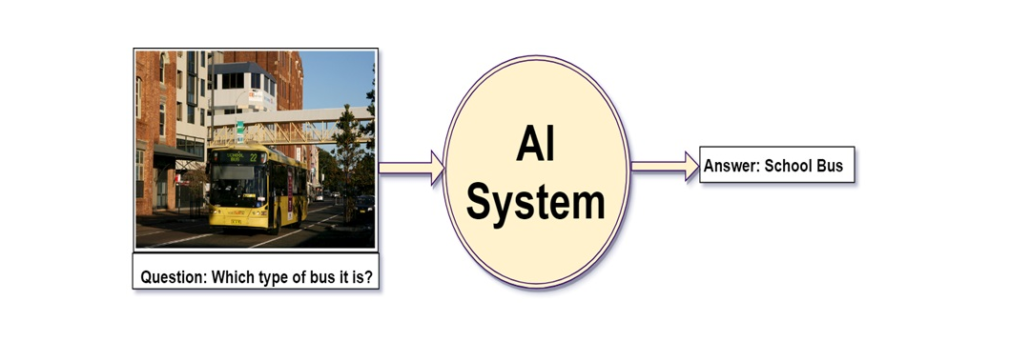
Visual Question Answering with Keras – Part 2: Making Computers Intelligent to answer from images

Making Computers Intelligent to answer from images
This is my second blog on Visual Question Answering, in the last blog, I have introduced to VQA, available datasets and some of the real-life applications of VQA. If you have not gone through then I would highly recommend you to go through it. Click here for more details about it.
In this blog post, I will walk through the implementation of VQA in Keras.
You can download the dataset from here: https://visualqa.org/index.html. All my experiments were performed with VQA v2 and I have used a very tiny subset of entire dataset i.e all samples for training and testing from the validation set.
Table of contents:
- Preprocessing Data
- Process overview for VQA
- Data Preprocessing – Images
- Data Preprocessing through the spaCy library- Questions
- Model Architecture
- Defining model parameters
- Evaluating the model
- Final Thought
- References
NOTE: The purpose of this blog is not to get the state-of-art performance on VQA. But the idea is to get familiar with the concept. All my experiments were performed with the validation set only.
Full code on my Github here.
1. Preprocessing Data:
If you have downloaded the dataset then the question and answers (called as annotations) are in JSON format. I have provided the code to extract the questions, annotations and other useful information in my Github repository. All extracted information is stored in .txt file format. After executing code the preprocessing directory will have the following structure.

All text files will be used for training.
2. Process overview for VQA:
As we have discussed in previous post visual question answering is broken down into 2 broad-spectrum i.e. vision and text. I will represent the Neural Network approach to this problem using the Convolutional Neural Network (for image data) and Recurrent Neural Network(for text data).
If you are not familiar with RNN (more precisely LSTM) then I would highly recommend you to go through Colah’s blog and Andrej Karpathy blog. The concepts discussed in this blogs are extensively used in my post.
The main idea is to get features for images from CNN and features for the text from RNN and finally combine them to generate the answer by passing them through some fully connected layers. The below figure shows the same idea.
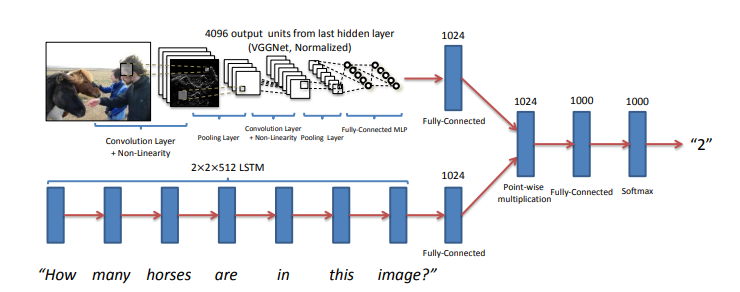
Image Source: https://arxiv.org/pdf/1505.00468.pdf
I have used VGG-16 to extract the features from the image and LSTM layers to extract the features from questions and combining them to get the answer.
3. Data Preprocessing – Images:
Images are nothing but one of the input to our model. But as you already may know that before feeding images to the model we need to convert into the fixed-size vector.
So we need to convert every image into a fixed-size vector then it can be fed to the neural network. For this, we will use the VGG-16 pretrained model. VGG-16 model architecture is trained on millions on the Imagenet dataset to classify the image into one of 1000 classes. Here our task is not to classify the image but to get the bottleneck features from the second last layer.
Hence after removing the softmax layer, we get a 4096-dimensional vector representation (bottleneck features) for each image.
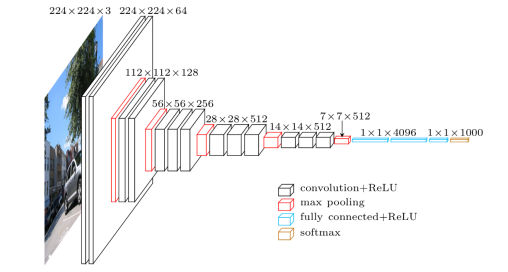
Image Source: https://www.cs.toronto.edu/~frossard/post/vgg16/
For the VQA dataset, the images are from the COCO dataset and each image has unique id associated with it. All these images are passed through the VGG-16 architecture and their vector representation is stored in the “.mat” file along with id. So in actual, we need not have to implement VGG-16 architecture instead we just do look up into file with the id of the image at hand and we will get a 4096-dimensional vector representation for the image.
4. Data Preprocessing through the spaCy library- Questions:
spaCy is a free, open-source library for advanced Natural Language Processing (NLP) in Python. As we have converted images into a fixed 4096-dimensional vector we also need to convert questions into a fixed-size vector representation. For installing spaCy click here.
You might know that for training word embeddings in Keras we have a layer called an Embedding layer which takes a word and embeds it into a higher dimensional vector representation. But by using the spaCy library we do not have to train the get the vector representation in higher dimensions.
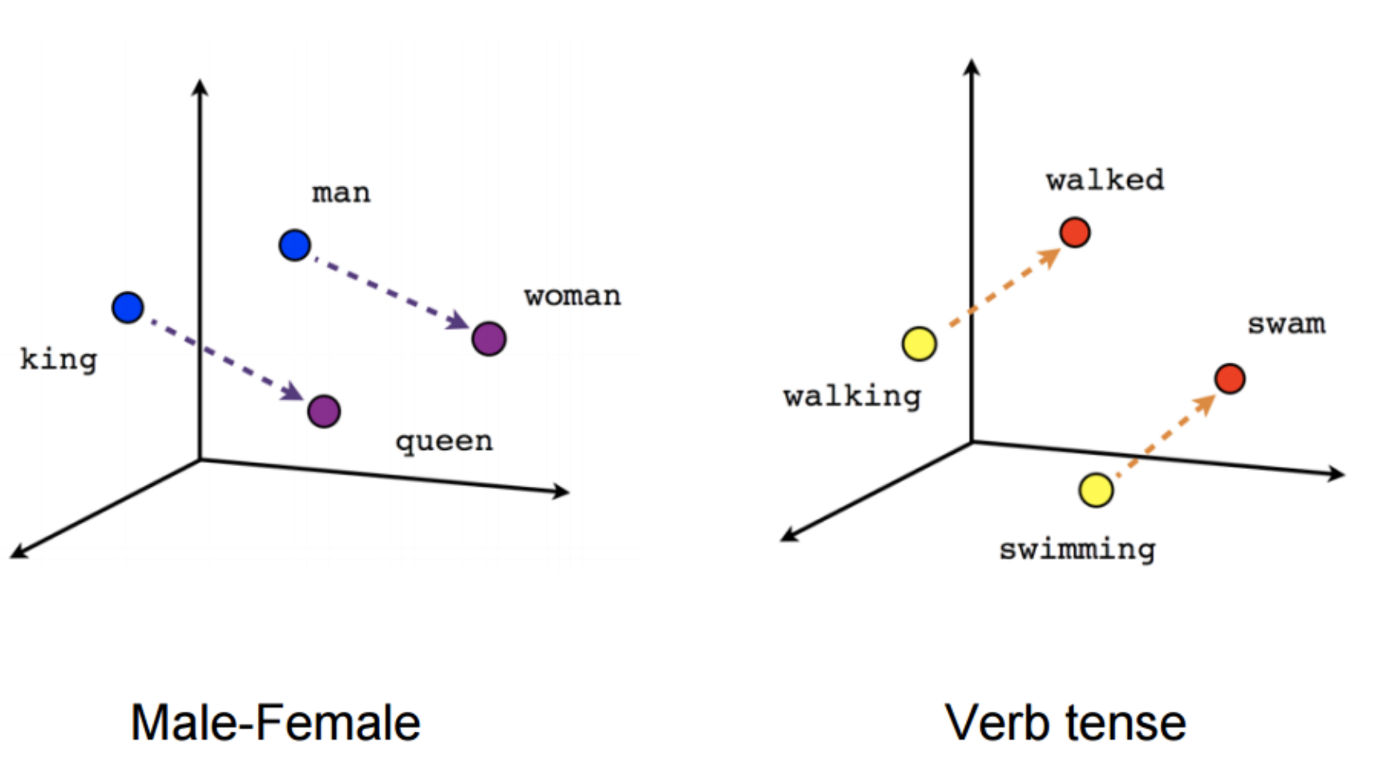
This model is actually trained on billions of tokens of the large corpus. So we just need to call the vector method of spaCy class and will get vector representation for word.
After fitting, the vector method on tokens of each question will get the 300-dimensional fixed representation for each word.
5. Model Architecture:
In our problem the input consists of two parts i.e an image vector, and a question, we cannot use the Sequential API of the Keras library. For this reason, we use the Functional API which allows us to create multiple models and finally merge models.
The below picture shows the high-level architecture idea of submodules of neural network.
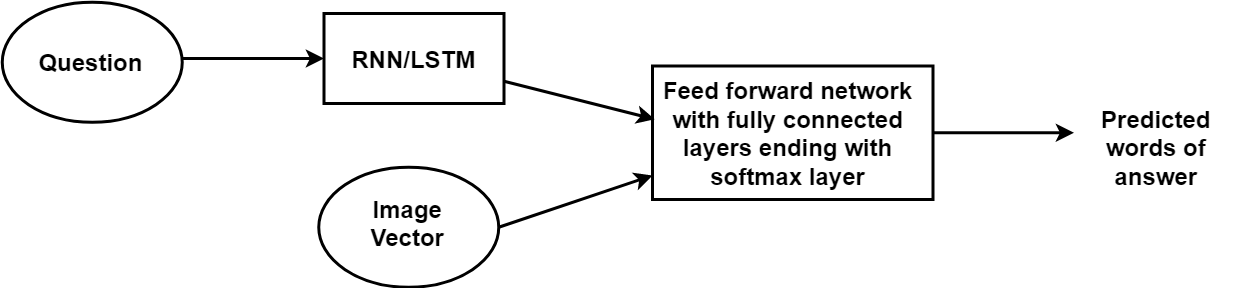
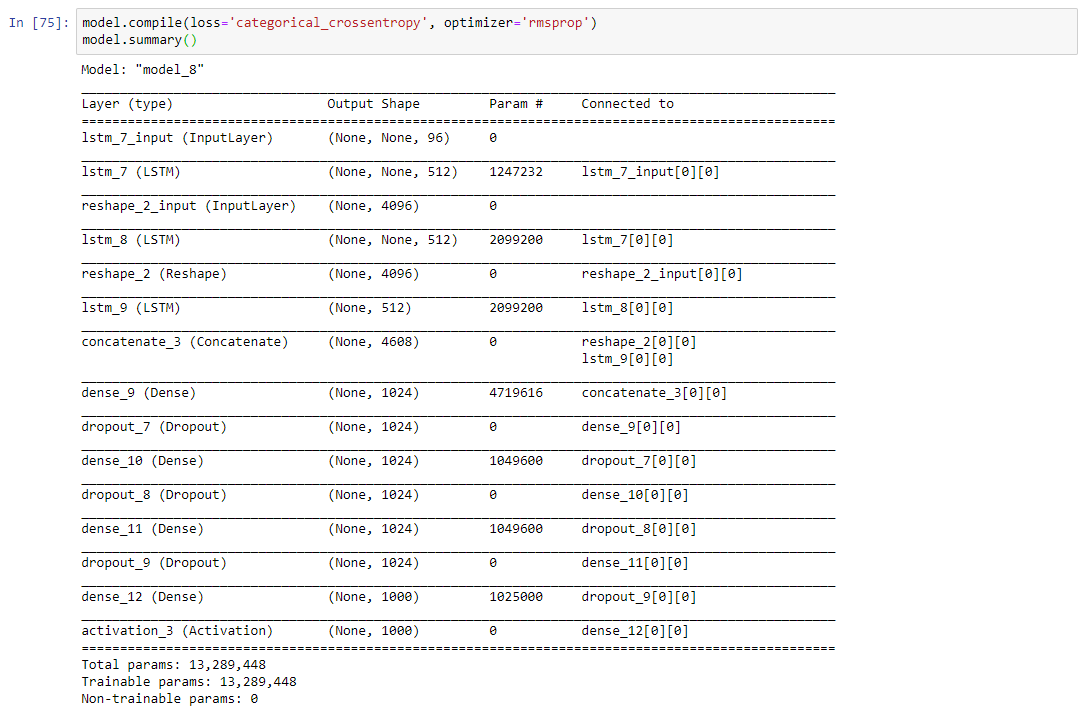
After concatenating the 2 different models the summary will look like the following.
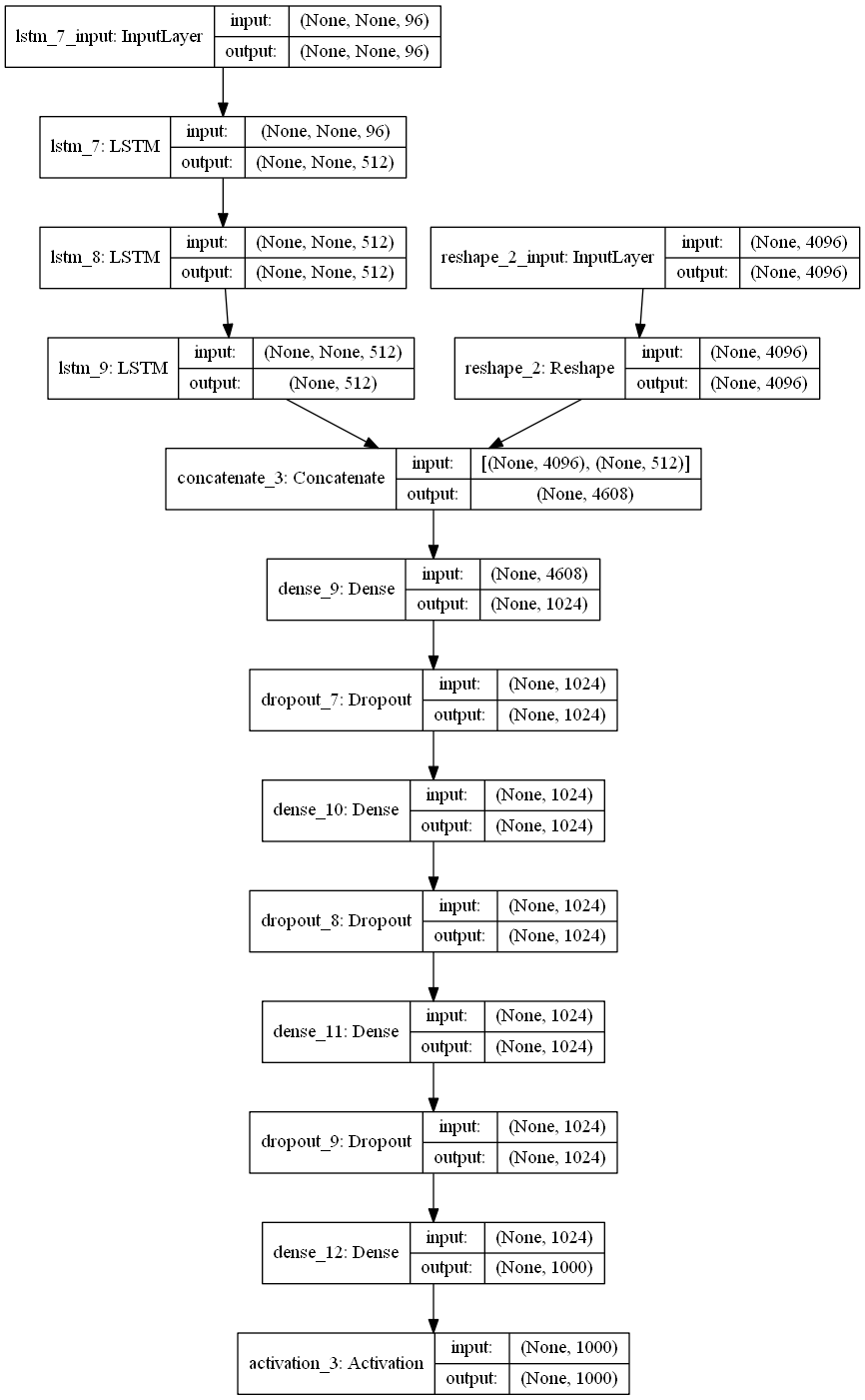
The below plot helps us to visualize neural network architecture and to understand the two types of input:
6. Defining model parameters:
The hyperparameters that we are going to use for our model is defined as follows:

If you know what this parameter means then you can play around it and can get better results.
Time Taken: I used the GPU on https://colab.research.google.com and hence it took me approximately 2 hours to train the model for 5 epochs. However, if you train it on a PC without GPU, it could take more time depending on the configuration of your machine.
7. Evaluating the model:
Since I have used the very small dataset for performing these experiments I am not able to get very good accuracy. The below code will calculate the accuracy of the model.
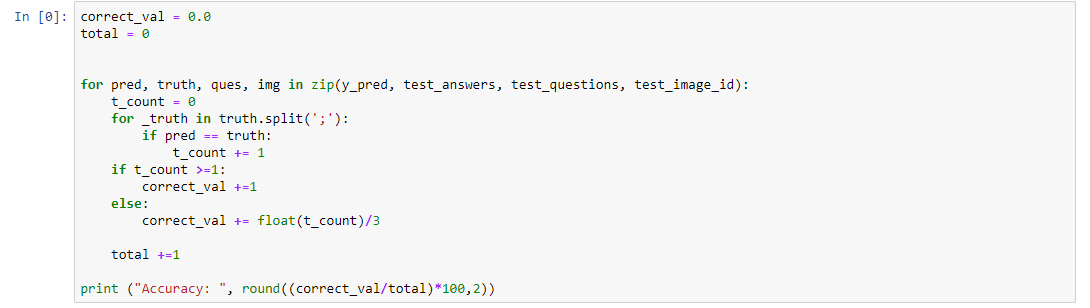
Since I have trained a model multiple times with different parameters you will not get the same accuracy as me. If you want you can directly download mode.h5 file from my google drive.
8. Final Thoughts:
One of the interesting thing about VQA is that it a completely new field. So there is absolutely no end to what you can do to solve this problem. Below are some tips while replicating the code.
- Start with a very small subset of data: When you start implementing I suggest you start with a very small amount of data. Because once you are ready with the whole setup then you can scale it any time.
- Understand the code: Understanding code line by line is very much helpful to match your theoretical knowledge. So for that, I suggest you can take very few samples(maybe 20 or less) and run a small chunk (2 to 3 lines) of code to get the functionality of each part.
- Be patient: One of the mistakes that I did while starting with this project was to do everything at one go. If you get some error while replicating code spend 4 to 5 days harder on that. Even after that if you won’t able to solve, I would suggest you resume after a break of 1 or 2 days.
VQA is the intersection of NLP and CV and hopefully, this project will give you a better understanding (more precisely practically) with most of the deep learning concepts.
If you want to improve the performance of the model below are few tips you can try:
- Use larger datasets
- Try Building more complex models like Attention, etc
- Try using other pre-trained word embeddings like Glove
- Try using a different architecture
- Do more hyperparameter tuning
The list is endless and it goes on.
In the blog, I have not provided the complete code you can get it from my Github repository.
9. References:
- https://blog.floydhub.com/asking-questions-to-images-with-deep-learning/
- https://tryolabs.com/blog/2018/03/01/introduction-to-visual-question-answering/
- https://github.com/sominwadhwa/vqamd_floyd








I have to need a code of this project to understand visual question answering. please help me in this regrad