

Sichern Sie sich ein Ticket für die Data Leader Days am 13. & 14. November 2019 in Berlin.
Nur noch wenige Summer Sale Tickets
(Angebot gültig bis zum 30. September 2019).
Alle Informationen finden Sie unter: www.dataleaderdays.com.
Haben Sie Fragen?
Kontaktieren Sie uns gerne per E-Mail: info@dataleaderday.com
Wir freuen uns auf Sie!

Sehr geehrter Kunden und Technik-Enthusiasten,
mehr wissen ist immer gut und ein hervorragender Grund das NetApp Technologie Forum Nordost zu besuchen. Unter dem Motto „aus der Region für die Region“ und bei unserem Kunden und Gastgeber der Medizinische Hochschule Hannover erfahren Sie, wie NetApp mit der Data Fabric die Konstitution Ihrer Dateninfrastruktur in Zeiten der Digitalisierung stärken kann.
Entdecken Sie das Neueste rund um HCI und unsere Cloud-Dienste sowie Aktuelles rund um ONTAP. Erste Hilfe, Absicherung, Vorsorge und Überwachung sind ebenso im Angebot wie KI vom Feinsten mit Nvidia, Hadoop, NVMe, Objektspeicher und Container-Orchestrierung. Speziell für Ihre Transformations-Beschwerden haben wir in der Session „Kunden fragen Kunden“ eine Selbsthilfegruppe mit NetApp Moderation vorgesehen.
Ihren Tagesablauf bestimmen Sie anhand der Agenda selbst. Melden Sie sich bitte schnellstmöglich an. Wir freuen uns auf Sie!
Mit freundlichen Grüßen
| Karsten Güntner District Manager |
Sven Heisig Manager Solutions Engineering |


Daten bilden das Fundament der digitalen Transformation. Die richtige Nutzung von Daten entwickelt sich daher zu einer Kernkompetenz und macht im Wettbewerb den Unterschied. Dies gilt sowohl für ganz Unternehmen als auch für einzelne Mitarbeiter, die mit Datennutzung ihre Karriere vorantreiben können.
Erfahrungen von Pionieren und führenden Anwenderunternehmen sind dafür unverzichtbar. Mit den Data Leader Days am 14. und 15. November 2018 in der Digital-Hauptstadt Berlin haben Sie die Chance, direkt von Spitzenkräften aus der Wirtschaft zu lernen und wichtige Impulse für Ihre digitale Weiterentwicklung zu erhalten.
Die Data Leader Days sind das Entscheider-Event für die Datenwirtschaft, das den Schwerpunkt auf die tatsächlichen Nutzer und Anwender-Unternehmen legt. Die Fachkonferenz hat sich seit Gründung im Jahr 2016 als eines der exklusivsten Events rund um die Themen Big Data und künstliche Intelligenz etabliert. In diesem Jahr werden die Data Leader Days erstmalig auf zwei Tage mit unterschiedlichen Schwerpunkten erweitert:
14. November 2018: Commercial & Finance Data
15. November 2018: Industrial & Automotive Data
Die Agenda ist stets aktuell direkt auf www.dataleaderdays.com zu finden.
Speaker der Data Leader Days 2018
Die Data Leader Days finden dieses Jahr zum dritten Mal statt und haben sich zur Pflichtveranstaltung für Geschäftsführer, Führungskräfte und Professionals aus den Bereichen IT, Business Intelligence und Data Analytics etabliert und empfehlen sich ebenfalls für Leiter der Funktionsbereiche Einkauf, Produktion, Marketing und Finance, die das hier brachliegende Potenzial ausschöpfen wollen.
Zum Event anmelden können sich Teilnehmer direkt auf www.dataleaderdays.com oder via Xing.com (Klick).

Anzeige
Die Technologieagentur tarent solutions GmbH präsentiert auf der DMEXCO 2018 neue Wege im Bereich Künstliche Intelligenz. Die Besucher lernen IoT-Projekte wie den interaktiven Funkstreifenwagen und die Mobile Self-Checkout-Lösung “snabble” kennen.
Am 12. und 13. September 2018 findet in Köln die DMEXCO statt, die Digital Marketing Exposition & Conference. Die Technologieagentur tarent solutions GmbH bietet an ihrem Stand (Halle 7, Stand A-031) einen Einblick in konkrete Verfahren und Technologien in den Bereichen “Internet of Things” (IoT) und “Künstliche Intelligenz” (KI).
Predictive Maintenance: Mehr Potenzial nutzen
Für Hersteller und Händler ergeben sich zahlreiche Vorteile, wenn sie die Möglichkeiten von KI und IoT richtig verstehen und effizient einsetzen. Es geht darum, Ausfälle zu minimieren, Störungen rechtzeitig vorherzusehen und sich nicht mehr um Nachbestellungen und Wartungssysteme kümmern zu müssen. Genauso relevant ist es, durch die Analyse des Produktlebenszyklusses nachhaltiger zu agieren und das Kundenverhalten besser zu verstehen und zu nutzen.
Um von diesen Vorteilen zu profitieren, müssen Unternehmen die Daten und Logfiles, die sie bereits haben oder aktuell sammeln, mit den richtigen Verfahren von KI und Machine Learning nutzbar machen – für ihr Produktmanagement, ihr Pricing und ihr Marketing. Wie das funktioniert erläutert die tarent auf der DMEXCO.
Sicher, schnell, erfolgreich: IoT in der Praxis
Ein Beispiel für moderne IoT-Projekte ist der sogenannte “Multi-PC”, der den “interaktiven Funkstreifenwagen” ermöglicht. Dabei handelt es sich um ein multifunktionales System für Sicherheit, Vernetzung und Kommunikation. Bei der Polizei in Brandenburg und Sachsen-Anhalt sind seit vielen Jahren mehrere hundert Geräte im Einsatz. Vorteile sind u. a. schnellere Abläufe durch Echtzeitübertragung, eine flächendeckendere Präsenz, eine höhere Eigen- und Fremdsicherung sowie eine optimierte Ressourcennutzung und Koordination. Neben dem Multi-PC stellt die tarent ihre Mobile Self-Checkout-Lösung “snabble” sowie ihreDigital Signage-Technologie “roomio” für Meeting- und Konferenzraumplanungen vor.
Über die tarent solutions GmbH
![]() Als Technologieagentur mit Sitz in Bonn, Köln, Berlin und Bukarest entwickeln wir seit mehr als 20 Jahren innovative Softwarelösungen für Unternehmen und integrieren diese in komplexe ITLandschaften. Besondere Expertise bieten wir in den Bereichen Wettbewerbsanalyse, Preismanagement und Mobile Self-Checkout sowie in der Erstellung hochskalierbarer Microservice-Plattformen und komplexer Integrationsprojekte.
Als Technologieagentur mit Sitz in Bonn, Köln, Berlin und Bukarest entwickeln wir seit mehr als 20 Jahren innovative Softwarelösungen für Unternehmen und integrieren diese in komplexe ITLandschaften. Besondere Expertise bieten wir in den Bereichen Wettbewerbsanalyse, Preismanagement und Mobile Self-Checkout sowie in der Erstellung hochskalierbarer Microservice-Plattformen und komplexer Integrationsprojekte.
Mehr auf www.tarent.de.
 IoT- und KI-Technologien der Zukunft_tarent auf der DMEXCO_Presseinfo
IoT- und KI-Technologien der Zukunft_tarent auf der DMEXCO_Presseinfo
DMEXCO 2018_tarent solutions GmbH
Ansprechpartner
Philip Braches
Teamleiter Vertrieb
tarent solutions GmbH
E-Mail: p.braches@tarent.de

Seit einiger Zeit versuche ich mein iPad Pro stärker in meinen Arbeitsaltag zu integrieren. Ähnlich wie Joseph (iPad Pro 10.5 as my Main Computer – Part 1, Part 2 und Part 3) sprechen auch für mich seit der Einführung des iPad Pro 9,7″, das nochmal verbesserte Display, die größeren Speicheroptionen, das faltbaren Smart Keyboard (funktioniert über einen seitlichen Konnektor und nicht über eine störanfällige BlueTooth-Verbindung) und der Apple Pencil dafür, dieses Gerät statt eines Notebooks zu nutzen.
Abbildung 1: Mein Homescreen
Neben der besseren Mobilität ist hier vor allen Dingen iOS 11 und das kommende iOS 12 zu nennen, welches mit einem verbesserte Dateisystem (transparente Einbindung von iCloud, DropBox, Google Drive etc.) und die Möglichkeit zwei Apps nebeneinander im Splitscreen auszuführen.
Apropos Apps: Diese sind ein weiteres Argument für mich, dieses Setup zu testen ist die unverändert gute bis sehr gute Qualität der verfügbaren iOS-Apps zu nutzen. Vorbei sind zum Glück die Zeiten, in der man keine eigenen Schriftarten (nach-) installieren kann (ich nutze dafür AnyFont), keine Kommendozeilenwerkzeug existieren (ich nutze StaSh), kein SSH-Tunneling (hier nutze ich SSH Tunnel von Yuri Bushev) funktioniert und sich GitHub/GitLab nicht nutzen lässt (hier nutze ich WorkingCopy). Ganze Arbeitsabläufe lassen sich darüber hinaus mit Hilfe von Workflow (und in iOS 12 mit Siri Shortcuts) automatisieren. Zum schreiben nutze ich verschiede Anwendungen, je nach Anwendungsfall. Für einfache (Markdown-) Texte nutze ich iA Writer und Editorial. Ulysses nutze ich nicht, da ich in dem Bereich Abomodelle nicht umbedingt bevorzuge, wenn es sich nicht vermeiden lässt.
Die Entwicklung von Software nativ auf dem iPad Pro funktioniert am besten mit Pythonista. Für alles andere benötigt man entsprechende Server auf denen sich der benötigte Tool-Stack befindet, welchen man benötigt. Hier nutze ich am liebsten Linux-Systeme (CentOS oder Ubuntu) da diese sehr nah an Systemen sind, welche ich für Produktivsysteme nutze.
Mit der Nutzung von Cloud-Infrastrukturen wie sie einem zum Beispiel Amazon Web Service bietet, lassen sich sehr schnell und vor allen Dingen on-demand, Systeme starten. Schnell merkt man, dass sich dieser Vorgang stark automatisieren lässt, möchte man nicht ständig mit Hilfe der AWS Console arbeiten. Mit Pythonista und der StaSh lässt sich zu diesem Zweck sehr einfach die boto2-Bibliothek installieren, welche eine direkte Anbindung des AWS SDKs über Python ermöglicht. Damit wiederum lassen sich alle AWS-Dienste als Infrastructure-as-Code nutzen.
Mit boto3 lassen sich nicht nur EC2-Instanzen starten oder der Inhalt von S3-Buckets bearbeiten. Es können auch die verschiedenen Amazon-Dienste zum Beispiel aus dem Bereich Maschine Learning genutzt werden. Damit lassen sich dann leicht Objekte in Bildern erkennen oder der Inhalt von Texten analysieren.
Möchte man effizient auf EC2-Instanzen arbeiten so lohnt ein Blick auf die UDP-basierte Mosh. Im Gegensatz zu normalen SSH-Verbindungen über TCP/IP, puffert Mosh Verbindungsabbrüche. So lassen sich Verbindungen auch nach mehreren Tagen noch ohne Probleme weiter nutzen. Genau wie SSH benötigt Mosh auch eine entsprechende Server-Komponente auf dem Host und ein Terminal, welches Mosh kann. Die Installation ist jedoch auch nicht schwieriger als bei anderer Software. Auf der Seite des iPads nutzte ich sowohl für SSH als auch Mosh die Termial-App Blink.
Wenn ich früher meinen Mac genutzt habe, dann hatte ich in der Regel mehr als eine (SSH-) Verbindung zum Zielsystem offen. Grund hierfür war, dass ich gern mehrere Dienste auf einem Server-Systems gleichzeitig im Auge behalten wollte. Ein oder zwei Fenster für die Ansicht von Logdateien mit ‘tail’, ein Fenster für meinen Lieblingseditor ‘vim’ und ein Fenster für die Arbeit auf der Kommandozeile. Seit dem ich das auf dem iPad mache, habe ich den Terminalmultiplexer tmux schätzen gelernt. Dieser ermöglicht, wie der Name sagt, die Verwaltung getrennter Sitzungen innerhalb eines Terminals (mehr dazu unter https://robots.thoughtbot.com/

Abbildung 2: Pythonista und Boto3 – Mit dem iPad die AWS kontrollieren
Seitdem es den Amazon Kindle in Deutschland gibt, nutze ich diesen Dienst. Ich hatte mir 2010 den Kindle2 noch aus den USA schicken lassen und dann irgendwann mein Konto auf den deutschen Kindle-Store migriert. Demnach nutze ich seit gut 9 Jahren die Kindle-Apps für meine Fachbücher. Auf dem iPad habe ich so bequem Zugriff auf über hundert IT- und andere Fachbücher. Papers und Cheat-Sheets speichere ich als PDFs in meinem DropBox- oder GoogleDrive-Account. Damit ich auch offline Zugriff auf die wichtigsten Manuelas habe (Python, git, ElasticSearch, Node.js etc.), nutze ich das freie Dash.
Für die Entwicklung von MVPs für den Bereich Data Science ist Spark, und hier vor allen Dingen PySpark in Kombination mit Jupyter Notebook, mein Werkzeug der Wahl. Auf den ersten Blick eine Unmöglichkeit auf dem iPad. Auf den zweiten aber lösbar. In der Regel arbeite ich eh mit Daten, welche zu groß sind um auf einem normalen Personalcomputer in endlicher Zeit effizient verarbeitet werden zu können. Hier arbeite ich mehr und mehr in der Cloud und hier aktuell verstärkt in der von Amazon.
Mein Workflow funktioniert demnach so:
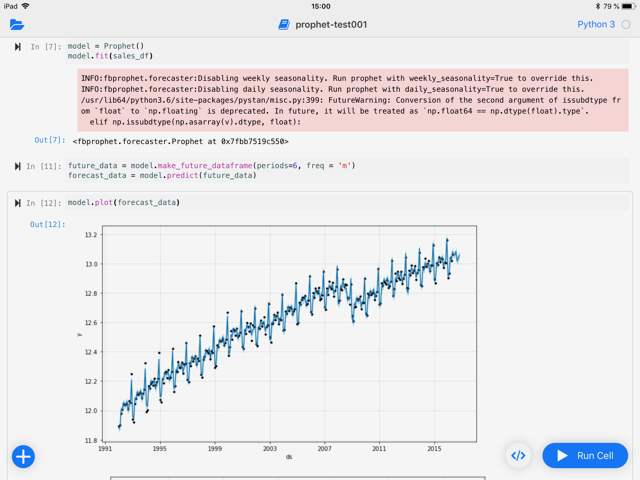
Abbildung 3: Mit Juno Jupyter Notebook aus auf dem iPad nutzen
Amazons Elastic Map Reduce Dienst bringt bereits eine Jupyter Notebook Installation inkl. Spark/PySpark mit und ermöglicht einen sicheren Zugang über einen verschlüsselten Tunnel. Einziges Problem bei der Nutzung von EMR: Alle Daten müssen in irgend einem System persistiert werden. Dies gilt nicht nur für die eigentlichen Daten sondern auch für die Notebooks. Günstiger Storage lässt sich über S3 einkaufen und mit Hilfe von s3fs-fuse (https://github.com/s3fs-fuse/
Jeder der ab und zu mal in Großraumbüros, in der Bahn oder Flugzeug arbeitet muß, kennt das Problem: Ab und zu möchte man sein Umfeld so gut es geht ausblenden um sich auf die eigene Arbeit voll und ganz zu konzentrieren. Dabei helfen kleine und große Kopfhörer ob mit oder ohne Noice Cancelation. Mit sind die Kabellosen dabei am liebsten und ich nutze lieber In-Ears als Over-Ears wegen der Wärmeentwicklung. Ich mag einfach keine warme Ohren beim Denken. Nach dem das geklärt ist wäre die nächste Frage: Musik oder Geräusche. Ab und zu kann ich Musik beim Arbeiten ertragen wenn sie
1. ohne Gesang und
2. dezent rhythmisch ist.
Zum Arbeiten höre ich dann gern Tosca, Milch Bar, oder Thievery Corporation. Schreiben kann ich unter Geräuscheinwirkung aber besser. Hier nutze ich Noisly mit ein paar eignen Presets für Wald-, Wind- und Wassergeräusche.
Das iPad Pro als Terminal des 21. Jahrhunderts bietet dank hervorragender Apps und der Möglichkeit zumindest Python nativ auszuführen, eine gute Ausgangsbasis für das mobile Arbeiten im Bereich Data Science. Hier muss man sich nur daran gewöhnen, dass man seinen Code nicht lokal ausführen kann, sondern dazu immer eine entsprechende Umgebung auf einem Server benötigt. Hier muß es nicht zwingend ein Server in der Cloud sein. Ein alter Rechner mit Linux und den nötigen Tools im Keller tut es auch. Für welches Modell man sich auch entscheidet, man sollte sehr früh Anfangen das Aufsetzten der entsprechenden Server-Umgebungen zu automatisieren (Infrastructure-as-Code). Auch hier bietet sich Pythonista (in Kombination mit Workflow) an. Was bei der täglichen Arbeit auf dem iPad manchmal stört ist, dass nicht alle Aktionen mit der Tastatur ausgeführt werden können und es hier immer noch zu einem haptischen Bruch kommt, wenn man einige Dingen nur über das Touch-Display macht und einige ausschließlich über die Tastatur. Manchmal würde ich mir auch ein größeres Display wünschen oder die Möglichkeit den Winkel des iPads auf der Tastatur ändern zu können. Diese Nachteile würde ich allerdings nicht gegen die Mobilität (Gewicht + Akkulaufzeit) eintauschen wollen.

Anzeige
In der Tagesseminarreihe „Dortmunder R-Kurse“ an der Technischen Universität Dortmund geben erfahrene Wissenschaftler der Fakultät Statistik ihre Expertise in der Anwendung der Open Source Statistiksoftware R weiter.

Von „information overload“ bis „predictive analytics“ – für Business Intelligence ist Big Data Fluch und Segen zugleich. Schnellere Rechner und höhere Speicherkapazitäten ermöglichen, immer mehr Daten zu sammeln. Aber wie werden sie im Sinne der Unternehmensziele effizient nutzbar? Artificial Intelligence (AI) ist derzeit die meistgenannte Antwort auf diese Frage und damit eines der zentralen Themen der TDWI München 2018.
Durch die intelligente Automatisierung von Prozessen ermöglicht AI die Datenmassen zu bändigen und sinnvoll zu nutzen. Auf der TDWI München wechseln Sie mit uns die BI-Fragestellung von „What happened?“ zu „What will happen next?“ und erfahren, wie Sie in Zukunft bessere Entscheidungen schneller treffen können.
Die TDWI München gibt einen vollständigen Überblick über
 Die TDWI München ist seit vielen Jahren fester Bestandteil im Kalender von Data Scientists, Business- & Data-Analysten, BI-Projektleitern, Leitern BICC/ACC und Consultants. Die Konferenz ist die zentrale Wissensdrehscheibe und Netzwerkplattform in der DACH-Region.
Die TDWI München ist seit vielen Jahren fester Bestandteil im Kalender von Data Scientists, Business- & Data-Analysten, BI-Projektleitern, Leitern BICC/ACC und Consultants. Die Konferenz ist die zentrale Wissensdrehscheibe und Netzwerkplattform in der DACH-Region.
Für mehr als 1.300 zufriedene Teilnehmer vom Neueinsteiger bis zum Profi ist die TDWI München die beste Möglichkeit für Networking und fachlichen Austausch mit Kollegen auf Augenhöhe. Aktive Pausen, Expo sowie Special Events und Abendveranstaltungen bieten Raum für Inspiration, neue Perspektiven und Lösungsansätze für Ihre aktuellen Herausforderungen.
In interaktiven Workshops können Sie mit Experten und Kollegen Ihre aktuellen Herausforderungen diskutieren. Erweitern Sie hier Ihr persönliches Netzwerk und kommen Sie Ihren Lösungen ein Stück näher.
World Café Sessions: Kontrovers, provokativ und konstruktiv – wir diskutieren die heißen Themen der Branche.
Hands-on-Workshops: Einstieg in Deep Learning, Deep Learning from Scratch with R, Text Mining in R, Your First Data Science Project, Data Science Platform und Advanced Analytics mit Python und TensorFlow
TDWI Meinungsforum: Unsere Referenten laden Sie mit polarisierenden Thesen in zwangloser Atmosphäre zur Diskussion mit Ihren Peers ein.
KI-Einsatz in der Industrie: Artificial Intelligence und das Internet of Things – in Kooperation mit Bitkom
Internet of Things/Industrie 4.0: Innovative BI-Lösungen in produzierenden Unternehmen – in Kooperation mit IIC German Regional Team
Branchentracks aus der Praxis: Was heute schon funktioniert – Anwenderberichte aus den Bereichen Handel, Automotive und Finanzen Schwerpunktthemen: Analytics (mit AI, Data Science u.v.m.), Architektur und Data Management
Die besten Talente kämpfen bei der TDWI Data Challenge um den Sieg. Im April erstellen Unternehmen Challenges auf Basis echter Projekte und Daten. Studierende und Young Professionals nehmen einzeln oder als Gruppe teil und können 4 Wochen ihre Challenge bearbeiten und zur TDWI München einreichen. Die jeweils 3 besten Einreichungen pro Challenge präsentieren ihre Ergebnisse am Dienstag vor einer Jury. Die Gewinner werden am Mittwoch prämiert.
Bitte melden Sie sich über folgenden Link zur Konferenz an: www.tdwi-konferenz.de
Deep Learning gilt als ein Teilgebiet des maschinellen Lernens (Machine Learning), welches wiederum ein Teilgebiet der künstlichen Intelligenz (Artificial Intelligence) ist. Machine Learning umfasst alle (teilweise äußerst unterschiedliche) Methoden der Klassifikation oder Regression, die die Maschine über ein vom Menschen begleitetes Training selbst erlernt. Darüber hinaus umfasst Machine Learning auch unüberwachte Methoden zum Data Mining in besonders großen und vielfältigen Datenmengen.
Deep Learning ist eine Unterform des maschinellen Lernens und macht im Grunde nichts anderes: Es geht um antrainierte Klassifikation oder Regression. Seltener werden Deep Learning Algorithmen auch als unüberwachter Lernenmechanismus verwendet, zum Lernen von Rauschen zur Erkennung von Mustern (Data Mining). Deep Learning bezeichnet den Einsatz von künstlichen neuronalen Netzen, die gegenüber anderen Verfahren des maschinellen Lernens häufig überlegen sind und diesen gegenüber auch andere Vor- und Nachteile besitzen.
Im Rahmen dieser Artikelserie erscheinen im Laufe der kommenden Monate folgende Artikel:
Seit 2016 arbeite ich mich in Deep Learning ein und biete auch Seminare und Workshops zu Machine Learning und Deep Learning an, dafür habe ich eine ausführliche Einarbeitung und ein immer wieder neu auflebendes Literaturstudium hinter mir. Unter Anderen habe ich folgende Bücher für mein Selbststudium verwendet und nutze ich auch Auszugsweise für meine Lehre:

Die Digitalisierung ist in Deutschland bereits seit Jahrzehnten am Voranschreiten. Im Gegensatz zum verbreiteten Glauben, dass die Digitalisierung erst mit der Innovation der Smartphones ihren Anfang fand, war der erste Schritt bereits die Einführung von ERP-Systemen. Sicherlich gibt es hier noch einiges zu tun, jedoch hat die Digitalisierung meines Erachtens nach das Plateau der Produktivität schon bald erreicht – Ganz im Gegensatz zur Datennutzung!
Die Digitalisierung erzeugt eine exponentiell anwachsende Menge an Daten, die ein hohes Potenzial an neuen Erkenntnissen für Medizin, Biologie, Agrawirtschaft, Verkehrswesen und die Geschäftswelt bedeuten. Es mag hier und da an Fachexperten fehlen, die wissen, wie mit großen und heterogenen Daten zu hantieren ist und wie sie zu analysieren sind. Das Aufleben dieser Experenberufe und auch neue Studengänge sorgen jedoch dafür, dass dem Mangel ein gewisser Nachwuchs entgegen steht.
Doch wie sieht es mit Führungskräften aus? Müssen Entscheider verstehen, was ein Data Engineer oder ein Data Scientist tut, wie seine Methoden funktionieren und an welche Grenzen eingesetzte Software stößt?
Als Führungskraft müssen Sie unternehmerisch denken und handeln. Wenn Sie eine neue geschäftliche Herausforderung erfolgreich bewältigen möchten, müssen Sie selbst Ideen entwickeln – oder diese zumindest bewerten – können, wie in Daten Antworten für eine Lösung gefunden werden können. Die meisten Führungskräfte reden sich erfahrungsgemäß damit heraus, dass sie selbst keine höheren Datenanalysen durchführen müssen. Unternehmen werden gegenwärtig bereits von Datenanalysten vorangetrieben und für die nahe Zukunft besteht kein Zweifel an der zunehmenden Bedeutung von Datenexperten für die Entscheidungsfindung nicht nur auf der operativen Ebene, bei der Dateningenieure sehr viele Entscheidungen automatisieren werden, sondern auch auf der strategischen Ebene.
Hinter den Begriffen Big Data und Advanced Analytics – teilweise verhasste Buzzwords – stecken reale Methoden und Technologien, die eine Führungskraft richtig einordnen können muss, um über Projekte und Invesitionen entscheiden zu können. Zumindest müssen Manager ihre Mitarbeiter kennen und deren Rollen und Fähigkeiten verstehen, dabei dürfen sie sich keinesfalls auf andere verlassen. Übrigens wissen auch viele Recruiter nicht, wen genau sie eigentlich suchen!
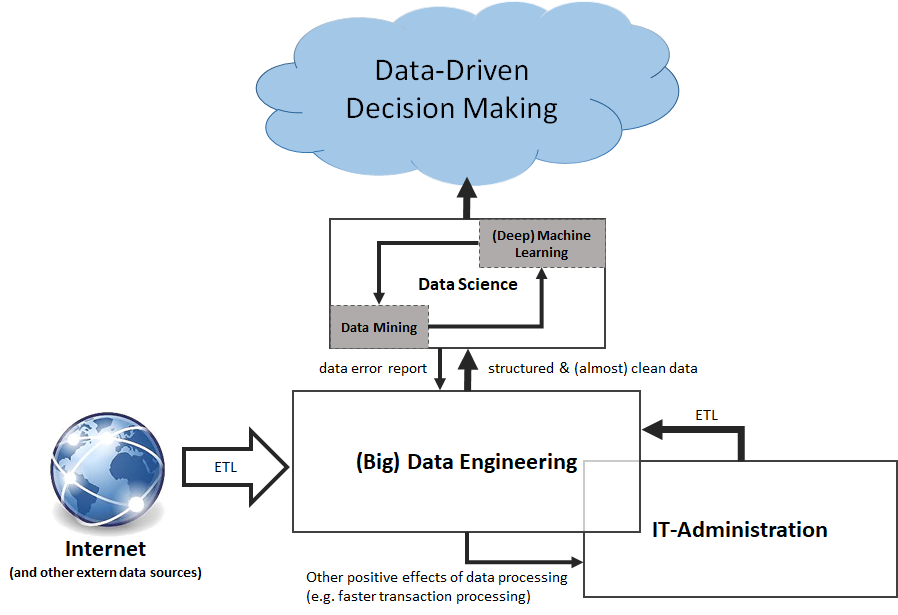
Der Weg zum Data-Driven Decision Making: Abgrenzung von IT-Administration, Data Engineering und Data Science, in Anlehnung an Data Science for Business: What you need to know about data mining and data-analytic thinking
Stark vereinfacht betrachtet, dreht sich dabei alles um Analysemethodik, Datenbanken und Programmiersprachen. Selbst unabhängig vom aktuellen Analytcs-Trend, fördert eine Einarbeitung in diese Themenfelder das logische denken und kann auch sehr viel Spaß machen. Als positiven Nebeneffekt werden Sie eine noch unternehmerischere und kreativere Denkweise entwickeln!
Nicht nur der Bedarf an Fachexperten für Data Science und Data Engineering steigt, sondern auch der Bedarf an Führungskräften bzw. Manager. Sicherlich ist der Bedarf an Führungskräften quantitativ stets geringer als der für Fachexperten, immerhin braucht jedes Team nur eine Führung, jedoch wird hier oft vergessen, dass insbesondere Data Science kein Selbstzweck ist, sondern für alle Fachbereiche (mit unterschiedlicher Priorisierung) Dienste leisten kann. Daten-Projekte scheitern entweder am Fehlen der datenaffinen Fachkräfte oder am Fehlen von datenaffinen Führungskräften in den Fachabteilungen. Unverständnisvolle Fachbereiche tendieren schnell zur Verweigerung der Mitwirkung – bis hin zur klaren Arbeitsverweigerung – auf Grund fehlender Expertise bei Führungspersonen.
Andersrum betrachtet, werden Sie als Führungskraft Ihren Marktwert deutlich steigern, wenn Sie ein oder zwei erfolgreiche Projekte in Ihr Portfolio aufnehmen können, die im engen Bezug zur Datennutzung stehen.
Führungskräfte, die zukünftige Herausforderungen meistern möchten, müssen selbst zwar nicht Data Scientist werden, jedoch dazu in der Lage sein, ein kleines Data Science Team führen zu können. Möglicherweise handelt es sich dabei nicht direkt um Ihr Team, vielleicht ist es jedoch Ihre Aufgabe, das Team durch Ihren Fachbereich zu leiten. Data Science Teams können zwar auch direkt in einer Fachabteilung angesiedelt sein, sind häufig jedoch zentrale Stabstellen.
Müssen Sie ein solches Team für Ihren Fachbereich begleiten, ist es selbstverständlich notwendig, dass sie sich über gängige Verfahren der Datenanalyse, also auch der Statistik, und der maschinellen Lernverfahren ein genaueres Bild machen. Erkennen Data Scientists, dass Sie sich als Führungskraft mit den Verfahren auseinander gesetzt haben, die wichtigsten Prozeduren, deren Anforderungen und potenziellen Ergebnisse kennen oder einschätzen können, werden Sie mit entsprechendem Respekt belohnt und Ihre Data Scientists werden Ihnen gute Berater sein, wie sie Ihre unternehmerischen Ziele mit Daten erreichen werden.

Lesetipps:



