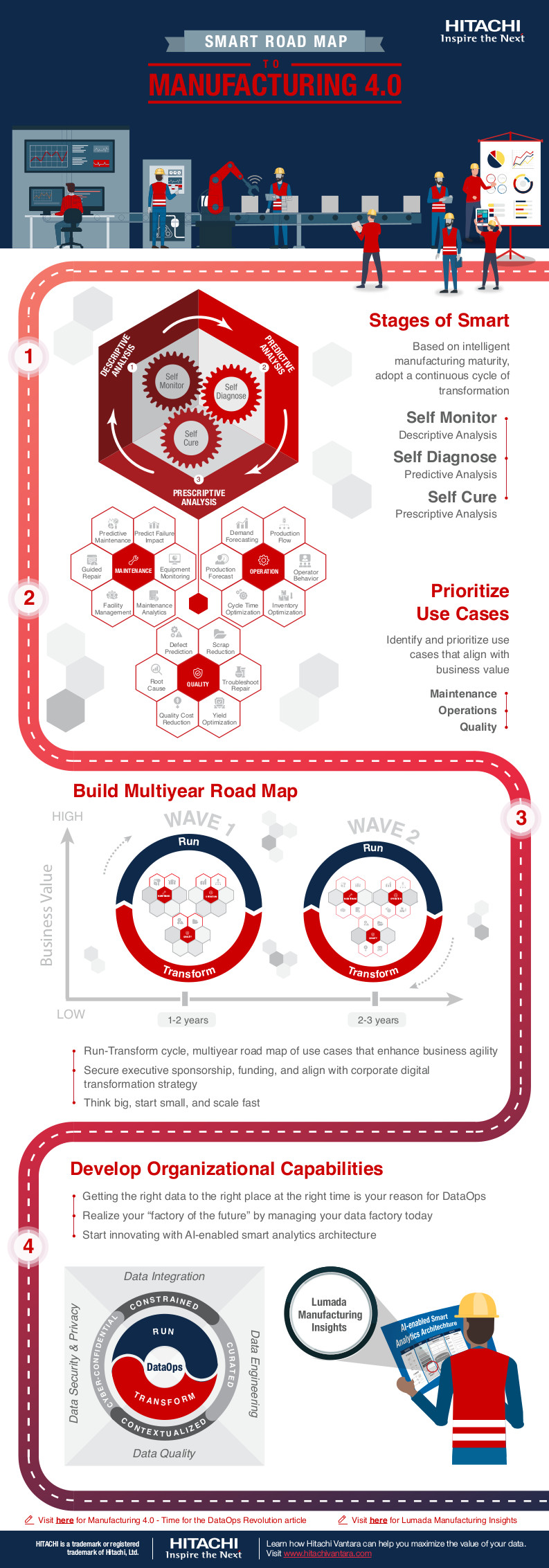
Predictive Maintenance – Konzept und Chancen
(Maschinen)Zeit ist kostbar. Das trifft besonders auf produzierende Unternehmen zu. Denn hier gilt, jeder Stillstand einer Anlage kostet wertvolle Produktionskapazität. Stillstände einer Maschine lassen sich nicht 100%ig vermeiden, nur können sie mit dem passenden Predictive Maintenance Konzept (im weiteren Text als PdM abgekürzt) reduziert und besser planbar gemacht werden. Mit intelligenten Add-ons wie IoT Anbindung von Maschinen in einer Industrie 4.0 Umgebungen und die Integration in ein gut geplantes Predictive Maintenance System lassen sich Kosten einsparen.
Was ist Predictive Maintenance?
Unter PdM sind Features beim Betrieb einer Anlage oder Maschine gemeint, die aus historischen Daten lernen und in Verbindung mit aktuellen oder sogar Echtzeitdaten Prognosen über bevorstehende Ereignisse durchführen. Aus den Berechnungen können z.B. kommende Wartungsarbeiten oder sich andeutende Ausfälle von Komponenten abgeleitet werden. Ersatzteile müssen nicht mehr vorsorglich auf Lager gelegt werden, sondern können aufgrund der tatsächlichen Notwendigkeit bestellt werden.
Vorteile durch Einsatz von Predictive Maintenance
Weiterer Pluspunkt ist die gute Planbarkeit von Wartungsintervallen. Betreiber als auch Hersteller können die Terminpläne nach dem vorherberechneten Wartungszeitpunkt einteilen. Als Betreiber können die Verfügbarkeiten mit den notwendigen Kapazitäten für die Produktion korreliert werden. Als Hersteller können Sie die Bestellung von Ersatzteilen im tatsächlich gebrauchten Umfang termingerecht durchführen. Und Sie müssen nicht von jedem möglichen Ersatzteil eine Anzahl immer vorrätig haben.
Technisches Konzept und Überlegungen
Für die Implementierung eines PdM, egal ob Sie das selbst durchführen wollen oder als Produkt zukaufen wollen, ist ein technisches Konzept der Startpunkt. Wir wollen hier die Eckdaten dieser Überlegungen skizzieren, um so als Arbeitsunterlage zur Erarbeitung des Konzepts dienen zu können.
Ein PdM Konzept besteht grob aus den folgenden Komponenten:
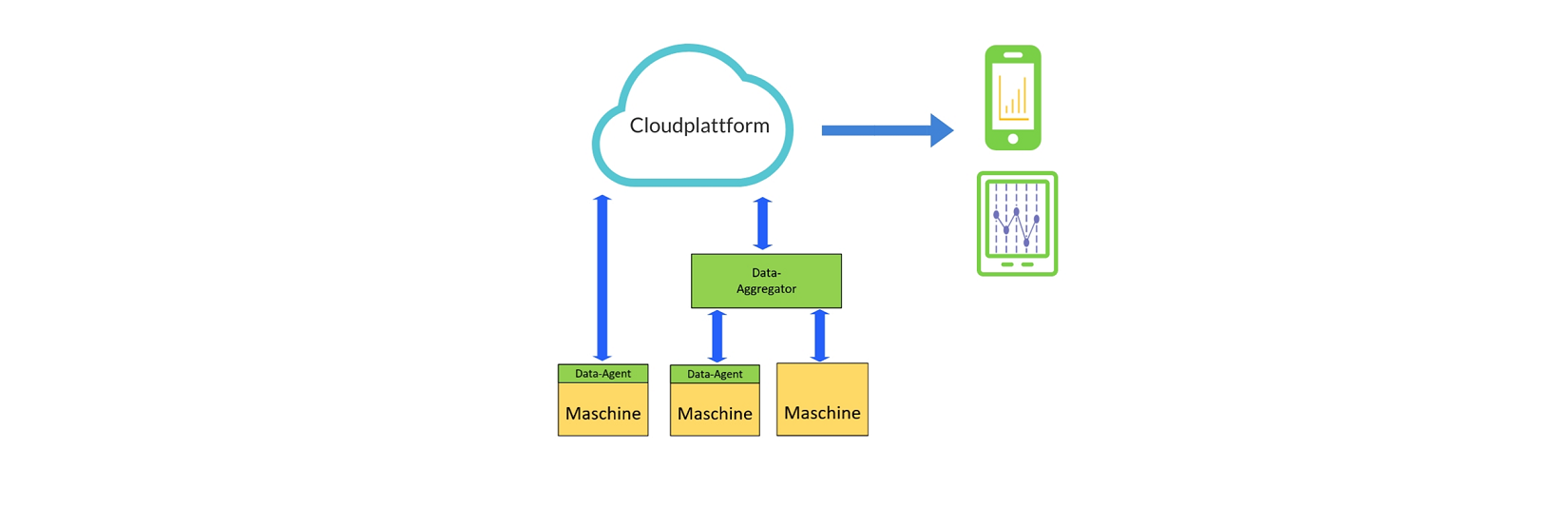
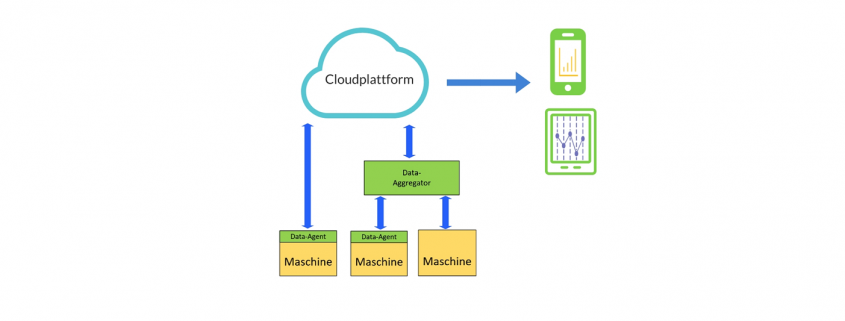
Predictive Maintenance Konzept
- Maschine: hier werden Daten erzeugt, die in das PdM System übernommen werden sollen. Von den Maschinen sollen die Daten möglichst rasch und instantan abgegriffen werden, um die Werte in die Cloud zu laden und am Endgerät verfügbar zu haben. Meist ist auf den Maschinen nur begrenzter Speicherplatz vorhanden. Und die Daten können dort nur kurz zwischengespeichert werden.
- Data-Agent und Transferprotokoll: die Übertragung der Daten auf die Cloudplattform wird durch eine Softwarekomponente durchgeführt. Diese kann entweder vom Hersteller mitgeliefert und bereits in der Maschine integriert sein. Oder sie wird als Teil des PdM Konzepts ergänzt.
Aufgabe ist, die Daten gesichert auf die Cloudplattform zu übertragen. Bei Ausfall der Netzwerkverbindung kann ein lokales Spooling der Daten mit anschließender gesammelter Übertragung erfolgen.
Neben der Datenübertragung muss an dieser Stelle auch eine Registrierung neuer Maschinen möglich sein. Der Data-Agent darf sich nicht einfach durch Klonen auf eine neue Maschine übertragen lassen. Eine geeignete Sicherung über z.B. Hardware-IDs muss hier durchgeführt werden. - Data-Aggregator: kann oder soll nicht die Maschine direkt Daten in die Cloud übertragen, können die Daten mehrerer Maschinen mit einem Data-Aggregator zusammengefasst werden. Von dort wird dann die verschlüsselte Übertragung auf die Cloudplattform durchgeführt.
Gründe für den Einsatz eines Data-Aggregators könnten sein, dass beim Endkunden keine Übertragung von einzelnen Maschinen ins Netz erlaubt ist. Oder dass auch „Legacy“ Maschinen angebunden werden sollen, für die es keine Plugins zur direkten Datenübertragung gibt. Z.B., wenn eine Maschine mit einer älteren SPS angebunden werden soll, für die technisch keine direkte Übertragung auf die Cloud möglich ist. - Cloud- / Webplattform: die übertragenen Daten müssen zentral in einer geeigneten Umgebung gespeichert werden. Aus diesen gesammelten Daten werden die eigentlichen Erkenntnisse und Vorhersagen eines PdM Systems gewonnen. Durch eine KI und selbstlernende Algorithmen können die Daten weiter verwertet werden. Die gewonnen Ergebnisse aus den analysierten Maschinendaten sind die Basis für das PdM System und werden den Anwendern grafisch aufbereitet oder als Infos und Warnungen per Message zugestellt.
- Endgerät: ist der Zugangspunkt für den Anwender. Die PdM Daten werden als App oder als Webanwendung dargestellt.
Der Data-Agent / Data-Aggregator kann mittels Edge Computing lokale Intelligenz erhalten. Daten können bereits vorausgewertet und zusammengefasst werden. Das reduziert die übertragenen Daten.
Welche Werte sollen übertragen werden?
Ziel des PdM ist durch das Abgreifen und Auswerten der Maschinendaten im Endeffekt eine Vernetzung mit den informationsverarbeitenden Systemen in einem Unternehmen. Das wird z.B. ein ERP Enterprise Resource Planning oder ein MES Manufacturing Execution System sein. Dort werden aufgrund der PdM Daten die Ressourcen und Kapazitäten für die Produktion geplant.
Typische Daten zur Übertragung bei einem PdM sind:
- Temperatur
- Druck
- Geschwindigkeiten
- Zurückgelegte Wege
- Schaltspiele
- Viskositäten
- Flüssigkeitsstände
- Vibrationen
Welche Daten Sie abgreifen können hängt damit zusammen, ob Sie Anwender also ein Produktionsbetrieb oder Hersteller also ein Maschinebauer sind. Als Anwender haben Sie normalerweise weniger tiefe Zugriffsmöglichkeiten auf Daten und Parameter der Maschinen. Nur die vom Hersteller bereitgestellten und dokumentierten Werte sind zugänglich. Diese sind vom Level eher auf Applikationsschicht angesetzt. Als Hersteller können Sie auf beliebige Werte zurückgreifen. Dazu gehören auch Dinge wie Schaltspiele oder zurückgelegte Fahrwege von Motoren.
Übertragen Sie jene Daten ins PdM, aus denen Sie die Wartungsarbeiten Ihrer Maschine ermitteln können.
Z.B. bei einer Glashärteanlage wären das die Betriebsstunden der Keramikwalzen, zurückgelegte Wege der Keilriemen oder Einschaltzeiten der Heizelemente.
Z.B. bei einer Automatisierung für die Leiterplattenfertigung wären das die Betriebsstunden der Saugnäpfe oder die zurückgelegten Wege der Antriebsriemen.
Wie oft sollen Werte übertragen werden?
Wenn Sie von der Netzwerkanbindung mit keinen Einschränkungen in Bezug auf Bandbreite oder Datenlimit rechnen müssen, nehmen Sie als Übertragungsintervall eine relativ gute Granularität an. Wählen Sie es so aus, dass Probleme an der Maschine auch nachträglich noch analysiert und der Auslöser gefunden werden kann.
Bei den meisten Industrie 4.0 Umgebungen sollte die Datenmenge keine große Rolle spielen. Sollten Sie in einer IoT Umgebung mit z.B. LoRaWAN-Anbindung arbeiten, dann teilen Sie die Daten in Kategorien nach Priorität ein. Z.B. hoch, mittel, niedrig oder z.B. Produktion, Standby. Die Übertragung der Kategorien können dann je nach Betriebszustand differenziert werden, wann welche Kategorie wichtig ist und priorisiert übertragen werden soll.
Chancen
Die Umsetzung eines Predictive Maintenance Konzepts hilft Ihnen die Produktion agiler zu gestalten. Terminpläne aufgrund vorausgesagter Wartungszeiten der Anlagen lassen eine präzisere und engere Planung der Kapazitäten zu. Dieser Effekt wirkt sich positiv auf Produktionskosten aus.
Ein großes Sparpotential hat ein PdM für die kommenden CO2 Steuermodelle. Mit den ermittelten Daten können Sie exakte Berechnungen über die verbrauchte Energie auf das produzierte Werkstück durchführen und so CO2 Steuer sparen.
Mit smarten Diensten wie einem PdM können Sie als Maschinenhersteller dauerhaft Geld verdienen. Sie generieren weiteren Umsatz von Ihren Kunden und erhöhen gleichzeitig die Kundenbindung. Ihre Kunden werden durch vorausschauende Wartung zufriedener mit Ihren Produkten.
Fazit
Vorausschauende Wartung hat Potential für Endanwender als auch für Hersteller. Beim Endanwender steht das Sparpotential im Vordergrund beim Hersteller die Kundenzufriedenheit. Mit intelligenten Edge-Computing Komponenten lassen sich PdM Lösungen gut skalieren und die Datenmenge reduzieren.
Die Umsetzung einer Lösung für Predictive Maintenance ist nicht an die Installation oder Entwicklung einer neuen Anlage gebunden. Auch bereits laufende Maschinen können leicht in ein PdM integriert werden.
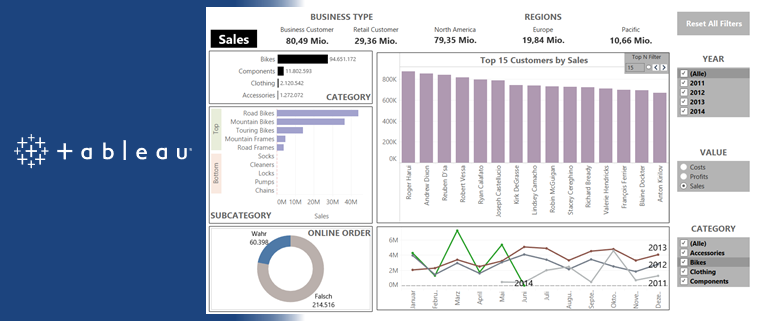
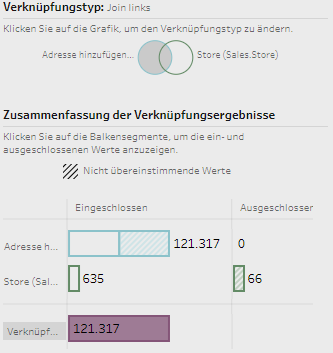
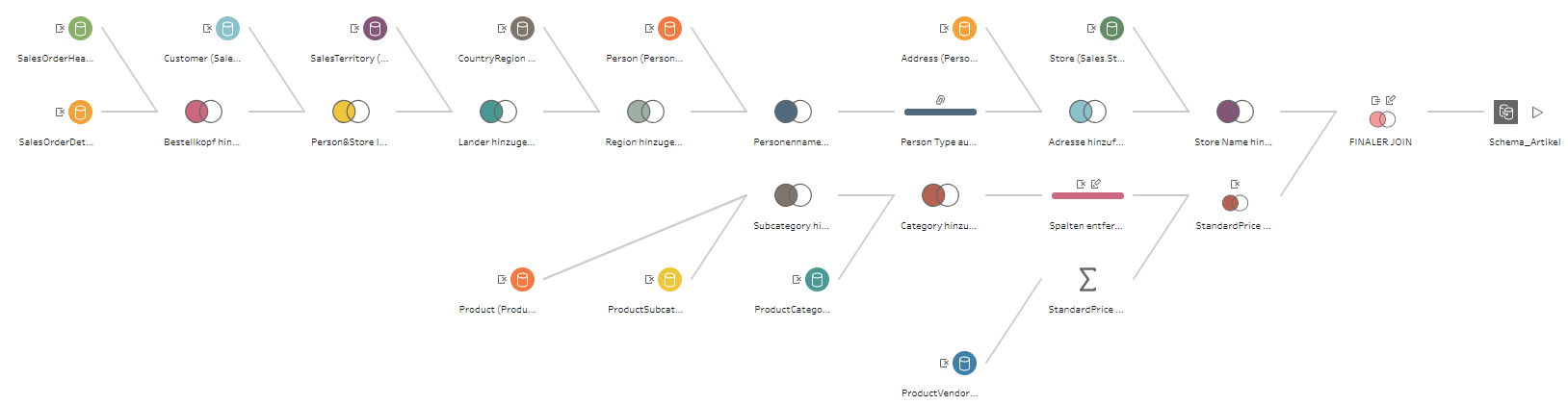
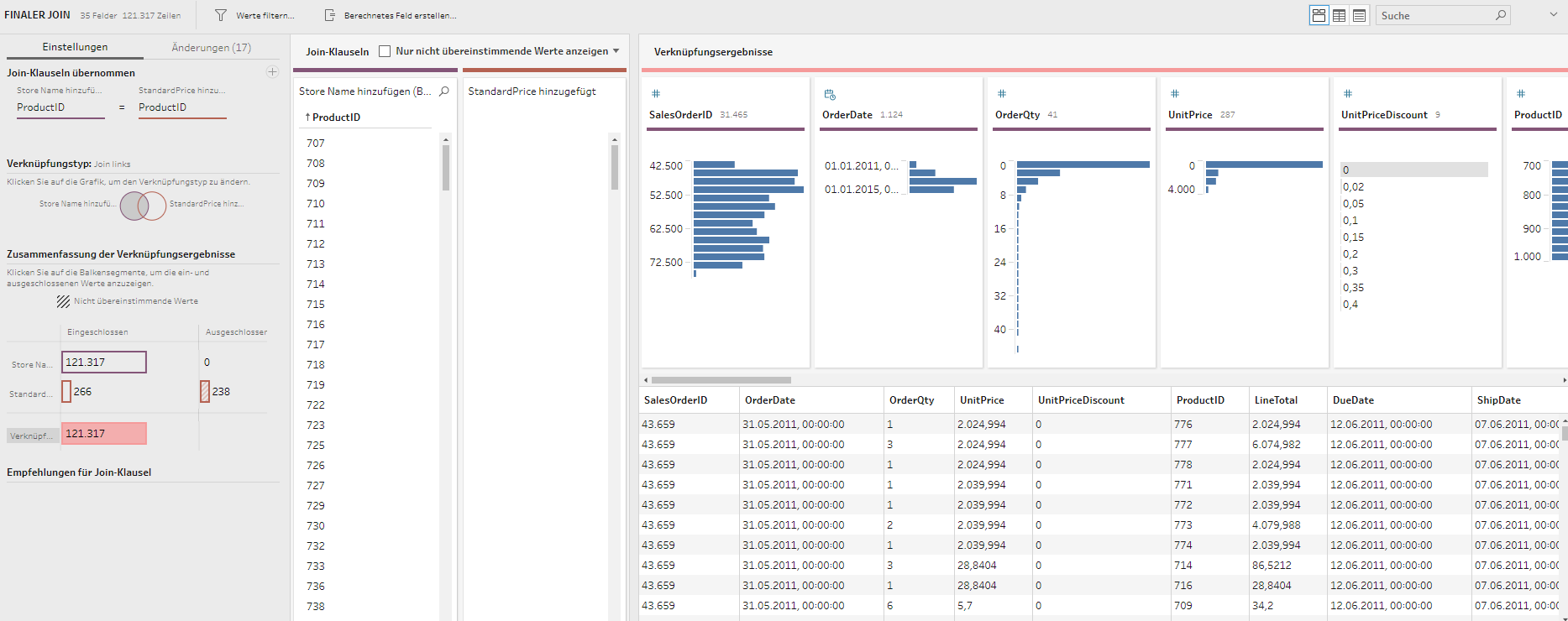
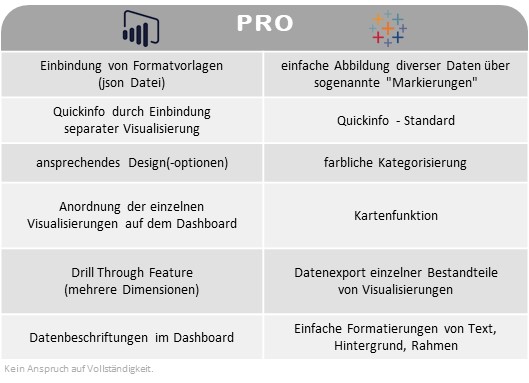
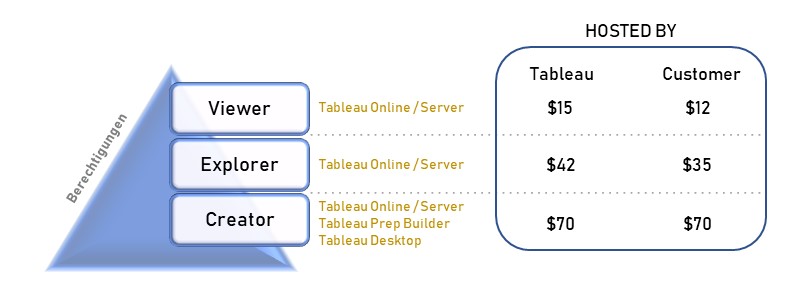 Der Creator ist befähigt, alle Funktionen von Tableau zu nutzen, sofern ein Unternehmen die angebotenen Add-ons hinzukauft. Die Lizenz Explorer ermöglicht es dem User, durch den Creator vordefinierte Datasets in Eigenregie zu analysieren und zu visualisieren. Demnach obliegt dem Creator, und somit einer kleinen Personengruppe, die Datenbereitstellung, womit eine Single Source of Truth garantiert werden soll. Der Viewer hat nur die Möglichkeit Berichte zu konsumieren, zu teilen und herunterzuladen. Wobei in Bezug auf Letzteres der Viewer limitiert ist, da dieser nicht die kompletten zugrundeliegenden Daten herunterladen kann. Lediglich eine Aggregation, auf welcher die Visualisierung beruht, kann heruntergeladen werden. Ein
Der Creator ist befähigt, alle Funktionen von Tableau zu nutzen, sofern ein Unternehmen die angebotenen Add-ons hinzukauft. Die Lizenz Explorer ermöglicht es dem User, durch den Creator vordefinierte Datasets in Eigenregie zu analysieren und zu visualisieren. Demnach obliegt dem Creator, und somit einer kleinen Personengruppe, die Datenbereitstellung, womit eine Single Source of Truth garantiert werden soll. Der Viewer hat nur die Möglichkeit Berichte zu konsumieren, zu teilen und herunterzuladen. Wobei in Bezug auf Letzteres der Viewer limitiert ist, da dieser nicht die kompletten zugrundeliegenden Daten herunterladen kann. Lediglich eine Aggregation, auf welcher die Visualisierung beruht, kann heruntergeladen werden. Ein