Was muss ein Data Scientist können? Diese Frage wurde bereits häufig gestellt und auch häufig beantwortet. In der Tat ist man sich mittlerweile recht einig darüber, welche Aufgaben ein Data […]
https://data-science-blog.com/de/wp-content/uploads/sites/5/2017/10/data-scientist-header.jpg492976Benjamin Aunkoferhttps://data-science-blog.com/de/wp-content/uploads/sites/5/2016/12/data-science-blog-logo-de-300x284.pngBenjamin Aunkofer2017-09-11 08:17:122017-10-22 12:55:09Data Science Knowledge Stack – Was ein Data Scientist können muss
Big Data ist allgegenwärtig – die Datenrevolution bietet in nahezu allen Branchen vielfältige Nutzungsmöglichkeiten. Bevor Sie jedoch investieren, sollten Sie sehr sorgfältig analysieren, welche Strategie auf Ihr Unternehmen exakt zugeschnitten […]
https://data-science-blog.com/de/wp-content/uploads/sites/5/2017/08/datenstrategie-header.png300800Benjamin Aunkoferhttps://data-science-blog.com/de/wp-content/uploads/sites/5/2016/12/data-science-blog-logo-de-300x284.pngBenjamin Aunkofer2017-08-30 16:07:112017-08-31 10:44:22Die fünf Schritte zur Datenstrategie
Viele Unternehmen stecken gerade in der Digitalisierung fest, digitalisieren Prozesse und Dokumente, vernetzen immer mehr Maschinen und Endgeräte, und generieren dabei folglich immer mehr Daten. Aber auch ungeachtet der aktuellen […]
Dieser Artikel ist Teil 2 von 4 der Artikelserie Maschinelles Lernen mit Entscheidungsbaumverfahren. Entscheidungsbäume sind den Ingenieuren bestens bekannt, um Produkte hierarchisch zu zerlegen und um Verfahrensanweisungen zu erstellen. Die […]
Data Scientist ist der „sexiest Job“ auf der Welt. Data Science ist die neu erfundene Wissenschaft, die viele unserer Probleme lösen und uns die Zukunft angenehmer gestalten wird. Aber was […]
https://data-science-blog.com/de/wp-content/uploads/sites/5/2015/12/big-data-science-1-1.jpg4651033Wolfgang Ecker-Lalahttps://data-science-blog.com/de/wp-content/uploads/sites/5/2016/12/data-science-blog-logo-de-300x284.pngWolfgang Ecker-Lala2017-07-07 15:42:382017-07-07 15:42:38Höhere Mathematik als Grundvoraussetzung für Data Scientists
Dies ist Artikel 1 von 4 aus der Artikelserie – Was ist eigentlich Machine Learning? Der Unterschied zwischen überwachten und unüberwachtem Lernen ist für Einsteiger in das Gebiet des maschinellen […]
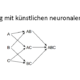
Machine Learning ist Technik und Mythos zugleich. Nachfolgend der Versuch einer verständlichen Erklärung, mit folgenden Artikeln: Unüberwachtes vs überwachtes Lernen Regression vs Klassifikation Parametrisierte vs nicht-parametrisierte Lernenverfahren Online- vs Offline-Lernen […]
Mit diesem Beitrag möchte ich darlegen, welche Grenzen uns in komplexen Umfeldern im Kontext Steuerung und Regelung auferlegt sind. Auf dieser Basis strebe ich dann nachgelagert eine Differenzierung in Bezug […]
https://data-science-blog.com/de/wp-content/uploads/sites/5/2017/05/kuenstliche-intelligenz-kommentar-kritik-header.png300800Conny Dethloffhttps://data-science-blog.com/de/wp-content/uploads/sites/5/2016/12/data-science-blog-logo-de-300x284.pngConny Dethloff2017-05-17 11:32:552017-05-18 07:35:19Geht mit Künstlicher Intelligenz nur „Malen nach Zahlen“?
Die Clusteranalyse ist ein gruppenbildendes Verfahren, mit dem Objekte Gruppen – sogenannten Clustern zuordnet werden. Die dem Cluster zugeordneten Objekte sollen möglichst homogen sein, wohingegen die Objekte, die unterschiedlichen Clustern […]
Der Data Science Blog ist Co-Organisator des Data Leader Day 2017 Der Data Leader Day am 09.11.2017 ist ein Event für Unternehmen aus dem deutschsprachigen Raum, das sich mit den Möglichkeiten und Lösungen […]
https://data-science-blog.com/de/wp-content/uploads/sites/5/2017/05/data-leader-day-2017.jpg6551563eventshttps://data-science-blog.com/de/wp-content/uploads/sites/5/2016/12/data-science-blog-logo-de-300x284.pngevents2017-05-11 09:24:512017-05-11 11:07:46In eigener Sache: Der Data Leader Day 2017


















 DATANOMIQ - Benjamin Aunkofer
DATANOMIQ - Benjamin Aunkofer







 Jurek Dörner @ DATANOMIQ
Jurek Dörner @ DATANOMIQ




































































































Data Science Knowledge Stack – Was ein Data Scientist können muss
/in Data Mining, Data Science, Data Science Hack, Data Science News, Education / Certification, Gerneral, Insights, Main Category/by Benjamin AunkoferWas muss ein Data Scientist können? Diese Frage wurde bereits häufig gestellt und auch häufig beantwortet. In der Tat ist man sich mittlerweile recht einig darüber, welche Aufgaben ein Data […]
Die fünf Schritte zur Datenstrategie
/in Big Data, Business Analytics, Business Intelligence, Customer Analytics, Data Science, Industrie 4.0, Main Category, Projectmanagement/by Benjamin AunkoferBig Data ist allgegenwärtig – die Datenrevolution bietet in nahezu allen Branchen vielfältige Nutzungsmöglichkeiten. Bevor Sie jedoch investieren, sollten Sie sehr sorgfältig analysieren, welche Strategie auf Ihr Unternehmen exakt zugeschnitten […]
Unternehmen brauchen eine Datenstrategie
/in Big Data, Business Analytics, Business Intelligence, Customer Analytics, Data Science, Data Science News, Datacenter, Experience, Gerneral, Main Category, Projectmanagement/by Benjamin AunkoferViele Unternehmen stecken gerade in der Digitalisierung fest, digitalisieren Prozesse und Dokumente, vernetzen immer mehr Maschinen und Endgeräte, und generieren dabei folglich immer mehr Daten. Aber auch ungeachtet der aktuellen […]
Entscheidungsbaum-Algorithmus ID3
/in Artificial Intelligence, Data Mining, Data Science, Data Science Hack, Machine Learning, Main Category, Predictive Analytics/by Benjamin AunkoferDieser Artikel ist Teil 2 von 4 der Artikelserie Maschinelles Lernen mit Entscheidungsbaumverfahren. Entscheidungsbäume sind den Ingenieuren bestens bekannt, um Produkte hierarchisch zu zerlegen und um Verfahrensanweisungen zu erstellen. Die […]
Höhere Mathematik als Grundvoraussetzung für Data Scientists
/in Carrier, Data Science News, Education / Certification, Gerneral/by Wolfgang Ecker-LalaData Scientist ist der „sexiest Job“ auf der Welt. Data Science ist die neu erfundene Wissenschaft, die viele unserer Probleme lösen und uns die Zukunft angenehmer gestalten wird. Aber was […]
Überwachtes vs unüberwachtes maschinelles Lernen
/in Artificial Intelligence, Big Data, Business Analytics, Business Intelligence, Data Mining, Data Science, Machine Learning, Main Category/by Benjamin AunkoferDies ist Artikel 1 von 4 aus der Artikelserie – Was ist eigentlich Machine Learning? Der Unterschied zwischen überwachten und unüberwachtem Lernen ist für Einsteiger in das Gebiet des maschinellen […]
Was ist eigentlich Machine Learning? Artikelserie
/in Artificial Intelligence, Business Analytics, Business Intelligence, Data Mining, Data Science, Deep Learning, Machine Learning, Main Category/by Benjamin AunkoferMachine Learning ist Technik und Mythos zugleich. Nachfolgend der Versuch einer verständlichen Erklärung, mit folgenden Artikeln: Unüberwachtes vs überwachtes Lernen Regression vs Klassifikation Parametrisierte vs nicht-parametrisierte Lernenverfahren Online- vs Offline-Lernen […]
Geht mit Künstlicher Intelligenz nur „Malen nach Zahlen“?
/in Artificial Intelligence, Big Data, Business Analytics, Data Mining, Data Science, Data Science News, Deep Learning, Machine Learning, Predictive Analytics, Projectmanagement/by Conny DethloffMit diesem Beitrag möchte ich darlegen, welche Grenzen uns in komplexen Umfeldern im Kontext Steuerung und Regelung auferlegt sind. Auf dieser Basis strebe ich dann nachgelagert eine Differenzierung in Bezug […]
Unsupervised Learning in R: K-Means Clustering
/in Data Mining, Data Science, Machine Learning, R Statistics, Statistics, Tutorial/by Markus LangDie Clusteranalyse ist ein gruppenbildendes Verfahren, mit dem Objekte Gruppen – sogenannten Clustern zuordnet werden. Die dem Cluster zugeordneten Objekte sollen möglichst homogen sein, wohingegen die Objekte, die unterschiedlichen Clustern […]
In eigener Sache: Der Data Leader Day 2017
/in Data Science News, Use Cases/by eventsDer Data Science Blog ist Co-Organisator des Data Leader Day 2017 Der Data Leader Day am 09.11.2017 ist ein Event für Unternehmen aus dem deutschsprachigen Raum, das sich mit den Möglichkeiten und Lösungen […]