
Kubernetes – der Steuermann für dein Big Data Projekt!
Kubernetes ist ein Container-Orchestrierungssystem. Damit lassen sich also Anwendungen auf verschiedene Container aufteilen, wodurch sie effizient und ausfallsicher ausgeführt werden können. Kubernetes ist ein Open-Source-Projekt und wurde erstmals im Jahr 2014 veröffentlicht. Es ist sehr leistungsfähig und kann verteilte Systeme, die über Tausende von Rechnern verstreut sind, verwalten.
In diesem und in vielen anderen Beiträgen zum Thema Kubernetes wird die Abkürzung k8s genutzt. Sie kommt daher, dass das Wort Kubernetes mit k beginnt, mit s endet und dazwischen 8 Buchstaben stehen. Bevor wir beginnen, noch eine kleine Anmerkung, woher der Name Kubernetes eigentlich stammt: Das griechische Wort „Kubernetes“ bedeutet Steuermann und beschreibt genau das, was Kubernetes macht, es steuert. Es steuert verschiedene sogenannte Container und koordiniert deren Ausführung.
Was sind Container und warum brauchen wir sie?
Eines der bestimmenden Merkmale von Big Data oder Machine Learning Projekte ist, dass ein einzelner Computer in vielen Fällen nicht ausreicht, um die gewaltigen Rechenlasten bewältigen zu können. Deshalb ist es notwendig, mehrere Computer zu verwenden, die sich die Arbeit teilen können. Zusätzlich können durch ein solches System auch Ausfälle von einzelnen Computern kompensiert werden, wodurch wiederum sichergestellt ist, dass die Anwendung durchgehend erreichbar ist. Wir bezeichnen eine solche Anordnung von Computern als Computing-Cluster oder verteiltes System für paralleles Rechnen.
Im Mittelpunkt des Open Source Projektes Docker stehen die sogenannten Container. Container sind alleinstehende Einheiten, die unabhängig voneinander ausgeführt werden und immer gleich ablaufen. Docker-Container können wir uns tatsächlich relativ praktisch wie einen Frachtcontainer vorstellen. Angenommen, in diesem Container arbeiten drei Menschen an einer bestimmten Aufgabe (Ich weiß, dass dies wahrscheinlich gegen jedes geltende Arbeitsschutzgesetz verstößt, aber es passt nun mal sehr gut in unser Beispiel).
In ihrem Container finden sie alle Ressourcen und Maschinen, die sie für ihre Aufgabe benötigen. Über eine bestimmte Lucke im Container bekommen sie die Rohstoffe geliefert, die sie benötigen, und über eine andere Lucke geben sie das fertige Produkt heraus. Unser Schiffscontainer kann dadurch ungestört und weitestgehend autark arbeiten. Den Menschen darin wird es nicht auffallen, ob sich das Schiff inklusive Container gerade im Hamburger Hafen, in Brasilien oder irgendwo bei ruhigem Seegang auf offenem Meer befindet. Solange sie kontinuierlich Rohstoffe geliefert bekommen, führen sie ihre Aufgabe aus, egal wo sie sind.

Foto von Ian Taylor auf Unsplash
Genauso verhält es sich mit Docker Containern im Softwareumfeld. Es handelt sich dabei um genau definierte, abgeschlossene Applikationen, die auf verschiedenen Maschinen/Rechnern laufen können. Solange sie die festgelegten Inputs kontinuierlich erhalten, können sie auch kontinuierlich weiterarbeiten, unabhängig von ihrer Umgebung.
Was macht Kubernetes?
Wir nutzen Computing-Cluster, um rechenintensive Projekte, wie Machine Learning Modelle, auf mehreren Rechnern zuverlässig und effizient laufen lassen zu können. In Containern wiederum programmieren wir Unteraufgaben, die in sich abgeschlossen sein können und die immer gleich ablaufen, egal ob auf Rechner 1 oder Rechner 2. Das klingt doch eigentlich ausreichend, oder?
Verteilte Systeme bieten gegenüber Einzelrechnern neben Vorteilen auch zusätzliche Herausforderungen, beispielsweise bei der gemeinsamen Nutzung von Daten oder der Kommunikation zwischen den Rechnern innerhalb des Clusters. Kubernetes übernimmt die Arbeit die Container auf das Cluster zu verteilen und sorgt für den reibungslosen Ablauf des Programmes. Dadurch können wir uns auf das eigentliche Problem, also unseren konkreten Anwendungsfall, konzentrieren.
Kubernetes ist also wie der Kapitän, oder Steuermann, auf dem großen Containerschiff, der die einzelnen Container auf seinem Schiff richtig platziert und koordiniert.
Aufbau eines Kubernetes Clusters
Kubernetes wird normalerweise auf einem Cluster von Computern installiert. Jeder Computer in diesem Cluster wird als Node bezeichnet. Auf einem Computer bzw. Node wiederum laufen mehrere sogenannte Pods. Auf den Pods sind die schlussendlichen Container mit den kleineren Applikationen installiert und können in einem lokalen System kommunizieren.
Damit die Pods und die Container darin ohne Komplikationen laufen können, gibt es einige Hilfsfunktionen und -komponenten im Kubernetes Cluster, die dafür sorgen, dass alle Systeme reibungslos funktionieren:
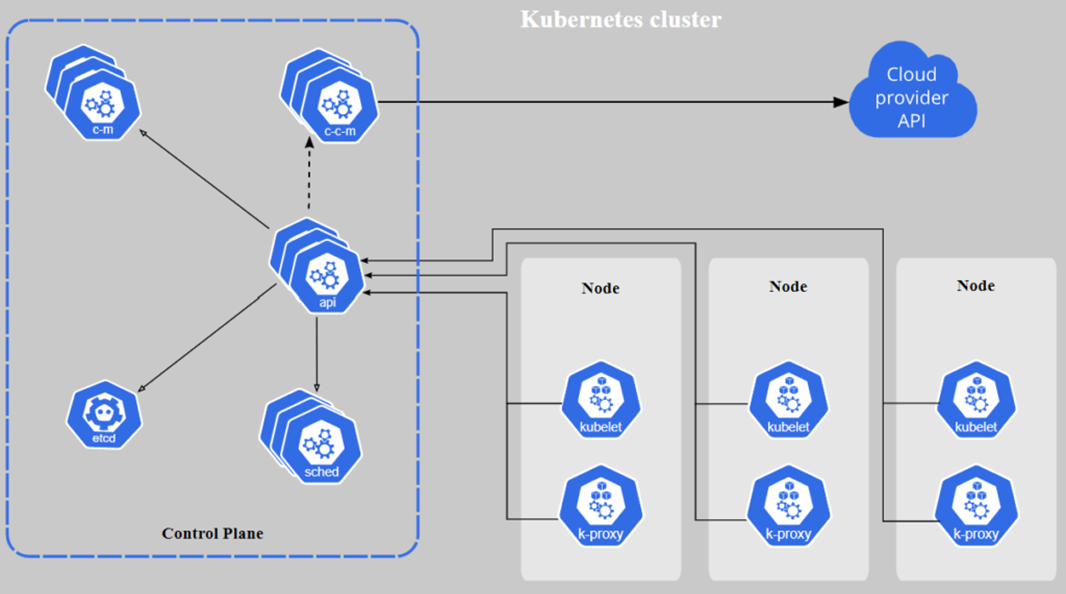
Aufbau Kubernetes Cluster | Abbildung: Kubernetes
- Control Plane: Das ist der Rechner, welcher das komplette Cluster überwacht. Auf diesem laufen keine Pods für die Anwendung. Stattdessen werden den einzelnen Pods die Container zugewiesen, die auf ihnen laufen sollen.
- Sched: Der Scheduler hält innerhalb des Clusters Ausschau nach neu erstellen Pods und teilt diese zu bestehenden Nodes zu.
- ETCD: Ein Speicher für alle Informationen, die im Cluster anfallen und aufbewahrt werden müssen, bspw. Metadaten zur Konfiguration.
- Cloud Controller Manager (CCM): Wenn ein Teil des Systems auf Cloud Ressourcen läuft, kommt diese Komponente zum Einsatz und übernimmt die Kommunikation und Koordination mit der Cloud.
- Controller Manager (CM): Die wichtigste Komponente im Kubernetes Cluster überwacht das Cluster und sucht nach ausgefallenen Nodes, um dann die Container und Pods neu zu verteilen.
- API: Diese Schnittstelle ermöglicht die Kommunikation zwischen den Nodes und dem Control Plane.
Die Nodes sind deutlich schlanker aufgebaut als das Control Plane und enthalten neben den Pods zwei wesentliche Komponenten zur Überwachung:
- Kubelet: Es ist das Control Plane innerhalb eines Nodes und sorgt dafür, dass alle Pods einwandfrei laufen.
- Kube-Proxy (k-proxy): Diese Komponente verteilt den eingehenden Node Traffic an die Pods, indem es das Netzwerk innerhalb des Nodes erstellt.
Fazit
Ein Netzwerk aus verschiedenen Computern wird als Cluster bezeichnet und wird genutzt, um große Rechenlasten auf mehrere Computer aufteilen und dadurch effizienter gestalten zu können. Die kleinste Einheit, in die man eine Applikation aufteilen kann, ist der Docker Container. Dieser beinhaltet eine Unteraufgabe des Programms, die autark, also unabhängig vom System, ausgeführt wird.
Da es in einem Computing-Cluster sehr viele dieser Container geben kann, übernimmt Kubernetes für uns das Management der Container, also unter anderem deren Kommunikation und Koordinierung. Das Kubernetes Cluster hat dazu verschiedene Komponenten die dafür sorgen, dass alle Container laufen und das System einwandfrei funktioniert.
 Jurek Dörner @ DATANOMIQ
Jurek Dörner @ DATANOMIQ





Leave a Reply
Want to join the discussion?Feel free to contribute!