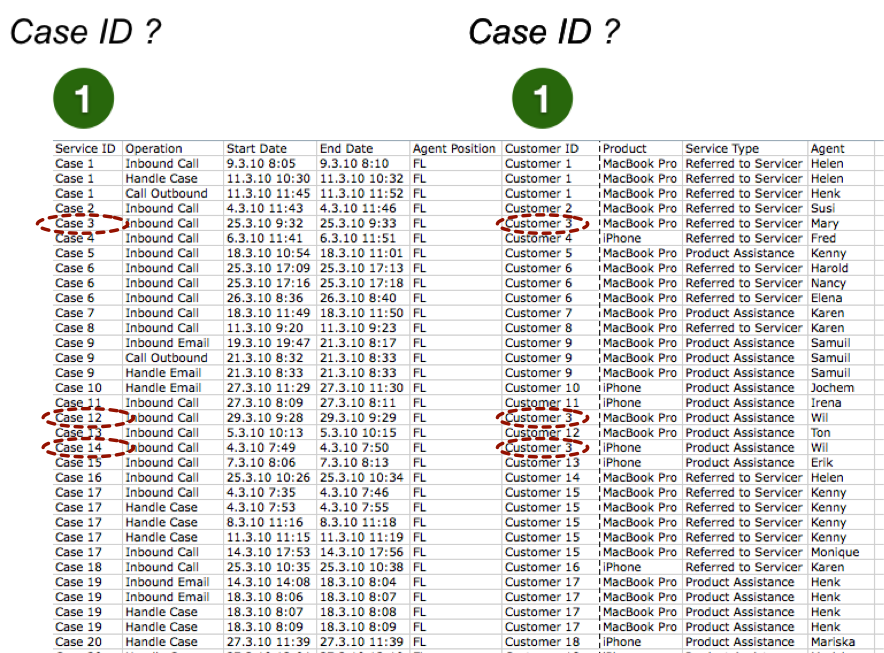
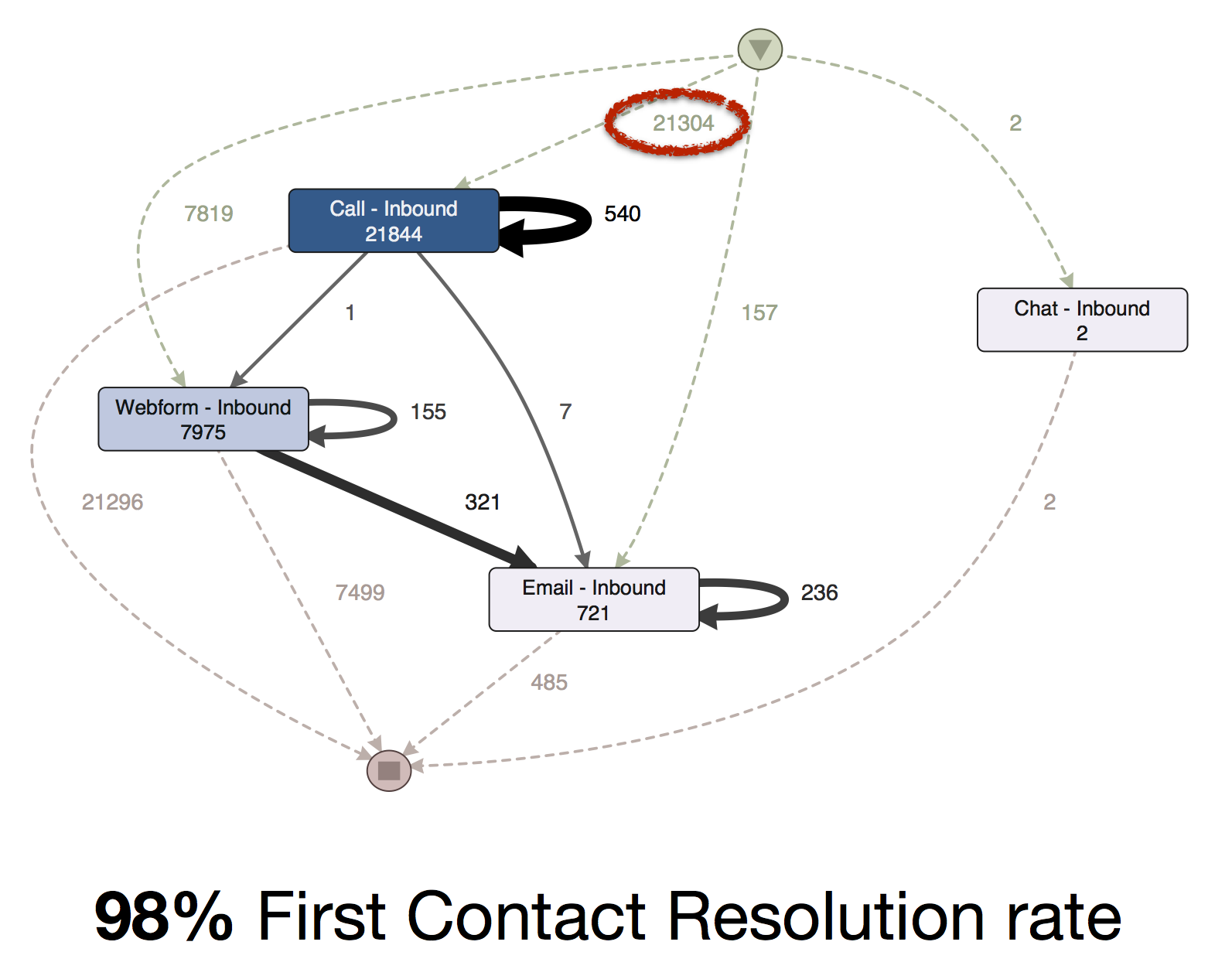
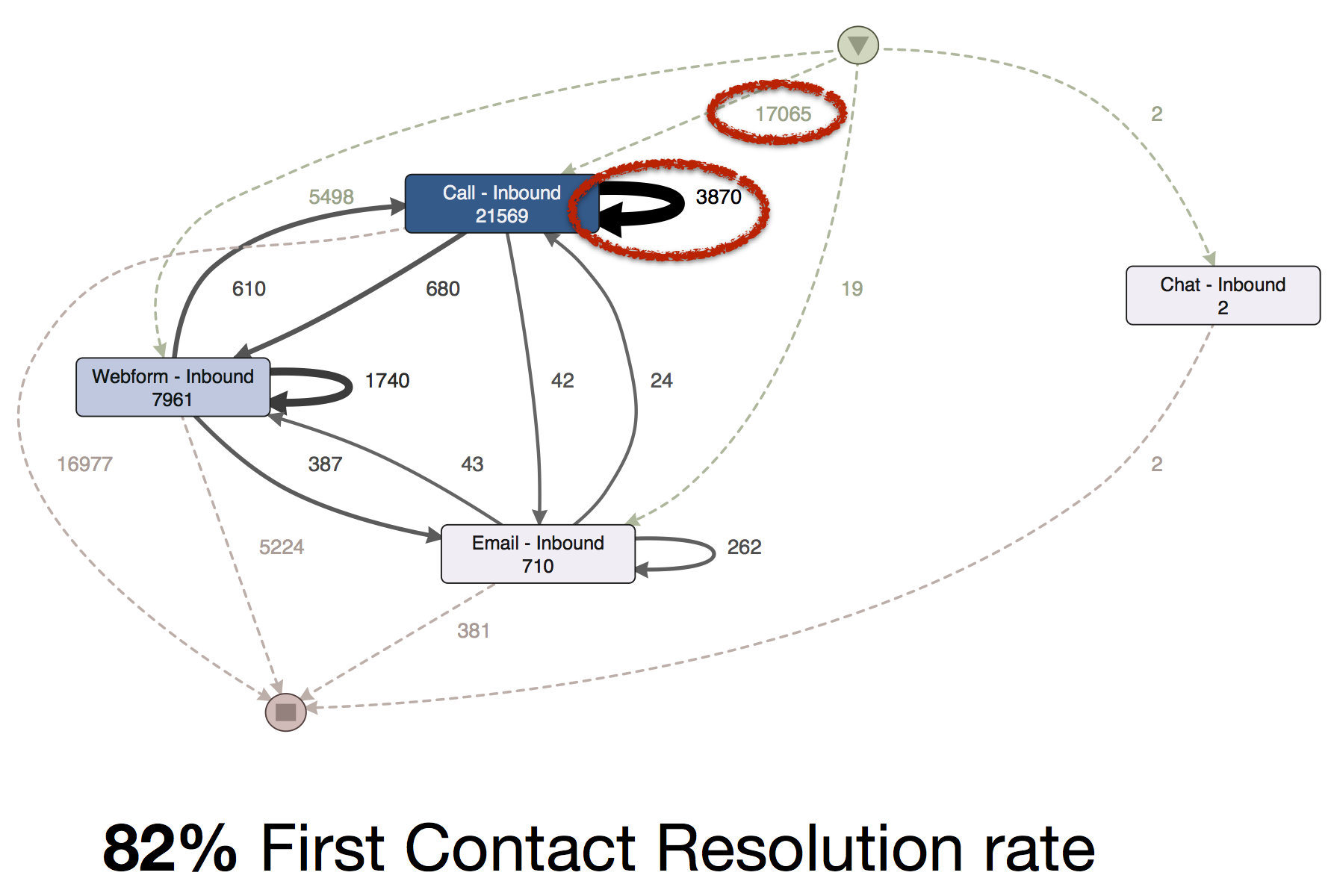
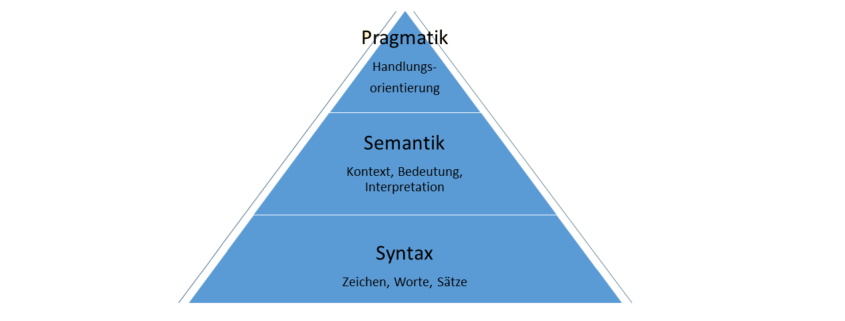
Beispiele für Data Science stehen häufig im Kontext von innovativen Internet-StartUps, die mit entsprechenden Methoden individuelle Kundenbedürfnisse in Erfahrung bringen. Es gibt jedoch auch eine Dunkle Seite der Macht, auf die ich nachfolgend über ein Brainstorming eingehen möchte.
Was ist Intelligence Gathering?
Unter Intelligence Gathering wird jegliche legale und illegale Beschaffung von wettbewerbsentscheidenden Informationen verstanden, von traditioneller Marktforschung bis hin zur Wirtschaftsspionage. Unter Intelligence Gathering fallen die Informationsbeschaffung und die Auswertung, wobei nicht zwangsläufig elektronische Beschaffungs- und Auswertungsszenarien gemeint sind, auch wenn diese den Großteil der relevanten Informationsbeschaffung ausmachen dürften.
Welche Data Science Methoden kommen zum Einsatz?
Alle. Unter dem Oberbegriff von Intelligence Gathering fallen die vielfältigsten Motive der Informationsgewinnung um Wettbewerbsvorteile zu erzielen. Genutzt werden statistische Datenanalysen, Process Mining, Predictive Analytics bis hin zu Deep Learning Netzen. Viele Einsatzzwecke bedingen ein gutes Data Engineering vorab, da Daten erstmal gesammelt, häufig in großen Mengen gespeichert und verknüpft werden müssen. Data Scraping, das Absammeln von Daten aus Dokumenten und von Internetseiten, kommt dabei häufig zum Einsatz. Dabei werden manchmal auch Grenzen nationaler Gesetze überschritten, wenn z. B. über die Umgehung von Sicherheitsmaßnahmen (z. B. IP-Sperren, CAPTCHA, bis hin zum Passwortschutz) unberechtigte Zugriffe auf Daten erfolgen.
Welche Daten werden beispielsweise analysiert?
- Social-Media-Daten
- Freie und kommerzielle Kontaktdatenbanken
- Internationale Finanzdaten (Stichwort: SWIFT)
- Import-Export-Daten (Stichworte: PIERS, AMS)
- Daten über Telefonie und Internetverkehr (Sitchwort: Vorratsdatenspeicherung)
- Positionsdaten (z. B. via GPS, IPs, Funkzellen, WLAN-Mapping)
- Daten über den weltweiten Reiseverkehr (Stichworte: CRS, GDS, PNR, APIS)
Das volle Potenzial der Daten entfaltet sich – wie jeder Data Scientist weiß – erst durch sinnvolle Verknüpfung.
Welche Insights sind beispielsweise üblich? Und welche darüber hinaus möglich?
Übliche Einblicke sind beispielsweise die Beziehungsnetze eines Unternehmens, aus denen sich wiederum alle wichtigen Kunden, Lieferanten, Mitarbeiter und sonstigen Stakeholder ableiten lassen. Es können tatsächliche Verkaufs- und Einkaufskonditionen der fremden Unternehmen ermittelt werden. Im Sinne von Wissen ist Macht können solche Informationen für eigene Verhandlungen mit Kunden, Lieferanten oder Investoren zum Vorteil genutzt werden. Häufiges Erkenntnisziel ist ferner, welche Mitarbeiter im Unternehmen tatsächliche Entscheider sind, welche beruflichen und persönlichen Vorlieben diese haben. Dies ist auch für das gezielte Abwerben von Technologieexperten möglich.
Darüber hinaus können dolose Handlungen wie etwa Bestechung oder Unterschlagung identifiziert werden. Beispielsweise gab es mehrere öffentlich bekannt gewordene Aufdeckungen von Bestechungsfällen bei der Vergabe von Großprojekten, die US-amerikanische Nachrichtendienste auf anderen Kontinenten aufgedeckt haben (z. B. der Thomson-Alcatel-Konzern Korruptionsfall in Brasilien). Die US-Politik konnte dadurch eine Neuvergabe der Projekte an US-amerikanische Unternehmen erreichen.
Welche Akteure nutzen diese Methoden der Informationsgewinnung?
Die Spitzenakteure sind Nachrichtendienste wie beispielsweise der BND (Deutschland), die CIA (USA) und die NSA (USA). In öffentlichen Diskussionen und Skandalen ebenfalls im Rampenlicht stehende Geheimdienste sind solche aus Frankreich, Großbritanien, Russland und China. Diese und andere nationale Nachrichtendienste analysieren Daten aus öffentlich zugänglichen Systemen, infiltrieren aber auch gezielt oder ungezielt fremde Computernetzwerke. Die Nachrichtendienste analysieren Daten in unterschiedlichsten Formen, neben Metadaten von z. B. Telefonaten und E-Mails auch umfangreiche Textinformationen, Bild-/Videomaterial sowie IT-Netzwerkverkehr. Der weltweit eingeschlagene Weg zur vernetzten Welt (Internet of Things) wird Intelligence Gathering weiter beflügeln.
[box]Anmerkung: Open Data Analytics
Eine Informationsquelle, die selbst von Experten häufig unterschätzt wird, ist die Möglichkeit der Gewinnung von Erkenntnissen über Märkte, Branchen und Unternehmen durch die Auswertung von öffentlich zugänglichen Informationen, die in gedruckter oder elektronischer Form in frei zugänglichen Open-Data-Datenbanken und Internetplattformen verfügbar gemacht werden, aber beispielsweise auch über Radio, Zeitungen, Journalen oder über teilweise frei zugängliche kommerzielle Datenbanken.[/box]
Die Nachrichtendienste analysieren Daten, um nationale Gefahren möglichst frühzeitig erkennen zu können. Längst ist jedoch bekannt, dass alle Nachrichtendienste zumindest auf internationaler Ebene auch der Wirtschaftsspionage dienen, ja sogar von Regierungen und Konzernen direkt dazu beauftragt werden.
Internet-Giganten wie Google, Baidu, Microsoft (Bing.com) oder Facebook haben Intelligence Gathering, häufig aber einfach als Big Data oder als Datenkrake bezeichnet, zu einem Hauptgeschäftszweck gemacht und sind nicht weit von der Mächtigkeit der Nachrichtendienste entfernt, in einigen Bereichen diesen vermutlich sogar deutlich überlegen (und zur Kooperation mit diesen gezwungen).
Finanzdienstleister wie Versicherungen und Investmentbanker nutzen Intelligence Gathering zur Reduzierung ihrer Geschäftsrisiken. Weitere Akteure sind traditionelle Industrieunternehmen, die auf einen Wettbewerbsvorteil durch Intelligence Methoden abzielen.
Nachfolgend beschränke ich mich weitgehend auf Intelligence Gathering für traditionelle Industrieunternehmen:

Industrielle Marktforschung
Die Industrielle Marktforschung ist eine auf bestimmte Branchen, Produkt- oder Kundengruppen spezialisierte Marktforschung die vor allem auf die Analyse des Kundenverhaltens abzielt. Diese kann auf vielen Wegen, beispielsweise durch gezielte Marktbeobachtung oder statistische Analyse der durch Kundenbefragung erhobenen Daten erfolgen. Customer Analytics und Procurement Analytics sind zwei Anwendungsgebiete für Data Science in der industriellen Marktforschung.
Business Intelligence und Competitive Intelligence
Der Begriff Business Intelligence ist aus der modernen Geschäftswelt nicht mehr wegzudenken. Business Intelligence bezeichnet die Analyse von unternehmensinternen und auch -externen Daten, um das eigene Unternehmen benchmarken zu können, eine Transparenz über die Prozesse und die Leistungsfähigkeit des Unternehmens zu erreichen. Das Unternehmen reflektiert sich mit Business Intelligence selbst.
Competitive Intelligence nutzt sehr ähnliche, in den überwiegenden Fällen genau dieselben Methoden, jedoch nicht mit dem Ziel, ein Abbild des eigenen, sondern ein Abbild von anderen Unternehmen zu erstellen, nämlich von direkten Konkurrenten des eigenen Unternehmens oder auch von strategischen Lieferanten oder Zielkunden.
Motivationen für Competitive Intelligence
Die Motivationen für die genaue Analyse von Konkurrenzunternehmen können sehr vielfältig sein, beispielsweise:
- Ermittlung der eigenen Wettbewerbsposition für ein Benchmarking oder zur Wettbewerberprofilierung
- (Strategische) Frühwarnung/-aufklärung
- Due Diligence bei Unternehmenskauf oder Bewertung von Marktzugangschancen
- Chancen-/Risikoanalyse für neue Angebote/Absatzregionen
- Issues Monitoring (für das eigene Unternehmen relevante Themen)
- Analyse von Kundenanforderungen
- Satisfaction Surveys (eigene und Wettbewerberkunden bzw. -zulieferer)
- Bewertung von Zulieferern (Loyalität, Preisgestaltung, Überlebensfähigkeit)
Viele dieser Anwendungsszenarien sind nicht weit weg von aktuellen Business Intelligence bzw. Data Science Projekten, die öffentlich kommuniziert werden. Beispielsweise arbeiten Data Scientists mit aller Selbstverständlichkeit im Rahmen von Procurement Analytics daran, Lieferantennetzwerke hinsichtlich der Ausfallrisiken zu analysieren oder auch in Abhängigkeit von Marktdaten ideale Bestellzeitpunkte zu berechnen. Im Customer Analytics ist es bereits Normalität, Kundenausfallrisiken zu berechnen, Kundenbedürfnisse und Kundenverhalten vorherzusagen. Die viel diskutierte Churn Prediction, also die Vorhersage der Loyalität des Kunden gegenüber dem Unternehmen, grenzt an Competetitve Intelligence mindestens an.
Wirtschaftsspionage
Während Competititve Intelligence noch mit grundsätzlich legalen Methoden der Datenbeschaffung und -auswertung auskommt, ist die Wirtschaftsspionage eine Form der Wirtschaftskriminalität, also eine illegale Handlung darstellt, die strafrechtliche Konsequenzen haben kann. Zur Wirtschaftsspionage steigern sich die Handlungen dann, wenn beispielsweise auch interne Dokumente oder der Datenverkehr ohne Genehmigung der Eigentümer abgegriffen werden.
Beispiele für Wirtschaftsspionage mit Unterstützung durch Data Science Methoden ist die Analyse von internen Finanztransaktionsdaten, des Datenverkehrs (über Leitungen oder Funknetze) oder des E-Mail-Verkehrs. Neue Methoden aus den Bereichen Machine Learning / Deep Learning werden auch die Möglichkeiten der Wirtschaftsspionage weiter beflügeln, beispielsweise durch Einsatz von gezielter Schrift-/Spracherkennung in Abhör-Szenarien.
Strafrechtliche Bewertung und Verfolgung
Die strafrechtliche Verfolgung von datengetriebener Wirtschaftsspionage ist in der Regel schwierig bis praktisch unmöglich. Zu Bedenken gilt zudem, dass Datenabgriffe und -analysen mit Leichtigkeit in anderen Nationen außerhalb der lokalen Gesetzgebung durchgeführt werden können.
Nicht zu vergessen: Data Science ist stets wertfrei zu betrachten, denn diese angewandte Wissenschaft kann zur Wirtschaftsspionage dienen, jedoch genauso gut auch bei der Aufdeckung von Wirtschaftsspionage helfen.
Literaturempfehlungen
Folgende Bücher sind Quellen für einen tieferen Einblick in Intelligence Gathering und die Möglichkeiten von Data Science zur Informationsbeschaffung.


Wirtschaftsspionage und Intelligence Gathering: Neue Trends der wirtschaftlichen Vorteilsbeschaffung


Data Mining and Predictive Analysis: Intelligence Gathering and Crime Analysis


 scientists, which will involve more sophisticated analysis, predictive modeling, regressions and Bayesian classification. That stuff at scale doesn’t work well on anyone’s engine right now. If you want to do complex analytics on big data, you have a big problem right now.”
scientists, which will involve more sophisticated analysis, predictive modeling, regressions and Bayesian classification. That stuff at scale doesn’t work well on anyone’s engine right now. If you want to do complex analytics on big data, you have a big problem right now.”