CAP Theorem
Understanding databases for storing, updating and analyzing data requires the understanding of the CAP Theorem. This is the second article of the article series Data Warehousing Basics.
Understanding NoSQL Databases by the CAP Theorem
CAP theorem – or Brewer’s theorem – was introduced by the computer scientist Eric Brewer at Symposium on Principles of Distributed computing in 2000. The CAP stands for Consistency, Availability and Partition tolerance.
- Consistency: Every read receives the most recent writes or an error. Once a client writes a value to any server and gets a response, it is expected to get afresh and valid value back from any server or node of the database cluster it reads from.
Be aware that the definition of consistency for CAP means something different than to ACID (relational consistency). - Availability: The database is not allowed to be unavailable because it is busy with requests. Every request received by a non-failing node in the system must result in a response. Whether you want to read or write you will get some response back. If the server has not crashed, it is not allowed to ignore the client’s requests.
- Partition tolerance: Databases which store big data will use a cluster of nodes that distribute the connections evenly over the whole cluster. If this system has partition tolerance, it will continue to operate despite a number of messages being delayed or even lost by the network between the cluster nodes.
CAP theorem applies the logic that for a distributed system it is only possible to simultaneously provide two out of the above three guarantees. Eric Brewer, the father of the CAP theorem, proved that we are limited to two of three characteristics, “by explicitly handling partitions, designers can optimize consistency and availability, thereby achieving some trade-off of all three.” (Brewer, E., 2012).
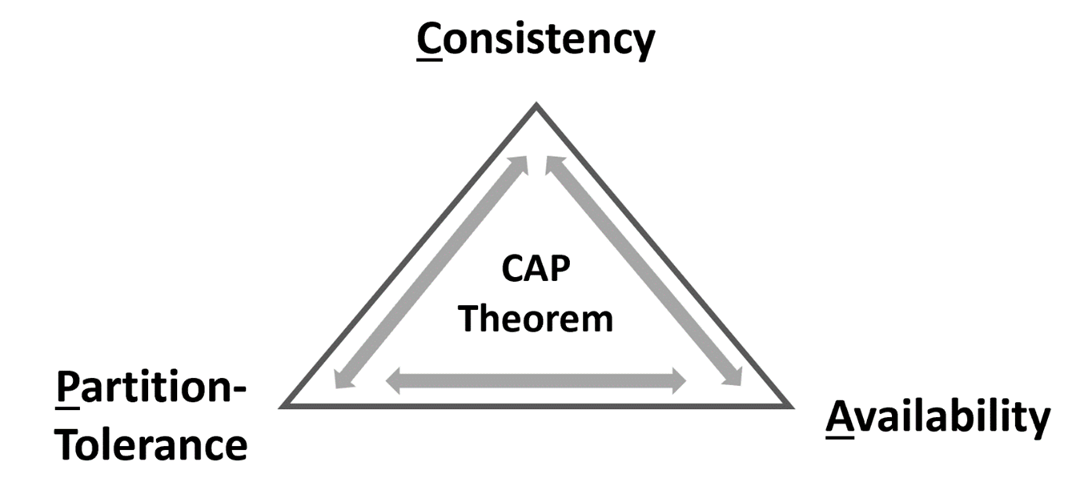
To recap, with the CAP theorem in relation to Big Data distributed solutions (such as NoSQL databases), it is important to reiterate the fact, that in such distributed systems it is not possible to guarantee all three characteristics (Availability, Consistency, and Partition Tolerance) at the same time.
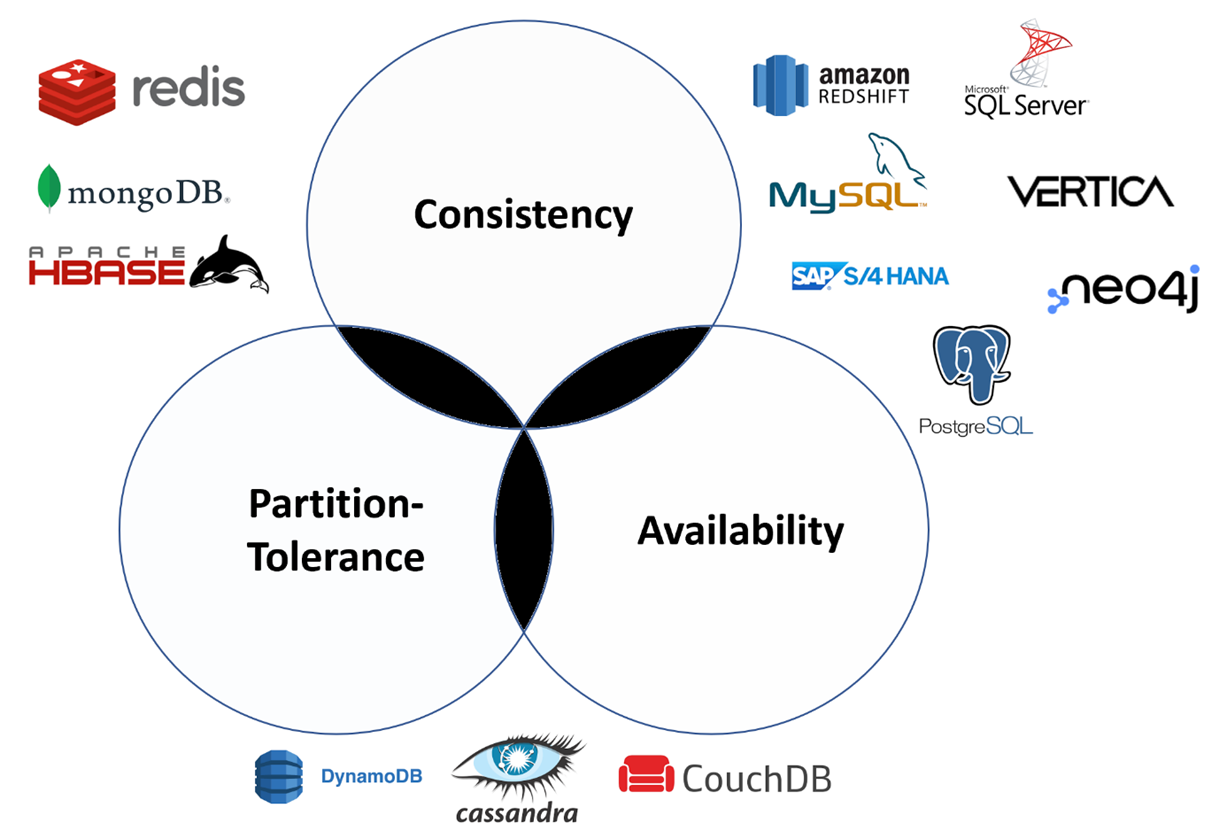
Database systems designed to fulfill traditional ACID guarantees like relational database (management) systems (RDBMS) choose consistency over availability, whereas NoSQL databases are mostly systems designed referring to the BASE philosophy which prefer availability over consistency.
The CAP Theorem in the real world
Lets look at some examples to understand the CAP Theorem further and provewe cannot create database systems which are being consistent, partition tolerant as well as always available simultaniously.
AP – Availability + Partition Tolerance
If we have achieved Availability (our databases will always respond to our requests) as well as Partition Tolerance (all nodes of the database will work even if they cannot communicate), it will immediately mean that we cannot provide Consistency as all nodes will go out of sync as soon as we write new information to one of the nodes. The nodes will continue to accept the database transactions each separately, but they cannot transfer the transaction between each other keeping them in synchronization. We therefore cannot fully guarantee the system consistency. When the partition is resolved, the AP databases typically resync the nodes to repair all inconsistencies in the system.
A well-known real world example of an AP system is the Domain Name System (DNS). This central network component is responsible for resolving domain names into IP addresses and focuses on the two properties of availability and failure tolerance. Thanks to the large number of servers, the system is available almost without exception. If a single DNS server fails,another one takes over. According to the CAP theorem, DNS is not consistent: If a DNS entry is changed, e.g. when a new domain has been registered or deleted, it can take a few days before this change is passed on to the entire system hierarchy and can be seen by all clients.
CA – Consistency + Availability
Guarantee of full Consistency and Availability is practically impossible to achieve in a system which distributes data over several nodes. We can have databases over more than one node online and available, and we keep the data consistent between these nodes, but the nature of computer networks (LAN, WAN) is that the connection can get interrupted, meaning we cannot guarantee the Partition Tolerance and therefor not the reliability of having the whole database service online at all times.
Database management systems based on the relational database models (RDBMS) are a good example of CA systems. These database systems are primarily characterized by a high level of consistency and strive for the highest possible availability. In case of doubt, however, availability can decrease in favor of consistency. Reliability by distributing data over partitions in order to make data reachable in any case – even if computer or network failure – meanwhile plays a subordinate role.
CP – Consistency + Partition Tolerance
If the Consistency of data is given – which means that the data between two or more nodes always contain the up-to-date information – and Partition Tolerance is given as well – which means that we are avoiding any desynchronization of our data between all nodes, then we will lose Availability as soon as only one a partition occurs between any two nodes In most distributed systems, high availability is one of the most important properties, which is why CP systems tend to be a rarity in practice. These systems prove their worth particularly in the financial sector: banking applications that must reliably debit and transfer amounts of money on the account side are dependent on consistency and reliability by consistent redundancies to always be able to rule out incorrect postings – even in the event of disruptions in the data traffic. If consistency and reliability is not guaranteed, the system might be unavailable for the users.
Conclusion
The CAP Theorem is still an important topic to understand for data engineers and data scientists, but many modern databases enable us to switch between the possibilities within the CAP Theorem. For example, the Cosmos DB von Microsoft Azure offers many granular options to switch between the consistency, availability and partition tolerance . A common misunderstanding of the CAP theorem that it´s none-absoluteness: “All three properties are more continuous than binary. Availability is continuous from 0 to 100 percent, there are many levels of consistency, and even partitions have nuances. Exploring these nuances requires pushing the traditional way of dealing with partitions, which is the fundamental challenge. Because partitions are rare, CAP should allow perfect C and A most of the time, but when partitions are present or perceived, a strategy is in order.” (Brewer, E., 2012).

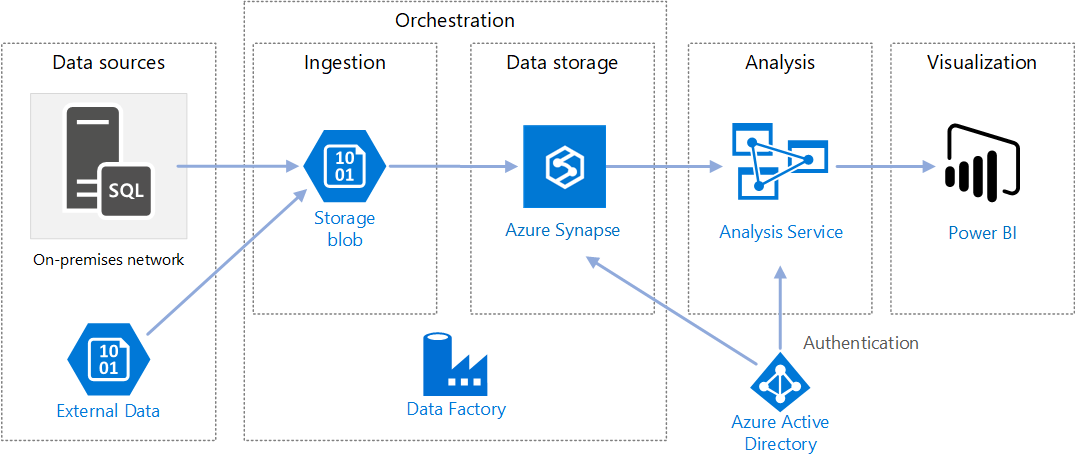 https://docs.microsoft.com/en-us/azure/architecture/reference-architectures/data/enterprise-bi-adfQuelle:
https://docs.microsoft.com/en-us/azure/architecture/reference-architectures/data/enterprise-bi-adfQuelle: 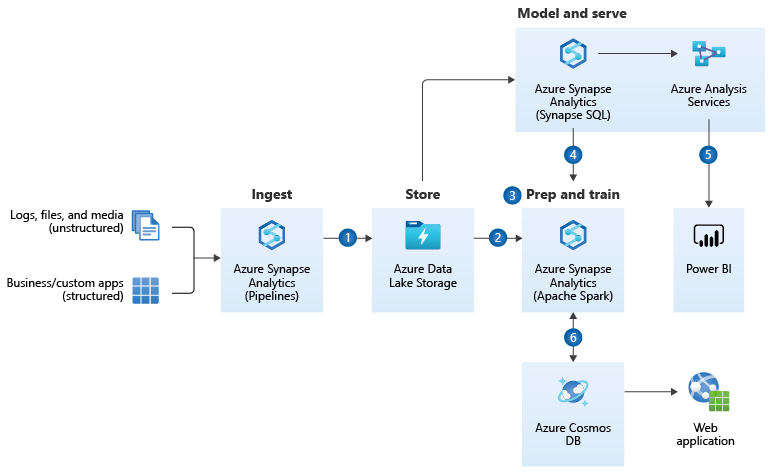 https://docs.microsoft.com/en-us/azure/architecture/solution-ideas/articles/enterprise-data-warehouseQuelle:
https://docs.microsoft.com/en-us/azure/architecture/solution-ideas/articles/enterprise-data-warehouseQuelle: 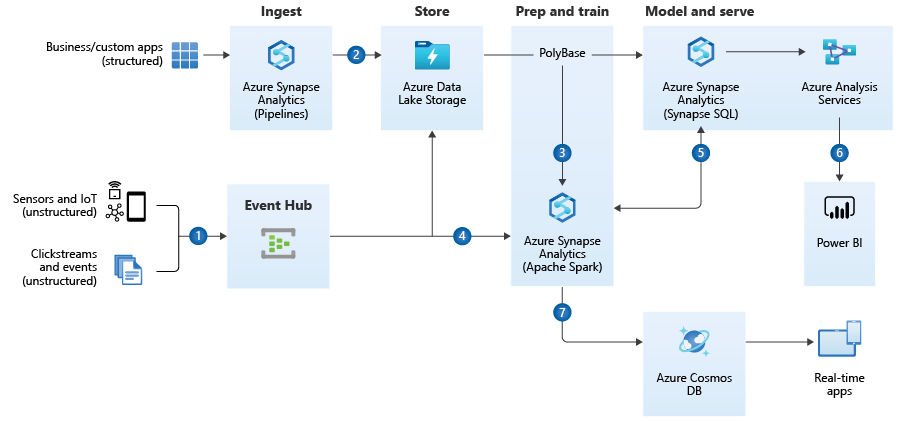
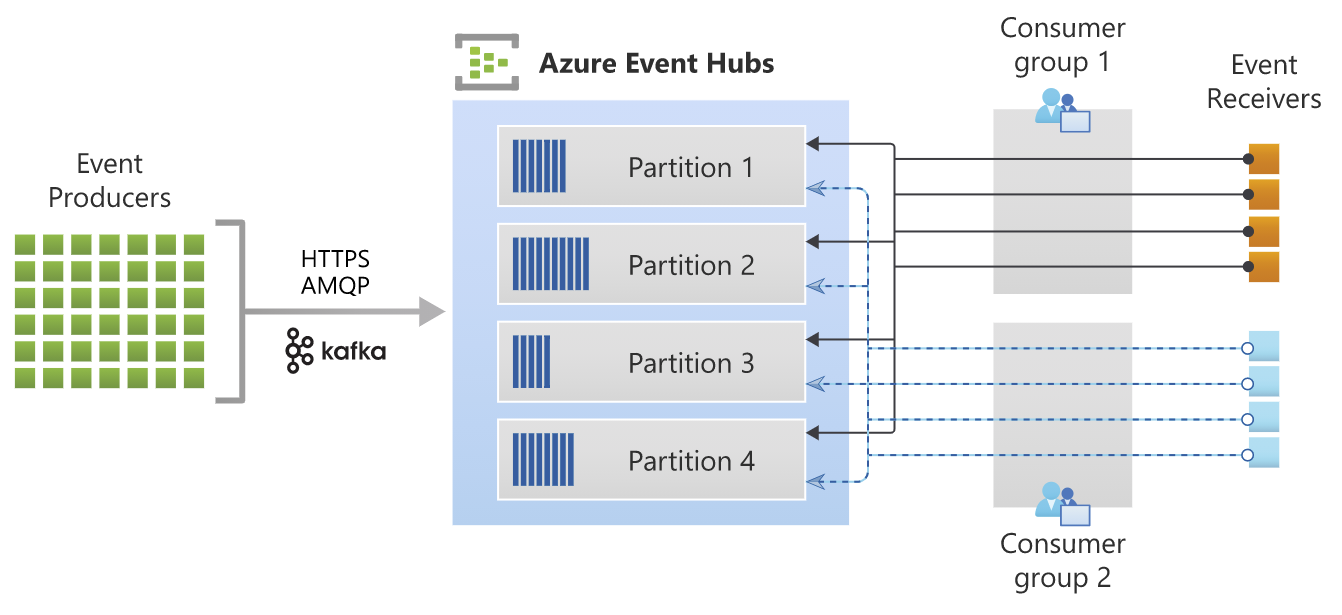 Quelle: https://docs.microsoft.com/de-de/azure/event-hubs/event-hubs-about
Quelle: https://docs.microsoft.com/de-de/azure/event-hubs/event-hubs-about 

 , and it includes words from “a”, “ablation”, “actually” to “zombie”, “?”, “!”
, and it includes words from “a”, “ablation”, “actually” to “zombie”, “?”, “!” , and the others are
, and the others are  . When you want to choose the No. i word, which is “indeed” in the example below, its corresponding one-hot vector is
. When you want to choose the No. i word, which is “indeed” in the example below, its corresponding one-hot vector is  , where only the No. i element is
, where only the No. i element is 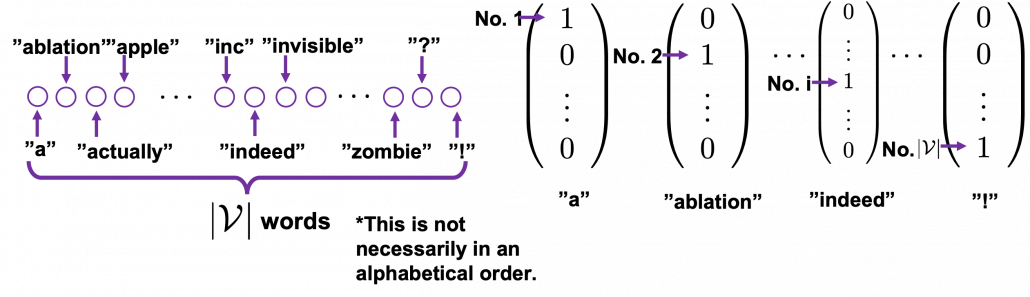
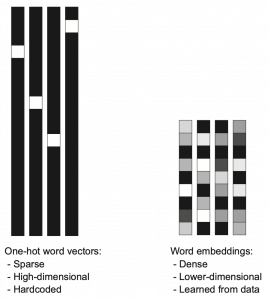
 dimensional vector, whose dimension is fewer than the vocabulary size
dimensional vector, whose dimension is fewer than the vocabulary size 
 . When the inputs are “You’ve got the touch” or “You’ve got the power” , you put the one-hot vector corresponding to “You’ve”, “got”, “the”, “touch” or “You’ve”, “got”, “the”, “power” sequentially every time step
. When the inputs are “You’ve got the touch” or “You’ve got the power” , you put the one-hot vector corresponding to “You’ve”, “got”, “the”, “touch” or “You’ve”, “got”, “the”, “power” sequentially every time step  .
.

 ,
,  .
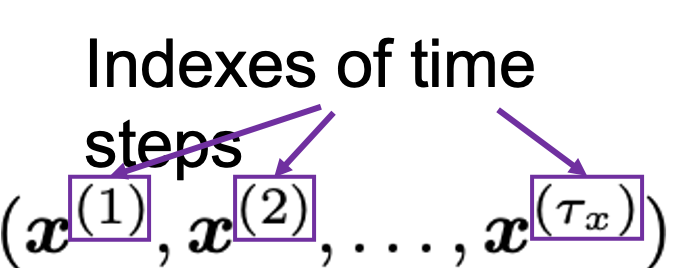
. , a list of vectors. The vectors are usually embedding vectors, and the
, a list of vectors. The vectors are usually embedding vectors, and the  is the index of the order of tokens. For example the sentence “You’ve go the power.” can be expressed as
is the index of the order of tokens. For example the sentence “You’ve go the power.” can be expressed as  , where
, where  denote “You’ve”, “got”, “the”, “power”, “.” respectively. In this case
denote “You’ve”, “got”, “the”, “power”, “.” respectively. In this case  .
. usually includes two tokens
usually includes two tokens  and
and  at the beginning and the end of the sentence. They mean “Beginning Of Sentence” and “End Of Sentence” respectively. Thus in many cases
at the beginning and the end of the sentence. They mean “Beginning Of Sentence” and “End Of Sentence” respectively. Thus in many cases  .
.  and
and  are also both vectors, at least in the Tensorflow tutorial.
are also both vectors, at least in the Tensorflow tutorial.
 is the probability of incidence of the sentence. But it is easy to imagine that it would be very hard to directly calculate how likely the sentence
is the probability of incidence of the sentence. But it is easy to imagine that it would be very hard to directly calculate how likely the sentence  as a product of the probability of incidence or a certain word, given all the words so far. When you’ve got the words
as a product of the probability of incidence or a certain word, given all the words so far. When you’ve got the words  so far, the probability of the incidence of
so far, the probability of the incidence of  , given the context is
, given the context is  .
.  is a probability of the the sentence
is a probability of the the sentence  , and the probability of
, and the probability of  can be decomposed this way:
can be decomposed this way: 
 .
.

 .
.





 be
be  be
be ![P(\boldsymbol{x}^{(t+1)}|\boldsymbol{X}_{[0, t]})](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-9b85b225f0635a7627a99481018f6166_l3.png "Rendered by QuickLaTeX.com") be
be  , then
, then ![P(\boldsymbol{X}) = P(\boldsymbol{x}^{(0)})\prod_{t=0}^{\tau}{P(\boldsymbol{x}^{(t+1)}|\boldsymbol{X}_{[0, t]})}](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-59e2d215f0fea11ec20386dfef220a30_l3.png "Rendered by QuickLaTeX.com") . Language models calculate which words to come sequentially in this way.
. Language models calculate which words to come sequentially in this way.


![P(\boldsymbol{x}^{(0)})\prod_{t=0}^{4}{P(\boldsymbol{x}^{(t+1)}|\boldsymbol{X}_{[0, t]})}](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-4d263b8554a322d3ab8a8841552bc75b_l3.png "Rendered by QuickLaTeX.com") . Given a context
. Given a context  is
is  . In the figure below, the distribution at the left side is less confident because probabilities do not spread widely, on the other hand the one at the right side is more confident that next word is “got” because the distribution concentrates on “got”.
. In the figure below, the distribution at the left side is less confident because probabilities do not spread widely, on the other hand the one at the right side is more confident that next word is “got” because the distribution concentrates on “got”. is
is 

 .
.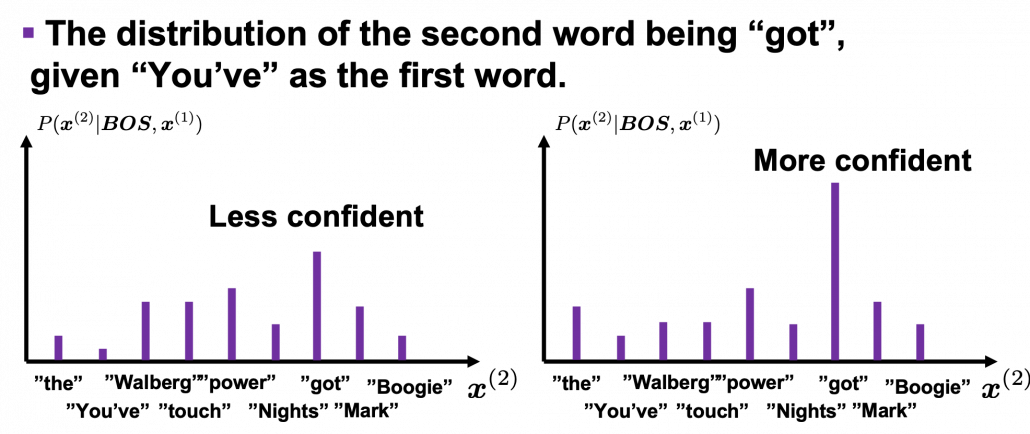



 gets higher. Thus
gets higher. Thus 



 gets lower, where usually
gets lower, where usually  or
or  .
. , which is composed of
, which is composed of  sentences in total. Each sentence
sentences in total. Each sentence 
![(\boldsymbol{x}^{(0)})\prod_{t=0}^{\tau ^{(n)}}{P(\boldsymbol{x}_{n}^{(t+1)}|\boldsymbol{X}_{n, [0, t]})}](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-ccc74ac2aee4f90a6b035dcfd2632927_l3.png "Rendered by QuickLaTeX.com") has
has  tokens in total excluding
tokens in total excluding  . And let
. And let  , where
, where ![z = \frac{-1}{|\mathcal{V}|}\sum_{n=1}^{|\mathcal{D}|}{\sum_{t=0}^{\tau ^{(n)}}{log_{b}P(\boldsymbol{x}_{n}^{(t+1)}|\boldsymbol{X}_{n, [0, t]})}](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-c1ccb76fcad455ad635fc1ec8b2f6f81_l3.png "Rendered by QuickLaTeX.com") . The
. The  is usually
is usually  or
or  .
. is vocabulary {“the”, “You’ve”, “Walberg”, “touch”, “power”, “Nights”, “got”, “Mark”, “Boogie”}. Also assume that the evaluation data set for perplexity of a language model is
is vocabulary {“the”, “You’ve”, “Walberg”, “touch”, “power”, “Nights”, “got”, “Mark”, “Boogie”}. Also assume that the evaluation data set for perplexity of a language model is  , where
, where 
 . In this case
. In this case 
 . I have already showed you how to calculate the perplexity of the sentence “You’ve got the touch.” above. You just need to do a similar thing on another sentence “You’ve got the power”, and then you can get the perplexity of the language model.
. I have already showed you how to calculate the perplexity of the sentence “You’ve got the touch.” above. You just need to do a similar thing on another sentence “You’ve got the power”, and then you can get the perplexity of the language model.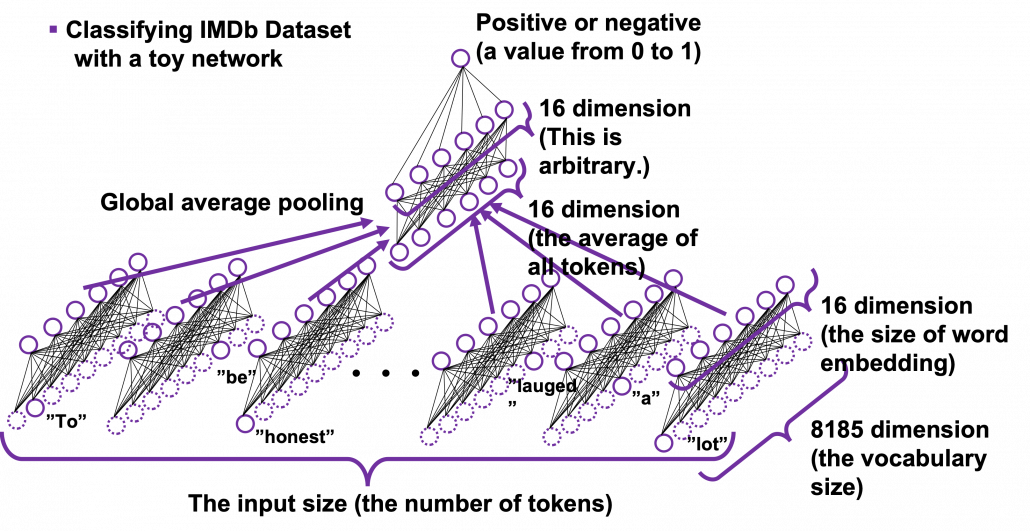


 is a certain type of
is a certain type of  matrix, the formula of a D-dimensional ellipsoid whose center is identical to the origin point is as follows:
matrix, the formula of a D-dimensional ellipsoid whose center is identical to the origin point is as follows:  , where
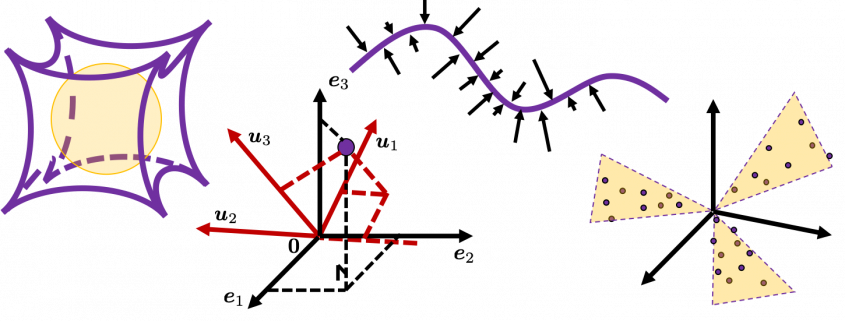
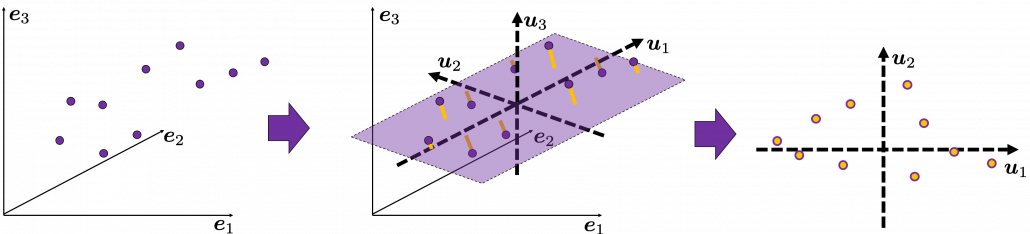
, where  . As is always the case with formulas in data science, you can visualize such ellipsoids if you are talking about 1, 2, or 3 dimensional data like in the figure below, but in general D-dimensional space, it is theoretical/imaginary stuff on blackboards.
. As is always the case with formulas in data science, you can visualize such ellipsoids if you are talking about 1, 2, or 3 dimensional data like in the figure below, but in general D-dimensional space, it is theoretical/imaginary stuff on blackboards.
 , where
, where  or
or  , where
, where  . These are special cases of the equation
. These are special cases of the equation  . In this case the axes of ellipsoids the same as those of the coordinate system. Thus in this simple case,
. In this case the axes of ellipsoids the same as those of the coordinate system. Thus in this simple case,  or
or  .
. as below (The samples are plotted in purple). Intuitively, the data “swell” the most along the vector
as below (The samples are plotted in purple). Intuitively, the data “swell” the most along the vector  . Also it is clear that
. Also it is clear that  is the only vector orthogonal to
is the only vector orthogonal to  expresses the data in a better way, and you you can get new coordinate points of the samples by projecting them on new axes as done with yellow lines below.
expresses the data in a better way, and you you can get new coordinate points of the samples by projecting them on new axes as done with yellow lines below.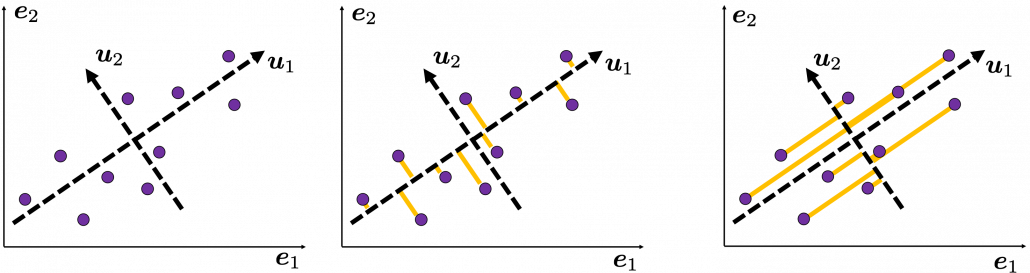
 as below, the data “swell” the most also along
as below, the data “swell” the most also along  .
.

 on the axis
on the axis  .
. is the mean of data in the original coordinate, then the deviation of
is the mean of data in the original coordinate, then the deviation of  on the axis
on the axis  , as shown in the figure. Hence the variance, I mean the mean of the deviation on is
, as shown in the figure. Hence the variance, I mean the mean of the deviation on is  , where
, where  is the total number of data points. After some deformations, you get the next equation
is the total number of data points. After some deformations, you get the next equation  , where
, where  .
.  is known as a covariance matrix.
is known as a covariance matrix. , and for mathematical derivation we need some college level calculus, so if that is too much for you, you can skip reading this part till the next section.
, and for mathematical derivation we need some college level calculus, so if that is too much for you, you can skip reading this part till the next section. including
including  . Introducing a
. Introducing a  . In conclusion
. In conclusion  satisfies
satisfies  . If you have read my last article on eigenvectors, you wold soon realize that this is an equation for calculating eigenvectors, and that means
. If you have read my last article on eigenvectors, you wold soon realize that this is an equation for calculating eigenvectors, and that means  . We have seen that
. We have seen that  is a the variance of data when projected on a vector
is a the variance of data when projected on a vector  is the biggest variance possible when the data are projected on a vector.
is the biggest variance possible when the data are projected on a vector. , and it it the second biggest variance possible, and in this case the date are projected on
, and it it the second biggest variance possible, and in this case the date are projected on 
 matrix
matrix  , and in fact the matrix is just a constant multiplication of this covariance matrix. I think now you understand that PCA is calculating the orthogonal eigenvectors of covariance matrix of data, that is diagonalizing covariance matrix with orthonormal eigenvectors. Hence we can guess that covariance matrix enables a type of linear transformation of rotation and expansion and contraction of vectors. And data points swell along eigenvectors of such matrix.
, and in fact the matrix is just a constant multiplication of this covariance matrix. I think now you understand that PCA is calculating the orthogonal eigenvectors of covariance matrix of data, that is diagonalizing covariance matrix with orthonormal eigenvectors. Hence we can guess that covariance matrix enables a type of linear transformation of rotation and expansion and contraction of vectors. And data points swell along eigenvectors of such matrix.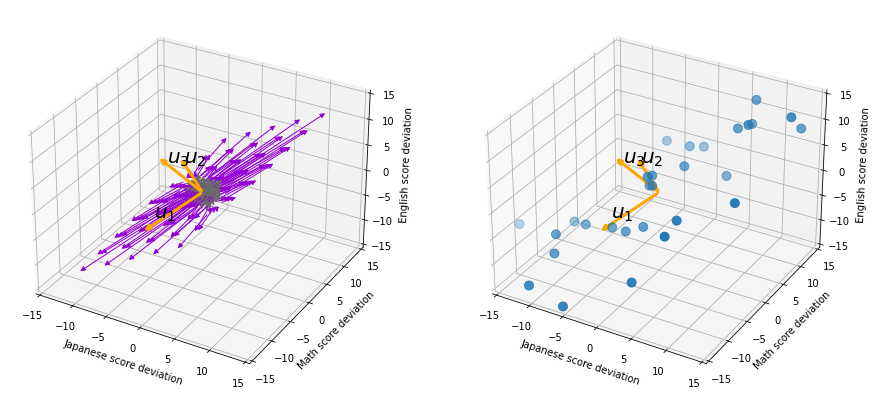
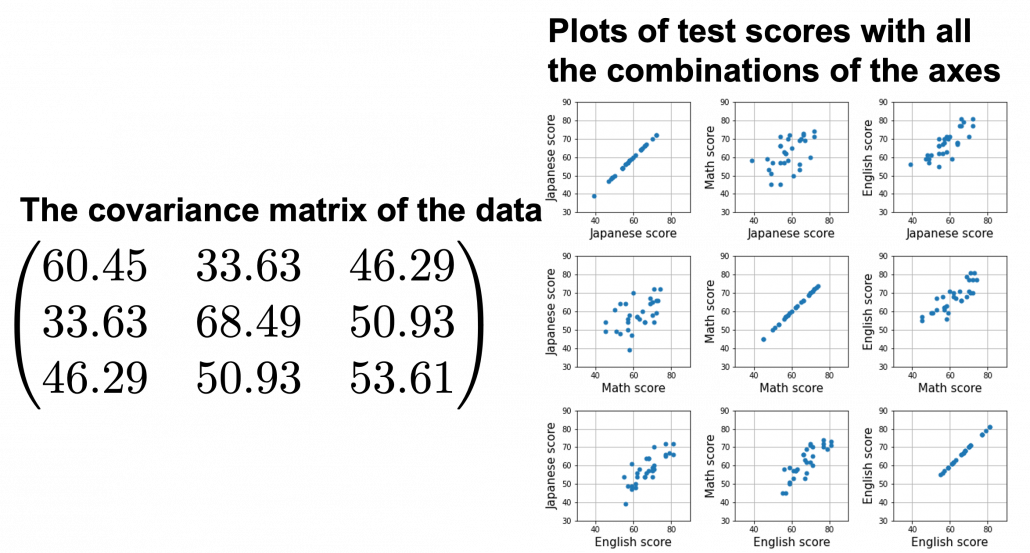
 denote Japanese, Math, English scores respectively. The mean of the data is
denote Japanese, Math, English scores respectively. The mean of the data is  , and the covariance matrix of data in the original coordinate system is
, and the covariance matrix of data in the original coordinate system is  . The eigenvalues of
. The eigenvalues of  are
are  , and
, and  , and their corresponding unit eigenvectors are
, and their corresponding unit eigenvectors are  respectively.
respectively.  is an orthonormal matrix, where
is an orthonormal matrix, where  . As I explained in the last article, you can diagonalize
. As I explained in the last article, you can diagonalize  :
:  .
. .
. means. Each element of
means. Each element of  denotes coordinate of the data point
denotes coordinate of the data point  , and
, and  ).
).  enables a rotation of a rigid body, which means the shape or arrangement of data will not change after the rotation, and
enables a rotation of a rigid body, which means the shape or arrangement of data will not change after the rotation, and  , and
, and  is the coordinate of
is the coordinate of  denotes the coordinate point of the purple point in the red coordinate system.
denotes the coordinate point of the purple point in the red coordinate system.  denotes the coordinates of data projected on new axes
denotes the coordinates of data projected on new axes  , which are unit eigenvectors of
, which are unit eigenvectors of 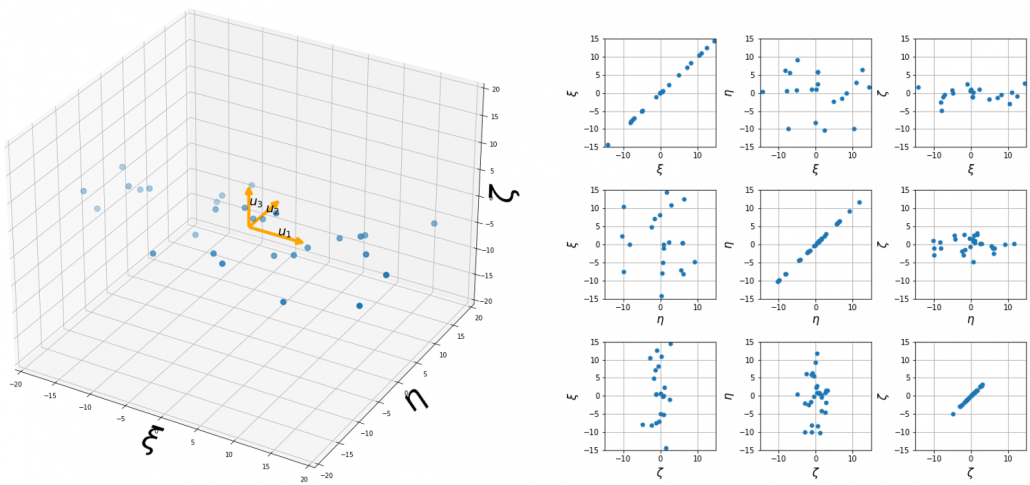
 , which means you can express deviations of the original data as linear combinations of the three factors
, which means you can express deviations of the original data as linear combinations of the three factors  , and
, and  . We expect that those three factors contain keys for understanding the original data more efficiently. If you concretely write down all the equations for the factors:
. We expect that those three factors contain keys for understanding the original data more efficiently. If you concretely write down all the equations for the factors:  ,
,  , and
, and  . If you examine the coefficients of the deviations
. If you examine the coefficients of the deviations  , and
, and  , we can observe that
, we can observe that  almost equally reflects the deviation of the scores of all the subjects, thus we can say
almost equally reflects the deviation of the scores of all the subjects, thus we can say  is
is  . You can see
. You can see  , where
, where  . The variance of data projected on new D-dimensional coordinate system is
. The variance of data projected on new D-dimensional coordinate system is 




 . This means that in the new coordinate system after PCA, covariances between any pair of variants are all zero.
. This means that in the new coordinate system after PCA, covariances between any pair of variants are all zero. .
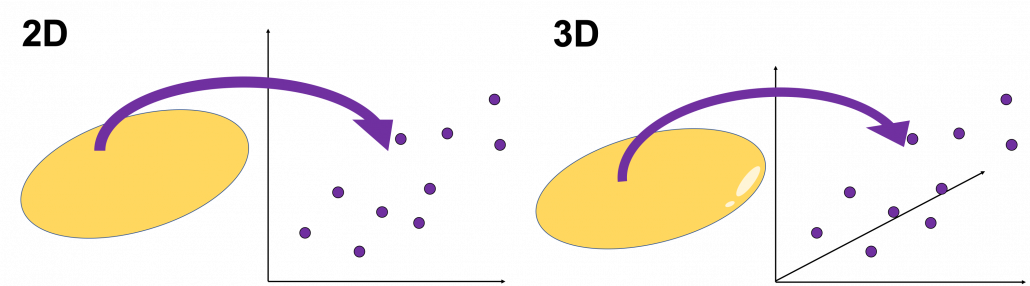
. from the reduced two dimensional coordinate system
from the reduced two dimensional coordinate system  . Then it mathematically clearer that we can express the data with two factors: “how smart the student is” and “whether he is at scientific side or liberal art side.”
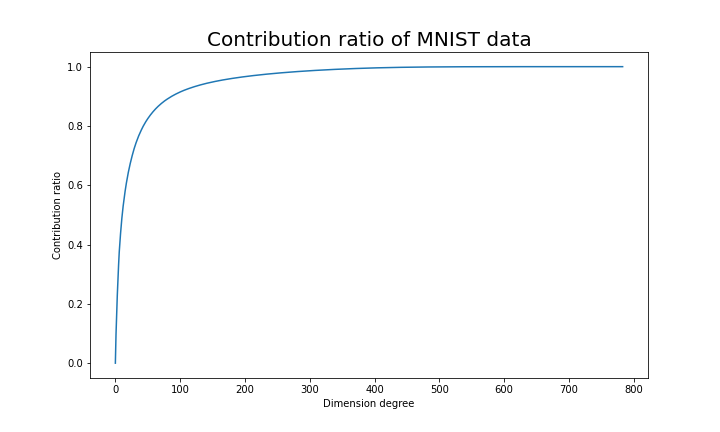
. Then it mathematically clearer that we can express the data with two factors: “how smart the student is” and “whether he is at scientific side or liberal art side.” is a statistic which indicates how much the corresponding
is a statistic which indicates how much the corresponding  is called the contribution ratio of eigenvector
is called the contribution ratio of eigenvector  and
and  are respectively
are respectively  ,
,  ,
,  . You can decide how many degrees of dimensions you reduce based on this information.
. You can decide how many degrees of dimensions you reduce based on this information.


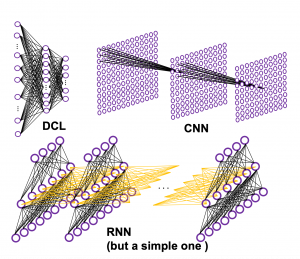
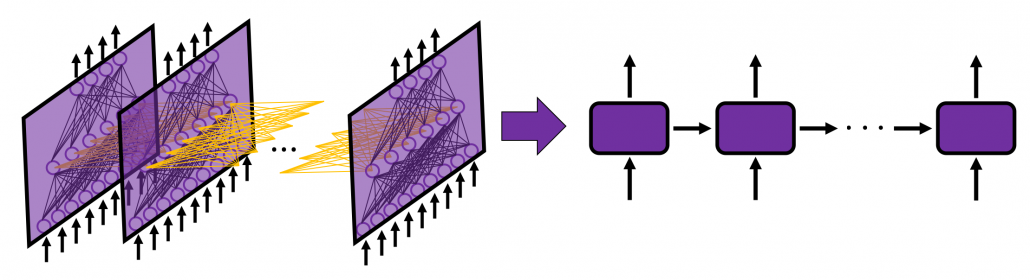
 , which most people would have seen in compulsory education, is a part of mapping. If you get a value x, you get a value y corresponding to the x.
, which most people would have seen in compulsory education, is a part of mapping. If you get a value x, you get a value y corresponding to the x.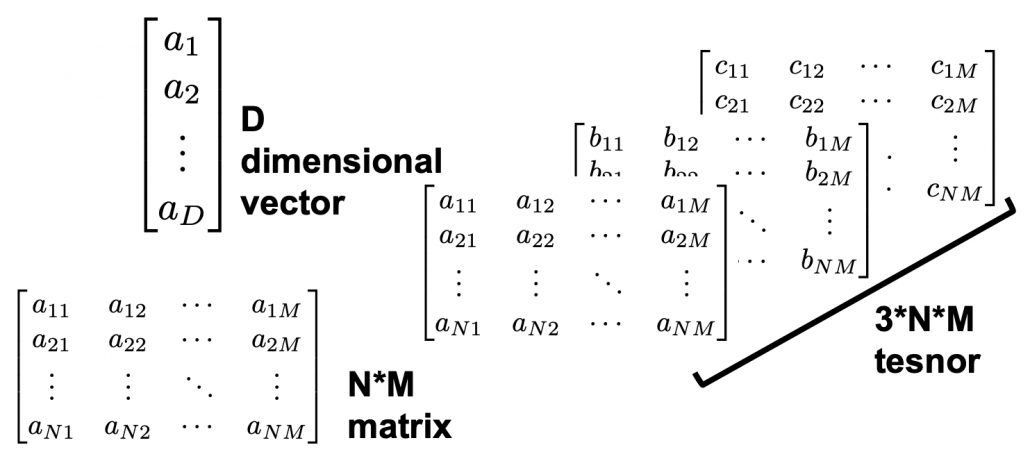


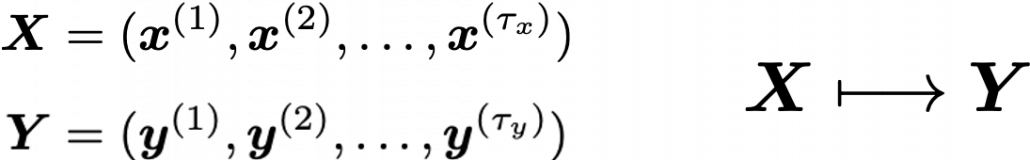
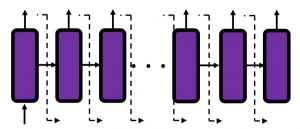
 , and machine translation is nothing but mappings between these sequence data.
, and machine translation is nothing but mappings between these sequence data.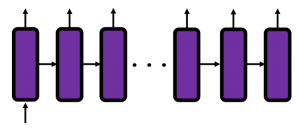
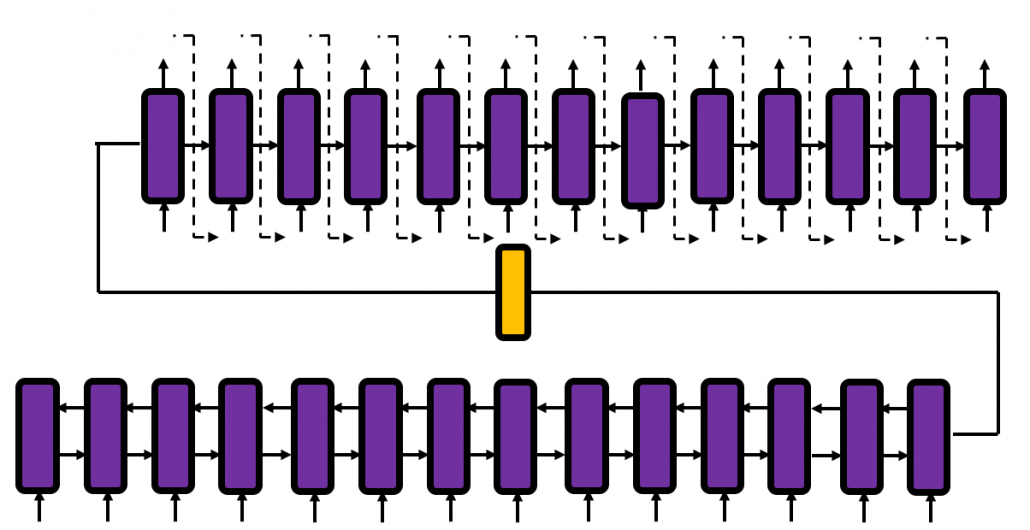
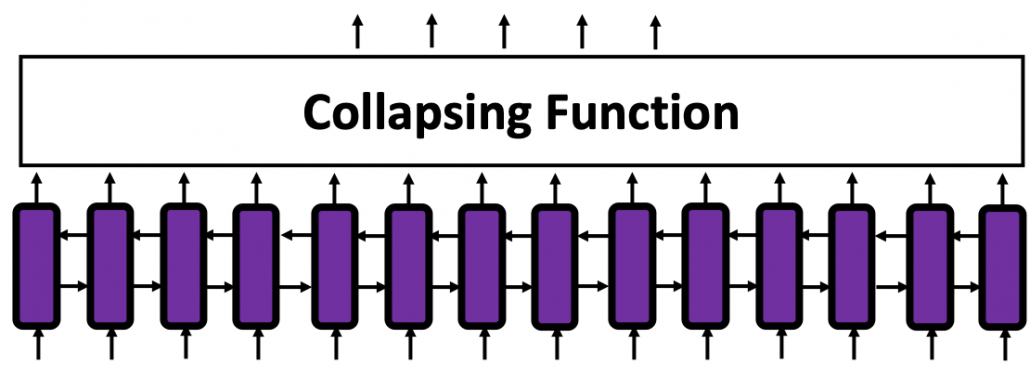

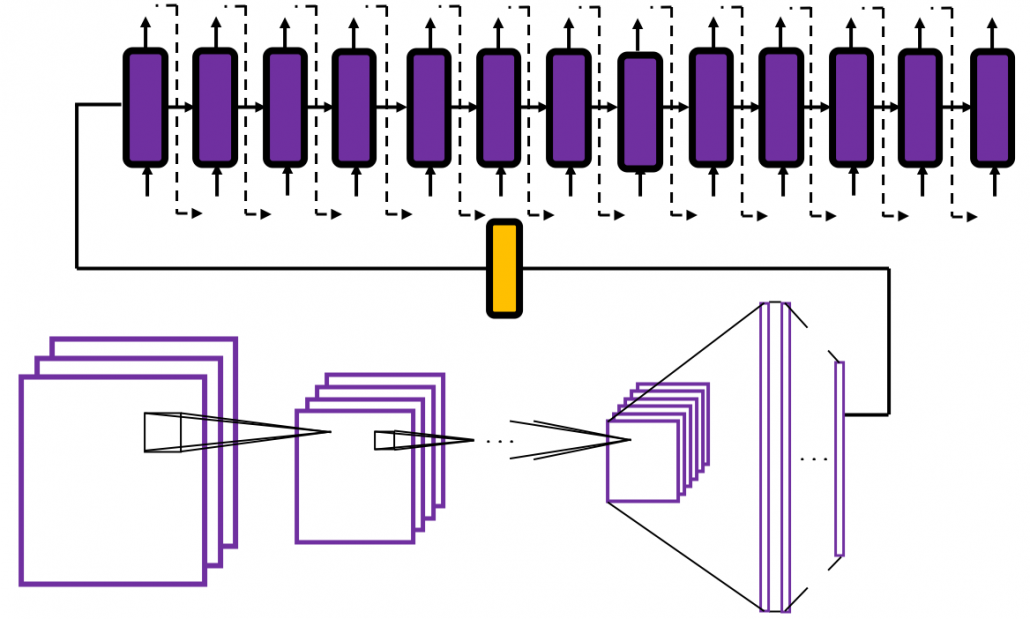

 Herr Dr. Frank Block ist Head of IT Data Science bei Roche Diagnostics mit Sitz in der Schweiz. Zuvor war er Chief Data Scientist bei der Ricardo AG nachdem er für andere Unternehmen die Datenanalytik verantwortet hatte und auch 20 Jahre mit mehreren eigenen Data Science Consulting Startups am Markt war. Heute tragen ca. 50 Mitarbeiter bei Roche Diagnostics zu Data Science Projekten bei, die in sein Aktivitätsportfolio fallen:
Herr Dr. Frank Block ist Head of IT Data Science bei Roche Diagnostics mit Sitz in der Schweiz. Zuvor war er Chief Data Scientist bei der Ricardo AG nachdem er für andere Unternehmen die Datenanalytik verantwortet hatte und auch 20 Jahre mit mehreren eigenen Data Science Consulting Startups am Markt war. Heute tragen ca. 50 Mitarbeiter bei Roche Diagnostics zu Data Science Projekten bei, die in sein Aktivitätsportfolio fallen: