Praxisbeispiel: Data Science im Marketing
Wie Sie mit Data Science die Conversion-Rate in Ihrem Online-Shop erhöhen
Die Fragestellung: Ein Hersteller von Elektrogeräten lancierte einen neuen Online-Shop, um einen neuen Vertriebskanal zu schaffen, der unabhängig von stationären Einzelhändlern und Amazon ist. Obwohl der Online-Shop von Interessent:innen häufig besucht wurde, war die Conversion-Rate zu niedrig und der Umsatz somit zu gering.
Die zentrale Frage war nun: Wie kann die Conversion-Rate erhöht werden, um den Umsatz über den neuen Vertriebskanal zu erhöhen?
Was ist eine Conversion-Rate? Die Conversion-Rate ist eine Marketing-Kennzahl, die in diesem Beispiel das Verhältnis der Besucher:innen des Online-Shops zu den getätigten Käufen meint. Halten sich viele Besucher:innen im Online-Shop auf und sind die Warenkorb-Abschlüsse dennoch gering, so ist die Conversion-Rate niedrig. Das Ziel ist es, die Conversion-Rate zu steigern, also dafür zu sorgen, dass Besucher:innen, die sich im Online-Shop befinden und dort etwas in den Warenkorb legen, auch einen Kauf tätigen.
Vorgehen: Um zu verstehen, warum eine Bestellung abgeschlossen bzw. nicht abgeschlossen wurde, wurden verschiedene Daten aus dem Web-Analytics-System des Online-Shops untersucht. Dazu gehörten im Wesentlichen Daten zu Besucherhandlungen auf der Website, die automatisch getrackt, also aufgezeichnet werden, wie z. B. Button & Link-Klicks, Bildergalerie öffnen, Produktvideo ansehen, Produktbeschreibung ausklappen, Time on page usw.
Mit diesen Daten wurden drei Analyseverfahren durchgeführt.
1) Website-Besucher verstehen
Zunächst wurden mit einer explorativen Datenanalyse die Website-Besucher:innen und deren Bedürfnisse untersucht. Über die meisten der Besucher:innen lagen bereits Daten vor, da sie in der Vergangenheit bereits Käufe auf der Website getätigt hatten und dafür ein Konto angelegt hatten. Darüber hinaus wurde untersucht, über welche Kanäle die Besucher:innen in den Online-Shop gelangten, beispielsweise über Google oder Facebook. Informationen zu Gerät, Standort, Browser und Betriebssystem waren ebenfalls verfügbar.
Anhand dieser unterschiedlichen Parameter wurden die Benutzerdaten einem Analyseverfahren, dem sog. Clustering, unterzogen, bei dem die Website-Besucher:innen aufgrund ihrer Ähnlichkeiten in verschiedenen Eigenschaften in Gruppen („Cluster“) eingeteilt wurden.
Beispiel: Besucher über Android-Smartphones und Chrome-Browser, die zwischen 17 und 19 Uhr am Samstag auf der Website sind, kaufen eher familienbezogene Produkte.
Daraufhin konnte man neue Website-Besucher:innen aufgrund der verschiedenen Eigenschaften meist recht eindeutig einem Cluster zuordnen, da ähnliche Besucher:innen tendenziell ein ähnliches Verhalten auf einer Website zeigen. Dieses Clustering lieferte dem Unternehmen bereits wertvolle Informationen. So konnten auf dieser Informationsgrundlage individuelle Marketingstrategien für verschiedene Zielgruppen entwickelt, das Werbe-Targeting angepasst und spezifische Sonderangebote erstellt werden.
Beispiel: Besucher über Android-Smartphones und Chrome-Browsern, die zwischen 17 und 19 Uhr am Samstag auf der Website sind, bekommen ein Sonderangebot für ein familienbezogenes Produkt, wie beispielsweise ein Babyfon ausgespielt.
In vielen Fällen reicht eine solche Analyse bereits aus, um die Conversion-Rate eines Online-Shops spürbar zu steigern. In diesem Projekt wurden jedoch noch zwei weitere Analyseschritte durchgeführt.
2) Conversion Path verstehen und Engpässe nachvollziehen
Der nächste Schritt bestand darin, den Conversion Path der Kund:innen zu untersuchen. Der Conversion Path umfasst alle Handlungen von Kund:innen vom Ankommen auf der Website über den Besuch verschiedener Seiten bis hin zum finalen Kauf bzw. Kaufabbruch. Bei der Analyse wurden alle Conversion Paths auf Gemeinsamkeiten und Unterschiede untersucht, um bestimmte Muster abzuleiten. Von besonderem Interesse waren mögliche Gründe, aus denen Besucher:innen ihre Sitzung vor Kaufabschluss abbrachen. Es stellte sich heraus, dass Besucher:innen ihre Sitzung vor allem dann abbrachen, wenn es für ein Produkt kein Produktvideo gab bzw. das Produktvideo nicht gefunden wurde. Diese mangelnde Produktinformation konnte anschließend gezielt bearbeitet werden, woraufhin sich die Conversion-Rate deutlich verbesserte.
3) Next-best-Action vorhersagen
Im dritten Schritt des Projektes zur Steigerung der Conversion-Rate wurde der Ansatz der Next-best-Action (NBA) gewählt. Damit wurde hier ein weiterer Schritt von der reinen Analyse von bereits vorhandenen Daten hin zur Vorhersage zukünftigen Verhaltens gewählt.
Was bedeutet Next-best-action? Next-best-action (NBA) ist eine Marketingstrategie, die darauf abzielt, Informationen über einzelne Kund:innen zu sammeln und zu nutzen, um einen Kauf anzuregen. Wie der Name schon sagt, wird versucht zu ermitteln, welcher der nächste beste Schritt im Verkaufsprozess für jede:n einzelne:n Kunde:in ist.
Mithilfe der allgemeinen Informationen über die Website-Besucher:innen und der Conversion Paths konnten unterschiedliche Aktionen identifiziert werden, die einen Kauf wahrscheinlicher machen würden. Dazu gehörte z. B., den Besucher:innen das Produktvideo anzuzeigen, einen Rabatt-Code oder ein Sonderangebot für eine spezielle Produktkategorie anzubieten oder ein Chat-Fenster für den Kundensupport zu öffnen.
Somit half die NBA-Vorhersage dabei, die Conversion erneut deutlich zu steigern, indem für jede:n Website-Besucher:in eine individuelle Aktion vorgeschlagen werden konnte.
Ergebnisse:
In diesem Projekt konnte die Marketingabteilung des Elektrogeräte-Herstellers durch drei verschiedene Analyseansätze die Conversion-Rate im Online-Shop deutlich verbessern:
- Mithilfe des Clustering war das Unternehmen in der Lage, individuelle Marketingstrategien für verschiedene Zielgruppen zu entwickeln, das Werbe-Targeting anzupassen und spezifische Sonderangebote zu erstellen.
- Durch die Analyse der Conversion Paths konnten produkt- und produktbeschreibungsspezifische Engpässe identifiziert und anschließend gezielt behoben werden.
- Mit der NBA-Analyse konnten nächste beste Schritte für jede:n einzelne:n Kunde:in bestimmt und automatisch ausgelöst werden.

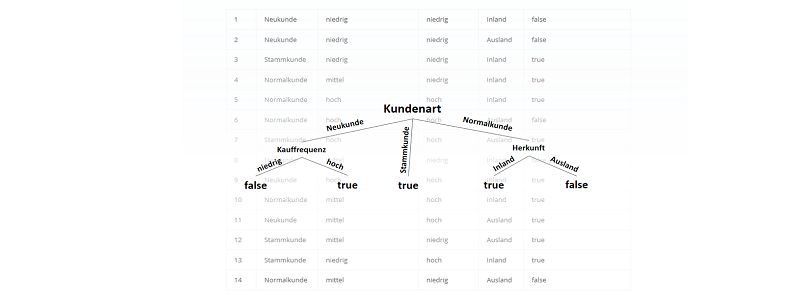
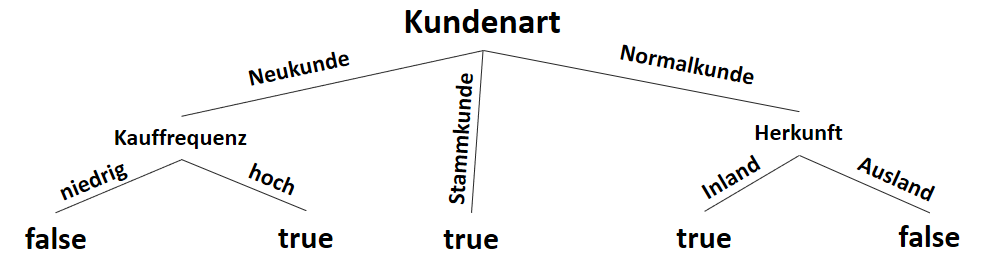
 ) im Sinne des ID3-Algorithmus ist die Differenz aus der Entropie (
) im Sinne des ID3-Algorithmus ist die Differenz aus der Entropie ( ) (siehe Teil 1 der Artikelserie
) (siehe Teil 1 der Artikelserie  ) und der Summe aus den gewichteten Entropien des Attributes für jeden einzelnen Wert (Value
) und der Summe aus den gewichteten Entropien des Attributes für jeden einzelnen Wert (Value  ), der im Attribut vorkommt:
), der im Attribut vorkommt:

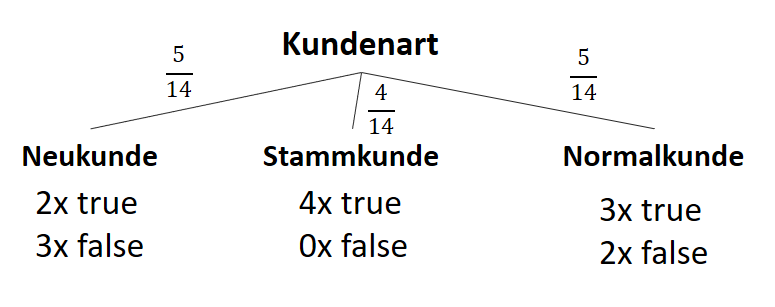



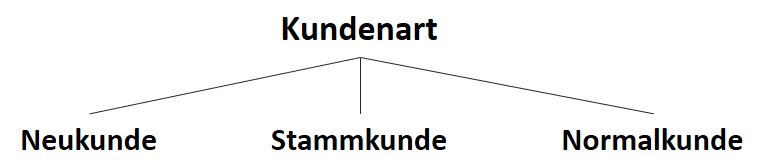
![\[ IG(S, A_{Kundenart}) = - \sum_{i=1}^n \frac{\bigl|S_i\bigl|}{\bigl|S\bigl|} \cdot H(S_i) \]](https://data-science-blog.com/de/wp-content/ql-cache/quicklatex.com-6380891cc61bb855d4208480091fdef0_l3.png "Rendered by QuickLaTeX.com")
![\[ IG(S, A_{Kundenart}) = H(S) - \frac{\bigl|S_{Neukunde}\bigl|}{\bigl|S\bigl|} \cdot H(S_{Neukunde}) - \frac{\bigl|S_{Stammkunde}\bigl|}{\bigl|S\bigl|} \cdot H(S_{Stammkunde}) - \frac{\bigl|S_{Normalkunde}\bigl|}{\bigl|S\bigl|} \cdot H(S_{Normalkunde}) \]](https://data-science-blog.com/de/wp-content/ql-cache/quicklatex.com-b3c9d40c7a171fd7b9e5fbed0aed041a_l3.png "Rendered by QuickLaTeX.com")
![\[ IG(S, A_{Kundenart}) = 0.94 - \frac{5}{14} \cdot 0.97 - \frac{4}{14} \cdot 0.00 - \frac{5}{14} \cdot 0.97 = 0.247 \]](https://data-science-blog.com/de/wp-content/ql-cache/quicklatex.com-33144ba5df6858348666daef5a5cf5d3_l3.png "Rendered by QuickLaTeX.com")
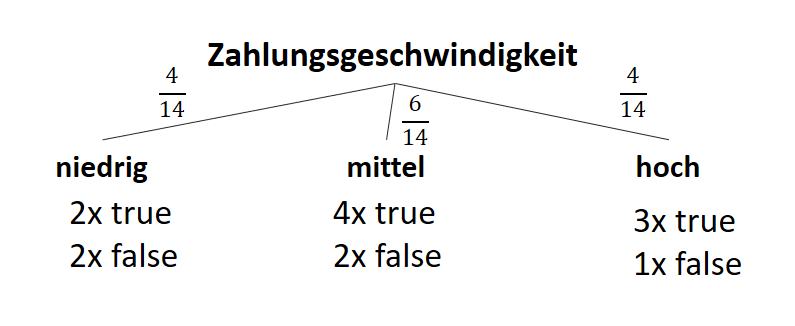



![\[ IG(S, A_{Zahlungsgeschwindigkeit}) = H(S) - \frac{\bigl|S_{niedrig}\bigl|}{\bigl|S\bigl|} \cdot H(S_{niedrig}) - \frac{\bigl|S_{mittel}\bigl|}{\bigl|S\bigl|} \cdot H(S_{mittel}) - \frac{\bigl|S_{schnell}\bigl|}{\bigl|S\bigl|} \cdot H(S_{schnell}) \]](https://data-science-blog.com/de/wp-content/ql-cache/quicklatex.com-a80e61c0adf9dff8ca219a28bce359cd_l3.png "Rendered by QuickLaTeX.com")
![\[ IG(S, A_{Zahlungsgeschwindigkeit}) = 0.94 - \frac{4}{14} \cdot 1.00 - \frac{6}{14} \cdot 0.92 - \frac{4}{14} \cdot 0.81 = 0.029 \]](https://data-science-blog.com/de/wp-content/ql-cache/quicklatex.com-ed4f1d54de66a9956bc2c1e53a0de2e8_l3.png "Rendered by QuickLaTeX.com")
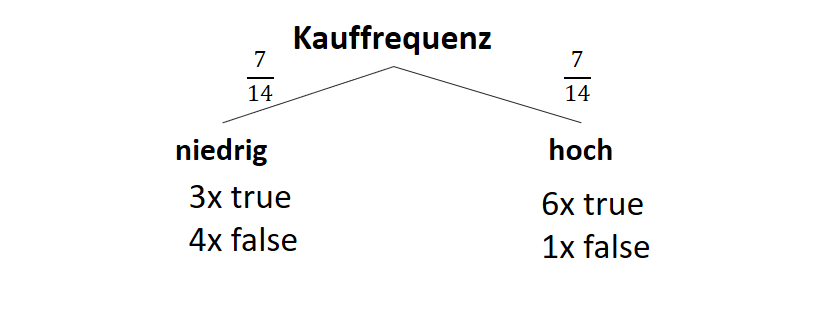


![\[ IG(S, A_{Kauffrequenz}) = H(S) - \frac{\bigl|S_{niedrig}\bigl|}{\bigl|S\bigl|} \cdot H(S_{niedrig}) - \frac{\bigl|S_{hoch}\bigl|}{\bigl|S\bigl|} \cdot H(S_{hoch}) \]](https://data-science-blog.com/de/wp-content/ql-cache/quicklatex.com-cbcfb6a5b118cfc2df4185ef03e4e1dd_l3.png "Rendered by QuickLaTeX.com")
![\[ IG(S, A_{Kauffrequenz}) = 0.94 - \frac{7}{14} \cdot 1.00 - \frac{7}{14} \cdot 0.59 = 0.150 \]](https://data-science-blog.com/de/wp-content/ql-cache/quicklatex.com-dc9f358f2d2cd071b815b3f6c571f813_l3.png "Rendered by QuickLaTeX.com")
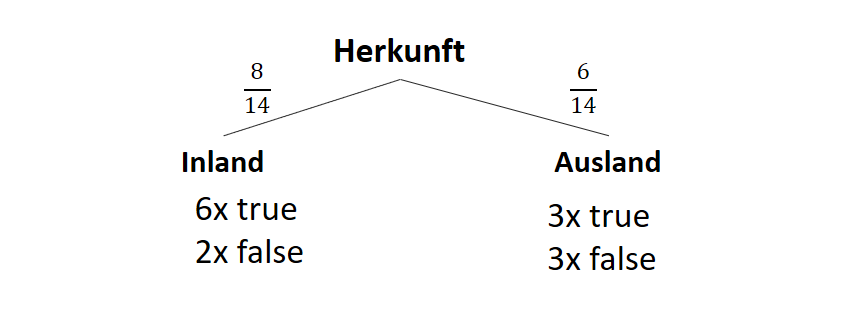


![\[ IG(S, A_{Herkunft}) = H(S) - \frac{\bigl|S_{Inland}\bigl|}{\bigl|S\bigl|} \cdot H(S_{Inland}) - \frac{\bigl|S_{Ausland}\bigl|}{\bigl|S\bigl|} \cdot H(S_{Ausland}) \]](https://data-science-blog.com/de/wp-content/ql-cache/quicklatex.com-3a0ecd4412fa44ca26c64ea16aa536d1_l3.png "Rendered by QuickLaTeX.com")
![\[ IG(S, A_{Herkunft}) = 0.94 - \frac{8}{14} \cdot 0.81 - \frac{6}{14} \cdot 1.00 = 0.05 \]](https://data-science-blog.com/de/wp-content/ql-cache/quicklatex.com-ab4db275a73c092813d00f26ef4c1183_l3.png "Rendered by QuickLaTeX.com")
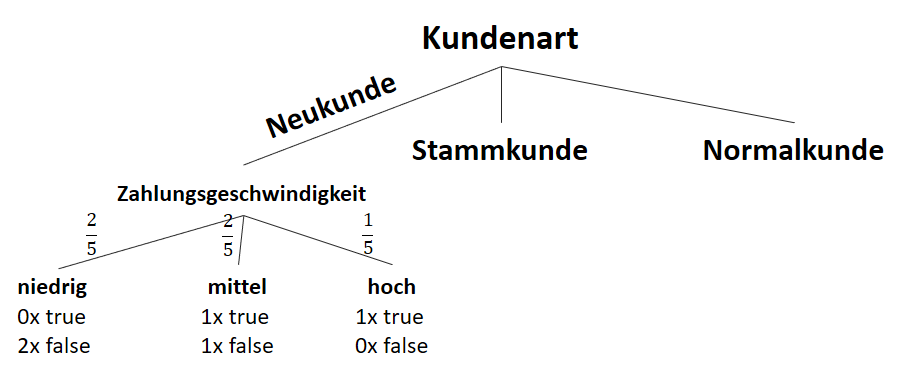



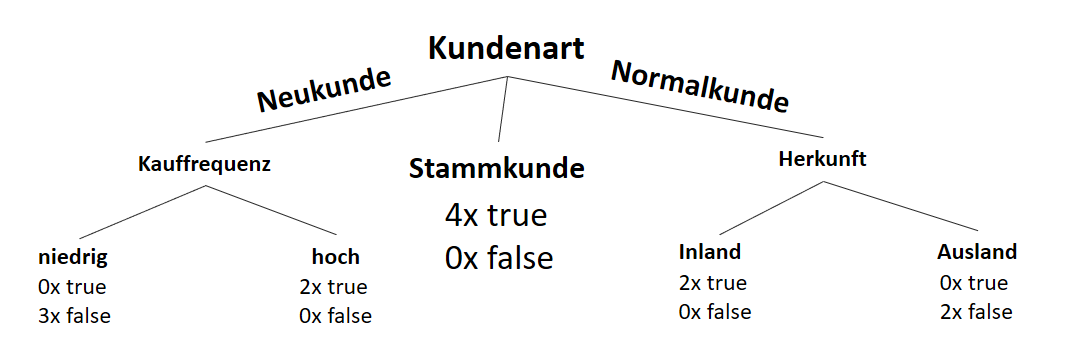
![\[ IG(S_{Neukunde},A_{Zahlungsgeschwindigkeit}) = 0.97 - \frac{3}{5} \cdot 0.00 - \frac{2}{5} \cdot 1.00 - \frac{1}{5} \cdot 0.00 = 0.57 \]](https://data-science-blog.com/de/wp-content/ql-cache/quicklatex.com-35c0216b5e69ee73831980225531ecc7_l3.png "Rendered by QuickLaTeX.com")
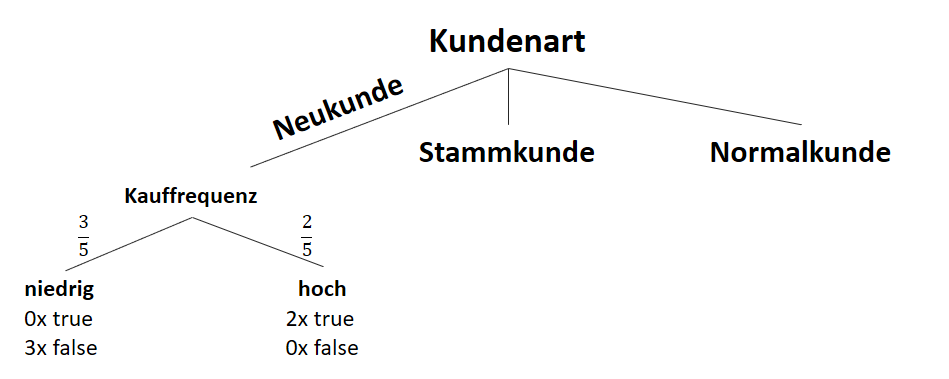
![\[ IG(S_{Neukunde},A_{Kauffrequenz}) = 0.97 - \frac{3}{5} \cdot 0.00 - \frac{2}{5} \cdot 0.00 = 0.97 \]](https://data-science-blog.com/de/wp-content/ql-cache/quicklatex.com-5f6849e7156c9505f53b484a8e7f505a_l3.png "Rendered by QuickLaTeX.com")
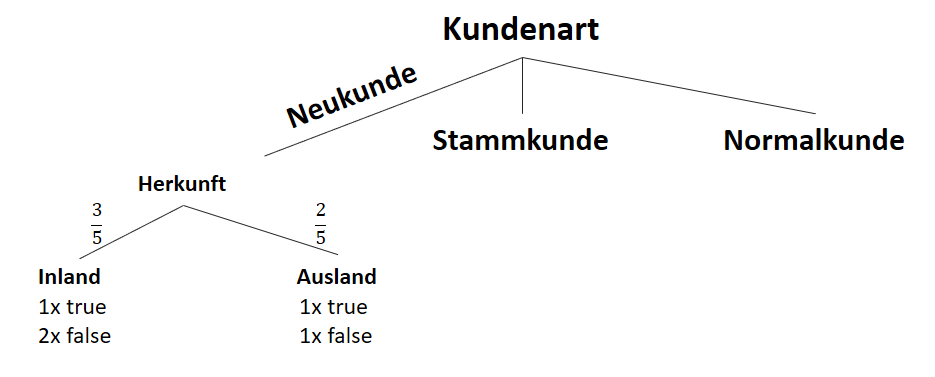


![\[ IG(S_{Neukunde},A_{Herkunft}) = 0.97 - \frac{3}{5} \cdot 0.92 - \frac{2}{5} \cdot 1.00 = 0.018 \]](https://data-science-blog.com/de/wp-content/ql-cache/quicklatex.com-890f306c397d0ac28cbbd9a316eb049b_l3.png "Rendered by QuickLaTeX.com")



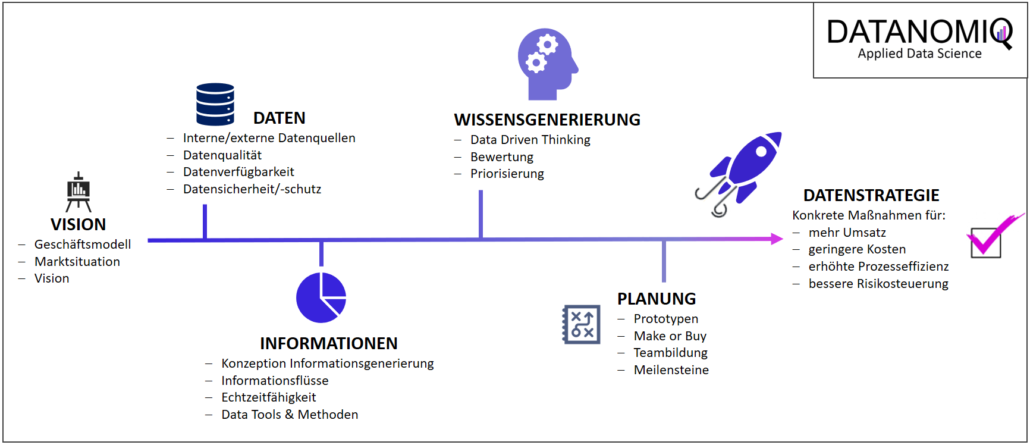
 Mein Vortrag zur Datenstrategie am Data Leader Day 2017
Mein Vortrag zur Datenstrategie am Data Leader Day 2017