“Er hätte Wirecard entlarvt!” – In der neuesten Podcast-Folge von DATENBUSINESS zeigt Benjamin Aunkofer, wie KI in der Wirtschaftsprüfung funktioniert.
Fehlbuchungen, doppelte Zahlungen, verdächtige Transaktionen – Wirtschaftsprüfer*innen sind täglich auf der Jagd nach Red Flags.
Interview-Folge über KI in der Wirtschaftsprüfung, mit Benjamin Aunkofer von AUDAVIS und DATANOMIQ.
Aber was wäre, wenn Künstliche Intelligenz diese Fehler automatisch – und vor allem sehr schnell finden könnte?
In der neuesten Podcast-Folge sprechen wir mit Benjamin Aunkofer, Gründer von AUDAVIS, über die Zukunft der Wirtschaftsprüfung und wie seine Software eine 100%ige Datenprüfung in Minuten statt Tagen ermöglicht.
𝗟𝗶𝗲𝗯𝗹𝗶𝗻𝗴𝘀𝘇𝗶𝘁𝗮𝘁 der Redaktion:
„Wir haben eine KI gebaut, die Buchhaltungsfehler findet, bevor sie jemand bemerkt – schneller als jeder Mensch es könnte.“
𝗘𝗶𝗻𝗶𝗴𝗲 𝗛𝗶𝗴𝗵𝗹𝗶𝗴𝗵𝘁𝘀:
Wie KI und Process Mining die Finanzwelt effizienter & sicherer machen.
Warum man Wirtschaftsprüfung nicht mehr nur mit Excel lösen kann.
Die spannendste Story: Warum Benjamin zwischen Berlin und Schweiz pendelt
𝗙𝘂𝗿 𝘄𝗲𝗻 𝗶𝘀𝘁 𝗱𝗶𝗲𝘀𝗲 𝗘𝗽𝗶𝘀𝗼𝗱𝗲 𝗯𝗲𝘀𝗼𝗻𝗱𝗲𝗿𝘀 𝗶𝗻𝘁𝗲𝗿𝗲𝘀𝘀𝗮𝗻𝘁?
CFOs & Wirtschaftsprüfer*innen, die sich fragen, wie KI ihre Arbeit revolutioniert.
Unternehmen, die ihre Finanzdatenqualität verbessern wollen.
Alle, die wissen wollen, wie Red Flags automatisiert entdeckt werden können.
https://data-science-blog.com/de/wp-content/uploads/sites/5/2025/03/benjamin_aunkofer_podcast_folge_audavis_.jpeg6281807Redaktionhttps://data-science-blog.com/de/wp-content/uploads/sites/5/2016/12/data-science-blog-logo-de-300x284.pngRedaktion2025-03-24 18:39:432025-03-24 19:00:51KI für die Finanzdatenprüfung – Podcastfolge
Nahezu alle Unternehmen beschäftigen sich heute mit dem Thema KI und die überwiegende Mehrheit hält es für die wichtigste Zukunftstechnologie – dennoch tun sich nach wie vor viele schwer, die ersten Schritte in Richtung Einsatz von KI zu gehen. Woran scheitern Initiativen aus Ihrer Sicht?
Zu den größten Hindernissen zählen Governance-Bedenken, etwa hinsichtlich Themen wie Sicherheit und Compliance, unklare Ziele und eine fehlende Implementierungsstrategie. Mit seinen flexiblen Bereitstellungsoptionen in der Public/Private Cloud, on-Premises oder in hybriden Umgebungen macht Exasol seine Kunden unabhängig von bestimmten Plattform- und Infrastrukturbeschränkungen, sorgt für die unkomplizierte Integration von KI-Funktionalitäten und ermöglicht Zugriff auf Datenerkenntnissen in real-time – und das, ohne den gesamten Tech-Stack austauschen zu müssen.
Dies ist der eine Teil – der technologische Teil – die Schritte, die die Unternehmen –selbst im Vorfeld gehen müssen, sind die Festlegung von klaren Zielen und KPIs und die Etablierung einer Datenkultur. Das Management sollte für Akzeptanz sorgen, indem es die Vorteile der Nutzung klar beleuchtet, Vorbehalte ernst nimmt und sie ausräumt. Der Weg zum datengetriebenen Unternehmen stellt für viele, vor allem wenn sie eher traditionell aufgestellt sind, einen echten Paradigmenwechsel dar. Führungskräfte sollten hier Orientierung bieten und klar darlegen, welche Rolle die Nutzung von Daten und der Einsatz neuer Technologien für die Zukunftsfähigkeit von Unternehmen und für jeden Einzelnen spielen. Durch eine Kultur der offenen Kommunikation werden Teams dazu ermutigt, digitale Lösungen zu finden, die sowohl ihren individuellen Anforderungen als auch den Zielen des Unternehmens entsprechen. Dazu gehört es natürlich auch, die eigenen Teams zu schulen und mit dem entsprechenden Know-how auszustatten.
Wie unterstützt Exasol die Kunden bei der Implementierung von KI?
Datenabfragen in natürlicher Sprache können, das ist spätestens seit dem Siegeszug von ChatGPT klar, generativer KI den Weg in die Unternehmen ebnen und ihnen ermöglichen, sich datengetrieben aufzustellen. Mit der Integration von Veezoo sind auch die Kunden von Exasol Espresso in der Lage, Datenabfragen in natürlicher Sprache zu stellen und KI unkompliziert in ihrem Arbeitsalltag einzusetzen. Mit dem integrierten autoML-Tool von TurinTech können Anwender zudem durch den Einsatz von ML-Modellen die Performance ihrer Abfragen direkt in ihrer Datenbank maximieren. So gelingt BI-Teams echte Datendemokratisierung und sie können mit ML-Modellen experimentieren, ohne dabei auf Support von ihren Data-Science-Teams angewiesen zu sei.
All dies trägt zur Datendemokratisierung – ein entscheidender Punkt auf dem Weg zum datengetriebenen Unternehmen, denn in der Vergangenheit scheiterte die Umsetzung einer unternehmensweiten Datenstrategie häufig an Engpässen, die durch Data Analytics oder Data Science Teams hervorgerufen werden. Espresso AI ermöglicht Unternehmen einen schnelleren und einfacheren Zugang zu Echtzeitanalysen.
Was war der Grund, Exasol Espresso mit KI-Funktionen anzureichern?
Immer mehr Unternehmen suchen nach Möglichkeiten, sowohl traditionelle als auch generative KI-Modelle und -Anwendungen zu entwickeln – das entsprechende Feedback unserer Kunden war einer der Hauptfaktoren für die Entwicklung von Espresso AI.
Ziel der Unternehmen ist es, ihre Datensilos aufzubrechen – oft haben Data Science Teams viele Jahre lang in Silos gearbeitet. Mit dem Siegeszug von GenAI durch ChatGPT hat ein deutlicher Wandel stattgefunden – KI ist greifbarer geworden, die Technologie ist zugänglicher und auch leistungsfähiger geworden und die Unternehmen suchen nach Wegen, die Technologie gewinnbringend einzusetzen.
Um sich wirklich datengetrieben aufzustellen und das volle Potenzial der eigenen Daten und der Technologien vollumfänglich auszuschöpfen, müssen KI und Data Analytics sowie Business Intelligence in Kombination gebracht werden. Espresso AI wurde dafür entwickelt, um genau das zu tun.
Und wie sieht die weitere Entwicklung aus? Welche Pläne hat Exasol?
Eines der Schlüsselelemente von Espresso AI ist das AI Lab, das es Data Scientists ermöglicht, die In-Memory-Analytics-Datenbank von Exasol nahtlos und schnell in ihr bevorzugtes Data-Science-Ökosystem zu integrieren. Es unterstützt jede beliebige Data-Science-Sprache und bietet eine umfangreiche Liste von Technologie-Integrationen, darunter PyTorch, Hugging Face, scikit-learn, TensorFlow, Ibis, Amazon Sagemaker, Azure ML oder Jupyter.
Weitere Integrationen sind ein wichtiger Teil unserer Roadmap. Während sich die ersten auf die Plattformen etablierter Anbieter konzentrierten, werden wir unser AI Lab weiter ausbauen und es werden Integrationen mit Open-Source-Tools erfolgen. Nutzer werden so in der Lage sein, eine Umgebung zu schaffen, in der sich Data Scientists wohlfühlen. Durch die Ausführung von ML-Modellen direkt in der Exasol-Datenbank können sie so die maximale Menge an Daten nutzen und das volle Potenzial ihrer Datenschätze ausschöpfen.
Über Exasol-CEO Martin Golombek
Mathias Golombek ist seit Januar 2014 Mitglied des Vorstands der Exasol AG. In seiner Rolle als Chief Technology Officer verantwortet er alle technischen Bereiche des Unternehmens, von Entwicklung, Produkt Management über Betrieb und Support bis hin zum fachlichen Consulting.
Über Exasol und Espresso AI
Sie leiden unter langsamer Business Intelligence, mangelnder Datenbank-Skalierung und weiteren Limitierungen in der Datenanalyse? Exasol bietet drei Produkte an, um Ihnen zu helfen, das Maximum aus Analytics zu holen und schnellere, tiefere und kostengünstigere Insights zu erzielen.
Kein Warten mehr auf das “Spinning Wheel”. Von Grund auf für Geschwindigkeit konzipiert, basiert Espresso auf einer einmaligen Datenbankarchitektur aus In-Memory-Caching, spaltenorientierter Datenspeicherung, “Massively Parallel Processing” (MPP), sowie Auto-Tuning. Damit können selbst die komplexesten Analysen beschleunigt und bessere Erkenntnisse in atemberaubender Geschwindigkeit geliefert werden.
https://data-science-blog.com/de/wp-content/uploads/sites/5/2024/03/Exasol_Mathias-Golombek_header-scaled.jpg11952560Redaktionhttps://data-science-blog.com/de/wp-content/uploads/sites/5/2016/12/data-science-blog-logo-de-300x284.pngRedaktion2024-03-19 08:14:592024-03-17 22:15:15Espresso AI: Q&A mit Mathias Golombek, CTO bei Exasol
Data Science und AI sind aufstrebende Arbeitsfelder, die sich mit der Gewinnung von Wissen aus Daten beschäftigen. Die Nachfrage nach Fähigkeiten im Bereich Data Science, aber auch in angrenzenden Bereichen wie Data Engineering oder Data Analytics, ist in den letzten Jahren explodiert, da Unternehmen versuchen, die Vorteile von Big Data und künstlicher Intelligenz (KI) zu nutzen. Es lohnt sich sehr, sich in diesen Bereich weiter zu entwickeln. Dafür eignen sich die Kurse von Coursera.org.
Online-Kurse lohnen sich dann, wenn eine Karriere im Bereich der Datenanalyse oder des maschinellen Lernens angestrebt oder einfach nur ihr Wissen in diesem Bereich erweitert werden soll.
Data Science hilft dabei, Entscheidungen auf Basis von Daten zu treffen, komplexe Probleme effektiver zu lösen und Karrierechancen zu verbessern. Die Tools von Google Cloud und Jupyter Notebook sind dafür geeignet, da sie eine leistungsstarke und skalierbare Infrastruktur sowie eine interaktive Entwicklungsplattform bieten.
Das Google Zertifikat für Datenanalyse behandelt neben dem Handwerkszeug für jeden Data Analyst – wie etwa SQL – auch die notwendige Datenbereinigung und Datenvisualisierung mit den Tools von Google. Es werden weder Erfahrung noch Vorkenntnisse vorausgsetzt.
Der Zertifikatskurs der erweiterten Datenanalyse von Google baut auf dem zuvorgenannten Data Analytics Kurs auf, kann jedoch auch direkt besucht werden. Hier werden grundlegende Fähigkeiten wie SQL vorausgesetzt und vertiefende Fähigkeiten vermittelt, die für einen Data Analysten nützlich sind und auch in die Data Science eintauchen.
Dieses Kursangebot zum Aufbau erweiterter Datenanalyse-Fähigkeiten von Coursera wird ebenfalls von Google angeboten. Hier werden die Tools der Datenanalyse sowie der statistischen Handwerkzeuge für Data Science eingeführt, bis hin zum ersten Einstieg in Machine Learning.
SQL ist wichtig für etablierte und angehende Data Scientists, da es eine grundlegende Technologie für die Arbeit mit Datenbanken und relationalen Datenbankmanagementsystemen ist. SQL für Data Science ermöglicht, Daten effektiv zu organisieren und schnell Abfragen zu erstellen, um Antworten auf komplexe Fragen zu finden. Es ist auch relevant für die Arbeit mit nicht-relationalen Datenbanken und hilft Data Scientists, wertvolle Erkenntnisse aus großen Datenmengen zu gewinnen.
Auch wenn Python als Skill für einen Data Scientist ganz vorne steht, ist eine Karriere als Data Scientist ohne SQL-Kenntnisse nicht vorstellbar und dieser Kurs daher der richtige, wenn Nachbolbedarf besteht.
Eine Karriere als Data Analyst ist attraktiv, da ihr eine hohe Nachfrage am Arbeitsmarkt gegenüber steht, die Arbeit vielfältig und herausfordernd ist, viele Weiterentwicklungsmöglichkeiten (z. B. zum Data Scientist) bietet und oft flexibel ist.
Der Online-Kurs von IBM bietet die Ausbildung der beruflichen Qualifikation zum Data Analyst. Ein weiterer Vorteil dieses Kurses ist, dass er für alle geeignet ist – unabhängig von ihrem Hintergrund oder der Vorbildung. Es sind keine Abschlüsse oder Vorkenntnisse erforderlich, was bedeutet, dass jeder, der sich für das Thema interessiert, am Kurs teilnehmen und von ihm profitieren kann.
Dieser Kurs bietet den Teilnehmern die Möglichkeit, ihre Kenntnisse in der Datenverarbeitung zu verbessern, eine Programmiersprache wie Python zu erlernen und grundlegende Kenntnisse in SQL zu erwerben. Diese Fähigkeiten sind für die Arbeit mit Daten unerlässlich und in der heutigen Arbeitswelt sehr gefragt. Darüber hinaus bietet der Kurs für Datenverarbeitung mit Python und SQL auch Schulungen zur Analyse und Visualisierung von Daten sowie zur Erstellung von Modellen für Maschinelles Lernen. Diese Fähigkeiten sind besonders wertvoll für die Entwicklung von Anwendungen und Systemen im Bereich der KI.
Dieser Kurs ist eine großartige Möglichkeit für alle, die ihre Kenntnisse im Bereich der Datenverarbeitung und des maschinellen Lernens verbessern möchten. Zwar werden auch hier keine Vorkenntnisse vorausgesetzt, jedoch geht der Kurs inhaltlich mehr in die Richtung Data Science als der zuvorgenannte Kurs zum Data Analyst und bietet ein umfassendes Training und Schulungen zu grundlegenden Fähigkeiten, die in der heutigen Arbeitswelt gefragt sind, und ist für jeden zugänglich, unabhängig von Hintergrund oder Erfahrung.
Das Erlernen der Grundlagen des maschinellen Lernens (Machine Learning) ist von großer Bedeutung, da es eine der am schnellsten wachsenden und wichtigsten Technologien in der heutigen Zeit ist. Maschinelles Lernen ermöglicht es Computern, aus Erfahrung zu lernen, ohne explizit programmiert zu werden. Die Teilnehmer lernen, dem Computer das lernen zu ermöglichen.
Machinelles Lernen ist der Schlüssel zur Entwicklung von Anwendungen und Systemen im Bereich der künstlichen Intelligenz (KI) und hat Anwendungen in vielen Bereichen, von der Gesundheitsversorgung und der Finanzindustrie bis hin zur Unterhaltungsbranche und der Automobilindustrie.
Der Kurs für Maschinelles Lernen ist nicht nur ein sinnvoller Einstieg in diese Materie, sondern kann darauf aufbauend mit dem Thema Deep Learning in der Qualifikation erweitert werden.
Das Verständnis von Deep Learning ist wichtig, da es eine Unterkategorie des maschinellen Lernens ist und viele noch mächtigere Anwendungen in verschiedenen Bereichen hat. Die populäre Applikation ChatGPT ist ein Produkt des Deep Learning. Deep Learning kann mit AI gleichgesetzt werden. Es ist eine gefragte Fähigkeit auf dem Arbeitsmarkt mit Job-Garantie.
Die Entscheidung für ein bestimmtes Thema eines Kurses in den Bereichen Data Analytics, Data Science und AI ist eine persönliche und abhängig von den eigenen Vorkenntnissen und Vorlieben, sowie den eigenen Karrierezielen. Für die Karriere des Data Analyst sind SQL sowie allgemeine Kenntnisse rund um Data Analytics bzw. Datenverarbeitung wichtig. Von einem Data Scientist wird ferner erwartet, die theoretischen Grundlagen sowie die praktische Anwendung von Machine Learning und Deep Learning als trainierte Fähigkeit abrufbar zu haben.
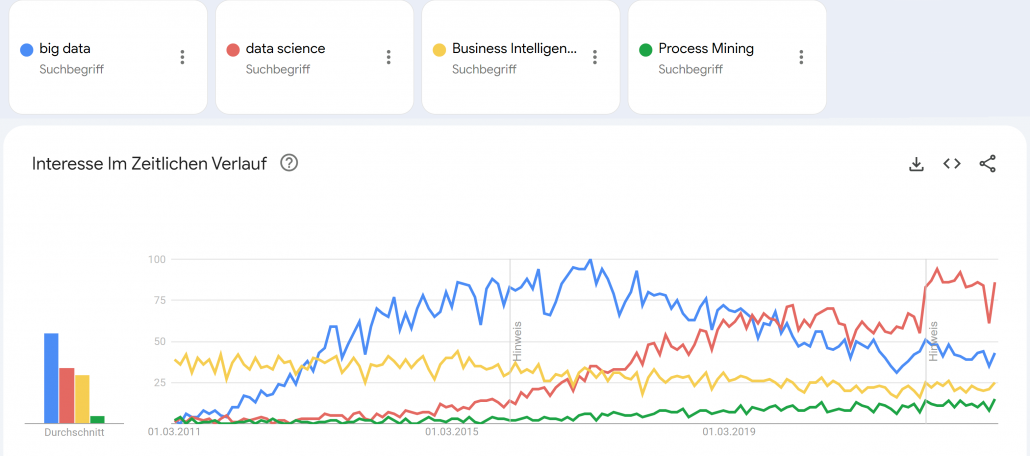
Big Data tauchte als Buzzword meiner Recherche nach erstmals um das Jahr 2011 relevant in den Medien auf. Big Data wurde zum Business-Sprech der darauffolgenden Jahre. In der Parallelwelt der ITler wurde das Tool und Ökosystem Apache Hadoop quasi mit Big Data beinahe synonym gesetzt. Der Guardian verlieh Apache Hadoop mit seinem Konzept des Distributed Computing mit MapReduce im März 2011 bei den MediaGuardian Innovation Awards die Auszeichnung “Innovator of the Year”. Im Jahr 2015 erlebte der Begriff Big Data in der allgemeinen Geschäftswelt seine Euphorie-Phase mit vielen Konferenzen und Vorträgen weltweit, die sich mit dem Thema auseinandersetzten. Dann etwa im Jahr 2018 flachte der Hype um Big Data wieder ab, die Euphorie änderte sich in eine Ernüchterung, zumindest für den deutschen Mittelstand. Die große Verarbeitung von Datenmassen fand nur in ganz bestimmten Bereichen statt, die US-amerikanischen Tech-Riesen wie Google oder Facebook hingegen wurden zu Daten-Monopolisten erklärt, denen niemand das Wasser reichen könne. Big Data wurde für viele Unternehmen der traditionellen Industrie zur Enttäuschung, zum falschen Versprechen.
Von Big Data über Data Science zu AI
Einer der Gründe, warum Big Data insbesondere nach der Euphorie wieder aus der Diskussion verschwand, war der Leitspruch “Shit in, shit out” und die Kernaussage, dass Daten in großen Mengen nicht viel wert seien, wenn die Datenqualität nicht stimme. Datenqualität hingegen, wurde zum wichtigen Faktor jeder Unternehmensbewertung, was Themen wie Reporting, Data Governance und schließlich dann das Data Engineering mehr noch anschob als die Data Science.
Google Trends – Big Data (blue), Data Science (red), Business Intelligence (yellow) und Process Mining (green). Quelle: https://trends.google.de/trends/explore?date=2011-03-01%202023-01-03&geo=DE&q=big%20data,data%20science,Business%20Intelligence,Process%20Mining&hl=de
Small Data wurde zum Fokus für die deutsche Industrie, denn “Big Data is messy!”1 und galt als nur schwer und teuer zu verarbeiten. Cloud Computing, erst mit den Infrastructure as a Service (IaaS) Angeboten von Amazon, Microsoft und Google, wurde zum Enabler für schnelle, flexible Big Data Architekturen. Zwischenzeitlich wurde die Business Intelligence mit Tools wie Qlik Sense, Tableau, Power BI und Looker (und vielen anderen) weiter im Markt ausgebaut, die recht neue Disziplin Process Mining (vor allem durch das deutsche Unicorn Celonis) etabliert und Data Science schloss als Hype nahtlos an Big Data etwa ab 2017 an, wurde dann ungefähr im Jahr 2021 von AI als Hype ersetzt. Von Data Science spricht auf Konferenzen heute kaum noch jemand und wurde hype-technisch komplett durch Machine Learning bzw. Artificial Intelligence (AI) ersetzt. AI wiederum scheint spätestens mit ChatGPT 2022/2023 eine neue Euphorie-Phase erreicht zu haben, mit noch ungewissem Ausgang.
Big Data Analytics erreicht die nötige Reife
Der Begriff Big Data war schon immer etwas schwammig und wurde von vielen Unternehmen und Experten schnell auch im Kontext kleinerer Datenmengen verwendet.2 Denn heute spielt die Definition darüber, was Big Data eigentlich genau ist, wirklich keine Rolle mehr. Alle zuvor genannten Hypes sind selbst Erben des Hypes um Big Data.
Während vor Jahren noch kleine Datenanalysen reichen mussten, können heute dank Data Lakes oder gar Data Lakehouse Architekturen, auf Apache Spark (dem quasi-Nachfolger von Hadoop) basierende Datenbank- und Analysesysteme, strukturierte Datentabellen über semi-strukturierte bis komplett unstrukturierte Daten umfassend und versioniert gespeichert, fusioniert, verknüpft und ausgewertet werden. Das funktioniert heute problemlos in der Cloud, notfalls jedoch auch in einem eigenen Rechenzentrum On-Premise. Während in der Anfangszeit Apache Spark noch selbst auf einem Hardware-Cluster aufgesetzt werden musste, kommen heute eher die managed Cloud-Varianten wie Microsoft Azure Synapse oder die agnostische Alternative Databricks zum Einsatz, die auf Spark aufbauen.
Die vollautomatisierte Analyse von textlicher Sprache, von Fotos oder Videomaterial war 2015 noch Nische, gehört heute jedoch zum Alltag hinzu. Während 2015 noch von neuen Geschäftsmodellen mit Big Data geträumt wurde, sind Data as a Service und AI as a Service heute längst Realität!
ChatGPT und GPT 4 sind King of Big Data
ChatGPT erschien Ende 2022 und war prinzipiell nichts Neues, keine neue Invention (Erfindung), jedoch eine große Innovation (Marktdurchdringung), die großes öffentliches Interesse vor allem auch deswegen erhielt, weil es als kostenloses Angebot für einen eigentlich sehr kostenintensiven Service veröffentlicht und für jeden erreichbar wurde. ChatGPT basiert auf GPT-3, die dritte Version des Generative Pre-Trained Transformer Modells. Transformer sind neuronale Netze, sie ihre Input-Parameter nicht nur zu Klasseneinschätzungen verdichten (z. B. ein Bild zeigt einen Hund, eine Katze oder eine andere Klasse), sondern wieder selbst Daten in ähnliche Gestalt und Größe erstellen. So wird aus einem gegeben Bild ein neues Bild, aus einem gegeben Text, ein neuer Text oder eine sinnvolle Ergänzung (Antwort) des Textes. GPT-3 ist jedoch noch komplizierter, basiert nicht nur auf Supervised Deep Learning, sondern auch auf Reinforcement Learning.
GPT-3 wurde mit mehr als 100 Milliarden Wörter trainiert, das parametrisierte Machine Learning Modell selbst wiegt 800 GB (quasi nur die Neuronen!)3.
ChatGPT basiert auf GPT-3.5 und wurde in 3 Schritten trainiert. Neben Supervised Learning kam auch Reinforcement Learning zum Einsatz. Quelle: openai.com
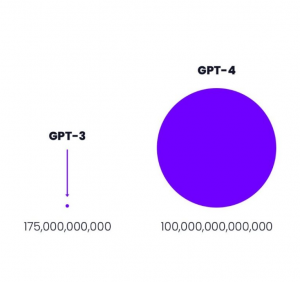
GPT-3 von openai.com war 2021 mit 175 Milliarden Parametern das weltweit größte Neuronale Netz der Welt.4
Größenvergleich: Parameteranzahl GPT-3 vs GPT-4 Quelle: openai.com
Der davor existierende Platzhirsch unter den Modellen kam von Microsoft mit “nur” 10 Milliarden Parametern und damit um den Faktor 17 kleiner. Das nun neue Modell GPT-4 ist mit 100 Billionen Parametern nochmal 570 mal so “groß” wie GPT-3. Dies bedeutet keinesfalls, dass GPT-4 entsprechend 570 mal so fähig sein wird wie GPT-3, jedoch wird der Faktor immer noch deutlich und spürbar sein und sicher eine Erweiterung der Fähigkeiten bedeuten.
Was Big Data & Analytics heute für Unternehmen erreicht
Auf Big Data basierende Systeme wie ChatGPT sollte es – der zuvor genannten Logik folgend – jedoch eigentlich gar nicht geben dürfen, denn die rohen Datenmassen, die für das Training verwendet wurden, konnten nicht im Detail auf ihre Qualität überprüft werden. Zum Einen mittelt die Masse an Daten die in ihnen zu findenden Fehler weitgehend raus, zum Anderen filtert Deep Learning selbst relevante Muster und unliebsame Ausreißer aus den Datenmassen heraus. Neuronale Netze, der Kern des Deep Learning, können durchaus als große Filter verstanden und erklärt werden.
Davon abgesehen, dass die neuen ChatBot-APIs von den Cloud-Providern Microsoft, Google und auch Amazon genutzt werden können, um Arbeitsprozesse und Kommunikation zu automatisieren, wird Big Data heute in vielen Unternehmen dazu eingesetzt, um Unternehmens-/Finanzkennzahlen auszuwerten und vorherzusagen, um Produktionsqualität zu überwachen, um Maschinen-Sensordaten mit den Geschäftsdaten aus ERP-, MES- und CRM-Systemen zu verheiraten, um operative Prozesse über mehrere IT-Systeme hinweg zu rekonstruieren und auf Schwachstellen hin zu untersuchen und um Schlussendlich auch den weiteren Datenhunger zu stillen, z. B. über Text-Extraktion aus Webseiten (Intelligence Gathering), die mit NLP und Computer Vision mächtiger wird als je zuvor.
Big Data hält sein Versprechen dank AI
Die frühere Enttäuschung aus Big Data resultierte aus dem fehlenden Vermittler zwischen Big Data (passive Daten) und den Applikationen (z. B. Industrie 4.0). Dieser Vermittler ist der aktive Part, die AI und weiterführende Datenverarbeitung (z. B. Lakehousing) und Analysemethodik (z. B. Process Mining). Davon abgesehen, dass mit AI über Big Data bereits in Medizin und im Verkehrswesen Menschenleben gerettet wurden, ist Big Data & AI längst auch in gewöhnlichen Unternehmen angekommen. Big Data hält sein Versprechen für Unternehmen doch noch ein und revolutioniert Geschäftsmodelle und Geschäftsprozesse, sichert so Wettbewerbsfähigkeit. Zumindest, wenn Unternehmen sich auf diesen Weg tatsächlich einlassen.
https://data-science-blog.com/de/wp-content/uploads/sites/5/2023/03/Fotolia_134813606_M.jpg13781378Benjamin Aunkoferhttps://data-science-blog.com/de/wp-content/uploads/sites/5/2016/12/data-science-blog-logo-de-300x284.pngBenjamin Aunkofer2023-03-14 16:31:052023-03-14 17:35:30Big Data – Das Versprechen wurde eingelöst
Das Format Business Talk am Kudamm in Berlin führte ein Interview mit Benjamin Aunkofer zu den Themen “Daten vermarkten, nicht verkaufen!”.
In dem Interview erklärt Benjamin Aunkofer, warum der Datenschutz für die meisten Anwendungsfälle keine Rolle spielt und wie Unternehmen mit Data as a Service oder AI as a Service Ihre Daten zu Geld machen, selbst dann, wenn diese Daten nicht herausgegeben werden können.
Nachfolgend das Interview auf Youtube sowie die schriftliche Form zum Nachlesen:
Nachfolgend das Transkript zum Interview:
1 – Herr Aunkofer, Daten gelten als der wichtigste Rohstoff des 22. Jahrhunderts. Bei der Vermarktung datengestützter Dienstleistung tun sich deutsche Unternehmen im Vergleich zur Konkurrenz aus den USA oder Asien aber deutlich schwerer. Woran liegt das?
Ach da will ich keinen Hehl draus machen. Die Unterschiede liegen in den verschiedenen Kulturen begründet. In den USA herrscht in der Gesellschaft ein sehr freiheitlicher Gedanke, der wohl eher darauf hinausläuft, dass wer Daten sammelt, über diese dann eben auch weitgehend verfügt.
In Asien ist die Kultur eher kollektiv ausgerichtet, um den Einzelnen geht es dort ja eher nicht so.
In Deutschland herrscht auch ein freiheitlicher Gedanke – Gott sei Dank – jedoch eher um den Schutz der personenbezogenen Daten.
Das muss nun aber gar nicht schlimm sein. Zwar mag es in Deutschland etwas umständlicher und so einen Hauch langsamer sein, Daten nutzen zu dürfen. Bei vielen Anwendungsfällen kann man jedoch sehr gut mit korrekt anonymisierten Massendaten arbeiten und bei gesellschaftsfördernen Anwendungsfällen, man denke z. B. an medizinische Vorhersagen von Diagnosen oder Behandlungserfolgen oder aber auch bei der Optimierung des öffentlichen Verkehrs, sind ja viele Menschen durchaus bereit, ihre Daten zu teilen.
Gesellschaftlichen Nutzen haben wir aber auch im B2B Geschäft, bei dem wir in Unternehmen und Institutionen die Prozesse kundenorientierter und schneller machen, Maschinen ausfallsicherer machen usw.. Da haben wir meistens sogar mit gar keinen personenbezogenen Daten zu tun.
2 – Sind die Bedenken im Zusammenhang mit Datenschutz und dem Schutz von Geschäftsgeheimnissen nicht berechtigt?
Also mit Datenschutz ist ja der gesetzliche Datenschutz gemeint, der sich nur auf personenbezogene Daten bezieht. Für Anwendungsfälle z. B. im Customer Analytics, also da, wo man Kundendaten analysieren möchte, geht das nur über die direkte Einwilligung oder eben durch anonymisierte Massendaten. Bei betrieblicher Prozessoptimierung, Anlagenoptimierung hat man mit personenbezogenen Daten aber fast nicht zu tun bzw. kann diese einfach vorher wegfiltern.
Ein ganz anderes Thema ist die Datensicherheit. Diese schließt die Sicherheit von personenbezogenen Daten mit ein, betrifft aber auch interne betriebliche Angelegenheiten, so wie etwas Lieferanten, Verträge, Preise… vielleicht Produktions- und Maschinendaten, natürlich auch Konstruktionsdaten in der Industrie.
Dieser Schutz ist jedoch einfach zu gewährleisten, wenn man einige Prinzipien der Datensicherheit verfolgt. Wir haben dafür Checklisten, quasi wie in der Luftfahrt. Bevor der Flieger abhebt, gehen wir die Checks durch… da stehen so Sachen drauf wie Passwortsicherheit, Identity Management, Zero Trust, Hybrid Cloud usw.
3 – Das Rückgrat der deutschen Wirtschaft sind die vielen hochspezialisierten KMU. Warum sollte sich beispielsweise ein Maschinenbauer darüber Gedanken machen, datengestützte Geschäftsmodelle zu entwickeln?
Nun da möchte ich dringend betonen, dass das nicht nur für Maschinenbauer gilt, aber es stimmt schon, dass Unternehmen im Maschinenbau, in der Automatisierungstechnik und natürlich der Werkzeugmaschinen richtig viel Potenzial haben, ihre Geschäftsmodelle mit Daten auszubauen oder sogar Datenbestände aufzubauen, die dann auch vermarktet werden können, und das so, dass diese Daten das Unternehmen gar nicht verlassen und dabei geheim bleiben.
4 – Daten verkaufen, ohne diese quasi zu verkaufen? Wie kann das funktionieren?
Das verrate ich gleich, aber reden wir vielleicht kurz einmal über das Verkaufen von Daten, die man sogar gerne verkauft. Das Verkaufen von Daten ist nämlich gerade so ein Trend. Das Konzept dafür heißt Data as a Service und bezieht sich dabei auf öffentliche Daten aus Quellen der Kategorie Open Data und Public Data. Diese Daten können aus dem Internet quasi gesammelt, als Datenbasis dann im Unternehmen aufgebaut werden und haben durch die Zusammenführung, Bereinigung und Aufbereitung einen Wert, der in die Millionen gehen kann. Denn andere Unternehmen brauchen vielleicht auch diese Daten, wollen aber nicht mehr warten, bis sie diese selbst aufbauen. Beispiele dafür sind Daten über den öffentlichen Verkehr, Infrastruktur, Marktpreise oder wir erheben z. B. für einen Industriekonzern Wasserqualitätsdaten beinahe weltweit aus den vielen vielen regionalen Veröffentlichungen der Daten über das Trinkwasser. Das sind zwar hohe Aufwände, aber der Wert der zusammengetragenen Daten ist ebenfalls enorm und kann an andere Unternehmen weiterverkauft werden. Und nur an jene Unternehmen, an die man das eben zu tun bereit ist.
5 – Okay, das sind öffentliche Daten, die von Unternehmen nutzbar gemacht werden. Aber wie ist es nun mit Daten aus internen Prozessen?
Interne Daten sind Geschäftsgeheimnisse und dürfen keinesfalls an Dritte weitergegeben werden. Dazu gehören beispielsweise im Handel die Umsatzkurven für bestimmte Produktkategorien sowie aber auch die Retouren und andere Muster des Kundenverhaltens, z. B. die Reaktion auf die Konfiguration von Online-Marketingkampagnen. Die Unternehmen möchten daraus jedoch Vorhersagemodelle oder auch komplexere Anomalie-Erkennung auf diese Daten trainieren, um sie für sich in ihren operativen Prozessen nutzbar zu machen. Machine Learning, übrigens ein Teilgebiet der KI (Künstlichen Intelligenz), funktioniert ja so, dass man zwei Algorithmen hat. Der erste Algorithmus ist ein Lern-Algorithmus. Diesen muss man richtig parametrisieren und überhaupt erstmal den richtigen auswählen, es gibt nämlich viele zur Auswahl und ja, die sind auch miteinander kombinierbar, um gegenseitige Schwächen auszugleichen und in eine Stärke zu verwandeln. Der Lernalgorithmus erstellt dann, über das Training mit den Daten, ein Vorhersagemodell, im Grunde eine Formel. Das ist dann der zweite Algorithmus. Dieser Algorithmus entstand aus den Daten und reflektiert auch das in den Daten eingelagerte Wissen, kanalisiert als Vorhersagemodell. Und dieses kann dann nicht nur intern genutzt werden, sondern auch anderen Unternehmen zur Nutzung zur Verfügung gestellt werden.
6 – Welche Arten von Problemen sind denn geeignet, um aus Daten ein neues Geschäftsmodell entwickeln zu können?
Alle operativen Geschäftsprozesse und deren Unterformen, also z. B. Handels-, Finanz-, Produktions- oder Logistikprozesse generieren haufenweise Daten. Das Problem für ein Unternehmen wie meines ist ja, dass wir zwar Analysemethodik kennen, aber keine Daten. Die Daten sind quasi wie der Inhalt einer Flasche oder eines Ballons, und der Inhalt bestimmt die Form mit. Unternehmen mit vielen operativen Prozessen haben genau diese Datenmengen.Ein Anwendungsfallgebiet sind z. B. Diagnosen. Das können neben medizinischen Diagnosen für Menschen auch ganz andere Diagnosen sein, z. B. über den Zustand einer Maschine, eines Prozesses oder eines ganzen Unternehmens. Die Einsatzgebiete reichen von der medizinischen Diagnose bis hin zu der Diagnose einer Prozesseffizienz oder eines Zustandes in der Wirtschaftsprüfung.Eine andere Kategorie von Anwendungsfällen sind die Prädiktionen durch Text- oder Bild-Erkennung. In der Versicherungsindustrie oder in der Immobilienbranche B. gibt es das Geschäftsmodell, dass KI-Modelle mit Dokumenten trainiert werden, so dass diese automatisiert, maschinell ausgelesen werden können. Die KI lernt dadurch, welche Textstellen im Dokument oder welche Objekte im Bild eine Rolle spielen und verwandelt diese in klare Aussagen.
Die Industrie benutzt KI zur generellen Objekterkennung z. B. in der Qualitätsprüfung. Hersteller von landwirtschaftlichen Maschinen trainieren KI, um Unkraut über auf Videobildern zu erkennen. Oder ein Algorithmus, der gelernt hat, wie Ultraschalldaten von Mirkochips zu interpretieren sind, um daraus Beschädigungen zu erkennen, so als Beispiel, den kann man weiterverkaufen.
Das Verkaufen erfolgt dabei idealerweise hinter einer technischen Wand, abgeschirmt über eine API. Eine API ist eine Schnittstelle, über die man die KI verwenden kann. Daraus wird dann AI as a Service, also KI als ein Service, den man Dritten gegen Bezahlung nutzen lassen kann.
7 – Gehen wir mal in die Praxis: Wie lassen sich aus erhobenen Daten Modelle entwickeln, die intern genutzt oder als Datenmodell an Kunden verkauft werden können?
Zuerst müssen wir die Idee natürlich richtig auseinander nehmen. Nach einer kurzen Euphorie-Phase, wie toll die Idee ist, kommt ja dann oft die Ernüchterung. Oft überwinden wir aber eben diese Ernüchterung und können starten. Der einzige Knackpunkt sind meistens fehlende Daten, denn ja, wir reden hier von großen Datenhistorien, die zum Einen überhaupt erstmal vorliegen müssen, zum anderen aber auch fast immer aufbereitet werden müssen.Wenn das erledigt ist, können wir den Algorithmus trainieren, ihn damit auf eine bestimmte Problemlösung sozusagen abrichten.Übrigens können Kunden oder Partner die KI selbst nachtrainieren, um sie für eigene besondere Zwecke besser vorzubereiten. Nehmen wir das einfache Beispiel mit der Unkrauterkennung via Bilddaten für landwirtschaftliche Maschinen. Nun sieht Unkraut in fernen Ländern sicherlich ähnlich, aber doch eben anders aus als hier in Mitteleuropa. Der Algorithmus kann jedoch nachtrainiert werden und sich der neuen Situation damit anpassen. Hierfür sind sehr viel weniger Daten nötig als es für das erstmalige Anlernen der Fall war.
8 – Viele Unternehmen haben Bedenken wegen des Zeitaufwands und der hohen Kosten für Spezialisten. Wie hoch ist denn der Zeit- und Kostenaufwand für die Implementierung solcher KI-Modelle in der Realität?
Das hängt sehr stark von der eigentlichen Aufgabenstellung ab, ob die Daten dafür bereits vorliegen oder erst noch generiert werden müssen und wie schnell das alles passieren soll. So ein Projekt dauert pauschal geschätzt gerne mal 5 bis 8 Monate bis zur ersten nutzbaren Version.
Sehen Sie die zwei anderen Video-Interviews von Benjamin Aunkofer:
Die Haufe Akademie im Gespräch mit Prof. Dr. Stephan Matzka, Hochschulprofessor an der HTW Berlin und Trainer der Haufe Akademie darüber, wie Data Science und KI verdaulich vermittelt werden können und was eigentlich passiert, wenn man es nicht tut.
Sie beschäftigen sich mit Data Science, Algorithmen und Machine Learning – Hand aufs Herz: Sind Sie ein Nerd, Herr Prof. Matzka?
Stephan Matzka: (lacht) Ich bin ein neugieriger Mensch und möchte gerne mehr über die Menschen und Dinge erfahren, die mich umgeben. Dafür benötige ich Informationen, die ich einordnen und bewerten kann und nichts anderes macht Data Science. Wenn Neugier also einen Nerd ausmacht, bin ich gerne ein Nerd.
Aber all die Buzzwords, die Sie gerade genannt haben, wie Machine Learning oder Algorithmen, blenden mehr als sie helfen. Ich spreche lieber von menschlicher und künstlicher Intelligenz. Deren Gemeinsamkeiten und Unterschiede sind gut zu erklären und dieses Verständnis ist der Schlüssel für alles Weitere.
Ist das Verständnis für Data Science und Machine Learning auch der Schlüssel für den Zukunftserfolg von Unternehmen oder wird die Businessrelevanz von Data Science überschätzt?
Stephan Matzka: Zunächst mal ist Machine Learning größtenteils einfach Statistik, die sehr clever angewandt wird. Damit wir Benutzer:innen nicht wie in der Schule mit der Hand rechnen müssen, gibt es Algorithmen, die uns die Arbeit abnehmen. Die Theorie ist also altbekannt. Aber die technischen Möglichkeiten haben sich geändert.
Sie können das mit Strom vergleichen, den gibt es schon länger. Aber erst mit einem Elektromotor können Sie Power auf die Straße bringen. Daten sind also altbekannte Rohstoffe, die Algorithmen und Rechenleistung von heute aber ein völlig neuer Motor.
Wenn Sie sehen, wie radikal die Dampfmaschine und der Elektromotor die Wirtschaft beeinflusst haben, dann gewinnen Sie einen Eindruck, was gerade im Bereich künstliche Intelligenz abgeht, und das über alle Unternehmensgrößen und Branchen hinweg.
So eine Dampfmaschine ist für viele wahrscheinlich deutlich einfacher zu greifen als das tech-lastige Universum Data Science. Das ist schon sehr abstrakt. Ist es so schwierig, wie es aussieht?
Stephan Matzka: Data Science kann man, wie alle Dinge im Leben, kompliziert oder einfach machen. Und es gibt auch auf diesem Feld Menschen, die Schwieriges einfach aussehen lassen. Das sind die Vorbilder, von denen wir alle lernen können.
Künstliche Intelligenz, oder kurz KI, bietet Menschen und Unternehmen große Chancen, wenn Sie sich rechtzeitig damit beschäftigen. Dabei geht es um nicht weniger als die Frage, ob wir in unserer Arbeitswelt zukünftig KI für uns arbeiten lassen oder abwarten, bis uns ein Algorithmus vorgibt, was wir als Nächstes tun sollen. Mit der richtigen Unterstützung ist der Aufwand jedoch überschaubar und der Nutzen für Unternehmen und Organisationen enorm.
Viele Mitarbeiter:innen hören nach „Wir sind jetzt agil“ neuerdings „Mach‘ mal KI“ – was raten Sie den Kolleg:innen und Entscheider:innen in mittelständischen Unternehmen für den Umgang mit dem Thema?
Stephan Matzka: Es braucht zum einen Impulse „von außen“, um sich mit diesem wichtigen Thema auseinanderzusetzen und einen Start zu finden. Und zum anderen braucht es Mitarbeiter:innen, die datenaffin sind, sich mit dem Thema bereits auseinandergesetzt haben und Use Cases entwickeln sowie hinterfragen können. Meine Berufserfahrung zeigt: Gerade am Anfang ist es noch sehr leicht, bei den klassischen „Low Hanging Fruits“ Erfolge zu erzielen. Das motiviert für das nächste Projekt und schon ist das Momentum im Unternehmen.
Was sind die Minimalanforderungen in einem Unternehmen, um mit Data Science und Machine Learning einen echten Mehrwert zu schaffen und die „Low Hanging Fruits“ zu ernten?
Stephan Matzka: Der Rohstoff sind Daten in digitaler Form, ob in Excel-Listen, in SAP oder einer Datenbank ist erst mal zweitrangig. Für die Auswertung brauchen Sie passende Software und Menschen, die diese Software bedienen können.
In jedem Unternehmen gibt es solche Daten, die Software ist häufig kostenlos, der eigentliche Engpass sind aktuell die Expert:innen.
Könnte ich mir nicht die Arbeit sparen und Beratungsunternehmen einsetzen?
Stephan Matzka: Das könnten Sie, und Beratungsunternehmen können Ihnen oft auch die richtigen Themen aufzeigen. Gleichzeitig wirft dies zwei wesentliche Fragen auf: Wie können Sie die Qualität und den Preis einer Lösung beurteilen, die Ihnen ein externer Dienstleister anbietet? Und zweitens, wie verankern Sie nachhaltig das Wissen in Ihrem Unternehmen?
Damit die Beratungsleistung Ihnen also wirklich weiterhilft, benötigen Sie Beurteilungskompetenz auf dem Gebiet der künstlichen Intelligenz im eigenen Unternehmen. Diese Beurteilungskompetenz im Businesskontext zu schaffen ist aus meiner Sicht ein wesentlicher Erfolgsfaktor für Unternehmen und sollte eher kurz- als mittelfristig angegangen werden.
Haufe Akademie: Nochmal zurück zu den Daten: Woher weiß ich, ob ich genug Daten habe? Sonst bilde ich jemanden aus oder stelle jemanden ein, der mich Geld kostet, aber nichts zu tun hat.
Stephan Matzka: Mit den Daten ist es ein wenig so wie mit den Finanzen, kann ich jemals „genug Budget“ im Unternehmen haben? Natürlich ist es mit großen Datenmengen leichter möglich, bessere Resultate zu erzielen, genauso wie mit mehr Projektbudget. Aber wir alle haben schon erlebt, wie kleine Projekte Erstaunliches bewegt haben und Großprojekte spektakulär gescheitert sind.
Genau wie Budgets sind Daten meist in dem Umfang vorhanden, in dem sie eben verfügbar sind. Die vorhandenen Daten klug zu nutzen: Das ist das Ziel.
Ein Beispiel aus der Praxis: Es gibt sehr große Firmen mit riesigen Datenmengen, die mir, nachdem ich bei ihnen einen Drucker gekauft habe, weiter Werbung für andere Drucker zeigen anstatt Werbung für passende Toner. So eine KI würde mir kein mittelständisches Unternehmen abnehmen.
Gleichzeitig werden Sie sich wundern, welches Wissen oft schon in einfachen Excel-Tabellen schlummert. Wissen Sie zum Beispiel, was Ihnen der höchste Umsatz eines Kunden in den letzten zwölf Monaten und die Zeitabstände der letzten drei Bestellungen schon jetzt über die nächste Bestellung verraten?
In meinen Recherchen zum Thema bin ich oft an hohen Einstiegshürden gescheitert. Trotzdem habe ich gespürt, dass das Thema wichtig ist. Das war mitunter frustrierend. Welche Fragen sollte ich mir als Mitarbeiter:in stellen, wenn ich mich für Data Science interessiere, aber keine Vorkenntnisse habe?
Stephan Matzka: Das Wichtigste ist erstmal, sich nicht abschrecken zu lassen. 80% der Themen lassen sich zum Beispiel komplett ohne Mathematik erklären. Nochmal 15% sind Stoff der Sekundarstufe, bleiben noch 5% übrig. Die haben es tatsächlich in sich und dann können Sie sich immer noch entscheiden: Finde ich das Thema so spannend (und habe ich die Zeit), dass ich mich auch da noch reinarbeite. Oder reichen mir die 95% Verständnis für die zuverlässige Lösung meiner Business-Fragestellungen aus. Viel entscheidender ist für mich, sich dem Thema mutig anzunehmen, die ersten Erfolge zu feiern und mit diesem Rückenwind die nächsten Schritte zu tun.
Vielen Dank für das Gespräch, Herr Prof. Matzka!
https://data-science-blog.com/de/wp-content/uploads/sites/5/2022/11/mehr-business-nerds-bitte-haufe-akademie-header.jpg384800Haufe Akademiehttps://data-science-blog.com/de/wp-content/uploads/sites/5/2016/12/data-science-blog-logo-de-300x284.pngHaufe Akademie2022-11-11 08:14:272022-11-09 23:14:47Interview – Mehr Business-Nerds, bitte!
Im Deep Learning gibt es unterschiedliche Trainingsmethoden. Welche wir in einem KI Projekt anwenden, hängt von den zur Verfügung gestellten Daten des Kunden ab: wieviele Daten gibt es, sind diese gelabelt oder ungelabelt? Oder gibt es sowohl gelabelte als auch ungelabelte Daten?
Nehmen wir einmal an, unser Kunde benötigt für sein Tourismusportal strukturierte, gelabelte Bilder. Die Aufgabe für unser KI Modell ist es also, zu erkennen, ob es sich um ein Bild des Schlafzimmers, Badezimmers, des Spa-Bereichs, des Restaurants etc. handelt. Sehen wir uns die möglichen Trainingsmethoden einmal an.
1. Supervised Learning
Hat unser Kunde viele Bilder und sind diese alle gelabelt, so ist das ein seltener Glücksfall. Wir können dann das Supervised Learning anwenden. Dabei lernt das KI Modell die verschiedenen Bildkategorien anhand der gelabelten Bilder. Es bekommt für das Training von uns also die Trainingsdaten mit den gewünschten Ergebnissen geliefert.
Während des Trainings sucht das Modell nach Mustern in den Bildern, die mit den gewünschten Ergebnissen zusammenpassen. So erlernt es Merkmale der Kategorien. Das Gelernte kann das Modell dann auf neue, ungesehene Daten übertragen und auf diese Weise eine Vorhersage für ungelabelte Bilder liefern, also etwa “Badezimmer 98%”.
2. Unsupervised learning
Wenn unser Kunde viele Bilder als Trainingsdaten liefern kann, diese jedoch alle nicht gelabelt sind, müssen wir auf Unsupervised Learning zurückgreifen. Das bedeutet, dass wir dem Modell nicht sagen können, was es lernen soll (die Zuordnung zu Kategorien), sondern es muss selbst Regelmäßigkeiten in den Daten finden.
Eine aktuell gängige Methode des Unsupervised Learning ist Contrastive Learning. Dabei generieren wir jeweils aus einem Bild mehrere Ausschnitte. Das Modell soll lernen, dass die Ausschnitte des selben Bildes ähnlicher zueinander sind als zu denen anderer Bilder. Oder kurz gesagt, das Modell lernt zwischen ähnlichen und unähnlichen Bildern zu unterscheiden.
Über diese Methode können wir zwar Vorhersagen erzielen, jedoch können diese niemals
die Ergebnisgüte von Supervised Learning erreichen.
3. Semi-supervised Learning
Kann uns unser Kunde eine kleine Menge an gelabelten Daten und eine große Menge an nicht gelabelten Daten zur Verfügung stellen, wenden wir Semi-supervised Learning an. Diese Datenlage begegnet uns in der Praxis tatsächlich am häufigsten. Bei fast allen KI Projekten stehen einer kleinen Menge an gelabelten Daten ein Großteil an unstrukturierten
Daten gegenüber.
Mit Semi-supervised Learning können wir beide Datensätze für das Training verwenden. Das gelingt zum Beispiel durch die Kombination von Contrastive Learning und Supervised Learning. Dabei trainieren wir ein KI Modell mit den gelabelten Daten, um Vorhersagen für Raumkategorien zu erhalten. Gleichzeitig lassen wir es Ähnlichkeiten und Unähnlichkeiten in den ungelabelten Daten erlernen und sich daraufhin selbst optimieren. Auf diese Weise können wir letztendlich auch gute Label-Vorhersagen für neue, ungesehene Bilder erzielen.
Fazit: Supervised vs. Unsupervised vs. Semi-supervised
Supervised Learning wünscht sich jeder, der mit einem KI Projekt betraut ist. In der Praxis ist das kaum anwendbar, da selten sämtliche Trainingsdaten gut strukturiert und gelabelt vorliegen.
Wenn nur unstrukturierte und ungelabelte Daten vorhanden sind, dann können wir mit Unsupervised Learning immerhin Informationen aus den Daten gewinnen, die unser Kunde so nicht hätte. Im Vergleich zu Supervised Learning ist aber die Ergebnisqualität deutlich schlechter.
Mit Semi-Supervised Learning versuchen wir das Datendilemma, also kleiner Teil gelabelte, großer Teil ungelabelte Daten, aufzulösen. Wir verwenden beide Datensätze und können gute Vorhersage-Ergebnisse erzielen, deren Qualität dem Supervised Learning oft ebenbürtig sind.
Dieser Artikel entstand in Zusammenarbeit zwischen DATANOMIQ, einem Unternehmen für Beratung und Services rund um Business Intelligence, Process Mining und Data Science. und pixolution, einem Unternehmen für AI Solutions im Bereich Computer Vision (Visuelle Bildsuche und individuelle KI Lösungen).
https://data-science-blog.com/de/wp-content/uploads/sites/5/2022/05/training-of-ai-models.jpg8002106Benjamin Aunkoferhttps://data-science-blog.com/de/wp-content/uploads/sites/5/2016/12/data-science-blog-logo-de-300x284.pngBenjamin Aunkofer2022-08-14 10:25:062022-05-20 12:25:43Alles dreht sich um Daten: die Trainingsmethoden des Deep Learning
Im ersten Teil unserer Serie „Buzzword Bingo: Data Science“ widmeten wir uns den Begriffen Künstliche Intelligenz, Algorithmen und Maschinelles Lernen, im zweiten Teil den Begriffen Big Data, Predictive Analytics und Internet of Things. Nun geht es hier im dritten und letzten Teil weiter mit der Begriffsklärung dreier weiterer Begriffe aus dem Data Science-Umfeld.
Buzzword Bingo: Data Science – Teil III: Künstliche neuronale Netze & Deep Learning
Im dritten Teil unserer dreiteiligen Reihe „Buzzword Bingo Data Science“ beschäftigen wir uns mit den Begriffen „künstliche neuronale Netze“ und „Deep Learning“.
Künstliche neuronale Netze
Künstliche neuronale Netze beschreiben eine besondere Form des überwachten maschinellen Lernens. Das Besondere hier ist, dass mit künstlichen neuronalen Netzen versucht wird, die Funktionsweise des menschlichen Gehirns nachzuahmen. Dort können biologische Nervenzellen durch elektrische Impulse von benachbarten Neuronen erregt werden. Nach bestimmten Regeln leiten Neuronen diese elektrischen Impulse dann wiederum an benachbarte Neuronen weiter. Häufig benutzte Signalwege werden dabei verstärkt, wenig benutzte Verbindungen werden gleichzeitig im Laufe der Zeit abgeschwächt. Dies wird beim Menschen üblicherweise dann als Lernen bezeichnet.
Dasselbe geschieht auch bei künstlichen neuronalen Netzen: Künstliche Neuronen werden hier hinter- und nebeneinander geschaltet. Diese Neuronen nehmen dann Informationen auf, modifizieren und verarbeiten diese nach bestimmten Regeln und geben dann Informationen wiederum an andere Neuronen ab. Üblicherweise werden bei künstlichen neuronalen Netzen mindestens drei Schichten von Neuronen unterschieden.
Die Eingabeschicht nimmt Informationen aus der Umwelt auf und speist diese in das neuronale Netz ein.
Die verborgene(n) Schichte(n) liegen zwischen der Eingabe- und der Ausgabeschicht. Hier werden wie beschrieben die eingegebenen Informationen von den einzelnen Neuronen verarbeitet und anschließend weitergegeben. Der Name „verborgene“ Schicht betont dabei, dass für Anwender meist nicht erkennbar ist, in welcher Form ein neuronales Netz die Eingabeinformationen in den verborgenen Schichten verarbeitet.
Die letzte Schicht eines neuronalen Netzes ist die Ausgabeschicht. Diese beinhaltet die Ausgabeneuronen, welche die eigentliche Entscheidung, auf die das neuronale Netz trainiert wurde, als Information ausgeben.
Das besondere an neuronalen Netzen: Wie die Neuronen die Informationen zwischen den verborgenen Schichten verarbeiten und an die nächste Schicht weitergeben, erlernt ein künstliches neuronales Netz selbstständig. Hierfür werden – einfach ausgedrückt – die verschiedenen Pfade durch ein neuronales Netz, die verschiedene Entscheidungen beinhalten, häufig hintereinander ausprobiert. Führt ein bestimmter Pfad während des Trainings des neuronalen Netzes nicht zu dem vordefinierten korrekten Ergebnis, wird dieser Pfad verändert und in dieser Form zukünftig eher nicht mehr verwendet. Führt ein Pfad stattdessen erfolgreich zu dem vordefinierten Ergebnis, dann wird dieser Pfad bestärkt. Schlussendlich kann, wie bei jedem überwachten Lernprozess, ein erfolgreich trainiertes künstliches neuronales Netz auf unbekannte Eingangsdaten angewandt werden.
Auch wenn diese Funktionsweise auf den ersten Blick nicht sehr leicht verständlich ist: Am Ende handelt es sich auch hier bloß um einen Algorithmus, dessen Ziel es ist, Muster in Daten zu erkennen. Zwei Eigenschaften teilen sich künstliche neuronale Netze aber tatsächlich mit den natürlichen Vorbildern: Sie können sich besonders gut an viele verschiedene Aufgaben anpassen, benötigen dafür aber auch meistens mehr Beispiele (Daten) und Zeit als die klassischen maschinellen Lernverfahren.
Sonderform: Deep Learning
Deep Learning ist eine besondere Form von künstlichen neuronalen Netzen. Hierbei werden viele verdeckte Schichten hintereinander verwendet, wodurch ein tiefes (also „deep“) neuronales Netz entsteht.
Je tiefer ein neuronales Netz ist, umso komplexere Zusammenhänge kann es abbilden. Aber es benötigt auch deutlich mehr Rechenleistung als ein flaches neuronales Netz. Seit einigen Jahren steht diese Leistung günstig zur Verfügung, weshalb diese Form des maschinellen Lernens an Bedeutung gewonnen hat.
https://data-science-blog.com/de/wp-content/uploads/sites/5/2022/08/buzzword_bingo_data_science_teil_III.jpg384800Julius Meierhttps://data-science-blog.com/de/wp-content/uploads/sites/5/2016/12/data-science-blog-logo-de-300x284.pngJulius Meier2022-08-14 08:58:562022-08-13 20:59:47Buzzword Bingo: Data Science – Teil III
Natural Language Understanding (NLU) ist ein Teilbereich von Computer Science, der sich damit beschäftigt natürliche Sprache, also beispielsweise Texte oder Sprachaufnahmen, verstehen und verarbeiten zu können. Das Ziel ist es, dass eine Maschine in der gleichen Weise mit Menschen kommunizieren kann, wie es Menschen untereinander bereits seit Jahrhunderten tun.
Was sind die Bereiche von NLU?
Eine neue Sprache zu erlernen ist auch für uns Menschen nicht einfach und erfordert viel Zeit und Durchhaltevermögen. Wenn eine Maschine natürliche Sprache erlernen will, ist es nicht anders. Deshalb haben sich einige Teilbereiche innerhalb des Natural Language Understandings herausgebildet, die notwendig sind, damit Sprache komplett verstanden werden kann.
Diese Unterteilungen können auch unabhängig voneinander genutzt werden, um einzelne Aufgaben zu lösen:
Speech Recognition versucht aufgezeichnete Sprache zu verstehen und in textuelle Informationen umzuwandeln. Das macht es für nachgeschaltete Algorithmen einfacher die Sprache zu verarbeiten. Speech Recognition kann jedoch auch alleinstehend genutzt werden, beispielsweise um Diktate oder Vorlesungen in Text zu verwandeln.
Part of Speech Tagging wird genutzt, um die grammatikalische Zusammensetzung eines Satzes zu erkennen und die einzelnen Satzbestandteile zu markieren.
Named Entity Recognition versucht innerhalb eines Textes Wörter und Satzbausteine zu finden, die einer vordefinierten Klasse zugeordnet werden können. So können dann zum Beispiel alle Phrasen in einem Textabschnitt markiert werden, die einen Personennamen enthalten oder eine Zeit ausdrücken.
Sentiment Analysis klassifiziert das Sentiment, also die Gefühlslage, eines Textes in verschiedene Stufen. Dadurch kann beispielsweise automatisiert erkannt werden, ob eine Produktbewertung eher positiv oder eher negativ ist.
Natural Language Generation ist eine allgemeine Gruppe von Anwendungen mithilfe derer automatisiert neue Texte generiert werden sollen, die möglichst natürlich klingen. Zum Beispiel können mithilfe von kurzen Produkttexten ganze Marketingbeschreibungen dieses Produkts erstellt werden.
Welche Algorithmen nutzt man für NLP?
Die meisten, grundlegenden Anwendungen von NLP können mit den Python Modulen spaCy und NLTK umgesetzt werden. Diese Bibliotheken bieten weitreichende Modelle zur direkten Anwendung auf einen Text, ohne vorheriges Trainieren eines eigenen Algorithmus. Mit diesen Modulen ist ohne weiteres ein Part of Speech Tagging oder Named Entity Recognition in verschiedenen Sprachen möglich.
Der Hauptunterschied zwischen diesen beiden Bibliotheken ist die Ausrichtung. NLTK ist vor allem für Entwickler gedacht, die eine funktionierende Applikation mit Natural Language Processing Modulen erstellen wollen und dabei auf Performance und Interkompatibilität angewiesen sind. SpaCy hingegen versucht immer Funktionen bereitzustellen, die auf dem neuesten Stand der Literatur sind und macht dabei möglicherweise Einbußen bei der Performance.
Für umfangreichere und komplexere Anwendungen reichen jedoch diese Optionen nicht mehr aus, beispielsweise wenn man eine eigene Sentiment Analyse erstellen will. Je nach Anwendungsfall sind dafür noch allgemeine Machine Learning Modelle ausreichend, wie beispielsweise ein Convolutional Neural Network (CNN). Mithilfe von Tokenizern von spaCy oder NLTK können die einzelnen in Wörter in Zahlen umgewandelt werden, mit denen wiederum das CNN als Input arbeiten kann. Auf heutigen Computern sind solche Modelle mit kleinen Neuronalen Netzwerken noch schnell trainierbar und deren Einsatz sollte deshalb immer erst geprüft und möglicherweise auch getestet werden.
Jedoch gibt es auch Fälle in denen sogenannte Transformer Modelle benötigt werden, die im Bereich des Natural Language Processing aktuell state-of-the-art sind. Sie können inhaltliche Zusammenhänge in Texten besonders gut mit in die Aufgabe einbeziehen und liefern daher bessere Ergebnisse beispielsweise bei der Machine Translation oder bei Natural Language Generation. Jedoch sind diese Modelle sehr rechenintensiv und führen zu einer sehr langen Rechenzeit auf normalen Computern.
Was sind Transformer Modelle?
In der heutigen Machine Learning Literatur führt kein Weg mehr an Transformer Modellen aus dem Paper „Attention is all you need“ (Vaswani et al. (2017)) vorbei. Speziell im Bereich des Natural Language Processing sind die darin erstmals beschriebenen Transformer Modelle nicht mehr wegzudenken.
Transformer werden aktuell vor allem für Übersetzungsaufgaben genutzt, wie beispielsweise auch bei www.deepl.com. Darüber hinaus sind diese Modelle auch für weitere Anwendungsfälle innerhalb des Natural Language Understandings geeignet, wie bspw. das Beantworten von Fragen, Textzusammenfassung oder das Klassifizieren von Texten. Das GPT-2 Modell ist eine Implementierung von Transformern, dessen Anwendungen und die Ergebnisse man hier ausprobieren kann.
Was macht den Transformer so viel besser?
Soweit wir wissen, ist der Transformer jedoch das erste Transduktionsmodell, das sich ausschließlich auf die Selbstaufmerksamkeit (im Englischen: Self-Attention) stützt, um Repräsentationen seiner Eingabe und Ausgabe zu berechnen, ohne sequenzorientierte RNNs oder Faltung (im Englischen Convolution) zu verwenden.
Übersetzt aus dem englischen Originaltext: Attention is all you need (Vaswani et al. (2017)).
In verständlichem Deutsch bedeutet dies, dass das Transformer Modell die sogenannte Self-Attention nutzt, um für jedes Wort innerhalb eines Satzes die Beziehung zu den anderen Wörtern im gleichen Satz herauszufinden. Dafür müssen nicht, wie bisher, Recurrent Neural Networks oder Convolutional Neural Networks zum Einsatz kommen.
Was dieser Mechanismus konkret bewirkt und warum er so viel besser ist, als die vorherigen Ansätze wird im folgenden Beispiel deutlich. Dazu soll der folgende deutsche Satz mithilfe von Machine Learning ins Englische übersetzt werden:
„Das Mädchen hat das Auto nicht gesehen, weil es zu müde war.“
Für einen Computer ist diese Aufgabe leider nicht so einfach, wie für uns Menschen. Die Schwierigkeit an diesem Satz ist das kleine Wort „es“, dass theoretisch für das Mädchen oder das Auto stehen könnte. Aus dem Kontext wird jedoch deutlich, dass das Mädchen gemeint ist. Und hier ist der Knackpunkt: der Kontext. Wie programmieren wir einen Algorithmus, der den Kontext einer Sequenz versteht?
Vor Veröffentlichung des Papers „Attention is all you need“ waren sogenannte Recurrent Neural Networks die state-of-the-art Technologie für solche Fragestellungen. Diese Netzwerke verarbeiten Wort für Wort eines Satzes. Bis man also bei dem Wort „es“ angekommen ist, müssen erst alle vorherigen Wörter verarbeitet worden sein. Dies führt dazu, dass nur noch wenig Information des Wortes „Mädchen“ im Netzwerk vorhanden sind bis den Algorithmus überhaupt bei dem Wort „es“ angekommen ist. Die vorhergegangenen Worte „weil“ und „gesehen“ sind zu diesem Zeitpunkt noch deutlich stärker im Bewusstsein des Algorithmus. Es besteht also das Problem, dass Abhängigkeiten innerhalb eines Satzes verloren gehen, wenn sie sehr weit auseinander liegen.
Was machen Transformer Modelle anders? Diese Algorithmen prozessieren den kompletten Satz gleichzeitig und gehen nicht Wort für Wort vor. Sobald der Algorithmus das Wort „es“ in unserem Beispiel übersetzen will, wird zuerst die sogenannte Self-Attention Layer durchlaufen. Diese hilft dem Programm andere Wörter innerhalb des Satzes zu erkennen, die helfen könnten das Wort „es“ zu übersetzen. In unserem Beispiel werden die meisten Wörter innerhalb des Satzes einen niedrigen Wert für die Attention haben und das Wort Mädchen einen hohen Wert. Dadurch ist der Kontext des Satzes bei der Übersetzung erhalten geblieben.
https://data-science-blog.com/de/wp-content/uploads/sites/5/2022/05/natural-language-understanding.png8051917Niklas Langhttps://data-science-blog.com/de/wp-content/uploads/sites/5/2016/12/data-science-blog-logo-de-300x284.pngNiklas Lang2022-06-03 08:12:552022-05-03 21:35:36Wie Maschinen uns verstehen: Natural Language Understanding
Sie wollen in Ihrem Unternehmen Kosten senken und effizientere Workflows einführen? Dann haben Sie vielleicht schon darüber nachgedacht, Prozesse mit Künstlicher Intelligenz zu automatisieren. Für einen gelungenen Start, besprechen wir nun, wie ein KI-Projekt abläuft und wie man es richtig umsetzt.
Wir von DATANOMIQ und pixolution teilen unsere Erfahrungen aus Deep Learning Projekten, wo es vor allem um die Optimierung und Automatisierung von Unternehmensprozessen rund um visuelle Daten geht, etwa Bilder oder Videos. Wir stellen Ihnen die einzelnen Projektschritte vor, verraten Ihnen, wo dabei die Knackpunkte liegen und wie alle Beteiligten dazu beitragen können, ein KI-Projekt zum Erfolg zu führen.
1. Erstgespräch
In einem Erstgespräch nehmen wir Ihre Anforderungen auf.
Bestandsaufnahme Ihrer aktuellen Prozesse und Ihrer Änderungswünsche: Wie sind Ihre aktuellen Prozesse strukturiert? An welchen Prozessen möchten Sie etwas ändern?
Zielformulierung: Welches Endergebnis wünschen Sie sich? Wie genau sollen die neuen Prozesse aussehen? Das Ziel sollte so detailliert wie möglich beschrieben werden.
Budget: Welches Budget haben Sie für dieses Projekt eingeplant? Zusammen mit dem formulierten Ziel gibt das Budget die Wege vor, die wir zusammen in dem Projekt gehen können. Meist wollen Sie durch die Einführung von KI Kosten sparen oder höhere Umsätze erreichen. Das spielt für Höhe des Budgets die entscheidende Rolle.
Datenlage: Haben Sie Daten, die wir für das Training verwenden können? Wenn ja, welche und wieviele Daten sind das? Ist eine kontinuierliche Datenerfassung vorhanden, die während des Projekts genutzt werden kann, oder muss dafür erst die Grundlage geschaffen werden?
2. Evaluation
In diesem Schritt evaluieren und planen wir mit Ihnen gemeinsam die Umsetzung des Projekts. Das bedeutet im Einzelnen folgendes.
Begutachtung der Daten und weitere Datenplanung
Wir sichten von Ihnen bereitgestellte Trainingsdaten, z.B. gelabelte Bilder, und machen uns ein Bild davon, ob diese für das Training sinnvoll verwendet werden können. Da man für Deep Learning sehr viele Trainingsdaten benötigt, ist das ein entscheidender Punkt. In die Begutachtung der Daten fließt auch die Beurteilung der Qualität und Ausgewogenheit ein, denn davon ist abhängig wie gut ein KI-Modell lernt und korrekte Vorhersagen trifft.
Wenn von Ihnen keinerlei Daten zum Projektstart bereitgestellt werden können, wird zuerst ein separates Projekt notwendig, das nur dazu dient, Daten zu sammeln. Das bedeutet für Sie etwa je nach Anwendbarkeit den Einkauf von Datensets oder Labeling-Dienstleistungen.
Wir stehen Ihnen dabei beratend zur Seite.
Während der gesamten Dauer des Projekts werden immer wieder neue Daten benötigt, um die Qualität des Modells weiter zu verbessern. Daher müssen wir mit Ihnen gemeinsam planen, wie Sie fortlaufend diese Daten erheben, falsche Predictions des Modells erkennen und korrigieren, sodass Sie diese uns bereitstellen können. Die richtig erkannten Daten sowie die falsch erkannten und dann korrigierten Daten werden nämlich in das nächste Training einfließen.
Definition des Minimum Viable Product (MVP)
Wir definieren mit Ihnen zusammen, wie eine minimal funktionsfähige Version der KI aussehen kann. Die Grundfrage hierbei ist: Welche Komponenten oder Features sollten als Erstes in den Produktivbetrieb gehen, sodass Sie möglichst schnell einen Mehrwert aus
der KI ziehen?
Ein Vorteil dieser Herangehensweise ist, dass Sie den neuen KI-basierten Prozess in kleinem Maßstab testen können. Gleichzeitig können wir Verbesserungen schneller identifizieren. Zu einem späteren Zeitpunkt können Sie dann skalieren und weitere Features aufnehmen. Die schlagenden Argumente, mit einem MVP zu starten, sind jedoch die Kostenreduktion und Risikominimierung. Anstatt ein riesiges Projekt umzusetzen wird ein kleines Mehrwert schaffendes Projekt geschnürt und in der Realität getestet. So werden Fehlplanungen und
-entwicklungen vermieden, die viel Geld kosten.
Definition der Key Performance Indicators (KPI)
Key Performance Indicators sind für die objektive Qualitätsmessung der KI und des Business Impacts wichtig. Diese Zielmarken definieren, was das geplante System leisten soll, damit es erfolgreich ist. Key Performance Indicators können etwa sein:
Durchschnittliche Zeitersparnis des Prozesses durch Teilautomatisierung
Garantierte Antwortzeit bei maximalem Anfrageaufkommen pro Sekunde
Parallel mögliche Anfragen an die KI
Accuracy des Modells
Zeit von Fertigstellung bis zur Implementierung des KI Modells
Planung in Ihr Produktivsystem
Wir planen mit Ihnen die tiefe Integration in Ihr Produktivsystem. Dabei sind etwa folgende Fragen wichtig: Wie soll die KI in der bestehenden Softwareumgebung und im Arbeitsablauf genutzt werden? Was ist notwendig, um auf die KI zuzugreifen?
Mit dem Erstgespräch und der Evaluation ist nun das Fundament für das Projekt gelegt. In den Folgeschritten treiben wir die Entwicklung nun immer weiter voran. Die Schritte 3 bis 5 werden dabei solange wiederholt bis wir von der minimal funktionsfähigen
Produktversion, dem MVP, bis zum gewünschten Endprodukt gelangt sind.
3. Iteration
Wir trainieren den Algorithmus mit dem Großteil der verfügbaren Daten. Anschließend überprüfen wir die Performance des Modells mit ungesehenen Daten.
Wie lange das Training dauert ist abhängig von der Aufgabe. Man kann jedoch sagen, dass das Trainieren eines Deep Learning Modells für Bilder oder Videos komplexer und zeitaufwändiger ist als bei textbasierten maschinellen Lernaufgaben. Das liegt daran, dass wir tiefe Modelle (mit vielen Layern) verwenden und die verarbeiteten Datenmengen in der Regel sehr groß sind.
Das Trainieren des Modells ist je nach Projekt jedoch nur ein Bruchstück des ganzen Entwicklungsprozesses, den wir leisten. Oft ist es notwendig, dass wir einen eigenen Prozess aufbauen, in den das Modell eingebettet werden kann, wie z.B. einen Webservice.
4. Integration
Ist eine akzeptable Qualitätsstufe des Modells nach dem Training erreicht, liefern wir Ihnen eine erste Produktversion aus. Üblicherweise stellen wir Ihnen die Version als Docker Image mit API zur Verfügung. Sie beginnen dann mit der Integration in Ihr System und Ihre Workflows. Wir begleiten Sie dabei.
5. Feedback erfassen
Nachdem die Integration in den Produktivbetrieb erfolgt ist, ist es sehr wichtig, dass Sie aus der Nutzung Daten sammeln. Nur so können Sie beurteilen, ob die KI funktioniert wie Sie es sich vorgestellt haben und ob es in die richtige Richtung geht. Es geht also darum, zu erfassen was das Modell im Realbetrieb kann und was nicht. Diese Daten sammeln Sie und übermitteln sie an uns. Wir speisen diese dann in nächsten Trainingslauf ein.
Es ist dabei nicht ungewöhnlich, dass diese Datenerfassung im Realbetrieb eine gewisse Zeit in Anspruch nimmt. Das ist natürlich davon abhängig, in welchem Umfang Sie Daten erfassen. Bis zum Beginn der nächsten Iteration können so üblicherweise Wochen oder sogar Monate vergehen.
Die nächste Iteration
Um mit der nächsten Iteration eine signifikante Steigerung der Ergebnisqualität zu erreichen, kann es notwendig sein, dass Sie uns mehr Daten oder andere Daten zur Verfügung stellen, die aus dem Realbetrieb anfallen.
Eine nächste Iteration kann aber auch motiviert sein durch eine Veränderung in den Anforderungen, wenn etwa bei einem Klassifikationsmodell neue Kategorien erkannt werden müssen. Das aktuelle Modell kann für solche Veränderungen dann keine guten Vorhersagen treffen und muss erst mit entsprechenden neuen Daten trainiert werden.
Tipps für ein erfolgreiches KI Projekt
Ein entscheidender Knackpunkt für ein erfolgreiches KI Projekt ist das iterative Vorgehen und schrittweise Einführen eines KI-basierten Prozesses, mit dem die Qualität und Funktionsbreite der Entwicklung gesteigert wird.
Weiterhin muss man sich darüber klar sein, dass die Bereitstellung von Trainingsdaten kein statischer Ablauf ist. Es ist ein Kreislauf, in dem Sie als Kunde eine entscheidende Rolle einnehmen. Ein letzter wichtiger Punkt ist die Messbarkeit des Projekts. Denn nur wenn die Zielwerte während des Projekts gemessen werden, können Rückschritte oder Fortschritte gesehen werden und man kann schließlich am Ziel ankommen.
Möglich wurde dieser Artikel durch die großartige Zusammenarbeit mit pixolution, einem Unternehmen für AI Solutions im Bereich Computer Vision (Visuelle Bildsuche und individuelle KI Lösungen).
https://data-science-blog.com/de/wp-content/uploads/sites/5/2022/05/training-of-ai-models.jpg8002106Benjamin Aunkoferhttps://data-science-blog.com/de/wp-content/uploads/sites/5/2016/12/data-science-blog-logo-de-300x284.pngBenjamin Aunkofer2022-03-30 07:17:432022-05-20 11:12:32Ein KI Projekt richtig umsetzen : So geht’s


 Über Exasol-CEO Martin Golombek
Über Exasol-CEO Martin Golombek