KI-gestützte Datenanalysen als Kompass für Unternehmen: Chancen und Herausforderungen
IT-Verantwortliche, Datenadministratoren, Analysten und Führungskräfte, sie alle stehen vor der Aufgabe, eine Flut an Daten effizient zu nutzen, um die Wettbewerbsfähigkeit ihres Unternehmens zu steigern. Die Fähigkeit, diese gewaltigen Datenmengen effektiv zu analysieren, ist der Schlüssel, um souverän durch die digitale Zukunft zu navigieren. Gleichzeitig wachsen die Datenmengen exponentiell, während IT-Budgets zunehmend schrumpfen, was Verantwortliche unter enormen Druck setzt, mit weniger Mitteln schnell relevante Insights zu liefern. Doch veraltete Legacy-Systeme verlängern Abfragezeiten und erschweren Echtzeitanalysen großer und komplexer Datenmengen, wie sie etwa für Machine Learning (ML) erforderlich sind. An dieser Stelle kommt die Integration von Künstlicher Intelligenz (KI) ins Spiel. Sie unterstützt Unternehmen dabei, Datenanalysen schneller, kostengünstiger und flexibler zu gestalten und erweist sich über verschiedenste Branchen hinweg als unentbehrlich.
Was genau macht KI-gestützte Datenanalyse so wertvoll?
KI-gestützte Datenanalyse verändern die Art und Weise, wie Unternehmen Daten nutzen. Präzise Vorhersagemodelle antizipieren Trends und Kundenverhalten, minimieren Risiken und ermöglichen proaktive Planung. Beispiele sind Nachfrageprognosen, Betrugserkennung oder Predictive Maintenance. Diese Echtzeitanalysen großer Datenmengen führen zu fundierteren, datenbasierten Entscheidungen.
Ein aktueller Report zur Nutzung von KI-gestützter Datenanalyse zeigt, dass Unternehmen, die KI erfolgreich implementieren, erhebliche Vorteile erzielen: schnellere Entscheidungsfindung (um 25%), reduzierte Betriebskosten (bis zu 20%) und verbesserte Kundenzufriedenheit (um 15%). Die Kombination von KI, Data Analytics und Business Intelligence (BI) ermöglicht es Unternehmen, das volle Potenzial ihrer Daten auszuschöpfen. Tools wie AutoML integrieren sich in Analytics-Datenbanken und ermöglichen BI-Teams, ML-Modelle eigenständig zu entwickeln und zu testen, was zu Produktivitätssteigerungen führt.
Herausforderungen und Chancen der KI-Implementierung
Die Implementierung von KI in Unternehmen bringt zahlreiche Herausforderungen mit sich, die IT-Profis und Datenadministratoren bewältigen müssen, um das volle Potenzial dieser Technologien zu nutzen.
- Technologische Infrastruktur und Datenqualität: Veraltete Systeme und unzureichende Datenqualität können die Effizienz der KI-Analyse erheblich beeinträchtigen. So sind bestehende Systeme häufig überfordert mit der Analyse großer Mengen aktueller und historischer Daten, die für verlässliche Predictive Analytics erforderlich sind. Unternehmen müssen zudem sicherstellen, dass ihre Daten vollständig, aktuell und präzise sind, um verlässliche Ergebnisse zu erzielen.
- Klare Ziele und Implementierungsstrategien: Ohne klare Ziele und eine durchdachte Strategie, die auch auf die Geschäftsstrategie einzahlt, können KI-Projekte ineffizient und ergebnislos verlaufen. Eine strukturierte Herangehensweise ist entscheidend für den Erfolg.
- Fachkenntnisse und Schulung: Die Implementierung von KI erfordert spezialisiertes Wissen, das in vielen Unternehmen fehlt. Die Kosten für Experten oder entsprechende Schulungen können eine erhebliche finanzielle Hürde darstellen, sind aber Grundlage dafür, dass die Technologie auch effizient genutzt wird.
- Sicherheit und Compliance: Auch Governance-Bedenken bezüglich Sicherheit und Compliance können ein Hindernis darstellen. Eine strategische Herangehensweise, die sowohl technologische, ethische als auch organisatorische Aspekte berücksichtigt, ist also entscheidend. Unternehmen müssen sicherstellen, dass ihre KI-Lösungen den rechtlichen Anforderungen entsprechen, um Datenschutzverletzungen zu vermeiden. Flexible Bereitstellungsoptionen in der Public Cloud, Private Cloud, On-Premises oder hybriden Umgebungen sind entscheidend, um Plattform- und Infrastrukturbeschränkungen zu überwinden.
Espresso AI von Exasol: Ein Lösungsansatz
Exasol hat mit Espresso AI eine Lösung entwickelt, die Unternehmen bei der Implementierung von KI-gestützter Datenanalyse unterstützt und KI mit Business Intelligence (BI) kombiniert. Espresso AI ist leistungsstark und benutzerfreundlich, sodass auch Teammitglieder ohne tiefgehende Data-Science-Kenntnisse mit neuen Technologien experimentieren und leistungsfähige Modelle entwickeln können. Große und komplexe Datenmengen können in Echtzeit verarbeitet werden – besonders für datenintensive Branchen wie den Einzelhandel oder E-Commerce ist die Lösung daher besonders geeignet. Und auch in Bereichen, in denen sensible Daten im eigenen Haus verbleiben sollen oder müssen, wie dem Finanz- oder Gesundheitsbereich, bietet Espresso die entsprechende Flexibilität – die Anwender haben Zugriff auf Realtime-Datenanalysen, egal ob sich ihre Daten on-Premise, in der Cloud oder in einer hybriden Umgebung befinden. Dank umfangreicher Integrationsmöglichkeiten mit bestehenden IT-Systemen und Datenquellen wird eine schnelle und reibungslose Implementierung gewährleistet.
Chancen durch KI-gestützte Datenanalysen
Der Einsatz von KI-gestützten Datenintegrationswerkzeugen automatisiert viele der manuellen Prozesse, die traditionell mit der Vorbereitung und Bereinigung von Daten verbunden sind. Dies entlastet Teams nicht nur von zeitaufwändiger Datenaufbereitung und komplexen Datenintegrations-Workflows, sondern reduziert auch das Risiko menschlicher Fehler und stellt sicher, dass die Daten für die Analyse konsistent und von hoher Qualität sind. Solche Werkzeuge können Daten aus verschiedenen Quellen effizient zusammenführen, transformieren und laden, was es den Teams ermöglicht, sich stärker auf die Analyse und Nutzung der Daten zu konzentrieren.
Die Integration von AutoML-Tools in die Analytics-Datenbank eröffnet Business-Intelligence-Teams neue Möglichkeiten. AutoML (Automated Machine Learning) automatisiert viele der Schritte, die normalerweise mit dem Erstellen von ML-Modellen verbunden sind, einschließlich Modellwahl, Hyperparameter-Tuning und Modellvalidierung.
Über Exasol-CEO Martin Golombek
Mathias Golombek ist seit Januar 2014 Mitglied des Vorstands der Exasol AG. In seiner Rolle als Chief Technology Officer verantwortet er alle technischen Bereiche des Unternehmens, von Entwicklung, Produkt Management über Betrieb und Support bis hin zum fachlichen Consulting.
Über Mathias Golombek

Nach seinem Informatikstudium, in dem er sich vor allem mit Datenbanken, verteilten Systemen, Softwareentwicklungsprozesse und genetischen Algorithmen beschäftigte, stieg Mathias Golombek 2004 als Software Developer bei der Nürnberger Exasol AG ein. Seitdem ging es für ihn auf der Karriereleiter steil nach oben: Ein Jahr danach verantwortete er das Database-Optimizer-Team. Im Jahr 2007 folgte die Position des Head of Research & Development. 2014 wurde Mathias Golombek schließlich zum Chief Technology Officer (CTO) und Technologie-Vorstand von Exasol benannt. In seiner Rolle als Chief Technology Officer verantwortet er alle technischen Bereiche des Unternehmens, von Entwicklung, Product Management über Betrieb und Support bis hin zum fachlichen Consulting.
Er ist der festen Überzeugung, dass sich jedes Unternehmen durch seine Grundwerte auszeichnet und diese stets gelebt werden sollten. Seit seiner Benennung zum CTO gibt Mathias Golombek in Form von Fachartikeln, Gastbeiträgen, Diskussionsrunden und Interviews Einblick in die Materie und fördert den Wissensaustausch.
 DATANOMIQ - Benjamin Aunkofer
DATANOMIQ - Benjamin Aunkofer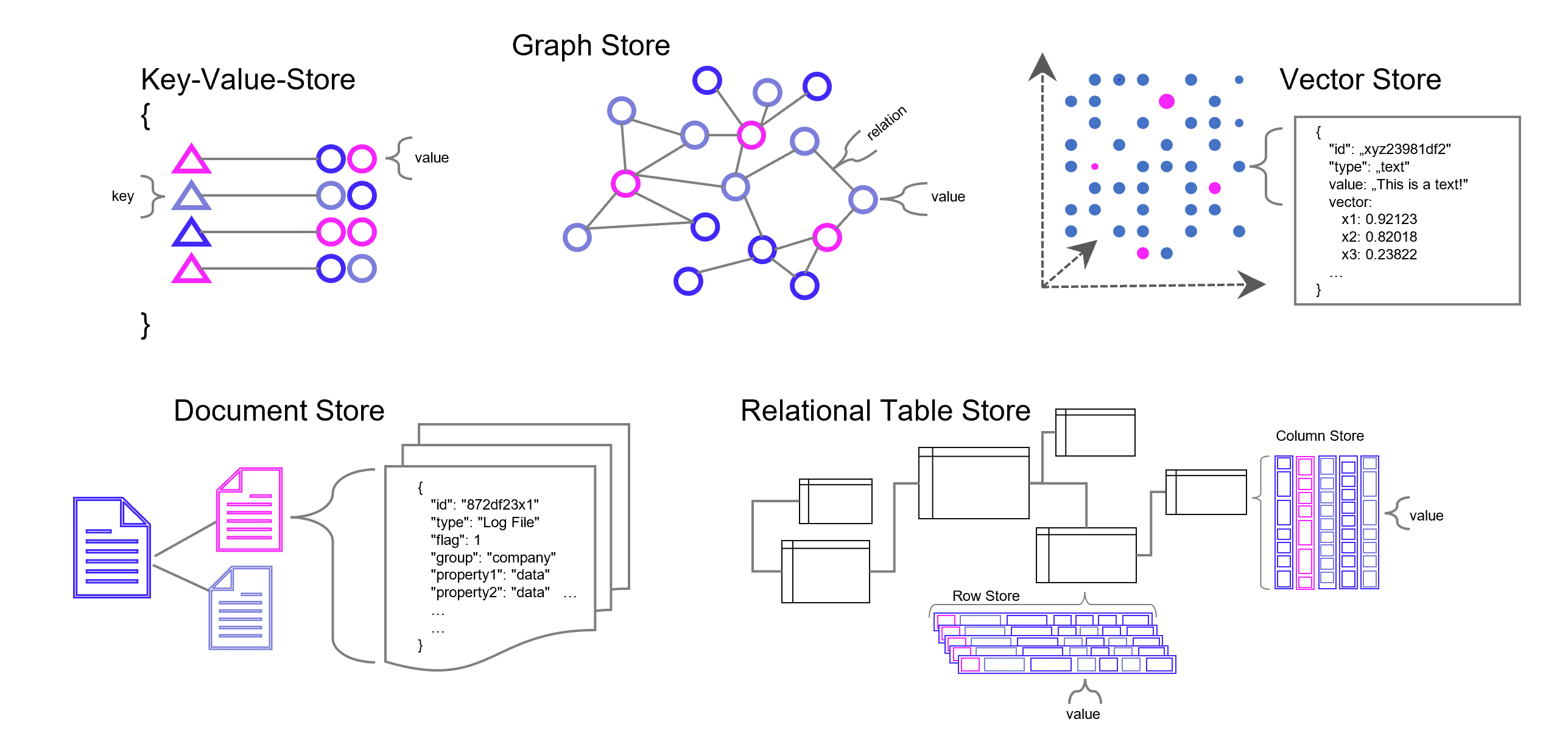
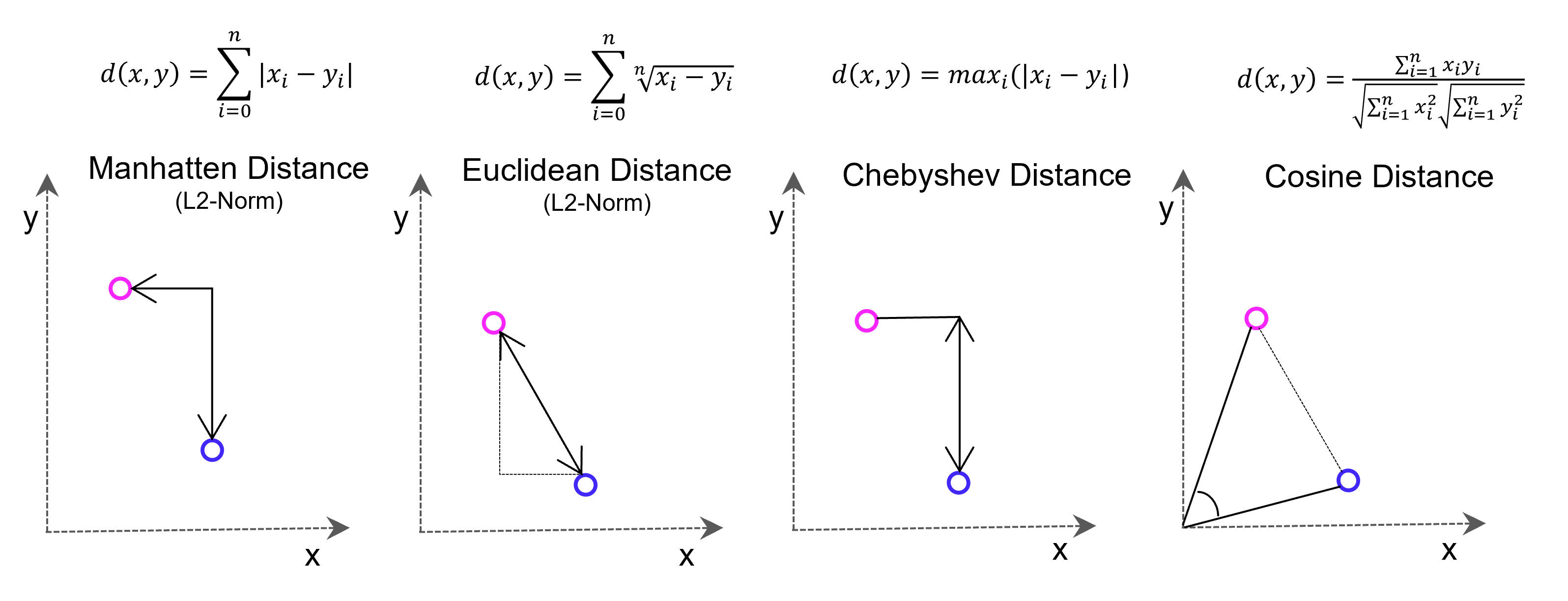
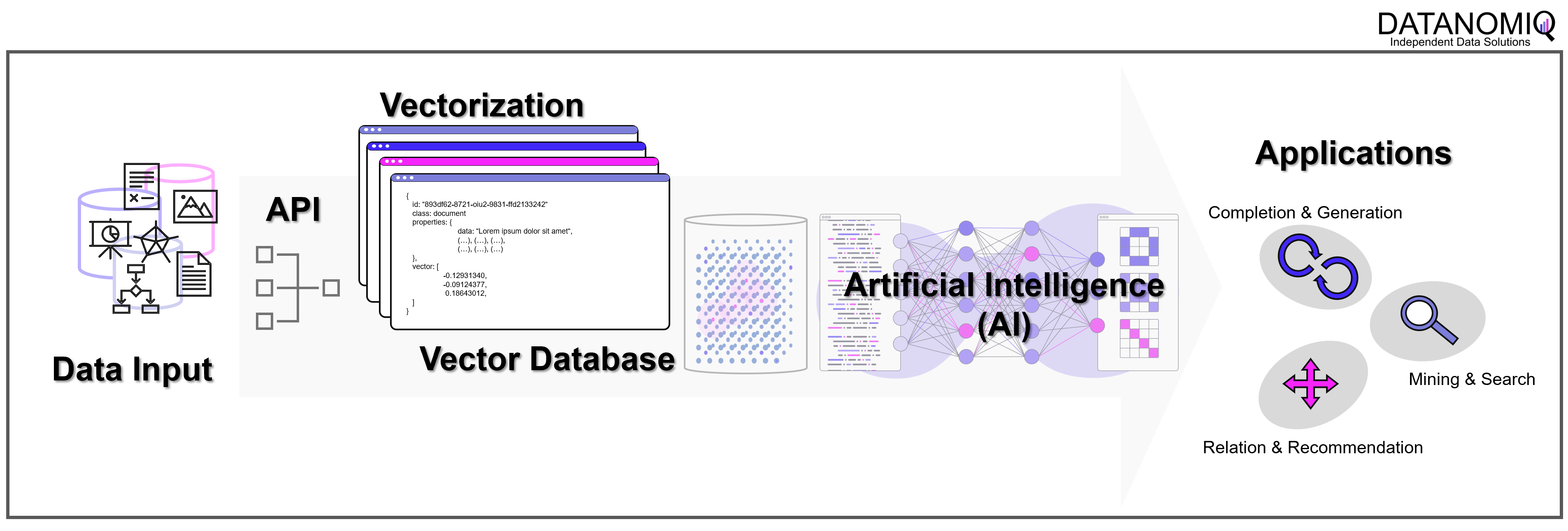
 Weise kann eine ganze Sammlung von Bildern als eine Sammlung von Vektoren dargestellt werden. Noch gängiger jedoch sind Vektorräume, die Texte z. B. über die Häufigkeit des Auftretens von Textbausteinen (Wörter, Silben, Buchstaben) in sich einbetten (Embeddings). Embeddings sind folglich Vektoren, die durch die Projektion des Textes auf einen Vektorraum entstehen.
Weise kann eine ganze Sammlung von Bildern als eine Sammlung von Vektoren dargestellt werden. Noch gängiger jedoch sind Vektorräume, die Texte z. B. über die Häufigkeit des Auftretens von Textbausteinen (Wörter, Silben, Buchstaben) in sich einbetten (Embeddings). Embeddings sind folglich Vektoren, die durch die Projektion des Textes auf einen Vektorraum entstehen.