The Basics of Logistic Regression in Data Science
Data science is a field that is growing by leaps and bounds. A couple decades ago, using a machine learning program to make predictions about datasets was the purview of science fiction. Today, all you need is a computer, some solid programming, and a bit of patience, and you, too, can have your own digital Zoltar.
Okay, it’s not really telling the future, but it does give you the ability to predict some future events, as long as those events fall within the data the system already has. These predictions fall into two categories: linear regression and logistic regression.
Today we’re going to focus on the latter. What is logistic regression in data science, and how can it help data scientists and analysts solve problems?
What Is Logistic Regression?
First, what is logistic regression, and how does it compare to its linear counterpart?
Logistic regression is defined as “a statistical analysis method used to predict a data value based on prior observations of a data set.” It is valuable for predicting the result if it is dichotomous, meaning there are only two possible outcomes.
For example, a logistic regression system could use its data set to predict whether a specific team will win a game, based on their previous performance and the performance of their competitors because there are only two possible outcomes — a win or a loss.
Linear regression, on the other hand, is better suited for continuous output or situations where there are more than two possible outcomes. A traffic prediction model would use linear regression. In these situations, no matter how much data the program has, there are always variables that can throw a wrench in the works.
This isn’t just a case of “go” or “no go,” like you might see with a rocket launch. A company using these predictive models to schedule deliveries will need to be able to compensate for those variables. Linear regression gives them the flexibility to do that.
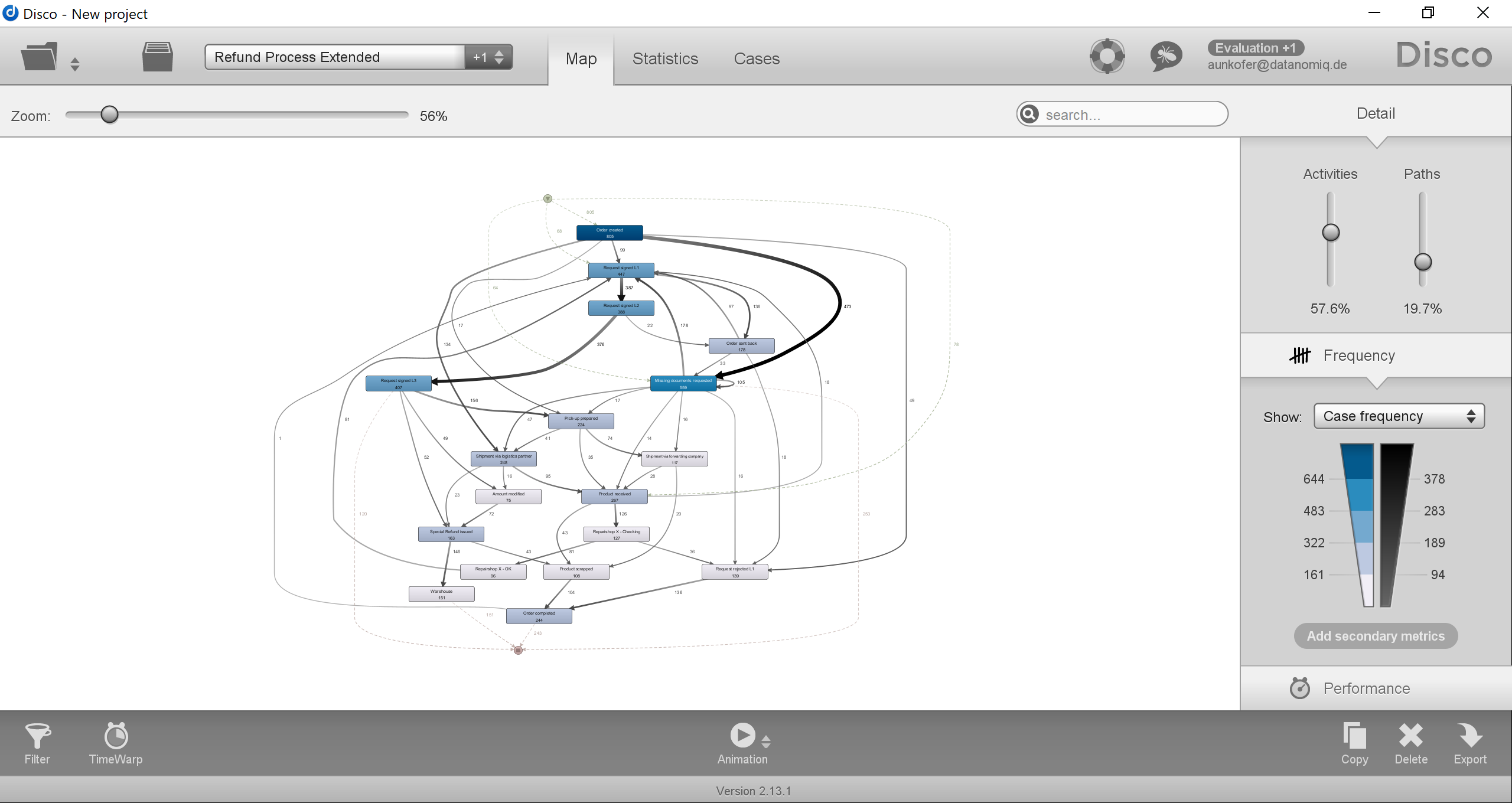
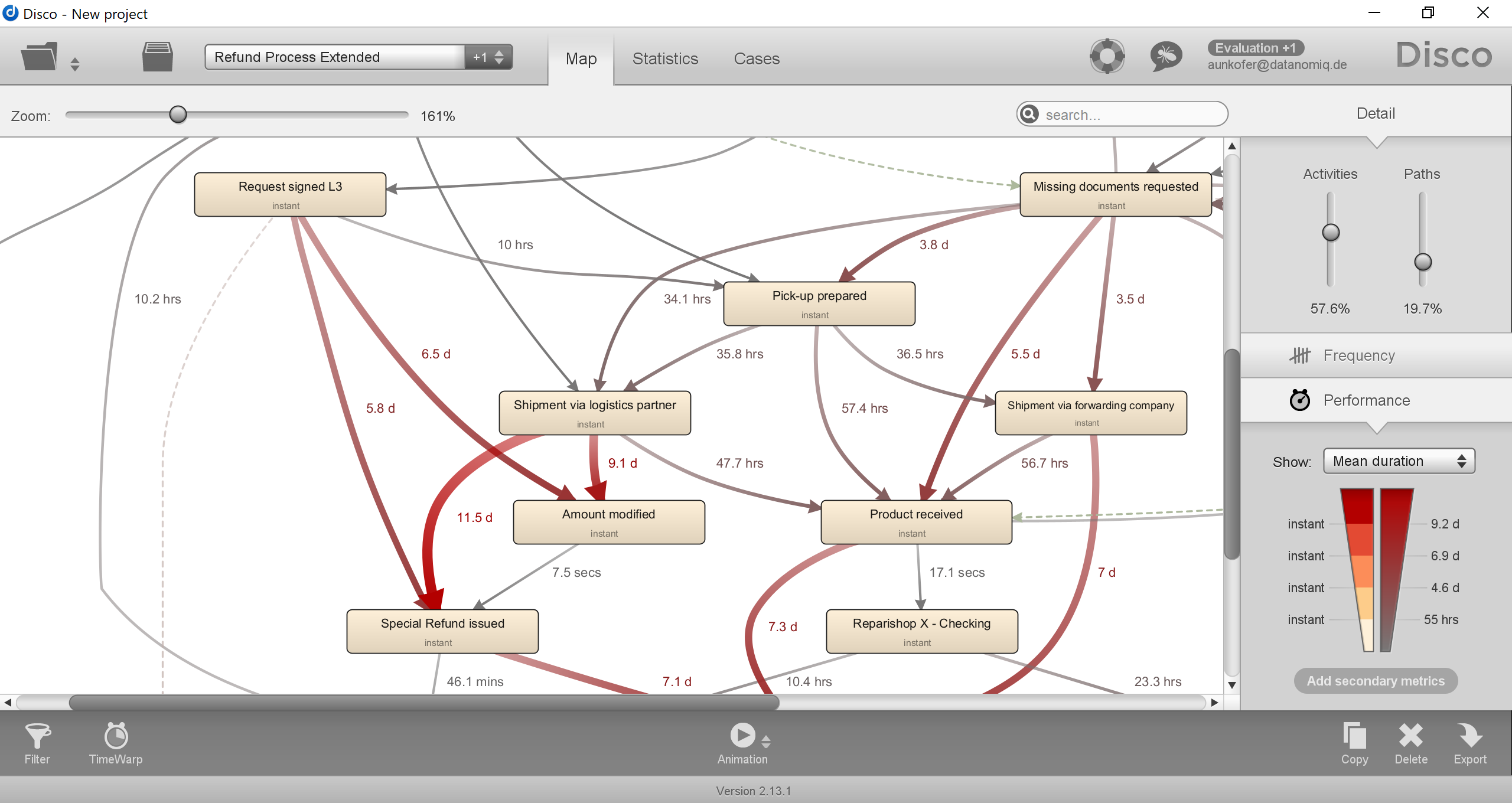
Logistic Regression in Data Analysis
If you broke down the expression of logistic regression on paper, it would look something like this:
![]() The left side of the equation is called a logit, while the right side represents the odds, or the probability of success vs. failure.
The left side of the equation is called a logit, while the right side represents the odds, or the probability of success vs. failure.
It seems incredibly complicated, but when you break it down and feed it into a machine learning algorithm, it provides a great number of benefits. For one, it’s simple — in relative terms — and doesn’t generate a lot of variance because, at the end, no matter how much data you feed a logistic regression system, there are only going to be two possible outcomes.
In addition to providing you with a “yes” or “no” answer, these systems can also provide the probability for each potential outcome. The downside of logistic regression systems is that they don’t function well if you feed them too many different variables. They will also need an additional translator system to convert non-linear features to linear ones.
Applications of Logistic Regression
The potential applications for logistic regression are nearly limitless. But if you find yourself struggling to picture where you might use this data analysis tool, here are a few examples that might help you.
Organizations can use logistic regression for credit scoring. While this might seem like it’s outside the scope of this particular type of programming because there are multiple credit scores a person might have, when you break it down to ones and zeros, there are usually only two possible outcomes where credit is concerned — approved or denied.
There are a number of potential applications for logistic regression in medicine as well. When it comes to testing for a specific condition, there are usually only two results — “yes” or “no.” Either the patient has the condition, or they don’t. In this case, it may be necessary to program in a third option — a null variable — that trips when there isn’t enough information available for a particular patient to make an accurate diagnostic decision.
Even text editing can benefit from logistic regression. Plug in a dictionary, and let it loose on a piece of text. These programs aren’t going to create masterpieces or even fix editing mistakes because they lack the programming to understand things like context and tone, but they are invaluable for spelling mistakes. Again, this brings us back to the binary of 1’s and 0’s — either a word is spelled correctly, according to the dictionary definition, or it isn’t.
If dichotomous outcomes are the goal of your data analysis system, logistic regression is going to be the best tool in your toolbox.
Breaking Down the Basics
A lot goes into the creation of a machine learning or predictive analysis tool, but understanding the difference between linear and logistic regression can make that process a bit simpler. Start by understanding what the program will do, then choose your regression form appropriately.