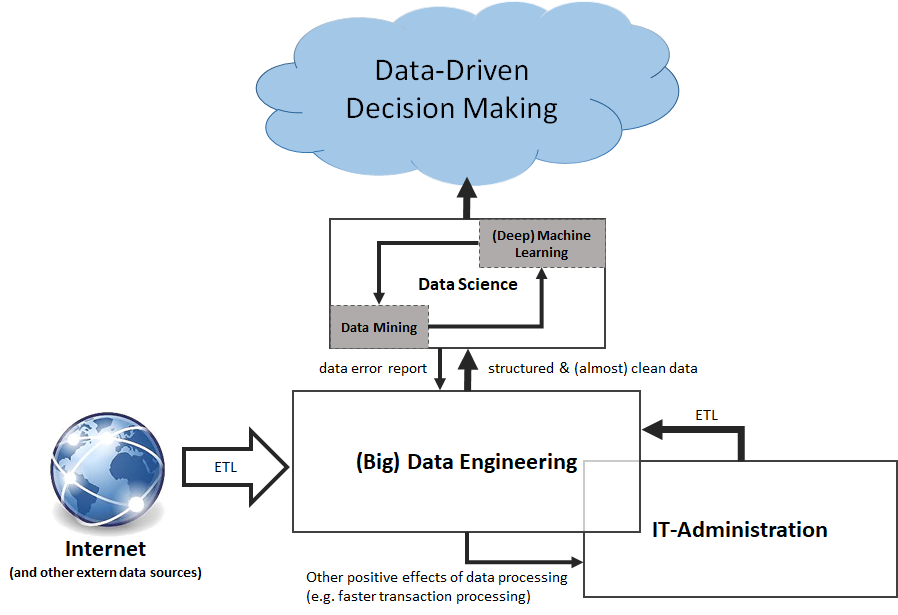
Die Digitalisierung ist in Deutschland bereits seit Jahrzehnten am Voranschreiten. Im Gegensatz zum verbreiteten Glauben, dass die Digitalisierung erst mit der Innovation der Smartphones ihren Anfang fand, war der erste Schritt bereits die Einführung von ERP-Systemen. Sicherlich gibt es hier noch einiges zu tun, jedoch hat die Digitalisierung meines Erachtens nach das Plateau der Produktivität schon bald erreicht – Ganz im Gegensatz zur Datennutzung!
Die Digitalisierung erzeugt eine exponentiell anwachsende Menge an Daten, die ein hohes Potenzial an neuen Erkenntnissen für Medizin, Biologie, Agrawirtschaft, Verkehrswesen und die Geschäftswelt bedeuten. Es mag hier und da an Fachexperten fehlen, die wissen, wie mit großen und heterogenen Daten zu hantieren ist und wie sie zu analysieren sind. Das Aufleben dieser Experenberufe und auch neue Studengänge sorgen jedoch dafür, dass dem Mangel ein gewisser Nachwuchs entgegen steht.
Doch wie sieht es mit Führungskräften aus? Müssen Entscheider verstehen, was ein Data Engineer oder ein Data Scientist tut, wie seine Methoden funktionieren und an welche Grenzen eingesetzte Software stößt?
Datenanalytische Denkweise ist ein strategisches Gut
Als Führungskraft müssen Sie unternehmerisch denken und handeln. Wenn Sie eine neue geschäftliche Herausforderung erfolgreich bewältigen möchten, müssen Sie selbst Ideen entwickeln – oder diese zumindest bewerten – können, wie in Daten Antworten für eine Lösung gefunden werden können. Die meisten Führungskräfte reden sich erfahrungsgemäß damit heraus, dass sie selbst keine höheren Datenanalysen durchführen müssen. Unternehmen werden gegenwärtig bereits von Datenanalysten vorangetrieben und für die nahe Zukunft besteht kein Zweifel an der zunehmenden Bedeutung von Datenexperten für die Entscheidungsfindung nicht nur auf der operativen Ebene, bei der Dateningenieure sehr viele Entscheidungen automatisieren werden, sondern auch auf der strategischen Ebene.
Sie müssen kein Data Scientist sein, aber Grundkenntnisse sind der Schlüssel zum Erfolg
Hinter den Begriffen Big Data und Advanced Analytics – teilweise verhasste Buzzwords – stecken reale Methoden und Technologien, die eine Führungskraft richtig einordnen können muss, um über Projekte und Invesitionen entscheiden zu können. Zumindest müssen Manager ihre Mitarbeiter kennen und deren Rollen und Fähigkeiten verstehen, dabei dürfen sie sich keinesfalls auf andere verlassen. Übrigens wissen auch viele Recruiter nicht, wen genau sie eigentlich suchen!
Stark vereinfacht betrachtet, dreht sich dabei alles um Analysemethodik, Datenbanken und Programmiersprachen. Selbst unabhängig vom aktuellen Analytcs-Trend, fördert eine Einarbeitung in diese Themenfelder das logische denken und kann auch sehr viel Spaß machen. Als positiven Nebeneffekt werden Sie eine noch unternehmerischere und kreativere Denkweise entwickeln!
Datenaffinität ist ein Karriere-Turbo!
Nicht nur der Bedarf an Fachexperten für Data Science und Data Engineering steigt, sondern auch der Bedarf an Führungskräften bzw. Manager. Sicherlich ist der Bedarf an Führungskräften quantitativ stets geringer als der für Fachexperten, immerhin braucht jedes Team nur eine Führung, jedoch wird hier oft vergessen, dass insbesondere Data Science kein Selbstzweck ist, sondern für alle Fachbereiche (mit unterschiedlicher Priorisierung) Dienste leisten kann. Daten-Projekte scheitern entweder am Fehlen der datenaffinen Fachkräfte oder am Fehlen von datenaffinen Führungskräften in den Fachabteilungen. Unverständnisvolle Fachbereiche tendieren schnell zur Verweigerung der Mitwirkung – bis hin zur klaren Arbeitsverweigerung – auf Grund fehlender Expertise bei Führungspersonen.
Andersrum betrachtet, werden Sie als Führungskraft Ihren Marktwert deutlich steigern, wenn Sie ein oder zwei erfolgreiche Projekte in Ihr Portfolio aufnehmen können, die im engen Bezug zur Datennutzung stehen.
Mit einem Data Science Team: Immer einen Schritt voraus!
Führungskräfte, die zukünftige Herausforderungen meistern möchten, müssen selbst zwar nicht Data Scientist werden, jedoch dazu in der Lage sein, ein kleines Data Science Team führen zu können. Möglicherweise handelt es sich dabei nicht direkt um Ihr Team, vielleicht ist es jedoch Ihre Aufgabe, das Team durch Ihren Fachbereich zu leiten. Data Science Teams können zwar auch direkt in einer Fachabteilung angesiedelt sein, sind häufig jedoch zentrale Stabstellen.
Müssen Sie ein solches Team für Ihren Fachbereich begleiten, ist es selbstverständlich notwendig, dass sie sich über gängige Verfahren der Datenanalyse, also auch der Statistik, und der maschinellen Lernverfahren ein genaueres Bild machen. Erkennen Data Scientists, dass Sie sich als Führungskraft mit den Verfahren auseinander gesetzt haben, die wichtigsten Prozeduren, deren Anforderungen und potenziellen Ergebnisse kennen oder einschätzen können, werden Sie mit entsprechendem Respekt belohnt und Ihre Data Scientists werden Ihnen gute Berater sein, wie sie Ihre unternehmerischen Ziele mit Daten erreichen werden.
Buchempfehlung:


Data Science für Unternehmen: Data Mining und datenanalytisches Denken praktisch anwenden (mitp Business)
Lesetipps: