“Er hätte Wirecard entlarvt!” – In der neuesten Podcast-Folge von DATENBUSINESS zeigt Benjamin Aunkofer, wie KI in der Wirtschaftsprüfung funktioniert.
Fehlbuchungen, doppelte Zahlungen, verdächtige Transaktionen – Wirtschaftsprüfer*innen sind täglich auf der Jagd nach Red Flags.
Interview-Folge über KI in der Wirtschaftsprüfung, mit Benjamin Aunkofer von AUDAVIS und DATANOMIQ.
Aber was wäre, wenn Künstliche Intelligenz diese Fehler automatisch – und vor allem sehr schnell finden könnte?
In der neuesten Podcast-Folge sprechen wir mit Benjamin Aunkofer, Gründer von AUDAVIS, über die Zukunft der Wirtschaftsprüfung und wie seine Software eine 100%ige Datenprüfung in Minuten statt Tagen ermöglicht.
𝗟𝗶𝗲𝗯𝗹𝗶𝗻𝗴𝘀𝘇𝗶𝘁𝗮𝘁 der Redaktion:
„Wir haben eine KI gebaut, die Buchhaltungsfehler findet, bevor sie jemand bemerkt – schneller als jeder Mensch es könnte.“
𝗘𝗶𝗻𝗶𝗴𝗲 𝗛𝗶𝗴𝗵𝗹𝗶𝗴𝗵𝘁𝘀:
Wie KI und Process Mining die Finanzwelt effizienter & sicherer machen.
Warum man Wirtschaftsprüfung nicht mehr nur mit Excel lösen kann.
Die spannendste Story: Warum Benjamin zwischen Berlin und Schweiz pendelt
𝗙𝘂𝗿 𝘄𝗲𝗻 𝗶𝘀𝘁 𝗱𝗶𝗲𝘀𝗲 𝗘𝗽𝗶𝘀𝗼𝗱𝗲 𝗯𝗲𝘀𝗼𝗻𝗱𝗲𝗿𝘀 𝗶𝗻𝘁𝗲𝗿𝗲𝘀𝘀𝗮𝗻𝘁?
CFOs & Wirtschaftsprüfer*innen, die sich fragen, wie KI ihre Arbeit revolutioniert.
Unternehmen, die ihre Finanzdatenqualität verbessern wollen.
Alle, die wissen wollen, wie Red Flags automatisiert entdeckt werden können.
https://data-science-blog.com/de/wp-content/uploads/sites/5/2025/03/benjamin_aunkofer_podcast_folge_audavis_.jpeg6281807Redaktionhttps://data-science-blog.com/de/wp-content/uploads/sites/5/2016/12/data-science-blog-logo-de-300x284.pngRedaktion2025-03-24 18:39:432025-03-24 19:00:51KI für die Finanzdatenprüfung – Podcastfolge
Gemeinsam mit Prof. Kai-Uwe Marten von der Universität Ulm und dortiger Direktor des Instituts für Rechnungswesen und Wirtschaftsprüfung, bespricht Benjamin Aunkofer, Co-Founder und Chief AI Officer von AUDAVIS, die Potenziale und heutigen Möglichkeiten von der Künstlichen Intelligenz (KI) in der Jahresabschlussprüfung bzw. allgemein in der Wirtschaftsprüfung: KI als Co-Pilot für den Abschlussprüfer.
Inhaltlich behandelt werden u.a. die Möglichkeiten von überwachtem und unüberwachten maschinellem Lernen, die Möglichkeit von verteiltem KI-Training auf Datensätzen sowie warum Large Language Model (LLM) nur für einige bestimmte Anwendungsfälle eine adäquate Lösung darstellen.
https://data-science-blog.com/de/wp-content/uploads/sites/5/2024/08/ki_als_copilot_in_der_wirtschaftspruefung_jahresabschluss_pruefung_benjamin_aunkofer_audavis-scaled.jpg10942560AUDAVIShttps://data-science-blog.com/de/wp-content/uploads/sites/5/2016/12/data-science-blog-logo-de-300x284.pngAUDAVIS2024-08-04 20:28:302024-08-04 20:48:41KI in der Abschlussprüfung – Podcast mit Benjamin Aunkofer
IT-Verantwortliche, Datenadministratoren, Analysten und Führungskräfte, sie alle stehen vor der Aufgabe, eine Flut an Daten effizient zu nutzen, um die Wettbewerbsfähigkeit ihres Unternehmens zu steigern. Die Fähigkeit, diese gewaltigen Datenmengen effektiv zu analysieren, ist der Schlüssel, um souverän durch die digitale Zukunft zu navigieren. Gleichzeitig wachsen die Datenmengen exponentiell, während IT-Budgets zunehmend schrumpfen, was Verantwortliche unter enormen Druck setzt, mit weniger Mitteln schnell relevante Insights zu liefern. Doch veraltete Legacy-Systeme verlängern Abfragezeiten und erschweren Echtzeitanalysen großer und komplexer Datenmengen, wie sie etwa für Machine Learning (ML) erforderlich sind. An dieser Stelle kommt die Integration von Künstlicher Intelligenz (KI) ins Spiel. Sie unterstützt Unternehmen dabei, Datenanalysen schneller, kostengünstiger und flexibler zu gestalten und erweist sich über verschiedenste Branchen hinweg als unentbehrlich.
Was genau macht KI-gestützte Datenanalyse so wertvoll?
KI-gestützte Datenanalyse verändern die Art und Weise, wie Unternehmen Daten nutzen. Präzise Vorhersagemodelle antizipieren Trends und Kundenverhalten, minimieren Risiken und ermöglichen proaktive Planung. Beispiele sind Nachfrageprognosen, Betrugserkennung oder Predictive Maintenance. Diese Echtzeitanalysen großer Datenmengen führen zu fundierteren, datenbasierten Entscheidungen.
Ein aktueller Report zur Nutzung von KI-gestützter Datenanalyse zeigt, dass Unternehmen, die KI erfolgreich implementieren, erhebliche Vorteile erzielen: schnellere Entscheidungsfindung (um 25%), reduzierte Betriebskosten (bis zu 20%) und verbesserte Kundenzufriedenheit (um 15%). Die Kombination von KI, Data Analytics und Business Intelligence (BI) ermöglicht es Unternehmen, das volle Potenzial ihrer Daten auszuschöpfen. Tools wie AutoML integrieren sich in Analytics-Datenbanken und ermöglichen BI-Teams, ML-Modelle eigenständig zu entwickeln und zu testen, was zu Produktivitätssteigerungen führt.
Herausforderungen und Chancen der KI-Implementierung
Die Implementierung von KI in Unternehmen bringt zahlreiche Herausforderungen mit sich, die IT-Profis und Datenadministratoren bewältigen müssen, um das volle Potenzial dieser Technologien zu nutzen.
Technologische Infrastruktur und Datenqualität: Veraltete Systeme und unzureichende Datenqualität können die Effizienz der KI-Analyse erheblich beeinträchtigen. So sind bestehende Systeme häufig überfordert mit der Analyse großer Mengen aktueller und historischer Daten, die für verlässliche Predictive Analytics erforderlich sind. Unternehmen müssen zudem sicherstellen, dass ihre Daten vollständig, aktuell und präzise sind, um verlässliche Ergebnisse zu erzielen.
Klare Ziele und Implementierungsstrategien: Ohne klare Ziele und eine durchdachte Strategie, die auch auf die Geschäftsstrategie einzahlt, können KI-Projekte ineffizient und ergebnislos verlaufen. Eine strukturierte Herangehensweise ist entscheidend für den Erfolg.
Fachkenntnisse und Schulung: Die Implementierung von KI erfordert spezialisiertes Wissen, das in vielen Unternehmen fehlt. Die Kosten für Experten oder entsprechende Schulungen können eine erhebliche finanzielle Hürde darstellen, sind aber Grundlage dafür, dass die Technologie auch effizient genutzt wird.
Sicherheit und Compliance: Auch Governance-Bedenken bezüglich Sicherheit und Compliance können ein Hindernis darstellen. Eine strategische Herangehensweise, die sowohl technologische, ethische als auch organisatorische Aspekte berücksichtigt, ist also entscheidend. Unternehmen müssen sicherstellen, dass ihre KI-Lösungen den rechtlichen Anforderungen entsprechen, um Datenschutzverletzungen zu vermeiden. Flexible Bereitstellungsoptionen in der Public Cloud, Private Cloud, On-Premises oder hybriden Umgebungen sind entscheidend, um Plattform- und Infrastrukturbeschränkungen zu überwinden.
Espresso AI von Exasol: Ein Lösungsansatz
Exasol hat mit Espresso AI eine Lösung entwickelt, die Unternehmen bei der Implementierung von KI-gestützter Datenanalyse unterstützt und KI mit Business Intelligence (BI) kombiniert. Espresso AI ist leistungsstark und benutzerfreundlich, sodass auch Teammitglieder ohne tiefgehende Data-Science-Kenntnisse mit neuen Technologien experimentieren und leistungsfähige Modelle entwickeln können. Große und komplexe Datenmengen können in Echtzeit verarbeitet werden – besonders für datenintensive Branchen wie den Einzelhandel oder E-Commerce ist die Lösung daher besonders geeignet. Und auch in Bereichen, in denen sensible Daten im eigenen Haus verbleiben sollen oder müssen, wie dem Finanz- oder Gesundheitsbereich, bietet Espresso die entsprechende Flexibilität – die Anwender haben Zugriff auf Realtime-Datenanalysen, egal ob sich ihre Daten on-Premise, in der Cloud oder in einer hybriden Umgebung befinden. Dank umfangreicher Integrationsmöglichkeiten mit bestehenden IT-Systemen und Datenquellen wird eine schnelle und reibungslose Implementierung gewährleistet.
Chancen durch KI-gestützte Datenanalysen
Der Einsatz von KI-gestützten Datenintegrationswerkzeugen automatisiert viele der manuellen Prozesse, die traditionell mit der Vorbereitung und Bereinigung von Daten verbunden sind. Dies entlastet Teams nicht nur von zeitaufwändiger Datenaufbereitung und komplexen Datenintegrations-Workflows, sondern reduziert auch das Risiko menschlicher Fehler und stellt sicher, dass die Daten für die Analyse konsistent und von hoher Qualität sind. Solche Werkzeuge können Daten aus verschiedenen Quellen effizient zusammenführen, transformieren und laden, was es den Teams ermöglicht, sich stärker auf die Analyse und Nutzung der Daten zu konzentrieren.
Die Integration von AutoML-Tools in die Analytics-Datenbank eröffnet Business-Intelligence-Teams neue Möglichkeiten. AutoML (Automated Machine Learning) automatisiert viele der Schritte, die normalerweise mit dem Erstellen von ML-Modellen verbunden sind, einschließlich Modellwahl, Hyperparameter-Tuning und Modellvalidierung.
Über Exasol-CEO Martin Golombek
Mathias Golombek ist seit Januar 2014 Mitglied des Vorstands der Exasol AG. In seiner Rolle als Chief Technology Officer verantwortet er alle technischen Bereiche des Unternehmens, von Entwicklung, Produkt Management über Betrieb und Support bis hin zum fachlichen Consulting.
Über Mathias Golombek
Nach seinem Informatikstudium, in dem er sich vor allem mit Datenbanken, verteilten Systemen, Softwareentwicklungsprozesse und genetischen Algorithmen beschäftigte, stieg Mathias Golombek 2004 als Software Developer bei der Nürnberger Exasol AG ein. Seitdem ging es für ihn auf der Karriereleiter steil nach oben: Ein Jahr danach verantwortete er das Database-Optimizer-Team. Im Jahr 2007 folgte die Position des Head of Research & Development. 2014 wurde Mathias Golombek schließlich zum Chief Technology Officer (CTO) und Technologie-Vorstand von Exasol benannt. In seiner Rolle als Chief Technology Officer verantwortet er alle technischen Bereiche des Unternehmens, von Entwicklung, Product Management über Betrieb und Support bis hin zum fachlichen Consulting.
Er ist der festen Überzeugung, dass sich jedes Unternehmen durch seine Grundwerte auszeichnet und diese stets gelebt werden sollten. Seit seiner Benennung zum CTO gibt Mathias Golombek in Form von Fachartikeln, Gastbeiträgen, Diskussionsrunden und Interviews Einblick in die Materie und fördert den Wissensaustausch.
https://data-science-blog.com/de/wp-content/uploads/sites/5/2024/03/Exasol_Mathias-Golombek_header-scaled.jpg11952560Redaktionhttps://data-science-blog.com/de/wp-content/uploads/sites/5/2016/12/data-science-blog-logo-de-300x284.pngRedaktion2024-07-09 11:33:092024-07-09 11:33:09KI-gestützte Datenanalysen als Kompass für Unternehmen: Chancen und Herausforderungen
In der heutigen Geschäftswelt ist der Einsatz von Daten unerlässlich, insbesondere für Unternehmen mit über 100 Mitarbeitern, die erfolgreich bleiben möchten. In der Podcast-Episode “Data Jobs – Was brauchst Du, um im Datenbereich richtig Karriere zu machen?” diskutieren Dr. Christian Krug und Benjamin Aunkofer, Gründer von DATANOMIQ, wie Angestellte ihre Datenkenntnisse verbessern und damit ihre berufliche Laufbahn aktiv vorantreiben können. Dies steigert nicht nur ihren persönlichen Erfolg, sondern erhöht auch den Nutzen und die Wettbewerbsfähigkeit des Unternehmens. Datenkompetenz ist demnach ein wesentlicher Faktor für den Erfolg sowohl auf individueller als auch auf Unternehmensebene.
In dem Interview erläutert Benjamin Aunkofer, wie man den Einstieg auch als Quereinsteiger schafft. Das Sprichwort „Ohne Fleiß kein Preis“ trifft besonders auf die Entwicklung beruflicher Fähigkeiten zu, insbesondere im Bereich der Datenverarbeitung und -analyse. Anstelle den Abend mit Serien auf Netflix zu verbringen, könnte man die Zeit nutzen, um sich durch Fachliteratur weiterzubilden. Es gibt eine Vielzahl von Büchern zu Themen wie Data Science, Künstliche Intelligenz, Process Mining oder Datenstrategie, die wertvolle Einblicke und Kenntnisse bieten können.
Der Nutzen steht in einem guten Verhältnis zum Aufwand, so Benjamin Aunkofer. Für diejenigen, die wirklich daran interessiert sind, in eine Datenkarriere einzusteigen, stehen die Türen offen. Der Einstieg erfordert zwar Engagement und Lernbereitschaft, ist aber für entschlossene Individuen absolut machbar. Dabei muss man nicht unbedingt eine Laufbahn als Data Scientist anstreben. Jede Fachkraft und insbesondere Führungskräfte können erheblich davon profitieren, die Grundlagen von Data Engineering und Data Science zu verstehen. Diese Kenntnisse ermöglichen es, fundiertere Entscheidungen zu treffen und die Potenziale der Datenanalyse optimal für das Unternehmen zu nutzen.
Podcast-Folge mit Benjamin Aunkofer und Dr. Christian Krug darüber, wie Menschen mit Daten Karriere machen und den Unternehmenserfolg herstellen.
https://data-science-blog.com/de/wp-content/uploads/sites/5/2024/05/podcast-folge-benjamin-aunkofer-datenkarriere-datenkompetenz.png8001729Redaktionhttps://data-science-blog.com/de/wp-content/uploads/sites/5/2016/12/data-science-blog-logo-de-300x284.pngRedaktion2024-05-09 21:26:272024-05-09 21:26:30Data Jobs – Podcast-Folge mit Benjamin Aunkofer
Nahezu alle Unternehmen beschäftigen sich heute mit dem Thema KI und die überwiegende Mehrheit hält es für die wichtigste Zukunftstechnologie – dennoch tun sich nach wie vor viele schwer, die ersten Schritte in Richtung Einsatz von KI zu gehen. Woran scheitern Initiativen aus Ihrer Sicht?
Zu den größten Hindernissen zählen Governance-Bedenken, etwa hinsichtlich Themen wie Sicherheit und Compliance, unklare Ziele und eine fehlende Implementierungsstrategie. Mit seinen flexiblen Bereitstellungsoptionen in der Public/Private Cloud, on-Premises oder in hybriden Umgebungen macht Exasol seine Kunden unabhängig von bestimmten Plattform- und Infrastrukturbeschränkungen, sorgt für die unkomplizierte Integration von KI-Funktionalitäten und ermöglicht Zugriff auf Datenerkenntnissen in real-time – und das, ohne den gesamten Tech-Stack austauschen zu müssen.
Dies ist der eine Teil – der technologische Teil – die Schritte, die die Unternehmen –selbst im Vorfeld gehen müssen, sind die Festlegung von klaren Zielen und KPIs und die Etablierung einer Datenkultur. Das Management sollte für Akzeptanz sorgen, indem es die Vorteile der Nutzung klar beleuchtet, Vorbehalte ernst nimmt und sie ausräumt. Der Weg zum datengetriebenen Unternehmen stellt für viele, vor allem wenn sie eher traditionell aufgestellt sind, einen echten Paradigmenwechsel dar. Führungskräfte sollten hier Orientierung bieten und klar darlegen, welche Rolle die Nutzung von Daten und der Einsatz neuer Technologien für die Zukunftsfähigkeit von Unternehmen und für jeden Einzelnen spielen. Durch eine Kultur der offenen Kommunikation werden Teams dazu ermutigt, digitale Lösungen zu finden, die sowohl ihren individuellen Anforderungen als auch den Zielen des Unternehmens entsprechen. Dazu gehört es natürlich auch, die eigenen Teams zu schulen und mit dem entsprechenden Know-how auszustatten.
Wie unterstützt Exasol die Kunden bei der Implementierung von KI?
Datenabfragen in natürlicher Sprache können, das ist spätestens seit dem Siegeszug von ChatGPT klar, generativer KI den Weg in die Unternehmen ebnen und ihnen ermöglichen, sich datengetrieben aufzustellen. Mit der Integration von Veezoo sind auch die Kunden von Exasol Espresso in der Lage, Datenabfragen in natürlicher Sprache zu stellen und KI unkompliziert in ihrem Arbeitsalltag einzusetzen. Mit dem integrierten autoML-Tool von TurinTech können Anwender zudem durch den Einsatz von ML-Modellen die Performance ihrer Abfragen direkt in ihrer Datenbank maximieren. So gelingt BI-Teams echte Datendemokratisierung und sie können mit ML-Modellen experimentieren, ohne dabei auf Support von ihren Data-Science-Teams angewiesen zu sei.
All dies trägt zur Datendemokratisierung – ein entscheidender Punkt auf dem Weg zum datengetriebenen Unternehmen, denn in der Vergangenheit scheiterte die Umsetzung einer unternehmensweiten Datenstrategie häufig an Engpässen, die durch Data Analytics oder Data Science Teams hervorgerufen werden. Espresso AI ermöglicht Unternehmen einen schnelleren und einfacheren Zugang zu Echtzeitanalysen.
Was war der Grund, Exasol Espresso mit KI-Funktionen anzureichern?
Immer mehr Unternehmen suchen nach Möglichkeiten, sowohl traditionelle als auch generative KI-Modelle und -Anwendungen zu entwickeln – das entsprechende Feedback unserer Kunden war einer der Hauptfaktoren für die Entwicklung von Espresso AI.
Ziel der Unternehmen ist es, ihre Datensilos aufzubrechen – oft haben Data Science Teams viele Jahre lang in Silos gearbeitet. Mit dem Siegeszug von GenAI durch ChatGPT hat ein deutlicher Wandel stattgefunden – KI ist greifbarer geworden, die Technologie ist zugänglicher und auch leistungsfähiger geworden und die Unternehmen suchen nach Wegen, die Technologie gewinnbringend einzusetzen.
Um sich wirklich datengetrieben aufzustellen und das volle Potenzial der eigenen Daten und der Technologien vollumfänglich auszuschöpfen, müssen KI und Data Analytics sowie Business Intelligence in Kombination gebracht werden. Espresso AI wurde dafür entwickelt, um genau das zu tun.
Und wie sieht die weitere Entwicklung aus? Welche Pläne hat Exasol?
Eines der Schlüsselelemente von Espresso AI ist das AI Lab, das es Data Scientists ermöglicht, die In-Memory-Analytics-Datenbank von Exasol nahtlos und schnell in ihr bevorzugtes Data-Science-Ökosystem zu integrieren. Es unterstützt jede beliebige Data-Science-Sprache und bietet eine umfangreiche Liste von Technologie-Integrationen, darunter PyTorch, Hugging Face, scikit-learn, TensorFlow, Ibis, Amazon Sagemaker, Azure ML oder Jupyter.
Weitere Integrationen sind ein wichtiger Teil unserer Roadmap. Während sich die ersten auf die Plattformen etablierter Anbieter konzentrierten, werden wir unser AI Lab weiter ausbauen und es werden Integrationen mit Open-Source-Tools erfolgen. Nutzer werden so in der Lage sein, eine Umgebung zu schaffen, in der sich Data Scientists wohlfühlen. Durch die Ausführung von ML-Modellen direkt in der Exasol-Datenbank können sie so die maximale Menge an Daten nutzen und das volle Potenzial ihrer Datenschätze ausschöpfen.
Über Exasol-CEO Martin Golombek
Mathias Golombek ist seit Januar 2014 Mitglied des Vorstands der Exasol AG. In seiner Rolle als Chief Technology Officer verantwortet er alle technischen Bereiche des Unternehmens, von Entwicklung, Produkt Management über Betrieb und Support bis hin zum fachlichen Consulting.
Über Exasol und Espresso AI
Sie leiden unter langsamer Business Intelligence, mangelnder Datenbank-Skalierung und weiteren Limitierungen in der Datenanalyse? Exasol bietet drei Produkte an, um Ihnen zu helfen, das Maximum aus Analytics zu holen und schnellere, tiefere und kostengünstigere Insights zu erzielen.
Kein Warten mehr auf das “Spinning Wheel”. Von Grund auf für Geschwindigkeit konzipiert, basiert Espresso auf einer einmaligen Datenbankarchitektur aus In-Memory-Caching, spaltenorientierter Datenspeicherung, “Massively Parallel Processing” (MPP), sowie Auto-Tuning. Damit können selbst die komplexesten Analysen beschleunigt und bessere Erkenntnisse in atemberaubender Geschwindigkeit geliefert werden.
https://data-science-blog.com/de/wp-content/uploads/sites/5/2024/03/Exasol_Mathias-Golombek_header-scaled.jpg11952560Redaktionhttps://data-science-blog.com/de/wp-content/uploads/sites/5/2016/12/data-science-blog-logo-de-300x284.pngRedaktion2024-03-19 08:14:592024-03-17 22:15:15Espresso AI: Q&A mit Mathias Golombek, CTO bei Exasol
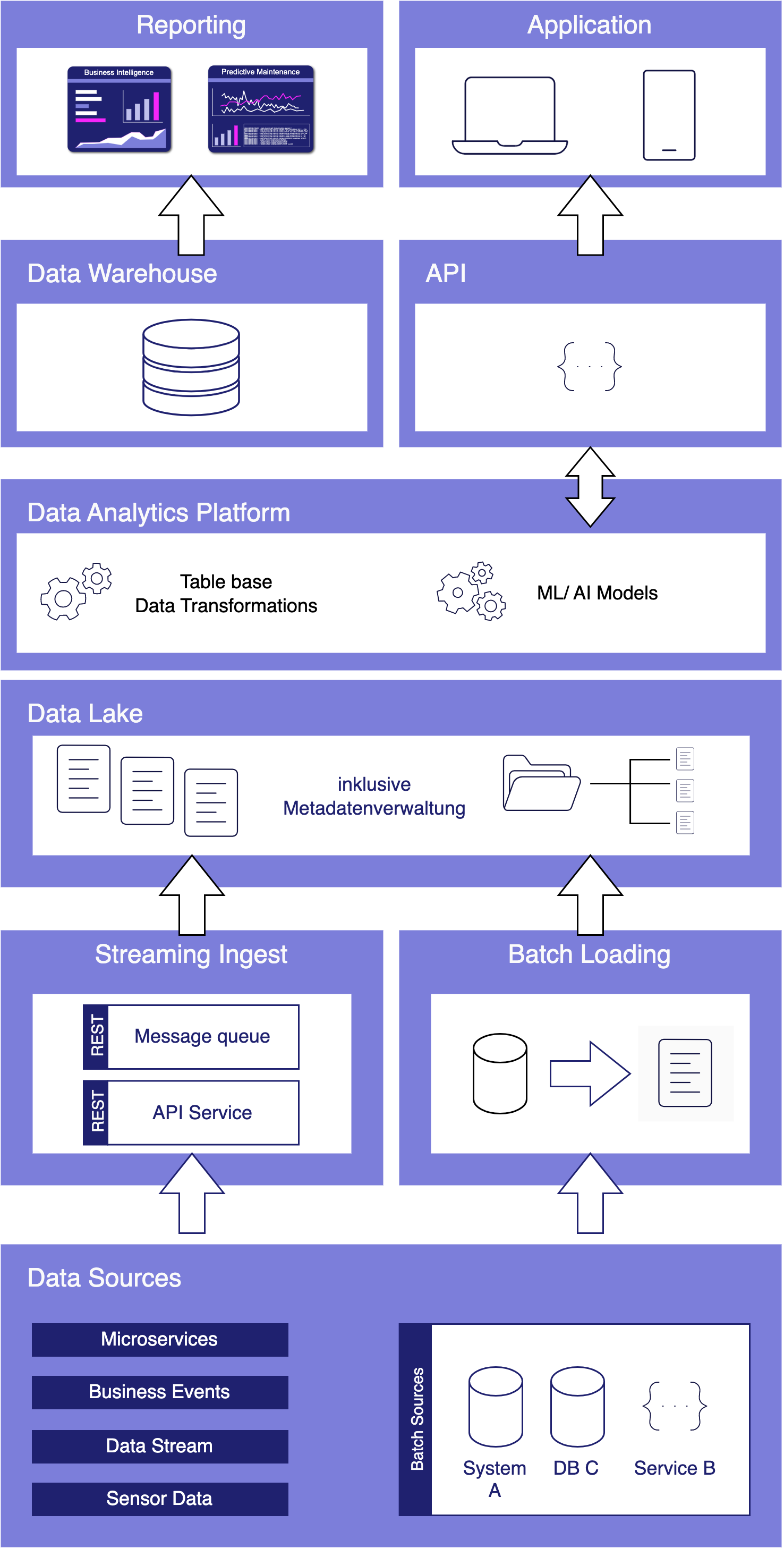
Process mining has emerged as a powerful Business Process Intelligence discipline (BPI) for analyzing and improving business processes. It involves extracting data from source systems to gain insights into process behavior and uncover opportunities for optimization. While there are many approaches to create value with process mining, organizations often face challenges when it comes to the cost of implementing the necessary solution. In this article, we will highlight the key elements when it comes to process mining architectures as well as the most common mistakes, to help organizations leverage the power of process mining while maintain cost control.
Process Mining – Elements of Process Mining and their cost aspects
Data Extraction for process mining
Most process mining projects underestimate the complexity of data extraction. Even for well-known sources like SAP-ERP’s, the extraction often consumes 50% of the first pilot’s resources. As a result, the extraction pipelines are often built with the credo of “asap” and this is where the cost-drama begins. Process Mining demands Big Data in 99% of the cases, releasing bad developed extraction jobs will end in big cost chunks down the value stream. Frequently organizations perform full loads of big SAP tables, causing source system performance impact, increasing maintenance, and moving hundred GB’s of data on daily basis without any new value. Other organizations fall for the connectors, provided by some process mining platform tools, promising time-to-value being the best. Against all odds the data is getting extracted then into costly third-party platforms where they can be only consumed by the platforms process mining tool itself. On top of that, these organizations often perform more than one Business Process Intelligence discipline, resulting in extracting the exact same data multiple times.
Process Mining – Data Extraction
The data extraction for process mining should be well planed and match the data strategy of the organization. By considering lightweighted data preprocessing techniques organizations can save both time and money. When accepting the investment character of big data extractions, the investment should be done properly in the beginning and therefore cost beneficial in the long term.
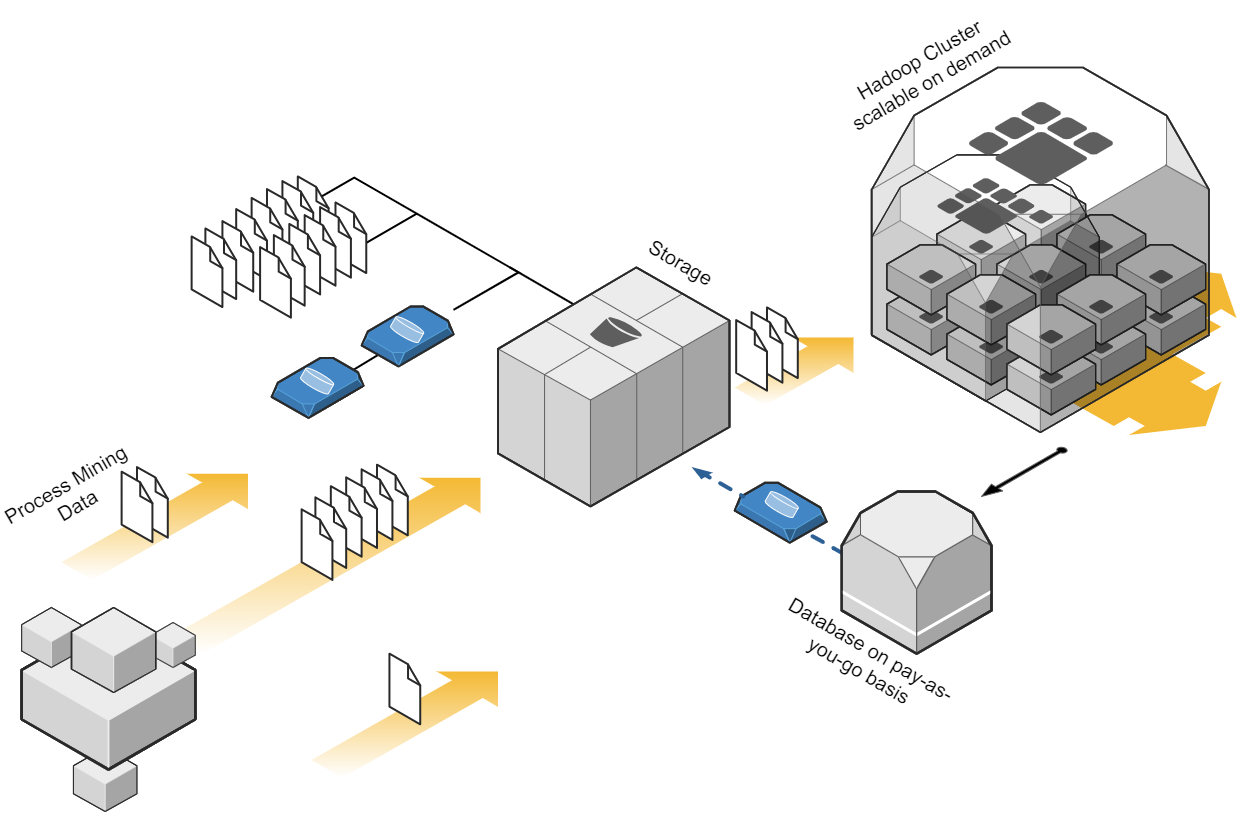
Cloud-Based infrastructure with process mining?
Depending on the data strategy of one organization, one cost-effective approach to process mining could be to leverage cloud computing resources. Cloud platforms, such as Amazon Web Services (AWS), Microsoft Azure, or Google Cloud Platform (GCP), provide scalable and flexible infrastructure options. By using cloud services, organizations can avoid the upfront investment in hardware and maintenance costs associated with on-premises infrastructure. They can pay for resources on a pay-as-you-go basis, scaling up or down as needed, which can significantly reduce costs. When dealing with big data in the cloud, meeting the performance requirements while keeping cost control can be a balancing act, that requires a high skillset in cloud technologies. Depending the organization situation and data strategy, on premises or hybrid approaches should be also considered. But costs won’t decrease only migrating from on-premises to cloud and vice versa. What makes the difference is a smart ETL design capturing the nature of process mining data.
Process Mining Cloud Architecture on “pay as you go” base.
Storage for process mining data
Storing data is a crucial aspect of process mining, as in most cases big data is involved. Instead of investing in expensive data storage solutions, which some process mining solutions offer, organizations can opt for cost-effective alternatives. Cloud storage services like Amazon S3, Azure Blob Storage, or Google Cloud Storage provide highly scalable and durable storage options at a fraction of the cost of process mining storage systems. By utilizing these services, organizations can store large volumes of event data without incurring substantial expenses. Moreover, when big data engineering technics, consider profound process mining logics the storage cost cut down can be tremendous.
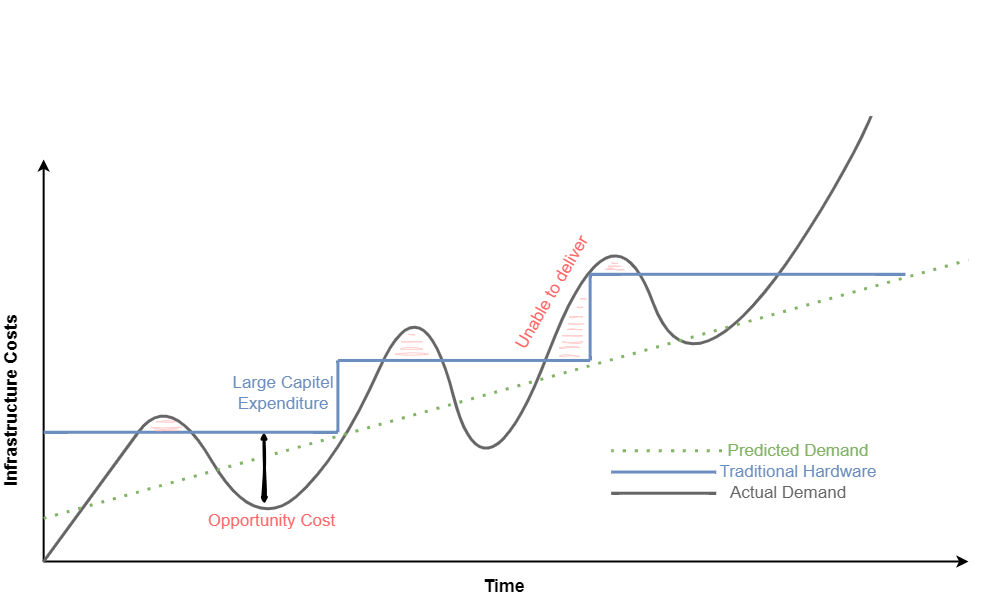
Process Mining – Infrastructure Cost Curve: On-Premise vs Cloud
Process Mining Tools
While some commercial process mining tools can be expensive, there are several powerful more economical alternatives available. Tools like Process Science, ProM, and Disco provide comprehensive process mining capabilities without the hefty price tag. These tools offer functionalities such as event log import, process discovery, conformance checking, and performance analysis. Organizations often mismanage the fact, that there can and should be more then one process mining tool available. As expensive solutions like Celonis have their benefits, not all use cases make up for the price of these tools. As a result, these low ROI-use cases will eat up the margin, or (and that’s even more critical) little promising use cases won’t be investigated on and therefore high hanging fruits never discovered. Leveraging process mining tools can significantly reduce costs while still enabling organizations to achieve valuable process insights.
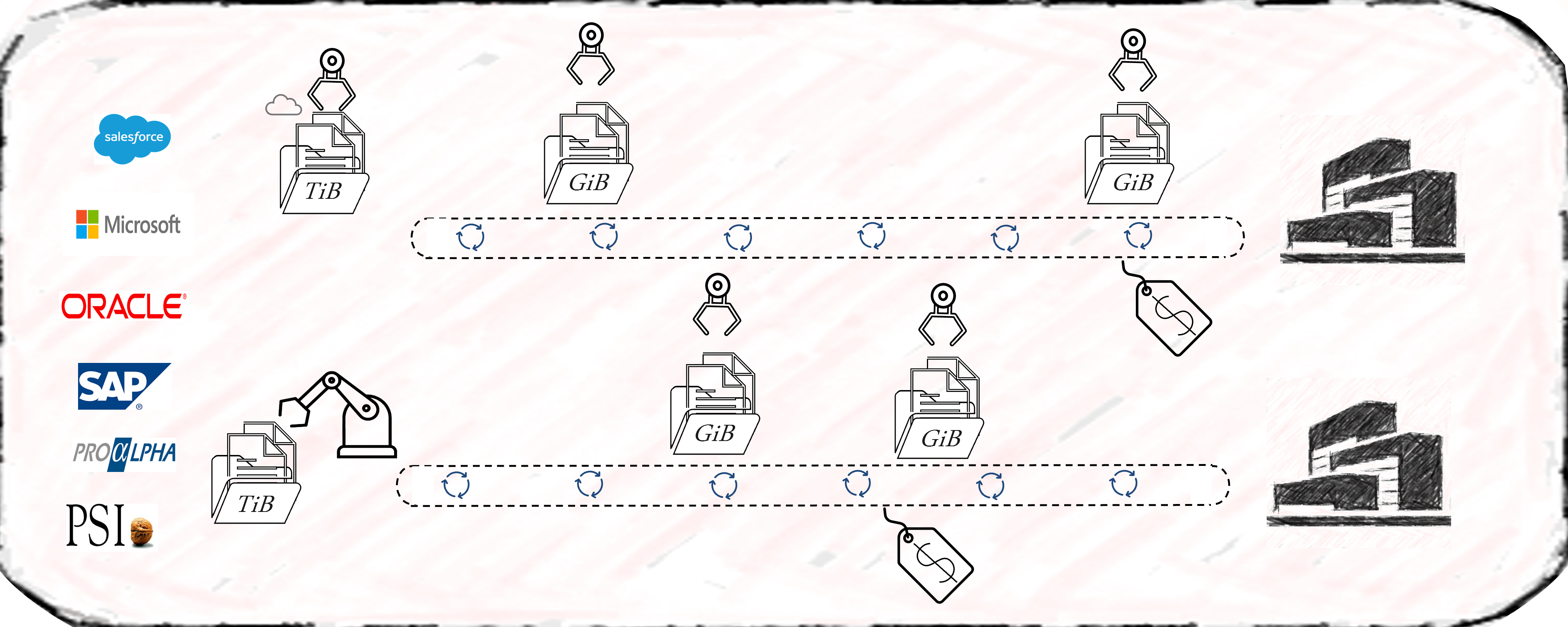
Process Mining Tool Landscape (examples shown)
Collaboration
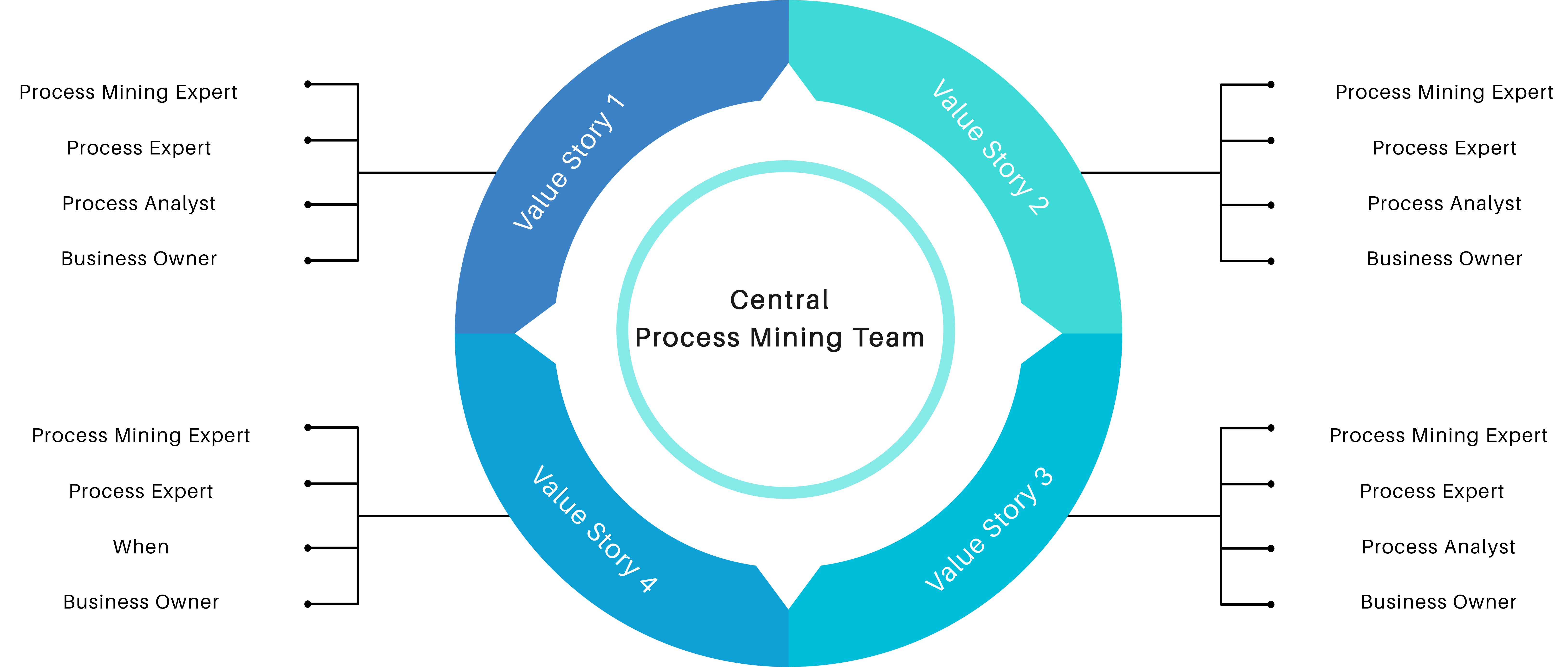
Another cost-saving aspect is to encourage collaboration within the organization itself. Most process mining initiatives require the input from process experts and often involve multiple stakeholders across different departments. By establishing cross-functional teams and supporting collaboration, organizations can share resources and distribute the cost burden. This approach allows for the pooling of expertise, reduces duplication of efforts, and facilitates knowledge exchange, all while keeping costs low.
Process Mining Team Structure
Conclusion
Process mining offers tremendous potential for organizations seeking to optimize their business processes. While many organizations start process mining projects euphorically, the costs set an abrupt end to the party. Implementing a low-cost and collaborative architecture can help to create a sustainable value for the organization. By leveraging cloud-based infrastructure, cost-effective storage solutions, big data engineering techniques, process mining tools, well developed data extractions, lightweight data preprocessing techniques, and fostering collaboration, organizations can embark on process mining initiatives without straining their budgets. With the right approach, organizations can unlock the power of process mining and drive operational excellence without losing cost control.
One might argue that implementing process mining is not only about the costs. In the end each organization must consider the long-term benefits and return on investment (ROI). But with a cost controlled and sustainable process mining approach, return on investment is likely higher and less risky.
This article provides general information for process mining cost reduction. Specific strategic decisions should always consider the unique requirements and restrictions of individual organizations.
https://data-science-blog.com/de/wp-content/uploads/sites/5/2023/06/process-mining-elements-header.png5741539Jurek Dörnerhttps://data-science-blog.com/de/wp-content/uploads/sites/5/2016/12/data-science-blog-logo-de-300x284.pngJurek Dörner2023-06-21 07:54:452023-06-21 09:06:06How to reduce costs for Process Mining
Wie können Unternehmen und andere Organisationen sicherstellen, dass kein Wissen verloren geht? Intranet, ERP, CRM, DMS oder letztendlich einfach Datenbanken mögen die erste Antwort darauf sein. Doch Datenbanken sind nicht gleich Datenbanken, ganz besonders, da operative IT-Systeme meistens auf relationalen Datenbanken aufsetzen. In diesen geht nur leider dann doch irgendwann das Wissen verloren… Und das auch dann, wenn es nie aus ihnen herausgelöscht wird!
Die meisten Datenbanken sind darauf ausgelegt, Daten zu speichern und wieder abrufbar zu machen. Neben den relationalen Datenbanken (SQL) gibt es auch die NoSQL-Datenbanken wie den Key-Value-Store, Dokumenten- und Graph-Datenbanken mit recht speziellen Anwendungsgebieten. Vektor-Datenbanken sind ein weiterer Typ von Datenbank, die unter Einsatz von AI (Deep Learning, n-grams, …) Wissen in Vektoren übersetzen und damit vergleichbarer und wieder auffindbarer machen. Diese Funktion der Datenbank spielt seinen Vorteil insbesondere bei vielen Dimensionen aus, wie sie Text- und Bild-Daten haben.
Datenbank-Typen in grobkörniger Darstellung. Es gibt in der Realität jedoch viele Feinheiten, Übergänge und Überbrückungen zwischen den Datenbanktypen, z. B. zwischen emulierter und nativer Graph-Datenbank. Manche Dokumenten- Vektor-Datenbanken können auch relationale Datenmodellierung. Und eigentlich relationale Datenbanken wie z. B. PostgreSQL können mit Zusatzmodulen auch Vektoren verarbeiten.
Vektor-Datenbanken speichern Daten grundsätzlich nicht relational oder in einer anderen Form menschlich konstruierter Verbindungen. Dennoch sichert die Datenbank gewissermaßen Verbindungen indirekt, die von Menschen jedoch – in einem hochdimensionalen Raum – nicht mehr hergeleitet werden können und sich auf bestimmte Kontexte beziehen, die sich aus den Daten selbst ergeben. Maschinelles Lernen kommt mit der nummerischen Auflösung von Text- und Bild-Daten (und natürlich auch bei ganz anderen Daten, z. B. Sound) am besten zurecht und genau dafür sind Vektor-Datenbanken unschlagbar.
Was ist eine Vektor-Datenbank?
Eine Vektordatenbank speichert Vektoren neben den traditionellen Datenformaten (Annotation) ab. Ein Vektor ist eine mathematische Struktur, ein Element in einem Vektorraum, der eine Reihe von Dimensionen hat (oder zumindest dann interessant wird, genaugenommen starten wir beim Null-Vektor). Jede Dimension in einem Vektor repräsentiert eine Art von Information oder Merkmal. Ein gutes Beispiel ist ein Vektor, der ein Bild repräsentiert: jede Dimension könnte die Intensität eines bestimmten Pixels in dem Bild repräsentieren.
Auf diese Weise kann eine ganze Sammlung von Bildern als eine Sammlung von Vektoren dargestellt werden. Noch gängiger jedoch sind Vektorräume, die Texte z. B. über die Häufigkeit des Auftretens von Textbausteinen (Wörter, Silben, Buchstaben) in sich einbetten (Embeddings). Embeddings sind folglich Vektoren, die durch die Projektion des Textes auf einen Vektorraum entstehen.
Vektor-Datenbanken sind besonders nützlich, wenn man Ähnlichkeiten zwischen Vektoren finden muss, z. B. ähnliche Bilder in einer Sammlung oder die Wörter “Hund” und “Katze”, die zwar in ihren Buchstaben keine Ähnlichkeit haben, jedoch in ihrem Kontext als Haustiere. Mit Vektor-Algorithmen können diese Ähnlichkeiten schnell und effizient aufgespürt werden, was sich mit traditionellen relationalen Datenbanken sehr viel schwieriger und vor allem ineffizienter darstellt.
Vektordatenbanken können auch hochdimensionale Daten effizient verarbeiten, was in vielen modernen Anwendungen, wie zum Beispiel Deep Learning, wichtig ist. Einige Beispiele für Vektordatenbanken sind Elasticsearch / Vector Search, Weaviate, Faiss von Facebook und Annoy von Spotify.
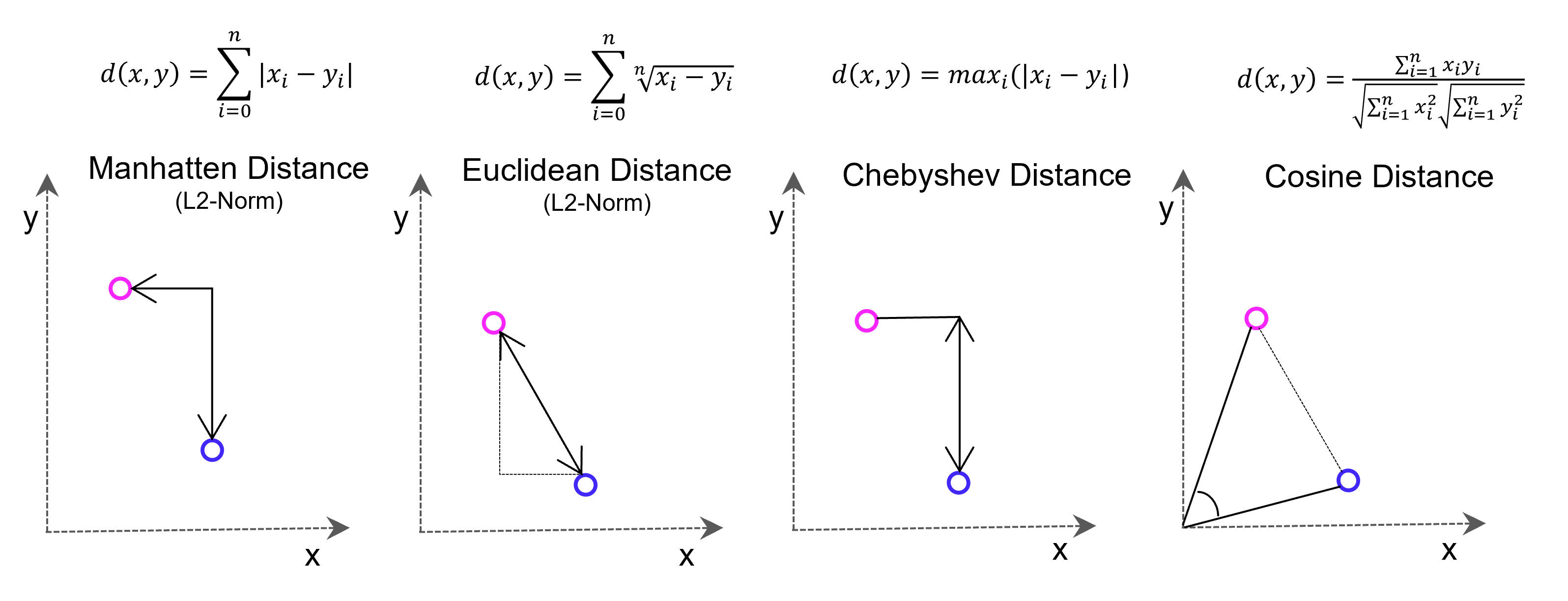
Viele Lernalgorithmen des maschinellen Lernens basieren auf Vektor-basierter Ähnlichkeitsmessung, z. B. der k-Nächste-Nachbarn-Prädiktionsalgorithmus (Regression/Klassifikation) oder K-Means-Clustering. Die Ähnlichkeitsbetrachtung erfolgt mit Distanzmessung im Vektorraum. Die dafür bekannteste Methode, die Euklidische Distanz zwischen zwei Punkten, basiert auf dem Satz des Pythagoras (Hypotenuse ist gleich der Quadratwurzel aus den beiden Dimensions-Katheten im Quadrat, im zwei-dimensionalen Raum). Es kann jedoch sinnvoll sein, aus Gründen der Effizienz oder besserer Konvergenz des maschinellen Lernens andere als die Euklidische Distanz in Betracht zu ziehen.
Der Aufbau von künstlichen Neuronalen Netzen im Deep Learning sieht nicht vor, dass ganze Sätze in ihren textlichen Bestandteilen in das jeweilige Netz eingelesen werden, denn sie funktionieren am besten mit rein nummerischen Input. Die Texte müssen in diese transformiert werden, eventuell auch nach diesen in Cluster eingeteilt und für verschiedene Trainingsszenarien separiert werden.
Vektordatenbanken werden für die Datenvorbereitung (Annotation) und als Trainingsdatenbank für Deep Learning zur effizienten Speicherung, Organisation und Manipulation der Texte genutzt. Für Natural Language Processing (NLP) benötigen Modelle des Deep Learnings die zuvor genannten Word Embedding, also hochdimensionale Vektoren, die Informationen über Worte, Sätze oder Dokumente repräsentieren. Nur eine Vektordatenbank macht diese effizient abrufbar.
Vektor-Datenbank und Large Language Modells (LLM)
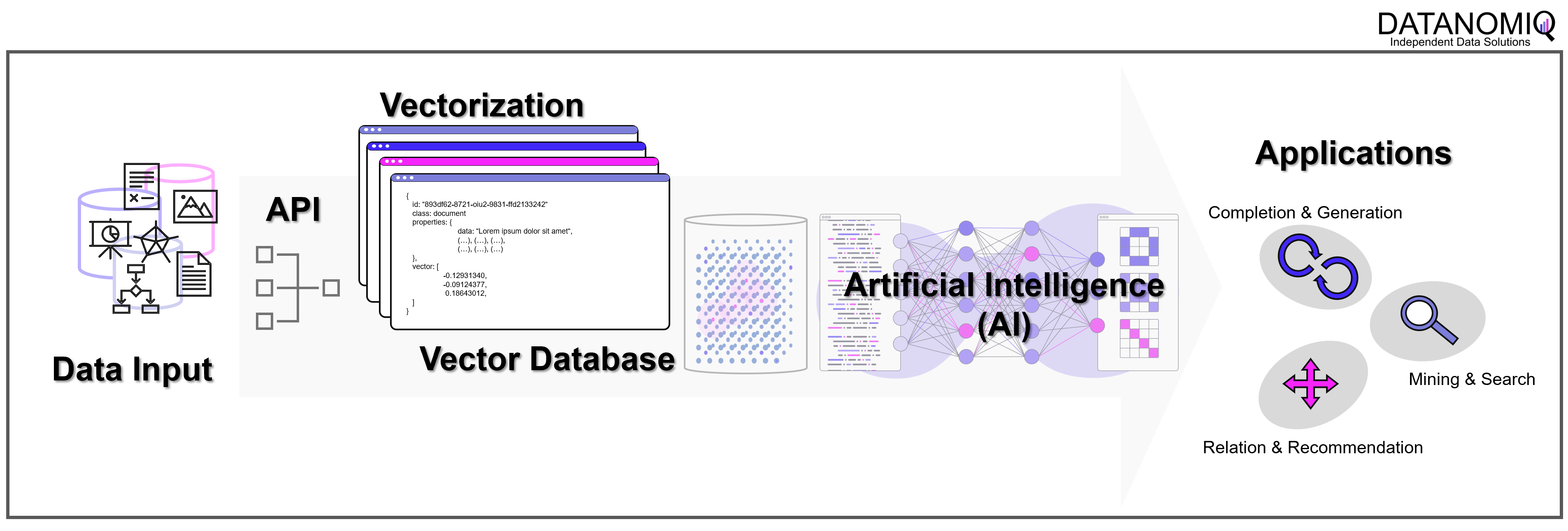
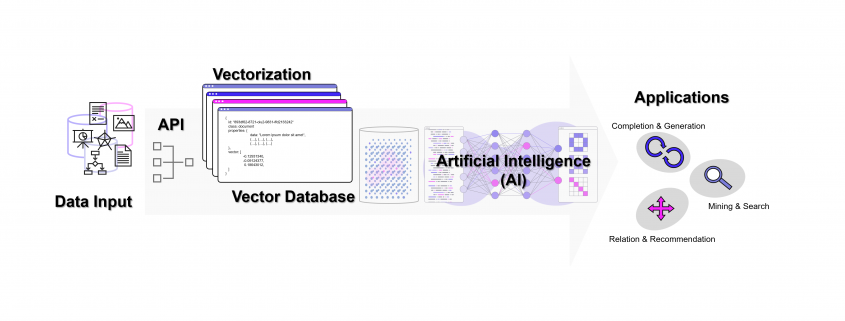
Ohne Vektor-Datenbanken wären die Erfolge von OpenAI und anderen Anbietern von LLMs nicht möglich geworden. Aber fernab der Entwicklung in San Francisco kann jedes Unternehmen unter Einsatz von Vektor-Datenbanken und den APIs von Google, OpenAI / Microsoft oder mit echten Open Source LLMs (Self-Hosting) ein wahres Orakel über die eigenen Unternehmensdaten herstellen. Dazu werden über APIs die Embedding-Engines z. B. von OpenAI genutzt. Wir von DATANOMIQ nutzen diese Architektur, um Unternehmen und andere Organisationen dazu zu befähigen, dass kein Wissen mehr verloren geht.
Mit der DATANOMIQ Enterprise AI Architektur, die auf jeder Cloud ausrollfähig ist, verfügen Unternehmen über einen intelligenten Unternehmens-Repräsentanten als KI, der für Mitarbeiter relevante Dokumente und Antworten auf Fragen liefert. Sollte irgendein Mitarbeiter im Unternehmen bereits einen bestimmten Vorgang, Vorfall oder z. B. eine technische Konstruktion oder einen rechtlichen Vertrag bearbeitet haben, der einem aktuellen Fall ähnlich ist, wird die AI dies aufspüren und sinnvollen Kontext, Querverweise oder Vorschläge oder lückenauffüllende Daten liefern.
Die AI lernt permanent mit, Unternehmenswissen geht nicht verloren. Das ist Wissensmanagement auf einem neuen Level, dank Vektor-Datenbanken und KI.
https://data-science-blog.com/de/wp-content/uploads/sites/5/2023/05/vector-database-ai-based-applications-enterprise-text-search-generator-datanomiq-header.png16204618Benjamin Aunkoferhttps://data-science-blog.com/de/wp-content/uploads/sites/5/2016/12/data-science-blog-logo-de-300x284.pngBenjamin Aunkofer2023-05-22 11:59:292023-05-23 07:51:54Was ist eine Vektor-Datenbank? Und warum spielt sie für AI eine so große Rolle?
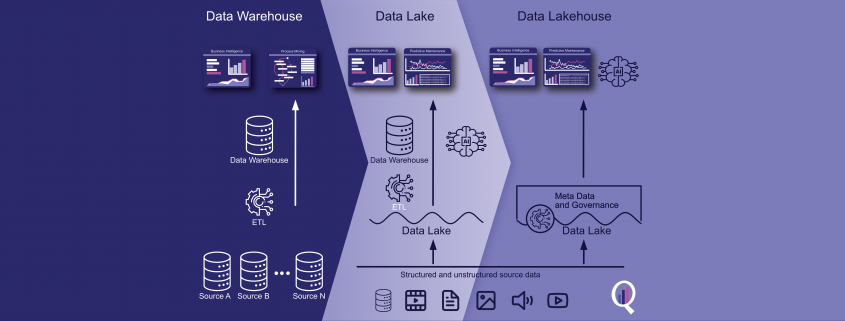
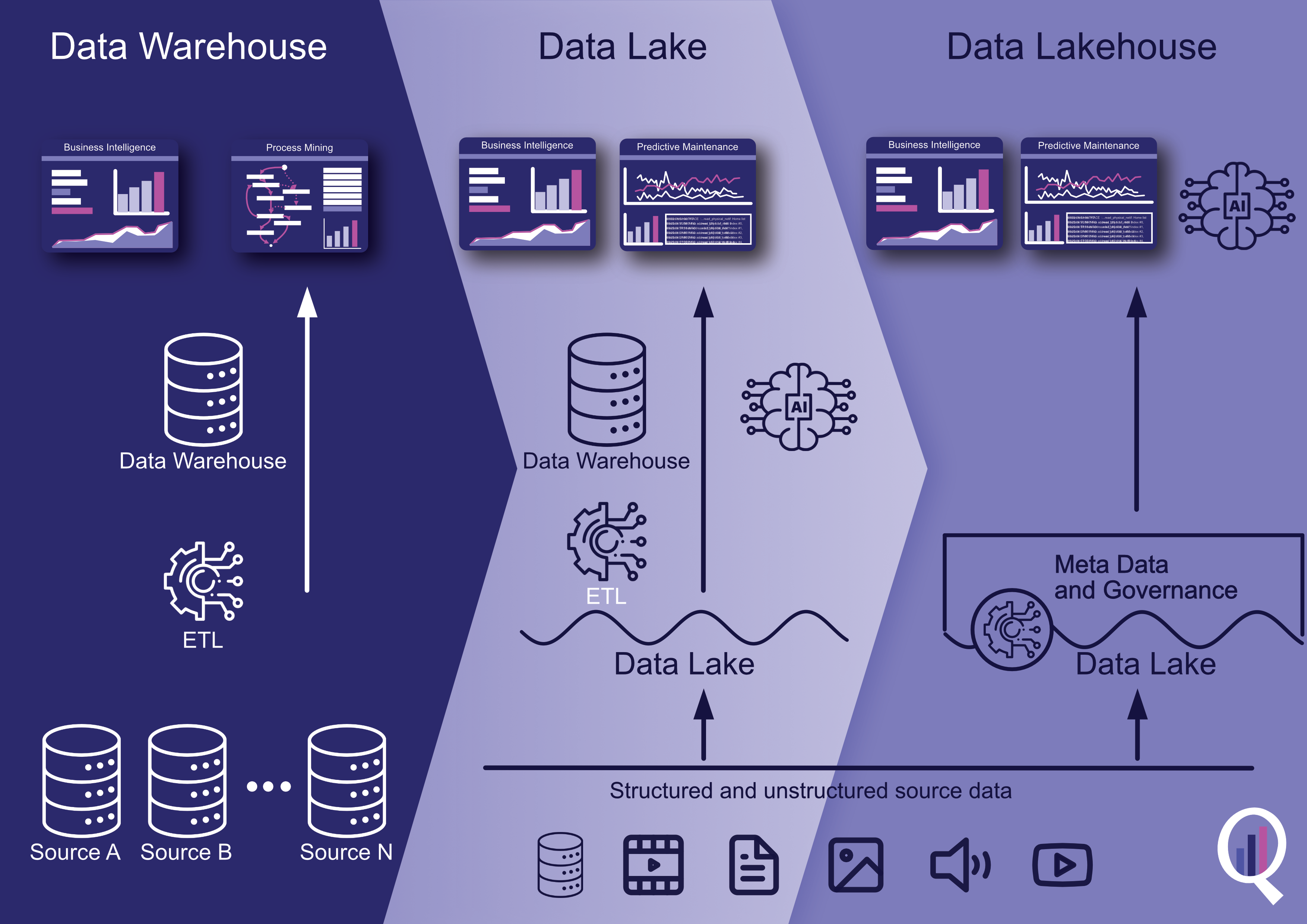
Ein Data Lakehouse ist eine moderne Datenarchitektur, die die Vorteile eines Data Lake und eines Data Warehouse kombiniert. Es kann strukturierte, halbstrukturierte und unstrukturierte Daten in einer Vielzahl von Formaten speichern und verarbeiten und bietet eine flexible und skalierbare Möglichkeit zur Speicherung und Analyse großer Datenmengen. In diesem Artikel werden die Geschichte von Data Lakehouses, ihre Vor- und Nachteile sowie einige der am häufigsten verwendeten Tools für ihre Erstellung erörtert, darunter Apache Spark, Delta Lake, Databricks, Apache Hudi und Apache Iceberg. Organisationen können je nach ihren spezifischen Bedürfnissen und Anforderungen zwischen einem Data Warehouse und einem Data Lakehouse wählen.
Einführung
In der Welt der Daten ist der Begriff Data Lakehouse allgegenwärtig und wird als Lösung für alle Datenanforderungen verkauft. Aber Moment mal, was ist eigentlich ein Data Lakehouse? Der Artikel beginnt mit einer Definition, was ein Lakehouse ist, gibt einen kurzen geschichtlichen Abriss, wie das Lakehouse entstanden ist und zeigt, warum und wie man ein Data Lakehouse aufbauen sollte.
Die Definition eines Data Lakehouse
Ein Data Lakehouse ist eine moderne Datenspeicher- und -verarbeitungsarchitektur, die die Vorteile von Data Lakes und Data Warehouses vereint. Es ist darauf ausgelegt, große Mengen an strukturierten, halbstrukturierten und unstrukturierten Daten aus verschiedenen Quellen zu verarbeiten und eine einheitliche Sicht auf die Daten für die Analyse bereitzustellen.
Data Lakehouses werden auf Cloud-basierten Objektspeichern wie Amazon S3, Google Cloud Storage oder Azure Blob Storage aufgebaut. Sie nutzen auch verteilte Computing-Frameworks wie Apache Spark, um skalierbare und effiziente Datenverarbeitungsfunktionen bereitzustellen.
In einem Data Lakehouse werden die Daten in ihrem Rohformat gespeichert, und Transformationen und Datenverarbeitung werden je nach Bedarf durchgeführt. Dies ermöglicht eine flexible und agile Datenexploration und -analyse, ohne dass komplexe Datenaufbereitungs- und Ladeprozesse erforderlich sind. Darüber hinaus können Data Governance- und Sicherheitsrichtlinien auf die Daten in einem Data Lakehouse angewendet werden, um die Datenqualität und die Einhaltung von Vorschriften zu gewährleisten.
Data Lakehouse Architecture
Eine kurze Geschichte des Data Lakehouse
Das Konzept des Data Lakehouse ist relativ neu und entstand Mitte der 2010er Jahre als Reaktion auf die Einschränkungen des traditionellen Data Warehousing und die wachsende Beliebtheit von Data Lakes.
Data Warehousing ist seit den 1980er Jahren die wichtigste Lösung für die Speicherung und Verarbeitung von Daten für Business Intelligence und Analysen. Data Warehouses wurden entwickelt, um strukturierte Daten aus Transaktionssystemen in einem zentralen Repository zu speichern, wo sie mit SQL-basierten Tools bereinigt, umgewandelt und analysiert werden konnten.
Mit der zunehmenden Datenmenge und -vielfalt wurde die Verwaltung von Data Warehouses jedoch immer schwieriger und teurer. Data Lakes, die Mitte der 2000er Jahre aufkamen, boten einen alternativen Ansatz für die Datenspeicherung und -verarbeitung. Data Lakes wurden entwickelt, um große Mengen an rohen und unstrukturierten Daten auf skalierbare und kostengünstige Weise zu speichern.
Data Lakes boten zwar viele Vorteile, verfügten aber nicht über die Struktur und die Data Governance-Funktionen von Data Warehouses. Dies machte es schwierig, aus den Daten aussagekräftige Erkenntnisse zu gewinnen und die Datenqualität und die Einhaltung von Vorschriften sicherzustellen.
Das Data Lakehouse wurde als Lösung für dieses Problem entwickelt und kombiniert die Vorteile von Data Lakes und Data Warehouses. Bei einem Data Lakehouse werden die Daten in ihrem Rohformat gespeichert, genau wie bei einem Data Lake. Das Data Lakehouse bietet jedoch auch die Struktur und die Governance-Funktionen eines Data Warehouse, was eine einfachere Datenverwaltung und -analyse ermöglicht.
Wann wird ein Data Lakehouse verwendet?
Ein Data Lakehouse kann für eine Vielzahl von Anwendungsfällen der Datenspeicherung und -verarbeitung eingesetzt werden, insbesondere für solche, bei denen große Mengen unterschiedlicher Datentypen aus verschiedenen Quellen anfallen. Einige häufige Anwendungsfälle sind:
Datenexploration und -erkennung: Ein Data Lakehouse ermöglicht es Benutzern, Rohdaten auf flexible und agile Weise zu untersuchen und zu analysieren, ohne dass komplexe Datenaufbereitungsprozesse erforderlich sind. Dies kann Unternehmen dabei helfen, Muster und Erkenntnisse zu erkennen, die sonst nur schwer zu entdecken wären.
Erweiterte Analysen und maschinelles Lernen: Data Lakehouses können erweiterte Analysen und maschinelles Lernen unterstützen, indem sie eine einheitliche Sicht auf die Daten bieten, die zum Trainieren von Modellen und zur Erstellung von Vorhersagen verwendet werden kann.
Datenverarbeitung in Echtzeit: Ein Data Lakehouse kann zum Speichern und Verarbeiten von Echtzeit-Datenströmen von IoT-Geräten, Social-Media-Feeds und anderen Quellen verwendet werden, um Einblicke und Maßnahmen in Echtzeit zu ermöglichen.
Datenintegration und -verwaltung: Data Lakehouses können Unternehmen dabei helfen, Daten aus verschiedenen Quellen zu integrieren und zu verwalten, um Datenqualität, Konsistenz und Compliance zu gewährleisten.
Kunde 360: Ein Data Lakehouse kann zur Konsolidierung von Kundendaten aus verschiedenen Quellen wie Transaktionssystemen, sozialen Medien und Kundensupportsystemen verwendet werden, um eine vollständige Sicht auf den Kunden zu erhalten und personalisierte Erfahrungen zu ermöglichen.
Data Lakehouse vs. Data Warehouse
Data Lakehouse Schema
Das Data Lakehouse ist also eine moderne Alternative zu Data Warehouse und Data Lake. Aber wie entscheidet man, ob man ein Data Lakehouse oder ein Data Warehouse einsetzt? Hier sind einige Faktoren, die bei der Bewertung der Verwendung eines Data Lakehouse gegenüber einem Data Warehouse für Ihr Unternehmen zu berücksichtigen sind:
Datentypen und -quellen: Wenn Ihr Unternehmen strukturierte Daten aus transaktionalen Systemen speichern und analysieren muss, ist ein Data Warehouse möglicherweise die bessere Wahl. Wenn Sie jedoch verschiedene Datentypen und -quellen haben, einschließlich unstrukturierter und halbstrukturierter Daten, ist ein Data Lakehouse die bessere Wahl.
Anforderungen an die Datenverarbeitung: Wenn Ihr Unternehmen komplexe Abfragen und Aggregationen von Daten durchführen muss, ist ein Data Warehouse möglicherweise die bessere Wahl. Wenn Sie jedoch Ad-hoc-Abfragen und explorative Analysen durchführen müssen, ist ein Data Lakehouse besser geeignet.
Datenvolumen: Wenn Sie relativ kleine Datenmengen haben, ist ein Data Warehouse möglicherweise die kostengünstigere Wahl. Wenn Sie jedoch große Datenmengen haben, die schnell wachsen, wäre ein Data Lakehouse die bessere Wahl.
Datenlatenz: Wenn Ihr Unternehmen Daten in Echtzeit verarbeiten und analysieren muss, ist ein Data Lakehouse möglicherweise die bessere Wahl. Wenn Ihre Analyse jedoch eine gewisse Latenzzeit tolerieren kann, könnte ein Data Warehouse die bessere Wahl sein.
Data Governance und Compliance: Wenn Ihr Unternehmen strenge Anforderungen an die Datenverwaltung und -einhaltung hat, ist ein Data Warehouse möglicherweise die bessere Wahl. Ein Data Lakehouse kann jedoch auch Data Governance und Compliance unterstützen, indem es die Datenabfolge, Zugriffskontrollen und Auditing-Funktionen bereitstellt.
Die Entscheidung für das eine oder das andere hängt hauptsächlich von der Menge und Häufigkeit der zu verarbeitenden Daten ab. Aber auch die Art der Daten (strukturiert oder unstrukturiert) spielt eine wichtige Rolle.
Tools zum Aufbau eines Data Lakehouse
Nachfolgend eine Liste an Tools, die für Data Lakehouses infrage kommen, ohne Anspruch auf Vollständigkeit:
Apache Spark: Spark ist eine beliebte Open-Source-Datenverarbeitungs-Engine, die für den Aufbau eines Data Lakehouse verwendet werden kann. Spark unterstützt eine Vielzahl von Datenquellen, einschließlich strukturierter, halbstrukturierter und unstrukturierter Daten, und kann sowohl für die Batch- als auch für die Echtzeit-Datenverarbeitung verwendet werden. Spark ist direkt auf mehreren Cloud-Plattformen verfügbar, darunter AWS, Azure und Google Cloud Platform.Apacke Spark ist jedoch mehr als nur ein Tool, es ist die Grundbasis für die meisten anderen Tools. So basieren z. B. Databricks und Azure Synapse auf Apache Spark, vereinfachen den Umgang mit Spark für den Benutzer dabei gleichzeitig sehr.
Delta Lake: Delta Lake ist eine Open-Source-Speicherschicht, die auf einem Data Lake läuft und Funktionen für die Zuverlässigkeit, Qualität und Leistung von Daten bietet. Delta Lake baut auf Apache Spark auf und ist auf mehreren Cloud-Plattformen verfügbar, darunter AWS, Azure und Google Cloud Platform.
AWS Lake Formation: AWS Lake Formation ist ein verwalteter Service, der den Prozess der Erstellung, Sicherung und Verwaltung eines Data Lakehouse auf AWS vereinfacht. Lake Formation bietet eine Vielzahl von Funktionen, einschließlich Datenaufnahme, Datenkatalogisierung und Datentransformation, und kann mit einer Vielzahl von Datenquellen verwendet werden.
Azure Synapse Analytics: Azure Synapse Analytics ist ein verwalteter Analysedienst, der eine einheitliche Erfahrung für Big Data und Data Warehousing bietet. Synapse Analytics umfasst eine Data Lakehouse-Funktion, die das Beste aus Data Lakes und Data Warehouses kombiniert, um eine flexible und skalierbare Lösung für die Speicherung und Verarbeitung von Daten zu bieten.
Google Cloud Data Fusion: Google Cloud Data Fusion ist ein vollständig verwalteter Datenintegrationsdienst, der zum Aufbau eines Data Lakehouse auf der Google Cloud Platform verwendet werden kann. Data Fusion bietet eine Vielzahl von Funktionen zur Datenaufnahme, -umwandlung und -verarbeitung und kann mit einer Vielzahl von Datenquellen verwendet werden.
Databricks: Databricks ist eine Cloud-basierte Datenverarbeitungs- und Analyseplattform, die auf Apache Spark aufbaut. Sie bietet einen einheitlichen Arbeitsbereich für Data Engineering, Data Science und maschinelles Lernen, der zum Aufbau und Betrieb eines Data Lakehouse verwendet werden kann. Databricks ist auf AWS, Azure und Google Cloud Platform verfügbar.
Apache Hudi: Apache Hudi ist ein Open-Source-Datenmanagement-Framework, das eine effiziente und skalierbare Datenaufnahme, -speicherung und -verarbeitung ermöglicht. Hudi bietet Funktionen wie inkrementelle Verarbeitung, Upserts und Deletes sowie Datenversionierung, um die Datenqualität in einem Data Lakehouse zu erhalten. Apache Hudi ist auf AWS, Azure und Google Cloud Platform verfügbar.
Apache Iceberg: Apache Iceberg ist ein Open-Source-Tabellenformat, das schnelle und effiziente Datenabfragen ermöglicht und gleichzeitig transaktionale und konsistente Ansichten von Daten in einem Data Lakehouse bietet. Es ist so konzipiert, dass es mit einer Vielzahl von Speichersystemen wie dem Hadoop Distributed File System (HDFS), Amazon S3 und Azure Blob Storage zusammenarbeitet. Apache Iceberg ist auf AWS, Azure und Google Cloud Platform verfügbar.
Alle diese Tools haben sich aufgrund ihrer Benutzerfreundlichkeit, Skalierbarkeit und Unterstützung für eine Vielzahl von Datenverarbeitungs- und Analyseanwendungen für den Aufbau von Data Lakehouses durchgesetzt. Die Wahl des Tools hängt von Ihren spezifischen Anforderungen ab, und es ist wichtig, jedes Tool sorgfältig zu bewerten, um festzustellen, welches den Anforderungen Ihres Unternehmens am besten entspricht.
Fazit
In diesem Artikel haben wir das Konzept des Data Lakehouse, seine Geschichte sowie seine Vor- und Nachteile erläutert. Wir haben auch über einige der gängigsten Tools gesprochen, die zum Aufbau eines Data Lakehouse verwendet werden, darunter Apache Spark, Apache Delta Lake, Databricks, Apache Hudi und Apache Iceberg.
Wir haben erörtert, wie Unternehmen zwischen einem Data Warehouse und einem Data Lakehouse wählen können und welche Faktoren bei dieser Entscheidung zu berücksichtigen sind. Zusammenfassend lässt sich sagen, dass es Vor- und Nachteile gibt, die zu berücksichtigen sind und mit den eigenen Anforderungen verglichen werden sollten.
Zusammengefasst bietet ein Data Lakehouse folgende Vor- und Nachteile:
Vorteile eines Data Lakehouse:
Flexibilität: Ein Data Lakehouse bietet eine flexible Datenarchitektur, die strukturierte, halbstrukturierte und unstrukturierte Daten in einer Vielzahl von Formaten speichern und verarbeiten kann, einschließlich Data Lakes und Data Warehouses.
Skalierbarkeit: Ein Data Lakehouse kann skaliert werden, um die Anforderungen großer und komplexer Datenverarbeitungs- und Analyse-Workloads zu erfüllen.
Kosteneffektiv: Ein Data Lakehouse kann zur Kostensenkung beitragen, indem es den Bedarf an mehreren Datensilos beseitigt und die Datenduplizierung reduziert.
Verarbeitung in Echtzeit: Ein Data Lakehouse kann für die Datenverarbeitung in Echtzeit genutzt werden, so dass Unternehmen datengesteuerte Entscheidungen in Echtzeit treffen können.
Datenverwaltung: Ein Data Lakehouse kann zur Verbesserung der Data Governance beitragen, indem es ein zentrales Repository für alle Daten bereitstellt und eine fein abgestufte Zugriffskontrolle ermöglicht.
Nachteile, die vor der Entscheidung für ein Data Lakehouse zu berücksichtigen sind:
Komplexität: Der Aufbau eines Data Lakehouse kann komplex sein und erfordert ein tiefes Verständnis von Datenmanagement- und -verarbeitungstechnologien.
Datenqualität: Die Datenqualität kann in einem Data Lakehouse aufgrund der Vielfalt der Datenquellen und der fehlenden Struktur eine Herausforderung darstellen.
Sicherheit: Die Sicherheit kann in einem Data Lakehouse ein Problem darstellen, da es oft notwendig ist, den Zugriff auf große Datenmengen zu verwalten, die an verschiedenen Orten gespeichert sind.
Qualifikationen: Der Aufbau und die Pflege eines Data Lakehouse erfordern ein spezifisches Skillset, das sich von dem des traditionellen Data Warehousing oder der Big Data-Verarbeitung unterscheiden kann.
Werkzeuge: Es gibt zwar viele Tools für den Aufbau eines Data Lakehouse, aber angesichts des rasanten Innovationstempos kann es eine Herausforderung sein, mit den neuesten Tools und Technologien Schritt zu halten.
Abschließend lässt sich sagen, dass ein Data Lakehouse für Unternehmen, die eine flexible, skalierbare und kosteneffiziente Methode zur Speicherung und Verarbeitung großer Datenmengen benötigen, erhebliche Vorteile bieten. Auch wenn der Aufbau eines Data Lakehouse grundsätzlich komplexer ist, gibt es viele Tools und Technologien, die Unternehmen beim Aufbau und Betrieb einer erfolgreichen Data Lakehouse-Architektur unterstützen und dieses vereinfachen.
Haben Sie bereits ein Data Lakehouse im Einsatz oder überlegen Sie, eines für Ihr Unternehmen zu bauen? Schreiben Sie mich an!
https://data-science-blog.com/de/wp-content/uploads/sites/5/2023/05/data-lakehouse-datanomiq-header.png24816608Otrek Wilkehttps://data-science-blog.com/de/wp-content/uploads/sites/5/2016/12/data-science-blog-logo-de-300x284.pngOtrek Wilke2023-05-15 08:28:162023-05-14 20:28:49Was ist ein Data Lakehouse?
Big Data tauchte als Buzzword meiner Recherche nach erstmals um das Jahr 2011 relevant in den Medien auf. Big Data wurde zum Business-Sprech der darauffolgenden Jahre. In der Parallelwelt der ITler wurde das Tool und Ökosystem Apache Hadoop quasi mit Big Data beinahe synonym gesetzt. Der Guardian verlieh Apache Hadoop mit seinem Konzept des Distributed Computing mit MapReduce im März 2011 bei den MediaGuardian Innovation Awards die Auszeichnung “Innovator of the Year”. Im Jahr 2015 erlebte der Begriff Big Data in der allgemeinen Geschäftswelt seine Euphorie-Phase mit vielen Konferenzen und Vorträgen weltweit, die sich mit dem Thema auseinandersetzten. Dann etwa im Jahr 2018 flachte der Hype um Big Data wieder ab, die Euphorie änderte sich in eine Ernüchterung, zumindest für den deutschen Mittelstand. Die große Verarbeitung von Datenmassen fand nur in ganz bestimmten Bereichen statt, die US-amerikanischen Tech-Riesen wie Google oder Facebook hingegen wurden zu Daten-Monopolisten erklärt, denen niemand das Wasser reichen könne. Big Data wurde für viele Unternehmen der traditionellen Industrie zur Enttäuschung, zum falschen Versprechen.
Von Big Data über Data Science zu AI
Einer der Gründe, warum Big Data insbesondere nach der Euphorie wieder aus der Diskussion verschwand, war der Leitspruch “Shit in, shit out” und die Kernaussage, dass Daten in großen Mengen nicht viel wert seien, wenn die Datenqualität nicht stimme. Datenqualität hingegen, wurde zum wichtigen Faktor jeder Unternehmensbewertung, was Themen wie Reporting, Data Governance und schließlich dann das Data Engineering mehr noch anschob als die Data Science.
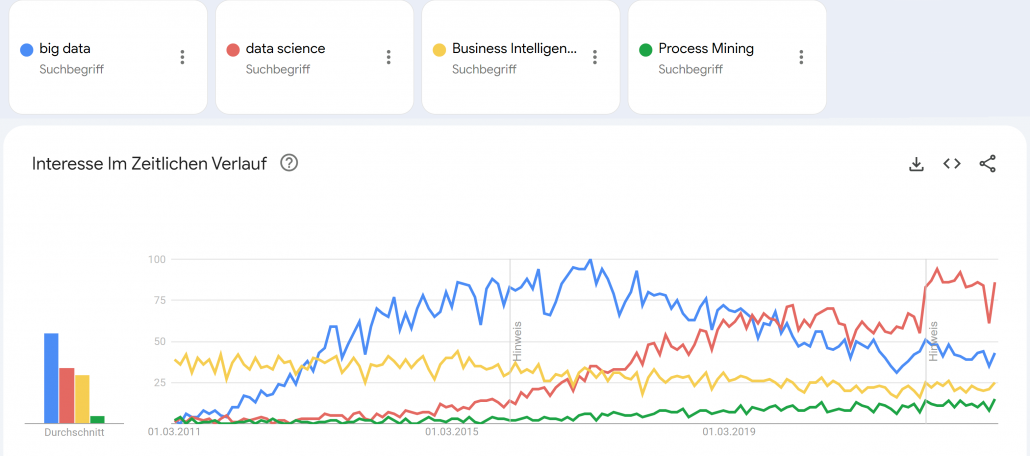
Google Trends – Big Data (blue), Data Science (red), Business Intelligence (yellow) und Process Mining (green). Quelle: https://trends.google.de/trends/explore?date=2011-03-01%202023-01-03&geo=DE&q=big%20data,data%20science,Business%20Intelligence,Process%20Mining&hl=de
Small Data wurde zum Fokus für die deutsche Industrie, denn “Big Data is messy!”1 und galt als nur schwer und teuer zu verarbeiten. Cloud Computing, erst mit den Infrastructure as a Service (IaaS) Angeboten von Amazon, Microsoft und Google, wurde zum Enabler für schnelle, flexible Big Data Architekturen. Zwischenzeitlich wurde die Business Intelligence mit Tools wie Qlik Sense, Tableau, Power BI und Looker (und vielen anderen) weiter im Markt ausgebaut, die recht neue Disziplin Process Mining (vor allem durch das deutsche Unicorn Celonis) etabliert und Data Science schloss als Hype nahtlos an Big Data etwa ab 2017 an, wurde dann ungefähr im Jahr 2021 von AI als Hype ersetzt. Von Data Science spricht auf Konferenzen heute kaum noch jemand und wurde hype-technisch komplett durch Machine Learning bzw. Artificial Intelligence (AI) ersetzt. AI wiederum scheint spätestens mit ChatGPT 2022/2023 eine neue Euphorie-Phase erreicht zu haben, mit noch ungewissem Ausgang.
Big Data Analytics erreicht die nötige Reife
Der Begriff Big Data war schon immer etwas schwammig und wurde von vielen Unternehmen und Experten schnell auch im Kontext kleinerer Datenmengen verwendet.2 Denn heute spielt die Definition darüber, was Big Data eigentlich genau ist, wirklich keine Rolle mehr. Alle zuvor genannten Hypes sind selbst Erben des Hypes um Big Data.
Während vor Jahren noch kleine Datenanalysen reichen mussten, können heute dank Data Lakes oder gar Data Lakehouse Architekturen, auf Apache Spark (dem quasi-Nachfolger von Hadoop) basierende Datenbank- und Analysesysteme, strukturierte Datentabellen über semi-strukturierte bis komplett unstrukturierte Daten umfassend und versioniert gespeichert, fusioniert, verknüpft und ausgewertet werden. Das funktioniert heute problemlos in der Cloud, notfalls jedoch auch in einem eigenen Rechenzentrum On-Premise. Während in der Anfangszeit Apache Spark noch selbst auf einem Hardware-Cluster aufgesetzt werden musste, kommen heute eher die managed Cloud-Varianten wie Microsoft Azure Synapse oder die agnostische Alternative Databricks zum Einsatz, die auf Spark aufbauen.
Die vollautomatisierte Analyse von textlicher Sprache, von Fotos oder Videomaterial war 2015 noch Nische, gehört heute jedoch zum Alltag hinzu. Während 2015 noch von neuen Geschäftsmodellen mit Big Data geträumt wurde, sind Data as a Service und AI as a Service heute längst Realität!
ChatGPT und GPT 4 sind King of Big Data
ChatGPT erschien Ende 2022 und war prinzipiell nichts Neues, keine neue Invention (Erfindung), jedoch eine große Innovation (Marktdurchdringung), die großes öffentliches Interesse vor allem auch deswegen erhielt, weil es als kostenloses Angebot für einen eigentlich sehr kostenintensiven Service veröffentlicht und für jeden erreichbar wurde. ChatGPT basiert auf GPT-3, die dritte Version des Generative Pre-Trained Transformer Modells. Transformer sind neuronale Netze, sie ihre Input-Parameter nicht nur zu Klasseneinschätzungen verdichten (z. B. ein Bild zeigt einen Hund, eine Katze oder eine andere Klasse), sondern wieder selbst Daten in ähnliche Gestalt und Größe erstellen. So wird aus einem gegeben Bild ein neues Bild, aus einem gegeben Text, ein neuer Text oder eine sinnvolle Ergänzung (Antwort) des Textes. GPT-3 ist jedoch noch komplizierter, basiert nicht nur auf Supervised Deep Learning, sondern auch auf Reinforcement Learning.
GPT-3 wurde mit mehr als 100 Milliarden Wörter trainiert, das parametrisierte Machine Learning Modell selbst wiegt 800 GB (quasi nur die Neuronen!)3.
ChatGPT basiert auf GPT-3.5 und wurde in 3 Schritten trainiert. Neben Supervised Learning kam auch Reinforcement Learning zum Einsatz. Quelle: openai.com
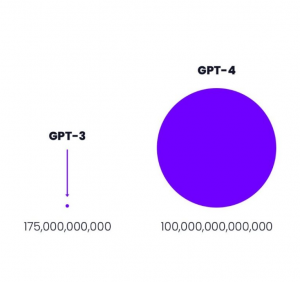
GPT-3 von openai.com war 2021 mit 175 Milliarden Parametern das weltweit größte Neuronale Netz der Welt.4
Größenvergleich: Parameteranzahl GPT-3 vs GPT-4 Quelle: openai.com
Der davor existierende Platzhirsch unter den Modellen kam von Microsoft mit “nur” 10 Milliarden Parametern und damit um den Faktor 17 kleiner. Das nun neue Modell GPT-4 ist mit 100 Billionen Parametern nochmal 570 mal so “groß” wie GPT-3. Dies bedeutet keinesfalls, dass GPT-4 entsprechend 570 mal so fähig sein wird wie GPT-3, jedoch wird der Faktor immer noch deutlich und spürbar sein und sicher eine Erweiterung der Fähigkeiten bedeuten.
Was Big Data & Analytics heute für Unternehmen erreicht
Auf Big Data basierende Systeme wie ChatGPT sollte es – der zuvor genannten Logik folgend – jedoch eigentlich gar nicht geben dürfen, denn die rohen Datenmassen, die für das Training verwendet wurden, konnten nicht im Detail auf ihre Qualität überprüft werden. Zum Einen mittelt die Masse an Daten die in ihnen zu findenden Fehler weitgehend raus, zum Anderen filtert Deep Learning selbst relevante Muster und unliebsame Ausreißer aus den Datenmassen heraus. Neuronale Netze, der Kern des Deep Learning, können durchaus als große Filter verstanden und erklärt werden.
Davon abgesehen, dass die neuen ChatBot-APIs von den Cloud-Providern Microsoft, Google und auch Amazon genutzt werden können, um Arbeitsprozesse und Kommunikation zu automatisieren, wird Big Data heute in vielen Unternehmen dazu eingesetzt, um Unternehmens-/Finanzkennzahlen auszuwerten und vorherzusagen, um Produktionsqualität zu überwachen, um Maschinen-Sensordaten mit den Geschäftsdaten aus ERP-, MES- und CRM-Systemen zu verheiraten, um operative Prozesse über mehrere IT-Systeme hinweg zu rekonstruieren und auf Schwachstellen hin zu untersuchen und um Schlussendlich auch den weiteren Datenhunger zu stillen, z. B. über Text-Extraktion aus Webseiten (Intelligence Gathering), die mit NLP und Computer Vision mächtiger wird als je zuvor.
Big Data hält sein Versprechen dank AI
Die frühere Enttäuschung aus Big Data resultierte aus dem fehlenden Vermittler zwischen Big Data (passive Daten) und den Applikationen (z. B. Industrie 4.0). Dieser Vermittler ist der aktive Part, die AI und weiterführende Datenverarbeitung (z. B. Lakehousing) und Analysemethodik (z. B. Process Mining). Davon abgesehen, dass mit AI über Big Data bereits in Medizin und im Verkehrswesen Menschenleben gerettet wurden, ist Big Data & AI längst auch in gewöhnlichen Unternehmen angekommen. Big Data hält sein Versprechen für Unternehmen doch noch ein und revolutioniert Geschäftsmodelle und Geschäftsprozesse, sichert so Wettbewerbsfähigkeit. Zumindest, wenn Unternehmen sich auf diesen Weg tatsächlich einlassen.
https://data-science-blog.com/de/wp-content/uploads/sites/5/2023/03/Fotolia_134813606_M.jpg13781378Benjamin Aunkoferhttps://data-science-blog.com/de/wp-content/uploads/sites/5/2016/12/data-science-blog-logo-de-300x284.pngBenjamin Aunkofer2023-03-14 16:31:052023-03-14 17:35:30Big Data – Das Versprechen wurde eingelöst
Das Format Business Talk am Kudamm in Berlin führte ein Interview mit Benjamin Aunkofer zu den Themen “Daten vermarkten, nicht verkaufen!”.
In dem Interview erklärt Benjamin Aunkofer, warum der Datenschutz für die meisten Anwendungsfälle keine Rolle spielt und wie Unternehmen mit Data as a Service oder AI as a Service Ihre Daten zu Geld machen, selbst dann, wenn diese Daten nicht herausgegeben werden können.
Nachfolgend das Interview auf Youtube sowie die schriftliche Form zum Nachlesen:
Nachfolgend das Transkript zum Interview:
1 – Herr Aunkofer, Daten gelten als der wichtigste Rohstoff des 22. Jahrhunderts. Bei der Vermarktung datengestützter Dienstleistung tun sich deutsche Unternehmen im Vergleich zur Konkurrenz aus den USA oder Asien aber deutlich schwerer. Woran liegt das?
Ach da will ich keinen Hehl draus machen. Die Unterschiede liegen in den verschiedenen Kulturen begründet. In den USA herrscht in der Gesellschaft ein sehr freiheitlicher Gedanke, der wohl eher darauf hinausläuft, dass wer Daten sammelt, über diese dann eben auch weitgehend verfügt.
In Asien ist die Kultur eher kollektiv ausgerichtet, um den Einzelnen geht es dort ja eher nicht so.
In Deutschland herrscht auch ein freiheitlicher Gedanke – Gott sei Dank – jedoch eher um den Schutz der personenbezogenen Daten.
Das muss nun aber gar nicht schlimm sein. Zwar mag es in Deutschland etwas umständlicher und so einen Hauch langsamer sein, Daten nutzen zu dürfen. Bei vielen Anwendungsfällen kann man jedoch sehr gut mit korrekt anonymisierten Massendaten arbeiten und bei gesellschaftsfördernen Anwendungsfällen, man denke z. B. an medizinische Vorhersagen von Diagnosen oder Behandlungserfolgen oder aber auch bei der Optimierung des öffentlichen Verkehrs, sind ja viele Menschen durchaus bereit, ihre Daten zu teilen.
Gesellschaftlichen Nutzen haben wir aber auch im B2B Geschäft, bei dem wir in Unternehmen und Institutionen die Prozesse kundenorientierter und schneller machen, Maschinen ausfallsicherer machen usw.. Da haben wir meistens sogar mit gar keinen personenbezogenen Daten zu tun.
2 – Sind die Bedenken im Zusammenhang mit Datenschutz und dem Schutz von Geschäftsgeheimnissen nicht berechtigt?
Also mit Datenschutz ist ja der gesetzliche Datenschutz gemeint, der sich nur auf personenbezogene Daten bezieht. Für Anwendungsfälle z. B. im Customer Analytics, also da, wo man Kundendaten analysieren möchte, geht das nur über die direkte Einwilligung oder eben durch anonymisierte Massendaten. Bei betrieblicher Prozessoptimierung, Anlagenoptimierung hat man mit personenbezogenen Daten aber fast nicht zu tun bzw. kann diese einfach vorher wegfiltern.
Ein ganz anderes Thema ist die Datensicherheit. Diese schließt die Sicherheit von personenbezogenen Daten mit ein, betrifft aber auch interne betriebliche Angelegenheiten, so wie etwas Lieferanten, Verträge, Preise… vielleicht Produktions- und Maschinendaten, natürlich auch Konstruktionsdaten in der Industrie.
Dieser Schutz ist jedoch einfach zu gewährleisten, wenn man einige Prinzipien der Datensicherheit verfolgt. Wir haben dafür Checklisten, quasi wie in der Luftfahrt. Bevor der Flieger abhebt, gehen wir die Checks durch… da stehen so Sachen drauf wie Passwortsicherheit, Identity Management, Zero Trust, Hybrid Cloud usw.
3 – Das Rückgrat der deutschen Wirtschaft sind die vielen hochspezialisierten KMU. Warum sollte sich beispielsweise ein Maschinenbauer darüber Gedanken machen, datengestützte Geschäftsmodelle zu entwickeln?
Nun da möchte ich dringend betonen, dass das nicht nur für Maschinenbauer gilt, aber es stimmt schon, dass Unternehmen im Maschinenbau, in der Automatisierungstechnik und natürlich der Werkzeugmaschinen richtig viel Potenzial haben, ihre Geschäftsmodelle mit Daten auszubauen oder sogar Datenbestände aufzubauen, die dann auch vermarktet werden können, und das so, dass diese Daten das Unternehmen gar nicht verlassen und dabei geheim bleiben.
4 – Daten verkaufen, ohne diese quasi zu verkaufen? Wie kann das funktionieren?
Das verrate ich gleich, aber reden wir vielleicht kurz einmal über das Verkaufen von Daten, die man sogar gerne verkauft. Das Verkaufen von Daten ist nämlich gerade so ein Trend. Das Konzept dafür heißt Data as a Service und bezieht sich dabei auf öffentliche Daten aus Quellen der Kategorie Open Data und Public Data. Diese Daten können aus dem Internet quasi gesammelt, als Datenbasis dann im Unternehmen aufgebaut werden und haben durch die Zusammenführung, Bereinigung und Aufbereitung einen Wert, der in die Millionen gehen kann. Denn andere Unternehmen brauchen vielleicht auch diese Daten, wollen aber nicht mehr warten, bis sie diese selbst aufbauen. Beispiele dafür sind Daten über den öffentlichen Verkehr, Infrastruktur, Marktpreise oder wir erheben z. B. für einen Industriekonzern Wasserqualitätsdaten beinahe weltweit aus den vielen vielen regionalen Veröffentlichungen der Daten über das Trinkwasser. Das sind zwar hohe Aufwände, aber der Wert der zusammengetragenen Daten ist ebenfalls enorm und kann an andere Unternehmen weiterverkauft werden. Und nur an jene Unternehmen, an die man das eben zu tun bereit ist.
5 – Okay, das sind öffentliche Daten, die von Unternehmen nutzbar gemacht werden. Aber wie ist es nun mit Daten aus internen Prozessen?
Interne Daten sind Geschäftsgeheimnisse und dürfen keinesfalls an Dritte weitergegeben werden. Dazu gehören beispielsweise im Handel die Umsatzkurven für bestimmte Produktkategorien sowie aber auch die Retouren und andere Muster des Kundenverhaltens, z. B. die Reaktion auf die Konfiguration von Online-Marketingkampagnen. Die Unternehmen möchten daraus jedoch Vorhersagemodelle oder auch komplexere Anomalie-Erkennung auf diese Daten trainieren, um sie für sich in ihren operativen Prozessen nutzbar zu machen. Machine Learning, übrigens ein Teilgebiet der KI (Künstlichen Intelligenz), funktioniert ja so, dass man zwei Algorithmen hat. Der erste Algorithmus ist ein Lern-Algorithmus. Diesen muss man richtig parametrisieren und überhaupt erstmal den richtigen auswählen, es gibt nämlich viele zur Auswahl und ja, die sind auch miteinander kombinierbar, um gegenseitige Schwächen auszugleichen und in eine Stärke zu verwandeln. Der Lernalgorithmus erstellt dann, über das Training mit den Daten, ein Vorhersagemodell, im Grunde eine Formel. Das ist dann der zweite Algorithmus. Dieser Algorithmus entstand aus den Daten und reflektiert auch das in den Daten eingelagerte Wissen, kanalisiert als Vorhersagemodell. Und dieses kann dann nicht nur intern genutzt werden, sondern auch anderen Unternehmen zur Nutzung zur Verfügung gestellt werden.
6 – Welche Arten von Problemen sind denn geeignet, um aus Daten ein neues Geschäftsmodell entwickeln zu können?
Alle operativen Geschäftsprozesse und deren Unterformen, also z. B. Handels-, Finanz-, Produktions- oder Logistikprozesse generieren haufenweise Daten. Das Problem für ein Unternehmen wie meines ist ja, dass wir zwar Analysemethodik kennen, aber keine Daten. Die Daten sind quasi wie der Inhalt einer Flasche oder eines Ballons, und der Inhalt bestimmt die Form mit. Unternehmen mit vielen operativen Prozessen haben genau diese Datenmengen.Ein Anwendungsfallgebiet sind z. B. Diagnosen. Das können neben medizinischen Diagnosen für Menschen auch ganz andere Diagnosen sein, z. B. über den Zustand einer Maschine, eines Prozesses oder eines ganzen Unternehmens. Die Einsatzgebiete reichen von der medizinischen Diagnose bis hin zu der Diagnose einer Prozesseffizienz oder eines Zustandes in der Wirtschaftsprüfung.Eine andere Kategorie von Anwendungsfällen sind die Prädiktionen durch Text- oder Bild-Erkennung. In der Versicherungsindustrie oder in der Immobilienbranche B. gibt es das Geschäftsmodell, dass KI-Modelle mit Dokumenten trainiert werden, so dass diese automatisiert, maschinell ausgelesen werden können. Die KI lernt dadurch, welche Textstellen im Dokument oder welche Objekte im Bild eine Rolle spielen und verwandelt diese in klare Aussagen.
Die Industrie benutzt KI zur generellen Objekterkennung z. B. in der Qualitätsprüfung. Hersteller von landwirtschaftlichen Maschinen trainieren KI, um Unkraut über auf Videobildern zu erkennen. Oder ein Algorithmus, der gelernt hat, wie Ultraschalldaten von Mirkochips zu interpretieren sind, um daraus Beschädigungen zu erkennen, so als Beispiel, den kann man weiterverkaufen.
Das Verkaufen erfolgt dabei idealerweise hinter einer technischen Wand, abgeschirmt über eine API. Eine API ist eine Schnittstelle, über die man die KI verwenden kann. Daraus wird dann AI as a Service, also KI als ein Service, den man Dritten gegen Bezahlung nutzen lassen kann.
7 – Gehen wir mal in die Praxis: Wie lassen sich aus erhobenen Daten Modelle entwickeln, die intern genutzt oder als Datenmodell an Kunden verkauft werden können?
Zuerst müssen wir die Idee natürlich richtig auseinander nehmen. Nach einer kurzen Euphorie-Phase, wie toll die Idee ist, kommt ja dann oft die Ernüchterung. Oft überwinden wir aber eben diese Ernüchterung und können starten. Der einzige Knackpunkt sind meistens fehlende Daten, denn ja, wir reden hier von großen Datenhistorien, die zum Einen überhaupt erstmal vorliegen müssen, zum anderen aber auch fast immer aufbereitet werden müssen.Wenn das erledigt ist, können wir den Algorithmus trainieren, ihn damit auf eine bestimmte Problemlösung sozusagen abrichten.Übrigens können Kunden oder Partner die KI selbst nachtrainieren, um sie für eigene besondere Zwecke besser vorzubereiten. Nehmen wir das einfache Beispiel mit der Unkrauterkennung via Bilddaten für landwirtschaftliche Maschinen. Nun sieht Unkraut in fernen Ländern sicherlich ähnlich, aber doch eben anders aus als hier in Mitteleuropa. Der Algorithmus kann jedoch nachtrainiert werden und sich der neuen Situation damit anpassen. Hierfür sind sehr viel weniger Daten nötig als es für das erstmalige Anlernen der Fall war.
8 – Viele Unternehmen haben Bedenken wegen des Zeitaufwands und der hohen Kosten für Spezialisten. Wie hoch ist denn der Zeit- und Kostenaufwand für die Implementierung solcher KI-Modelle in der Realität?
Das hängt sehr stark von der eigentlichen Aufgabenstellung ab, ob die Daten dafür bereits vorliegen oder erst noch generiert werden müssen und wie schnell das alles passieren soll. So ein Projekt dauert pauschal geschätzt gerne mal 5 bis 8 Monate bis zur ersten nutzbaren Version.
Sehen Sie die zwei anderen Video-Interviews von Benjamin Aunkofer:






 Über Exasol-CEO Martin Golombek
Über Exasol-CEO Martin Golombek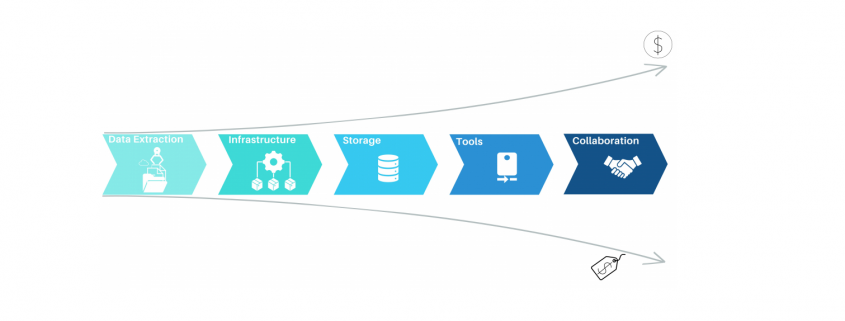 Jurek Dörner @ DATANOMIQ
Jurek Dörner @ DATANOMIQ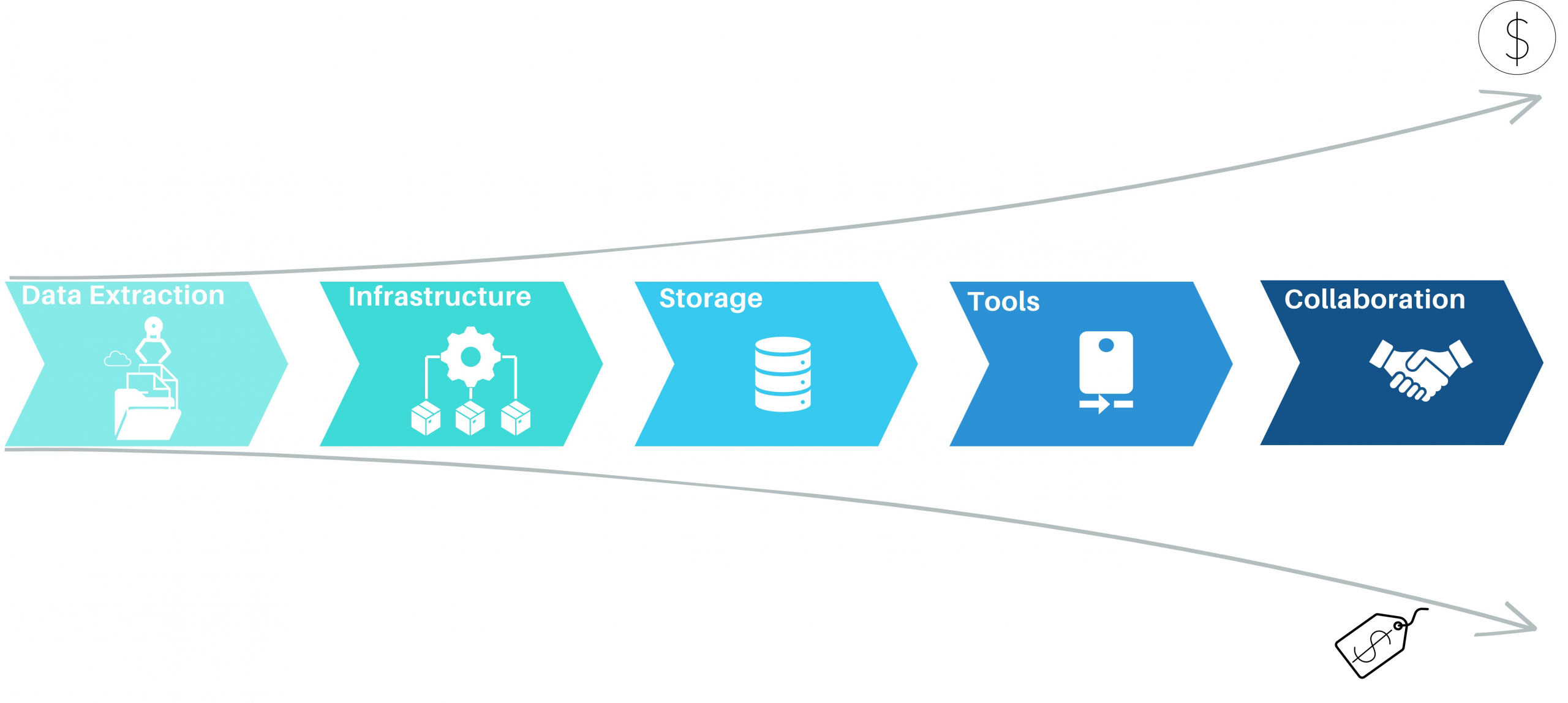

 DATANOMIQ - Benjamin Aunkofer
DATANOMIQ - Benjamin Aunkofer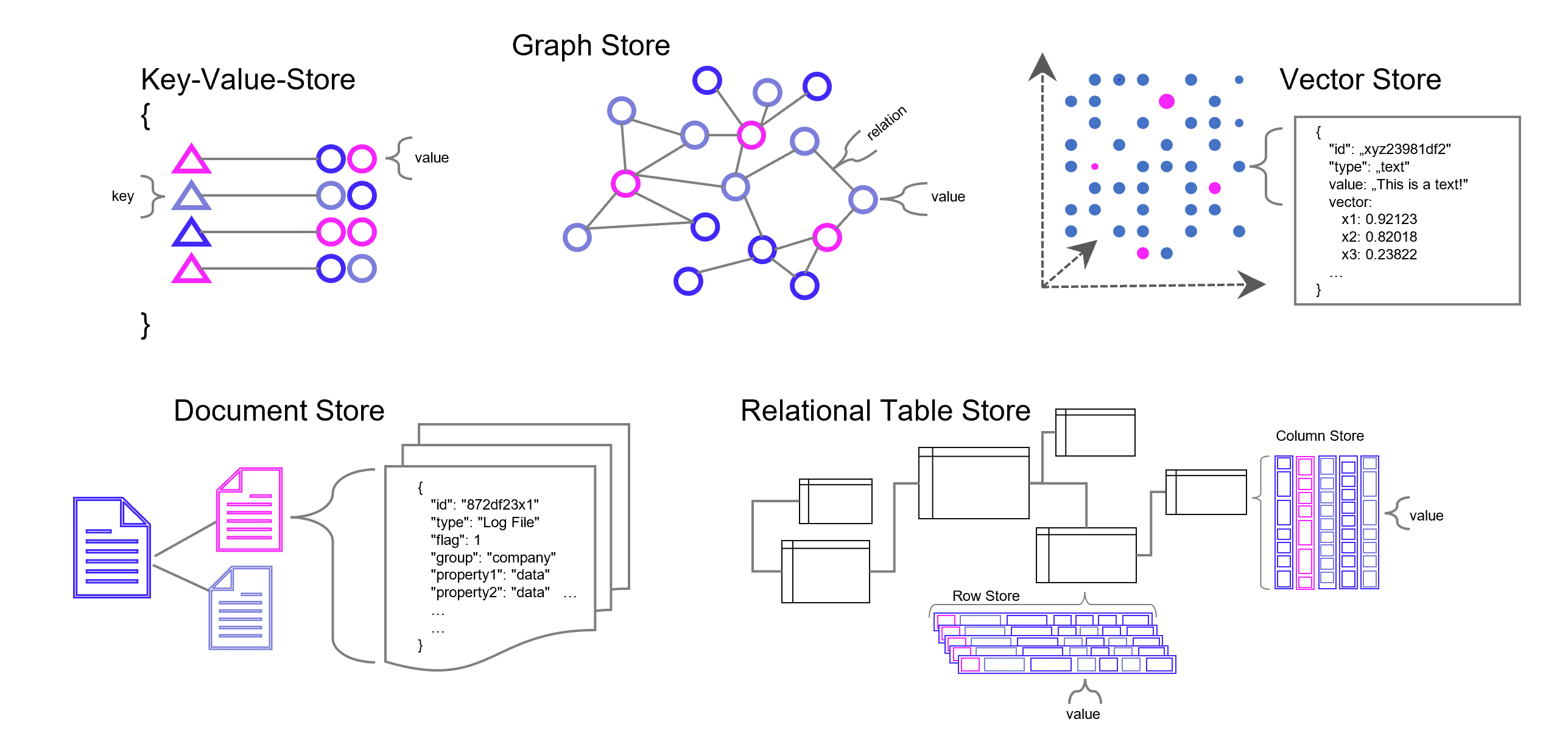
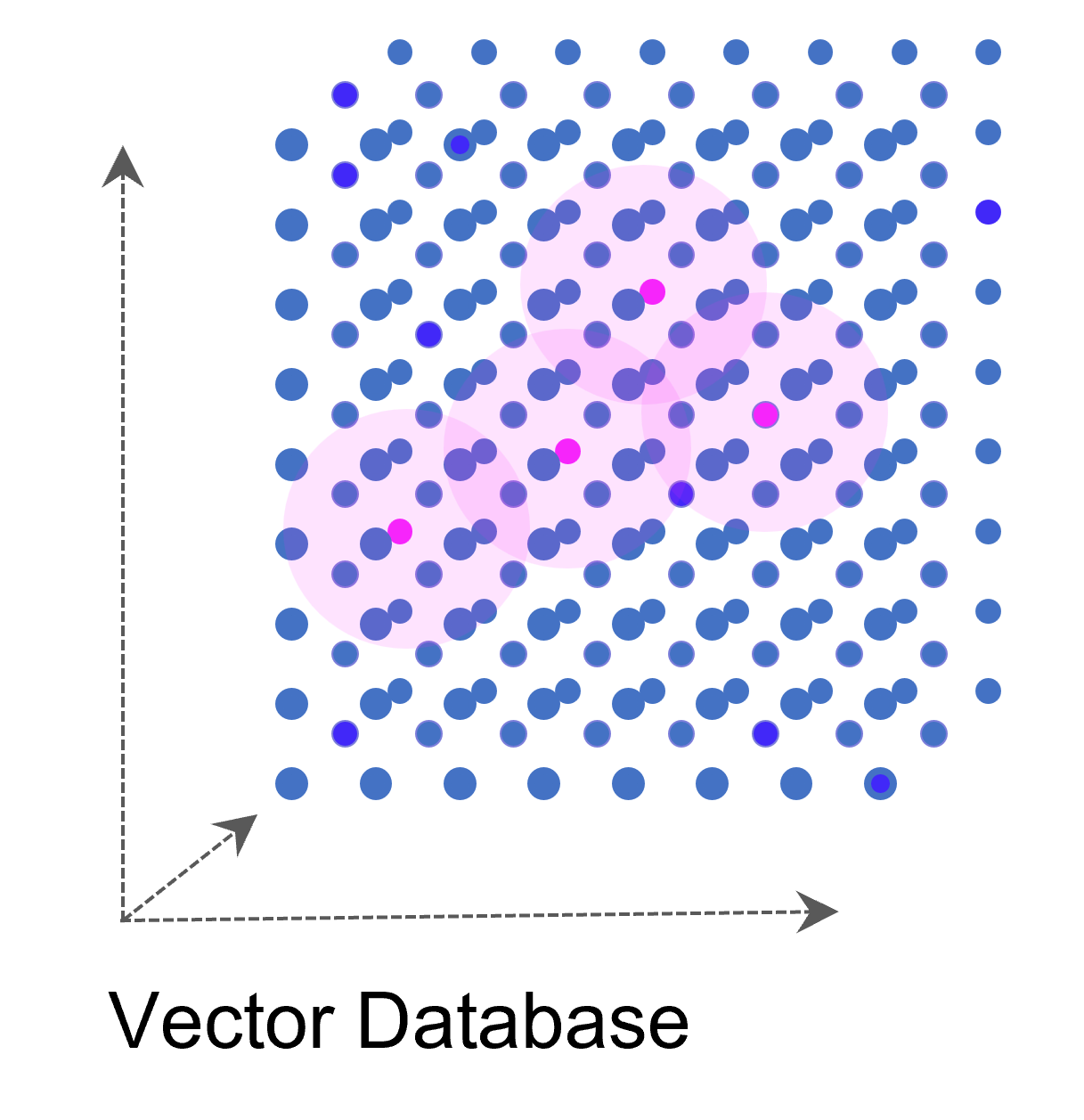 Weise kann eine ganze Sammlung von Bildern als eine Sammlung von Vektoren dargestellt werden. Noch gängiger jedoch sind Vektorräume, die Texte z. B. über die Häufigkeit des Auftretens von Textbausteinen (Wörter, Silben, Buchstaben) in sich einbetten (Embeddings). Embeddings sind folglich Vektoren, die durch die Projektion des Textes auf einen Vektorraum entstehen.
Weise kann eine ganze Sammlung von Bildern als eine Sammlung von Vektoren dargestellt werden. Noch gängiger jedoch sind Vektorräume, die Texte z. B. über die Häufigkeit des Auftretens von Textbausteinen (Wörter, Silben, Buchstaben) in sich einbetten (Embeddings). Embeddings sind folglich Vektoren, die durch die Projektion des Textes auf einen Vektorraum entstehen.