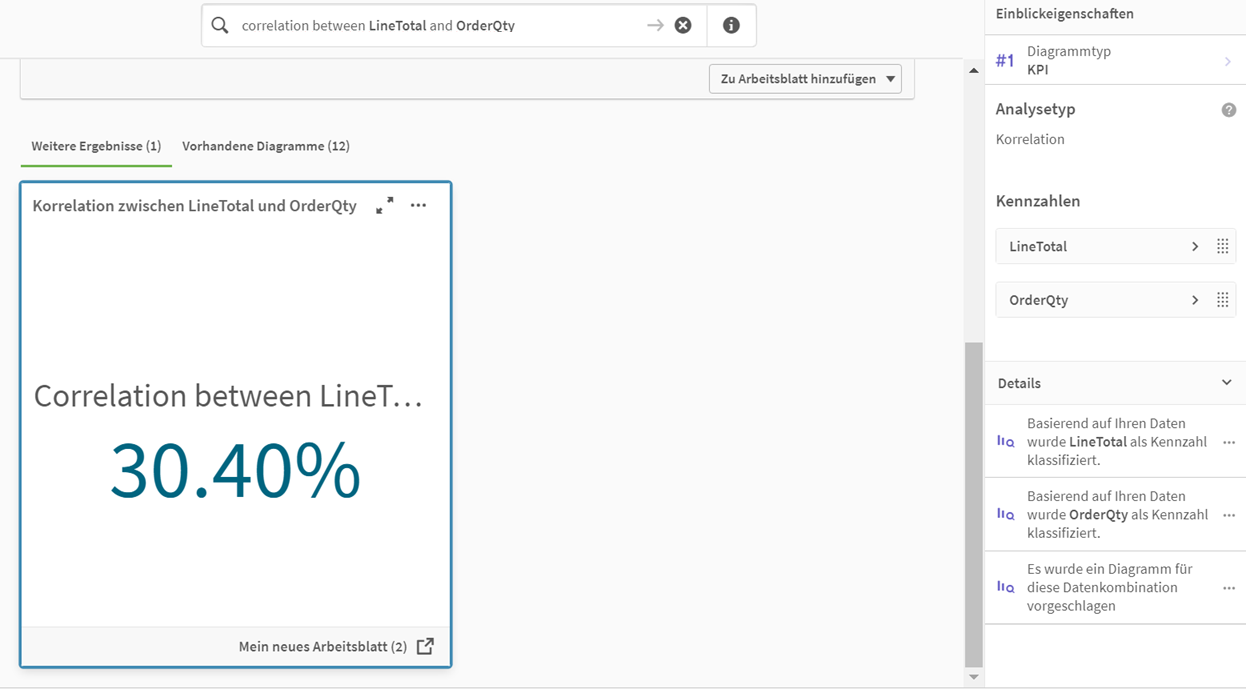
Qlik Sense Insights – Korrelation erstellt mit Anweisung auf Englisch
Den ersten Auftritt hatte die Cognitive Engine im April 2018 und der Insight Advisor im Juni 2018. Über den Insight Adviser werden auch die empfohlenen Verknüpfungen im Datenmanager generiert, diese sollten jedoch vom Anwender (z. B. BI-Developer, Data Analyst oder Data Engineer) jedoch nochmal überblickt werden, da diese nicht unbedingt fehlerfrei abläuft. Gerade in vielen Geschäftsdaten verstecken sich viele “falsche Freunde” unter den ID-Spalten-Benennungen, die einen Zusammenhang herzustellen scheinen – aber es nicht immer tun.
Diagramme können ansonsten auf übliche Weise über eine Paletten ausgewählt werden, um sie dann mit Kennzahlen und Dimensionen zu befüllen. Die Charts können mit vordefinierten Optionen in den Kategorien Daten, Sortieren, Darstellung usw. bearbeitet werden. Unter Darstellung können ggf. verschiedene Designs ausgewählt werden und Beschriftungen, Titel etc. angepasst werden. Die Felder zur Auswahl der Kennzahlen und Dimensionen können nach Tabelle ausgewählt werden, sie sind ansonsten alle in einer Liste und können über eine Suchfunktion schnell gefunden werden, vorausgesetzt die genaue Bezeichnung ist bekannt. Diese Suchfunktion wird auch an anderen Stellen angewandt, immer dann, wenn Felder ausgewählt werden.
Es gibt außerdem die Option „Master-Elemente“, um wieder verwendbare Dimensionen oder Kennzahlen (Measures) zu erstellen.
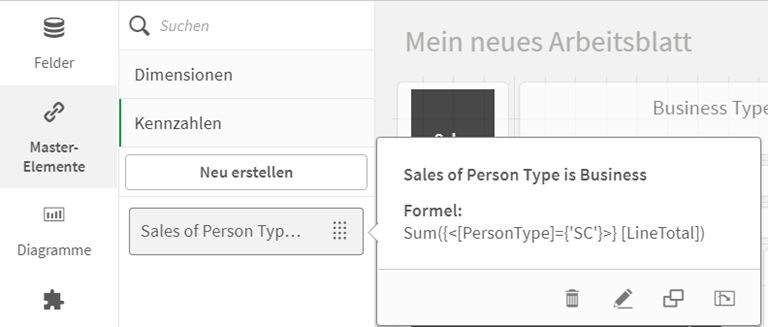
Hier können Berechnungen für Kennzahlen und Dimensionen hinterlegt und in jedem Arbeitsblatt wiederverwendet werden. Dies gilt auch für Visualisierungen und die damit verbundenen Dateninputs und Einstellungen.
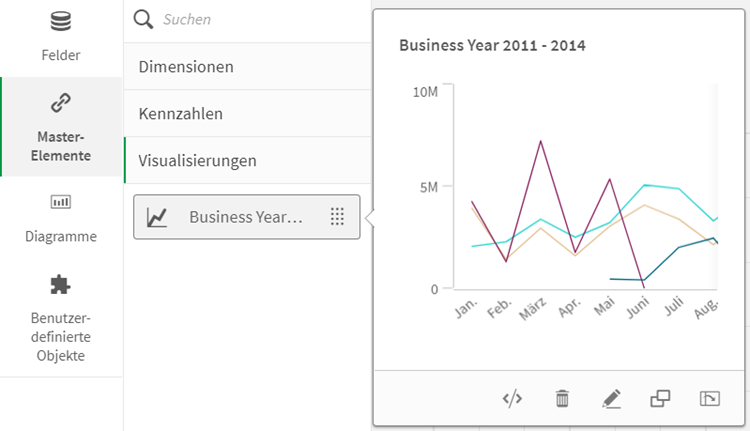
Mit Drag and Drop stößt der Anwender hier schon mal an seine Grenzen, aber dann helfen die Formeln von Qlik Sense Script weiter. Wenn bspw. das Diagramm namens KPI eine Kennzahl mit Filterung nach einer Dimension anzeigen soll, hilft die Formel: Sum({<DimensionName={‘Value’}>} MeasureName. Eine Qlik Sense Formelsammlung ist hier zu finden. Jede Kennzahl und Dimension kann als Formel eingegeben werden. Im Formel bearbeiten – Editor werden auch schon gebräuchliche Berechnungen wie Aggregierungsfunktionen (Sum, Avg, Max usw.) und Distinct, vorgegeben und können auf Knopfdruck und ohne Coding generiert werden, ähnliche wie ein Quick Measure in Power BI.
Fazit
Das Finanzmodell ist auf jede Unternehmensgröße ausgerichtet. Wenn die Datenbereinigung im Vorfeld stattgefunden hat, sind Visualisierungen in wenigen Schritten möglich. Es gibt dabei die Möglichkeit, die Daten in gewissem Rahmen zu transformieren. Für die gewünschte Darstellung der Kennzahlen ist die Verwendung von Qlik Sense Script oftmals erforderlich, jedoch kommen Anfänger auch lange ohne Coding aus. Insgesamt bewerte ich die Nutzerfreundlichkeit auf Grund der intuitiveren Bedienung subjektiv höher als bei Tableau oder Power BI.
Es können Erweiterungen und Widgets zur tiefgründigen Dashboard Erstellung und Analyse genutzt werden. Es gibt viele Drag and Drop Funktionen, um die Dashboards zusammen zu ziehen. Die Erstellung einfacher Berichte erfordert keinen Entwickler oder einen gut ausgebildeten Data Analyst, dennoch werden Unternehmen bei größeren Vorhaben auf Grund der Komplexität von Unternehmensprozessen, die in der Business Intelligence darzustellen versucht werden, nicht um geschultes Personal herum kommen, wofür es viele Angebote an Trainings auch von Qlik-Partnern gibt. Die Schnelligkeit der Datenverarbeitung liegt dank der Associative Engine im Vergleich zu den anderen beiden Tools vorne. AI-gestützte Vorschläge können bei der Dashboard-Erstellung zusätzliche Unterstützung leisten. Die Kombination beider Komponenten, Schnelligkeit und Ai-gestützte Vorschläge des Insight Advisors, grenzt das Qlik Sense Tool zwar nicht so sehr von den anderen Anbietern ab, wie Qlik gerne hätte…. Dennoch ist Qlik Sense auch heute noch ein Tool, dass für Ad-Hoc-Analytics wie Business Intelligence mit Standard Reporting in Erwägung gezogen werden sollte.








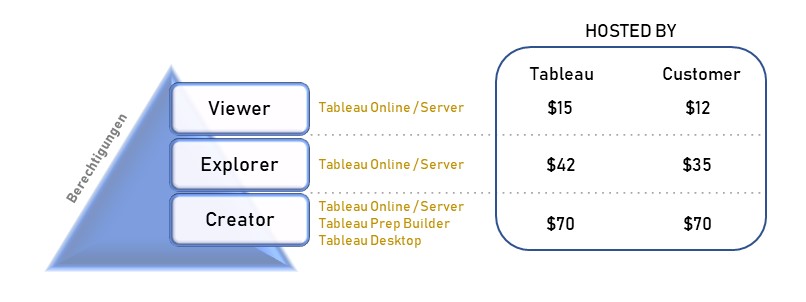 Der Creator ist befähigt, alle Funktionen von Tableau zu nutzen, sofern ein Unternehmen die angebotenen Add-ons hinzukauft. Die Lizenz Explorer ermöglicht es dem User, durch den Creator vordefinierte Datasets in Eigenregie zu analysieren und zu visualisieren. Demnach obliegt dem Creator, und somit einer kleinen Personengruppe, die Datenbereitstellung, womit eine Single Source of Truth garantiert werden soll. Der Viewer hat nur die Möglichkeit Berichte zu konsumieren, zu teilen und herunterzuladen. Wobei in Bezug auf Letzteres der Viewer limitiert ist, da dieser nicht die kompletten zugrundeliegenden Daten herunterladen kann. Lediglich eine Aggregation, auf welcher die Visualisierung beruht, kann heruntergeladen werden. Ein
Der Creator ist befähigt, alle Funktionen von Tableau zu nutzen, sofern ein Unternehmen die angebotenen Add-ons hinzukauft. Die Lizenz Explorer ermöglicht es dem User, durch den Creator vordefinierte Datasets in Eigenregie zu analysieren und zu visualisieren. Demnach obliegt dem Creator, und somit einer kleinen Personengruppe, die Datenbereitstellung, womit eine Single Source of Truth garantiert werden soll. Der Viewer hat nur die Möglichkeit Berichte zu konsumieren, zu teilen und herunterzuladen. Wobei in Bezug auf Letzteres der Viewer limitiert ist, da dieser nicht die kompletten zugrundeliegenden Daten herunterladen kann. Lediglich eine Aggregation, auf welcher die Visualisierung beruht, kann heruntergeladen werden. Ein