Ein Einblick in die Aktienmärkte unter Berücksichtigung von COVID-19
Einleitung
Die COVID-19-Pandemie hat uns alle fest im Griff. Besonders die Wirtschaft leidet stark unter den erforderlichen Maßnahmen, die weltweit angewendet werden. Wir wollen daher die Gelegenheit nutzen einen Blick auf die Aktienkurse zu wagen und analysieren, inwieweit der Virus einen Einfluss auf das Wachstum des Marktes hat.
Rahmenbedingungen
Zuallererst werden wir uns auf die Industrie-, Schwellenländer und Grenzmärkte konzentrieren. Dafür nutzen wir die MSCI Global Investable Market Indizes (kurz GIMI), welche die zuvor genannten Gruppen abbilden. Die MSCI Inc. ist ein US-amerikanischer Finanzdienstleister und vor allem für ihre Aktienindizes bekannt.
Aktienindizes sind Kennzahlen der Entwicklung bzw. Änderung einer Auswahl von Aktienkursen und können repräsentativ für ganze Märkte, spezifische Branchen oder Länder stehen. Der DAX ist zum Beispiel ein Index, welcher die Entwicklung der größten 30 deutschen Unternehmen zusammenfasst.
Leider sind die Daten von MSCI nicht ohne weiteres zugänglich, weshalb wir unsere Analysen mit ETFs (engl.: “Exchange Traded Fund”) durchführen werden. ETFs sind wiederum an Börsen gehandelte Fonds, die von Fondgesellschaften/-verwaltern oder Banken verwaltet werden.
Für unsere erste Analyse sollen folgende ETFs genutzt werden, welche die folgenden Indizes führen:
| Index | Beschreibung | ETF |
| MSCI World | über 1600 Aktienwerte aus 24 Industrieländern | iShares MSCI World ETF |
| MSCI Emerging Markets | ca. 1400 Aktienwerte aus 27 Schwellenländern | iShares MSCI Emerging Markets ETF |
| MSCI Frontier Markets | Aktienwerte aus ca. 29 Frontier-Ländern | iShares MSCI Frontier 100 ETF |
Tab.1: MSCI Global Investable Market Indizes mit deren repräsentativen ETFs
Datenquellen
Zur Extraktion der ETF-Börsenkurse nehmen wir die yahoo finance API zur Hilfe. Mit den richtigen Symbolen können wir die historischen Daten unserer ETF-Auswahl ausgeben lassen. Wie unter diesem Link für den iShares MSCI World ETF zu sehen ist, gibt es mehrere Werte in den historischen Daten. Für unsere Analyse nutzen wir den Wert, nachdem die Börse geschlossen hat.
Da die ETFs in ihren Kurswerten Unterschiede haben und uns nur die relative Entwicklung interessiert, werden wir relative Werte für die Analyse nutzen. Der Startzeitpunkt soll mit dem 06.01.2020 festgelegt werden.
Die Daten über bestätigte Infektionen mit COVID-19 entnehmen wir aus der Hochrechnung der Johns Hopkins Universität.
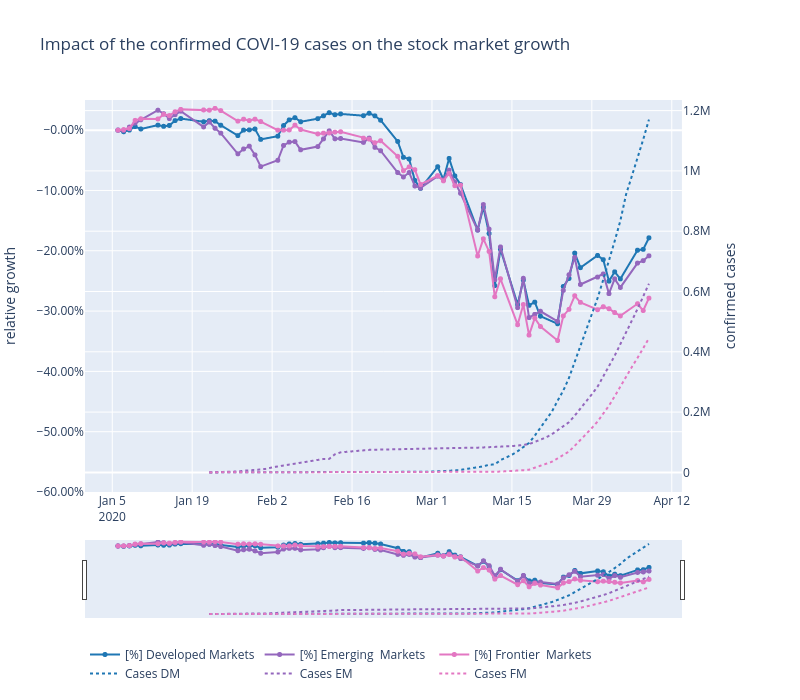
Interpretation des Diagramms
Auf den ersten Blick sieht man deutlich, dass mit steigenden COVID-19 Fällen die Aktienkurse bis zu -31% einbrechen. (Anfangszeitpunkt: 06.01.2020 Endzeitpunkt: 09.04.2020)
Betrachten wir den Anfang des Diagramms so sehen wir einen Einbruch der Emerging Markets, welche eine Gewichtung von 39.69 % (Stand 09.04.20) chinesische Aktien haben. Am 17.01.20 verzeichnen die Emerging Marktes noch ein Plus von 3.15 % gegenüber unserem Startzeitpunkt, wohingegen wir am 01.02.2020 ein Defizit von -6.05 % gegenüber dem Startzeitpunkt haben, was ein Einbruch von -9.20 % zum 17.01.2020 entspricht. Da der Ursprung des COVID-19 Virus auch in China war, könnte man diesen Punkt als Grund des Einbruches interpretieren. Die Industrie- und Frontier-Länder bleiben hingegen recht stabil und auch deren bestätigten Fälle sind noch sehr niedrig.
Die Industrieländer erreichen ihren Höchststand am 19.02.20 mit einem Plus von 2.80%. Danach brachen alle drei Märkte deutlich ein. Auch in diesem Zeitraum gab es die ersten Todesopfer in Europa und in den USA. Der derzeitige Tiefpunkt, welcher am 23.03.20 zu registrieren ist, beläuft sich für die Industrieländer -32.10 %, Schwellenländer 31.7 % und Frontier-Länder auf -34.88 %.
Interessanterweise steigen die Marktwerte ab diesem Zeitpunkt wieder an. Gründe könnten die Nachrichten aus China sein, welche keine weiteren Neu-Infektionen verzeichnen, die FED dem Markt bis zu 1.5 Billionen Dollar zur Verfügung stellt und/oder die Ankündigung der Europäische Zentralbank Anleihen in Höhe von 750 MRD. Euro zu kaufen. Auch in Deutschland wurden große Hilfspakete angekündigt.
Um detaillierte Aussagen treffen zu können, müssen wir uns die Kurse auf granularer Ebene anschauen. Durch eine gezieltere Betrachtung auf Länderebene könnten Zusammenhänge näher beschrieben werden.
Wenn du dich für interaktive Analysen interessierst und tiefer in die Materie eintauchen möchtest: DATANOMIQ COVID-19 Dashboard
Hier haben wir ein Dashboard speziell für Analysen für die Aktienmärkte, welches stetig verbessert wird. Auch sollen Krypto-Währungen bald implementiert werden. Habt ihr Vorschläge und Verbesserungswünsche, dann lasst gerne ein Kommentar da!


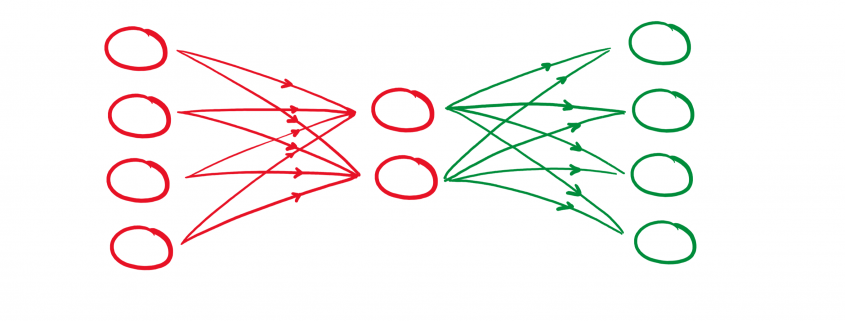
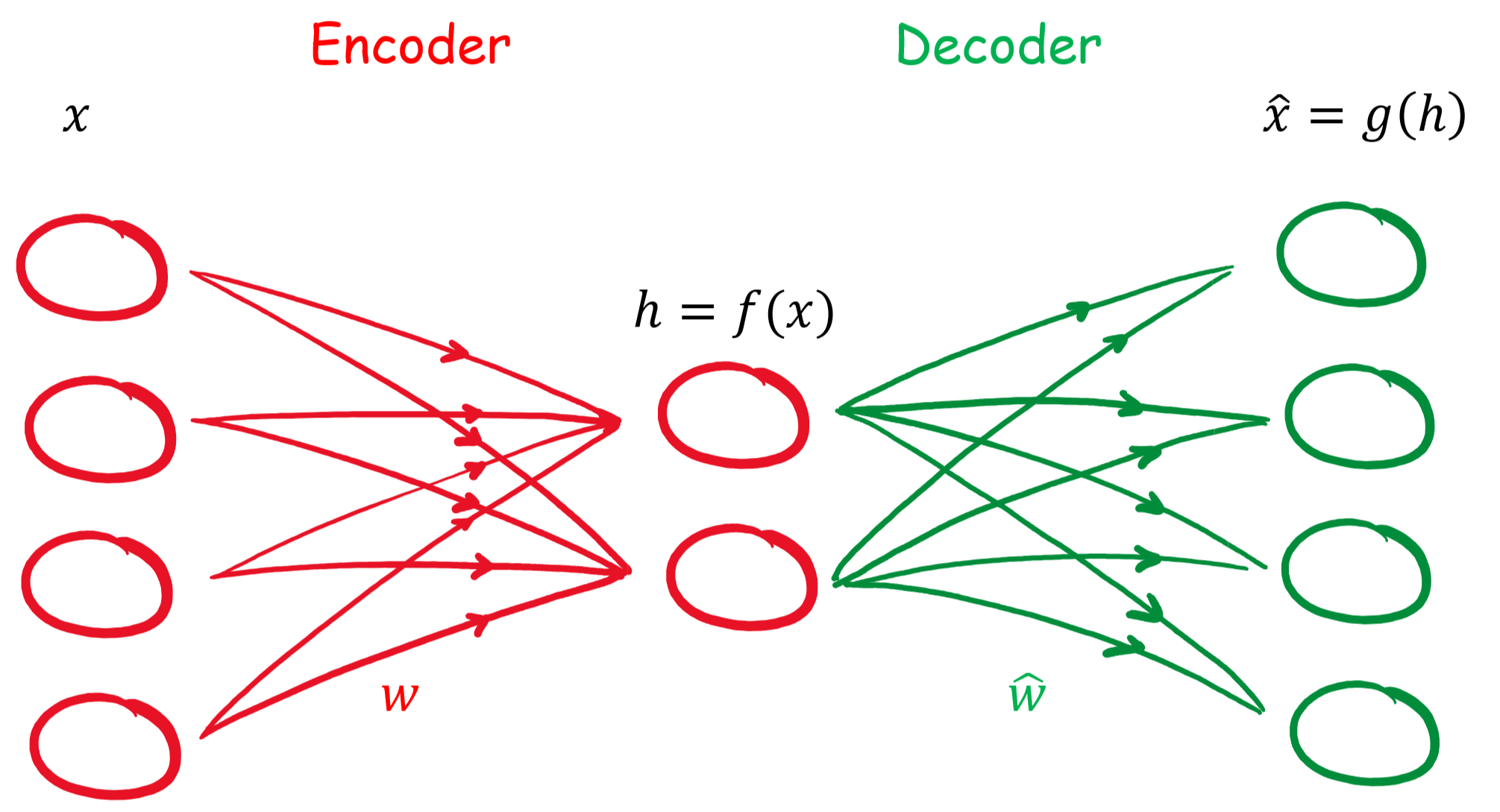






 gekennzeichnet werden. Damit besteht der Zusammenhang:
gekennzeichnet werden. Damit besteht der Zusammenhang:![\begin{align*} \mathbf{h} &= f(\mathbf{x}) = \sigma(\mathbf{W}\mathbf{x} + \mathbf{B}) \\ \hat{\mathbf{x}} &= g(\mathbf{h}) = \hat{\sigma}(\hat{\mathbf{W}} \mathbf{h} + \hat{\mathbf{B}}) \\ \hat{\mathbf{x}} &= \hat{\sigma} \{ \hat{\mathbf{W}} \left[\sigma ( \mathbf{W}\mathbf{x} + \mathbf{B} )\right] + \hat{\mathbf{B}} \}\\ \end{align*}](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-96b9128bd26ff4d2975a372d338e15c4_l3.png "Rendered by QuickLaTeX.com")
![\begin{align*} L(\mathbf{x}, \hat{\mathbf{x}}) &= \mathbf{MSE}(\mathbf{x}, \hat{\mathbf{x}}) = \| \mathbf{x} - \hat{\mathbf{x}} \| ^2 &= \| \mathbf{x} - \hat{\sigma} \{ \hat{\mathbf{W}} \left[\sigma ( \mathbf{W}\mathbf{x} + \mathbf{B} )\right] + \hat{\mathbf{B}} \} \| ^2 \end{align*}](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-2afadab2e44942274d566bd163b513cf_l3.png "Rendered by QuickLaTeX.com")
![\begin{align*} [1, 0, 0, 0] \ \widehat{=} \ 0 \\ [0, 1, 0, 0] \ \widehat{=} \ 1 \\ [0, 0, 1, 0] \ \widehat{=} \ 2 \\ [0, 0, 0, 1] \ \widehat{=} \ 3\\ \end{align*}](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-072135e2e36d72e0e3bf860c5308e03a_l3.png "Rendered by QuickLaTeX.com")
![\begin{align*} [1, 0, 0, 0] \ \widehat{=} \ 0 \ \widehat{=} \ [0, 0] \\ [0, 1, 0, 0] \ \widehat{=} \ 1 \ \widehat{=} \ [0, 1] \\ [0, 0, 1, 0] \ \widehat{=} \ 2 \ \widehat{=} \ [1, 0] \\ [0, 0, 0, 1] \ \widehat{=} \ 3 \ \widehat{=} \ [1, 1] \\ \end{align*}](https://data-science-blog.com/wp-content/ql-cache/quicklatex.com-17422530a780bd436a53fc45b2a523aa_l3.png "Rendered by QuickLaTeX.com")