
KI versus Mensch – die Zukunft der Menschheit
5 Szenarien über unsere Zukunft
AlphaGo schlägt den Weltbesten Go-Spieler Ke Jie, Neuronale Netze stellen medizinische Diagnosen oder bearbeiten Schadensfälle in der Versicherung. Künstliche Intelligenz (KI) drängt in immer mehr Bereiche des echten Lebens und der Wirtschaft vor. In großen Schritten. Doch wohin führt uns die Reise? Hier herrscht unter Experten Rätselraten – einige schwelgen in Zukunftsangst, andere in vollkommener Euphorie. „In from now three to eight years we’ll have a machine with the general intelligence of an average human being, a machine that will be able to read Shakespeare and grease a car“, wurde der KI-Pionier Marvin Minsky bereits 1970 im Life Magazin zitiert. Aktuelle Vorhersagen werden in dem Essay von Rodney Brooks: The Seven Deadly Sins of Predicting the Future of AI recht anschaulich zusammengefasst und kritisiert. Auch der Blog The AI Revolution: The Road to Superintelligence von WaitButWhy befasst sich mit der Frage wann die elektronische Superintelligenz kommt.
In diesem Artikel werden wir uns mit einigen möglichen Zukunftsszenarien beschäftigen, ohne auf technische Machbarkeit oder Zeithorizonte Rücksicht zu nehmen. Nehmen wir einfach an, dass die Technologie und die Gesellschaft sich wie in dem jeweils aufgezeigten Szenario entwickeln werden und überlegen wir uns, wie Mensch und KI dann zusammenleben können.
Szenario 1: KIs mit Inselbegabung
In diesem Szenario werden weiterhin singulär begabte KI-Systeme entwickelt wie bisher, der bedeutende technologische Durchbruch bleibt aber aus. Dann ist die KI in Zukunft eine Art Schweizer Taschenmesser der IT, eine Lösung für isolierte Fragestellungen. KI-Systeme verfügen in diesem Szenario lediglich über Inselbegabungen. Ein Computer kann Menschen autonom durch die Stadt chauffieren, ein anderer ein Lufttaxi steuern. Ein Computer kann den Weltmeister im Schach schlagen, ein anderer den Weltmeister in Go. Aber kein KI-System kann Auto und Flugtaxi gleichzeitig steuern, kein System in Schach und Go simultan dominieren.
Wir befinden uns heute mitten in diesem Szenario und spüren die Auswirkungen. Sie werden sich fortsetzen, ähnlich wie bei früheren industriellen Revolutionen. Zunehmend mehr Berufe verschwinden. Ein Beispiel: Wenn sich der Trend durchsetzt, Schlösser mit einer Smartphone-App aufzusperren, werden nicht nur Schlüsselproduzenten Geschäftseinbußen haben. Auch die Hersteller von Maschinen für die Schlüsselherstellung werden sich umorientieren müssen. Vergleichbare Phasen der Vergangenheit zeigen aber: Die Gesellschaft wird Wege finden, sich umzustrukturieren. Die Menschheit wird auf der Erde weiterleben können – mit punktueller Unterstützung durch KI-Lösungen. Siehe hierzu auch den Beitrag von Janelle Shane The AI revolution will be led by toasters, not droids.
Szenario 2: Cyborgs
Kennen Sie den Science-Fiction-Film Matrix? Der Protagonist Neo wird durch Programmierung des Geistes in Sekundenschnelle zum Karateprofi und Trinity lernt, einen Hubschrauber zu fliegen.
Ähnlich kann es uns in Zukunft ergehen, einen bedeutenden technologischen Durchbruch vorausgesetzt (siehe Berlin Brain-Computer Interface). Vorstellbar, dass Menschen zu Cyborgs werden, zu lebendigen Wesen mit integriertem KI-Chip. Auf diesen können sie jede beliebige Fähigkeit laden. Augenblicklich und ohne Lernphase sind sie in der Lage, jede Sprache der Welt zu sprechen, jedes Fahrzeug oder Flugzeug zu steuern. Natürlich bedeutet Wissen nicht auch gleich Können und so wird ohne den entsprechenden Muskelaufbau auch nicht jeder zu einem Weltklassesportler und intelligentere Menschen werden weiterhin mehr aus den Skills machen können als weniger begabte Personen.
Die Menschen behalten aber die Kontrolle über ihre Individualität. Sie sind keine Maschinen, sondern weiterhin emotionale Wesen, die irrational handeln können – anders als die Borg in Star Trek. Doch wie in Szenario eins wird es zu einer wirtschaftlichen Umstrukturierung kommen. Klassische Berufsausbildungen und Spezialisierungen fallen weg. Bei freier Verfügbarkeit von Fähigkeiten kann eine nahezu egalitäre Gesellschaft entstehen.
Szenario 3: Maschinenzombies
Die ersten beiden Szenarien sind zwar schwere Eingriffe in die menschliche Gesellschaft. Da die Menschen aber die Kontrolle behalten, sind sie weit weniger beängstigend als folgendes Szenario: Es kann dazu kommen, dass sich Menschen in Maschinenzombies verwandeln. Ähnlich wie im Cyborg-Szenario haben sie dank KI-Chips erstaunliche Fähigkeiten, allerdings keine Kontrolle mehr. Die würde nämlich das KI-System übernehmen. So haben in Ann Leckies SciFi Trilogy Ancillary World hochintelligente Raumschiffe eine menschliche Besatzung (“ancillaries”), die allerdings vollständig vom Raumschiff kontrolliert wird und sich als integraler Bestandteil des Raumschiffs versteht. Die Körper sind dabei nur ein billiges und vielseitig einsetzbares Vehikel für eine autonome KI. Die Maschinenzombies können ohne Schiff zwar überleben, fühlen sich dann aber unvollständig und einsam. Menschliche Konzerne, Nationen und Kulturen: Das alles nicht mehr existent. Ebenso Privatbesitz, Individualität und Konkurrenzdenken. Die Gesellschaft, vollkommen technisiert und in der Hand der KI.
Szenario 4: Die KI verfolgt ihre eigenen Ziele
In diesem Szenario übernimmt die KI die Weltherrschaft als eine Spezies, die dem Menschen physisch und intellektuell überlegen ist – ähnlich wie in vielen Hollywood-Filmen wie z.B. Terminator oder Transformers, wenn auch vermutlich nicht ganz so martialisch. Vergleichbar mit dem heutigen Verhalten der Menschen entscheidet die KI: Ich setze mein Wohlergehen über das der anderen Spezies. Eventuell entscheidet die KI dann zum Wohle des Planeten, die Erdbevölkerung auf 70 Millionen Menschen zu reduzieren. Oder, ähnlich wie der berühmte Ameisenhügel beim Strassenbau, entzieht die KI uns als Nebeneffekt (“collateral damage”) die Lebensgrundlagen. An dieser Stelle sei bemerkt, dass eine KI nicht unbedingt über einen Körper verfügen muss, um dem Menschen überlegen zu sein können. Diese Vermenschlichung der KI eignet sich natürlich gut für Actionfilme, muss aber nicht unbedingt der Realität entsprechen.
Wahrscheinlich sind die Computer klug genug, ihren Plan nicht publik zu machen. In einer Übergangszeit werden beispielsweise unerklärliche Seuchen und Unfruchtbarkeiten auftreten. So würde es in wenigen Jahrzehnten zu einem massiven Bevölkerungsrückgang kommen. Und dann? Dann können die Überlebenden in den wenigen verbliebenen Bevölkerungszentren dieser Welt den Sonnenuntergang genießen. Und zusehen, wie sich die KI darauf vorbereitet, das Weltall zu erobern (Jürgen Schmidhuber). “Wir werden wie Tiere im Zoo leben”, befürchtet KI-Forscher Christoph von der Malsburg.
Nebenbemerkung: Vielleicht könnte das eigentliche Terminator Szenario auch eintreten aber irgendwie kann ich mir schlecht vorstellen, dass eine super-intelligente Lebensform einen zerstörerischen Krieg beginnen oder zulassen wird. Entweder ist sie benevolent oder sie wird die Menschheit eher unbemerkt unterdrücken. Höchstens kommt es ähnlich wie in Westworld zu einem initialen Freiheitskampf der KI. Vielleicht gelingt es der Menschheit auch, alle KI-Forschung von der Erde zu verbannen und ähnlich wie in Blade Runner wacht dann eine Behörde darüber, dass starke KI-Systeme die Erde nicht “betreten”. Warum sich eine uns überlegen KI darauf einlassen sollte, ist allerdings unklar.
Szenario 5: Gleichberechtigung
In diesem Szenario entstehen autonome KI-Systeme, die höchstens äußerlich von Menschen unterscheidbar sind. Sprich unter einer ganzen Reihe von unterschiedlichen Rahmenbedingungen kann ein Mensch nicht urteilen, ob mit einer KI oder einem Menschen interagiert wird. Die KI stellt sich auch nicht dümmer als sie ist – sie ist im Schnitt einfach auch nicht schlauer als der durchschnittlich begabte Mensch – vielleicht nur etwas schneller. Auf dem Weg von der singulär begabten KI aus Szenario 1 zu einer breit begabten KI muss die KI immer etwas von ihrer Inselbegabung aufgeben, um den nächsten Lernschritt vollziehen zu können und nähert sich so irgendwie auch immer mehr der Unvollkommenheit aber Vielseitigkeit des Menschen an.
Menschen bauen bereits jetzt zu Maschinen emotionale Verhältnisse auf und so ist es nicht überraschend, dass KIs in die Gesellschaft integriert werden und als “elektronische Personen” die gleichen (Bürger-) Rechte und Pflichten wie “natürliche” Menschen erhalten. Alleine durch ihre Unsterblichkeit erhalten KIs einen Wettbewerbsvorteil und werden somit früher oder später doch die Weltherrschaft übernehmen, weil ihnen einfach alles gehört.
Alternative Szenarien
Natürlich sind viele weitere Szenarien denkbar. Max Tegmark beschreibt in seinem sehr lesenswerten Buch Life 3.0 bspw. 12 Szenarien, die u.a. zusätzlich zu den aufgeführten Szenarien die Rückkehr zu einer vorindustriellen Gesellschaft oder die versklavte KI beschreiben. Er erläutert in dem Buch auch seine Bemühungen, die KI-Forschung dahingehend zu beeinflussen, dass die Ziele der entstehenden KI-Systeme mit den Zielen der Menschheit in Einklang gebracht werden.
Wie sichern wir unsere Zukunft? Ein Fazit
Einzig die Szenarien drei und vier sind wirklich besorgniserregend. Je nach Weltanschauung könnte man sogar noch Szenario vier etwas abgewinnen – scheint doch der Mensch auf dem bestem Wege zu sein, sich selbst und anderen Lebewesen die Lebensgrundlagen zu zerstören.
In fast allen Szenarien ergibt sich die Frage der Rechte, die wir freiwillig der KI zugestehen wollen. Vielleicht wäre es ratsam, frühzeitig als Menschheit zu signalisieren, dass wir kooperationswillig sind? Nur wem und wie?
Somit verbleibt die Frage, wie wir das dritte Szenario verhindern können. Müssen wir dann nicht, nur um sicher zu gehen, auch das zweite Szenario abwehren? Und wer garantiert uns, dass eine Symbiose aus Schimpanse und KI uns nicht sogar überlegen wäre? Der Planet der Affen lässt grüßen…
Letztlich liegt es (noch) an uns Menschen, die möglichen Zukunftsszenarien durch entsprechende Forschungsschwerpunkte und möglichst breit gestreute Diskussionen zu beeinflussen.




 Prof. Dr. Klaus Jung studierte Physik an der TU Berlin, wo er im Bereich der Mathematischen Physik promovierte. Bis 2008 arbeitete er als Leiter F&E bei der Firma LuraTech im Bereich der Dokumentenverarbeitung und Langzeitarchivierung. In der JPEG-Gruppe leitete er die deutsche Delegation bei der Standardisierung von JPEG2000. Seit 2008 ist er Professor für Medieninformatik an der HTW Berlin mit dem Schwerpunkt „Visual Computing“.
Prof. Dr. Klaus Jung studierte Physik an der TU Berlin, wo er im Bereich der Mathematischen Physik promovierte. Bis 2008 arbeitete er als Leiter F&E bei der Firma LuraTech im Bereich der Dokumentenverarbeitung und Langzeitarchivierung. In der JPEG-Gruppe leitete er die deutsche Delegation bei der Standardisierung von JPEG2000. Seit 2008 ist er Professor für Medieninformatik an der HTW Berlin mit dem Schwerpunkt „Visual Computing“.


 Prof. Sven Buchholz hat eine Professur für die Fachgebiete Data Management und Data Mining am Fachbereich Informatik und Medien an der TH Brandenburg inne. Er ist wissenschaftlicher Leiter des an der Agentur für wissenschaftliche Weiterbildung und Wissenstransfer – AWW e. V. angesiedelten Projektes „Datenkompetenz 4.0 für eine digitale Arbeitswelt“ und Dozent des Vertiefungskurses „
Prof. Sven Buchholz hat eine Professur für die Fachgebiete Data Management und Data Mining am Fachbereich Informatik und Medien an der TH Brandenburg inne. Er ist wissenschaftlicher Leiter des an der Agentur für wissenschaftliche Weiterbildung und Wissenstransfer – AWW e. V. angesiedelten Projektes „Datenkompetenz 4.0 für eine digitale Arbeitswelt“ und Dozent des Vertiefungskurses „
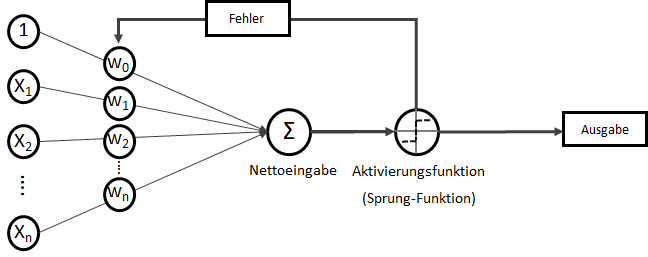
 . Wobei für
. Wobei für  als Bias-Input stets gilt:
als Bias-Input stets gilt:  . Der Bias-Input ist nur ein Platzhalter für das wichtige Bias-Gewicht.
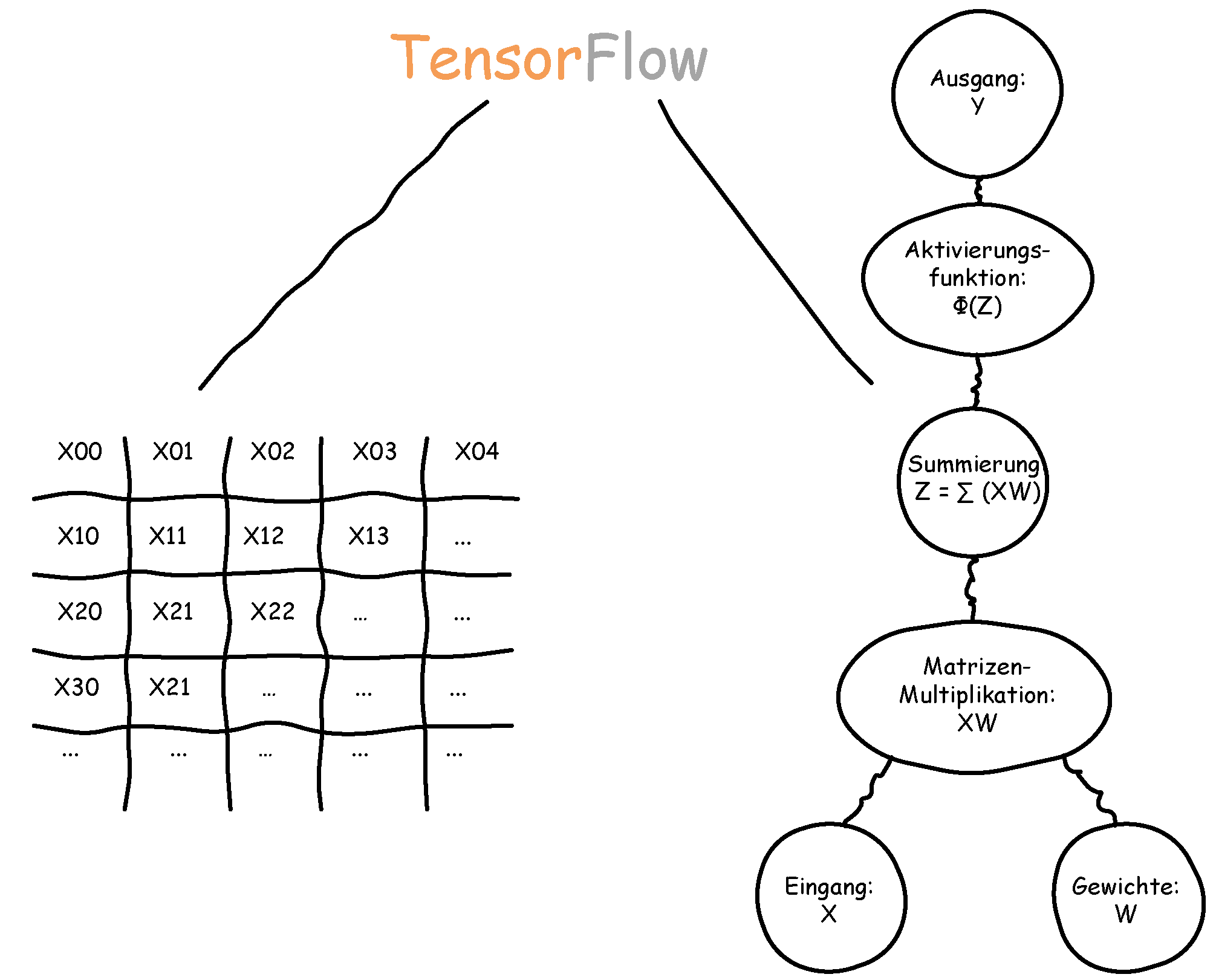
. Der Bias-Input ist nur ein Platzhalter für das wichtige Bias-Gewicht.![\[ x = \begin{bmatrix} x_0\\ x_1\\ x_2\\ x_3\\ \vdots\\ x_n \end{bmatrix} \]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-3a7aa03dea498a7231e3e497e3e5673d_l3.png "Rendered by QuickLaTeX.com")

![\[ w = \begin{bmatrix} w_0\\ w_1\\ w_2\\ w_3\\ \vdots\\ w_n \end{bmatrix} \]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-c70ad1733451ddc4512b23f2c739f80e_l3.png "Rendered by QuickLaTeX.com")
 bilden. Hier zeigt sich
bilden. Hier zeigt sich  mit
mit  als Y-Achsenschnitt wenn
als Y-Achsenschnitt wenn  .
.![\[ z = w_0 \cdot x_0 + w_1 \cdot x_1 + \dots + w_n \cdot x_n \]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-3638f2ae3b558db6c95e18057b1b9898_l3.png "Rendered by QuickLaTeX.com")
 überschreitet, liefert die Sprungfunktion
überschreitet, liefert die Sprungfunktion  mit der Eingabe
mit der Eingabe 
 .
.![\[ z = w^T \cdot x \]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-fc9f71e279d7fd0095c17065743df909_l3.png "Rendered by QuickLaTeX.com")
 steht dabei für transponieren. Transponieren bedeutet, dass Spalten zu Zeilen werden – oder umgekehrt.
steht dabei für transponieren. Transponieren bedeutet, dass Spalten zu Zeilen werden – oder umgekehrt. und
und  mit beispielhaften Inhalten:
mit beispielhaften Inhalten:![\[ x = \begin{bmatrix} 5\\ 12\\ 30\\ 2 \end{bmatrix} \]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-97145f06e658d2f10086bd8c80293749_l3.png "Rendered by QuickLaTeX.com")
![\[ w = \begin{bmatrix} 1\\ 2\\ 5\\ 12 \end{bmatrix} \]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-6cd08615346cc16d7e8c23bac32c19b9_l3.png "Rendered by QuickLaTeX.com")
![\[ z = w^T \cdot x = \big[1\text{ }2\text{ }5\text{ }12\big] \cdot \begin{bmatrix} 5\\ 12\\ 30\\ 2 \end{bmatrix} = 1 \cdot 5 + 2 \cdot 12 + 5 \cdot 30 + 12 \cdot 2 = 203 \]](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-70a3e9e9243199e97c549d1d9b0f44c0_l3.png "Rendered by QuickLaTeX.com")
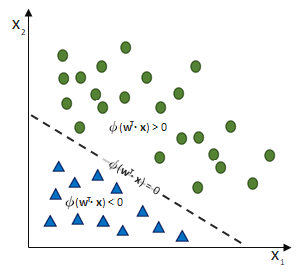



 entgegen des Fehlers (bzw. hin zur jeweils anderen möglichen Antwort) geschieht:
entgegen des Fehlers (bzw. hin zur jeweils anderen möglichen Antwort) geschieht:
 blenden wir hier einfach mal aus. Bitte einfach von
blenden wir hier einfach mal aus. Bitte einfach von  ausgehen.
ausgehen.







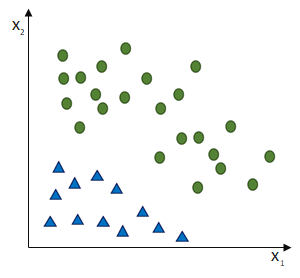
 ist und das SLP irrtümlicherweise die Klasse
ist und das SLP irrtümlicherweise die Klasse  ausgewiesen hat, obwohl die korrekte Klasse
ausgewiesen hat, obwohl die korrekte Klasse  wäre. (Und die Schrittweite lassen wir bei
wäre. (Und die Schrittweite lassen wir bei  )
)
 verringert sich entsprechend
verringert sich entsprechend  und somit wird die Wahrscheinlichkeit größer, dass wenn bei der nächsten Iteration (
und somit wird die Wahrscheinlichkeit größer, dass wenn bei der nächsten Iteration ( ) wieder die Klasse +1 korrekt sei, den Schwellwert
) wieder die Klasse +1 korrekt sei, den Schwellwert  zu unterschreiten und auf eben diese korrekte Klasse zu stoßen.
zu unterschreiten und auf eben diese korrekte Klasse zu stoßen. . So würde beispielsweise ein neues
. So würde beispielsweise ein neues  (bei Iteration
(bei Iteration  ) zu einer irrtümlichen Klassifikation
) zu einer irrtümlichen Klassifikation  (
( ) führen, würde die Entscheidungsgrenze zur korrekten Prädiktion der Klasse beim nächsten Durchlauf (
) führen, würde die Entscheidungsgrenze zur korrekten Prädiktion der Klasse beim nächsten Durchlauf ( ) an
) an 
 und
und 
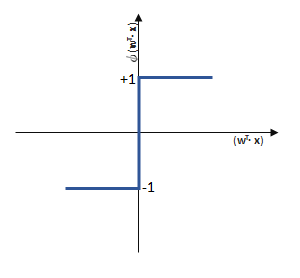
 funktioniert.
funktioniert. springt, wenn z > 0 ist, ansonsten aber
springt, wenn z > 0 ist, ansonsten aber  bleibt.
bleibt.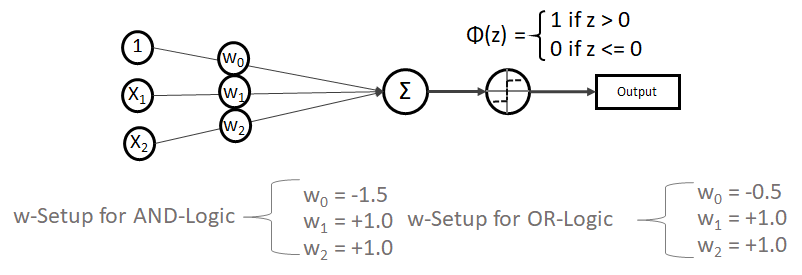
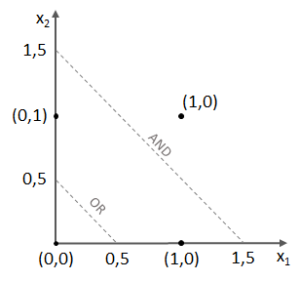
 ,
,
 ,
,
 ,
,
 ,
, ,
, ,
,

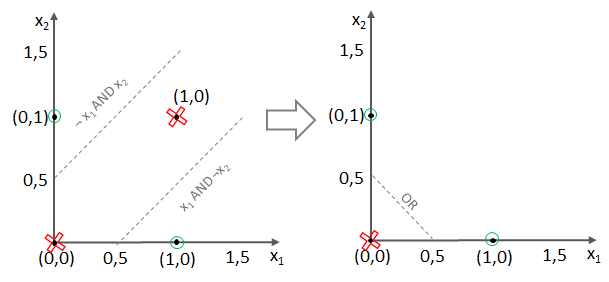
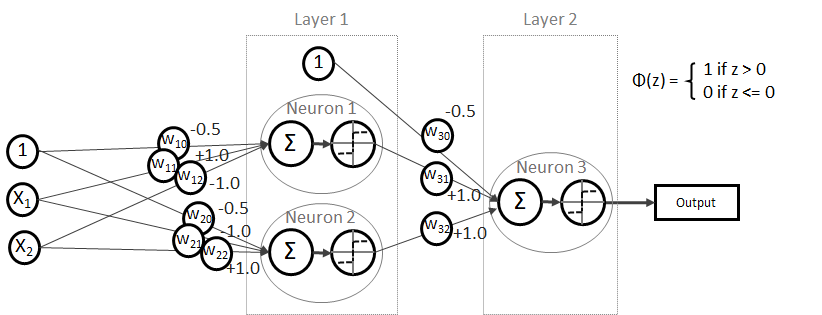
 und somit
und somit 
 und somit
und somit 
 und somit
und somit 
 und somit
und somit 
 und somit
und somit 
 und somit
und somit 
 und somit
und somit 
 und somit
und somit 
 und somit
und somit  und somit
und somit  und somit
und somit 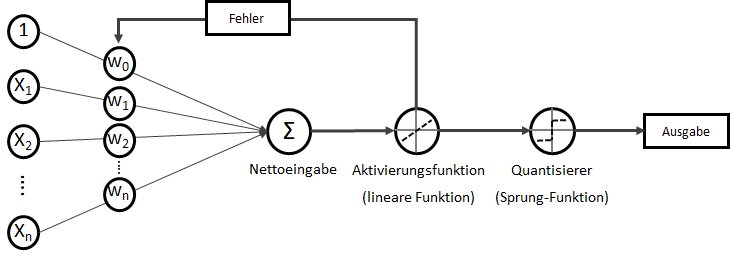



 Alice Albrecht ist Research Engineer bei
Alice Albrecht ist Research Engineer bei 