Daten in Formation bringen
Bei den vielfach stattfindenden Diskussionen um und über den Begriff Big Data scheint es eine Notwendigkeit zu sein, Daten und Informationen gegeneinander abzugrenzen. Auf Berthold Brecht geht folgendes Zitat zurück: „Ein Begriff ist ein Griff, mit denen man Dinge bewegen kann“. Folgt man dieser Aussage, so kann man leicht die falschen Dinge bewegen, wenn man die Begriffe nicht im Griff hat.
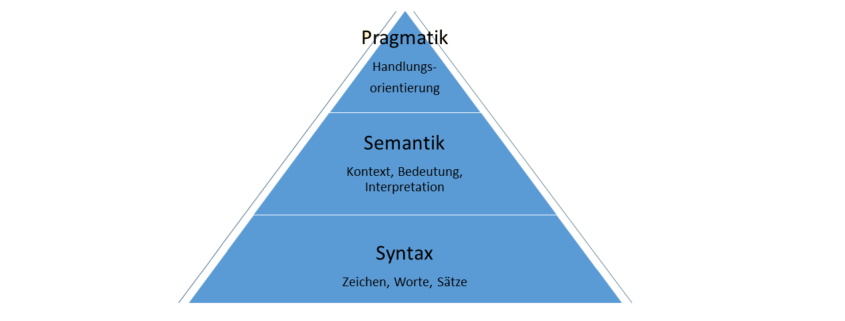
Eine mögliche Herangehensweise zur Unterscheidung der Begriffe Daten und Informationen liefert dabei die Semiotik (Zeichentheorie), welche in Syntax, Semantik und Pragmatik untergliedert werden kann:
Unter Syntax (altgr.: Ordnung, Reihenfolge) versteht man im Allgemeinen Regeln, welche es erlauben, elementare Zeichen zu neuen, zusammengesetzten Zeichen, Worten und Wortgruppen zu kombinieren. Daten sind tendenziell diesem Bereich zuzuordnen.
Beispiel: 10:30 24 Essen
Die Semantik (griech.: bezeichnen, zum Zeichen gehörend, auch Bedeutungslehre) indes beschäftigt sich mit Beziehungen und Bedeutung von Zeichen (Kontext). Regeln der Zusammensetzung aus der Syntax stehen demnach den Interpretationsregeln der Semantik gegenüber. Mit anderen Worten, der Kontext (Bezugsrahmen), in welchem die Zeichen verwendet werden, bestimmt deren Bedeutung. Ludwig Wittgenstein (1889 – 1951) verglich Worte mit Schachfiguren und postulierte, dass die Verwendung eines Wortes dessen Bedeutung bestimmt.
Beispiel: 10:30 Uhr 24 Grad Celcius Stadt Essen
Pragmatik wiederum beschäftigt sich mit dem Gebrauch von Worten und somit der Verwendung von Sprache in spezifischen Situationen. Bei Informationen stehen dabei Handlungsorientierung sowie subjektiver Nutzen im Vordergrund. Informationen reduzieren Unsicherheit beim Empfänger, sie bereiten eine Entscheidung vor.
Beispiel: Auf Grund der Temperatur in der Stadt Essen um 10:30 Uhr benötige ich keine Jacke

Abbildung 1 Daten versus Informationen, eigene Darstellung
Fazit:
(Big) Daten sind eine notwendige, aber keine hinreichende Bedingung für die Bildung von entscheidungsrelevanten Informationen. In anderen Worten, Daten sind vergleichbar mit Ziegelsteinen. Wenn man aus Ziegelsteinen (Daten) kein Haus (Kontext, Informationen) baut, sind es bloß Ziegelsteine. Man kann Informationen wiederum als Rohstoff interpretieren, aus welchem Entscheidungen hergestellt werden (können).