Dieser Artikel ist der Auftakt in einer Artikelserie zum Thema “Geodatenanalyse”.
Von den vielen Arten an Datensätzen, die öffentlich im Internet verfügbar sind, bin ich in letzter Zeit vermehrt über eine besonders interessante Gruppe gestolpert, die sich gleich für mehrere Zwecke nutzen lassen: Geodaten.
Gerade in wirtschaftlicher Hinsicht bieten sich eine ganze Reihe von Anwendungsfällen, bei denen Geodaten helfen können, Einblicke in Tatsachen zu erlangen, die ohne nicht möglich wären. Der wohl bekannteste Fall hierfür ist vermutlich die einfache Navigation zwischen zwei Punkten, die jeder kennt, der bereits ein Navigationssystem genutzt oder sich eine Route von Google Maps berechnen lassen hat.
Hiermit können nicht nur Fragen nach dem schnellsten oder Energie einsparensten (und damit gleichermaßen auch witschaftlichsten) Weg z. B. von Berlin nach Hamburg beantwortet werden, sondern auch die bestmögliche Lösung für Ausnahmesituationen wie Stau oder Vollsperrungen berechnet werden (ja, Stau ist, zumindest in der Theorie immer noch eine “Ausnahmesituation” ;-)).
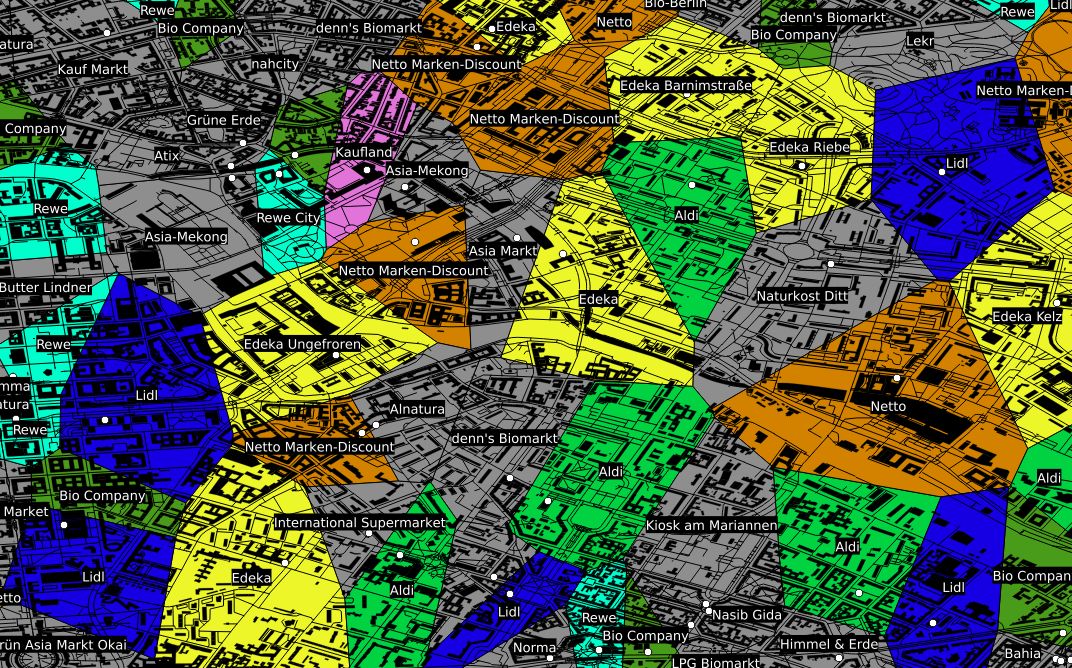
Neben dieser beliebten Art Geodaten zu nutzen, gibt es eine ganze Reihe weiterer Situationen in denen deren Nutzung hilfreich bis essentiell sein kann. Als Beispiel sei hier der Einzugsbereich von in Konkurrenz stehenden Einheiten, wie z. B. Supermärkten genannt. Ohne an dieser Stelle statistische Nachweise vorlegen zu können, kaufen (zumindest meiner persönlichen Beobachtung nach) die meisten Menschen fast immer bei dem Supermarkt ein, der am bequemsten zu erreichen ist und dies ist in der Regel der am nächsten gelegene. Besitzt man nun eine Datenbank mit der Information, wo welcher Supermarkt bzw. welche Supermarktkette liegt, kann man mit so genannten Voronidiagrammen recht einfach den jeweiligen Einzugsbereich der jeweiligen Supermärkte berechnen.
Entsprechende Karten können auch von beliebigen anderen Entitäten mit fester geographischer Position gezeichnet werden: Geldautomaten, Funkmasten, öffentlicher Nahverkehr, …
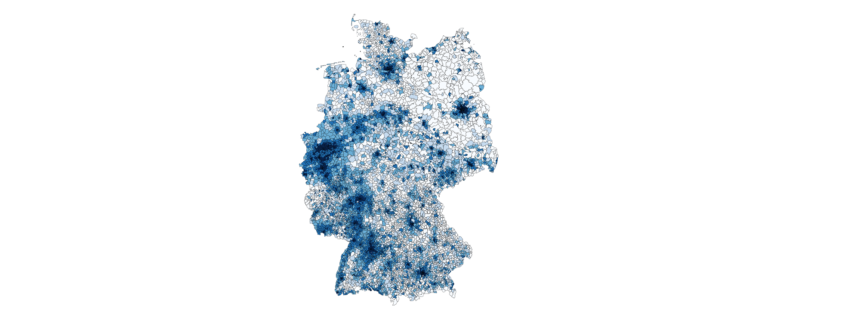
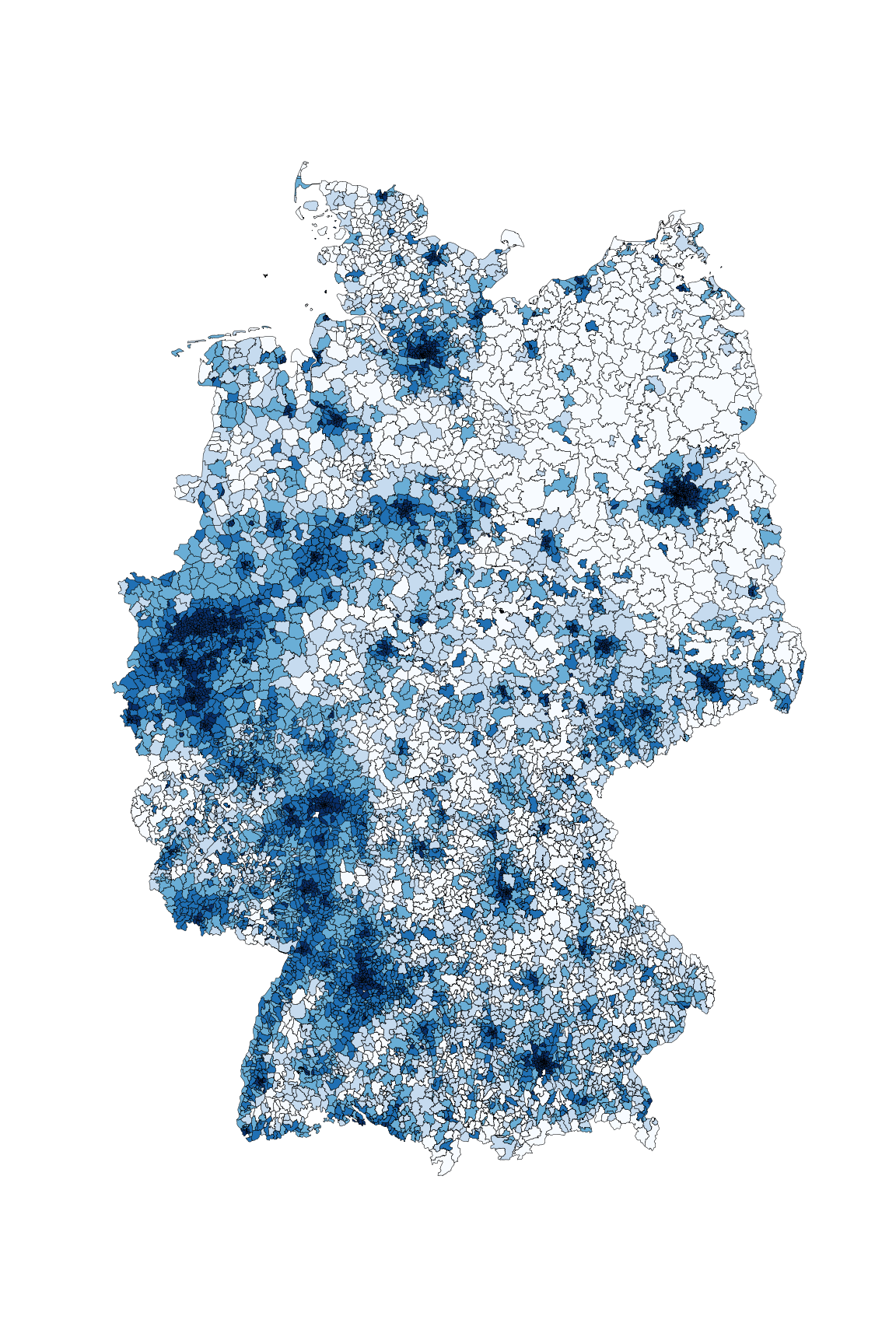
Ein anderes Beispiel, das für die Datenauswertung interessant ist, ist die kartographische Auswertung von Postleitzahlen. Diese sind in fast jedem Datensatz zu Kunden, Lieferanten, ect. vorhanden, bilden jedoch weder eine ordinale, noch eine sinnvolle kategorische Größe, da es viele tausend verschiedene gibt. Zudem ist auch eine einfache Gruppierung in gröbere Kategorien wie beispielsweise Postleitzahlen des Schemas 1xxxx oft kaum sinnvoll, da diese in aller Regel kein sinnvolles Mapping auf z. B. politische Gebiete – wie beispielsweise Bundesländer – zulassen. Ein Ausweg aus diesem Dilemma ist eine einfache kartographische Übersicht, welche die einzelnen Postleitzahlengebiete in einer Farbskala zeigt.
Im gezeigten Beispiel ist die Bevölkerungsdichte Deutschlands als Karte zu sehen. Hiermit wird schnell und übersichtlich deutlich, wo in Deutschland die Bevölkerung lokalisiert ist. Ähnliche Karten können beispielsweise erstellt werden, um Fragen wie “Wie ist meine Kundschaft verteilt?” oder “Wo hat die Werbekampange XYZ besonders gut funktioniert?” zu beantworten. Bezieht man weitere Daten wie die absolute Bevölkerung oder die Bevölkerungsdichte mit ein, können auch Antworten auf Fragen wie “Welchen Anteil der Bevölkerung habe ich bereits erreicht und wo ist noch nicht genutztes Potential?” oder “Ist mein Produkt eher in städtischen oder ländlichen Gebieten gefragt?” einfach und schnell gefunden werden.
Ohne die entsprechende geographische Zusatzinformation bleiben insbesondere Postleitzahlen leider oft als “nicht sinnvoll auswertbar” bei der Datenauswertung links liegen.
Eine ganz andere Art von Vorteil der Geodaten ist der educational point of view:
- Wer erst anfängt, sich mit Datenbanken zu beschäftigen, findet mit Straßen, Postleitzahlen und Ländern einen deutlich einfacheren und vor allem besser verständlichen Zugang zu SQL als mit abstrakten Größen und Nummern wie ProductID, CustomerID und AdressID. Zudem lassen sich Geodaten nebenbei bemerkt mittels so genannter GeoInformationSystems (*gis-Programme), erstaunlich einfach und ansprechend plotten.
- Wer sich mit SQL bereits ein wenig auskennt, kann mit den (beispielsweise von Spatialite oder PostGIS) bereitgestellten SQL-Funktionen eine ganze Menge über Datenbanken sowie deren Möglichkeiten – aber auch über deren Grenzen – erfahren.
- Für wen relationale Datenbanken sowie deren Funktionen schon lange nichts Neues mehr darstellen, kann sich hier (selbst mit dem eigenen Notebook) erstaunlich einfach in das Thema “Bug Data” einarbeiten, da die Menge an öffentlich vorhandenen Geodaten z.B. des OpenStreetMaps-Projektes selbst in optimal gepackten Format vielen Dutzend GB entsprechen. Gerade die Möglichkeit, die viele *gis-Programme wie beispielsweise QGIS bieten, nämlich Straßen-, Schienen- und Stromnetze “on-the-fly” zu plotten, macht die Bedeutung von richtig oder falsch gesetzten Indices in verschiedenen Datenbanken allein anhand der Geschwindigkeit mit der sich die Plots aufbauen sehr eindrucksvoll deutlich.
Um an Datensätze zu kommen, reicht es in der Regel Google mit den entsprechenden Schlagworten zu versorgen.
Neben – um einen Vergleich zu nutzen – dem Brockhaus der Karten
GoogleMaps gibt es beispielsweise mit dem
OpenStreetMaps-Projekt einen freien Geodatensatz, welcher in diesem Kontext etwa als das
Wikipedia der Karten zu verstehen ist.
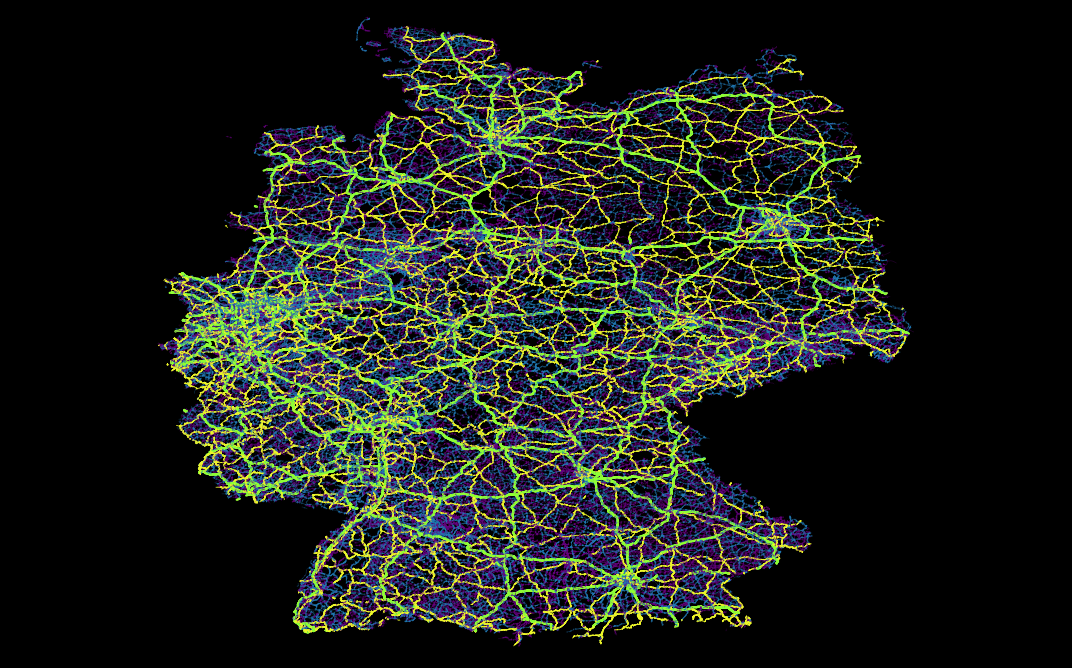
Hier findet man zum Beispiel Daten wie Straßen-, Schienen- oder dem Stromnetz, aber auch die im obigen Voronidiagramm eingezeichneten Gebäude und Supermärkte stammen aus diesem Datensatz. Hiermit lassen sich recht einfach just for fun interessante Dinge herausfinden, wie z. B., dass es in Deutschland ca. 28 Mio Gebäude gibt (ein SQL-Einzeiler), dass der Berliner Osten auch ca. 30 Jahre nach der Wende noch immer vorwiegend von der Tram versorgt wird, während im Westen hauptsächlich die U-Bahn fährt. Oder über welche Trassen der in der Nordsee von Windkraftanlagen erzeugte Strom auf das Festland kommt und von da aus weiter verteilt wird.
Eher grundlegende aber deswegen nicht weniger nützliche Datensätze lassen sich unter dem Stichwort “
natural earth” finden. Hier sind Daten wie globale Küstenlinien, mittels Echolot ausgemessene Meerestiefen, aber auch von Menschen geschaffene Dinge wie Landesgrenzen und Städte sehr übersichtlich zu finden.
Im Grunde sind der Vorstellung aber keinerlei Grenzen gesetzt und fast alle denkbaren geographischen Fakten können, manchmal sogar live via Sattelit, mitverfolgt werden. So kann man sich beispielsweise neben aktueller Wolkenbedekung,
Regenradar und
globaler Oberflächentemperatur des Planeten auch das Abschmelzen der Polkappen seit 1970 ansehen (
NSIDC) oder sich live die Blitzeinschläge auf dem gesamten Planeten anschauen – mit Vorhersage darüber, wann und wo der Donner zu hören ist (das funktioniert wirklich! Beispielsweise auf
lightningmaps).
Kurzum Geodaten sind neben ihrer wirtschaftlichen Relevanz – vor allem für die Logistik – auch für angehende Data Scientists sehr aufschlussreich und ein wunderbares Spielzeug, mit dem man sich lange beschäftigen und eine Menge interessanter Dinge herausfinden kann.