
Interview – Mehr Business-Nerds, bitte!
Die Haufe Akademie im Gespräch mit Prof. Dr. Stephan Matzka, Hochschulprofessor an der HTW Berlin und Trainer der Haufe Akademie darüber, wie Data Science und KI verdaulich vermittelt werden können und was eigentlich passiert, wenn man es nicht tut.
Sie beschäftigen sich mit Data Science, Algorithmen und Machine Learning – Hand aufs Herz: Sind Sie ein Nerd, Herr Prof. Matzka?
Stephan Matzka: (lacht) Ich bin ein neugieriger Mensch und möchte gerne mehr über die Menschen und Dinge erfahren, die mich umgeben. Dafür benötige ich Informationen, die ich einordnen und bewerten kann und nichts anderes macht Data Science. Wenn Neugier also einen Nerd ausmacht, bin ich gerne ein Nerd.
Aber all die Buzzwords, die Sie gerade genannt haben, wie Machine Learning oder Algorithmen, blenden mehr als sie helfen. Ich spreche lieber von menschlicher und künstlicher Intelligenz. Deren Gemeinsamkeiten und Unterschiede sind gut zu erklären und dieses Verständnis ist der Schlüssel für alles Weitere.
Ist das Verständnis für Data Science und Machine Learning auch der Schlüssel für den Zukunftserfolg von Unternehmen oder wird die Businessrelevanz von Data Science überschätzt?
Stephan Matzka: Zunächst mal ist Machine Learning größtenteils einfach Statistik, die sehr clever angewandt wird. Damit wir Benutzer:innen nicht wie in der Schule mit der Hand rechnen müssen, gibt es Algorithmen, die uns die Arbeit abnehmen. Die Theorie ist also altbekannt. Aber die technischen Möglichkeiten haben sich geändert.
Sie können das mit Strom vergleichen, den gibt es schon länger. Aber erst mit einem Elektromotor können Sie Power auf die Straße bringen. Daten sind also altbekannte Rohstoffe, die Algorithmen und Rechenleistung von heute aber ein völlig neuer Motor.
Wenn Sie sehen, wie radikal die Dampfmaschine und der Elektromotor die Wirtschaft beeinflusst haben, dann gewinnen Sie einen Eindruck, was gerade im Bereich künstliche Intelligenz abgeht, und das über alle Unternehmensgrößen und Branchen hinweg.
So eine Dampfmaschine ist für viele wahrscheinlich deutlich einfacher zu greifen als das tech-lastige Universum Data Science. Das ist schon sehr abstrakt. Ist es so schwierig, wie es aussieht?
Stephan Matzka: Data Science kann man, wie alle Dinge im Leben, kompliziert oder einfach machen. Und es gibt auch auf diesem Feld Menschen, die Schwieriges einfach aussehen lassen. Das sind die Vorbilder, von denen wir alle lernen können.
Künstliche Intelligenz, oder kurz KI, bietet Menschen und Unternehmen große Chancen, wenn Sie sich rechtzeitig damit beschäftigen. Dabei geht es um nicht weniger als die Frage, ob wir in unserer Arbeitswelt zukünftig KI für uns arbeiten lassen oder abwarten, bis uns ein Algorithmus vorgibt, was wir als Nächstes tun sollen. Mit der richtigen Unterstützung ist der Aufwand jedoch überschaubar und der Nutzen für Unternehmen und Organisationen enorm.
Viele Mitarbeiter:innen hören nach „Wir sind jetzt agil“ neuerdings „Mach‘ mal KI“ – was raten Sie den Kolleg:innen und Entscheider:innen in mittelständischen Unternehmen für den Umgang mit dem Thema?
Stephan Matzka: Es braucht zum einen Impulse „von außen“, um sich mit diesem wichtigen Thema auseinanderzusetzen und einen Start zu finden. Und zum anderen braucht es Mitarbeiter:innen, die datenaffin sind, sich mit dem Thema bereits auseinandergesetzt haben und Use Cases entwickeln sowie hinterfragen können. Meine Berufserfahrung zeigt: Gerade am Anfang ist es noch sehr leicht, bei den klassischen „Low Hanging Fruits“ Erfolge zu erzielen. Das motiviert für das nächste Projekt und schon ist das Momentum im Unternehmen.
Was sind die Minimalanforderungen in einem Unternehmen, um mit Data Science und Machine Learning einen echten Mehrwert zu schaffen und die „Low Hanging Fruits“ zu ernten?
Stephan Matzka: Der Rohstoff sind Daten in digitaler Form, ob in Excel-Listen, in SAP oder einer Datenbank ist erst mal zweitrangig. Für die Auswertung brauchen Sie passende Software und Menschen, die diese Software bedienen können.
In jedem Unternehmen gibt es solche Daten, die Software ist häufig kostenlos, der eigentliche Engpass sind aktuell die Expert:innen.
Könnte ich mir nicht die Arbeit sparen und Beratungsunternehmen einsetzen?
Stephan Matzka: Das könnten Sie, und Beratungsunternehmen können Ihnen oft auch die richtigen Themen aufzeigen. Gleichzeitig wirft dies zwei wesentliche Fragen auf: Wie können Sie die Qualität und den Preis einer Lösung beurteilen, die Ihnen ein externer Dienstleister anbietet? Und zweitens, wie verankern Sie nachhaltig das Wissen in Ihrem Unternehmen?
Damit die Beratungsleistung Ihnen also wirklich weiterhilft, benötigen Sie Beurteilungskompetenz auf dem Gebiet der künstlichen Intelligenz im eigenen Unternehmen. Diese Beurteilungskompetenz im Businesskontext zu schaffen ist aus meiner Sicht ein wesentlicher Erfolgsfaktor für Unternehmen und sollte eher kurz- als mittelfristig angegangen werden.
Haufe Akademie: Nochmal zurück zu den Daten: Woher weiß ich, ob ich genug Daten habe? Sonst bilde ich jemanden aus oder stelle jemanden ein, der mich Geld kostet, aber nichts zu tun hat.
Stephan Matzka: Mit den Daten ist es ein wenig so wie mit den Finanzen, kann ich jemals „genug Budget“ im Unternehmen haben? Natürlich ist es mit großen Datenmengen leichter möglich, bessere Resultate zu erzielen, genauso wie mit mehr Projektbudget. Aber wir alle haben schon erlebt, wie kleine Projekte Erstaunliches bewegt haben und Großprojekte spektakulär gescheitert sind.
Genau wie Budgets sind Daten meist in dem Umfang vorhanden, in dem sie eben verfügbar sind. Die vorhandenen Daten klug zu nutzen: Das ist das Ziel.
Ein Beispiel aus der Praxis: Es gibt sehr große Firmen mit riesigen Datenmengen, die mir, nachdem ich bei ihnen einen Drucker gekauft habe, weiter Werbung für andere Drucker zeigen anstatt Werbung für passende Toner. So eine KI würde mir kein mittelständisches Unternehmen abnehmen.
Gleichzeitig werden Sie sich wundern, welches Wissen oft schon in einfachen Excel-Tabellen schlummert. Wissen Sie zum Beispiel, was Ihnen der höchste Umsatz eines Kunden in den letzten zwölf Monaten und die Zeitabstände der letzten drei Bestellungen schon jetzt über die nächste Bestellung verraten?
In meinen Recherchen zum Thema bin ich oft an hohen Einstiegshürden gescheitert. Trotzdem habe ich gespürt, dass das Thema wichtig ist. Das war mitunter frustrierend. Welche Fragen sollte ich mir als Mitarbeiter:in stellen, wenn ich mich für Data Science interessiere, aber keine Vorkenntnisse habe?
Stephan Matzka: Das Wichtigste ist erstmal, sich nicht abschrecken zu lassen. 80% der Themen lassen sich zum Beispiel komplett ohne Mathematik erklären. Nochmal 15% sind Stoff der Sekundarstufe, bleiben noch 5% übrig. Die haben es tatsächlich in sich und dann können Sie sich immer noch entscheiden: Finde ich das Thema so spannend (und habe ich die Zeit), dass ich mich auch da noch reinarbeite. Oder reichen mir die 95% Verständnis für die zuverlässige Lösung meiner Business-Fragestellungen aus. Viel entscheidender ist für mich, sich dem Thema mutig anzunehmen, die ersten Erfolge zu feiern und mit diesem Rückenwind die nächsten Schritte zu tun.
Vielen Dank für das Gespräch, Herr Prof. Matzka!




 Jürgen Seitz
Jürgen Seitz Alicia Krafft
Alicia Krafft
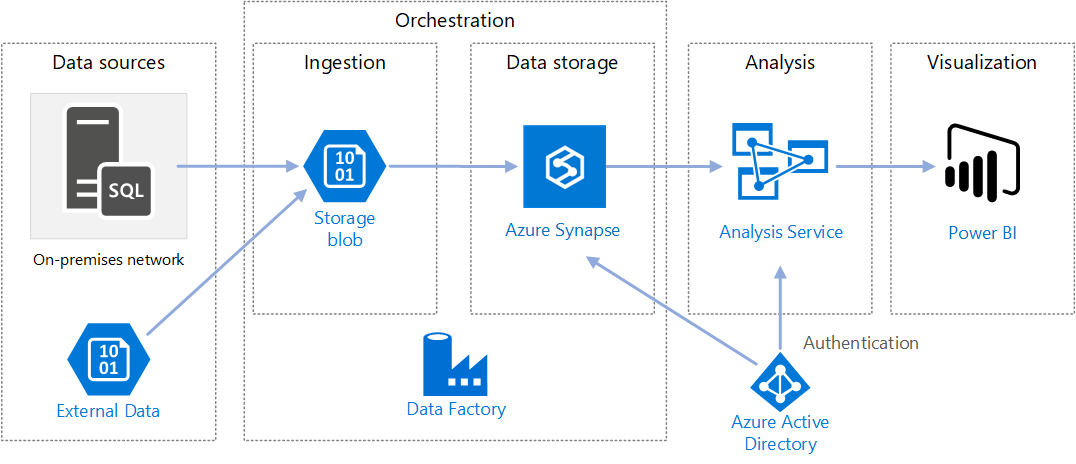 https://docs.microsoft.com/en-us/azure/architecture/reference-architectures/data/enterprise-bi-adfQuelle:
https://docs.microsoft.com/en-us/azure/architecture/reference-architectures/data/enterprise-bi-adfQuelle: 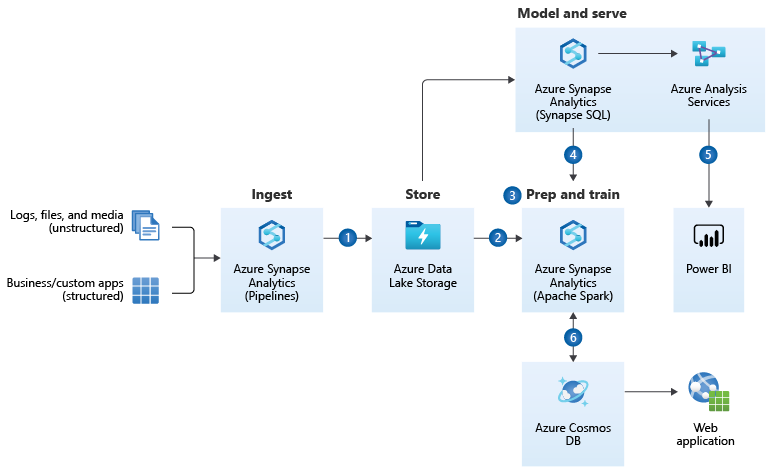 https://docs.microsoft.com/en-us/azure/architecture/solution-ideas/articles/enterprise-data-warehouseQuelle:
https://docs.microsoft.com/en-us/azure/architecture/solution-ideas/articles/enterprise-data-warehouseQuelle: 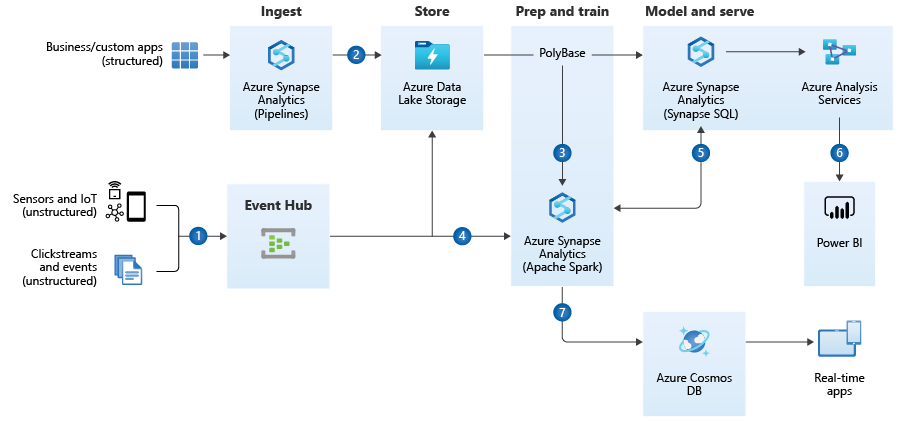
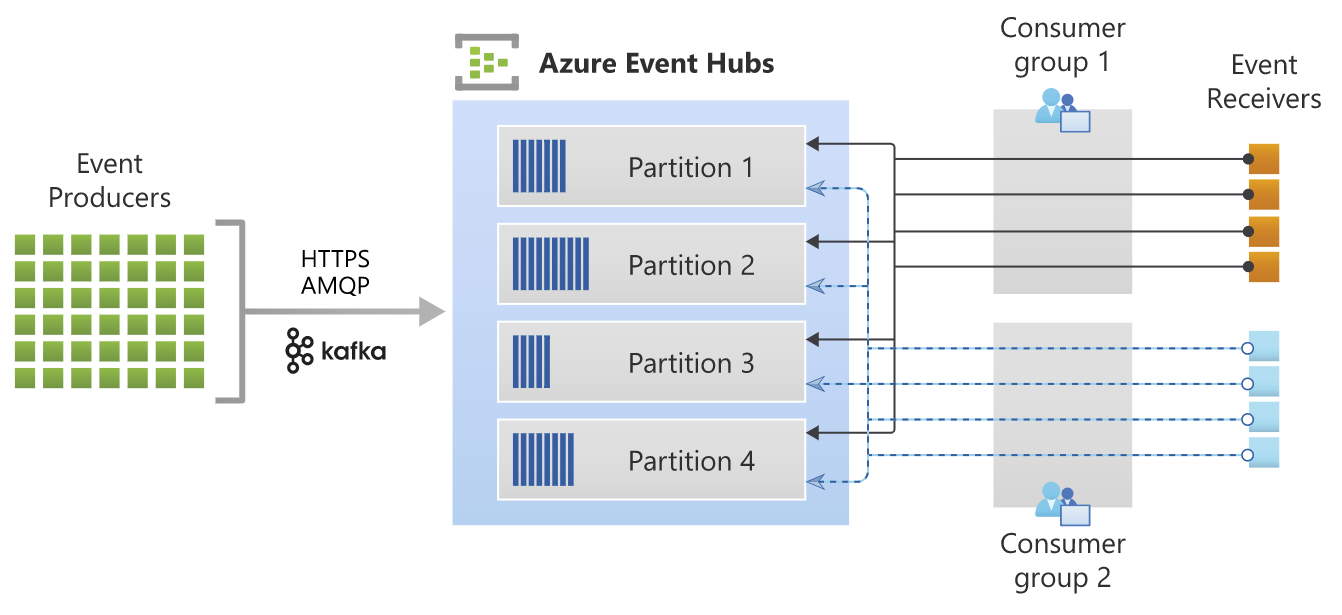 Quelle: https://docs.microsoft.com/de-de/azure/event-hubs/event-hubs-about
Quelle: https://docs.microsoft.com/de-de/azure/event-hubs/event-hubs-about 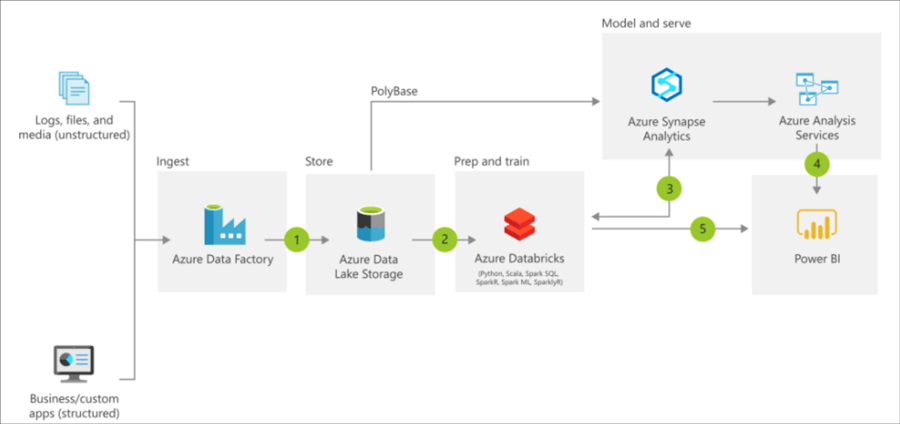

 Dr. Florian Nielsen ist Principal for AI und Data Science bei Miele im Bereich Smart Home und zuständig für die Entwicklung daten-getriebener digitaler Produkte und Produkterweiterungen. Der studierte Informatiker promovierte an der Universität Ulm zum Thema multimodale kognitive technische Systeme.
Dr. Florian Nielsen ist Principal for AI und Data Science bei Miele im Bereich Smart Home und zuständig für die Entwicklung daten-getriebener digitaler Produkte und Produkterweiterungen. Der studierte Informatiker promovierte an der Universität Ulm zum Thema multimodale kognitive technische Systeme.