Interview mit Gregory Blepp von NetDescribe über Data Analytics zur Überwachung und Optimierung von IT-Netzwerken
Gregory Blepp ist Managing Director der NetDescribe GmbH mit Sitz in Oberhaching im Süden von München. Er befasst sich mit seinem Team aus Consultants, Data Scientists und IT-Netzwerk-Experten mit der technischen Analyse von IT-Netzwerken und der Automatisierung der Analyse über Applikationen.
Data Science Blog: Herr Blepp, der Name Ihres Unternehmens NetDescribe beschreibt tatsächlich selbstsprechend wofür Sie stehen: die Analyse von technischen Netzwerken. Wo entsteht hier der Bedarf für diesen Service und welche Lösung haben Sie dafür parat?
Unsere Kunden müssen nahezu in Echtzeit eine Visibilität über die Leistungsfähigkeit ihrer Unternehmens-IT haben. Dazu gehört der aktuelle Status der Netzwerke genauso wie andere Bereiche, also Server, Applikationen, Storage und natürlich die Web-Infrastruktur sowie Security.
Im Bankenumfeld sind zum Beispiel die uneingeschränkten WAN Verbindungen für den Handel zwischen den internationalen Börsenplätzen absolut kritisch. Hierfür bieten wir mit StableNetⓇ von InfosimⓇ eine Netzwerk Management Plattform, die in Echtzeit den Zustand der Verbindungen überwacht. Für die unterlagerte Netzwerkplattform (Router, Switch, etc.) konsolidieren wir mit GigamonⓇ das Monitoring.
Für Handelsunternehmen ist die Performance der Plattformen für den Online Shop essentiell. Dazu kommen die hohen Anforderungen an die Sicherheit bei der Übertragung von persönlichen Informationen sowie Kreditkarten. Hierfür nutzen wir SplunkⓇ. Diese Lösung kombiniert in idealer Form die generelle Performance Überwachung mit einem hohen Automatisierungsgrad und bietet dabei wesentliche Unterstützung für die Sicherheitsabteilungen.
Data Science Blog: Geht es den Unternehmen dabei eher um die Sicherheitsaspekte eines Firmennetzwerkes oder um die Performance-Analyse zum Zwecke der Optimierung?
Das hängt von den aktuellen Ansprüchen des Unternehmens ab.
Für viele unserer Kunden standen und stehen zunächst Sicherheitsaspekte im Vordergrund. Im Laufe der Kooperation können wir durch die Etablierung einer konsequenten Performance Analyse aufzeigen, wie eng die Verzahnung der einzelnen Abteilungen ist. Die höhere Visibilität erleichtert Performance Analysen und sie liefert den Sicherheitsabteilung gleichzeitig wichtige Informationen über aktuelle Zustände der Infrastruktur.
Data Science Blog: Haben Sie es dabei mit Big Data – im wörtlichen Sinne – zu tun?
Wir unterscheiden bei Big Data zwischen
- dem organischen Wachstum von Unternehmensdaten aufgrund etablierter Prozesse, inklusive dem Angebot von neuen Services und
- wirklichem Big Data, z. B. die Anbindung von Produktionsprozessen an die Unternehmens IT, also durch die Digitalisierung initiierte zusätzliche Prozesse in den Unternehmen.
Beide Themen sind für die Kunden eine große Herausforderung. Auf der einen Seite muss die Leistungsfähigkeit der Systeme erweitert und ausgebaut werden, um die zusätzlichen Datenmengen zu verkraften. Auf der anderen Seite haben diese neuen Daten nur dann einen wirklichen Wert, wenn sie richtig interpretiert werden und die Ergebnisse konsequent in die Planung und Steuerung der Unternehmen einfließen.
Wir bei NetDescribe kümmern uns mehrheitlich darum, das Wachstum und die damit notwendigen Anpassungen zu managen und – wenn Sie so wollen – Ordnung in das Datenchaos zu bringen. Konkret verfolgen wir das Ziel den Verantwortlichen der IT, aber auch der gesamten Organisation eine verlässliche Indikation zu geben, wie es der Infrastruktur als Ganzes geht. Dazu gehört es, über die einzelnen Bereiche hinweg, gerne auch Silos genannt, die Daten zu korrelieren und im Zusammenhang darzustellen.
Data Science Blog: Log-Datenanalyse gibt es seit es Log-Dateien gibt. Was hält ein BI-Team davon ab, einen Data Lake zu eröffnen und einfach loszulegen?
Das stimmt absolut, Log-Datenanalyse gibt es seit jeher. Es geht hier schlichtweg um die Relevanz. In der Vergangenheit wurde mit Wireshark bei Bedarf ein Datensatz analysiert um ein Problem zu erkennen und nachzuvollziehen. Heute werden riesige Datenmengen (Logs) im IoT Umfeld permanent aufgenommen um Analysen zu erstellen.
Nach meiner Überzeugung sind drei wesentliche Veränderungen der Treiber für den flächendeckenden Einsatz von modernen Analysewerkzeugen.
- Die Inhalte und Korrelationen von Log Dateien aus fast allen Systemen der IT Infrastruktur sind durch die neuen Technologien nahezu in Echtzeit und für größte Datenmengen überhaupt erst möglich. Das hilft in Zeiten der Digitalisierung, wo aktuelle Informationen einen ganz neuen Stellenwert bekommen und damit zu einer hohen Gewichtung der IT führen.
- Ein wichtiger Aspekt bei der Aufnahme und Speicherung von Logfiles ist heute, dass ich die Suchkriterien nicht mehr im Vorfeld formulieren muss, um dann die Antworten aus den Datensätzen zu bekommen. Die neuen Technologien erlauben eine völlig freie Abfrage von Informationen über alle Daten hinweg.
- Logfiles waren in der Vergangenheit ein Hilfswerkzeug für Spezialisten. Die Information in technischer Form dargestellt, half bei einer Problemlösung – wenn man genau wusste was man sucht. Die aktuellen Lösungen sind darüber hinaus mit einer GUI ausgestattet, die nicht nur modern, sondern auch individuell anpassbar und für Nicht-Techniker verständlich ist. Somit erweitert sich der Anwenderkreis des “Logfile Managers” heute vom Spezialisten im Security und Infrastrukturbereich über Abteilungsverantwortliche und Mitarbeiter bis zur Geschäftsleitung.
Der Data Lake war und ist ein wesentlicher Bestandteil. Wenn wir heute Technologien wie Apache/KafkaⓇ und, als gemanagte Lösung, Confluent für Apache/KafkaⓇ betrachten, wird eine zentrale Datendrehscheibe etabliert, von der alle IT Abteilungen profitieren. Alle Analysten greifen mit Ihren Werkzeugen auf die gleiche Datenbasis zu. Somit werden die Rohdaten nur einmal erhoben und allen Tools gleichermaßen zur Verfügung gestellt.
Data Science Blog: Damit sind Sie ein Unternehmen das Datenanalyse, Visualisierung und Monitoring verbindet, dies jedoch auch mit der IT-Security. Was ist Unternehmen hierbei eigentlich besonders wichtig?
Sicherheit ist natürlich ganz oben auf die Liste zu setzen. Organisation sind naturgemäß sehr sensibel und aktuelle Medienberichte zu Themen wie Cyber Attacks, Hacking etc. zeigen große Wirkung und lösen Aktionen aus. Dazu kommen Compliance Vorgaben, die je nach Branche schneller und kompromissloser umgesetzt werden.
Die NetDescribe ist spezialisiert darauf den Bogen etwas weiter zu spannen.
Natürlich ist die sogenannte Nord-Süd-Bedrohung, also der Angriff von außen auf die Struktur erheblich und die IT-Security muss bestmöglich schützen. Dazu dienen die Firewalls, der klassische Virenschutz etc. und Technologien wie Extrahop, die durch konsequente Überwachung und Aktualisierung der Signaturen zum Schutz der Unternehmen beitragen.
Genauso wichtig ist aber die Einbindung der unterlagerten Strukturen wie das Netzwerk. Ein Angriff auf eine Organisation, egal von wo aus initiiert, wird immer über einen Router transportiert, der den Datensatz weiterleitet. Egal ob aus einer Cloud- oder traditionellen Umgebung und egal ob virtuell oder nicht. Hier setzen wir an, indem wir etablierte Technologien wie zum Beispiel ´flow` mit speziell von uns entwickelten Software Modulen – sogenannten NetDescibe Apps – nutzen, um diese Datensätze an SplunkⓇ, StableNetⓇ weiterzuleiten. Dadurch entsteht eine wesentlich erweiterte Analysemöglichkeit von Bedrohungsszenarien, verbunden mit der Möglichkeit eine unternehmensweite Optimierung zu etablieren.
Data Science Blog: Sie analysieren nicht nur ad-hoc, sondern befassen sich mit der Formulierung von Lösungen als Applikation (App).
Das stimmt. Alle von uns eingesetzten Technologien haben ihre Schwerpunkte und sind nach unserer Auffassung führend in ihren Bereichen. InfosimⓇ im Netzwerk, speziell bei den Verbindungen, VIAVI in der Paketanalyse und bei flows, SplunkⓇ im Securitybereich und Confluent für Apache/KafkaⓇ als zentrale Datendrehscheibe. Also jede Lösung hat für sich alleine schon ihre Daseinsberechtigung in den Organisationen. Die NetDescribe hat es sich seit über einem Jahr zur Aufgabe gemacht, diese Technologien zu verbinden um einen “Stack” zu bilden.
Konkret: Gigaflow von VIAVI ist die wohl höchst skalierbare Softwarelösung um Netzwerkdaten in größten Mengen schnell und und verlustfrei zu speichern und zu analysieren. SplunkⓇ hat sich mittlerweile zu einem Standardwerkzeug entwickelt, um Datenanalyse zu betreiben und die Darstellung für ein großes Auditorium zu liefern.
NetDescribe hat jetzt eine App vorgestellt, welche die NetFlow-Daten in korrelierter Form aus Gigaflow, an SplunkⓇ liefert. Ebenso können aus SplunkⓇ Abfragen zu bestimmten Datensätzen direkt an die Gigaflow Lösung gestellt werden. Das Ergebnis ist eine wesentlich erweiterte SplunkⓇ-Plattform, nämlich um das komplette Netzwerk mit nur einem Knopfdruck (!!!).
Dazu schont diese Anbindung in erheblichem Umfang SplunkⓇ Ressourcen.
Dazu kommt jetzt eine NetDescribe StableNetⓇ App. Weitere Anbindungen sind in der Planung.
Das Ziel ist hier ganz pragmatisch – wenn sich SplunkⓇ als die Plattform für Sicherheitsanalysen und für das Data Framework allgemein in den Unternehmen etabliert, dann unterstützen wir das als NetDescribe dahingehend, dass wir die anderen unternehmenskritischen Lösungen der Abteilungen an diese Plattform anbinden, bzw. Datenintegration gewährleisten. Das erwarten auch unsere Kunden.
Data Science Blog: Auf welche Technologien setzen Sie dabei softwareseitig?
Wie gerade erwähnt, ist SplunkⓇ eine Plattform, die sich in den meisten Unternehmen etabliert hat. Wir machen SplunkⓇ jetzt seit über 10 Jahren und etablieren die Lösung bei unseren Kunden.
SplunkⓇ hat den großen Vorteil dass unsere Kunden mit einem dedizierten und überschaubaren Anwendung beginnen können, die Technologie selbst aber nahezu unbegrenzt skaliert. Das gilt für Security genauso wie Infrastruktur, Applikationsmonitoring und Entwicklungsumgebungen. Aus den ständig wachsenden Anforderungen unserer Kunden ergeben sich dann sehr schnell weiterführende Gespräche, um zusätzliche Einsatzszenarien zu entwickeln.
Neben SplunkⓇ setzen wir für das Netzwerkmanagement auf StableNetⓇ von InfosimⓇ, ebenfalls seit über 10 Jahren schon. Auch hier, die Erfahrungen des Herstellers im Provider Umfeld erlauben uns bei unseren Kunden eine hochskalierbare Lösung zu etablieren.
Confluent für Apache/KafkaⓇ ist eine vergleichbar jüngere Lösung, die aber in den Unternehmen gerade eine extrem große Aufmerksamkeit bekommt. Die Etablierung einer zentralen Datendrehscheibe für Analyse, Auswertungen, usw., auf der alle Daten zur Performance zentral zur Verfügung gestellt werden, wird es den Administratoren, aber auch Planern und Analysten künftig erleichtern, aussagekräftige Daten zu liefern. Die Verbindung aus OpenSource und gemanagter Lösung trifft hier genau die Zielvorstellung der Kunden und scheinbar auch den Zahn der Zeit. Vergleichbar mit den Linux Derivaten von Red Hat Linux und SUSE.
VIAVI Gigaflow hatte ich für Netzwerkanalyse schon erwähnt. Hier wird in den kommenden Wochen mit der neuen Version der VIAVI Apex Software ein Scoring für Netzwerke etabliert. Stellen sie sich den MOS score von VoIP für Unternehmensnetze vor. Das trifft es sehr gut. Damit erhalten auch wenig spezialisierte Administratoren die Möglichkeit mit nur 3 (!!!) Mausklicks konkrete Aussagen über den Zustand der Netzwerkinfrastruktur, bzw. auftretende Probleme zu machen. Ist es das Netz? Ist es die Applikation? Ist es der Server? – der das Problem verursacht. Das ist eine wesentliche Eindämmung des derzeitigen Ping-Pong zwischen den Abteilungen, von denen oft nur die Aussage kommt, “bei uns ist alles ok”.
Abgerundet wird unser Software Portfolio durch die Lösung SentinelOne für Endpoint Protection.
Data Science Blog: Inwieweit spielt Künstliche Intelligenz (KI) bzw. Machine Learning eine Rolle?
Machine Learning spielt heute schon ein ganz wesentliche Rolle. Durch konsequentes Einspeisen der Rohdaten und durch gezielte Algorithmen können mit der Zeit bessere Analysen der Historie und komplexe Zusammenhänge aufbereitet werden. Hinzu kommt, dass so auch die Genauigkeit der Prognosen für die Zukunft immens verbessert werden können.
Als konkretes Beispiel bietet sich die eben erwähnte Endpoint Protection von SentinelOne an. Durch die Verwendung von KI zur Überwachung und Steuerung des Zugriffs auf jedes IoT-Gerät, befähigt SentinelOne Maschinen, Probleme zu lösen, die bisher nicht in größerem Maßstab gelöst werden konnten.
Hier kommt auch unser ganzheitlicher Ansatz zum Tragen, nicht nur einzelne Bereiche der IT, sondern die unternehmensweite IT ins Visier zu nehmen.
Data Science Blog: Mit was für Menschen arbeiten Sie in Ihrem Team? Sind das eher die introvertierten Nerds und Hacker oder extrovertierte Consultants? Was zeichnet Sie als Team fachlich aus?
Nerds und Hacker würde ich unsere Mitarbeiter im technischen Consulting definitiv nicht nennen.
Unser Consulting Team besteht derzeit aus neun Leuten. Jeder ist ausgewiesener Experte für bestimmte Produkte. Natürlich ist es auch bei uns so, dass wir introvertierte Kollegen haben, die zunächst lieber in Abgeschiedenheit oder Ruhe ein Problem analysieren, um dann eine Lösung zu generieren. Mehrheitlich sind unsere technischen Kollegen aber stets in enger Abstimmung mit dem Kunden.
Für den Einsatz beim Kunden ist es sehr wichtig, dass man nicht nur fachlich die Nase vorn hat, sondern dass man auch kommunikationsstark und extrem teamfähig ist. Eine schnelle Anpassung an die verschiedenen Arbeitsumgebungen und “Kollegen” bei den Kunden zeichnet unsere Leute aus.
Als ständig verfügbares Kommunikationstool nutzen wir einen internen Chat der allen jederzeit zur Verfügung steht, so dass unser Consulting Team auch beim Kunden immer Kontakt zu den Kollegen hat. Das hat den großen Vorteil, dass das gesamte Know-how sozusagen “im Pool” verfügbar ist.
Neben den Consultants gibt es unser Sales Team mit derzeit vier Mitarbeitern*innen. Diese Kollegen*innen sind natürlich immer unter Strom, so wie sich das für den Vertrieb gehört.
Dedizierte PreSales Consultants sind bei uns die technische Speerspitze für die Aufnahme und das Verständnis der Anforderungen. Eine enge Zusammenarbeit mit dem eigentlichen Consulting Team ist dann die Voraussetzung für die vorausschauende Planung aller Projekte.
Wir suchen übrigens laufend qualifizierte Kollegen*innen. Details zu unseren Stellenangeboten finden Ihre Leser*innen auf unserer Website unter dem Menüpunkt “Karriere”. Wir freuen uns über jede/n Interessenten*in.
Über NetDescribe:
 NetDescribe steht mit dem Claim Trusted Performance für ausfallsichere Geschäftsprozesse und Cloud-Anwendungen. Die Stärke von NetDescribe sind maßgeschneiderte Technologie Stacks bestehend aus Lösungen mehrerer Hersteller. Diese werden durch selbst entwickelte Apps ergänzt und verschmolzen.
NetDescribe steht mit dem Claim Trusted Performance für ausfallsichere Geschäftsprozesse und Cloud-Anwendungen. Die Stärke von NetDescribe sind maßgeschneiderte Technologie Stacks bestehend aus Lösungen mehrerer Hersteller. Diese werden durch selbst entwickelte Apps ergänzt und verschmolzen.
Das ganzheitliche Portfolio bietet Datenanalyse und -visualisierung, Lösungskonzepte, Entwicklung, Implementierung und Support. Als Trusted Advisor für Großunternehmen und öffentliche Institutionen realisiert NetDescribe hochskalierbare Lösungen mit State-of-the-Art-Technologien für dynamisches und transparentes Monitoring in Echtzeit. Damit erhalten Kunden jederzeit Einblicke in die Bereiche Security, Cloud, IoT und Industrie 4.0. Sie können agile Entscheidungen treffen, interne und externe Compliance sichern und effizientes Risikomanagement betreiben. Das ist Trusted Performance by NetDescribe.
 DATANOMIQ - Benjamin Aunkofer
DATANOMIQ - Benjamin Aunkofer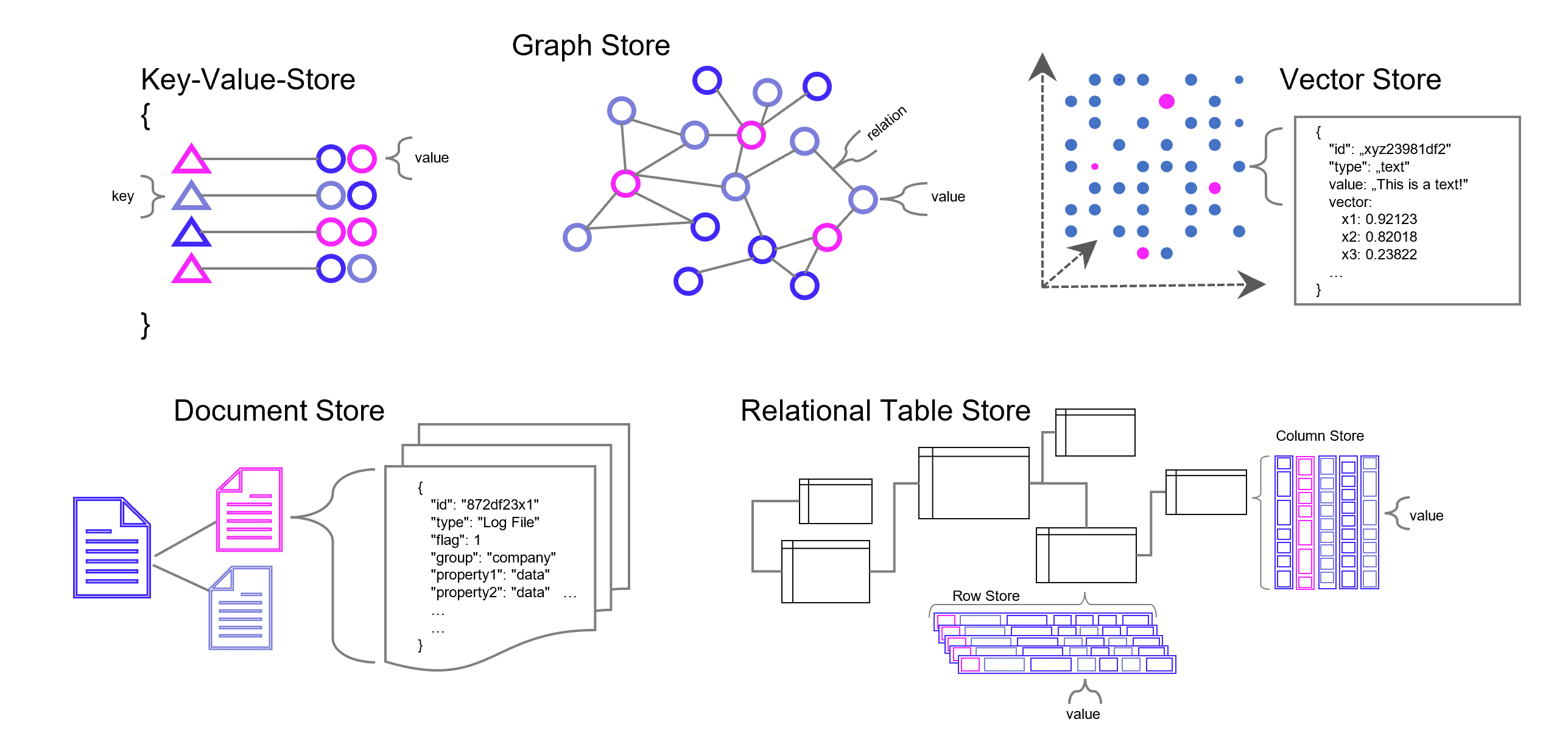
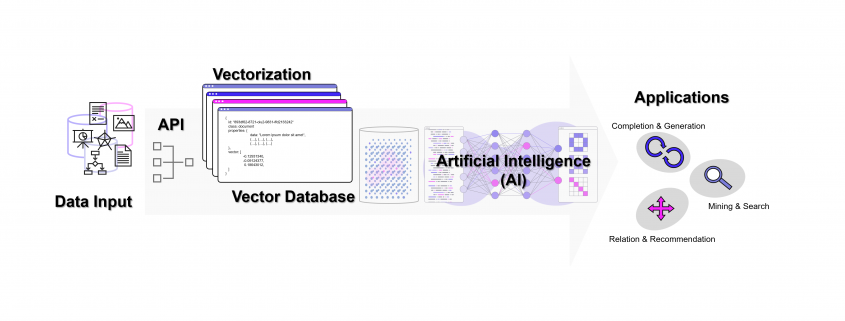
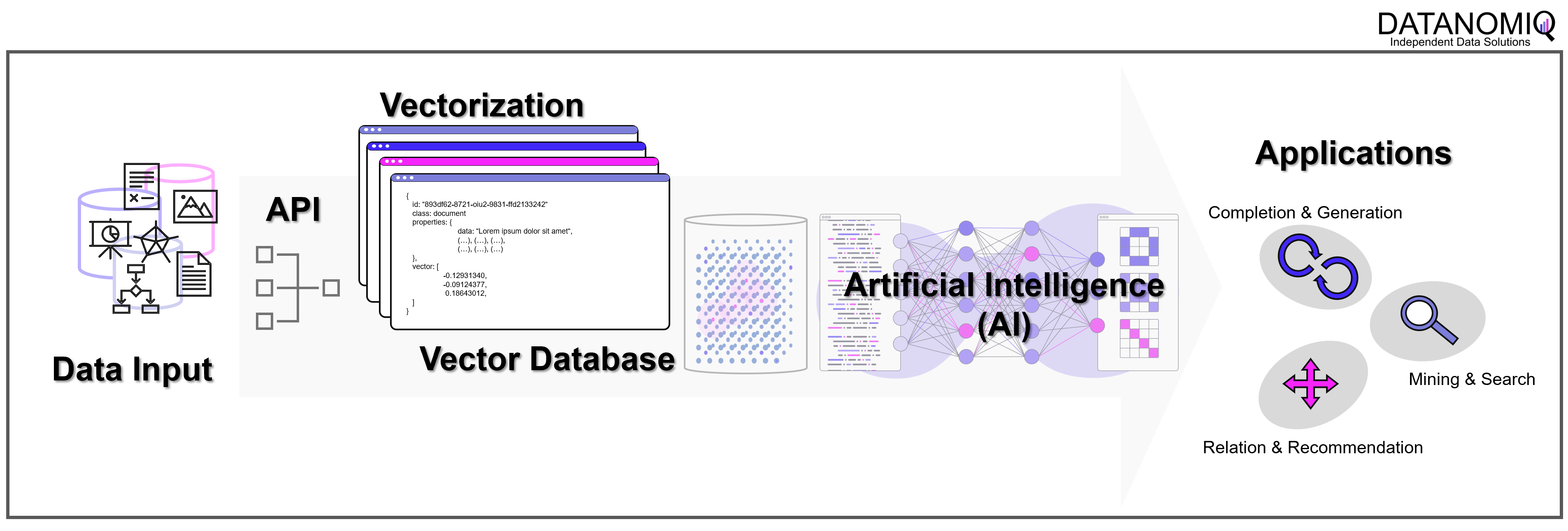
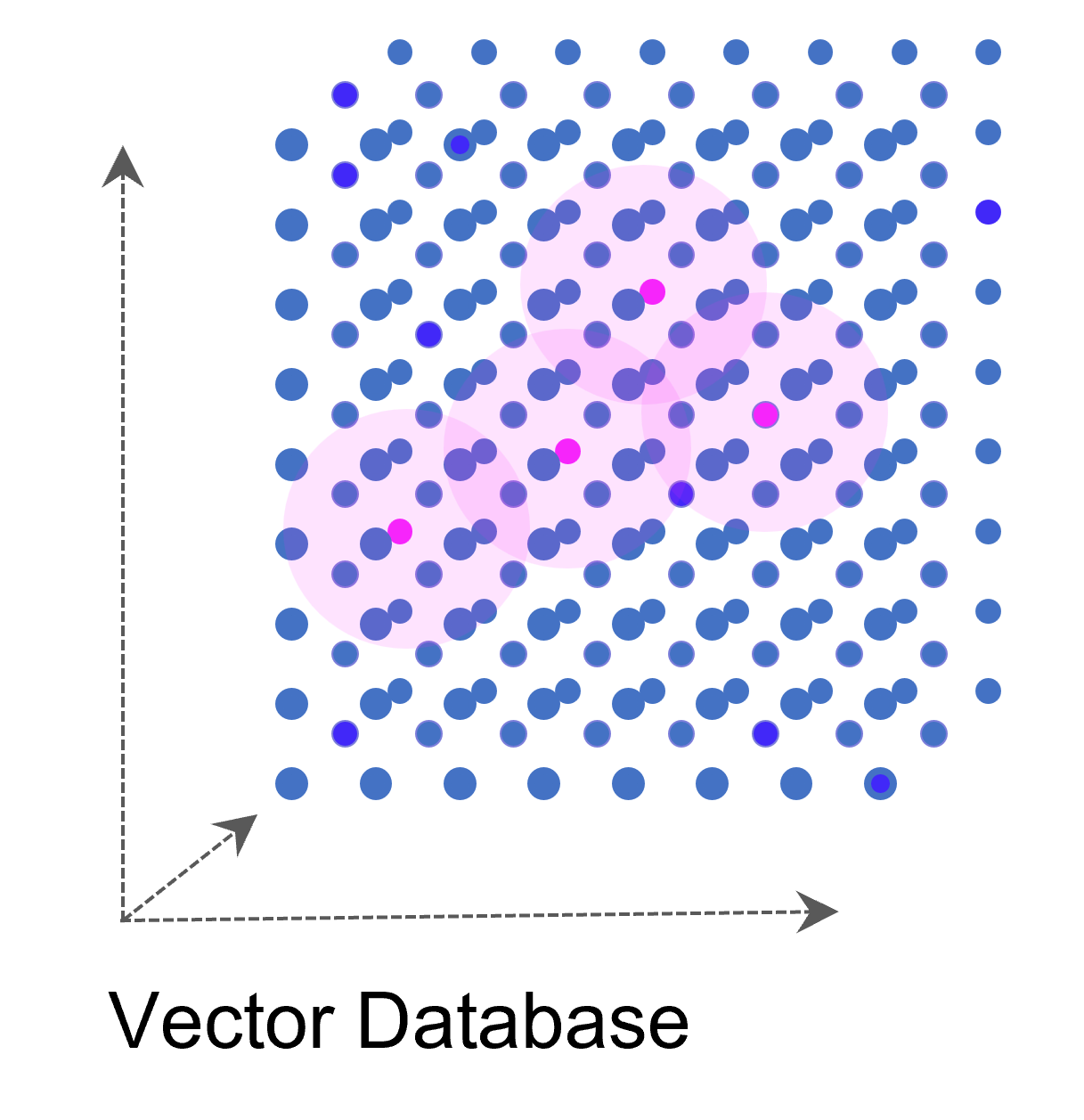 Weise kann eine ganze Sammlung von Bildern als eine Sammlung von Vektoren dargestellt werden. Noch gängiger jedoch sind Vektorräume, die Texte z. B. über die Häufigkeit des Auftretens von Textbausteinen (Wörter, Silben, Buchstaben) in sich einbetten (Embeddings). Embeddings sind folglich Vektoren, die durch die Projektion des Textes auf einen Vektorraum entstehen.
Weise kann eine ganze Sammlung von Bildern als eine Sammlung von Vektoren dargestellt werden. Noch gängiger jedoch sind Vektorräume, die Texte z. B. über die Häufigkeit des Auftretens von Textbausteinen (Wörter, Silben, Buchstaben) in sich einbetten (Embeddings). Embeddings sind folglich Vektoren, die durch die Projektion des Textes auf einen Vektorraum entstehen.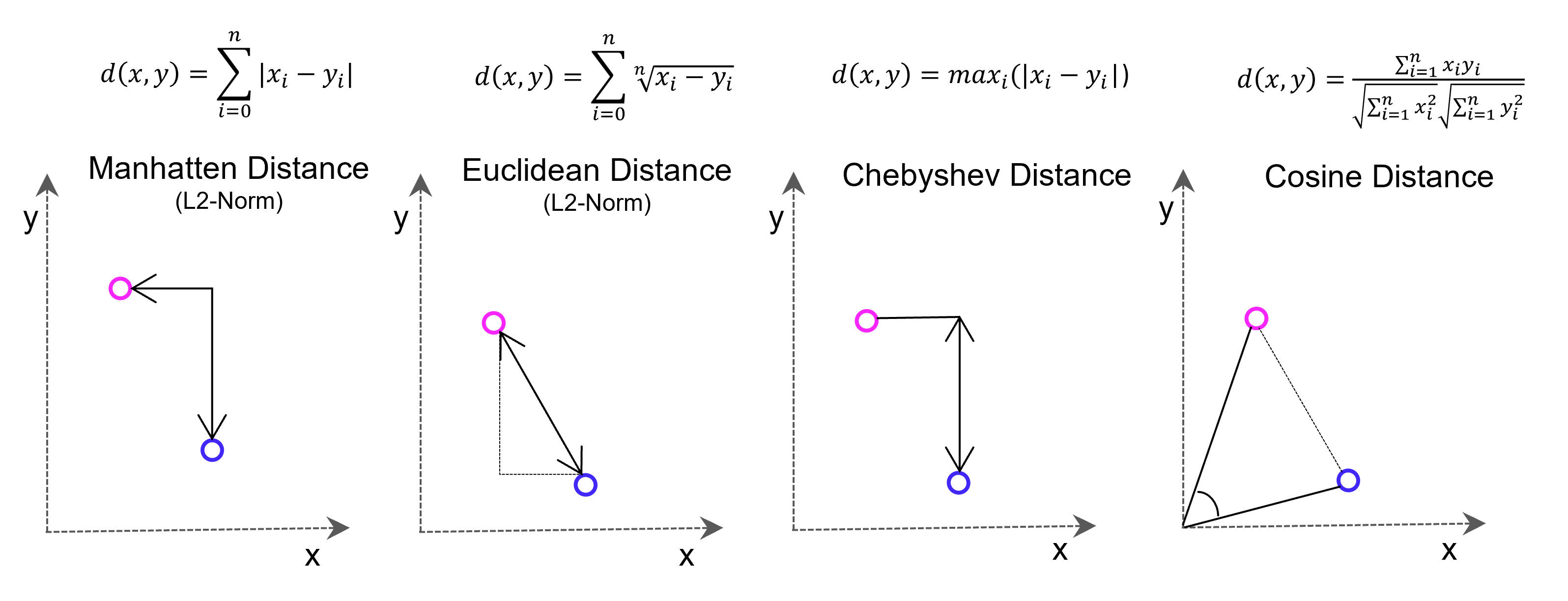





 Dr. Florian Nielsen ist Principal for AI und Data Science bei Miele im Bereich Smart Home und zuständig für die Entwicklung daten-getriebener digitaler Produkte und Produkterweiterungen. Der studierte Informatiker promovierte an der Universität Ulm zum Thema multimodale kognitive technische Systeme.
Dr. Florian Nielsen ist Principal for AI und Data Science bei Miele im Bereich Smart Home und zuständig für die Entwicklung daten-getriebener digitaler Produkte und Produkterweiterungen. Der studierte Informatiker promovierte an der Universität Ulm zum Thema multimodale kognitive technische Systeme.




 Andreas Festl ist Data Scientist bei VIRTUAL VEHICLE, ein führendes F&E Zentrum für die Automobil- und Bahnindustrie mit Sitz in Graz, Österreich. Das Zentrum konzentriert sich auf die konsequente Virtualisierung der Fahrzeugentwicklung. Wesentliches Element dabei ist die Verknüpfung von numerischer Simulation und Hardware-Testen, welche ein umfassendes HW-SW Systemdesign sicherstellt. Herr Festl forscht dort an Kontext-basierten Informationssystemen für den Einsatz im Fahrzeug und in der Entwicklung. Er ist ausgebildeter Mathematiker, der sich schon früh dem Thema Data Science verschrieben hat. Zusätzlich ist Herr Festl in der Lehre für Data and Information Science an der Fachhochschule Joanneum tätig.
Andreas Festl ist Data Scientist bei VIRTUAL VEHICLE, ein führendes F&E Zentrum für die Automobil- und Bahnindustrie mit Sitz in Graz, Österreich. Das Zentrum konzentriert sich auf die konsequente Virtualisierung der Fahrzeugentwicklung. Wesentliches Element dabei ist die Verknüpfung von numerischer Simulation und Hardware-Testen, welche ein umfassendes HW-SW Systemdesign sicherstellt. Herr Festl forscht dort an Kontext-basierten Informationssystemen für den Einsatz im Fahrzeug und in der Entwicklung. Er ist ausgebildeter Mathematiker, der sich schon früh dem Thema Data Science verschrieben hat. Zusätzlich ist Herr Festl in der Lehre für Data and Information Science an der Fachhochschule Joanneum tätig.
