6 Faktoren, wie Process Mining Projekte zum Erfolg werden
Zuerst wollte ich diesen Artikel mit “6 Gründe, warum Process Mining Projekt scheitern” betiteln, das würde dann aber doch etwas zu negativ klingen. Kein Process Mining Projekt muss scheitern oder überhaupt in Verzögerungen geraten, denn das lässt sich mit etwas Erfahrung und der richtigen Einstellung zum Projekt immer verhindern.
 Nach dutzenden Process Mining Projekten mit unterschiedlichen Rahmenbedingungen gebe ich hier nun sechs handfeste Hinweise, wie Process Mining Projekte generell zum Erfolg werden:
Nach dutzenden Process Mining Projekten mit unterschiedlichen Rahmenbedingungen gebe ich hier nun sechs handfeste Hinweise, wie Process Mining Projekte generell zum Erfolg werden:
1. Richtige Erwartungshaltung setzen und kommunizieren
Dieser Punkt mag banal klingen, das ist jedoch nicht der Fall. Ich habe schon einige Process Mining Projekte gesehen, die deswegen gescheitert sind, weil dem Vorstand oder anderen Entscheidern gegenüber falsche Versprechungen abgegeben wurden. Tatsächlich werden Process Mining Projekte oft mit ambitionierten Zielen gestartet, wie dem Herabsenken von Prozesskosten um konkrete 10% oder dem Reduzieren der Durchlaufzeit eines bestimmten Prozesses um 20%. Es sei den Entscheidern nicht zu verübeln, dass Budgets gestrichen und Projekte eingestampft werden, wenn diese konkreten Versprechen nicht realisiert werden können.
Dabei können exakt diese Ziele oftmals doch erreicht werden, nur nicht gleich bei den ersten Projektiterationen, denn oft fehlen Datenpunkte, die wichtige Prozessaktivitäten in operativen Prozessketten dokumentieren. Das Event Log kann anfangs – gerade für exotischere Prozesse in weniger verbreiteten IT-Systemen – oft noch nicht sofort vollständig erstellt werden.
Aber eben genau diese Lücken in der Prozessdatenerfassung sind ein “Finding”, denn sie zeigen erst auf, an welchen Stellen es blinde Flecken in der Daten- und Prozesstransparenz noch gibt. Somit ist im Process Mining auch der Weg der datenbasierten Prozesstransparenz ein oder sogar DAS große Ziel.
Konkretes Beispiel: Eine Krankenversicherung wollte die Prozesse der Reha-Bewilligung für ihre Versicherte analysieren. Unter Einsatz eines umfangreichen Process Mining Tools sollten die Prozesse tiefgehend analysiert und unnötige Prozessschleifen identifizieren, aber auch den Prozess abkürzen, indem Ausschlusspunkte frühzeitig im Prozess entdeckt werden. Das war das Versprechen an den Vorstand, der das Budget einfror, auf Grund nicht erreichter Ziele.
In der Tat gab es bei der Rekonstruktion der Prozesse aus den Legacy-Systemen, die über Jahrzehnte von der IT der Krankenkasse selbst entwickelt wurden, viele Lücken in den Daten und somit blinde Flecken in der Prozessen. Die Aufdeckung aber genau dieser Lücken führt dazu, dass diese geschlossen werden können und die vollständige Transparenz über Daten damit erst hergestellt wird. Erst dann, im zweiten Schritt, können die Prozesse ausführlich genug auf Optimierungspotenziale untersucht werden.
Process Mining nicht zu betreiben, weil die Prozesse nicht lückenlos getrackt werden, ist im Grunde unterlassene Hilfeleistung gegenüber des Unternehmens.
2. Process Mining als Methode, nicht als Tool verstehen
Viele Process Mining Projekte drehen sich vor allem um die Auswahl und die Einführung der richtigen Process Mining Tools. Auf das richtige Tool zu setzen, ist natürlich ein wichtiger Aspekt im Process Mining Projekt. Abhängig davon, ob es sich beim Vorhaben der Prozessanalyse um eine einmalige Angelegenheit oder ein tägliches Monitoring von Prozessen handelt, kommen unterschiedliche Tools in die Vorauswahl. Auch ob beispielsweise bereits ein BI-System etabliert ist und ob ein ausgeklügeltes Berechtigungskonzept für die Prozessanalysen notwendig ist, spielen für die Auswahl eine Rolle, sowie viele weitere Faktoren.
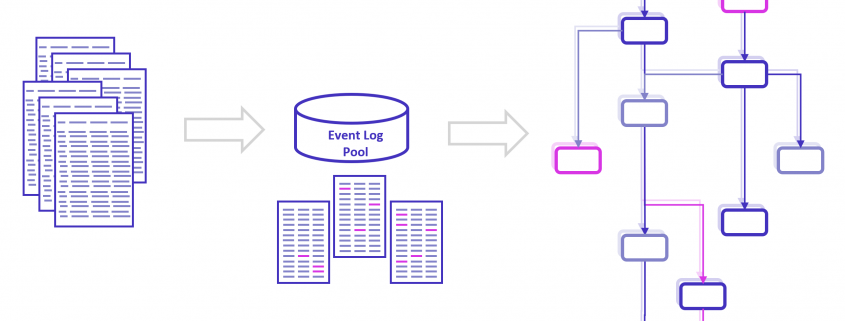
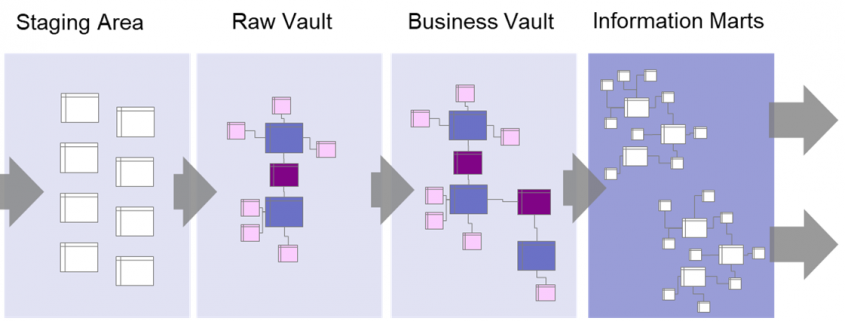
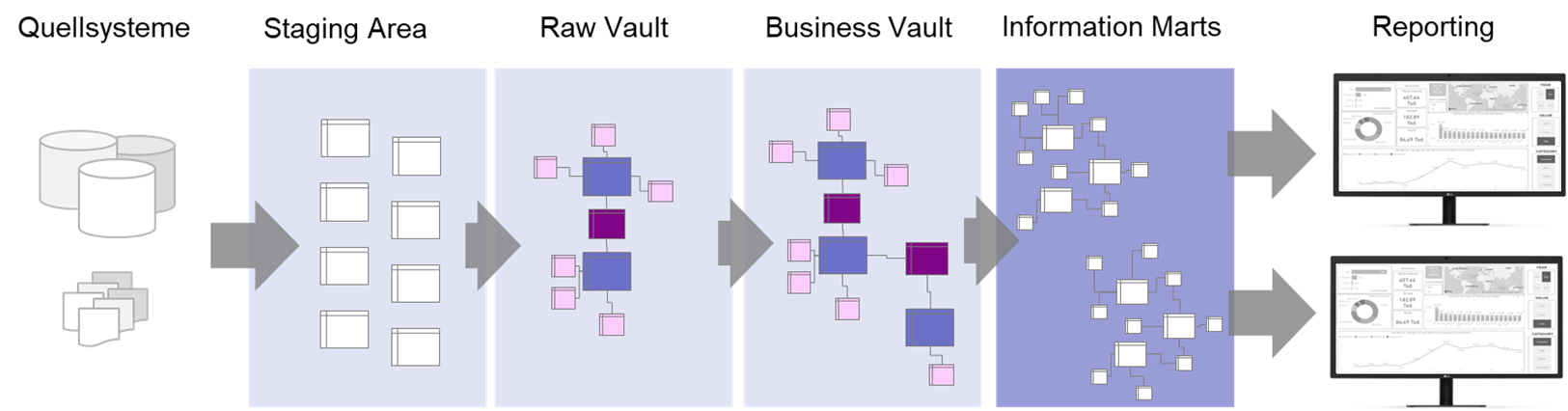
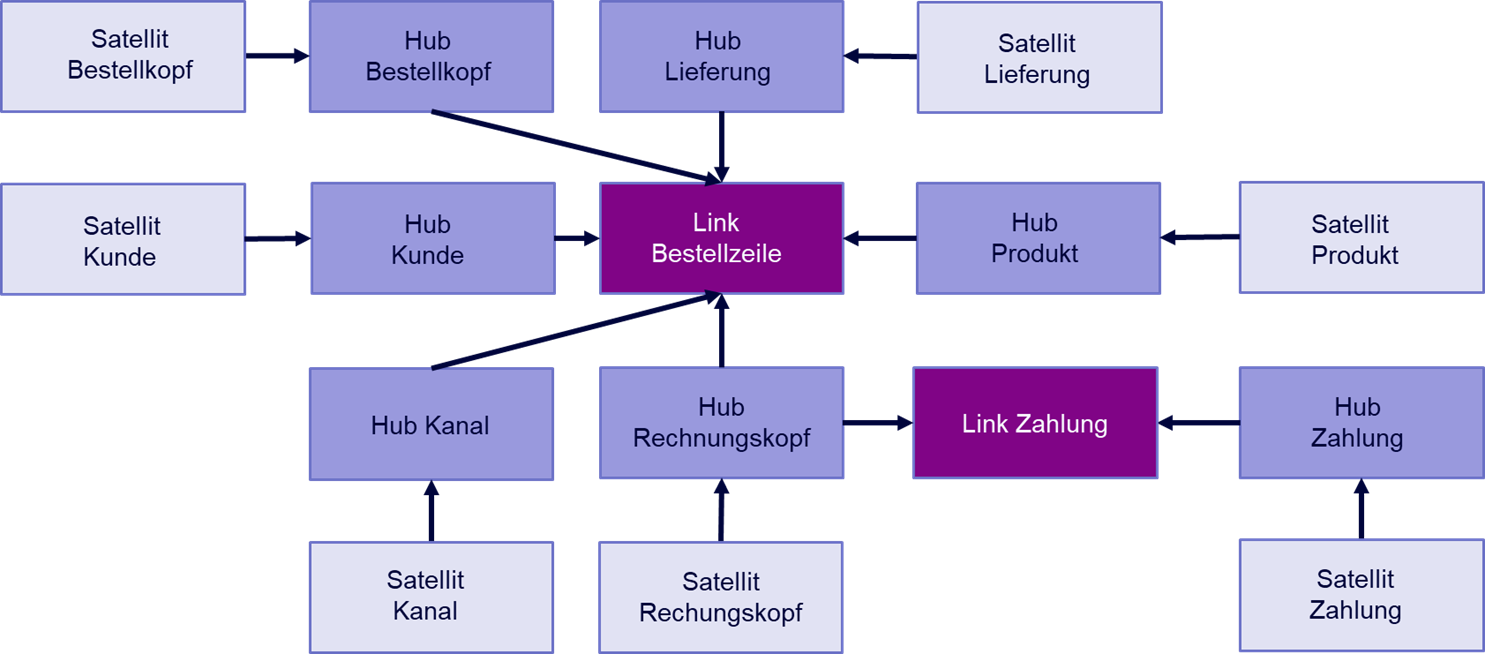
Dennoch sollte nicht vergessen werden, dass Process Mining in erster Linie kein Tool, sondern eine Analysemethodik ist, bei der es im ersten Abschnitt um die Rekonstruktion der Prozesse aus operativen IT-Systemen in ein resultierendes Prozessprotokoell (Event Log) geht, im zweiten Schritt um eine (im Kern) Graphenanalyse zur Visualisierung der Prozessflüsse mit weiteren Analyse-/Reporting-Elementen. Wird diese Perspektive auf Process Mining nicht aus den Augen verloren, können Unternehmen viele Kosten sparen, denn es erlaubt die Konzentration auf lösungsorientierte Konzepte.
Konkretes Beispiel: Ein Unternehmen plante die Einführung von Process Mining über einen marktführenden Tool-Anbieter. Nahezu alle Ressourcen wurden für die Tool-Einführung allokiert, das eigentliche Vorhaben schien rein in der Tool-Einführung aufgehen zu müssen, bis Projektanforderungen sogar zu Gunsten des auserwählten Tools angepasst wurden, um es realisieren zu können.
Zudem kann das Unternehmen noch vor der umfangreichen Tool-Einführung, erste Schritte oder Zumindest erste Machbarkeitstests mit einem günstigeren Tool durchführen, oder sogar gänzlich kostenlos z. B. mit PM4Py (Python Package für Process Mining).
Oftmals sind die Tools der Marktführer auf Grund der Preismodelle schädlich für die Durchdringung von Process Mining im Unternehmen, denn nicht alle Abteilungen verfügen über die notwendigen Budgets und gerade experimentelle Projekte finden keinen Sponsor. Umso wichtiger ist es, diese Analysetechnik als Methodik zu verstehen, die auch mit einem Tool-Mix funktionieren kann. Ich kenne mehrere Unternehmen, die aus verschiedenen Gründen nicht ein, nicht zwei, sondern gleich mehrere Tools im Unternehmen im Einsatz haben.
3. Auf Unabhängigkeit und Wiederverwendbarkeit setzen
Wie zuvor bereits erwähnt, kann für ein Unternehmen ein Mix aus mehreren Tools infrage kommen und eigentlich sollte dieser Punkt sich um die richtige Tool-Auswahl drehen. Der Markt für Process Mining Software Tools in einem turbulenten Umfeld, die Tools, Funktionsumfänge und Konditionen ändern sich häufig und sind noch nicht vollends ausgereift. Viele der höherpreisigen Process Mining Tools wollen die Erstellung des Event Logs übernehmen und setzen dabei meistens auf vorgefertigte SQL-Skripte, die in der Plattform (also dem Tool) laufen und dort an kundenindividuelle Prozesse (z. B. durch ERP-Customizing) angepasst werden können.
Wie bereits erwähnt, besteht das Verfahren für Process Mining aus zwei Abschnitten, der erste ist die Erstellung des Event Logs, der zweite die eigentliche Analyse im Process Mining Tool, in welches das Event Log geladen wird. Soll das Tool auch den ersten Abschnitt übernehmen, steckt viel unternehmensindividuelles Prozess-Know-How im Tool, welches nicht für andere Tools verwendet werden kann. Es entsteht eine Abhängigkeit vom Tool, eine Migration zu einem anderen Tool wird schwieriger.
Konkretes Beispiel: Ein Unternehmen starten einen Proof of Concept für die Einführung eines Process Mining Tools, dabei wird ein Budget i.H.v. hundertausenden bereit gestellt, um drei Tools von unterschiedlichen Software-Herstellern gegeneinander antreten zu lassen. Die Tools sollen jeweils eine Gesamtlösung darstellen und Process Mining komplett liefern können, inklusive Event Logs.
Das Unternehmen könnte sich den Proof of Concept zum überwiegenden Teil sparen, wenn der erste Abschnitt des Process Minings – die Erstellung der Event Logs – vom Unternehmen selbst durchgeführt werden würde. Die Tools der Anbieter würden dann nur noch der eigentlichen Analyse der Event Logs dienen, die Anforderungen verringern sich und die Tools werden austauschbarer.
Unternehmen können Event Logs selbst herstellen und in ein Data Warehouse speisen, die dann alle Process Mining Tools mit Prozessdaten versorgen können. Die investierten Aufwände in Process Mining würden somit nachhaltiger (weil länger nutzbar) werden und die Abhängigkeit von bestimmter Software würde sich auf ein Minimum reduzieren, wir riskieren keinen neuen Aufwand für Migration von einem Anbieter zum nächsten. Übrigens können die Event Logs dann auch in andere Tools z. B. für Business Intelligence (BI) geladen und anderweitig analysiert werden.
4. Den richtigen Fokus setzen
Für Process Mining sollte nicht nur im Generellen eine realistische Erwartungshaltung kommuniziert werden, sondern auch im Speziellen, durch Selektion der besten Prozesse für den Start der Process Mining Vorhaben. Auf den ersten Blick sind das sicherlich die Prozesse, die aus Führungssicht als besonders kritisch betrachtet werden, für manche Unternehmen mögen das besondere Prozesse der Logistik sein, der Wareneinkauf bzw. die Materialbereitstellung, bei anderen Unternehmen vielleicht bestimmte Verwaltungs- oder Genehmigungsprozesse. Es sind meistens Prozesse, die entweder eine besondere Kostenbedeutung für das Unternehmen haben oder für die Kundenbindung wichtig sind. Da ist es verständlich, dass erste Projekte sich exakt diesen Prozessen widmen.
Konkretes Beispiel: Ein Unternehmen der Werkzeugmaschinen-Branche plant einen erstmaligen Einsatz von Process Mining. Der für das Unternehmen besonders kritische Prozess ist die Fertigung und Montage von Maschinen, denn hier liegen die größten Potenziale verborgen. Das Vorhaben gerät jedoch schnell ins Stocken, denn die Erhebung der Daten nicht nur aus ERP- und MES-Systemen, sondern auch von Machinen und Arbeitsplätzen erweist sich als zeitaufwändig.
Das Unternehmen startet eine zweite Kampagne zur Untersuchung eines Einkaufsprozesses, das zwar geringere Potenziale bietet, jedoch schneller und reibungsloser durchführbar ist. Das Projekt wird zum Erfolg und motiviert die Geschäftsführung, mehr Aufwände für Process Mining auch für schwieriger zu untersuchende Prozesse freizugeben.
Sofern Process Mining noch nicht im Unternehmen etabliert ist, sollten Sie die “low hanging Fruits” finden, damit Ihre Initiative zu einem nachhaltigen Erfolg für das ganze Unternehmen werden kann, beginnen Sie möglichst nicht gleich mit der größten “Baustelle”.
5. Datenanforderung und Datenrestriktionen frühzeitig klären
Dass der Erfolg Ihrer Process Mining Initiative auch vom zu analysierenden Prozess abhängt und damit auch die Datenverfügbarkeit vorab untersucht worden sein sollte, hatten wir schon erörtert. Aber selbst für gängigere Prozesse verzögern sich Process Mining Vorhaben auf eigentlich vermeidbarer Weise, weil die Anforderung an die Daten nicht vorab festgelegt worden sind. In der Tat ist die Definition der Datenanforderung, also welche Datentabellen mit Filterung auf Spalten und Zeilen für das Event Log benötigt werden, vorab manchmal gar nicht so einfach, besonders bei exotischeren Quellsystemen. Es sollte zumindest jedoch die grobe Anforderung beschrieben werden, unter Nennung der Datenbanken und einer Metabeschreibung, um welche Daten es geht. Auch deswegen, um den Datenschutzbeauftragten und sonstige Genehmiger frühzeitig einbinden zu können. Bei gängigen Quellsystemen und Standardprozessen (z. B. Procure to Pay oder Order to Cash eines SAP ERPs) kann die Anforderung bereits früh auf hohem Detaillevel vorab geschehen.
Konkretes Beispiel: Ein Unternehmen hat gerade sein Process Mining Projekt gestartet, steckt jedoch seit Tagen in der Datenbeschaffung fest. Die IT-Systemintegratoren weigern sich, Daten ohne genaue Anforderung aus den Quellsystemen zu exportieren oder einen API-Zugang bereit zu stellen und die Freigabe des Datenschutzbeauftragten sowie der IT-Sicherheit fehlen.
Neben der Anforderungsdefinition sollte also auch die Kommunikation mit den Administratoren der Quellsysteme frühzeitig erfolgen.
6. Das Big Picture vor Augen haben
Insbesondere wenn Process Mining nicht nur eine einmalige Ad-Hoc Analyse bleiben, sondern unternehmensweit eingeführt werden soll, sollte eine verlässliche, integrative und nachhaltige Architektur überlegt werden. Process Mining ist – wir wiederholen uns – eine Methodik, die mit Business Intelligence, Data Science (Machine Learning) und RPA in Verbindung gebracht werden kann.
Konkretes Beispiel: Eine Fachabteilung eines Unternehmens führte ein Process Mining Tool als eigenständige Lösung ein, um Prozesse hinsichtlich ihrer Automatisierbarkeit zu untersuchen. Dabei werden NLP-Algorithmen aus dem Machine Learning bei der Datenextraktion aus Texten eine Rolle spielen. Das ausgewählte Process Mining Tool wurde auch auf Grund seiner inhouse-Lösung für Machine Learning ausgesucht. In einer benachbarten Abteilung ist bereits ein RPA-Tool im Einsatz und auf der globalen Unternehmensebene ist ein bestimmtes BI-Tool der Standard für Reporting und Datenanalysen.
Statt vieler Einzellösungen, könnte die Fachabteilung das konzernweite BI-Tool mit Process Mining Erweiterung (Plugin zum BI-Tool, z. B. für Qlik Sense oder Power BI erhältlich) nutzen und dabei auch die RPA-Lösung mit dieser verbinden. Ein Data Warehouse für BI ist ebenfalls vorhanden und könnte ggf. zu einem für Process Mining erweitert werden. Für den Einsatz von Machine Learning können Data Scientists die Daten im Process Mining Data Warehouse zum Training verwenden und Prädiktionsergebnisse direkt in dieses zurückspielen.
Achten Sie auf die Gesamtarchitektur. Process Mining kann für sich alleine stehen, es kann jedoch auch sinnvoll sein, eine Datenstrategie zu entwickeln, die das Projekt im Kontext vorhandener Daten-Initiativen betrachtet und einen integrativen Ansatz erlaubt.



 Jürgen Seitz
Jürgen Seitz Alicia Krafft
Alicia Krafft