Data & AI im Unternehmen zu etablieren ist ein Prozess, der eine fachlich kompetente Führung benötigt. Hier kann Interim Management die Lösung sein.
Unternehmer stehen dabei vor großen Herausforderungen und stellen sich oft diese oder ähnliche Fragen:
Welche Top-Level Strategie brauche ich?
Wo und wie finde ich die ersten Show Cases im Unternehmen?
Habe ich aktuell den richtigen Daten back-bone?
Diese Fragen beantwortet Benjamin Aunkofer (Gründer von DATANOMIQ und AUDAVIS) im Interview mit Atreus Interim Management. Er erläutert, wie Unternehmen die Disziplinen Data Science, Business Intelligence, Process Mining und KI zusammenführen können, und warum Interim Management dazu eine gute Idee sein kann.
Video Interview “Meet the Manager” auf Youtube mit Franz Kubbillum von Atreus Interim Management und Benjamin Aunkofer von DATANOMIQ.
Über Benjamin Aunkofer
Benjamin Aunkofer – Interim Manager für Data & AI, Gründer von DATANOMIQ und AUDAVIS.
Benjamin Aunkofer ist Gründer des Beratungs- und Implementierungspartners für Daten- und KI-Lösungen namens DATANOMIQ sowie Co-Gründer der AUDAVIS, einem AI as a Service für die Wirtschaftsprüfung.
Nach seiner Ausbildung zum Software-Entwickler (FI-AE IHK) und seinem Einstieg als Consultant bei Deloitte, gründete er 2015 die DATANOMIQ GmbH in Berlin und unterstütze mit mehreren kleinen Teams Unternehmen aus unterschiedlichen Branchen wie Handel, eCommerce, Finanzdienstleistungen und der produzierenden Industrie (Pharma, Automobilzulieferer, Maschinenbau). Er partnert mit anderen Unternehmensberatungen und unterstütze als externer Dienstleister auch Wirtschaftsprüfungsgesellschaften.
Der Projekteinstieg in Unternehmen erfolgte entweder rein projekt-basiert (Projektangebot) oder über ein Interim Management z. B. als Head of Data & AI, Chief Data Scientist oder Head of Process Mining.
Im Jahr 2023 gründete Benjamin Aunkofer mit zwei Mitgründern die AUDAVIS GmbH, die eine Software as a Service Cloud-Plattform bietet für Wirtschaftsprüfungsgesellschaften, Interne Revisionen von Konzernen oder für staatliche Prüfung von Finanztransaktionen.
https://data-science-blog.com/de/wp-content/uploads/sites/5/2024/03/benjamin-aunkofer-franz-kubbillum-interview-meet-the-manager.png10541802Redaktionhttps://data-science-blog.com/de/wp-content/uploads/sites/5/2016/12/data-science-blog-logo-de-300x284.pngRedaktion2024-03-13 10:13:282024-03-13 10:13:30Video Interview – Interim Management für Daten & KI
Die Verwendung von Künstlicher Intelligenz (KI) in der Wirtschaftsprüfung, wie Sie es beschreiben, klingt in der Tat revolutionär. Die Integration von KI in diesem Bereich könnte enorme Vorteile mit sich bringen, insbesondere in Bezug auf Effizienzsteigerung und Genauigkeit.
Die verschiedenen von Ihnen genannten Lernmethoden wie (Un-)Supervised Learning, Reinforcement Learning und Federated Learning bieten unterschiedliche Ansätze, um KI-Systeme für spezifische Anforderungen der Wirtschaftsprüfung zu trainieren. Diese Methoden ermöglichen es, aus großen Datenmengen Muster zu erkennen, Vorhersagen zu treffen und Entscheidungen zu optimieren.
Der Artificial Auditor von AUDAVIS, der auf einer Kombination von verschiedenen KI-Verfahren basiert, könnte beispielsweise in der Lage sein, 100% der Buchungsdaten zu analysieren, was mit herkömmlichen Methoden praktisch unmöglich wäre. Dies würde nicht nur die Genauigkeit der Prüfung verbessern, sondern auch Betrug und Fehler effektiver aufdecken.
Der Punkt, den Sie über den Podcast Unf*ck Your Datavon Dr. Christian Krug und die Aussagen von Benjamin Aunkofer ansprechen, ist ebenfalls interessant. Es scheint, dass die Diskussion darüber, wie Datenautomatisierung und KI die Wirtschaftsprüfung effizienter gestalten können, bereits im Gange ist und dabei hilft, das Bewusstsein für diese Technologien zu schärfen und ihre Akzeptanz in der Branche zu fördern.
Es wird dabei im Podcast betont, dass die Rolle des menschlichen Prüfers durch KI nicht ersetzt, sondern ergänzt wird. KI kann nämlich dabei helfen, Routineaufgaben zu automatisieren und komplexe Datenanalysen durchzuführen, während menschliche Experten weiterhin für ihre Fachkenntnisse, ihr Urteilsvermögen und ihre Fähigkeit, den Kontext zu verstehen, unverzichtbar bleiben.
Insgesamt spricht Benjamin Aunkofer darüber, dass die Integration von KI in die Wirtschaftsprüfung bzw. konkret in der Jahresabschlussprüfung ein aufregender Schritt in Richtung einer effizienteren und effektiveren Zukunft sei, der sowohl Unternehmen als auch die gesamte Volkswirtschaft positiv beeinflussen wird.
Benjamin Aunkofer – Podcast – KI in der Wirtschaftsprüfung
https://data-science-blog.com/de/wp-content/uploads/sites/5/2024/01/benjamin_header.png3501400Redaktionhttps://data-science-blog.com/de/wp-content/uploads/sites/5/2016/12/data-science-blog-logo-de-300x284.pngRedaktion2024-01-22 23:09:502024-05-09 21:27:17Podcast – KI in der Wirtschaftsprüfung
Der Data Literacy Day 2023 findet am 7. November 2023 in Berlin oder bequem von zu Hause aus statt.Eine hybride Veranstaltung zum Thema Datenkompetenz.
Darum geht es bei der hybriden Daten-Konferenz.
Data Literacy ist heutzutage ein Must-have – beruflich wie privat. Seit 2021 wird Datenkompetenz von der Bundesregierung als unverzichtbares Grundwissen eingestuft. Doch der Umgang mit Daten will gelernt sein. Wie man Data Literacy in der deutschen Bevölkerung verankert und wie Bürger:innen zu Data Citizens werden, kannst Du am 7. November 2023 mit den wichtigsten Köpfen der Branche am #DLD23 im Basecamp Berlin oder online von zu Hause aus diskutieren.
Lerne von den Besten der Branche.
Am Data Literacy Day 2023 kommen führende Expert:innen aus den Bereichen Politik, Wirtschaft und Forschung zusammen. In Diskussionen, Vorträgen und Roundtables sprechen wir über Initiativen, mit dessen Hilfe Datenkompetenzen flächendeckend über alle Berufs- und Gesellschaftsbereiche hinweg in Deutschland verankert werden.
StackFuel garantiert den Schulungserfolg mit bewährtem Trainingskonzept dank der Online-Lernumgebung. Ob im Data Science Onlinekurs oder Python-Weiterbildung, mit StackFuel lernen Studenten und Arbeitskräfte, wie mit Daten in der Wirklichkeit nutzbringend umgegangen und das volle Potenzial herrausgeholt werden kann.
https://data-science-blog.com/de/wp-content/uploads/sites/5/2023/10/dld-2023-header.png13883763Redaktionhttps://data-science-blog.com/de/wp-content/uploads/sites/5/2016/12/data-science-blog-logo-de-300x284.pngRedaktion2023-10-27 10:27:302023-10-27 10:27:31Data Literacy Day 2023 by StackFuel
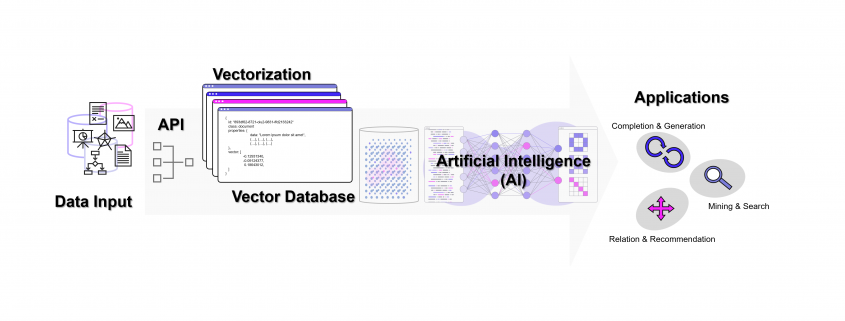
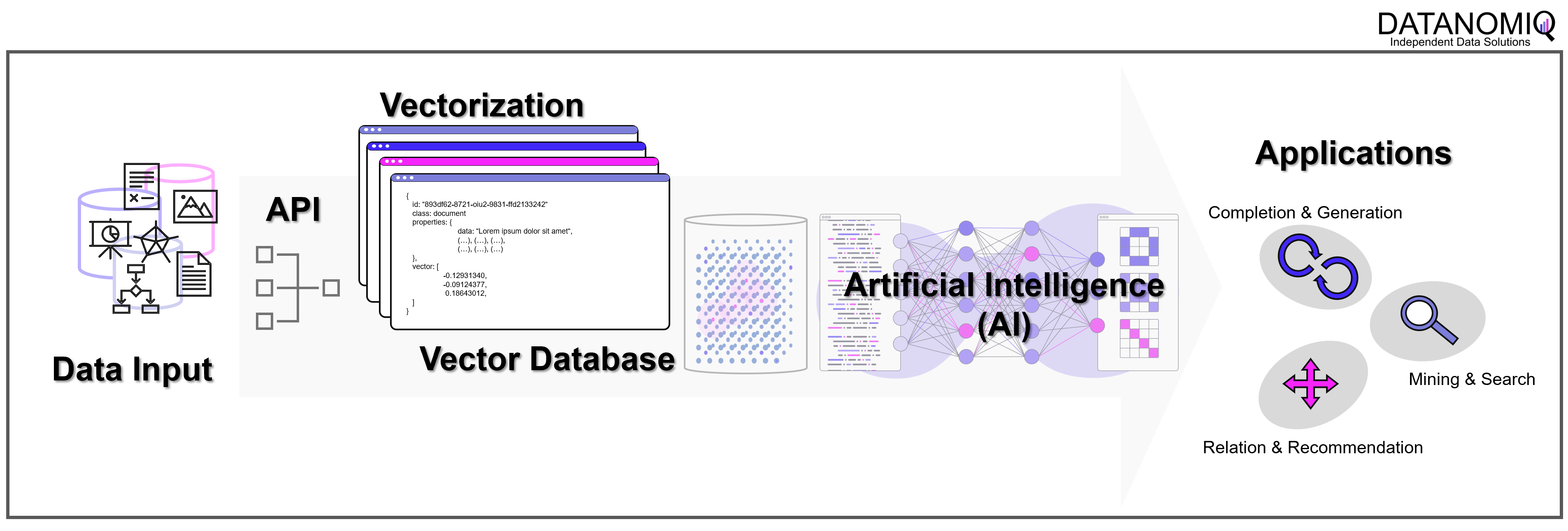
Wie können Unternehmen und andere Organisationen sicherstellen, dass kein Wissen verloren geht? Intranet, ERP, CRM, DMS oder letztendlich einfach Datenbanken mögen die erste Antwort darauf sein. Doch Datenbanken sind nicht gleich Datenbanken, ganz besonders, da operative IT-Systeme meistens auf relationalen Datenbanken aufsetzen. In diesen geht nur leider dann doch irgendwann das Wissen verloren… Und das auch dann, wenn es nie aus ihnen herausgelöscht wird!
Die meisten Datenbanken sind darauf ausgelegt, Daten zu speichern und wieder abrufbar zu machen. Neben den relationalen Datenbanken (SQL) gibt es auch die NoSQL-Datenbanken wie den Key-Value-Store, Dokumenten- und Graph-Datenbanken mit recht speziellen Anwendungsgebieten. Vektor-Datenbanken sind ein weiterer Typ von Datenbank, die unter Einsatz von AI (Deep Learning, n-grams, …) Wissen in Vektoren übersetzen und damit vergleichbarer und wieder auffindbarer machen. Diese Funktion der Datenbank spielt seinen Vorteil insbesondere bei vielen Dimensionen aus, wie sie Text- und Bild-Daten haben.
Datenbank-Typen in grobkörniger Darstellung. Es gibt in der Realität jedoch viele Feinheiten, Übergänge und Überbrückungen zwischen den Datenbanktypen, z. B. zwischen emulierter und nativer Graph-Datenbank. Manche Dokumenten- Vektor-Datenbanken können auch relationale Datenmodellierung. Und eigentlich relationale Datenbanken wie z. B. PostgreSQL können mit Zusatzmodulen auch Vektoren verarbeiten.
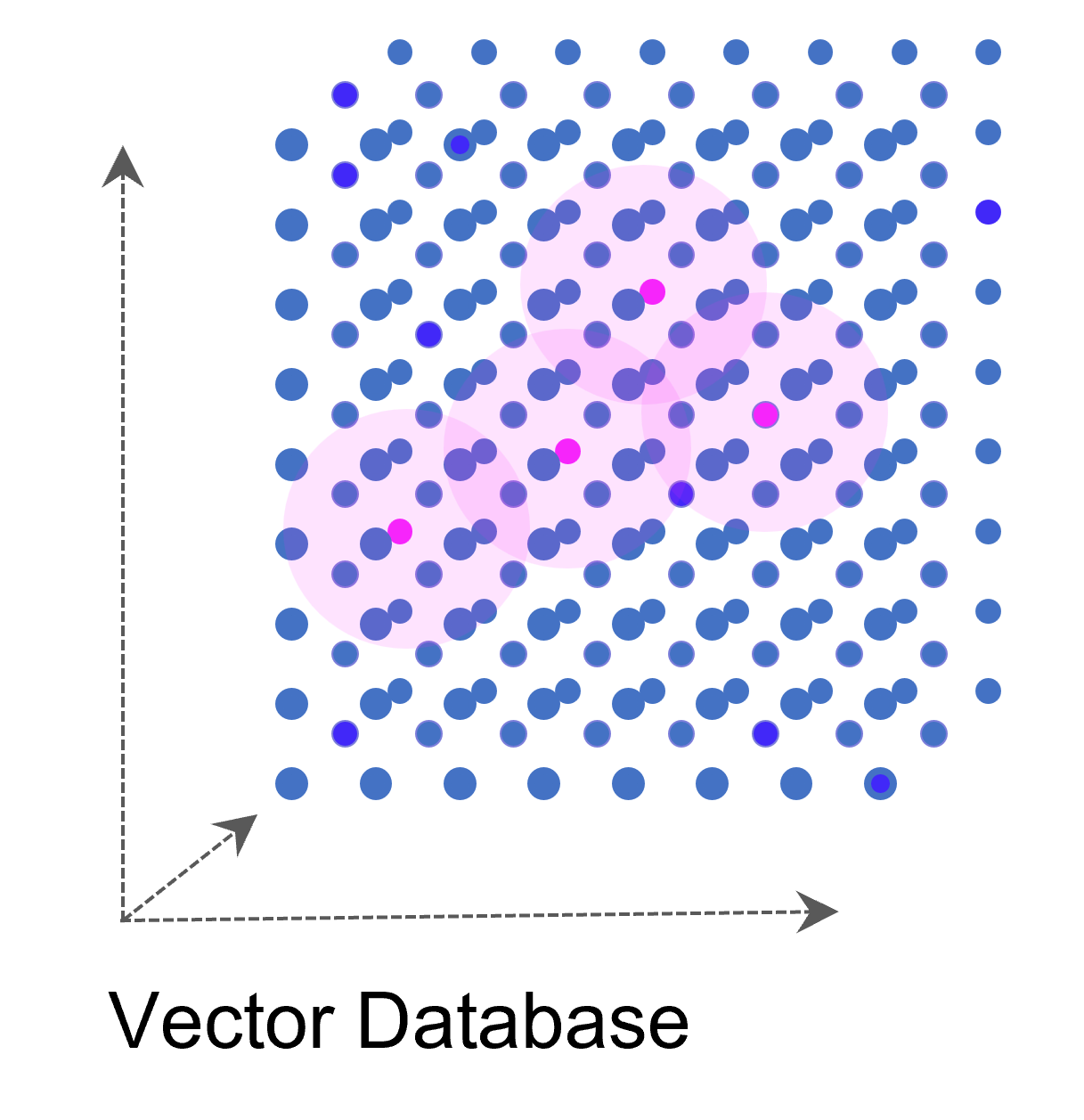
Vektor-Datenbanken speichern Daten grundsätzlich nicht relational oder in einer anderen Form menschlich konstruierter Verbindungen. Dennoch sichert die Datenbank gewissermaßen Verbindungen indirekt, die von Menschen jedoch – in einem hochdimensionalen Raum – nicht mehr hergeleitet werden können und sich auf bestimmte Kontexte beziehen, die sich aus den Daten selbst ergeben. Maschinelles Lernen kommt mit der nummerischen Auflösung von Text- und Bild-Daten (und natürlich auch bei ganz anderen Daten, z. B. Sound) am besten zurecht und genau dafür sind Vektor-Datenbanken unschlagbar.
Was ist eine Vektor-Datenbank?
Eine Vektordatenbank speichert Vektoren neben den traditionellen Datenformaten (Annotation) ab. Ein Vektor ist eine mathematische Struktur, ein Element in einem Vektorraum, der eine Reihe von Dimensionen hat (oder zumindest dann interessant wird, genaugenommen starten wir beim Null-Vektor). Jede Dimension in einem Vektor repräsentiert eine Art von Information oder Merkmal. Ein gutes Beispiel ist ein Vektor, der ein Bild repräsentiert: jede Dimension könnte die Intensität eines bestimmten Pixels in dem Bild repräsentieren.
Auf diese Weise kann eine ganze Sammlung von Bildern als eine Sammlung von Vektoren dargestellt werden. Noch gängiger jedoch sind Vektorräume, die Texte z. B. über die Häufigkeit des Auftretens von Textbausteinen (Wörter, Silben, Buchstaben) in sich einbetten (Embeddings). Embeddings sind folglich Vektoren, die durch die Projektion des Textes auf einen Vektorraum entstehen.
Vektor-Datenbanken sind besonders nützlich, wenn man Ähnlichkeiten zwischen Vektoren finden muss, z. B. ähnliche Bilder in einer Sammlung oder die Wörter “Hund” und “Katze”, die zwar in ihren Buchstaben keine Ähnlichkeit haben, jedoch in ihrem Kontext als Haustiere. Mit Vektor-Algorithmen können diese Ähnlichkeiten schnell und effizient aufgespürt werden, was sich mit traditionellen relationalen Datenbanken sehr viel schwieriger und vor allem ineffizienter darstellt.
Vektordatenbanken können auch hochdimensionale Daten effizient verarbeiten, was in vielen modernen Anwendungen, wie zum Beispiel Deep Learning, wichtig ist. Einige Beispiele für Vektordatenbanken sind Elasticsearch / Vector Search, Weaviate, Faiss von Facebook und Annoy von Spotify.
Viele Lernalgorithmen des maschinellen Lernens basieren auf Vektor-basierter Ähnlichkeitsmessung, z. B. der k-Nächste-Nachbarn-Prädiktionsalgorithmus (Regression/Klassifikation) oder K-Means-Clustering. Die Ähnlichkeitsbetrachtung erfolgt mit Distanzmessung im Vektorraum. Die dafür bekannteste Methode, die Euklidische Distanz zwischen zwei Punkten, basiert auf dem Satz des Pythagoras (Hypotenuse ist gleich der Quadratwurzel aus den beiden Dimensions-Katheten im Quadrat, im zwei-dimensionalen Raum). Es kann jedoch sinnvoll sein, aus Gründen der Effizienz oder besserer Konvergenz des maschinellen Lernens andere als die Euklidische Distanz in Betracht zu ziehen.
Der Aufbau von künstlichen Neuronalen Netzen im Deep Learning sieht nicht vor, dass ganze Sätze in ihren textlichen Bestandteilen in das jeweilige Netz eingelesen werden, denn sie funktionieren am besten mit rein nummerischen Input. Die Texte müssen in diese transformiert werden, eventuell auch nach diesen in Cluster eingeteilt und für verschiedene Trainingsszenarien separiert werden.
Vektordatenbanken werden für die Datenvorbereitung (Annotation) und als Trainingsdatenbank für Deep Learning zur effizienten Speicherung, Organisation und Manipulation der Texte genutzt. Für Natural Language Processing (NLP) benötigen Modelle des Deep Learnings die zuvor genannten Word Embedding, also hochdimensionale Vektoren, die Informationen über Worte, Sätze oder Dokumente repräsentieren. Nur eine Vektordatenbank macht diese effizient abrufbar.
Vektor-Datenbank und Large Language Modells (LLM)
Ohne Vektor-Datenbanken wären die Erfolge von OpenAI und anderen Anbietern von LLMs nicht möglich geworden. Aber fernab der Entwicklung in San Francisco kann jedes Unternehmen unter Einsatz von Vektor-Datenbanken und den APIs von Google, OpenAI / Microsoft oder mit echten Open Source LLMs (Self-Hosting) ein wahres Orakel über die eigenen Unternehmensdaten herstellen. Dazu werden über APIs die Embedding-Engines z. B. von OpenAI genutzt. Wir von DATANOMIQ nutzen diese Architektur, um Unternehmen und andere Organisationen dazu zu befähigen, dass kein Wissen mehr verloren geht.
Mit der DATANOMIQ Enterprise AI Architektur, die auf jeder Cloud ausrollfähig ist, verfügen Unternehmen über einen intelligenten Unternehmens-Repräsentanten als KI, der für Mitarbeiter relevante Dokumente und Antworten auf Fragen liefert. Sollte irgendein Mitarbeiter im Unternehmen bereits einen bestimmten Vorgang, Vorfall oder z. B. eine technische Konstruktion oder einen rechtlichen Vertrag bearbeitet haben, der einem aktuellen Fall ähnlich ist, wird die AI dies aufspüren und sinnvollen Kontext, Querverweise oder Vorschläge oder lückenauffüllende Daten liefern.
Die AI lernt permanent mit, Unternehmenswissen geht nicht verloren. Das ist Wissensmanagement auf einem neuen Level, dank Vektor-Datenbanken und KI.
https://data-science-blog.com/de/wp-content/uploads/sites/5/2023/05/vector-database-ai-based-applications-enterprise-text-search-generator-datanomiq-header.png16204618Benjamin Aunkoferhttps://data-science-blog.com/de/wp-content/uploads/sites/5/2016/12/data-science-blog-logo-de-300x284.pngBenjamin Aunkofer2023-05-22 11:59:292023-05-23 07:51:54Was ist eine Vektor-Datenbank? Und warum spielt sie für AI eine so große Rolle?
Das Format Business Talk am Kudamm in Berlin führte ein Interview mit Benjamin Aunkofer zu den Themen “Daten vermarkten, nicht verkaufen!”.
In dem Interview erklärt Benjamin Aunkofer, warum der Datenschutz für die meisten Anwendungsfälle keine Rolle spielt und wie Unternehmen mit Data as a Service oder AI as a Service Ihre Daten zu Geld machen, selbst dann, wenn diese Daten nicht herausgegeben werden können.
Nachfolgend das Interview auf Youtube sowie die schriftliche Form zum Nachlesen:
Nachfolgend das Transkript zum Interview:
1 – Herr Aunkofer, Daten gelten als der wichtigste Rohstoff des 22. Jahrhunderts. Bei der Vermarktung datengestützter Dienstleistung tun sich deutsche Unternehmen im Vergleich zur Konkurrenz aus den USA oder Asien aber deutlich schwerer. Woran liegt das?
Ach da will ich keinen Hehl draus machen. Die Unterschiede liegen in den verschiedenen Kulturen begründet. In den USA herrscht in der Gesellschaft ein sehr freiheitlicher Gedanke, der wohl eher darauf hinausläuft, dass wer Daten sammelt, über diese dann eben auch weitgehend verfügt.
In Asien ist die Kultur eher kollektiv ausgerichtet, um den Einzelnen geht es dort ja eher nicht so.
In Deutschland herrscht auch ein freiheitlicher Gedanke – Gott sei Dank – jedoch eher um den Schutz der personenbezogenen Daten.
Das muss nun aber gar nicht schlimm sein. Zwar mag es in Deutschland etwas umständlicher und so einen Hauch langsamer sein, Daten nutzen zu dürfen. Bei vielen Anwendungsfällen kann man jedoch sehr gut mit korrekt anonymisierten Massendaten arbeiten und bei gesellschaftsfördernen Anwendungsfällen, man denke z. B. an medizinische Vorhersagen von Diagnosen oder Behandlungserfolgen oder aber auch bei der Optimierung des öffentlichen Verkehrs, sind ja viele Menschen durchaus bereit, ihre Daten zu teilen.
Gesellschaftlichen Nutzen haben wir aber auch im B2B Geschäft, bei dem wir in Unternehmen und Institutionen die Prozesse kundenorientierter und schneller machen, Maschinen ausfallsicherer machen usw.. Da haben wir meistens sogar mit gar keinen personenbezogenen Daten zu tun.
2 – Sind die Bedenken im Zusammenhang mit Datenschutz und dem Schutz von Geschäftsgeheimnissen nicht berechtigt?
Also mit Datenschutz ist ja der gesetzliche Datenschutz gemeint, der sich nur auf personenbezogene Daten bezieht. Für Anwendungsfälle z. B. im Customer Analytics, also da, wo man Kundendaten analysieren möchte, geht das nur über die direkte Einwilligung oder eben durch anonymisierte Massendaten. Bei betrieblicher Prozessoptimierung, Anlagenoptimierung hat man mit personenbezogenen Daten aber fast nicht zu tun bzw. kann diese einfach vorher wegfiltern.
Ein ganz anderes Thema ist die Datensicherheit. Diese schließt die Sicherheit von personenbezogenen Daten mit ein, betrifft aber auch interne betriebliche Angelegenheiten, so wie etwas Lieferanten, Verträge, Preise… vielleicht Produktions- und Maschinendaten, natürlich auch Konstruktionsdaten in der Industrie.
Dieser Schutz ist jedoch einfach zu gewährleisten, wenn man einige Prinzipien der Datensicherheit verfolgt. Wir haben dafür Checklisten, quasi wie in der Luftfahrt. Bevor der Flieger abhebt, gehen wir die Checks durch… da stehen so Sachen drauf wie Passwortsicherheit, Identity Management, Zero Trust, Hybrid Cloud usw.
3 – Das Rückgrat der deutschen Wirtschaft sind die vielen hochspezialisierten KMU. Warum sollte sich beispielsweise ein Maschinenbauer darüber Gedanken machen, datengestützte Geschäftsmodelle zu entwickeln?
Nun da möchte ich dringend betonen, dass das nicht nur für Maschinenbauer gilt, aber es stimmt schon, dass Unternehmen im Maschinenbau, in der Automatisierungstechnik und natürlich der Werkzeugmaschinen richtig viel Potenzial haben, ihre Geschäftsmodelle mit Daten auszubauen oder sogar Datenbestände aufzubauen, die dann auch vermarktet werden können, und das so, dass diese Daten das Unternehmen gar nicht verlassen und dabei geheim bleiben.
4 – Daten verkaufen, ohne diese quasi zu verkaufen? Wie kann das funktionieren?
Das verrate ich gleich, aber reden wir vielleicht kurz einmal über das Verkaufen von Daten, die man sogar gerne verkauft. Das Verkaufen von Daten ist nämlich gerade so ein Trend. Das Konzept dafür heißt Data as a Service und bezieht sich dabei auf öffentliche Daten aus Quellen der Kategorie Open Data und Public Data. Diese Daten können aus dem Internet quasi gesammelt, als Datenbasis dann im Unternehmen aufgebaut werden und haben durch die Zusammenführung, Bereinigung und Aufbereitung einen Wert, der in die Millionen gehen kann. Denn andere Unternehmen brauchen vielleicht auch diese Daten, wollen aber nicht mehr warten, bis sie diese selbst aufbauen. Beispiele dafür sind Daten über den öffentlichen Verkehr, Infrastruktur, Marktpreise oder wir erheben z. B. für einen Industriekonzern Wasserqualitätsdaten beinahe weltweit aus den vielen vielen regionalen Veröffentlichungen der Daten über das Trinkwasser. Das sind zwar hohe Aufwände, aber der Wert der zusammengetragenen Daten ist ebenfalls enorm und kann an andere Unternehmen weiterverkauft werden. Und nur an jene Unternehmen, an die man das eben zu tun bereit ist.
5 – Okay, das sind öffentliche Daten, die von Unternehmen nutzbar gemacht werden. Aber wie ist es nun mit Daten aus internen Prozessen?
Interne Daten sind Geschäftsgeheimnisse und dürfen keinesfalls an Dritte weitergegeben werden. Dazu gehören beispielsweise im Handel die Umsatzkurven für bestimmte Produktkategorien sowie aber auch die Retouren und andere Muster des Kundenverhaltens, z. B. die Reaktion auf die Konfiguration von Online-Marketingkampagnen. Die Unternehmen möchten daraus jedoch Vorhersagemodelle oder auch komplexere Anomalie-Erkennung auf diese Daten trainieren, um sie für sich in ihren operativen Prozessen nutzbar zu machen. Machine Learning, übrigens ein Teilgebiet der KI (Künstlichen Intelligenz), funktioniert ja so, dass man zwei Algorithmen hat. Der erste Algorithmus ist ein Lern-Algorithmus. Diesen muss man richtig parametrisieren und überhaupt erstmal den richtigen auswählen, es gibt nämlich viele zur Auswahl und ja, die sind auch miteinander kombinierbar, um gegenseitige Schwächen auszugleichen und in eine Stärke zu verwandeln. Der Lernalgorithmus erstellt dann, über das Training mit den Daten, ein Vorhersagemodell, im Grunde eine Formel. Das ist dann der zweite Algorithmus. Dieser Algorithmus entstand aus den Daten und reflektiert auch das in den Daten eingelagerte Wissen, kanalisiert als Vorhersagemodell. Und dieses kann dann nicht nur intern genutzt werden, sondern auch anderen Unternehmen zur Nutzung zur Verfügung gestellt werden.
6 – Welche Arten von Problemen sind denn geeignet, um aus Daten ein neues Geschäftsmodell entwickeln zu können?
Alle operativen Geschäftsprozesse und deren Unterformen, also z. B. Handels-, Finanz-, Produktions- oder Logistikprozesse generieren haufenweise Daten. Das Problem für ein Unternehmen wie meines ist ja, dass wir zwar Analysemethodik kennen, aber keine Daten. Die Daten sind quasi wie der Inhalt einer Flasche oder eines Ballons, und der Inhalt bestimmt die Form mit. Unternehmen mit vielen operativen Prozessen haben genau diese Datenmengen.Ein Anwendungsfallgebiet sind z. B. Diagnosen. Das können neben medizinischen Diagnosen für Menschen auch ganz andere Diagnosen sein, z. B. über den Zustand einer Maschine, eines Prozesses oder eines ganzen Unternehmens. Die Einsatzgebiete reichen von der medizinischen Diagnose bis hin zu der Diagnose einer Prozesseffizienz oder eines Zustandes in der Wirtschaftsprüfung.Eine andere Kategorie von Anwendungsfällen sind die Prädiktionen durch Text- oder Bild-Erkennung. In der Versicherungsindustrie oder in der Immobilienbranche B. gibt es das Geschäftsmodell, dass KI-Modelle mit Dokumenten trainiert werden, so dass diese automatisiert, maschinell ausgelesen werden können. Die KI lernt dadurch, welche Textstellen im Dokument oder welche Objekte im Bild eine Rolle spielen und verwandelt diese in klare Aussagen.
Die Industrie benutzt KI zur generellen Objekterkennung z. B. in der Qualitätsprüfung. Hersteller von landwirtschaftlichen Maschinen trainieren KI, um Unkraut über auf Videobildern zu erkennen. Oder ein Algorithmus, der gelernt hat, wie Ultraschalldaten von Mirkochips zu interpretieren sind, um daraus Beschädigungen zu erkennen, so als Beispiel, den kann man weiterverkaufen.
Das Verkaufen erfolgt dabei idealerweise hinter einer technischen Wand, abgeschirmt über eine API. Eine API ist eine Schnittstelle, über die man die KI verwenden kann. Daraus wird dann AI as a Service, also KI als ein Service, den man Dritten gegen Bezahlung nutzen lassen kann.
7 – Gehen wir mal in die Praxis: Wie lassen sich aus erhobenen Daten Modelle entwickeln, die intern genutzt oder als Datenmodell an Kunden verkauft werden können?
Zuerst müssen wir die Idee natürlich richtig auseinander nehmen. Nach einer kurzen Euphorie-Phase, wie toll die Idee ist, kommt ja dann oft die Ernüchterung. Oft überwinden wir aber eben diese Ernüchterung und können starten. Der einzige Knackpunkt sind meistens fehlende Daten, denn ja, wir reden hier von großen Datenhistorien, die zum Einen überhaupt erstmal vorliegen müssen, zum anderen aber auch fast immer aufbereitet werden müssen.Wenn das erledigt ist, können wir den Algorithmus trainieren, ihn damit auf eine bestimmte Problemlösung sozusagen abrichten.Übrigens können Kunden oder Partner die KI selbst nachtrainieren, um sie für eigene besondere Zwecke besser vorzubereiten. Nehmen wir das einfache Beispiel mit der Unkrauterkennung via Bilddaten für landwirtschaftliche Maschinen. Nun sieht Unkraut in fernen Ländern sicherlich ähnlich, aber doch eben anders aus als hier in Mitteleuropa. Der Algorithmus kann jedoch nachtrainiert werden und sich der neuen Situation damit anpassen. Hierfür sind sehr viel weniger Daten nötig als es für das erstmalige Anlernen der Fall war.
8 – Viele Unternehmen haben Bedenken wegen des Zeitaufwands und der hohen Kosten für Spezialisten. Wie hoch ist denn der Zeit- und Kostenaufwand für die Implementierung solcher KI-Modelle in der Realität?
Das hängt sehr stark von der eigentlichen Aufgabenstellung ab, ob die Daten dafür bereits vorliegen oder erst noch generiert werden müssen und wie schnell das alles passieren soll. So ein Projekt dauert pauschal geschätzt gerne mal 5 bis 8 Monate bis zur ersten nutzbaren Version.
Sehen Sie die zwei anderen Video-Interviews von Benjamin Aunkofer:
Im Rahmen dieses praxisorientierten Kurses wird anhand eines konkreten Beispiels ein gesamter Prozess zur Mustererkennung nachvollzogen und selbst programmiert. Dabei werden die möglichen Methoden beleuchtet und angewandt.
Aufbaukurs: Angewandte Künstliche Intelligenz
Am 18.1. + 19.1.2023 in Gotha.
Ziele:
– Datenvorverarbeitung zur Nutzung von KI
– Einsatz von Künstlichen Neuronalen Netzen für spezielle Anwendungen (Lernen mit Lehrer)
– Nutzung von Anaconda, Tensorflow und Keras an konkreten Beispielen
– Erarbeitung und Einsatz von KI-Methoden zur Datenverarbeitung
– KI zur Mustererkennung (z. B. k-MEANS, Lernen ohne Lehrer)
Zielgruppe:
– Erfahrene aus den Bereichen Programmierung, Entwicklung, Anwendung
Voraussetzungen:
– Grundlegende Programmierkenntnisse empfehlenswert (aber nicht erforderlich)
Inhalte:
– Datenverarbeitungsmethoden kennenlernen und nutzen
– Programmierung und Nutzung von Klassifizierungsmethoden
– Anwendung vom bestärkenden Lernen (Reinforcement Learning)
– Einsatz kostenloser und kostenpflichtiger Tools zur Datenauswertung
– Umfangreiche Darstellung der Ergebnisse
Ein Schulungstag umfasst 6 Lehrveranstaltungsstunden am 18.1. + 19.1.2023 in Gotha (9.30 Uhr – 15.30 Uhr) und findet großenteils am PC statt. Die Verpflegung ist jeweils inklusive.
Im Rahmen dieses praxisorientierten Kurses wird anhand eines konkreten Beispiels ein gesamter Prozess zur Mustererkennung nachvollzogen und selbst programmiert. Dabei werden die möglichen Methoden beleuchtet und angewandt.
Aufbaukurs: Angewandte Künstliche Intelligenz
Am 2.11. – 3.11.2022 oder 18.1. + 19.1.2023 in Gotha
Ziele:
– Datenvorverarbeitung zur Nutzung von KI
– Einsatz von Künstlichen Neuronalen Netzen für spezielle Anwendungen (Lernen mit Lehrer)
– Nutzung von Anaconda, Tensorflow und Keras an konkreten Beispielen
– Erarbeitung und Einsatz von KI-Methoden zur Datenverarbeitung
– KI zur Mustererkennung (z. B. k-MEANS, Lernen ohne Lehrer)
Zielgruppe:
– Erfahrene aus den Bereichen Programmierung, Entwicklung, Anwendung
Voraussetzungen:
– Grundlegende Programmierkenntnisse empfehlenswert (aber nicht erforderlich)
Inhalte:
– Datenverarbeitungsmethoden kennenlernen und nutzen
– Programmierung und Nutzung von Klassifizierungsmethoden
– Anwendung vom bestärkenden Lernen (Reinforcement Learning)
– Einsatz kostenloser und kostenpflichtiger Tools zur Datenauswertung
– Umfangreiche Darstellung der Ergebnisse
Ausweichtermin:
– 18.1. + 19.1.2023 in Gotha
Ein Schulungstag umfasst 6 Lehrveranstaltungsstunden (9.30 Uhr – 15.30 Uhr) und findet großenteils am PC statt. Die Verpflegung ist jeweils inklusive.
Im Deep Learning gibt es unterschiedliche Trainingsmethoden. Welche wir in einem KI Projekt anwenden, hängt von den zur Verfügung gestellten Daten des Kunden ab: wieviele Daten gibt es, sind diese gelabelt oder ungelabelt? Oder gibt es sowohl gelabelte als auch ungelabelte Daten?
Nehmen wir einmal an, unser Kunde benötigt für sein Tourismusportal strukturierte, gelabelte Bilder. Die Aufgabe für unser KI Modell ist es also, zu erkennen, ob es sich um ein Bild des Schlafzimmers, Badezimmers, des Spa-Bereichs, des Restaurants etc. handelt. Sehen wir uns die möglichen Trainingsmethoden einmal an.
1. Supervised Learning
Hat unser Kunde viele Bilder und sind diese alle gelabelt, so ist das ein seltener Glücksfall. Wir können dann das Supervised Learning anwenden. Dabei lernt das KI Modell die verschiedenen Bildkategorien anhand der gelabelten Bilder. Es bekommt für das Training von uns also die Trainingsdaten mit den gewünschten Ergebnissen geliefert.
Während des Trainings sucht das Modell nach Mustern in den Bildern, die mit den gewünschten Ergebnissen zusammenpassen. So erlernt es Merkmale der Kategorien. Das Gelernte kann das Modell dann auf neue, ungesehene Daten übertragen und auf diese Weise eine Vorhersage für ungelabelte Bilder liefern, also etwa “Badezimmer 98%”.
2. Unsupervised learning
Wenn unser Kunde viele Bilder als Trainingsdaten liefern kann, diese jedoch alle nicht gelabelt sind, müssen wir auf Unsupervised Learning zurückgreifen. Das bedeutet, dass wir dem Modell nicht sagen können, was es lernen soll (die Zuordnung zu Kategorien), sondern es muss selbst Regelmäßigkeiten in den Daten finden.
Eine aktuell gängige Methode des Unsupervised Learning ist Contrastive Learning. Dabei generieren wir jeweils aus einem Bild mehrere Ausschnitte. Das Modell soll lernen, dass die Ausschnitte des selben Bildes ähnlicher zueinander sind als zu denen anderer Bilder. Oder kurz gesagt, das Modell lernt zwischen ähnlichen und unähnlichen Bildern zu unterscheiden.
Über diese Methode können wir zwar Vorhersagen erzielen, jedoch können diese niemals
die Ergebnisgüte von Supervised Learning erreichen.
3. Semi-supervised Learning
Kann uns unser Kunde eine kleine Menge an gelabelten Daten und eine große Menge an nicht gelabelten Daten zur Verfügung stellen, wenden wir Semi-supervised Learning an. Diese Datenlage begegnet uns in der Praxis tatsächlich am häufigsten. Bei fast allen KI Projekten stehen einer kleinen Menge an gelabelten Daten ein Großteil an unstrukturierten
Daten gegenüber.
Mit Semi-supervised Learning können wir beide Datensätze für das Training verwenden. Das gelingt zum Beispiel durch die Kombination von Contrastive Learning und Supervised Learning. Dabei trainieren wir ein KI Modell mit den gelabelten Daten, um Vorhersagen für Raumkategorien zu erhalten. Gleichzeitig lassen wir es Ähnlichkeiten und Unähnlichkeiten in den ungelabelten Daten erlernen und sich daraufhin selbst optimieren. Auf diese Weise können wir letztendlich auch gute Label-Vorhersagen für neue, ungesehene Bilder erzielen.
Fazit: Supervised vs. Unsupervised vs. Semi-supervised
Supervised Learning wünscht sich jeder, der mit einem KI Projekt betraut ist. In der Praxis ist das kaum anwendbar, da selten sämtliche Trainingsdaten gut strukturiert und gelabelt vorliegen.
Wenn nur unstrukturierte und ungelabelte Daten vorhanden sind, dann können wir mit Unsupervised Learning immerhin Informationen aus den Daten gewinnen, die unser Kunde so nicht hätte. Im Vergleich zu Supervised Learning ist aber die Ergebnisqualität deutlich schlechter.
Mit Semi-Supervised Learning versuchen wir das Datendilemma, also kleiner Teil gelabelte, großer Teil ungelabelte Daten, aufzulösen. Wir verwenden beide Datensätze und können gute Vorhersage-Ergebnisse erzielen, deren Qualität dem Supervised Learning oft ebenbürtig sind.
Dieser Artikel entstand in Zusammenarbeit zwischen DATANOMIQ, einem Unternehmen für Beratung und Services rund um Business Intelligence, Process Mining und Data Science. und pixolution, einem Unternehmen für AI Solutions im Bereich Computer Vision (Visuelle Bildsuche und individuelle KI Lösungen).
https://data-science-blog.com/de/wp-content/uploads/sites/5/2022/05/training-of-ai-models.jpg8002106Benjamin Aunkoferhttps://data-science-blog.com/de/wp-content/uploads/sites/5/2016/12/data-science-blog-logo-de-300x284.pngBenjamin Aunkofer2022-08-14 10:25:062022-05-20 12:25:43Alles dreht sich um Daten: die Trainingsmethoden des Deep Learning
Natural Language Understanding (NLU) ist ein Teilbereich von Computer Science, der sich damit beschäftigt natürliche Sprache, also beispielsweise Texte oder Sprachaufnahmen, verstehen und verarbeiten zu können. Das Ziel ist es, dass eine Maschine in der gleichen Weise mit Menschen kommunizieren kann, wie es Menschen untereinander bereits seit Jahrhunderten tun.
Was sind die Bereiche von NLU?
Eine neue Sprache zu erlernen ist auch für uns Menschen nicht einfach und erfordert viel Zeit und Durchhaltevermögen. Wenn eine Maschine natürliche Sprache erlernen will, ist es nicht anders. Deshalb haben sich einige Teilbereiche innerhalb des Natural Language Understandings herausgebildet, die notwendig sind, damit Sprache komplett verstanden werden kann.
Diese Unterteilungen können auch unabhängig voneinander genutzt werden, um einzelne Aufgaben zu lösen:
Speech Recognition versucht aufgezeichnete Sprache zu verstehen und in textuelle Informationen umzuwandeln. Das macht es für nachgeschaltete Algorithmen einfacher die Sprache zu verarbeiten. Speech Recognition kann jedoch auch alleinstehend genutzt werden, beispielsweise um Diktate oder Vorlesungen in Text zu verwandeln.
Part of Speech Tagging wird genutzt, um die grammatikalische Zusammensetzung eines Satzes zu erkennen und die einzelnen Satzbestandteile zu markieren.
Named Entity Recognition versucht innerhalb eines Textes Wörter und Satzbausteine zu finden, die einer vordefinierten Klasse zugeordnet werden können. So können dann zum Beispiel alle Phrasen in einem Textabschnitt markiert werden, die einen Personennamen enthalten oder eine Zeit ausdrücken.
Sentiment Analysis klassifiziert das Sentiment, also die Gefühlslage, eines Textes in verschiedene Stufen. Dadurch kann beispielsweise automatisiert erkannt werden, ob eine Produktbewertung eher positiv oder eher negativ ist.
Natural Language Generation ist eine allgemeine Gruppe von Anwendungen mithilfe derer automatisiert neue Texte generiert werden sollen, die möglichst natürlich klingen. Zum Beispiel können mithilfe von kurzen Produkttexten ganze Marketingbeschreibungen dieses Produkts erstellt werden.
Welche Algorithmen nutzt man für NLP?
Die meisten, grundlegenden Anwendungen von NLP können mit den Python Modulen spaCy und NLTK umgesetzt werden. Diese Bibliotheken bieten weitreichende Modelle zur direkten Anwendung auf einen Text, ohne vorheriges Trainieren eines eigenen Algorithmus. Mit diesen Modulen ist ohne weiteres ein Part of Speech Tagging oder Named Entity Recognition in verschiedenen Sprachen möglich.
Der Hauptunterschied zwischen diesen beiden Bibliotheken ist die Ausrichtung. NLTK ist vor allem für Entwickler gedacht, die eine funktionierende Applikation mit Natural Language Processing Modulen erstellen wollen und dabei auf Performance und Interkompatibilität angewiesen sind. SpaCy hingegen versucht immer Funktionen bereitzustellen, die auf dem neuesten Stand der Literatur sind und macht dabei möglicherweise Einbußen bei der Performance.
Für umfangreichere und komplexere Anwendungen reichen jedoch diese Optionen nicht mehr aus, beispielsweise wenn man eine eigene Sentiment Analyse erstellen will. Je nach Anwendungsfall sind dafür noch allgemeine Machine Learning Modelle ausreichend, wie beispielsweise ein Convolutional Neural Network (CNN). Mithilfe von Tokenizern von spaCy oder NLTK können die einzelnen in Wörter in Zahlen umgewandelt werden, mit denen wiederum das CNN als Input arbeiten kann. Auf heutigen Computern sind solche Modelle mit kleinen Neuronalen Netzwerken noch schnell trainierbar und deren Einsatz sollte deshalb immer erst geprüft und möglicherweise auch getestet werden.
Jedoch gibt es auch Fälle in denen sogenannte Transformer Modelle benötigt werden, die im Bereich des Natural Language Processing aktuell state-of-the-art sind. Sie können inhaltliche Zusammenhänge in Texten besonders gut mit in die Aufgabe einbeziehen und liefern daher bessere Ergebnisse beispielsweise bei der Machine Translation oder bei Natural Language Generation. Jedoch sind diese Modelle sehr rechenintensiv und führen zu einer sehr langen Rechenzeit auf normalen Computern.
Was sind Transformer Modelle?
In der heutigen Machine Learning Literatur führt kein Weg mehr an Transformer Modellen aus dem Paper „Attention is all you need“ (Vaswani et al. (2017)) vorbei. Speziell im Bereich des Natural Language Processing sind die darin erstmals beschriebenen Transformer Modelle nicht mehr wegzudenken.
Transformer werden aktuell vor allem für Übersetzungsaufgaben genutzt, wie beispielsweise auch bei www.deepl.com. Darüber hinaus sind diese Modelle auch für weitere Anwendungsfälle innerhalb des Natural Language Understandings geeignet, wie bspw. das Beantworten von Fragen, Textzusammenfassung oder das Klassifizieren von Texten. Das GPT-2 Modell ist eine Implementierung von Transformern, dessen Anwendungen und die Ergebnisse man hier ausprobieren kann.
Was macht den Transformer so viel besser?
Soweit wir wissen, ist der Transformer jedoch das erste Transduktionsmodell, das sich ausschließlich auf die Selbstaufmerksamkeit (im Englischen: Self-Attention) stützt, um Repräsentationen seiner Eingabe und Ausgabe zu berechnen, ohne sequenzorientierte RNNs oder Faltung (im Englischen Convolution) zu verwenden.
Übersetzt aus dem englischen Originaltext: Attention is all you need (Vaswani et al. (2017)).
In verständlichem Deutsch bedeutet dies, dass das Transformer Modell die sogenannte Self-Attention nutzt, um für jedes Wort innerhalb eines Satzes die Beziehung zu den anderen Wörtern im gleichen Satz herauszufinden. Dafür müssen nicht, wie bisher, Recurrent Neural Networks oder Convolutional Neural Networks zum Einsatz kommen.
Was dieser Mechanismus konkret bewirkt und warum er so viel besser ist, als die vorherigen Ansätze wird im folgenden Beispiel deutlich. Dazu soll der folgende deutsche Satz mithilfe von Machine Learning ins Englische übersetzt werden:
„Das Mädchen hat das Auto nicht gesehen, weil es zu müde war.“
Für einen Computer ist diese Aufgabe leider nicht so einfach, wie für uns Menschen. Die Schwierigkeit an diesem Satz ist das kleine Wort „es“, dass theoretisch für das Mädchen oder das Auto stehen könnte. Aus dem Kontext wird jedoch deutlich, dass das Mädchen gemeint ist. Und hier ist der Knackpunkt: der Kontext. Wie programmieren wir einen Algorithmus, der den Kontext einer Sequenz versteht?
Vor Veröffentlichung des Papers „Attention is all you need“ waren sogenannte Recurrent Neural Networks die state-of-the-art Technologie für solche Fragestellungen. Diese Netzwerke verarbeiten Wort für Wort eines Satzes. Bis man also bei dem Wort „es“ angekommen ist, müssen erst alle vorherigen Wörter verarbeitet worden sein. Dies führt dazu, dass nur noch wenig Information des Wortes „Mädchen“ im Netzwerk vorhanden sind bis den Algorithmus überhaupt bei dem Wort „es“ angekommen ist. Die vorhergegangenen Worte „weil“ und „gesehen“ sind zu diesem Zeitpunkt noch deutlich stärker im Bewusstsein des Algorithmus. Es besteht also das Problem, dass Abhängigkeiten innerhalb eines Satzes verloren gehen, wenn sie sehr weit auseinander liegen.
Was machen Transformer Modelle anders? Diese Algorithmen prozessieren den kompletten Satz gleichzeitig und gehen nicht Wort für Wort vor. Sobald der Algorithmus das Wort „es“ in unserem Beispiel übersetzen will, wird zuerst die sogenannte Self-Attention Layer durchlaufen. Diese hilft dem Programm andere Wörter innerhalb des Satzes zu erkennen, die helfen könnten das Wort „es“ zu übersetzen. In unserem Beispiel werden die meisten Wörter innerhalb des Satzes einen niedrigen Wert für die Attention haben und das Wort Mädchen einen hohen Wert. Dadurch ist der Kontext des Satzes bei der Übersetzung erhalten geblieben.
https://data-science-blog.com/de/wp-content/uploads/sites/5/2022/05/natural-language-understanding.png8051917Niklas Langhttps://data-science-blog.com/de/wp-content/uploads/sites/5/2016/12/data-science-blog-logo-de-300x284.pngNiklas Lang2022-06-03 08:12:552022-05-03 21:35:36Wie Maschinen uns verstehen: Natural Language Understanding
Dieser Artikel ist eine Zusammenfassung der Ergebnisse einer Studie namens “What can AI do for me?” (www.whatcanaidoforme.com) Ansprechpartnerin für dieses Projekt ist Frau Carina Weber, Mitarbeiterin der Hochschule der Medien in Stuttgart.
Hintergrund zur Studie: Zu dem Thema Anwendung von Künstliche Intelligenz und ihrem Potenzial für die Wertschöpfung von Unternehmen gibt es bereits einige wenige Studien. Die wenigen Forschungsarbeiten stellen positive Auswirkungen, wie Produktoptimierung, Kosteneinsparung durch Optimierung des Ressourcenmanagements, Steigerung der allgemein Unternehmensperformance, etc. fest. Allerdings bleibt unerforscht welchen individuellen Beitrag spezifische Anwendungsfälle leisten. Dieses Wissen wird jedoch für strategische Entscheidungen bezüglich der Implementierung von AI benötigt, um beispielsweise den ROI von AI-Projekten schätzen zu können. Dazu soll die vorliegende Studie Einsicht bringen.
Darüberhinaus wurden die Ergebnisse genutzt um im Rahmen des Verbundforschungsprojekts What Can AI Do For Me? eine AI-basierte Matching-Plattform zu entwickeln. Eine bis jetzt einzigartige Anwendung, mittels derer Unternehmen individuelle AI-Anwendungsfälle mit ihren jeweiligen Potenzialen kennenlernen und sich direkt mit Lösungsanbietern verknüpfen lassen können.
Beispiele: Praktische Anwendung von AI – Mit welchen Herausforderungen sehen sich Unternehmen konfrontiert?
Schon heute stellt Artificial Intelligence, folgend abgekürzt mit AI, im unternehmerischen
Sinne eine Schlüsseltechnologie dar. Es stellt sich jedoch die Frage, inwieweit sich die Technologien rund um AI tatsächlich auf die essentiellen Unternehmensziele auswirken und mit welchen Hindernissen sich die Unternehmen bei der Implementierung konfrontiert sehen.
In der AI Value Creation Studie des Forschungsprojekts “What can AI do for me” ist man mit Unterstützung von Expertinnen und Experten, sowohl auf Anwenderseite, als auch auf der von Nutzerinnen und Nutzer, dieser Fragestellung, durch eine qualitative und quantitative Forschung nachgegangen.
Unsicher beim Einsatz von AI? Die Studie bietet Orientierungshilfe
Das Institute of Applied Artificial Intelligence (IAAI) der Hochschule der Medien entwickelt im Rahmen des oben genannten Verbundforschungsprojekts zusammen mit der thingsTHINKING GmbH und der KENBUN IT AG eine AI-basierte Matching-Plattform, mittels derer Unternehmen geeignete Anwendungsmöglichkeiten und Lösungsunternehmen finden können. Gefördert wurde das Projekt im Jahr 2021 über den KI-Innovationswettbewerb des Ministeriums für Wirtschaft, Arbeit und Tourismus Baden-Württemberg und erhielt zusätzliche Unterstützung von bekannten AI-Initiativen und Verbänden. So konnte am 19. Oktober die Inbetriebnahme der Beta-Version erfolgreich gestartet werden. Sie steht seitdem unter der Domain WhatCanAIDoForMe.com kostenfrei zur Verfügung.
Die Basis der Annahmen der Matching-Plattform bilden die Ergebnisse der AI Value Creation Studie des IAAI der Hochschule der Medien. Im Verlauf der qualitativen Forschung konnten über 90 verschiedene AI Use Cases aus der Unternehmenspraxis in über 40 Interviews mit Expertinnen und -experten vielfältigster Branchen identifiziert werden. Die erhobenen Use Cases wurden in insgesamt 19 Use Case Cluster strukturiert, um eine bessere Vergleichbarkeit zu schaffen und gleichzeitig vielfältige Anwendungsmöglichkeiten aufzuzeigen.
Es wird eine Orientierungshilfe für Unternehmen geschaffen, über die sie einen Überblick erlangen können, in welchen Unternehmensfunktionen AI bereits erfolgreich eingesetzt wird.
Des Weiteren sollen durch die Studie Potenziale von AI in Bezug auf die Wertschöpfung, im Sinne einer möglichen Umsatz-, Unternehmenswertsteigerung sowie Kostensenkung, erhoben und Hindernisse bei der Realisierung von AI Use Cases erkannt werden. Zuletzt sollen Unternehmen dazu befähigt werden Stellschrauben zu identifizieren, an welchen sie ansetzen müssen, um AI erfolgreich im Unternehmen einzusetzen.
Im Rahmen der erhobenen Studie wurde einerseits eine Dominanz der AI Use Cases im Bereich der Produktion und Supply Chain, Marketing und Sales sowie im Kundenservice deutlich. Andererseits konnten vielzählige Use Cases ermittelt werden, die crossfunktional in Unternehmen eingesetzt werden können und somit wiederkehrende Tätigkeiten, wie AI-gestützte Recherche in Datenbanken oder Sachbearbeitung von Dokumenten, in Unternehmen unterstützen.
Variierendes Wertschöpfungspotenzial je nach Einsatzbereich und Aufgabe
Gerade bei Use Cases mit AI-Anwendungen, die über verschiedeneUnternehmensfunktionen hinweg eingesetzt werden können, ist die Einschätzung des Wertschöpfungspotenzials abhängig von der individuellen Aufgabe und dem Anwendungsbereich und demnach sehr divers.
Über alle erhobenen Use Cases hinweg tendieren die befragten Personen dazu das Wertschöpfungspotenzial zur Kostenreduktion am höchsten einzuschätzen. Dieses Phänomen kann dadurch erklärt werden, dass ineffiziente Prozesse schnell zu höheren Kosten führen, bei einer beschleunigten, zuverlässigeren Ausführung durch AI das Potenzial zur Kostenersparnis schnell ersichtlich werden kann. Dadurch wurde dieses Wertschöpfungspotenzial im Vergleich zu Umsatz- und Unternehmenswertsteigerung auch häufiger von Expertinnen und Experten identifiziert. Zusätzlich zu diesen Erkenntnissen wurden in Interviews weitere Aspekte bzw. Ziele des
AI-Einsatzes in den Unternehmen abgefragt, die sich abseits schon genannten Wertschöpfungspotenziale indirekt auf die Wertschöpfung und den Unternehmenserfolg auswirken. So wurden neben Prozessoptimierung, die Steigerung der ökologischen und ökonomischen Nachhaltigkeit, die Verbesserung des Unternehmensimages und eine Steigerung der Unternehmensattraktivität genannt.
Fehlende Daten, fehlendes Personal – die Hindernisse bei der Implementierung
In der qualitativen Studie wurden neben den Potenzialen von AI auch Hindernisse und Herausforderungen. Durch eine genaue Systematisierung und Analyse wurde deutlich: der Mangel an Daten, personellen und finanziellen Ressourcen und das fehlendes Mindset machen den Unternehmen zu schaffen. Um diese Ergebnisse besser beurteilen und einschätzen zu können wurden Branchenexpertinnen und -experten gebeten, die ermittelten Herausforderungen im Rahmen einer quantitativen Studie zu bewerten. Die Stichprobe besteht aus Mitarbeiterinnen und Mitarbeiter in beratender Funktion bei AI-Projekte, Managerinnen und Manager mit Entscheidungsfunktion auf diesem Gebiet sowie Unternehmensberaterinnen und -berater aus Beratungsfirmen mit Fokus auf AI-Projekten.
Sehr deutlich wurde hierbei der allgegenwärtige Mangel an Fachpersonal, der von weit mehr als der Hälfte der Befragten angegeben wurde. Zudem ist die gegebenen Datenqualität oft nur unzureichend und es fehlt an AI-Strategien, was sehr große Hindernisse angesehen wurden. Im Vergleich hierzu waren Hindernisse wie ein mangelnder Reifegrad der AI-Technologien und offene Rechtsfragen nur von etwas mehr als einem Drittel der Befragten angegeben worden. Was natürlich zum einen deutlich macht, dass zwar verschiedene Herausforderungen bei der AI-Implementierung gibt, es aber oft in den Händen der Unternehmen liegt inwieweit diese überwunden werden.
Weiterführende Informationen zum Forschungsbericht und dem Projekt
Weitere Ergebnisse und Informationen zur Forschungsmethode können dem Forschungsbericht der Autoren Prof. Dr. Jürgen Seitz, Katharina Willbold, Robin Haiber und Alicia Krafft entnommen werden. Dieser kann vollständig kostenlos unter https://www.hdm-stuttgart.de/iaai_download/ eingesehen werden. Weiterhin steht die AI-basierte Matching-Plattform WhatCanAIDoForMe? des IAAI der Hochschule der Medien, der thingsTHINKING Gmbh und der KENBUN IT AG kostenfrei zur Anwendung bereit.
Hier werden Unternehmen ausgehend von einer Beschreibung zur Problemstellung ihres Business Cases über ein semantisches Matching passende AI-Anwendungsfälle vorgeschlagen. Darüber hinaus wird ein numerisches Wertschöpfungspotenzial aus Basis einer Expertinnen-/ Expertenmeinung angezeigt. Dieses kann als ein erster Indikator für eine Bewertung des AI-Vorhabens herangezogen werden.
Unter der Domain WhatCanAIDoForMe.com kann die Plattform aufgerufen werden.
Autoren
Jürgen Seitz
Dr. Jürgen Seitz ist einer der führenden Professoren im Bereich Digitalisierung in Deutschland. Als Mitbegründer, Geschäftsführer und Beirat hat er geholfen, mehrere erfolgreiche digitale Unternehmen aufzubauen und zu skalieren. Seine beruflichen Stationen umfassten u.A. Microsoft, WEB.DE und die United Internet Gruppe (1&1). Heute forscht und lehrt er an der Hochschule der Medien in Stuttgart in den Bereichen Digital Marketing und Digital Business. Er ist außerdem Gründungsprofessor am Institute for Applied Artificial Intelligence (IAAI), Herausgeber der Digital Insights Studienreihe und engagiert sich für die Digitalisierung von NGOs.
Alicia Krafft
Alicia Krafft, Studentin an der Hochschule der Medien in Stuttgart, absolviert derzeit ihr Masterstudium in Unternehmenskommunikation mit den Schwerpunkten Digitale Medien und Marketing sowie Web Analytics. In den letzten Jahren half sie digitale Kommunikationsstrategien für diverse Unternehmen zu entwickeln und umzusetzen, u.a. für die ARENA2036, ein Forschungscampus der Universität Stuttgart, und zuletzt für das Forschungsteam rund um Dr. Jürgen Seitz.
https://data-science-blog.com/de/wp-content/uploads/sites/5/2022/02/32303793_s.jpg557860Redaktionhttps://data-science-blog.com/de/wp-content/uploads/sites/5/2016/12/data-science-blog-logo-de-300x284.pngRedaktion2022-02-09 08:27:372022-02-08 20:28:04Vorstellung des Verbundforschungsprojekts “What can AI do for me?”







 DATANOMIQ - Benjamin Aunkofer
DATANOMIQ - Benjamin Aunkofer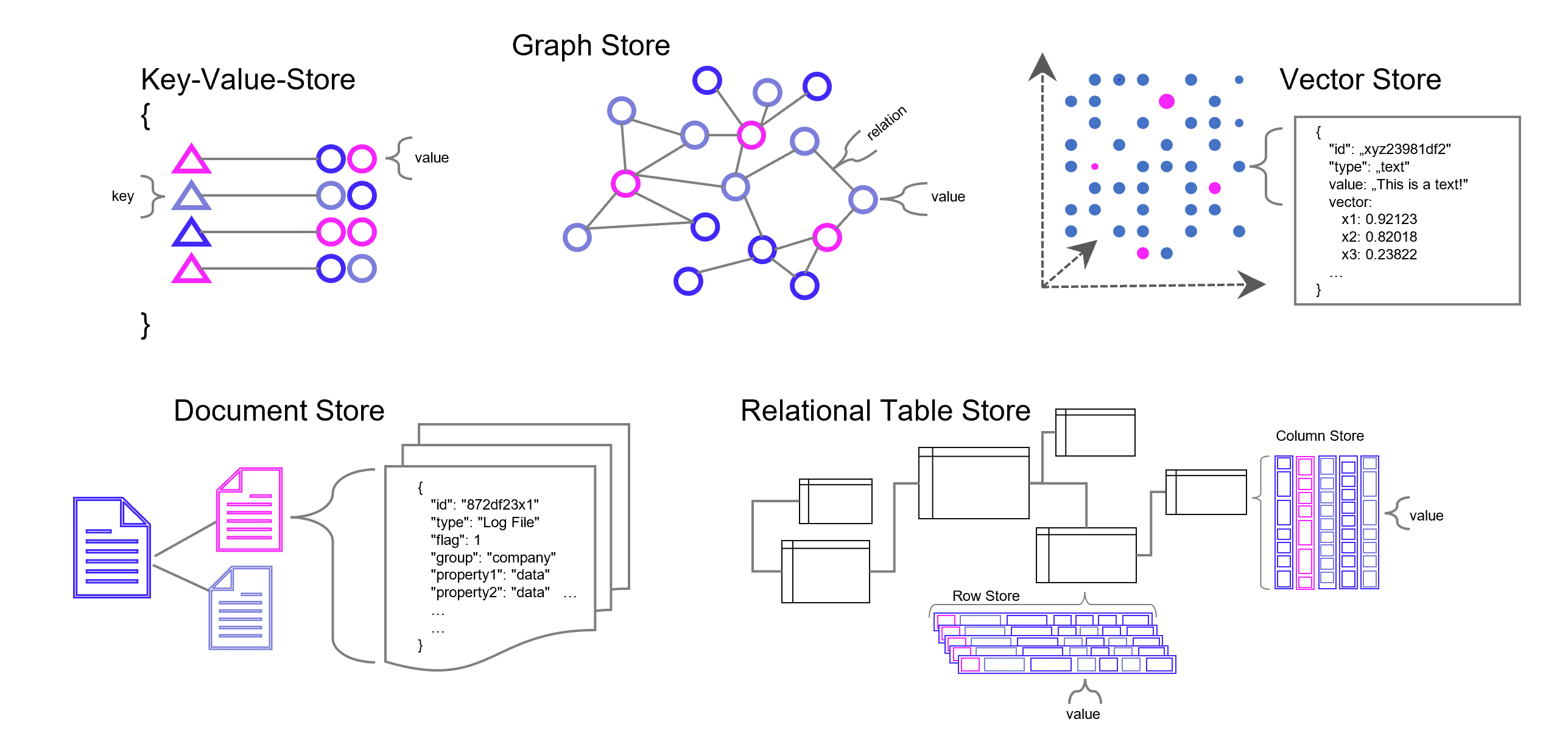
 Weise kann eine ganze Sammlung von Bildern als eine Sammlung von Vektoren dargestellt werden. Noch gängiger jedoch sind Vektorräume, die Texte z. B. über die Häufigkeit des Auftretens von Textbausteinen (Wörter, Silben, Buchstaben) in sich einbetten (Embeddings). Embeddings sind folglich Vektoren, die durch die Projektion des Textes auf einen Vektorraum entstehen.
Weise kann eine ganze Sammlung von Bildern als eine Sammlung von Vektoren dargestellt werden. Noch gängiger jedoch sind Vektorräume, die Texte z. B. über die Häufigkeit des Auftretens von Textbausteinen (Wörter, Silben, Buchstaben) in sich einbetten (Embeddings). Embeddings sind folglich Vektoren, die durch die Projektion des Textes auf einen Vektorraum entstehen.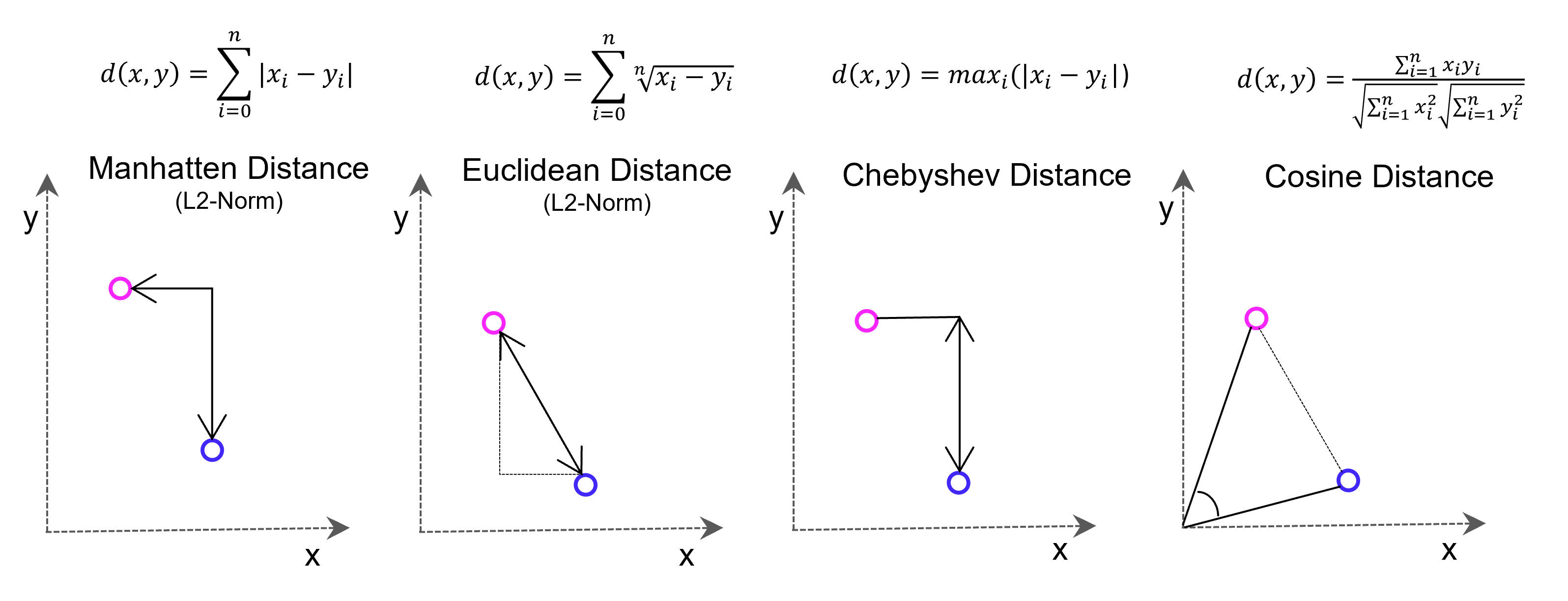





 Jürgen Seitz
Jürgen Seitz Alicia Krafft
Alicia Krafft