
Data Vault 2.0 – Flexible Datenmodellierung
Was ist Data Vault 2.0?
Data Vault 2.0 ist ein im Jahr 2000 von Dan Linstedt veröffentlichtes und seitdem immer weiter entwickeltes Modellierungssystem für Enterprise Data Warehouses.
Im Unterschied zum normalisierten Data Warehouse – Definition von Inmon [1] ist ein Data Vault Modell funktionsorientiert über alle Geschäftsbereiche hinweg und nicht themenorientiert (subject-oriented)[2]. Ein und dasselbe Produkt beispielsweise ist mit demselben Business Key sichtbar für Vertrieb, Marketing, Buchhaltung und Produktion.
Data Vault ist eine Kombination aus Sternschema und dritter Normalform[3] mit dem Ziel, Geschäftsprozesse als Datenmodell abzubilden. Dies erfordert eine enge Zusammenarbeit mit den jeweiligen Fachbereichen und ein gutes Verständnis für die Geschäftsvorgänge.
Die Schichten des Data Warehouses:
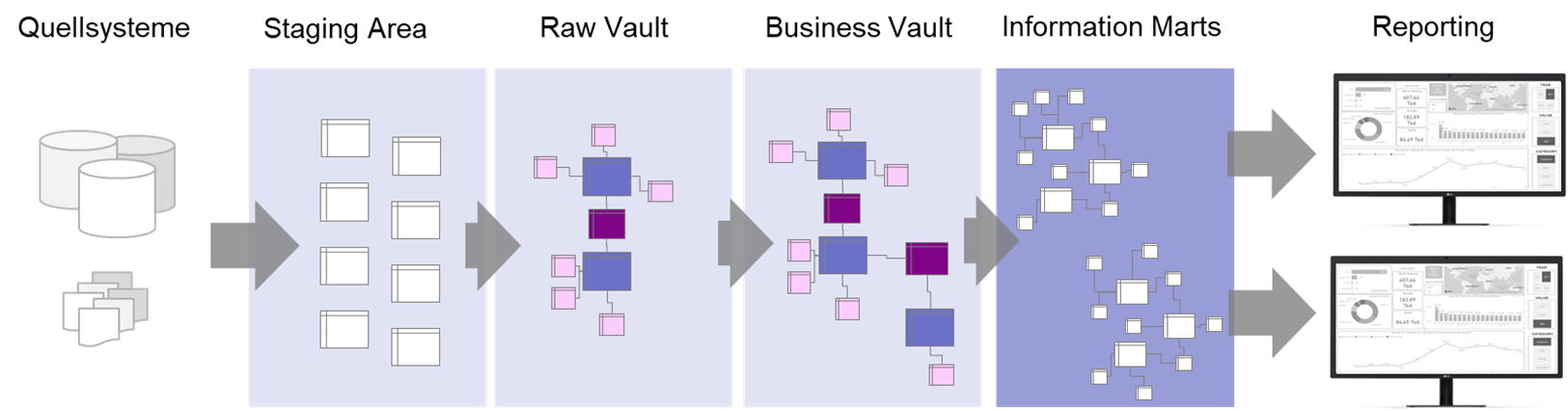
Data Warehouse mit Data Vault und Data Marts
Die Daten werden zunächst über eine Staging – Area in den Raw Vault geladen.
Bis hierher werden sie nur strukturell verändert, das heißt, von ihrer ursprünglichen Form in die Data Vault Struktur gebracht. Inhaltliche Veränderungen finden erst im Business Vault statt; wo die Geschäftslogiken auf den Daten angewandt werden.
Die Information Marts bilden die Basis für die Reporting-Schicht. Hier müssen nicht unbedingt Tabellen erstellt werden, Views können hier auch ausreichend sein. Hier werden Hubs zu Dimensionen und Links zu Faktentabellen, jeweils angereichert mit Informationen aus den zugehörigen Satelliten.
Die Grundelemente des Data Vault Modells:
Daten werden aus den Quellsystemen in sogenannte Hubs, Links und Satelliten im Raw Vault geladen:
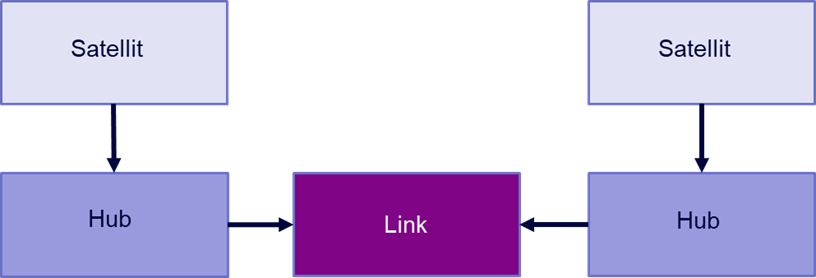
Data Vault 2.0 Schema
Hub:
Hub-Tabellen beschreiben ein Geschäftsobjekt, beispielsweise einen Kunden, ein Produkt oder eine Rechnung. Sie enthalten einen Business Key (eine oder mehrere Spalten, die einen Eintrag eindeutig identifizieren), einen Hashkey – eine Verschlüsselung der Business Keys – sowie Datenquelle und Ladezeitstempel.
Link:
Ein Link beschreibt eine Interaktion oder Transaktion zwischen zwei Hubs. Beispielsweise eine Rechnungszeile als Kombination aus Rechnung, Kunde und Produkt. Auch ein Eintrag einer Linktabelle ist über einen Hashkey eindeutig identifizierbar.
Satellit:
Ein Satellit enthält zusätzliche Informationen über einen Hub oder einen Link. Ein Kundensatellit enthält beispielsweise Name und Anschrift des Kunden sowie Hashdiff (Verschlüsselung der Attribute zur eindeutigen Identifikation eines Eintrags) und Ladezeitstempel.
Herausforderungen bei der Modellierung
Die Erstellung des vollständigen Data Vault Modells erfordert nicht nur eine enge Zusammenarbeit mit den Fachbereichen, sondern auch eine gute Planung im Vorfeld. Es stehen oftmals mehrere zulässige Modellierungsoptionen zur Auswahl, aus denen die für das jeweilige Unternehmen am besten passende Option gewählt werden muss.
Es ist zudem wichtig, sich im Vorfeld Gedanken um die Handhabbarkeit des Modells zu machen, da die Zahl der Tabellen leicht explodieren kann und viele eventuell vermeidbare Joins notwendig werden.
Obwohl Data Vault als Konzept schon viele Jahre besteht, sind online nicht viele Informationen frei verfügbar – gerade für komplexere Modellierungs- und Performanceprobleme.
Zusätzliche Elemente:
Über die Kernelemente hinaus sind weitere Tabellen notwendig, um die volle Funktionalität des Data Vault Konzeptes auszuschöpfen:
PIT Tabelle
Point-in-Time Tabellen zeigen einen Snapshot der Daten zu einem bestimmten Zeitpunkt. Sie enthalten die Hashkeys und Hashdiffs der Hubs bzw. Links und deren zugehörigen Satelliten. So kann man schnell den jeweils aktuellsten Satelliteneintrag zu einem Hashkey herausfinden.
Referenztabellen
Zusätzliche, weitgehend feststehende Tabellen, beispielsweise Kalendertabellen.
Effektivitätssatellit
Diese Satelliten verfolgen die Gültigkeit von Satelliteneinträgen und markieren gelöschte Datensätze mit einem Zeitstempel. Sie können in den PIT Tabellen verarbeitet werden, um ungültige Datensätze herauszufiltern.
Bridge Tabelle
Bridge Tabellen sind Teil des Business Vaults und enthalten nur Hub- und Linkhashkeys. Sie ähneln Faktentabellen und dienen dazu, von Endanwender*innen benötigte Schlüsselkombinationen vorzubereiten.
Vorteile und Nachteile von Data Vault 2.0
Vorteile:
- Da Hubs, Links und Satelliten jeweils unabhängig voneinander sind, können sie schnell parallel geladen werden.
- Durch die Modularität des Systems können erste Projekte schnell umgesetzt werden.
- Vollständige Historisierung aller Daten, denn es werden niemals Daten gelöscht.
- Nachverfolgbarkeit der Daten
- Handling personenbezogener Daten in speziellen Satelliten
- Einfache Erweiterung des Datenmodells möglich
- Zusammenführung von Daten aus unterschiedlichen Quellen grundsätzlich möglich
- Eine fast vollständige Automatisierung der Raw Vault Ladeprozesse ist möglich, da das Grundkonzept immer gleich ist.
Nachteile:
- Es sind verhältnismäßig wenige Informationen, Hilfestellungen und Praxisbeispiele online zu finden und das Handbuch von Dan Linstedt ist unübersichtlich gestaltet.
- Zusammenführung unterschiedlicher Quellsysteme kaum in der verfügbaren Literatur dokumentiert und in der Praxis aufwendig.
- Hoher Rechercheaufwand im Vorfeld und eine gewisse Anlauf- und Experimentierphase auch was die Toolauswahl angeht sind empfehlenswert.
- Es wird mit PIT- und Bridge Tabellen und Effektivitätssatelliten noch viel zusätzlicher Overhead geschaffen, der verwaltet werden muss.
- Business Logiken können die Komplexität des Datemodells stark erhöhen.
- Eine Automatisierung des Business Vaults ist nur begrenzt möglich.
Praxisbeispiel Raw Vault Bestellung:
Das Design eines Raw Vault Modells funktioniert in mehreren Schritten:
- Business Keys identifizieren und Hubs definieren
- Verbindungen (Links) zwischen den Hubs identifizieren
- Zusätzliche Informationen zu den Hubs in Satelliten hinzufügen
Angenommen, man möchte eine Bestellung inklusive Rechnung und Versand als Data Vault modellieren.
Hubs sind alle Entitäten, die sich mit einer eindeutigen ID – einem Business Key – identifizieren lassen. So erstellt man beispielsweise einen Hub für den Kunden, das Produkt, den Kanal, über den die Bestellung hereinkommt (online / telefonisch), die Bestellung an sich, die dazugehörige Rechnung, eine zu bebuchende Kostenstelle, Zahlungen und Lieferung. Diese Liste ließe sich beliebig ergänzen.
Jeder Eintrag in einem dieser Hubs ist durch einen Schlüssel eindeutig identifizierbar. Die Rechnung durch die Rechnungsnummer, das Produkt durch eine SKU, der Kunde durch die Kundennummer etc.
Eine Zeile einer Bestellung kann nun modelliert werden als ein Link aus Bestellung (im Sinne von Bestellkopf), Kunde, Rechnung, Kanal, Produkt, Lieferung, Kostenstelle und Bestellzeilennummer.
Analog dazu können Rechnung und Lieferung ebenso als Kombination aus mehreren Hubs modelliert werden.
Allen Hubs werden anschließend ein oder mehrere Satelliten zugeordnet, die zusätzliche Informationen zu ihrem jeweiligen Hub enthalten.
Personenbezogene Daten, beispielsweise Namen und Adressen von Kunden, werden in separaten Satelliten gespeichert. Dies ermöglicht einen einfachen Umgang mit der DSGVO.
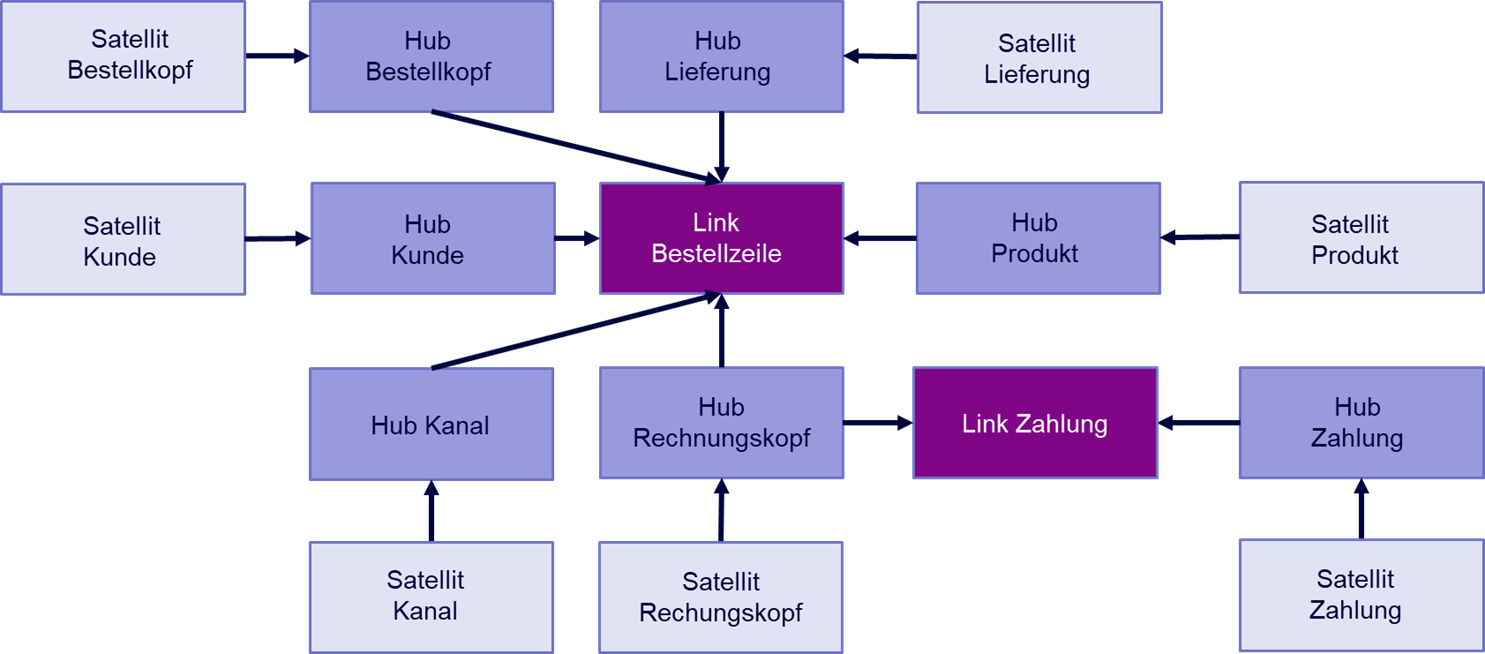
Data Vault 2.0 Beispiel Bestelldatenmodell
Fazit
Data Vault ist ein Modellierungsansatz, der vor allem für Organisationen mit vielen Quellsystemen und sich häufig ändernden Daten sinnvoll ist. Hier lohnt sich der nötige Aufwand für Design und Einrichtung eines Data Vaults und die Benefits in Form von Flexibilität, Historisierung und Nachverfolgbarkeit der Daten kommen wirklich zum Tragen.
Quellen
[1] W. H. Inmon, What is a Data Warehouse?. Volume 1, Number 1, 1995
[2] Dan Linstedt, Super Charge Your Data Warehouse: Invaluable Data Modeling Rules to Implement Your Data Vault. CreateSpace Independent Publishing Platform 2011
[3] Vgl. Linstedt 2011
Weiterführende Links und
Blogartikel von Analytics Today
Einführung in Data Vault von Kent Graziano: pdf
Website von Dan Linstedt mit vielen Informationen und Artikeln
„Building a Scalable Data Warehouse with Data Vault 2.0“ von Dan Linstedt (Amazon Link)


 Jurek Dörner @ DATANOMIQ
Jurek Dörner @ DATANOMIQ



 https://www.haufe-akademie.de
https://www.haufe-akademie.de
Leave a Reply
Want to join the discussion?Feel free to contribute!