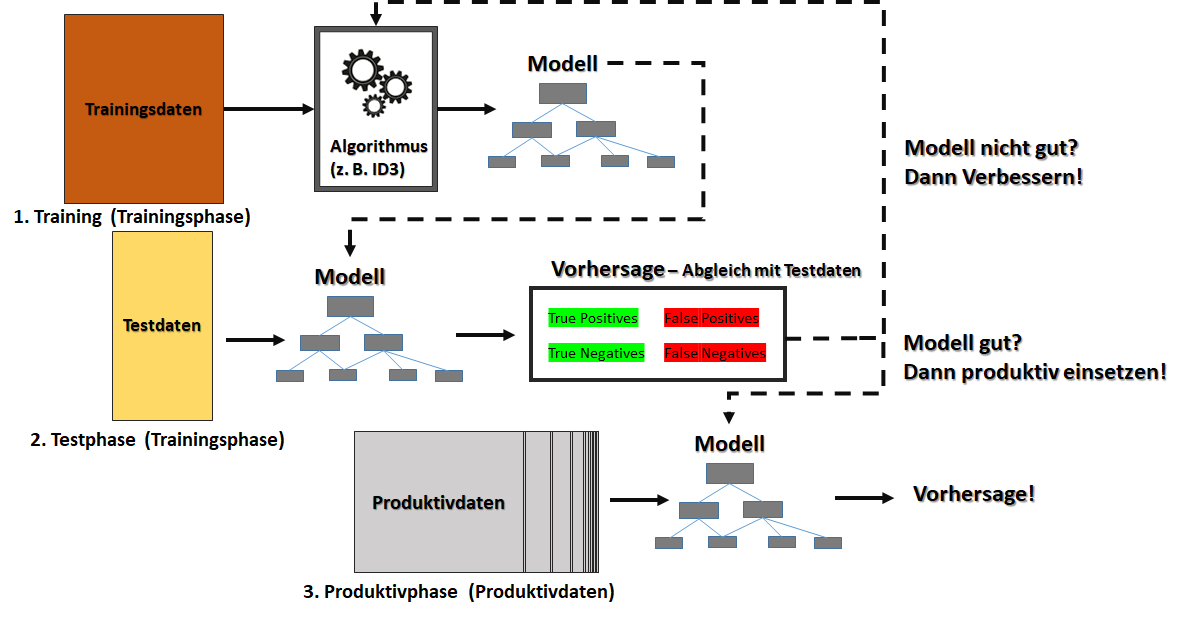
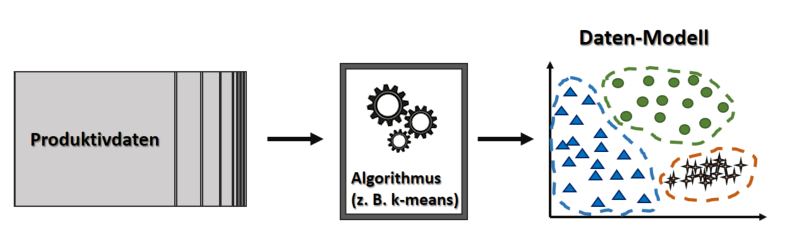
Ways AI & ML Are Changing How We Live
From Amazon’s Alexa, a personal assistant that can do anything from making your to-do list to giving a wide range of real-time information about the world around you, to Google’s DeepMind that has very recently made headlines for possibly being able to predict the future, AI and ML are the biggest development in human history.
Machine Learning Used by Hospitals
We hear a lot about Artificial Intelligence (AI) in the realm of insurance Big Data, but there isn’t much buzz around how AI and ML are revolutionising hospitals. The national health expenditures were around $3.4 trillion and estimated to increase from 17.8 percent of GDP to 19.9 percent between 2015 and 2025. By 2021, industry analysts have predicted that the AI health market will reach $6.6 billion. By 2026, such increases in AI technology in the healthcare sector will save the economy around $150 billion annually.
Some of the most popular Artificial Intelligence applications used in hospitals now are:
- Predictive Health Trackers – Technology that has the ability to monitor patients’ health status using real-time data collection. One such technology is the Health and Environmental Tracker (HET) which can predict if someone is about to have an asthma attack.
- Chatbots – It isn’t only retail customer service that uses chatbots to deal with consumers. Now hospitals have automated physicians that inquire and route clinicians to the right specialists.
- Predictive Analytics – Cleveland Clinics have partnered with Microsoft (Cortana) while John Hopkins has partnered up with GE in order to create Machine Learning technology that has the ability to monitor patients and prevent patient emergencies before they happen. It does this by analysing data for primary indicators of potential risks.
Cognitive Marketing – Content Marketing on Steroids
Customer experience and content marketing are terms often tossed around in the world of business and advertising these days. Why do we bring them up now, you ask? Well, things are about to be kicked into sixth gear, thanks to Cognitive Marketing. To explain what that is, let’s go back a bit: remember when Google’s DeepMind AlphaGo bested the top human player at the game? This wasn’t some computer beating a bored office clerk at the game of Solitaire. In order to achieve that victory, Google’s AI had to “actually show its cognitive capability to ‘think’ like humans, because to win the game, ‘intuition’ was needed rather than just ‘logical reasoning’.” Similar algorithm-powered AI’s are enabling machines to learn and grow on their own. Soon, they’ll reach the potential to create content for marketeers at a massive scale. Not only that, but they’ll always deliver the right content, to the right kind of audience, at just the right time.
More Ways Than One: How Retail Is Harnessing AI & ML
-
Developing Store That Don’t Need Checkout Lines
Tech companies and online retail giants such as Amazon want to create cashier-free stores, at least they are trying to. Last year Amazon launched its Amazon Go which uses sensors and hundreds of cameras to track what customers pick up and then charge the amount to an application on their smart phone, put simply. But only months into the experiment Amazon has said they need to work out some kinks in the system. As of now, Amazon Go’s system can only handle 20 or so customers at a time.
Among other issues, The Guardian, citing an unnamed source, wrote in an article, stated “…if an item has been moved from its specific spot on the shelf.” Located in Seattle, Washington, Amazon Go is now running in “beta mode” only for Amazon employees as it tests its systems. And these tests are showing that Amazon’s attempt at a cashier-free brick-and-mortar convenience store is far from ready for the real world. A Journal report stated, “For now, the technology functions flawlessly only if there are a small number of customers present, or when their movements are slow.”
-
Could Drones Be Delivering Goods to Your Home One Day?
Imagine ordering something online from, let’s say, Amazon, and it arrives at your door in 30 minutes or so via drone. Does that sound like something out of the movie The Fifth Element? Maybe, but this technology is already is already here.
Amazon Prime Air made its first delivery to a customer via a GPS-guided flying drone on December 7th, 2016. It only took 13 minutes for the drone to deliver the merchandise to the customer. This sort of technology will be a huge game changer for retail. The supply chain industry is headed for a revolution – drone delivery is coming, and retailers who want to keep up really should adopt such technologies.
Even in 2016, consumers were totally ready to accept drone delivery. The Walk Sands Future of Retail 2016 Study showed that 79 percent of US consumers said they would be “very likely” or “somewhat likely” to choose drone delivery if their product could be delivered within an hour. For me, I’d choose it just to see how cool it was. I think it would be pretty rad to have a drone land in my yard with my package, don’t you? Furthermore, other consumers stated they would pay up to $10 for a drone delivery. Lastly, 26 percent of consumers are already expecting to have their packages delivered to them in the next two years or so.
Driverless Delivery Vehicles Already Here as Well
There was a movie I watched some months ago – you most likely heard of it or even watched it. It was the latest movie about Wolverine titled Logan. There was a certain scene that never left my memory (basically because I found it awesome) where Logan and his companions were driving along a freeway full of driverless tractor trailers that had no tractor.
In an article written for pastemagazine.com, Carlos Alvarez of Getty wrote: “… Logan’s writer and director James Mangold’s inclusion of the self-driving trucking machines make it clear that the filmmaker understands the writing on the wall about the future of shipping. It’s a future without truck drivers.” He continues to explain that the movie takes place a little over 10 years from now in 2029.
“The change may well be here long before 2029. It’s only 2017, and already we’re seeing the beginnings of automated trucking taking over the industry. At the 2017 Consumer Electronics Show this January, Peloton Technology demonstrated “platooning,” where trucks are kept in a row on the highway to reduce wind resistance and save fuel. The trucks are controlled by computers on a “Level One” of autonomous driving,” Alvarez continued in his article.
Now in Germany, Mercedes-Benz is has been developing and testing their Actros truck which is fitted with a ‘highway pilot’ system, which acts like an auto-pilot and includes a radar and stereo camera system. So far, German carmaker Daimler has restricted testing on a German autobahn. The autobahn is generally safer than testing in city conditions since the curves are not as steep. Since the tests have started, this autonomous truck has already driven over 20,000 kilometres.
Did I Say Flying Taxis? Huh, Yeah I Did!
But, if you are still not amazed, then I am about to blow your socks off. Dubai has promised to build a fully autonomous public transportation system by 2030, including autonomous flying drone taxis! Now that is really something. And it isn’t a matter of when they’ll be produced and in use because they already are.
Manufactured in China by the drone-making firm EHang, these really freaking cool quad drones on steroids can carry one person weighing up to 100 kilogrammes (I weigh over that, guess I’m walking) plus maybe a backpack or suitcase. They can fly about 30 kilometres (or 19 miles), at a speed of 60 miles per hour, give or take. And, if that isn’t the cool part, you won’t need any lessons on how to fly it. Simply push a button and it flies you from point A to point B. Whether or not you have to give it directions, don’t know. Either way, this is mostly likely the coolest piece of tech out there right now.

Copyright @ CBS Interactive Inc.