 DATANOMIQ - Benjamin Aunkofer
DATANOMIQ - Benjamin AunkoferWas ist eine Vektor-Datenbank? Und warum spielt sie für AI eine so große Rolle?
Wie können Unternehmen und andere Organisationen sicherstellen, dass kein Wissen verloren geht? Intranet, ERP, CRM, DMS oder letztendlich einfach Datenbanken mögen die erste Antwort darauf sein. Doch Datenbanken sind nicht gleich Datenbanken, ganz besonders, da operative IT-Systeme meistens auf relationalen Datenbanken aufsetzen. In diesen geht nur leider dann doch irgendwann das Wissen verloren… Und das auch dann, wenn es nie aus ihnen herausgelöscht wird!
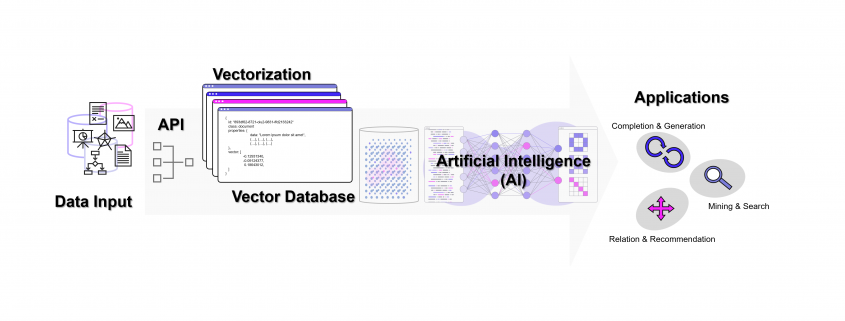
Die meisten Datenbanken sind darauf ausgelegt, Daten zu speichern und wieder abrufbar zu machen. Neben den relationalen Datenbanken (SQL) gibt es auch die NoSQL-Datenbanken wie den Key-Value-Store, Dokumenten- und Graph-Datenbanken mit recht speziellen Anwendungsgebieten. Vektor-Datenbanken sind ein weiterer Typ von Datenbank, die unter Einsatz von AI (Deep Learning, n-grams, …) Wissen in Vektoren übersetzen und damit vergleichbarer und wieder auffindbarer machen. Diese Funktion der Datenbank spielt seinen Vorteil insbesondere bei vielen Dimensionen aus, wie sie Text- und Bild-Daten haben.
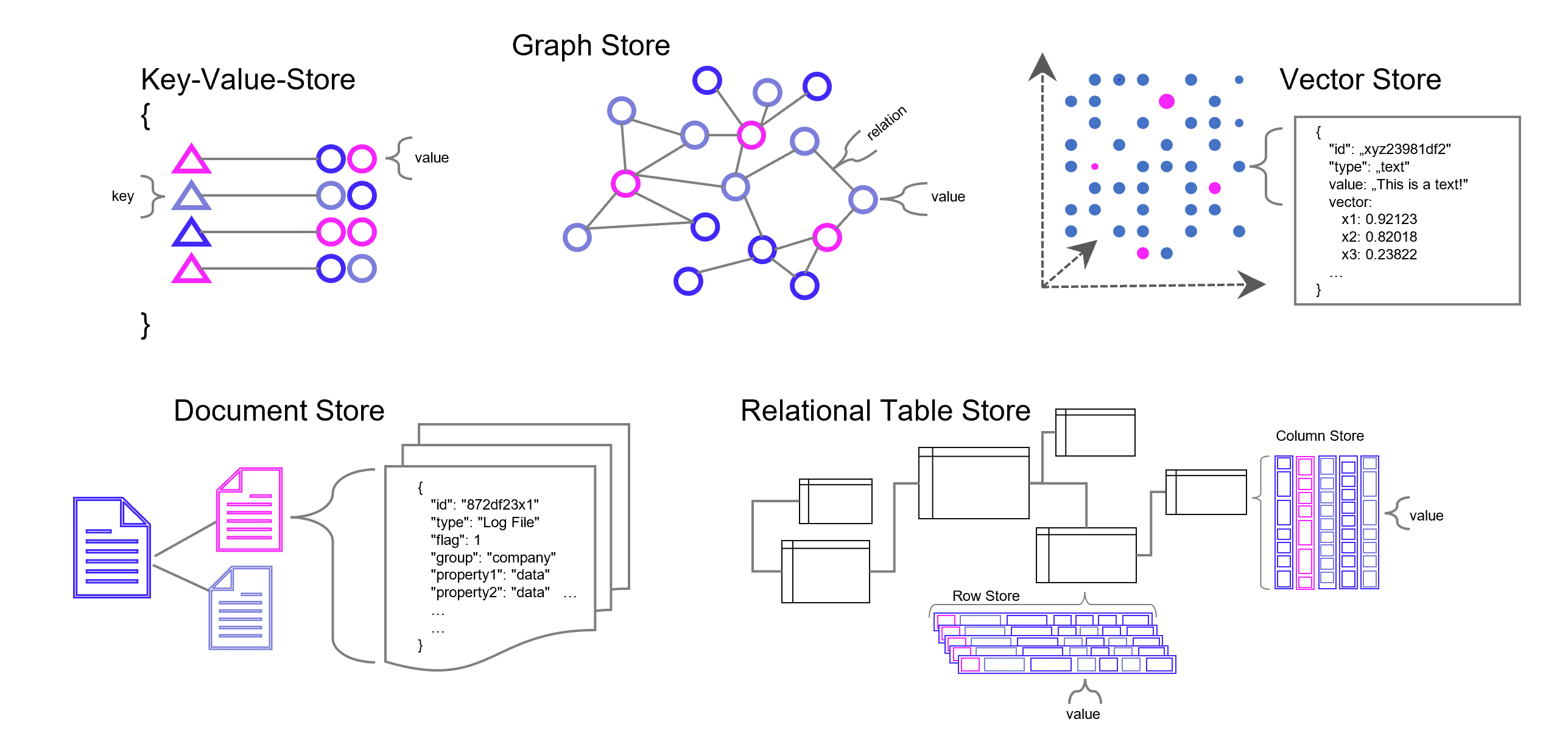
Datenbank-Typen in grobkörniger Darstellung. Es gibt in der Realität jedoch viele Feinheiten, Übergänge und Überbrückungen zwischen den Datenbanktypen, z. B. zwischen emulierter und nativer Graph-Datenbank. Manche Dokumenten- Vektor-Datenbanken können auch relationale Datenmodellierung. Und eigentlich relationale Datenbanken wie z. B. PostgreSQL können mit Zusatzmodulen auch Vektoren verarbeiten.
Vektor-Datenbanken speichern Daten grundsätzlich nicht relational oder in einer anderen Form menschlich konstruierter Verbindungen. Dennoch sichert die Datenbank gewissermaßen Verbindungen indirekt, die von Menschen jedoch – in einem hochdimensionalen Raum – nicht mehr hergeleitet werden können und sich auf bestimmte Kontexte beziehen, die sich aus den Daten selbst ergeben. Maschinelles Lernen kommt mit der nummerischen Auflösung von Text- und Bild-Daten (und natürlich auch bei ganz anderen Daten, z. B. Sound) am besten zurecht und genau dafür sind Vektor-Datenbanken unschlagbar.
Was ist eine Vektor-Datenbank?
Eine Vektordatenbank speichert Vektoren neben den traditionellen Datenformaten (Annotation) ab. Ein Vektor ist eine mathematische Struktur, ein Element in einem Vektorraum, der eine Reihe von Dimensionen hat (oder zumindest dann interessant wird, genaugenommen starten wir beim Null-Vektor). Jede Dimension in einem Vektor repräsentiert eine Art von Information oder Merkmal. Ein gutes Beispiel ist ein Vektor, der ein Bild repräsentiert: jede Dimension könnte die Intensität eines bestimmten Pixels in dem Bild repräsentieren.
Auf diese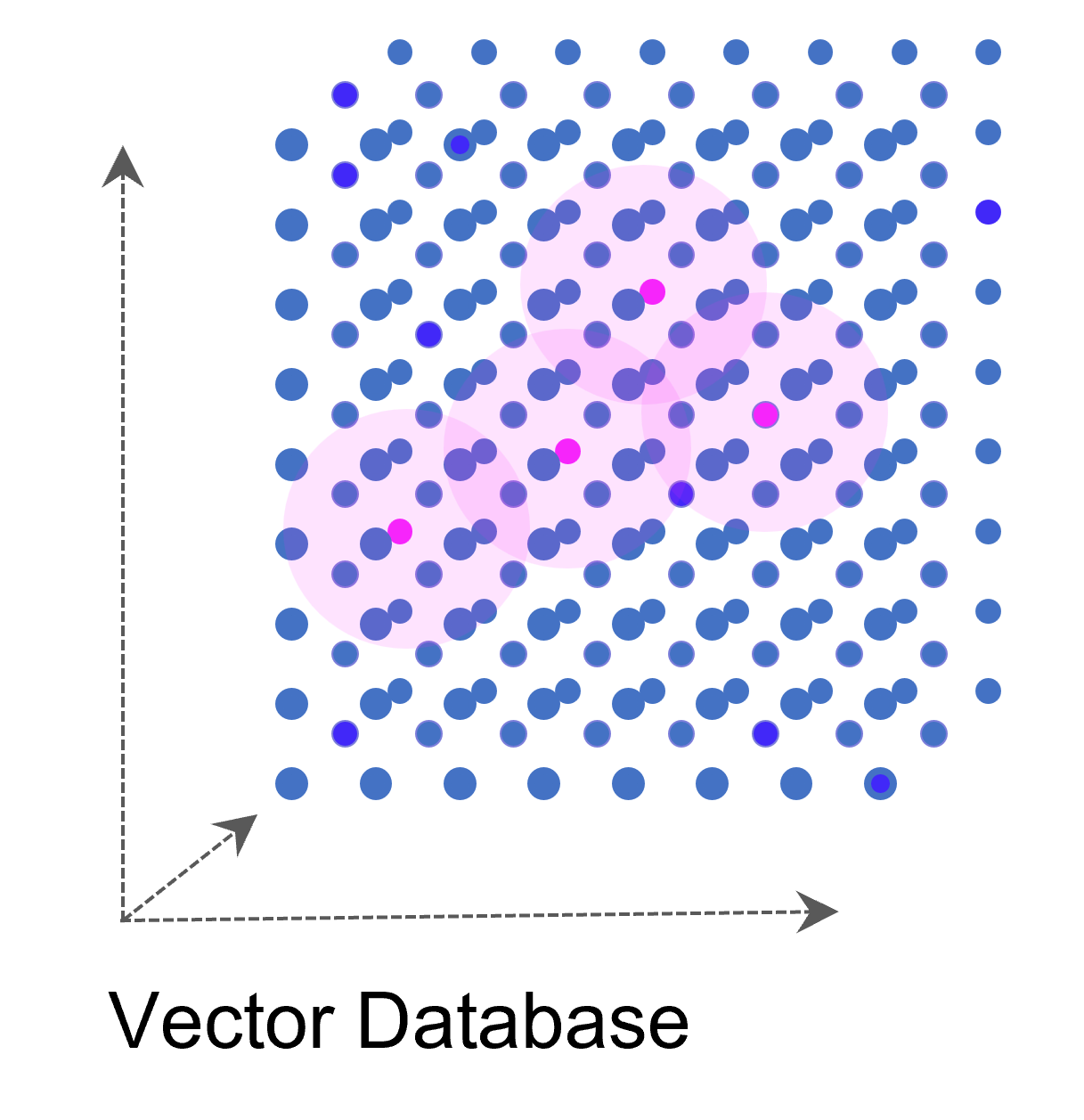 Weise kann eine ganze Sammlung von Bildern als eine Sammlung von Vektoren dargestellt werden. Noch gängiger jedoch sind Vektorräume, die Texte z. B. über die Häufigkeit des Auftretens von Textbausteinen (Wörter, Silben, Buchstaben) in sich einbetten (Embeddings). Embeddings sind folglich Vektoren, die durch die Projektion des Textes auf einen Vektorraum entstehen.
Weise kann eine ganze Sammlung von Bildern als eine Sammlung von Vektoren dargestellt werden. Noch gängiger jedoch sind Vektorräume, die Texte z. B. über die Häufigkeit des Auftretens von Textbausteinen (Wörter, Silben, Buchstaben) in sich einbetten (Embeddings). Embeddings sind folglich Vektoren, die durch die Projektion des Textes auf einen Vektorraum entstehen.
Vektor-Datenbanken sind besonders nützlich, wenn man Ähnlichkeiten zwischen Vektoren finden muss, z. B. ähnliche Bilder in einer Sammlung oder die Wörter “Hund” und “Katze”, die zwar in ihren Buchstaben keine Ähnlichkeit haben, jedoch in ihrem Kontext als Haustiere. Mit Vektor-Algorithmen können diese Ähnlichkeiten schnell und effizient aufgespürt werden, was sich mit traditionellen relationalen Datenbanken sehr viel schwieriger und vor allem ineffizienter darstellt.
Vektordatenbanken können auch hochdimensionale Daten effizient verarbeiten, was in vielen modernen Anwendungen, wie zum Beispiel Deep Learning, wichtig ist. Einige Beispiele für Vektordatenbanken sind Elasticsearch / Vector Search, Weaviate, Faiss von Facebook und Annoy von Spotify.
Viele Lernalgorithmen des maschinellen Lernens basieren auf Vektor-basierter Ähnlichkeitsmessung, z. B. der k-Nächste-Nachbarn-Prädiktionsalgorithmus (Regression/Klassifikation) oder K-Means-Clustering. Die Ähnlichkeitsbetrachtung erfolgt mit Distanzmessung im Vektorraum. Die dafür bekannteste Methode, die Euklidische Distanz zwischen zwei Punkten, basiert auf dem Satz des Pythagoras (Hypotenuse ist gleich der Quadratwurzel aus den beiden Dimensions-Katheten im Quadrat, im zwei-dimensionalen Raum). Es kann jedoch sinnvoll sein, aus Gründen der Effizienz oder besserer Konvergenz des maschinellen Lernens andere als die Euklidische Distanz in Betracht zu ziehen.
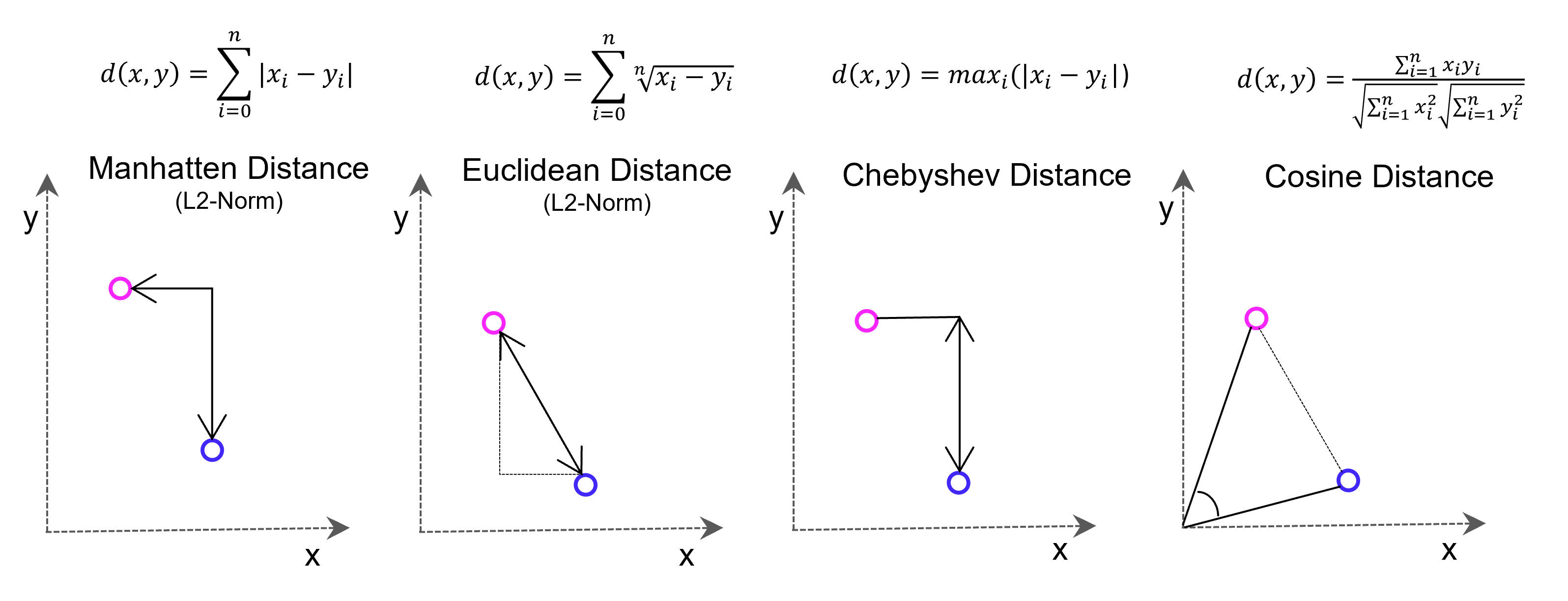
Vectore-based distance measuring methods: Euclidean Distance L2-Norm, Manhatten Distance L1-Norm, Chebyshev Distance and Cosine Distance
Vektor-Datenbanken für Deep Learning
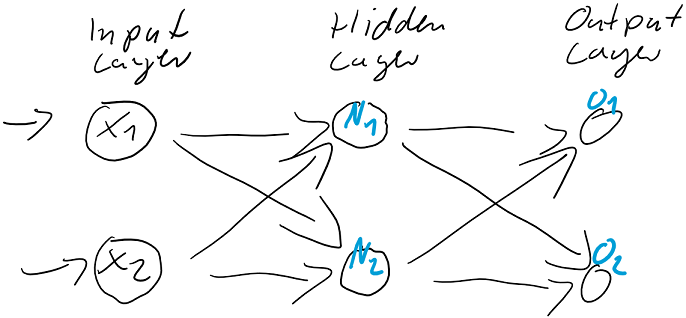
Der Aufbau von künstlichen Neuronalen Netzen im Deep Learning sieht nicht vor, dass ganze Sätze in ihren textlichen Bestandteilen in das jeweilige Netz eingelesen werden, denn sie funktionieren am besten mit rein nummerischen Input. Die Texte müssen in diese transformiert werden, eventuell auch nach diesen in Cluster eingeteilt und für verschiedene Trainingsszenarien separiert werden.
Vektordatenbanken werden für die Datenvorbereitung (Annotation) und als Trainingsdatenbank für Deep Learning zur effizienten Speicherung, Organisation und Manipulation der Texte genutzt. Für Natural Language Processing (NLP) benötigen Modelle des Deep Learnings die zuvor genannten Word Embedding, also hochdimensionale Vektoren, die Informationen über Worte, Sätze oder Dokumente repräsentieren. Nur eine Vektordatenbank macht diese effizient abrufbar.
Vektor-Datenbank und Large Language Modells (LLM)
Ohne Vektor-Datenbanken wären die Erfolge von OpenAI und anderen Anbietern von LLMs nicht möglich geworden. Aber fernab der Entwicklung in San Francisco kann jedes Unternehmen unter Einsatz von Vektor-Datenbanken und den APIs von Google, OpenAI / Microsoft oder mit echten Open Source LLMs (Self-Hosting) ein wahres Orakel über die eigenen Unternehmensdaten herstellen. Dazu werden über APIs die Embedding-Engines z. B. von OpenAI genutzt. Wir von DATANOMIQ nutzen diese Architektur, um Unternehmen und andere Organisationen dazu zu befähigen, dass kein Wissen mehr verloren geht.
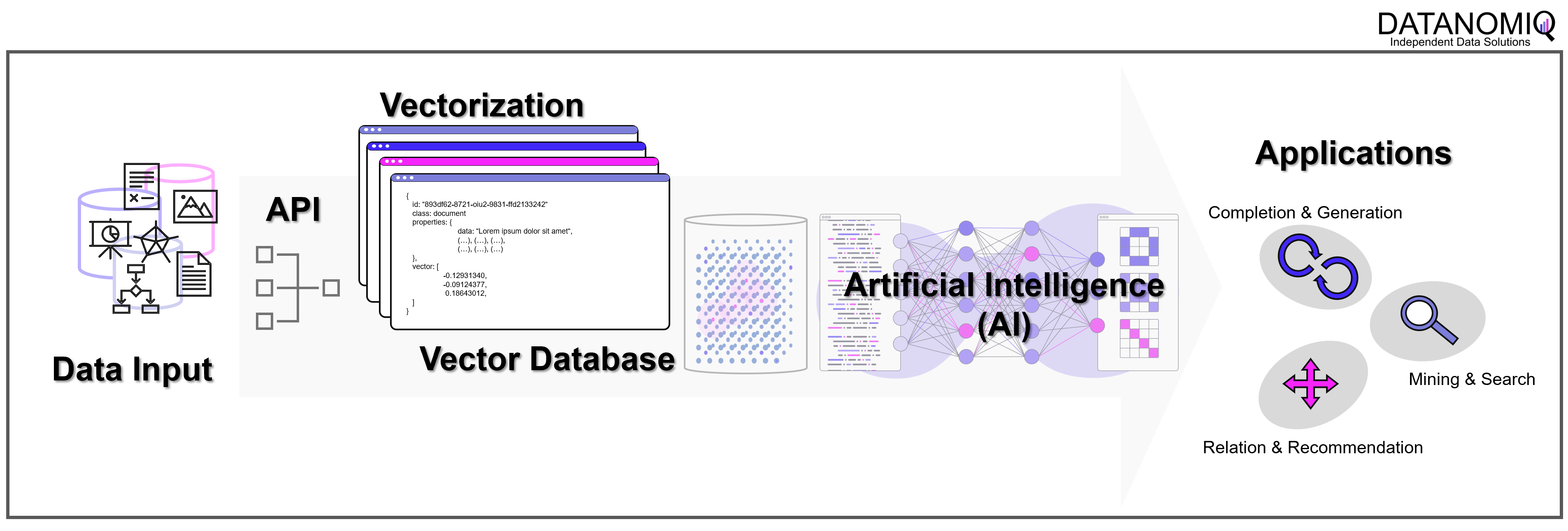
Mit der DATANOMIQ Enterprise AI Architektur, die auf jeder Cloud ausrollfähig ist, verfügen Unternehmen über einen intelligenten Unternehmens-Repräsentanten als KI, der für Mitarbeiter relevante Dokumente und Antworten auf Fragen liefert. Sollte irgendein Mitarbeiter im Unternehmen bereits einen bestimmten Vorgang, Vorfall oder z. B. eine technische Konstruktion oder einen rechtlichen Vertrag bearbeitet haben, der einem aktuellen Fall ähnlich ist, wird die AI dies aufspüren und sinnvollen Kontext, Querverweise oder Vorschläge oder lückenauffüllende Daten liefern.
Die AI lernt permanent mit, Unternehmenswissen geht nicht verloren. Das ist Wissensmanagement auf einem neuen Level, dank Vektor-Datenbanken und KI.


 berechnen…
berechnen…


 werden dann als Berechnungsgrundlage für die Ausgaben der Ausgabeschicht
werden dann als Berechnungsgrundlage für die Ausgaben der Ausgabeschicht  verwendet. Auch die Ausgabe-Neuronen berechnen ihre jeweilige Nettoeingabe
verwendet. Auch die Ausgabe-Neuronen berechnen ihre jeweilige Nettoeingabe 
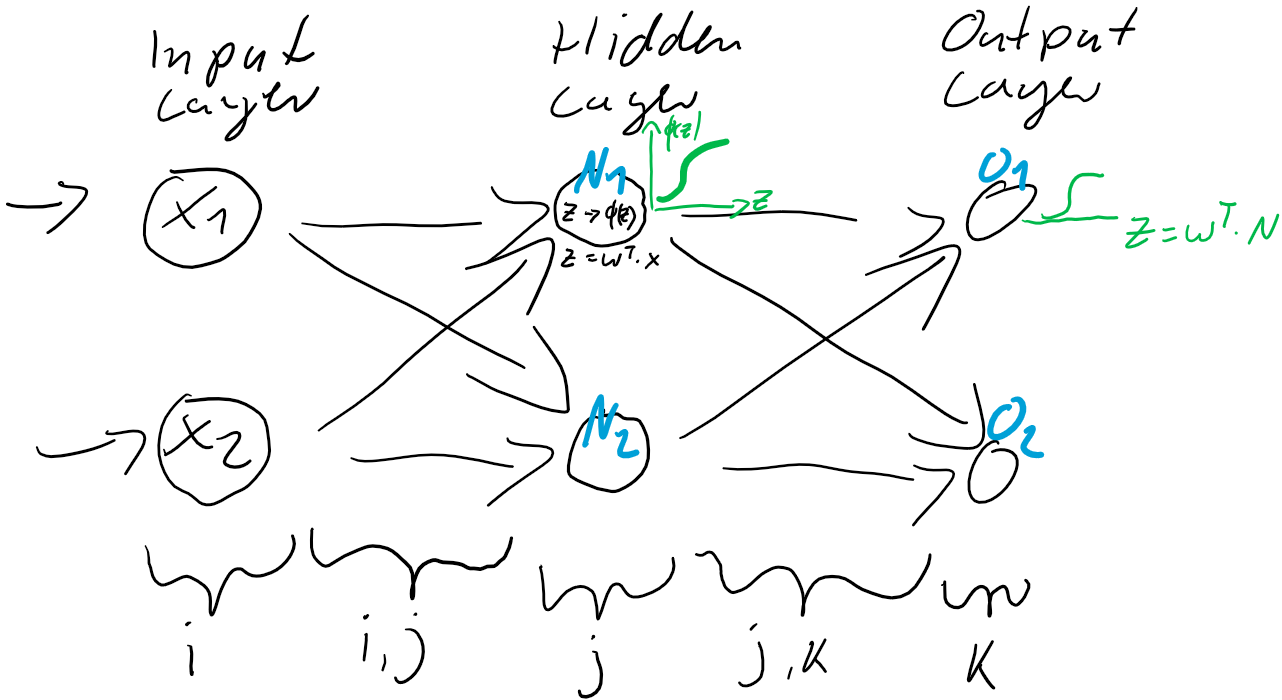
 ) und der Prädiktion (Ausgabe
) und der Prädiktion (Ausgabe 
 ist also einfach der Unterschied zwischen dem Ziel-Wert und der Prädiktion. Jedes Training ist eine Wiederholung von Prädiktion (Forward) und Gewichtsanpassung (Back). Im ersten Schritt werden üblicherweise die Gewichtungen zufällig gesetzt, jede Gewichtung unterschiedlich nach Zufallszahl. So ist die Wahrscheinlichkeit, gleich zu Beginn die “richtigen” Gewichtungen gefunden zu haben auch bei kleinen neuronalen Netzen verschwindend gering. Der Fehler wird also groß sein und kann über den Gradientenabstieg durch Gewichtsanpassung verkleinert werden.
ist also einfach der Unterschied zwischen dem Ziel-Wert und der Prädiktion. Jedes Training ist eine Wiederholung von Prädiktion (Forward) und Gewichtsanpassung (Back). Im ersten Schritt werden üblicherweise die Gewichtungen zufällig gesetzt, jede Gewichtung unterschiedlich nach Zufallszahl. So ist die Wahrscheinlichkeit, gleich zu Beginn die “richtigen” Gewichtungen gefunden zu haben auch bei kleinen neuronalen Netzen verschwindend gering. Der Fehler wird also groß sein und kann über den Gradientenabstieg durch Gewichtsanpassung verkleinert werden. und
und  und passen danach die Gewichte
und passen danach die Gewichte  (
( &
&  und
und  &
&  ) der Schicht zwischen dem Hidden-Layer
) der Schicht zwischen dem Hidden-Layer 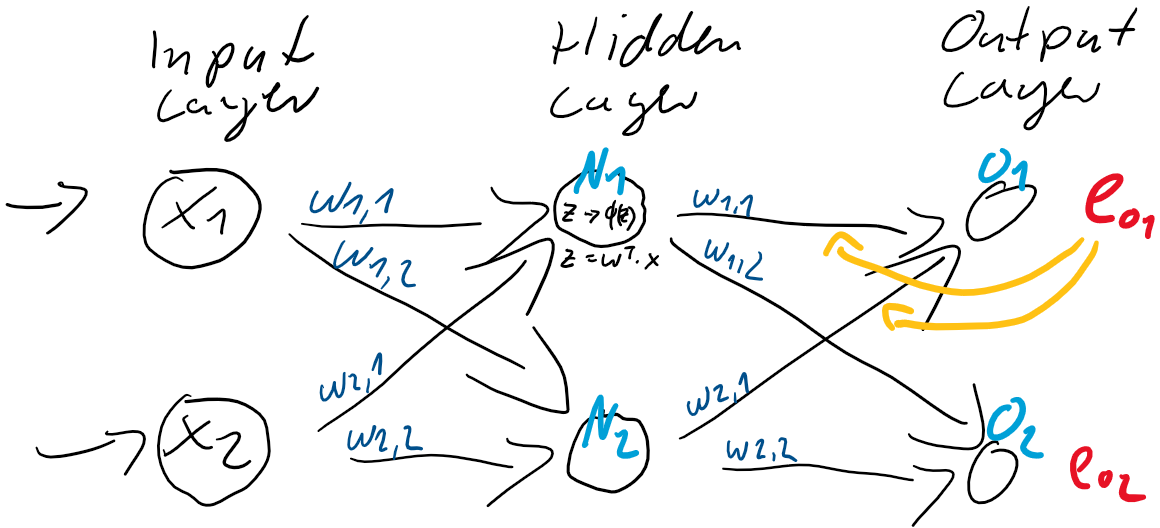
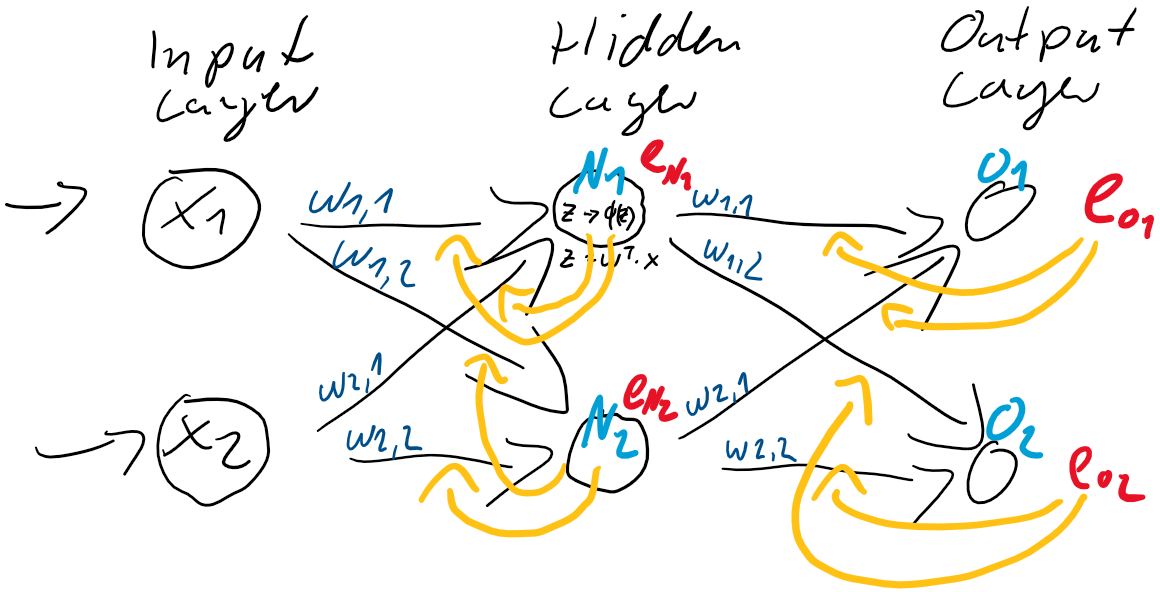
 und dem Hidden-Layer
und dem Hidden-Layer  und
und  . Dieser Anteil am Fehler der jeweiligen Neuronen ergibt sich direkt aus den Gewichtungen
. Dieser Anteil am Fehler der jeweiligen Neuronen ergibt sich direkt aus den Gewichtungen 

![\[ e_{N} = \left(\begin{array}{rr} \frac{w_{1,1}}{w_{1,1} + w_{1,2}} & \frac{w_{1,2}}{w_{1,1} + w_{1,2}} \\ \frac{w_{2,1}}{w_{2,1} + w_{2,2}} & \frac{w_{2,2}}{w_{2,1} + w_{2,2}} \end{array}\right) \cdot \left(\begin{array}{c} e_{1} \\ e_{2} \end{array}\right) \qquad \]](https://data-science-blog.com/de/wp-content/ql-cache/quicklatex.com-6fadfe69caec8e8c351788824875138a_l3.png "Rendered by QuickLaTeX.com")
![\[ e_{N} = \left(\begin{array}{rr} w_{1,1} & w_{1,2} \\ w_{2,1} & w_{2,2} \end{array}\right) \cdot \left(\begin{array}{c} e_{1} \\ e_{2} \end{array}\right) \qquad \]](https://data-science-blog.com/de/wp-content/ql-cache/quicklatex.com-7dee7d02ac1aba606a45895afe90a837_l3.png "Rendered by QuickLaTeX.com")

 zwischen der Eingabe-Schicht
zwischen der Eingabe-Schicht  und der verborgenden Schicht
und der verborgenden Schicht  .
.

 (Random Initialization). Wir berechnen die Ausgabe (Forwardpropogation) und vergleichen sie über eine Verlustfunktion (z. B. über die Funktion Mean Squared Error) mit dem tatsächlich korrekten Wert. Auf Grund der zufälligen Initialisierung haben wir eine nahe zu garantierte Falschheit der Ergebnisse und somit einen Verlust. Für die Verlustfunktion berechnen wir den Gradienten für gegebene Eingabewerte. Voraussetzung dafür ist, dass die Funktion ableitbar ist. Wir bewegen uns entgegen des Gradienten in Richtung Minimum der Verlustfunktion. Ist dieses Minimum (fast) gefunden, spricht man auch davon, dass der Lernalgorithmus konvergiert.
(Random Initialization). Wir berechnen die Ausgabe (Forwardpropogation) und vergleichen sie über eine Verlustfunktion (z. B. über die Funktion Mean Squared Error) mit dem tatsächlich korrekten Wert. Auf Grund der zufälligen Initialisierung haben wir eine nahe zu garantierte Falschheit der Ergebnisse und somit einen Verlust. Für die Verlustfunktion berechnen wir den Gradienten für gegebene Eingabewerte. Voraussetzung dafür ist, dass die Funktion ableitbar ist. Wir bewegen uns entgegen des Gradienten in Richtung Minimum der Verlustfunktion. Ist dieses Minimum (fast) gefunden, spricht man auch davon, dass der Lernalgorithmus konvergiert.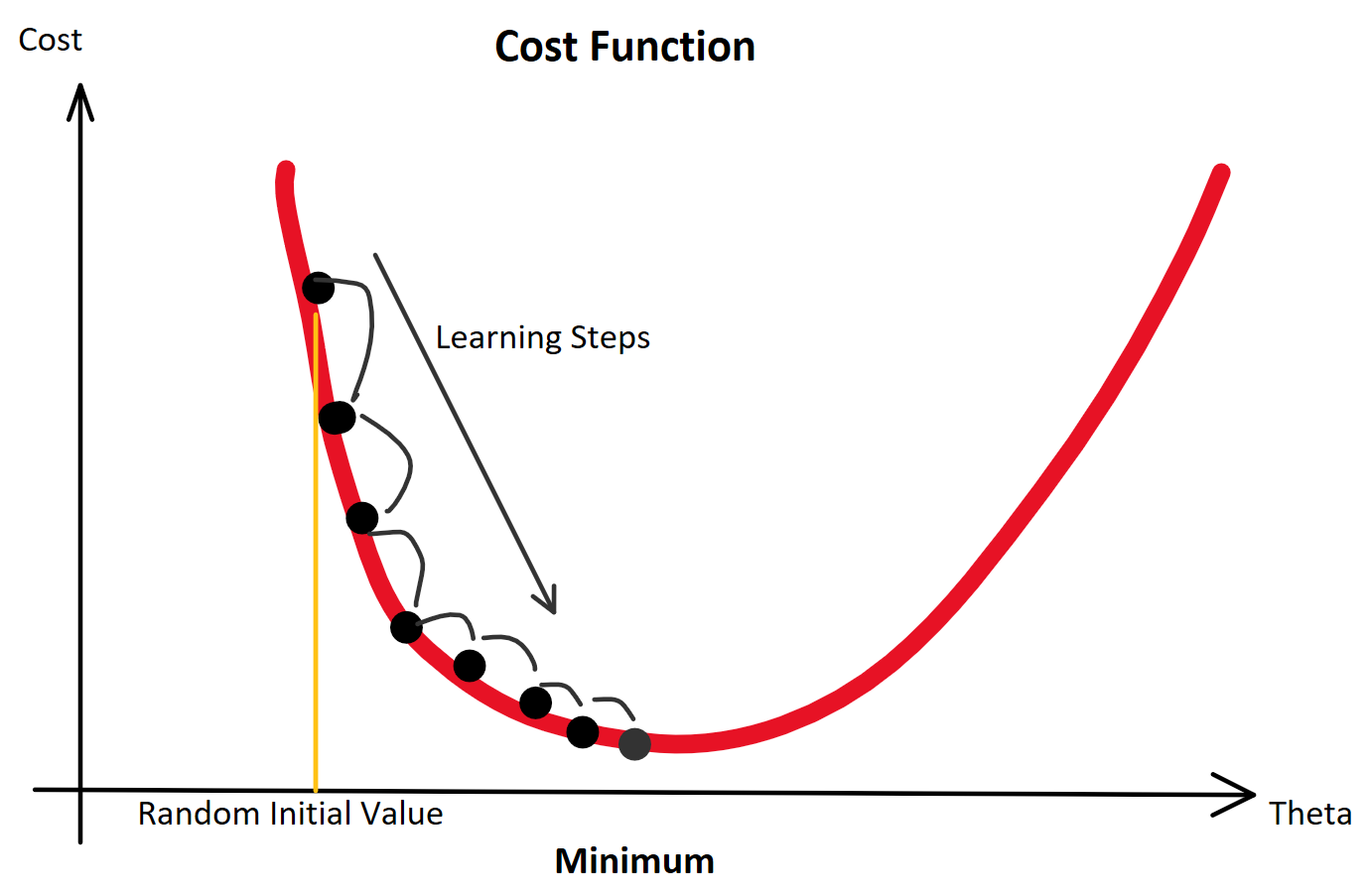
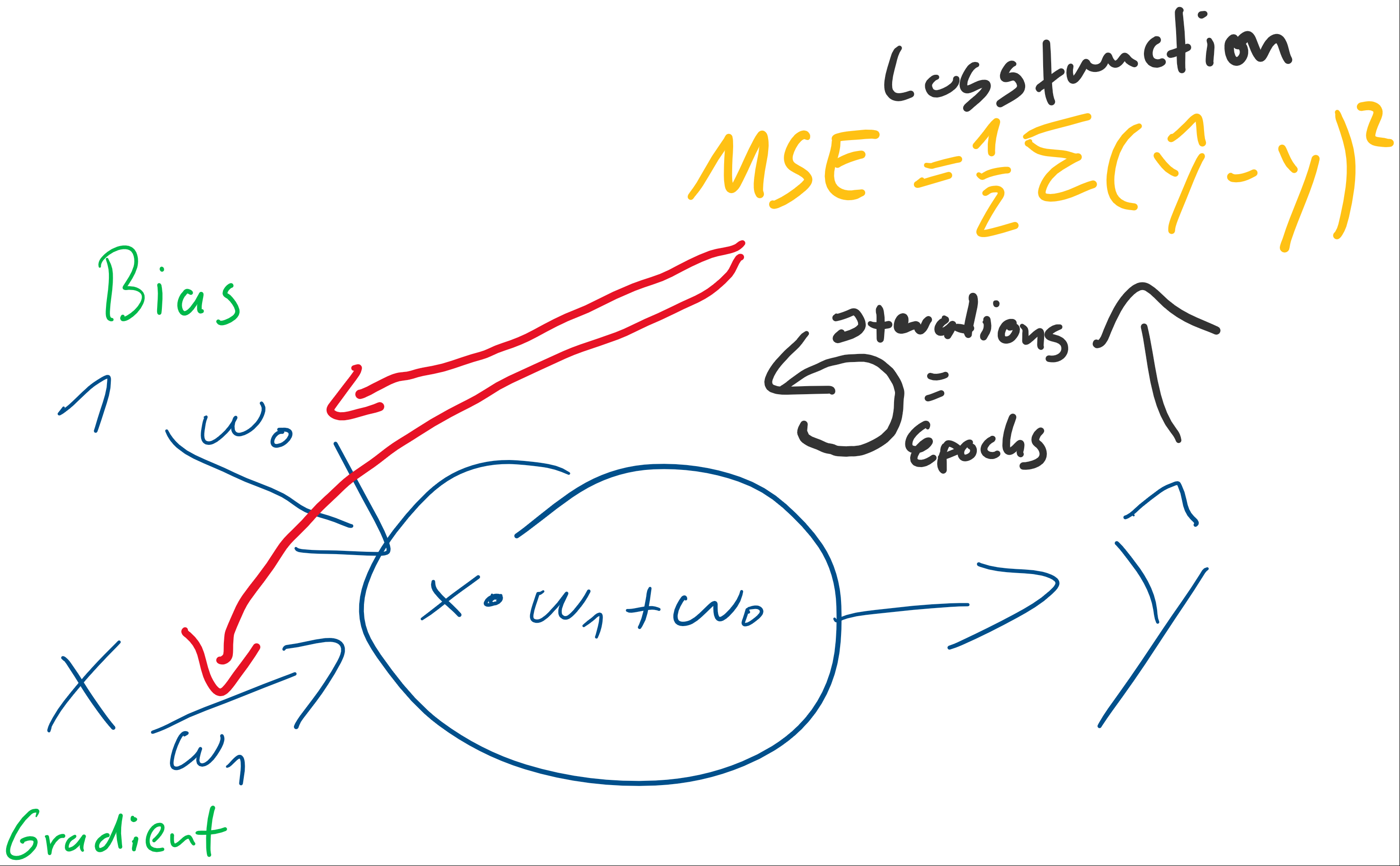
 ) der stets mit einer Eingangskonstante multipliziert und somit als Wert erhalten bleibt. Der Bias ist das Alpha
) der stets mit einer Eingangskonstante multipliziert und somit als Wert erhalten bleibt. Der Bias ist das Alpha  in einer Schulmathe-tauglichen Formel wie
in einer Schulmathe-tauglichen Formel wie  .
. ist die Steigung, der Gradient, der Funktion.
ist die Steigung, der Gradient, der Funktion. und den darauffolgenden Abgleich mit dem tatsächlichen
und den darauffolgenden Abgleich mit dem tatsächlichen  herauszufinden. Anfangs behaupten wir beispielsweise einfach, sowohl
herauszufinden. Anfangs behaupten wir beispielsweise einfach, sowohl  . Folglich wird
. Folglich wird 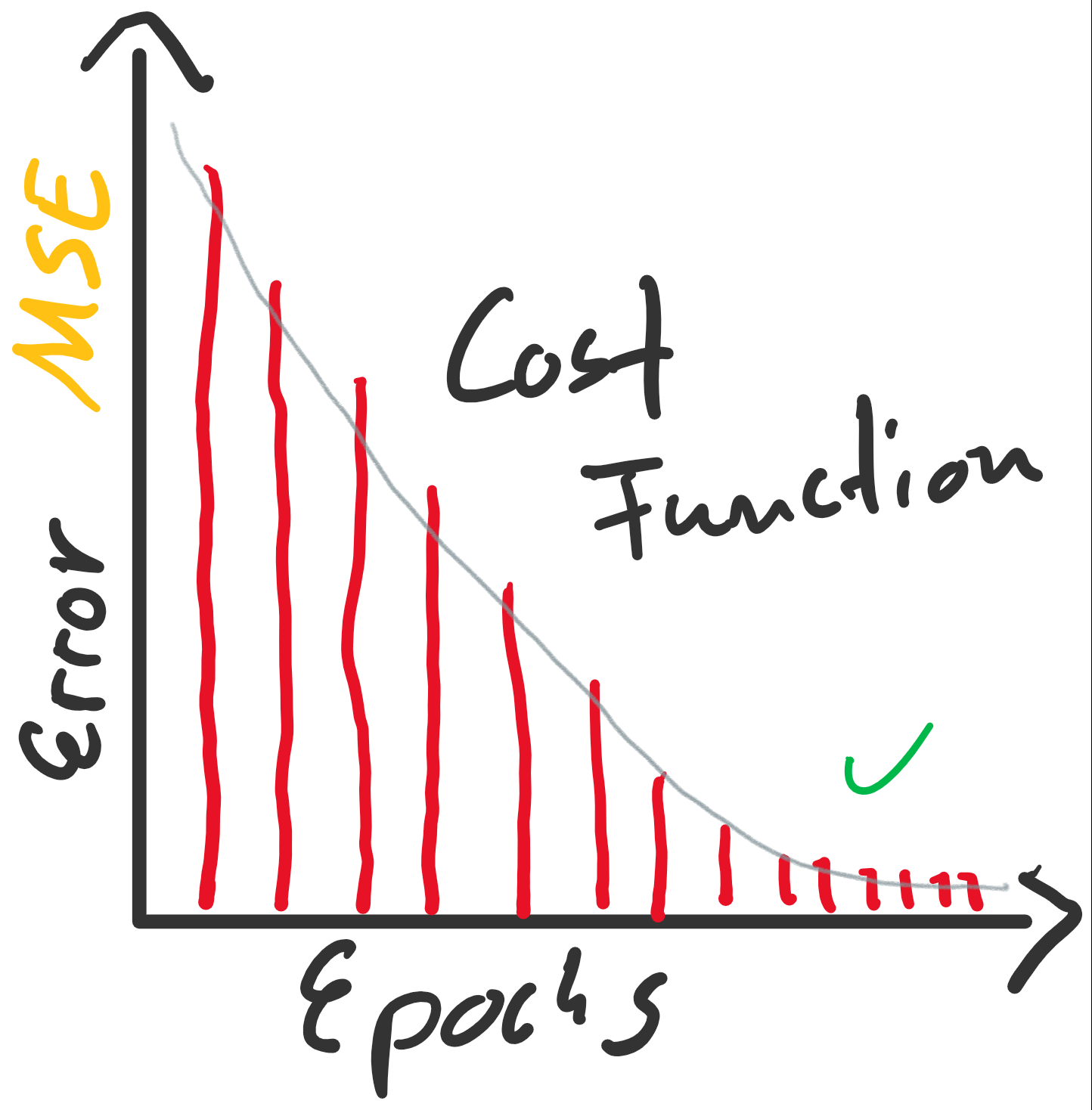



 bzw. partiell nach jedem vorhandenen
bzw. partiell nach jedem vorhandenen  :
:


 am Ende her haben? Das ergibt sie aus der Kettenregel: Die äußere Funktion wurde abgeleitet, so wurde aus
am Ende her haben? Das ergibt sie aus der Kettenregel: Die äußere Funktion wurde abgeleitet, so wurde aus  dann
dann  . Jedoch muss im Sinne eben dieser Kettenregel auch die innere Funktion abgeleitet werden. Da wir nach
. Jedoch muss im Sinne eben dieser Kettenregel auch die innere Funktion abgeleitet werden. Da wir nach  erhalten.
erhalten.
 ist der Gradient der Funktion!)
ist der Gradient der Funktion!)
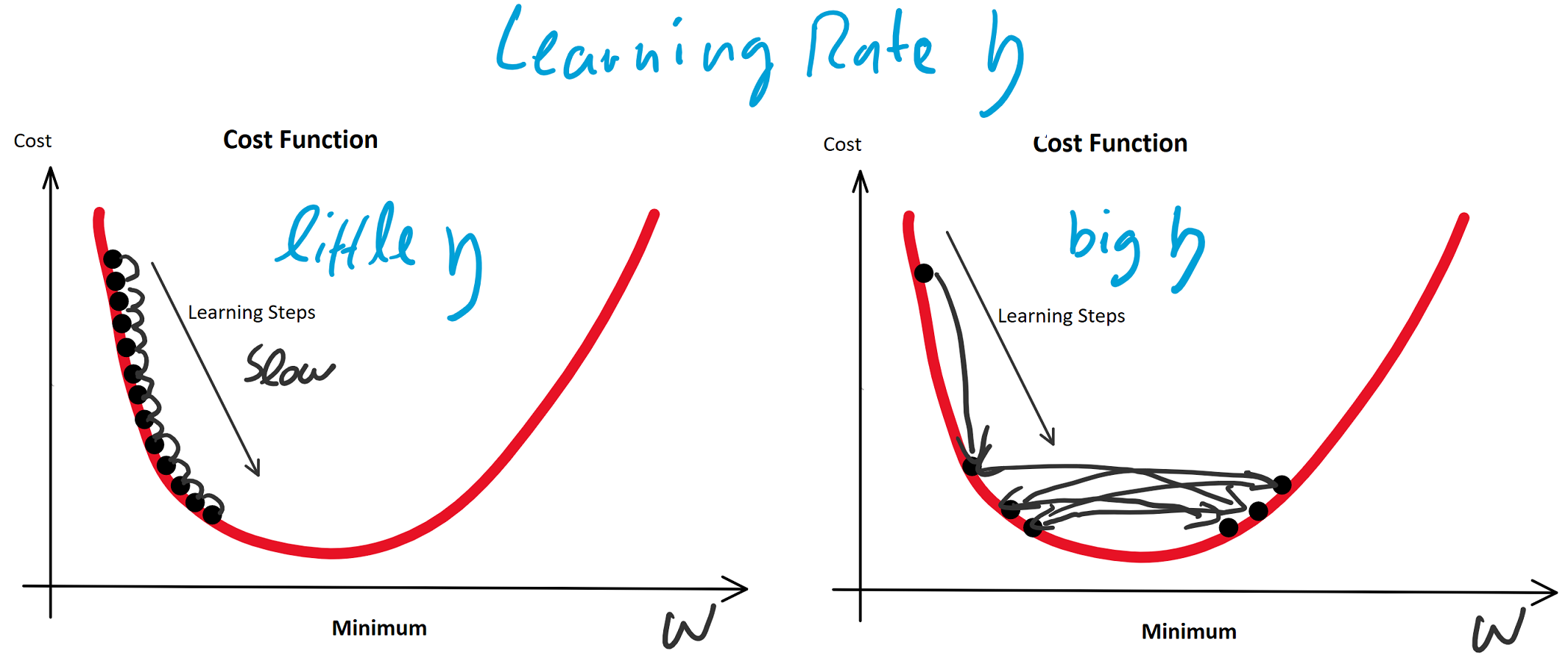
 (eta) bezeichnet:
(eta) bezeichnet:
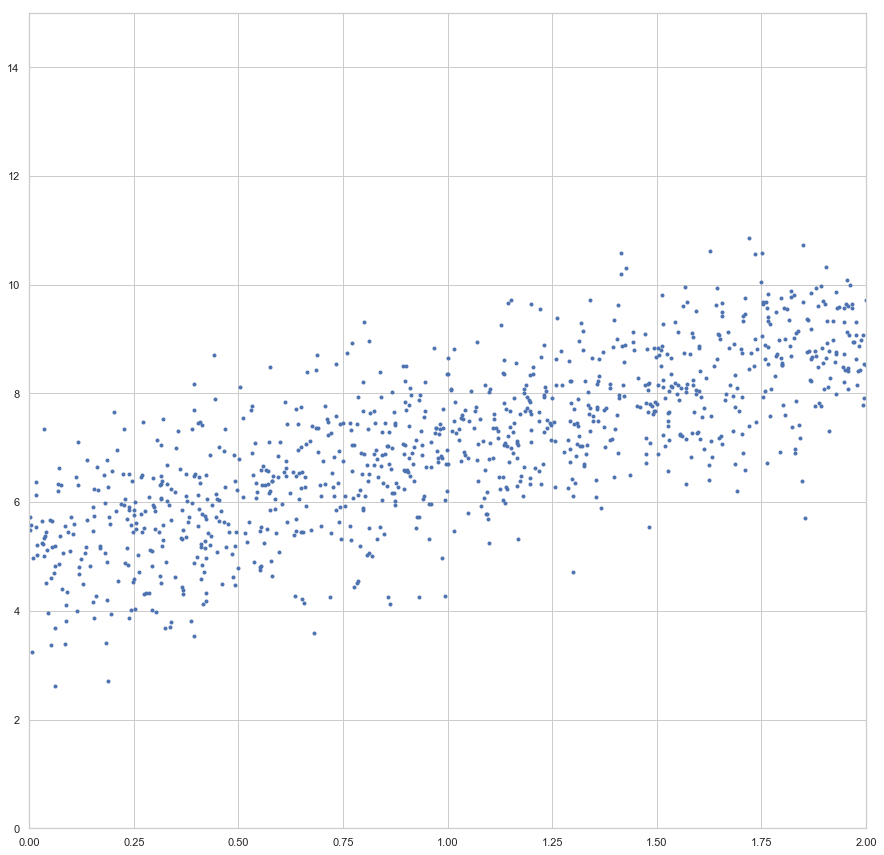
 enthalten sind. Der Fehler ist dann aber sehr groß (sollte maximal sein, im Vergleich zu zukünftigen Epochen). Die Gewichte werden also angepasst, die Gerade somit besser in die Punktwolke platziert. Mit jeder Epoche wird die Gerade erneut in die Punktwolke gelegt, der Gesamtfehler (über alle
enthalten sind. Der Fehler ist dann aber sehr groß (sollte maximal sein, im Vergleich zu zukünftigen Epochen). Die Gewichte werden also angepasst, die Gerade somit besser in die Punktwolke platziert. Mit jeder Epoche wird die Gerade erneut in die Punktwolke gelegt, der Gesamtfehler (über alle 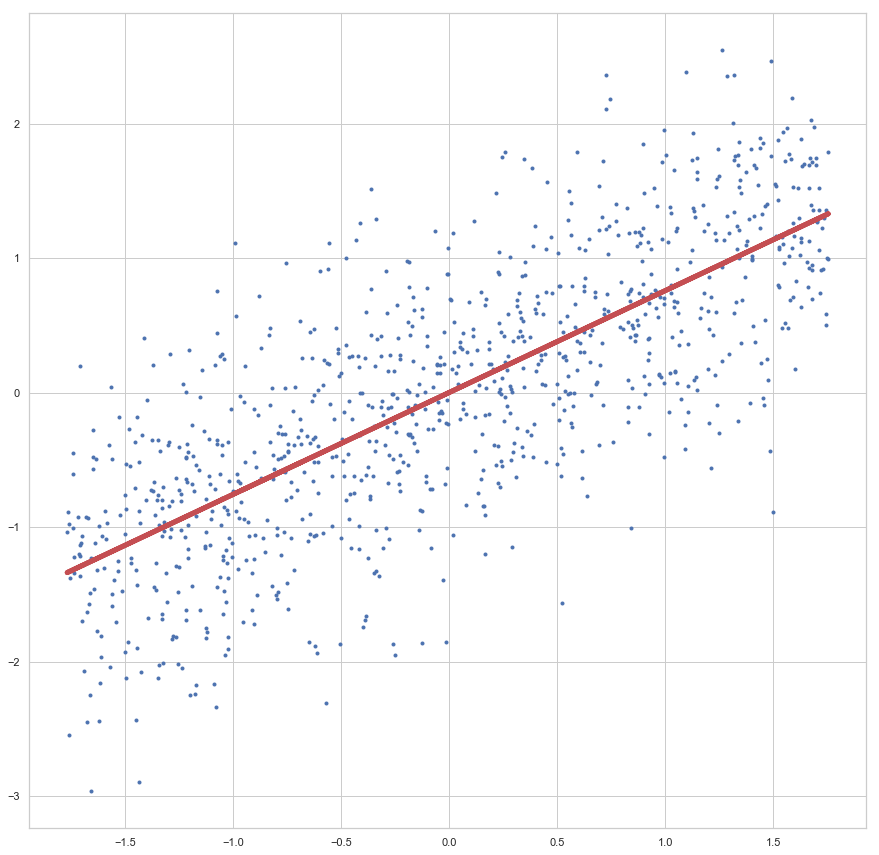
 konvergiert:
konvergiert: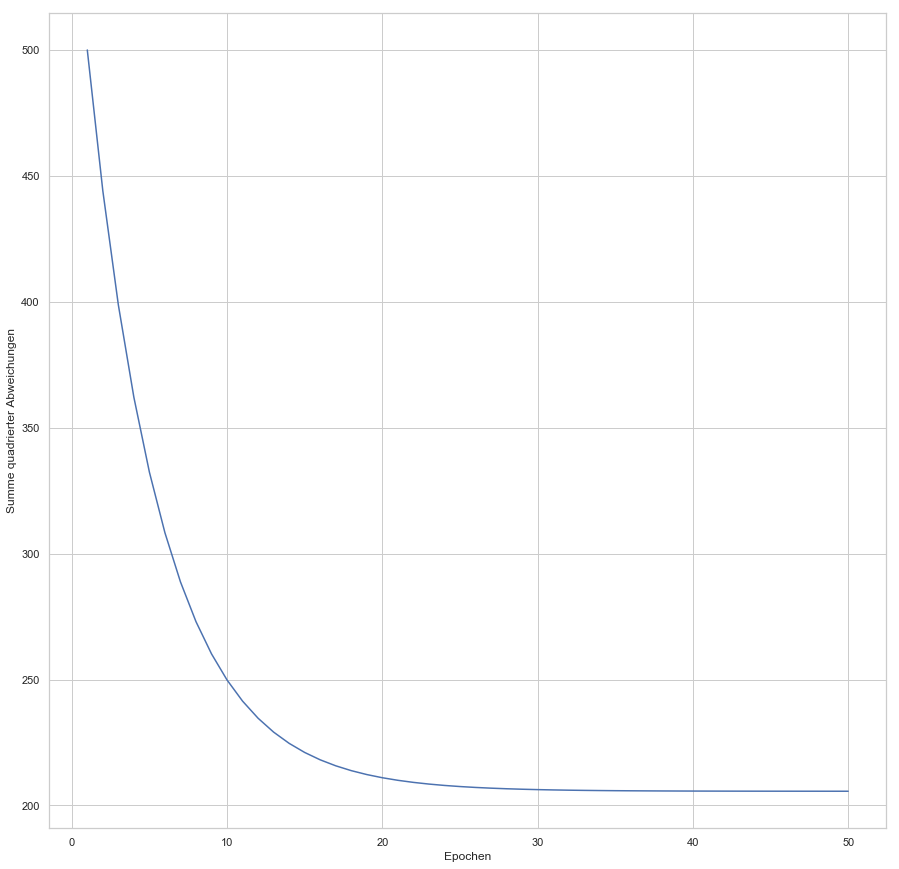




 Prof. Dr. Klaus Jung studierte Physik an der TU Berlin, wo er im Bereich der Mathematischen Physik promovierte. Bis 2008 arbeitete er als Leiter F&E bei der Firma LuraTech im Bereich der Dokumentenverarbeitung und Langzeitarchivierung. In der JPEG-Gruppe leitete er die deutsche Delegation bei der Standardisierung von JPEG2000. Seit 2008 ist er Professor für Medieninformatik an der HTW Berlin mit dem Schwerpunkt „Visual Computing“.
Prof. Dr. Klaus Jung studierte Physik an der TU Berlin, wo er im Bereich der Mathematischen Physik promovierte. Bis 2008 arbeitete er als Leiter F&E bei der Firma LuraTech im Bereich der Dokumentenverarbeitung und Langzeitarchivierung. In der JPEG-Gruppe leitete er die deutsche Delegation bei der Standardisierung von JPEG2000. Seit 2008 ist er Professor für Medieninformatik an der HTW Berlin mit dem Schwerpunkt „Visual Computing“.

 Prof. Sven Buchholz hat eine Professur für die Fachgebiete Data Management und Data Mining am Fachbereich Informatik und Medien an der TH Brandenburg inne. Er ist wissenschaftlicher Leiter des an der Agentur für wissenschaftliche Weiterbildung und Wissenstransfer – AWW e. V. angesiedelten Projektes „Datenkompetenz 4.0 für eine digitale Arbeitswelt“ und Dozent des Vertiefungskurses „
Prof. Sven Buchholz hat eine Professur für die Fachgebiete Data Management und Data Mining am Fachbereich Informatik und Medien an der TH Brandenburg inne. Er ist wissenschaftlicher Leiter des an der Agentur für wissenschaftliche Weiterbildung und Wissenstransfer – AWW e. V. angesiedelten Projektes „Datenkompetenz 4.0 für eine digitale Arbeitswelt“ und Dozent des Vertiefungskurses „

 . Dieser wird als Bias, selten auch als Default-Wert, bezeichnet. Der Bias ist also der Wert, wenn die
. Dieser wird als Bias, selten auch als Default-Wert, bezeichnet. Der Bias ist also der Wert, wenn die  ein Fehler
ein Fehler  existiert. Diesen Fehler wollen wir in diesem Artikel ignorieren.
existiert. Diesen Fehler wollen wir in diesem Artikel ignorieren. statt
statt  ) sind nichts anderes als Gewichtungen zwischen den Eingaben.
) sind nichts anderes als Gewichtungen zwischen den Eingaben.![\[y = w_{0} \cdot x_{0} + w_{1} \cdot x_{1} + \ldots + w_{n} \cdot x_{n}\]](https://data-science-blog.com/de/wp-content/ql-cache/quicklatex.com-19728ae5f9e3065a4c17d50c417e0a8b_l3.png "Rendered by QuickLaTeX.com")
 . Verkürzt ausgedrückt:
. Verkürzt ausgedrückt:![\[y = \sum_{i=0}^n w_{i} \cdot x_{i}\]](https://data-science-blog.com/de/wp-content/ql-cache/quicklatex.com-3bbcbb30d482e7a1fd8da528030d6561_l3.png "Rendered by QuickLaTeX.com")
![\[y = w^T \cdot x\]](https://data-science-blog.com/de/wp-content/ql-cache/quicklatex.com-939f4bae6617db519d13b502d6337ee1_l3.png "Rendered by QuickLaTeX.com")
 .
.
 . Auf der linken Seite finden wir alle Eingabewerte, wobei der erste Wert statisch mit 1.0 belegt ist, nur für den Zweck, den Bias (
. Auf der linken Seite finden wir alle Eingabewerte, wobei der erste Wert statisch mit 1.0 belegt ist, nur für den Zweck, den Bias (
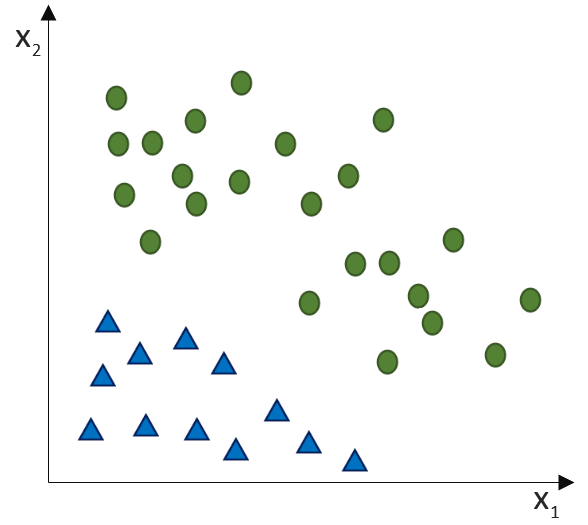
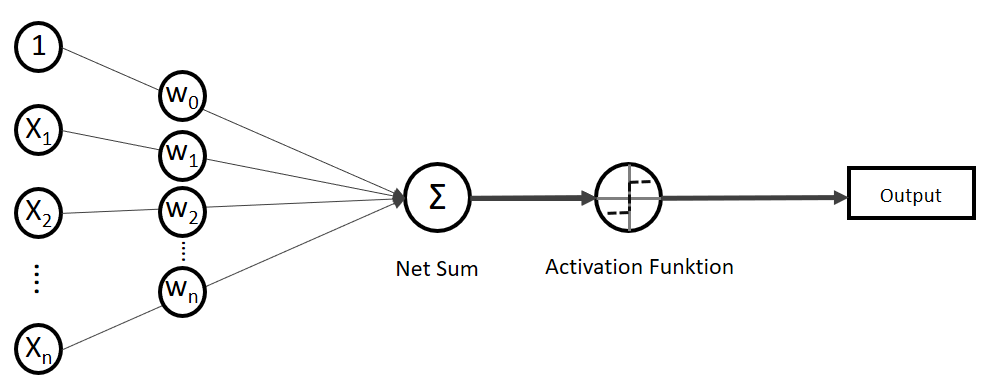
 (Phi), die uns die stetigen Werte der Nettoeingabe in einen binären Wert (z. B. 0 oder 1) umwandelt.
(Phi), die uns die stetigen Werte der Nettoeingabe in einen binären Wert (z. B. 0 oder 1) umwandelt. 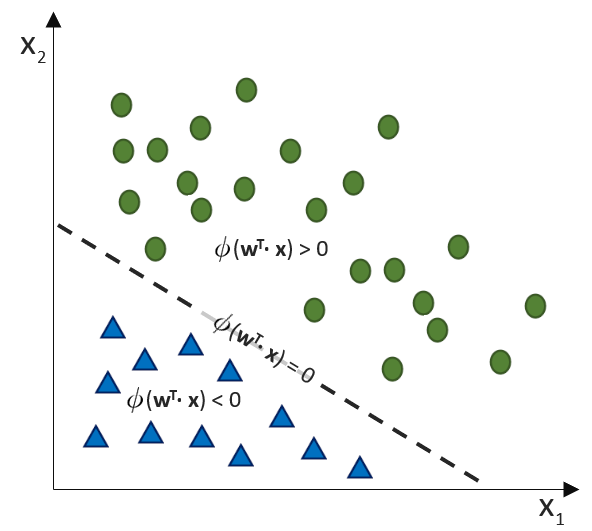
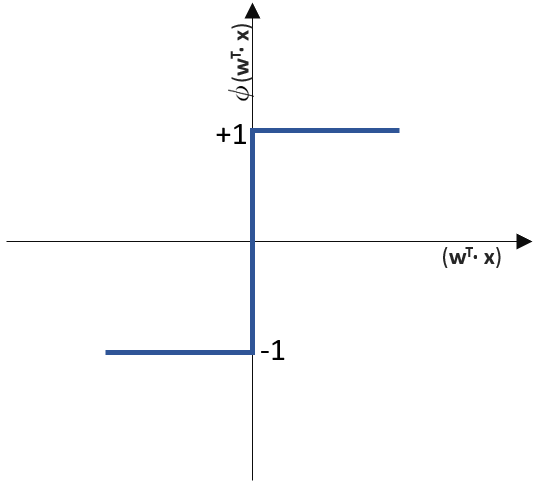
![\[ y = \phi(w^T \cdot x) = \left\{ \begin{array}{12} 1 & w^T \cdot x > 0\\ -1 & \text{otherwise} \end{array} \]](https://data-science-blog.com/de/wp-content/ql-cache/quicklatex.com-7b828cf4bbabf9e1a84ec9b628d51249_l3.png "Rendered by QuickLaTeX.com")