Funktionsweise künstlicher neuronaler Netze
Künstliche neuronale Netze sind ein Spezialbereich des maschinellen Lernens, der sogar einen eigenen Trendbegriff hat: Deep Learning.
Doch wie funktioniert ein künstliches neuronales Netz überhaupt? Und wie wird es in Python realisiert? Dies ist Artikel 2 von 6 der Artikelserie –Einstieg in Deep Learning.
Gleich vorweg, wir beschränken uns hier auf die künstlichen neuronalen Netze des überwachten maschinellen Lernens. Dafür ist es wichtig, dass das Prinzip des Trainings und Testens von überwachten Verfahren verstanden ist. Künstliche neuronale Netze können aber auch zur unüberwachten Dimensionsreduktion und zum Clustering eingesetzt werden. Das bekannteste Verfahren ist das AE-Net (Auto Encoder Network), das hier aus der Betrachtung herausgenommen wird.
Beginnen wir mit einfach künstlichen neuronalen Netzen, die alle auf dem Perzeptron als Kernidee beruhen. Das Vorbild für künstliche neuronale Netze sind natürliche neuronale Netze, wie Sie im menschlichen Gehirn zu finden sind.
Perzeptron
Das Perzeptron (engl. Perceptron) ist ein „Klassiker“ unter den künstlichen neuronalen Netzen. Wenn von einem neuronalen Netz gesprochen wird, ist meistens ein Perzeptron oder eine Variation davon gemeint. Perzeptrons sind mehrschichtige Netze ohne Rückkopplung, mit festen Eingabe- und Ausgabeschichten. Es gibt keine absolut einheitliche Definition eines Perzeptrons, in der Regel ist es jedoch ein reines FeedForward-Netz mit einer Input-Schicht (auch Abtast-Schicht oder Retina genannt) mit statisch oder dynamisch gewichteten Verbindungen zur Ausgabe-Schicht, die (als Single-Layer-Perceptron) aus einem einzigen Neuron besteht. Das eine Neuron setzt sich aus zwei mathematischen Funktionen zusammen: Einer Berechnung der Nettoeingabe und einer Aktivierungsfunktion, die darüber entscheidet, ob die berechnete Nettoeingabe im Brutto nun “feuert” oder nicht. Es ist in seiner Ausgabe folglich binär: Man kann es sich auch als kleines Lämpchen vorstellen, so dass abhängig von den Eingabewerten und den Gewichtungen eine Nettoeingabe (Summe) bildet und eine Sprungfunktion darüber entscheidet, ob am Ende das Lämpchen leuchtet oder nicht. Dieses Konzept der Ausgabeerzeugung wird Forward-Propagation genannt.
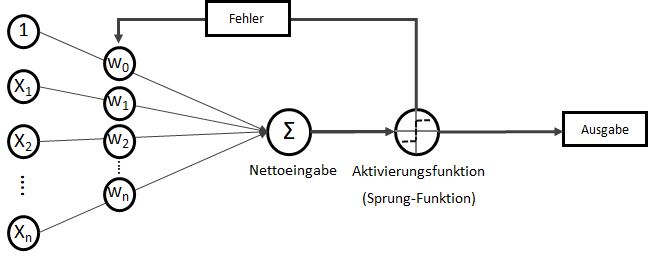
Single-Layer-Perceptron
Auch wenn “Netz” für ein einzelnes Perzeptron mit seinem einen Neuron etwas übertrieben wirken mag, ist es doch die Grundlage für viele größere und mehrschichtige Netze.
Betrachten wir nun die Mathematik der Forward-Propagation.
Wir haben eine Menge an Eingabewerten  . Wobei für
. Wobei für  als Bias-Input stets gilt:
als Bias-Input stets gilt:  . Der Bias-Input ist nur ein Platzhalter für das wichtige Bias-Gewicht.
. Der Bias-Input ist nur ein Platzhalter für das wichtige Bias-Gewicht.
![\[ x = \begin{bmatrix} x_0\\ x_1\\ x_2\\ x_3\\ \vdots\\ x_n \end{bmatrix} \]](https://data-science-blog.com/de/wp-content/ql-cache/quicklatex.com-3a7aa03dea498a7231e3e497e3e5673d_l3.png "Rendered by QuickLaTeX.com")
Für jede Eingabevariable wird eine Gewichtsvariable benötigt:

![\[ w = \begin{bmatrix} w_0\\ w_1\\ w_2\\ w_3\\ \vdots\\ w_n \end{bmatrix} \]](https://data-science-blog.com/de/wp-content/ql-cache/quicklatex.com-c70ad1733451ddc4512b23f2c739f80e_l3.png "Rendered by QuickLaTeX.com")
Jedes Produkt aus Eingabewert und Gewichtung soll in Summe die Nettoeingabe  bilden. Hier zeigt sich als lineare mathematische Funktion, die zwei-dimensional leicht als
bilden. Hier zeigt sich als lineare mathematische Funktion, die zwei-dimensional leicht als  mit
mit  als Y-Achsenschnitt wenn
als Y-Achsenschnitt wenn  .
.
![\[ z = w_0 \cdot x_0 + w_1 \cdot x_1 + \dots + w_n \cdot x_n \]](https://data-science-blog.com/de/wp-content/ql-cache/quicklatex.com-3638f2ae3b558db6c95e18057b1b9898_l3.png "Rendered by QuickLaTeX.com")
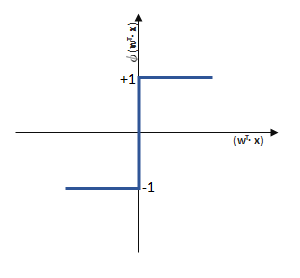
Die lineare Funktion wird nur durch die Sprungfunktion als sogenannte Aktivierungsfunktion zu einer binären Klasseneinteilung (siehe hierzu: Machine Learning – Regression vs Klassifikation), denn wenn einen festzulegenden Schwellwert  überschreitet, liefert die Sprungfunktion
überschreitet, liefert die Sprungfunktion  mit der Eingabe einen anderen Wert als wenn dieser Schwellwert nicht überschritten wird.
mit der Eingabe einen anderen Wert als wenn dieser Schwellwert nicht überschritten wird.
(1) 
Die Definition dieser Aktivierungsfunktion ist der Kern der Klassifikation und viele erweiterte künstliche neuronale Netze unterscheiden sich im Wesentlichen vom Perzeptron dadurch, dass die Aktivierungsfunktion komplexer ist, als eine reine Sprungfunktion, beispielsweise als Sigmoid-Funktion (basierend auf der logistischen Funktion) oder die Tangens hyperbolicus (tanh) -Funktion. Mehr darüber dann im nächsten Artikel dieser Artikelserie, bleiben wir also bei der einfachen Sprungfunktion.
Künstliche neuronale Netze sind im Grunde nichts anderes als viel-dimensionale, mathematische Funktionen, die durch Schaltung als Neuronen nebeneinander (Neuronen einer Schicht) und hintereinander (mehrere Schichten) eine enorme Komplexität erfassen können. Die Gewichtungen sind dabei die Stellschraube, die die Form der mathematischen Funktion gestaltet, aus Geraden und Kurven, um eine Punktwolke zu beschreiben (Regression) oder um Klassengrenzen zu identifizieren (Klassifikation).
Eine andere Sichtweise auf künstliche neuronale ist die des Filters: Ein künstliches neuronales Netz nimmt alle Eingabe-Variablen entgegen (z. B. alle Pixel eines Bildes) und über ein Training werden die Gewichtungen (die Form des Filters) so gestaltet, dass der Filter immer zu richtigen Klasse (im Kontext der Bildklassifikation: die Objektklasse) führt.
Kommen wir nochmal kurz zurück zu der Berechnung der Nettoeingabe . Da diese Schreibweise…
… recht anstrengend ist, schreiben Fortgeschrittene der linearen Algebra lieber  .
.
![\[ z = w^T \cdot x \]](https://data-science-blog.com/de/wp-content/ql-cache/quicklatex.com-fc9f71e279d7fd0095c17065743df909_l3.png "Rendered by QuickLaTeX.com")
Das hochgestellte  steht dabei für transponieren. Transponieren bedeutet, dass Spalten zu Zeilen werden – oder umgekehrt.
steht dabei für transponieren. Transponieren bedeutet, dass Spalten zu Zeilen werden – oder umgekehrt.
Beispielsweise befüllen wir zwei Vektoren  und
und  mit beispielhaften Inhalten:
mit beispielhaften Inhalten:
Eingabewerte:
![\[ x = \begin{bmatrix} 5\\ 12\\ 30\\ 2 \end{bmatrix} \]](https://data-science-blog.com/de/wp-content/ql-cache/quicklatex.com-97145f06e658d2f10086bd8c80293749_l3.png "Rendered by QuickLaTeX.com")
Gewichtungen:
![\[ w = \begin{bmatrix} 1\\ 2\\ 5\\ 12 \end{bmatrix} \]](https://data-science-blog.com/de/wp-content/ql-cache/quicklatex.com-6cd08615346cc16d7e8c23bac32c19b9_l3.png "Rendered by QuickLaTeX.com")
Kann nun die Nettoeingabe berechnet werden, denn der Gewichtungsvektor wird vom Spaltenvektor zum Zeilenvektor. So kann – mathematisch korrekt dargestellt – jedes Element des einen Vektors mit dem zugehörigen Element des anderen Vektors multipliziert werden, die dabei entstehenden Ergebniswerte werden summiert.
![\[ z = w^T \cdot x = \big[1\text{ }2\text{ }5\text{ }12\big] \cdot \begin{bmatrix} 5\\ 12\\ 30\\ 2 \end{bmatrix} = 1 \cdot 5 + 2 \cdot 12 + 5 \cdot 30 + 12 \cdot 2 = 203 \]](https://data-science-blog.com/de/wp-content/ql-cache/quicklatex.com-70a3e9e9243199e97c549d1d9b0f44c0_l3.png "Rendered by QuickLaTeX.com")
Zurück zur eigentlichen Aufgabe des künstlichen neuronalen Netzes: Klassifikation! (Regression, Clustering und Dimensionsreduktion blenden wir ja in diesem Artikel als Aufgabe aus 🙂
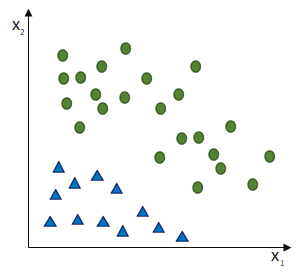
Das Perzeptron soll zwei Klassen trennen. Dafür sollen alle Eingaben richtig gewichtet werden, so dass die entstehende Nettoeingabe die Sprungfunktion dann aktiviert, wenn der Datensatz nicht für die eine, sondern für die andere Klasse ausweist.
 |
 |
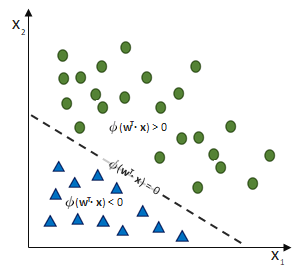 |
Da wir es mit einer linearen Funktion zutun haben, ist die Konvergenz (= Passgenauigkeit des Models mit der Realität) eines Single-Layer-Perzeptrons nur für lineare Trennbarkeit möglich!
Training des Perzeptron-Netzes
Die Aufgabe ist nun, die richtigen Gewichte zu finden – und nicht nur irgendwelche richtigen, sondern genau die optimalen. Die Frage, die sich für jedes künstliche neuronale Netz stellt, ist die nach den richtigen Gewichtungen. Das Training eines Perzeptron ist vergleichsweise einfach, gerade weil es binär ist. Denn binär bedeutet auch, dass wenn eine falsche Antwort gegeben wurde, muss das jeweils andere mögliche Ergebnis korrekt sein.
Das Training eines Perzeptrons funktioniert wie folgt:
- Setze alle Gewichtungen auf den Wert 0,00
- Mit jedem Datensatz des Trainings
- Berechne den Ausgabewert

- Vergleiche den Ausgabewert mit dem tatsächlichen Ergebnis

- Aktualisiere die Gewichtungen entgegen des Fehlers:

- Berechne den Ausgabewert
Wobei die Gewichtsanpassung  entgegen des Fehlers (bzw. hin zur jeweils anderen möglichen Antwort) geschieht:
entgegen des Fehlers (bzw. hin zur jeweils anderen möglichen Antwort) geschieht:

Anmerkung für die Experten: Die Schrittweite  blenden wir hier einfach mal aus. Bitte einfach von
blenden wir hier einfach mal aus. Bitte einfach von  ausgehen.
ausgehen.
ist die Differenz aus der Prädiktion und dem tatsächlichen Ergebnis (Klasse). Alle Gewichtungen werden mit jedem Fehler gleichzeitig aktualisiert. Sind alle Gewichtungen aktualisiert, kommt der nächste Durchlauf (erneuter Vergleich zwischen und ), nicht zu vergessen ist dabei natürlich die Abhängigkeit von den Eingabewerten x:




Training eines Perzeptrons
Das Training im überwachten Lernen basiert immer auf der Idee, den Ausgabe-Fehler (die Differenz zwischen Prädiktion und tatsächlich korrektem Ergebnis) zu betrachten und die Klassifikationslogik an den richtigen Stellschrauben (bei neuronalen Netzen sind das die Gewichtungen) entgegen des Fehlers anzupassen.
Richtige Klassifikations-Situationen können True-Positives und True-Negatives darstellen, die zu keiner Gewichtsanpassung führen sollen:
True-Positive -> Klassifikation: 1 | korrekte Klasse: 1

True-Negative-> Klassifikation: -1 | korrekte Klasse: -1

Falsche Klassifikationen erzeugen einen Fehler, der zu einer Gewichtsanpassung entgegen des Fehlers führen soll:
False-Positive -> Klassifikation: 1 | korrekte Klasse: -1

False-Negative -> Klassifikation: -1 | korrekte Klasse: 1

Imaginäres Trainingsbeispiel eines Single-Layer-Perzeptrons (SLP)
Nehmen wir an, dass  ist und das SLP irrtümlicherweise die Klasse
ist und das SLP irrtümlicherweise die Klasse  ausgewiesen hat, obwohl die korrekte Klasse
ausgewiesen hat, obwohl die korrekte Klasse  wäre. (Und die Schrittweite lassen wir bei
wäre. (Und die Schrittweite lassen wir bei  )
)
Dann passiert folgendes:

Die Gewichtung  verringert sich entsprechend
verringert sich entsprechend  und somit wird die Wahrscheinlichkeit größer, dass wenn bei der nächsten Iteration (
und somit wird die Wahrscheinlichkeit größer, dass wenn bei der nächsten Iteration ( ) wieder die Klasse +1 korrekt sei, den Schwellwert
) wieder die Klasse +1 korrekt sei, den Schwellwert  zu unterschreiten und auf eben diese korrekte Klasse zu stoßen.
zu unterschreiten und auf eben diese korrekte Klasse zu stoßen.
Die Aktualisierung der Gewichtung ist proportional zu  . So würde beispielsweise ein neues
. So würde beispielsweise ein neues  (bei Iteration
(bei Iteration  ) zu einer irrtümlichen Klassifikation
) zu einer irrtümlichen Klassifikation  (
( ) führen, würde die Entscheidungsgrenze zur korrekten Prädiktion der Klasse beim nächsten Durchlauf (
) führen, würde die Entscheidungsgrenze zur korrekten Prädiktion der Klasse beim nächsten Durchlauf ( ) an noch weiter in die gleiche Richtung verschoben werden:
) an noch weiter in die gleiche Richtung verschoben werden:

Mehr zum Training von künstlichen neuronalen Netzen ist im nächsten Artikel dieser Artikelserie zu erfahren.
Single-Layer-Perzeptrons (SLP) – Beispiel mit der boolischen Trennung
Verlassen wir nun das Training des Perzeptrons und gehen einfach mal davon aus, dass die idealen Gewichte schon gefunden wurden und schauen uns nun an, was ein Perzeptron alles (nicht) kann. Denn nicht vergessen, es soll eigentlich Klassen unterscheiden bzw. die dafür nötigen Entscheidungsgrenzen finden.
Boolische Operatoren unterscheiden Fälle nach boolischen Werten. Sie sind ein beliebtes “Hello World” für die Einarbeitung in die lineare Entscheidungslogik eines Perzeptrons. Es gibt drei grundlegende boolische Vergleichsoperatoren: AND, OR und XOR
| x1 | x2 | AND | OR | XOR |
| 0 | 0 | 0 | 0 | 0 |
| 0 | 1 | 0 | 1 | 1 |
| 1 | 0 | 0 | 1 | 1 |
| 1 | 1 | 1 | 1 | 0 |
Ein Perzeptron zur Lösung dieser Aufgabe bräuchte also zwei Dimensionen (+ Bias):  und
und 
Und es müsste Gewichtungen haben, die dafür sorgen, dass die Vorhersage entsprechend der Logik AND, OR oder XOR mit  funktioniert.
funktioniert.
Dabei ist es wichtig, dass wir auch phi als Sprungfunktion definieren. Sie könnte beispielsweise so aussehen, dass sie auf den Wert  springt, wenn z > 0 ist, ansonsten aber
springt, wenn z > 0 ist, ansonsten aber  bleibt.
bleibt.
Das Netz und die Gewichtungen (w-Setup) könnten für die AND- und die OR-Logik so aussehen:
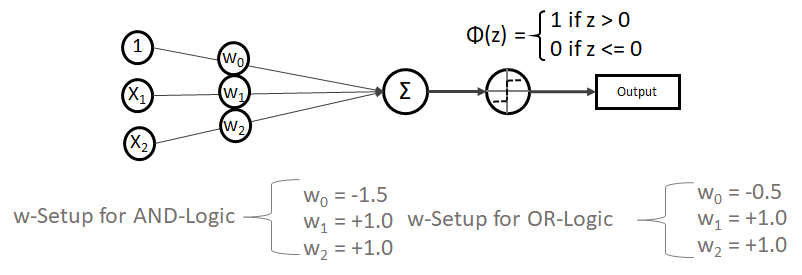
Die Gewichtungen funktionieren beim SLP problemlos, denn wir haben es mit linear trennbaren Problemen zutun:
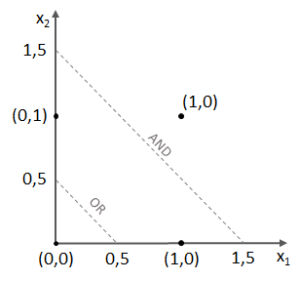
Kleiner Test gefällig? So nehmen wir uns erstmal die AND-Logik vor:
- Wenn x1 = 0 und x2 = 0 ist, gilt:
 ,
,
wie erhalten als Prädiktion
- Wenn x1 = 1 und x2 = 0 ist, gilt:
 ,
,
wie erhalten als Prädiktion
- Wenn x1 = 1 und x2 = 1 ist, gilt:
 ,
,
wie erhalten als Prädiktion
Scheint zu funktionieren!
Und dann die OR-Logik mit
- Wenn x1 = 0 und x2 = 0 ist, gilt:
 ,
,
wie erhalten als Prädiktion - Wenn x1 = 1 und x2 = 0 ist, gilt:
 ,
,
wie erhalten als Prädiktion - Wenn x1 = 1 und x2 = 1 ist, gilt:
 ,
,
wie erhalten als Prädiktion
Super! Jedoch stellt sich nun die Frage, wie das XOR-Problem zu lösen ist, denn das bedingt sowohl die Grenzen von AND als auch jene des OR-Operators.
Multi-Layer-Perzeptron (MLP) bzw. (Deep) Feed Forward (FF) Net
Denn ein XOR kann mathematisch auch so korrekt beschrieben werden: 
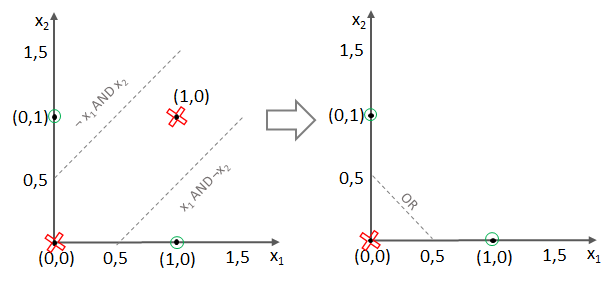
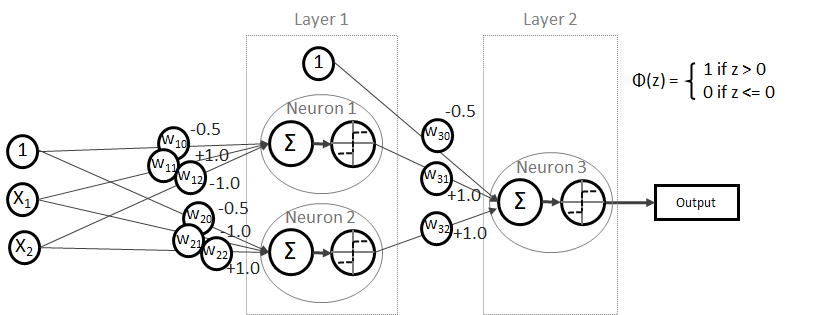
Testen wir es aus!
- Wenn x1 = 0 und x2 = 0 ist, gilt:
 und somit
und somit 
 und somit
und somit 
 und somit
und somit 
- Wenn x1 = 1 und x2 = 0 ist, gilt:
 und somit
und somit 
 und somit
und somit 
 und somit
und somit 
- Wenn x1 = 0 und x2 = 1 ist, gilt:
 und somit
und somit 
 und somit
und somit 
 und somit
und somit - Wenn x1 = 1 und x2 = 1 ist, gilt:
 und somit
und somit
 und somit
und somit
und somit
Es funktioniert!
Mehrfachklassifikation mit dem Perzeptron
Ein Perzeptron-Netz klassifiziert binär, die Ausgabe beschränkt sich auf 1 oder -1 bzw. 0 oder 1.
Jedoch wird in der Praxis oftmals eine One-vs-All (OvA) bzw. One-vs-Rest (OvR) Klassifikation implementiert. In diesem Fall steht die 1 für die Erkennung einer konkreten Klasse, während alle anderen übrigen Klassen als negativ betrachtet werden.
Um jede Klasse erkennen zu können, werden n Klassifizierer (= n Perzeptron-Netze) benötigt. Jedes Perzeptron-Netz ist auf die Erkennung einer bestimmten Klasse trainiert.
Adaline – Oder: die Limitation des Perzeptrons
Das Perzeptron wird nur über eine Sprungfunktion aktiviert. Das schränkt die Feinabstimmung des Trainings enorm ein. Besser sind Aktivierungen über stetige Funktionen, die dann nämlich differenzierbar (ableitbar) sind. Das ergibt eine konvexe Fehlerfunktion mit einem eindeutigen Minimum. Der Adaline-Algorithmus (ADAptive Linear NEuron) erweitert die Idee des Perzeptrons um genau diese Idee. Der wesentliche Fortschritt der Adaline-Regel gegenüber der des Perzeptrons ist demnach, dass die Aktualisierung der Gewichtungen nicht wie beim Perzeptron auf einer einfachen Sprungfunktion, sondern auf einer linearen, stetigen Aktivierungsfunktion beruht.
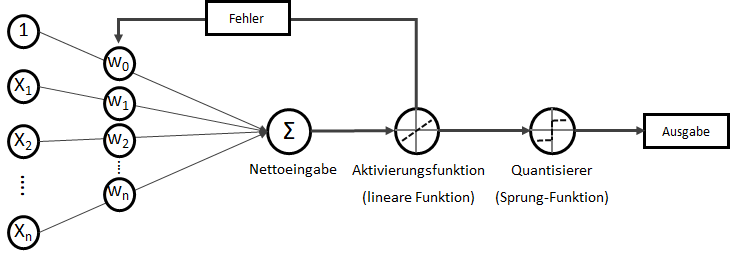
Single-Layer-Adaline
Wie ein künstliches neuronales Netz mit der Kategorie Adaline trainiert werden kann, wird im nächsten Artikel dieser Artikelserie erläutert.
Weiterführende Netz-Konzepte (CNN und RNN)
Wer bereits mit Frameworks wie TensorFlow in das Deep Learning eingestiegen ist, hat möglicherweise schon erweiterte Konzepte der künstlichen neuronalen Netze kennen gelernt. Die CNNs (Convolutional Neuronal Network) sind im Moment die Wahl für die Verarbeitung von hochdimensionalen Aufgaben, beispielsweise die Bilderkennung (Computer Vision) und Texterkennung (NLP). Das CNN erweitert die Möglichkeiten mit neuronalen Netzen deutlich, indem ein Netz zur Dimensionsreduktion vorgeschaltet wird, im Kern steckt jedoch weiterhin die Idee der MLPs. Beim Einsatz in der Bilderkennung funktionieren CNNs vereinfacht gesprochen so, dass der vorgeschaltete Netzbereich die Millionen Bildpixel sektorweise ausliest (Convolution, Faltung durch Auslesen über Sektoren, die sich gegenseitig überlappen), verdichtet (Pooling, beispielsweise über nicht-lineare Funktionen wie max()) und dann – nach diesem Prozedere – ähnlich eim MLP klassifiziert.
Eine andere erweiterte Form sind RNNs (Recurrent Neuronal Network), die ebenfalls auf der Idee des MLPs basieren, dieses Konzept jedoch dank Rückverbindungen (Neuronen senden an vorherige Schichten) und Selbstverbindungen (Neuronen senden an sich selbst) wiederum auf den Kopf stellen.
Dennoch ist es für das tiefere Verständnis von CNNs und RNNs essenziell, dass vorher das Konzept des MLPs verstanden ist. Es ist die einfachste Form der auch heute noch am meisten eingesetzten und sehr mächtigen Netz-Topologien.
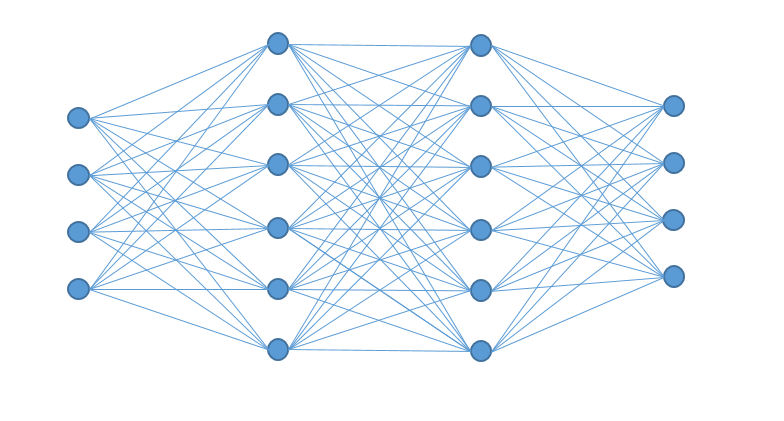
Im Jahr 2016 hatte Fjodor van Veen von asimovinstitute.org hatte – dankenswerterweise – mal eine Zusammenstellung von Netz-Topologien erstellt, auf die ich heute noch immer mal wieder einen Blick werfe:
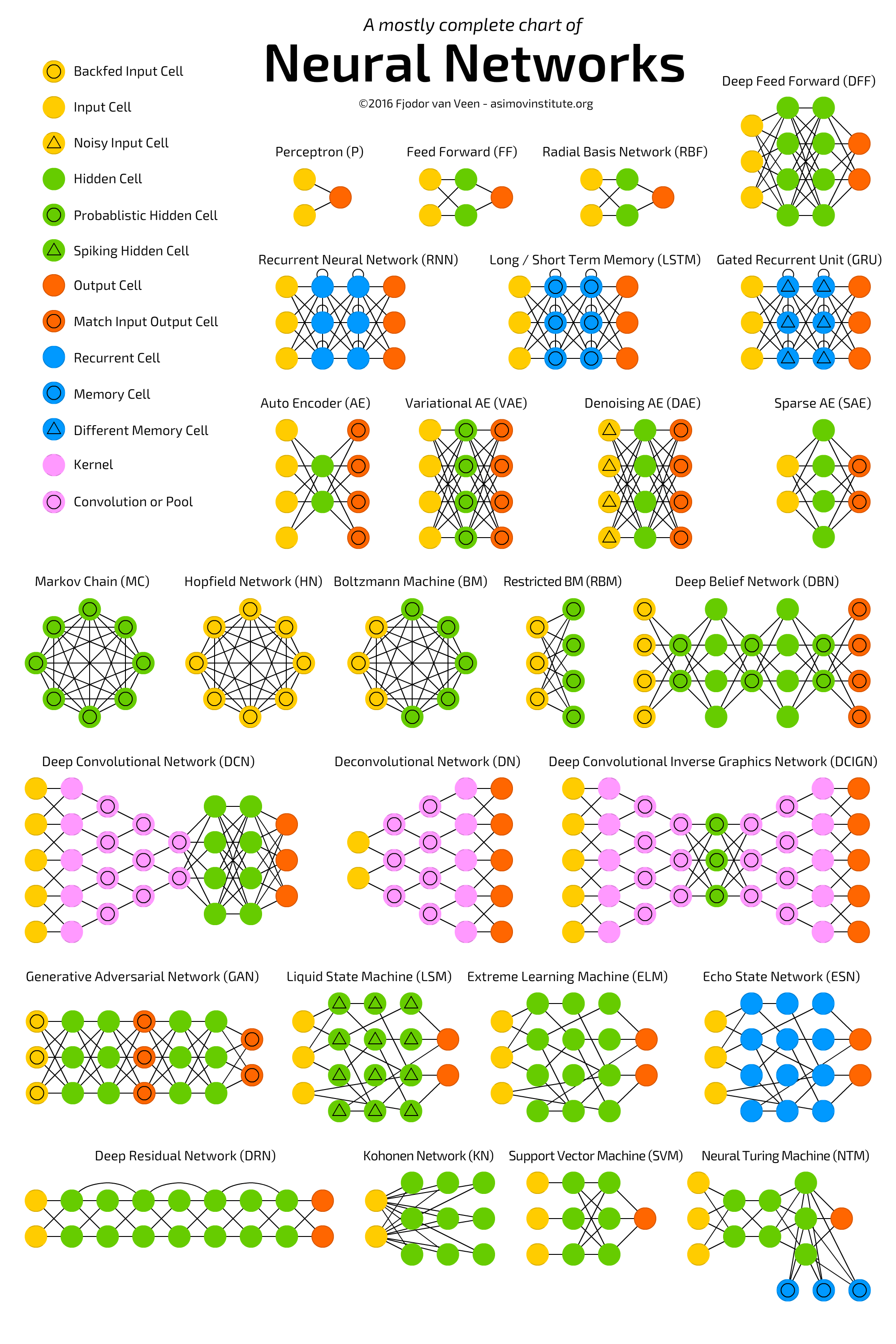
Künstliche neuronale Netze – Topologie-Übersicht von Fjodor van Veen
Buchempfehlungen
Die folgenden Bücher nutze ich für mein Selbststudium von Machine Learning und Deep Learning und sind teilweise Gedankenvorlagen auch für diesen Artikel gewesen:



 Alice Albrecht ist Research Engineer bei
Alice Albrecht ist Research Engineer bei 











 kann allgemein mit folgender Formel bestimmt werden
kann allgemein mit folgender Formel bestimmt werden  .
. aus dem Datenraum
aus dem Datenraum  , die ein Trainer dem Lernverfahren vorgibt, um Zielkonzept c zu erlernen, eine Hypothese aus dem Hypothesenraum
, die ein Trainer dem Lernverfahren vorgibt, um Zielkonzept c zu erlernen, eine Hypothese aus dem Hypothesenraum  des Lernverfahrens zu ermitteln, welche (möglichst) alle positiven Beispiel
des Lernverfahrens zu ermitteln, welche (möglichst) alle positiven Beispiel  umfasst und (möglichst) alle negativen Beispiele
umfasst und (möglichst) alle negativen Beispiele  ausschließt.
ausschließt.
 .
. und im Fall von Dummy-Encoding
und im Fall von Dummy-Encoding  neue Bool’sche Eigenschaften.
neue Bool’sche Eigenschaften. und für allgemeine endliche Eigenschaften
und für allgemeine endliche Eigenschaften . Diese Repräsentation ist sehr eingeschränkt und erlaubt es nur einzelne und keine kombinierten Konzepte zu erlernen. Sie ist daher eigentlich nur von theoretischem Interesse und wird – soweit bekannt – in keinem praktisch eingesetzten Lernverfahren genutzt.
. Diese Repräsentation ist sehr eingeschränkt und erlaubt es nur einzelne und keine kombinierten Konzepte zu erlernen. Sie ist daher eigentlich nur von theoretischem Interesse und wird – soweit bekannt – in keinem praktisch eingesetzten Lernverfahren genutzt. . Mit dieser Sprache können alle Eigenschaften zwar separat auf beliebige Teilmengen generalisiert werden, Korrelationen zwischen Eigenschaften werden jedoch nicht berücksichtigt.
. Mit dieser Sprache können alle Eigenschaften zwar separat auf beliebige Teilmengen generalisiert werden, Korrelationen zwischen Eigenschaften werden jedoch nicht berücksichtigt. . Auf beliebige endliche Eigenschaften übertragen, kann diese Aussage zu
. Auf beliebige endliche Eigenschaften übertragen, kann diese Aussage zu  verallgemeinert werden.
verallgemeinert werden.

 die ein „konsistenter Lernalgorithmus“
die ein „konsistenter Lernalgorithmus“ und einer Unsicherheit
und einer Unsicherheit  (bzw. einer Wahrscheinlichkeit von
(bzw. einer Wahrscheinlichkeit von  ) zu erlernen, abgeschätzt werden mit
) zu erlernen, abgeschätzt werden mit![\[m \geq \frac{1}{\epsilon}(ln{(|H|)} + ln{(\frac{1}{\delta})})\]](https://data-science-blog.com/de/wp-content/ql-cache/quicklatex.com-901f897bb0040e542c0eeaa14098b677_l3.png "Rendered by QuickLaTeX.com")
 Mrd. Punkten. Mit einer einfachen bool’schen Kodierung ergibt sich
Mrd. Punkten. Mit einer einfachen bool’schen Kodierung ergibt sich  und
und  .
. – wie auch immer – klassifizieren, so würden wir für den Einsatz von Naive Bayes oder unbegrenzten DecisionTrees mindestens 76.145 Datensätze benötigen. Weder die monatlichen Daten von Produkt A noch Produkt B würden ausreichen.
– wie auch immer – klassifizieren, so würden wir für den Einsatz von Naive Bayes oder unbegrenzten DecisionTrees mindestens 76.145 Datensätze benötigen. Weder die monatlichen Daten von Produkt A noch Produkt B würden ausreichen. kann etwas außerhalb des Hypothesenraums liegen, der durch das eingesetzte Lernverfahren erfasst wird. Dies bedeutet, dass wir im Hypothesenraum des Lernverfahrens nur eine Näherung
kann etwas außerhalb des Hypothesenraums liegen, der durch das eingesetzte Lernverfahren erfasst wird. Dies bedeutet, dass wir im Hypothesenraum des Lernverfahrens nur eine Näherung  erlernen können, die möglichst gut sein sollte. Solch ein – als agnostisch bezeichnetes – Lernverfahren muss daher bestrebt sein den Fehler zwischen den Trainingsdaten und dem Fehler der sich durch das Erlernen der Näherung
erlernen können, die möglichst gut sein sollte. Solch ein – als agnostisch bezeichnetes – Lernverfahren muss daher bestrebt sein den Fehler zwischen den Trainingsdaten und dem Fehler der sich durch das Erlernen der Näherung ![\[m \geq \frac{1}{2\epsilon^2}(ln{(|H|)} + ln{(\frac{2}{\delta})})\]](https://data-science-blog.com/de/wp-content/ql-cache/quicklatex.com-0630d9d4a9a075de904ef5d5610c93eb_l3.png "Rendered by QuickLaTeX.com")