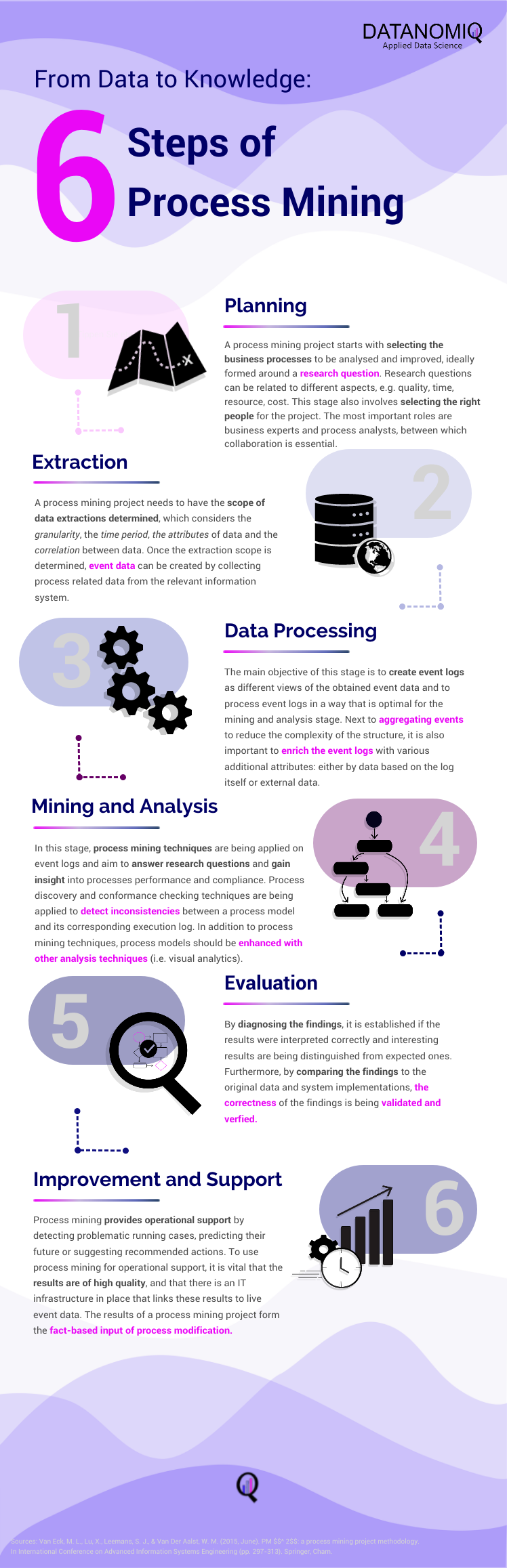
 Jurek Dörner @ DATANOMIQ
Jurek Dörner @ DATANOMIQHow to reduce costs for Process Mining
Process mining has emerged as a powerful Business Process Intelligence discipline (BPI) for analyzing and improving business processes. It involves extracting data from source systems to gain insights into process behavior and uncover opportunities for optimization. While there are many approaches to create value with process mining, organizations often face challenges when it comes to the cost of implementing the necessary solution. In this article, we will highlight the key elements when it comes to process mining architectures as well as the most common mistakes, to help organizations leverage the power of process mining while maintain cost control.
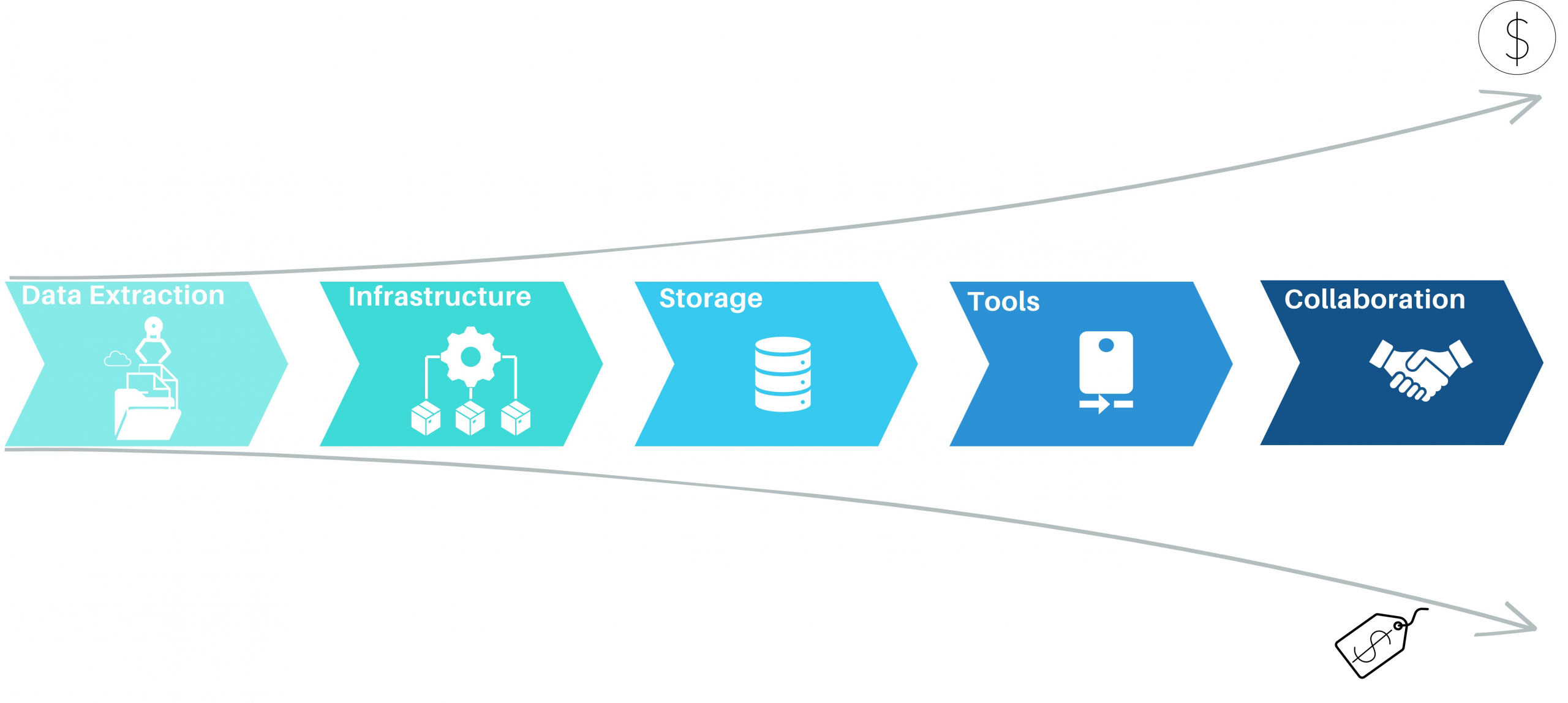
Process Mining – Elements of Process Mining and their cost aspects
Data Extraction for process mining
Most process mining projects underestimate the complexity of data extraction. Even for well-known sources like SAP-ERP’s, the extraction often consumes 50% of the first pilot’s resources. As a result, the extraction pipelines are often built with the credo of “asap” and this is where the cost-drama begins. Process Mining demands Big Data in 99% of the cases, releasing bad developed extraction jobs will end in big cost chunks down the value stream. Frequently organizations perform full loads of big SAP tables, causing source system performance impact, increasing maintenance, and moving hundred GB’s of data on daily basis without any new value. Other organizations fall for the connectors, provided by some process mining platform tools, promising time-to-value being the best. Against all odds the data is getting extracted then into costly third-party platforms where they can be only consumed by the platforms process mining tool itself. On top of that, these organizations often perform more than one Business Process Intelligence discipline, resulting in extracting the exact same data multiple times.
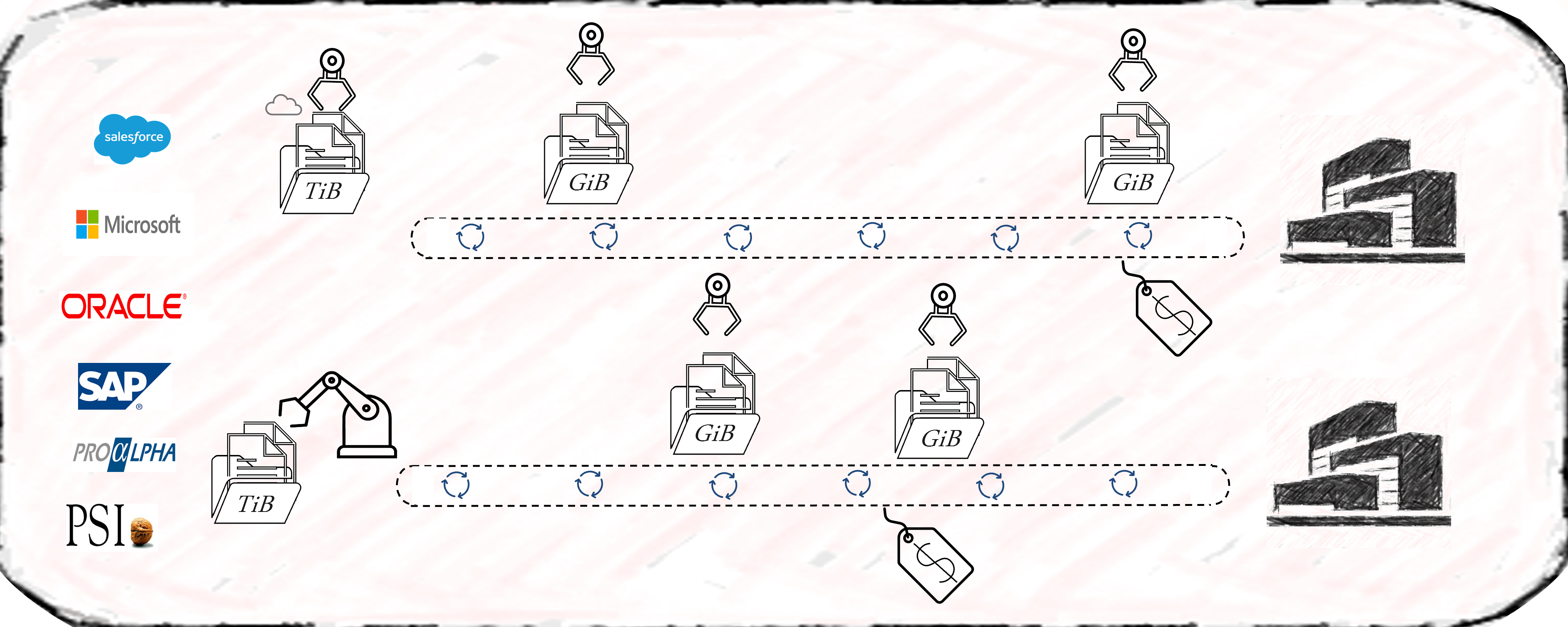
Process Mining – Data Extraction
The data extraction for process mining should be well planed and match the data strategy of the organization. By considering lightweighted data preprocessing techniques organizations can save both time and money. When accepting the investment character of big data extractions, the investment should be done properly in the beginning and therefore cost beneficial in the long term.
Cloud-Based infrastructure with process mining?
Depending on the data strategy of one organization, one cost-effective approach to process mining could be to leverage cloud computing resources. Cloud platforms, such as Amazon Web Services (AWS), Microsoft Azure, or Google Cloud Platform (GCP), provide scalable and flexible infrastructure options. By using cloud services, organizations can avoid the upfront investment in hardware and maintenance costs associated with on-premises infrastructure. They can pay for resources on a pay-as-you-go basis, scaling up or down as needed, which can significantly reduce costs. When dealing with big data in the cloud, meeting the performance requirements while keeping cost control can be a balancing act, that requires a high skillset in cloud technologies. Depending the organization situation and data strategy, on premises or hybrid approaches should be also considered. But costs won’t decrease only migrating from on-premises to cloud and vice versa. What makes the difference is a smart ETL design capturing the nature of process mining data.
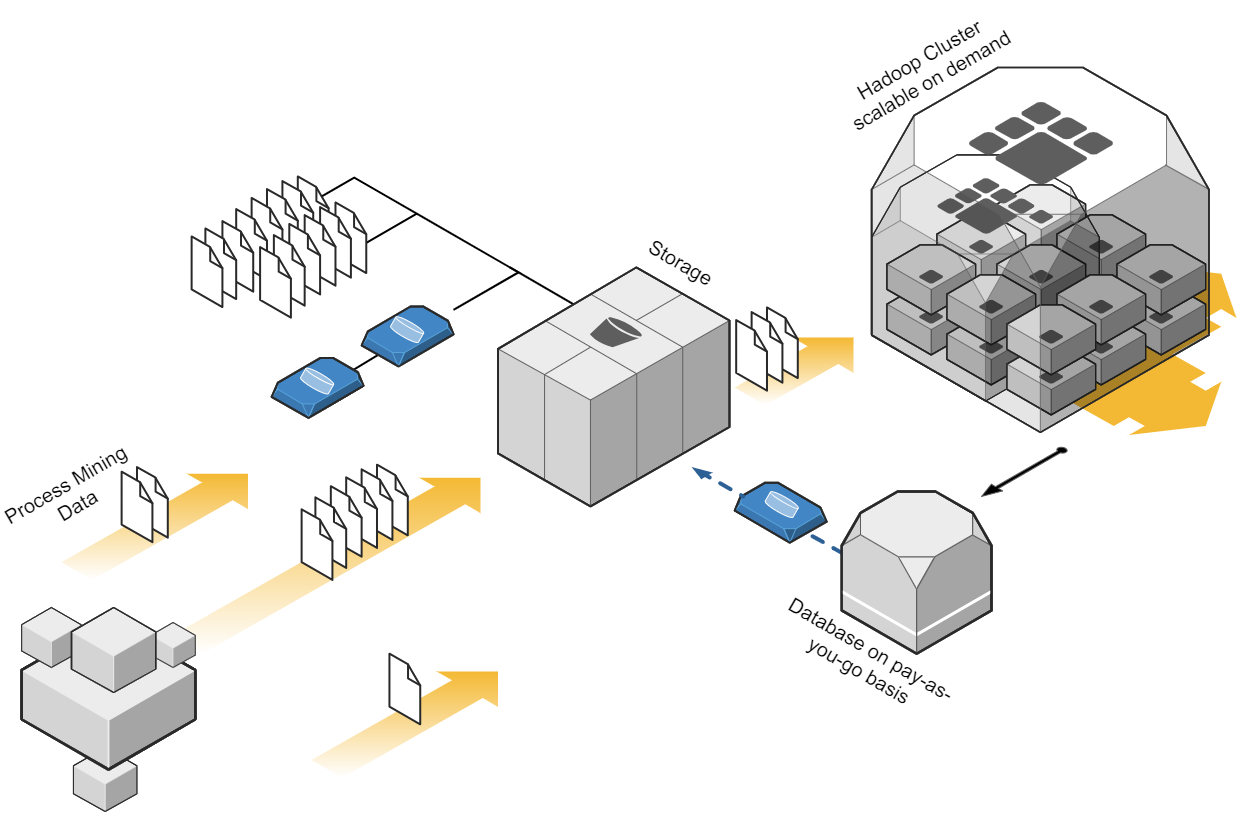
Process Mining Cloud Architecture on “pay as you go” base.
Storage for process mining data
Storing data is a crucial aspect of process mining, as in most cases big data is involved. Instead of investing in expensive data storage solutions, which some process mining solutions offer, organizations can opt for cost-effective alternatives. Cloud storage services like Amazon S3, Azure Blob Storage, or Google Cloud Storage provide highly scalable and durable storage options at a fraction of the cost of process mining storage systems. By utilizing these services, organizations can store large volumes of event data without incurring substantial expenses. Moreover, when big data engineering technics, consider profound process mining logics the storage cost cut down can be tremendous.
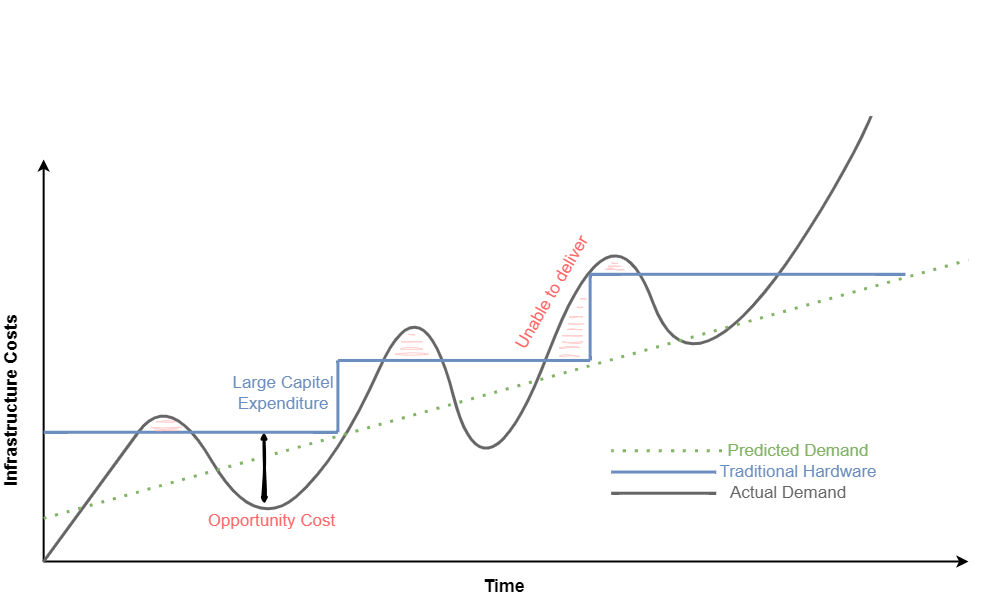
Process Mining – Infrastructure Cost Curve: On-Premise vs Cloud
Process Mining Tools
While some commercial process mining tools can be expensive, there are several powerful more economical alternatives available. Tools like Process Science, ProM, and Disco provide comprehensive process mining capabilities without the hefty price tag. These tools offer functionalities such as event log import, process discovery, conformance checking, and performance analysis. Organizations often mismanage the fact, that there can and should be more then one process mining tool available. As expensive solutions like Celonis have their benefits, not all use cases make up for the price of these tools. As a result, these low ROI-use cases will eat up the margin, or (and that’s even more critical) little promising use cases won’t be investigated on and therefore high hanging fruits never discovered. Leveraging process mining tools can significantly reduce costs while still enabling organizations to achieve valuable process insights.

Process Mining Tool Landscape (examples shown)
Collaboration
Another cost-saving aspect is to encourage collaboration within the organization itself. Most process mining initiatives require the input from process experts and often involve multiple stakeholders across different departments. By establishing cross-functional teams and supporting collaboration, organizations can share resources and distribute the cost burden. This approach allows for the pooling of expertise, reduces duplication of efforts, and facilitates knowledge exchange, all while keeping costs low.
Process Mining Team Structure
Conclusion
Process mining offers tremendous potential for organizations seeking to optimize their business processes. While many organizations start process mining projects euphorically, the costs set an abrupt end to the party. Implementing a low-cost and collaborative architecture can help to create a sustainable value for the organization. By leveraging cloud-based infrastructure, cost-effective storage solutions, big data engineering techniques, process mining tools, well developed data extractions, lightweight data preprocessing techniques, and fostering collaboration, organizations can embark on process mining initiatives without straining their budgets. With the right approach, organizations can unlock the power of process mining and drive operational excellence without losing cost control.
One might argue that implementing process mining is not only about the costs. In the end each organization must consider the long-term benefits and return on investment (ROI). But with a cost controlled and sustainable process mining approach, return on investment is likely higher and less risky.
This article provides general information for process mining cost reduction. Specific strategic decisions should always consider the unique requirements and restrictions of individual organizations.
 DATANOMIQ - Benjamin Aunkofer
DATANOMIQ - Benjamin Aunkofer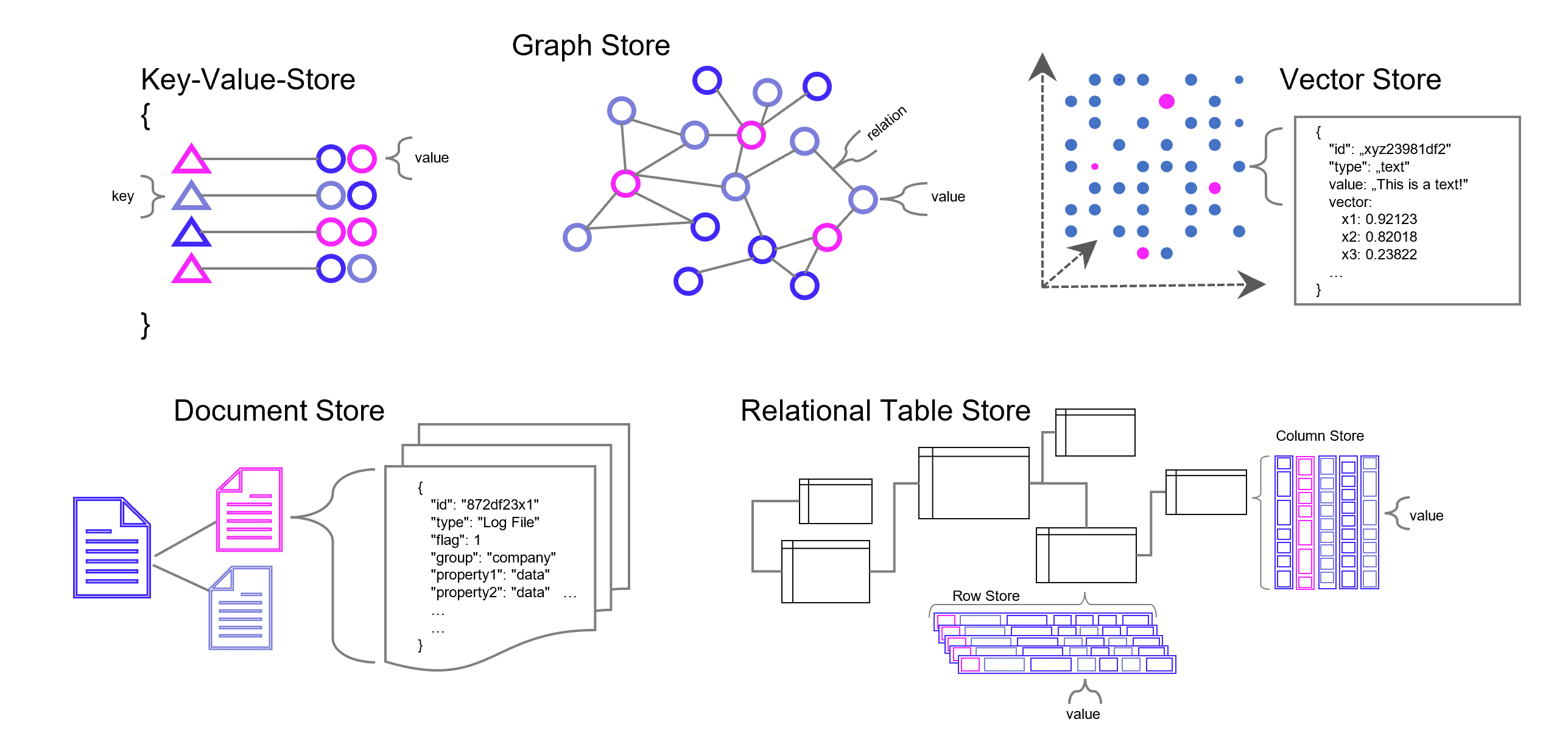
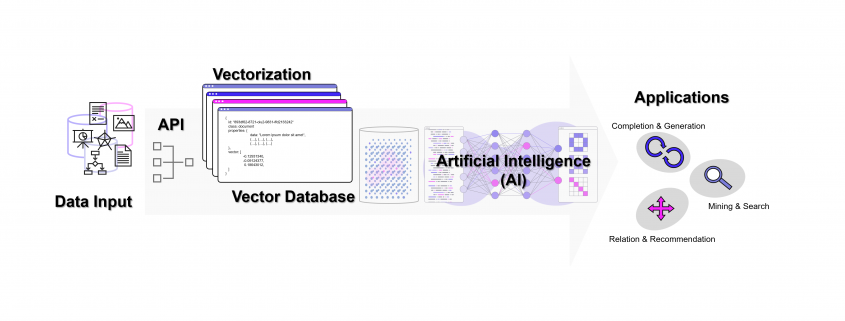
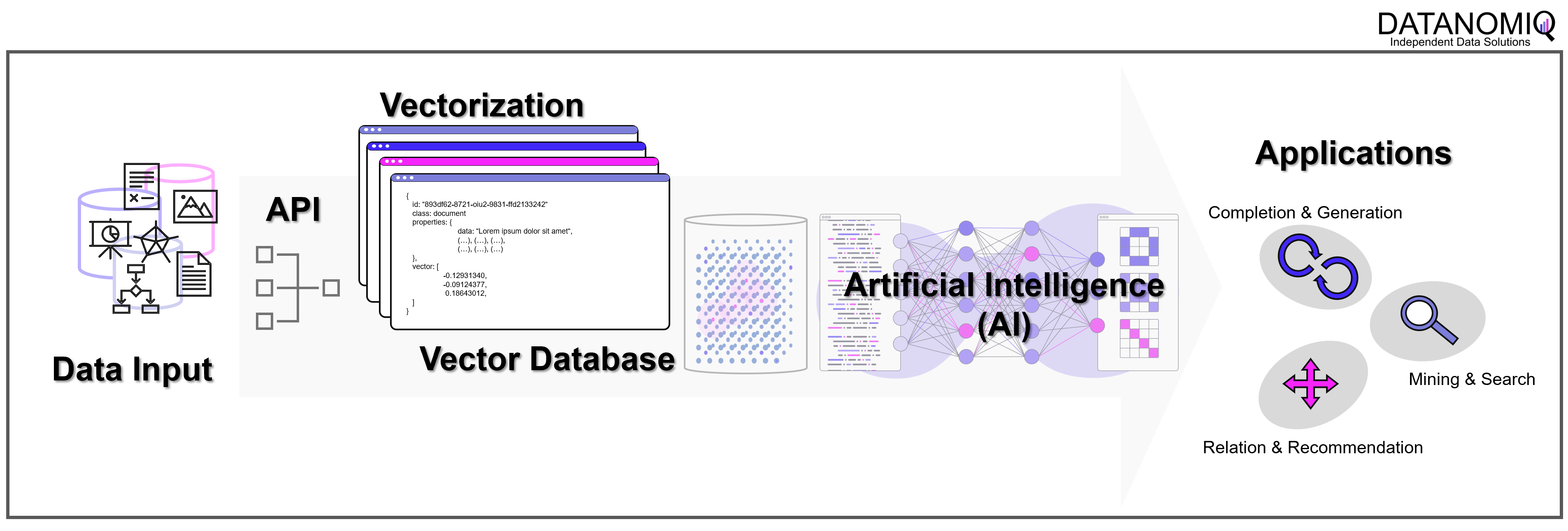
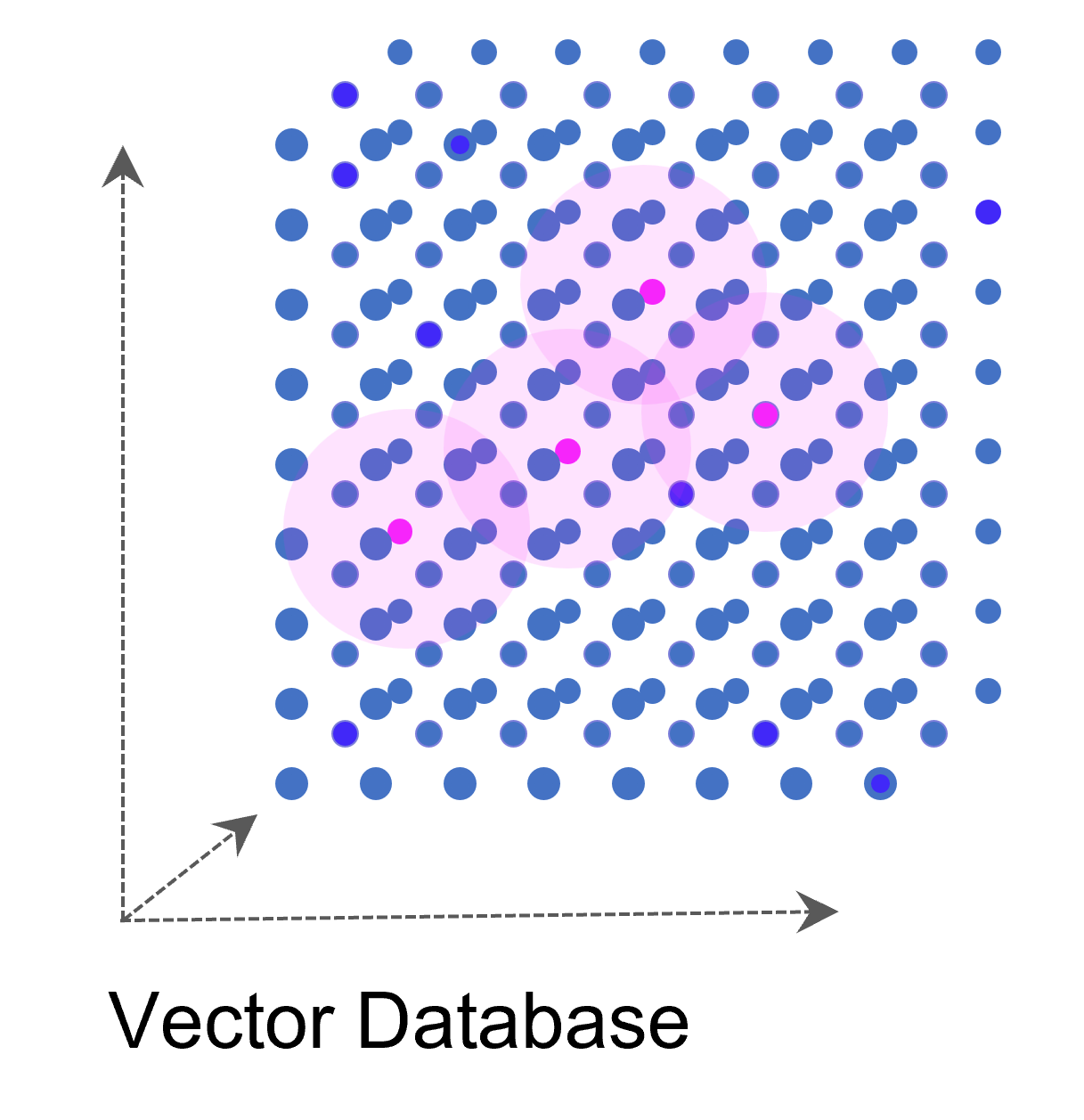 Weise kann eine ganze Sammlung von Bildern als eine Sammlung von Vektoren dargestellt werden. Noch gängiger jedoch sind Vektorräume, die Texte z. B. über die Häufigkeit des Auftretens von Textbausteinen (Wörter, Silben, Buchstaben) in sich einbetten (Embeddings). Embeddings sind folglich Vektoren, die durch die Projektion des Textes auf einen Vektorraum entstehen.
Weise kann eine ganze Sammlung von Bildern als eine Sammlung von Vektoren dargestellt werden. Noch gängiger jedoch sind Vektorräume, die Texte z. B. über die Häufigkeit des Auftretens von Textbausteinen (Wörter, Silben, Buchstaben) in sich einbetten (Embeddings). Embeddings sind folglich Vektoren, die durch die Projektion des Textes auf einen Vektorraum entstehen.
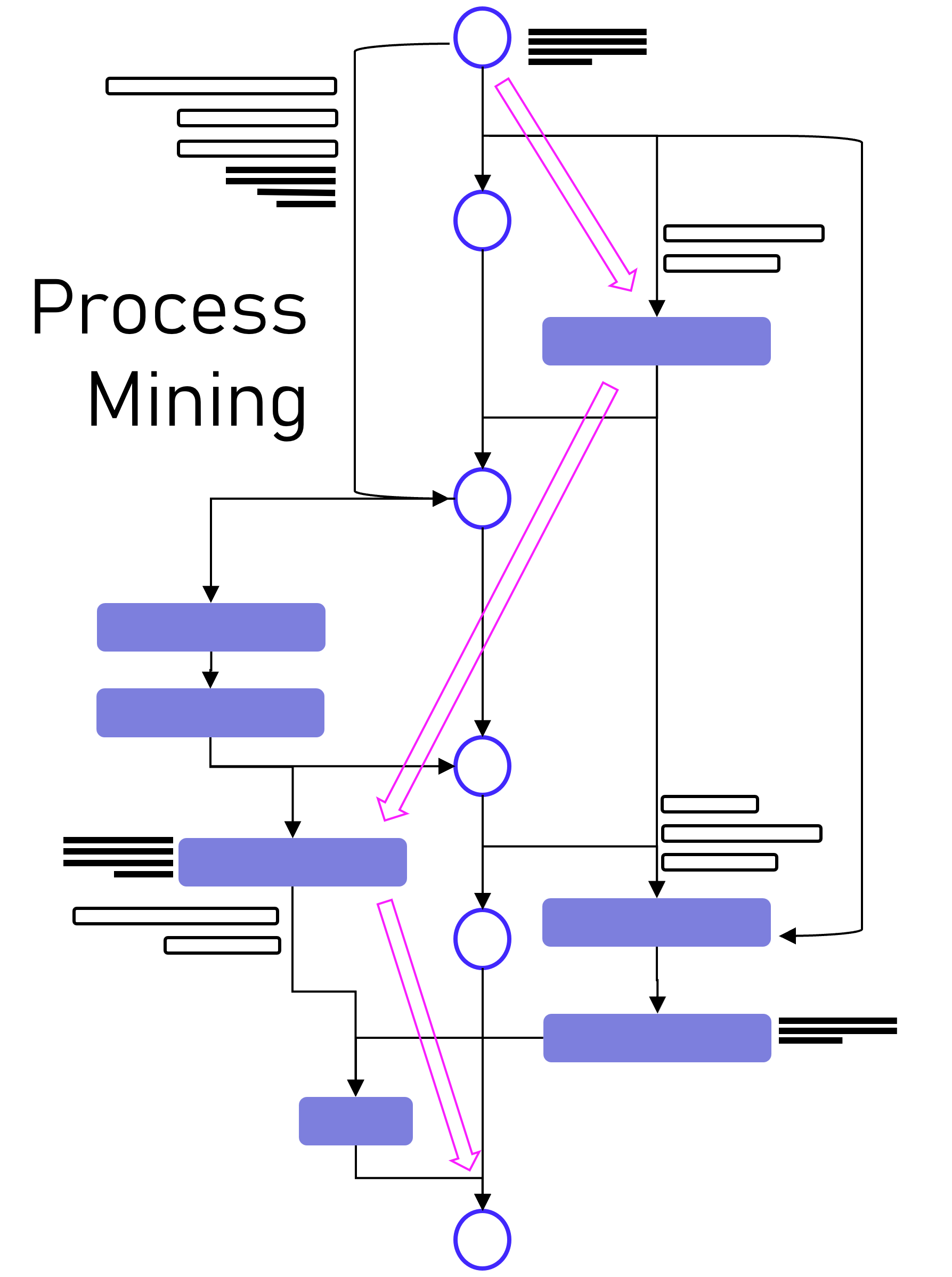 Dabei gibt es viele Hebel für Unternehmen, die Kosten für diese Analysen deutlich zu reduzieren, dabei gesamtheitlicher analysieren zu können und sich von einzelnen Tool-Anbietern unabhängiger zu machen. Denn die Herausforderung beginnt bereits mit denen eigentlichen Zielen von Process Mining für ein Unternehmen, und diese sind oft nicht einmal direkt finanziell messbar.
Dabei gibt es viele Hebel für Unternehmen, die Kosten für diese Analysen deutlich zu reduzieren, dabei gesamtheitlicher analysieren zu können und sich von einzelnen Tool-Anbietern unabhängiger zu machen. Denn die Herausforderung beginnt bereits mit denen eigentlichen Zielen von Process Mining für ein Unternehmen, und diese sind oft nicht einmal direkt finanziell messbar.