Die Interaktion in Netzwerken ist mit der Entstehung von sozialen Netzwerken, der Einkauf in Online-Shops, die Finanzierungen mit Crowd-Funding oder die nächste Mitfahrgelegenheit ein wesentlicher Bestandteil in unserem Alltag geworden. Insbesondere in der Share Economy hat sich die Bildung von Netzwerken als Erfolgsfaktor digitaler Geschäftsmodelle bereits fest etabliert. Je nach Geschäftsmodell kommt hierbei im Allgemeinen folgende Fragestellung auf:
Was hängt miteinander zusammen und welcher Effekt löst die Verbindung aus?
Effekte können das Wachsen oder Schrumpfen beschleunigen bzw. zu Strukturveränderungen des Netzwerks selbst führen. Eine Besonderheit ist der mögliche Multiplikator-Effekt bis hin zum Erreichen des Tipping-Points, der zu einen überproportionalen Wachstum, nach Erreichen einer kritischen Masse hervorgerufen wird. Aus der Geschäftsperspektive sind vor allem die Wachstumseffekte für eine schnelle Umsatzgenerierung interessant. Daher ist das Erkennen solcher Effekte wesentlich für den Geschäftserfolg.
Aufgrund der Komplexität und der Dynamik solcher Netzwerke ist der Einsatz von Data Mining Methoden zur Erkennung solcher Effekte, anhand von Mustern oder Regeln, hilfreich. In diesem Blog-Beitrag wird der Effekt von Netzwerken anhand von Produktverkäufen erläutert. Diese können beim Einkauf in Online-Shops oder im stationären Handel stattfinden. Hierbei unterscheiden sich die Konsumentengewohnheiten deutlich vom gewählten Kanal des Einkaufs oder welche Produkte eingekauft werden. Ob es um Lebensmittel, Kleidung oder Autos geht, das Kaufverhalten kann sich deutlich unterscheiden ob hierbei regelmäßige oder Spontankäufe vorliegen. Auch wer mögliche Zielgruppen darstellt ist ein wesentlicher Faktor. All diese Überlegungen werden im analytischen Customer Relationship Management zusammengefasst und bilden eine Reihe an Methoden zur Analyse dieser Phänomene (u.a. Customer-Lifetime-Value, Klassifikation, Churn-Analyse).
Aus den benannten Eigenheiten ist ein Verständnis über das Geschäft entscheidend für die Auswahl geeigneter Data Mining Methoden und dessen Interpretation von Erkenntnissen. Bevor es jedoch zur Interpretation kommt, werden die erforderlichen Vorabschritte über einen strukturierten Prozess für die Analyse in diesem Beitrag vorgestellt.
Data Mining Prozess
Ein ausgewählter Prozess bildet der KDD-Prozess (Knowledge Discovery in Databases) nach Fayyad, Piatetsky-Shapiro und Smyth. Alternative Herangehensweisen wie CRISP-DM (Cross Industry Standard Process for Data Mining) oder SEMMA (Sample, Explore, Modify, Model, Asses) können hierbei zu ähnlichen Ergebnissen führen.
Der KDD-Prozess unterteilt Data Mining Vorhaben in die folgenden Schritte:
- Bereitstellung des Domänenwissen und Aufstellung der Ziele
- Datenauswahl
- Datenbereinigung und -verdichtung (Transformation)
- Modellauswahl
- Data Mining
- Interpretation der Erkenntnissen
Je nach Umfang des Data Mining Vorhaben können sich die sechs Schritte weiter ausdifferenzieren. Jedoch wird sich in diesem Beitrag auf diese sechs Schritte fokussiert.
Domänenwissen und Zielstellung
Aus der obigen Einleitung wurde dargestellt, dass ein Domänenwissen essentiell für das Data Mining Vorhaben darstellt. Aus diesem Grund muss vor Beginn des Projekts ein reger Austausch über die Zielstellung zwischen Data Scientists und Entscheidungsträger stattfinden. Insbesondere die explorative Natur von Analysevorhaben kann dazu genutzt werden, um neue Muster zu identifizieren. Hierbei haben diese Muster jedoch nur einen Neuigkeitswert, wenn diese von den Entscheidungsträgern als originell und wertstiftend interpretiert werden. Daher müssen beide Seiten einen möglichst tiefen Einblick in das Geschäft und möglicher Analysen geben, da ansonsten das Projekt im „Shit-In, Shit-Out“-Prinzip mündet. Dies gilt gleichermaßen für die bereitgestellten Daten.
In diesem Beitrag geht es um den Kauf von Produkten durch Konsumenten. Dabei wird die Platzierung von Produkten in Online-Shops und stationären Handel im Wesentlichen durch den Betreiber bzw. Anbieter bestimmt. Während in Online-Shops die Produkte durch Recommendation-Engines zusätzlich platziert werden können ist im stationären Handel ein höherer Aufwand durch Point-of-Interest (POI) Platzierungen erforderlich. Jedoch gilt als Vision in der digitalen Transformation, das die Produkte durch das Konsumentenverhalten platziert werden sollen. Hierbei wird davon ausgegangen das die konsumentengetriebene Platzierung den höchstmöglichen Cross-Selling-Effekt erzielt. Dies lässt sich in einer Zielstellung für das Data Mining Vorhaben zusammenfassen:
Steigerung des Umsatzes durch die Steigerung des Cross-Selling-Effekts anhand einer konsumentengetriebenen Platzierung von Produkten
In dieser Zielstellung wird der Cross-Selling-Effekt als Treiber für die Umsatzsteigerung hervorgehoben. Hierbei wird davon ausgegangen, das gemeinsam platzierte Produkte, das Interesse von Konsumenten steigert auch beide Produkte zu kaufen. Dies führt zu einem insgesamt gesteigerten Umsatz anstatt, wenn beide Produkte nicht gemeinsam beworben oder platziert werden. Aus der Zielstellung lässt sich anschließend die Auswahl der Daten und erforderliche Aufbereitungsschritte ableiten.
Datenauswahl, -bereinigung und -verdichtung
Der Umsatz ist die Zielvariable für die Entscheidungsträger und dient als Kennzahl zur Messung der Zielstellung. Für den Cross-Selling-Effekt müssen die Verbindungen von gemeinsam gekauften Produkten identifiziert werden. Dies stellt das grundlegende Netzwerk da und wird durch das Konsumverhalten bestimmt.
Als Datengrundlage wird daher der Warenkorb mit den gemeinsam gekauften Produkten herangezogen. Dieser dient als Entscheidungsgrundlage und es lassen sich einerseits die erzielten Umsätze und Zusammenhänge zwischen den Produkten erkennen.
Aufgrund der Vertraulichkeit solcher Projekte und umfangreichen Datenaufbereitungsschritten wird zur Vereinfachung ein synthetisches Beispiel herangezogen. Insbesondere die erforderlichen Schritte zur Erreichung einer hohen Datenqualität ist ein eigener Beitrag wert und wird von diesem Beitrag abgegrenzt. Dies ermöglicht den Fokus auf die Kernerkenntnisse aus dem Projekt ohne von den detaillierten Schritten und Teilergebnissen abgelenkt zu werden.
Generell besteht ein Warenkorb aus den Informationen gekaufter Produkte, Stückzahl und Preis. Diese können noch weitere Informationen, wie bspw. Mehrwertsteuer, Kasse, Zeitpunkt des Kaufs, etc. enthalten. Für dieses Projekt sieht die allgemeine Struktur wie folgt aus:
|
|
{ "key":"basket1", "children":[ {"description":"Product 1",”quantity”: 1, "price": 12.2}, {"description":"Product 2",”quantity”: 2, "price ": 1.8}, {"description":"Product 3",”quantity”: 5, "price ": 3.98}, … {"description":"Product 99",”quantity”: 1, "price ": 16.95} ], … } |
Dabei wird jeder Warenkorb mit einem eindeutigen Schlüssel („key“) und den enthaltenen Produktinformationen versehen. In den Rohdaten können sich eine Menge von Datenqualitätsfehlern verbergen. Angefangen von fehlenden Informationen, wie bspw. der Produktmenge aufgrund von Aktionsverkäufen, uneindeutigen Produktbezeichnungen wegen mangelnder Metadaten, Duplikaten aufgrund fehlgeschlagener Datenkonsolidierungen, beginnt die Arbeit von Data Scientists oft mühselig.
In dieser Phase können die Aufwände für die Datenaufbereitung oft steigen und sollten im weiteren Projektvorgehen gesteuert werden. Es gilt eine ausreichende Datenqualität in dem Projekt zu erzielen und nicht eine vollständige Datenqualität des Datensatzes zu erreichen. Das Pareto-Prinzip hilft als Gedankenstütze, um im besten Fall mit 20% des Aufwands auch 80% der Ergebnisse zu erzielen und nicht umgedreht. Dies stellt sich jedoch oft als Herausforderung dar und sollte ggf. in einem Vorabprojekt vor dem eigentlichen Data-Mining Vorhaben angegangen werden.
Modellauswahl und Data Mining
Nach der Datenaufbereitung erfolgen die eigentliche Modellauswahl und Ausführung der Analyseprozesse. Aus der Zielstellung wurde der Umsatz als Kennzahl abgeleitet. Diese Größe bildet eine Variable für das Modell und der anschließenden Diskussion der Ergebnisse. Das dahinterstehende Verfahren ist eine Aggregation der Umsätze von den einzelnen Produkten.
Der Cross-Selling-Effekt ist dagegen nicht einfach zu aggregieren sondern durch ein Netzwerk zu betrachten. Aus Sicht der Netzwerkanalyse bilden die Produkte die Knoten und die gemeinsamen Käufe die Kanten in einem Graphen. Ein Graph hat den Vorteil die Verbindungen zwischen Produkten aufzuzeigen, kann jedoch auch zu einer endlosen Verstrickung führen in der sich bei einer anschließenden Visualisierung nichts erkennen lässt. Dieser Enmesh-Effekt tritt insbesondere bei einer hohen Anzahl an zu verarbeitenden Knoten und Kanten auf. Wenn wir in eine Filiale oder Online-Shop schauen ist dieser Enmesh-Effekt durchaus gegeben, wenn wir anfangen die Produkte zu zählen und einen Blick auf die täglichen Käufe und erzeugten Kassenbons bzw. Bestellungen werfen. Der Effekt wird umso größer wenn wir nicht nur eine Filiale sondern global verteilte Filialen betrachten.
Aus diesem Grund müssen die Knoten und Verbindungen mit den angemessenen Ergebniswerten hinterlegt und visuell enkodiert werden. Auch eine mögliche Aggregation (Hierarchie), durch bspw. einem Category Management ist in Betracht zu ziehen.
Die Modellauswahl bildet daher nicht nur die Auswahl des geeigneten Analysemodells sondern auch dessen geeignete Visualisierung. In dem Beitragsbeispiel wird die Assoziationsanalyse als Modell herangezogen. In diesem Verfahren wird die Suche nach Regeln durch die Korrelation zwischen gemeinsam gekauften Produkten eruiert. Die Bedeutung einer Regel, bspw. „Produkt 1 wird mit Produkt 2 gekauft“ wird anhand des Lifts angegeben. Aus der Definition des Lifts lässt sich erkennen, dass dieses Verfahren für die Messung des Cross-Selling-Effekts geeignet ist. Hierbei können unterschiedliche Algorithmen mit unterschiedlichen Ausgangsparametern herangezogen werden (z.B. AIS, Apriori, etc.). Entscheidend ist dabei nicht nur eine Modellkonstellation zu wählen sondern sich auf eine Menge von Modellen zu beziehen. Dabei kann das Modell mit den vielversprechendsten Ergebnissen ausgewählt werden.
Nach der Ausführung des Analyseverfahrens und der Bereinigung sowie -verdichtung der Warenkorbdaten ergeben sich einerseits die aggregierten Produktumsätze als auch die berechneten Modelldaten.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
//Produktumsätze { "key":"revenues", "children":[ {"description":"Product 1","revenue":1245354.2}, {"description":"Product 2","revenue":13818.8}, {"description":"Product 3","revenue":27565}, {"description":"Product 4","revenue":4245}, {"description":"Product 5","revenue":2450}, {"description":"Product 6","revenue":707897.69}, {"description":"Product 7","revenue":10398}, {"description":"Product 8","revenue":4688.8}, {"description":"Product 9","revenue":110713.5}, ... {"description":"Product 10","revenue":76141} ]} |
Neben den Lift dienen die Hilfsvariablen Support und Confidence auch als Kenngrößen, um einen Aufschluss auf die Validität der errechneten Ergebnisse zu geben. Diese beiden Werte können dazu genutzt werden, einzelnen Knoten aufgrund ihrer unwesentlichen Bedeutung zu entfernen und damit das Netzwerk auf die wesentlichen Produktverbindungen zu fokussieren.
|
|
//Modelldaten [{"source":"Product 1","target":"Product 2","lift":11, "parent": "revenues"}, {"source":"Product 2","target":"Product 6","lift":9, "parent": "revenues"}, {"source":"Product 3","target":"Product 20","lift":4, "parent": "revenues"}, {"source":"Product 4","target":"Product 59","lift":5, "parent": "revenues"}, {"source":"Product 5","target":"Product 46","lift":16, "parent": "revenues"}, {"source":"Product 6","target":"Product 17","lift":18, "parent": "revenues"}, {"source":"Product 7","target":"Product 6","lift":13, "parent": "revenues"}, {"source":"Product 8","target":"Product 56","lift":25, "parent": "revenues"}, ... {"source":"Product 26","target":"Product 49","lift":16, "parent": "revenues"} ] |
Diese beiden Zieldatensätze werden für die Ergebnispräsentation und der Interpretation herangezogen. Generell findet in den Phasen der Datenauswahl bis zum Data Mining ein iterativer Prozess statt, bis die Zielstellung adäquat beantwortet und gemessen werden kann. Dabei können weitere Datenquellen hinzukommen oder entfernt werden.
Interpretation der Erkenntnisse
Bevor die Ergebnisse interpretiert werden können muss eine Visualisierung auch die Erkenntnisse verständlich präsentieren. Dabei kommt es darauf die originellsten und nützlichsten Erkenntnisse in den Vordergrund zu rücken und dabei das bereits Bekannte und Wesentliche des Netzwerks nicht zur vergessen. Nichts ist schlimmer als das die investierten Mühen in Selbstverständnis und bereits bekannten Erkenntnissen in der Präsentation vor den Entscheidungsträgern versickern.
Als persönliche Empfehlung bietet sich Datenvisualisierung als geeignetes Medium für die Aufbereitung von Erkenntnissen an. Insbesondere die Darstellung in einem „Big Picture“ kann dazu genutzt werden, um bereits bekannte und neue Erkenntnisse zusammenzuführen. Denn in der Präsentation geht es um eine Gradwanderung zwischen gehandhabter Intuition der Entscheidungsträger und dem Aufbrechen bisheriger Handlungspraxis.
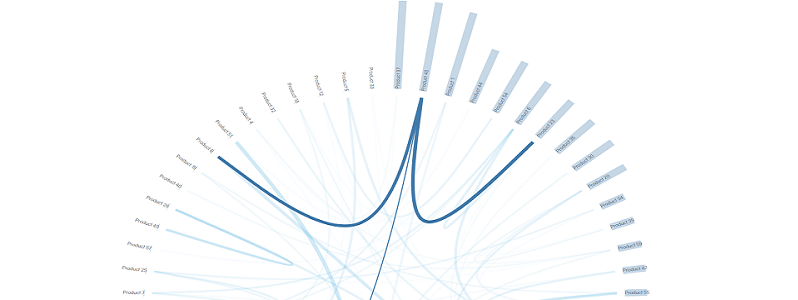
In der folgenden Visualisierung wurden die Produkte mit ihren Umsätzen kreisförmig angeordnet. Durch die Sortierung lässt sich schnell erkennen welches Produkt die höchsten Umsätze anhand der Balken erzielt. Der Lift-Wert wurde als verbindende Linie zwischen zwei Produkten dargestellt. Dabei wird die Linie dicker und sichtbarer je höher der Lift-Wert ist.

Abbildung 1: Netzwerkvisualisierung von erkannten Regeln zu gekauften Produkten (ein Klick auf die Grafik führt zur interaktiven JavaScript-Anwendung)
[box type=”info” style=”rounded”]Dieser Link (Klick) führt zur interaktiven Grafik (JavaScript) mit Mouse-Hover-Effekten.[/box]
Es wurde versucht die Zieldatensätze in einem Big Picture zusammenzuführen, um das Netzwerk in seiner Gesamtheit darzustellen. Hieraus lässt sich eine Vielzahl von Erkenntnissen ablesen:
- Das „Produkt 37“ erzielt den höchsten Umsatz, zeigt jedoch keinen Cross-Selling-Effekt von gemeinsam gekauften Produkten.
- Dagegen das „Produkt 23“ erzielte weniger Umsatz, wird jedoch häufig mit anderen Produkten gemeinsam gekauft.
- Das „Produkt 8“ weist zwei starke Regeln (Assoziationen) für „Produkt 45 & 56“ auf. Ggf. lassen sich diese Produkte in Aktionen zusammenanbieten.
Im Erstellungsprozess der Ergebnispräsentation ergab sich die Erfahrungspraxis flexibel eine geeignete Visualisierung zu erstellen anstatt die Erkenntnisse in vordefinierte Visualisierungen oder Diagramme zur pressen. Dies kann einerseits den Neuigkeitswert erhöhen und die Informationen anschließend besser transportieren aber auf der anderen Seite den Aufwand zur Erstellung der Visualisierung und das Verständnis für die neu erstellte Visualisierung mindern.
Ein Blick hinter die Bühne zeigt, dass die Visualisierung mit D3.js erstellt wurde. Dies bietet ein geeignetes Framework für die Flexibilität zur Erstellung von Datenpräsentationen. Wer sich nach Bibliotheken in R oder Python umschaut, wird auch in diesen Technologiebereichen fündig. Für R-Entwickler existierten die Packages „statnet“ und „gplots“ zur Verarbeitung und Visualisierung von Netzwerkdaten. Für Ptyhon-Entwickler steht graph-tool als sehr leistungsfähiges Modul, insb. für große Mengen an Knoten und Kanten zur Verfügung.
In unserem Vorhaben haben wir uns für D3.js aufgrund der möglichen Implementierung von Interaktionsmöglichkeiten, wie bspw. Highlighting von Verbindungen, entschieden. Dies ermöglicht auch eine bessere Interaktion mit den Entscheidungsträgern, um relevante Details anhand der Visualisierung darzustellen.
Ein Abriss in die Entwicklung der D3-Visualisierung zeigt, dass die Daten durch eine Verkettung von Methoden zur Enkodierung von Daten implementiert werden. Hierbei wird bspw. den Produkten ein Rechteck mit der berechneten Größe, Position und Farbe (.attr()) zugewiesen.
|
|
svg.selectAll(".node_rect_shape") .data(nodes.filter(function(n) { return !n.children; })) .enter().append("g") .attr("class", "node_rect") .attr("transform", function(d) { return "rotate(" + (d.x - 90) + ")translate(" + (d.y + rect_width)+ ")"; }) .append("rect") .attr("x", function(d) { return -(rect_width/2.0); }) .attr("width", function(d) { return rect_width; }) .attr("height", function(d) { return rect_size_scale(parseFloat(d.values)); }) .attr("class", "node_rect_shape") .attr("transform", function(d) { return "rotate(" + (-90) + ")"; }) .on("mouseover", mouseovered) .on("mouseout", mouseouted); |
Insbesondere die Höhe des Balkens zur Darstellung des Umsatzes wird mit der Implementierung von Skalen erleichtert.
|
|
var rect_size_scale = d3.scale.linear().domain([0, d3.max(revenue_data.children, function(d){return parseFloat(d.values);})]).range([0, rect_height]); |
Für die verbindenden Linien wurde auch ein visuelles Clustering anhand eines Edge-Bundling herangezogen. Dies führt gemeinsame Verbindungen zusammen und reduziert den Enmesh-Effekt.
|
|
link.data(bundle(links)).enter().append("path") .each(function(d) { d.source = d[0], d.target = d[d.length - 1]; }) .attr("class", "link") .style("stroke-opacity", function(d, i){ return transparent_scale(link_data[i].lift); }) .style("stroke-width", function(d, i){ return size_scale(link_data[i].lift); }) .attr("d", line); |
* Das vollständige Beispiel kann dem zip-File (siehe Download-Link unten) entnommen werden. Die Ausführung reicht mit einem Klick auf die index.html Datei zur Darstellung im Browser aus.
Eine kritische Betrachtung der Ergebnisvisualisierung zeigt auf, dass die Anordnung der Produkte (Knoten) das interpretieren der Darstellung vereinfacht aber auch hier der Enmesh-Effekt fortschreitet je höher die Anzahl an Verbindungen ist. Dies wurde mit verschiedenen Mitteln im Analyseverfahren (Modellparameter, Entfernen von Produkten aufgrund eines geringen Supprt/Confidence Wertes oder Pruning) als auch in der der Darstellung (Transparenz, Linienstärke Edge-Bundling) reduziert.
Fazit
Als Quintessenz lässt sich festhalten, dass eine Auseinandersetzung mit Netzwerken auch Überlegungen über Komplexität im gesamten Data-Mining Vorhaben mit sich bringt. Dabei unterscheiden sich diese Überlegungen zwischen Data Scientists und Entscheidungsträger nach dem Kontext. Während Data Scientists über das geeignete Analyseverfahren und Visualisierung nachdenken überlegt der Entscheidungsträger welche Produkte wesentlich für sein Geschäft sind. Auf beiden Seiten geht es darum, die entscheidenden Effekte herauszuarbeiten und die Zielstellung gemeinsam voranzutreiben. Im Ergebnis wurde die Zielstellung durch die Darstellung der Produktumsätze und der Darstellung des Cross-Selling-Impacts in einem Netzwerk als Big Picture aufbereitet. Hieraus können Entscheidungsträger interaktiv, die geeigneten Erkenntnisse für sich interpretieren und geeignete Handlungsalternativen ableiten. Dabei hängt jedoch die Umsetzung einer konsumentengetriebenen Produktplatzierung vom eigentlichen Geschäftsmodell ab.
Während sich diese Erkenntnisse im Online-Geschäft einfach umsetzen lassen, ist dies eine Herausforderungen für den stationären Handel. Die Produktplatzierung in Filialen kann aufgrund der begrenzten Fläche als auch den Gewohnheiten von Konsumenten nur bedingt verändert werden. Daher können auch Mischformen aus bspw. „Online-Schauen, Offline-Kaufen“ eruiert werden.
Nach der Entscheidung erfolgt sogleich auch die Überlegung nach den Konsequenzen, Veränderungen und Einfluss auf das Geschäft. Hieraus bildet sich für Data Scientists und Entscheidungsträger eine Kette von Überlegungen über erkannte Muster in Netzwerken, Implikation und möglicher Prognosefähigkeit. Letzteres ist eine besondere Herausforderung, da die Analyse der Dynamik vom Netzwerk im Vordergrund steht. Die Suche nach einer kritischen Masse oder Tipping-Point kann zu möglichen Veränderungen führen, die aufgrund des Informationsmangels nur schwer vorhersagbar sind. Dies kann vom Ablegen bisheriger Gewohnheiten zu negativen Kundenfeedback aber auch positiver Wirkung gesteigerter Absätze rangieren.
Hierbei zeigt sich das evolutionäre als auch das disruptive Potenzial von Data Mining-Vorhaben unabhängig davon welche Entscheidung aus den Erkenntnissen abgeleitet wird. Data Scientists schaffen neue Handlungsalternativen anstatt auf bestehende Handlungspraxen zu verharren. Die Eigenschaft sich entsprechend der Dynamik von Netzwerken zu verändern ist umso entscheidender „Wie“ sich ein Unternehmen verändern muss, um im Geschäft bestehen zu bleiben. Dies gelingt nur in dem sich auf das Wesentliche fokussiert wird und so der Enmesh-Effekt erfolgreich durch einen Dialog zwischen Entscheidungsträger und Data Scientists in einer datengetriebenen Geschäftswelt gemeistert wird.
Quellcode Download
Der vollständige und sofort einsatzbereite Quellcode steht als .zip-Paket zum Download bereit.
Bitte hierbei beachten, dass die meisten Browser die Ausführung von JavaScript aus lokalen Quellen standardmäßig verhindern. JavaScript muss daher in der Regel erst manuell aktiviert werden.

 Frau Dr. Eva-Marie Müller-Stüler ist Associate Director in Decision Science der KPMG LLP in London. Sie absolvierte zur Diplom-Mathematikerin an der Technischen Universität München, mit einem einjährigen Auslandssemester in Tokyo, und promovierte an der Philipp Universität in Marburg.
Frau Dr. Eva-Marie Müller-Stüler ist Associate Director in Decision Science der KPMG LLP in London. Sie absolvierte zur Diplom-Mathematikerin an der Technischen Universität München, mit einem einjährigen Auslandssemester in Tokyo, und promovierte an der Philipp Universität in Marburg.