
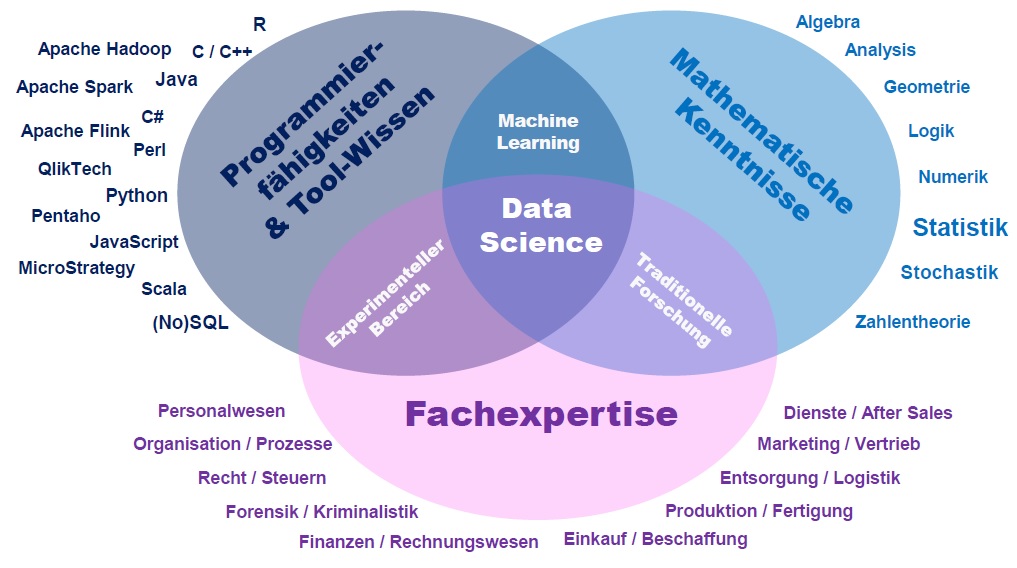
Data Science Knowledge Stack – Was ein Data Scientist können muss
 Was muss ein Data Scientist können? Diese Frage wurde bereits häufig gestellt und auch häufig beantwortet. In der Tat ist man sich mittlerweile recht einig darüber, welche Aufgaben ein Data Scientist für Aufgaben übernehmen kann und welche Fähigkeiten dafür notwendig sind. Ich möchte versuchen, diesen Konsens in eine Grafik zu bringen: Ein Schichten-Modell, ähnlich des OSI-Layer-Modells (welches übrigens auch jeder Data Scientist kennen sollte).
Was muss ein Data Scientist können? Diese Frage wurde bereits häufig gestellt und auch häufig beantwortet. In der Tat ist man sich mittlerweile recht einig darüber, welche Aufgaben ein Data Scientist für Aufgaben übernehmen kann und welche Fähigkeiten dafür notwendig sind. Ich möchte versuchen, diesen Konsens in eine Grafik zu bringen: Ein Schichten-Modell, ähnlich des OSI-Layer-Modells (welches übrigens auch jeder Data Scientist kennen sollte).
Ich gebe Einführungs-Seminare in Data Science für Kaufleute und Ingenieure und bei der Erläuterung, was wir in den Seminaren gemeinsam theoretisch und mit praxisnahen Übungen erarbeiten müssen, bin ich auf die Idee für dieses Schichten-Modell gekommen. Denn bei meinen Seminaren fängt es mit der Problemstellung bereits an, ich gebe nämlich Seminare für Data Science für Business Analytics mit Python. Also nicht beispielsweise für medizinische Analysen und auch nicht mit R oder Julia. Ich vermittle also nicht irgendein Data Science, sondern eine ganz bestimmte Richtung.
Ein Data Scientist muss bei jedem Data Science Vorhaben Probleme auf unterschiedlichsten Ebenen bewältigen, beispielsweise klappt der Datenzugriff nicht wie geplant oder die Daten haben eine andere Struktur als erwartet. Ein Data Scientist kann Stunden damit verbringen, seinen eigenen Quellcode zu debuggen oder sich in neue Data Science Pakete für seine ausgewählte Programmiersprache einzuarbeiten. Auch müssen die richtigen Algorithmen zur Datenauswertung ausgewählt, richtig parametrisiert und getestet werden, manchmal stellt sich dabei heraus, dass die ausgewählten Methoden nicht die optimalen waren. Letztendlich soll ein Mehrwert für den Fachbereich generiert werden und auch auf dieser Ebene wird ein Data Scientist vor besondere Herausforderungen gestellt.
![]() Read this article in English:
Read this article in English:
“Data Science Knowledge Stack – Abstraction of the Data Scientist Skillset”
Data Science Knowledge Stack
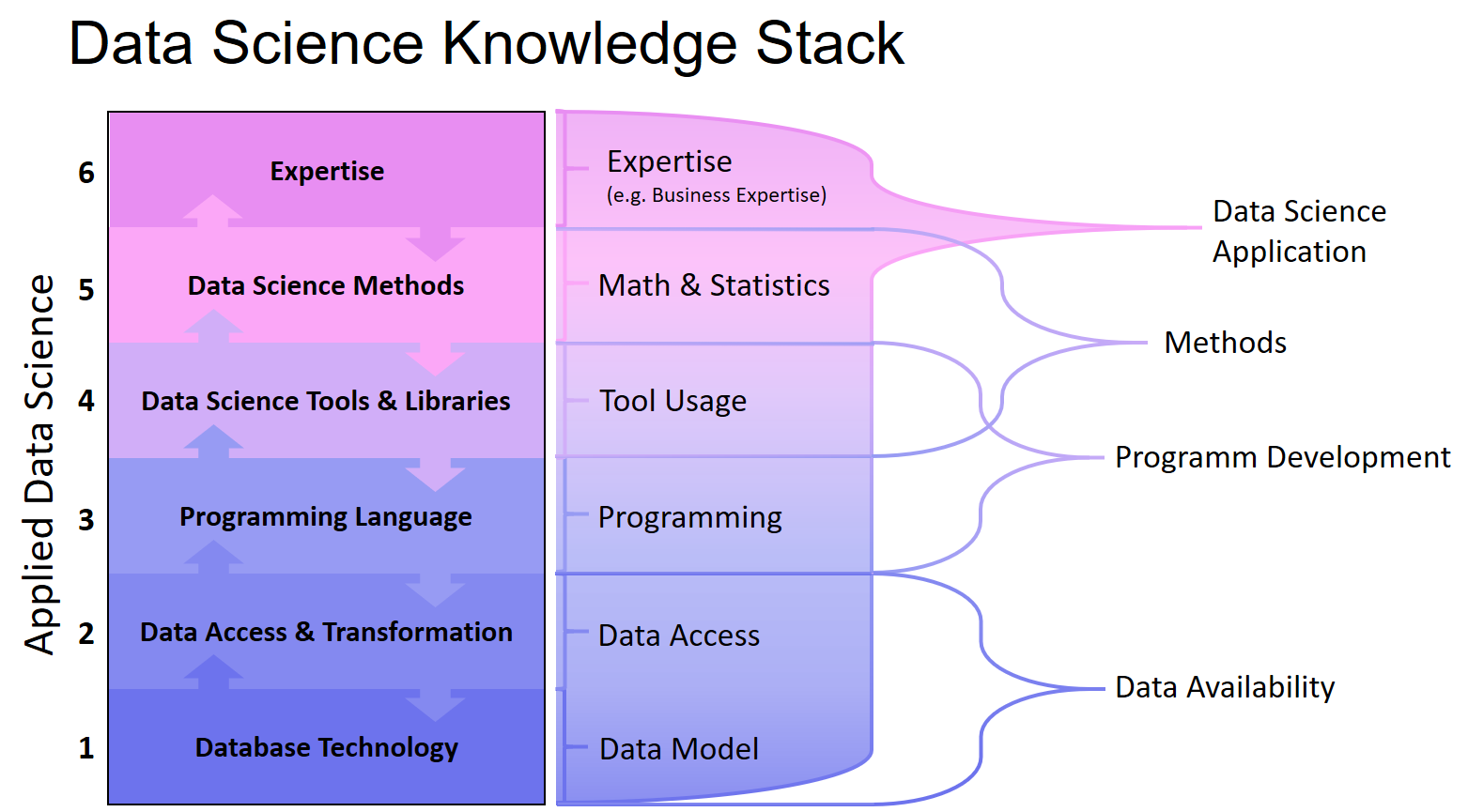
Mit dem Data Science Knowledge Stack möchte ich einen strukturierten Einblick in die Aufgaben und Herausforderungen eines Data Scientists geben. Die Schichten des Stapels stellen zudem einen bidirektionalen Fluss dar, der von oben nach unten und von unten nach oben verläuft, denn Data Science als Disziplin ist ebenfalls bidirektional: Wir versuchen gestellte Fragen mit Daten zu beantworten oder wir schauen, welche Potenziale in den Daten liegen, um bisher nicht gestellte Fragen zu beantworten.
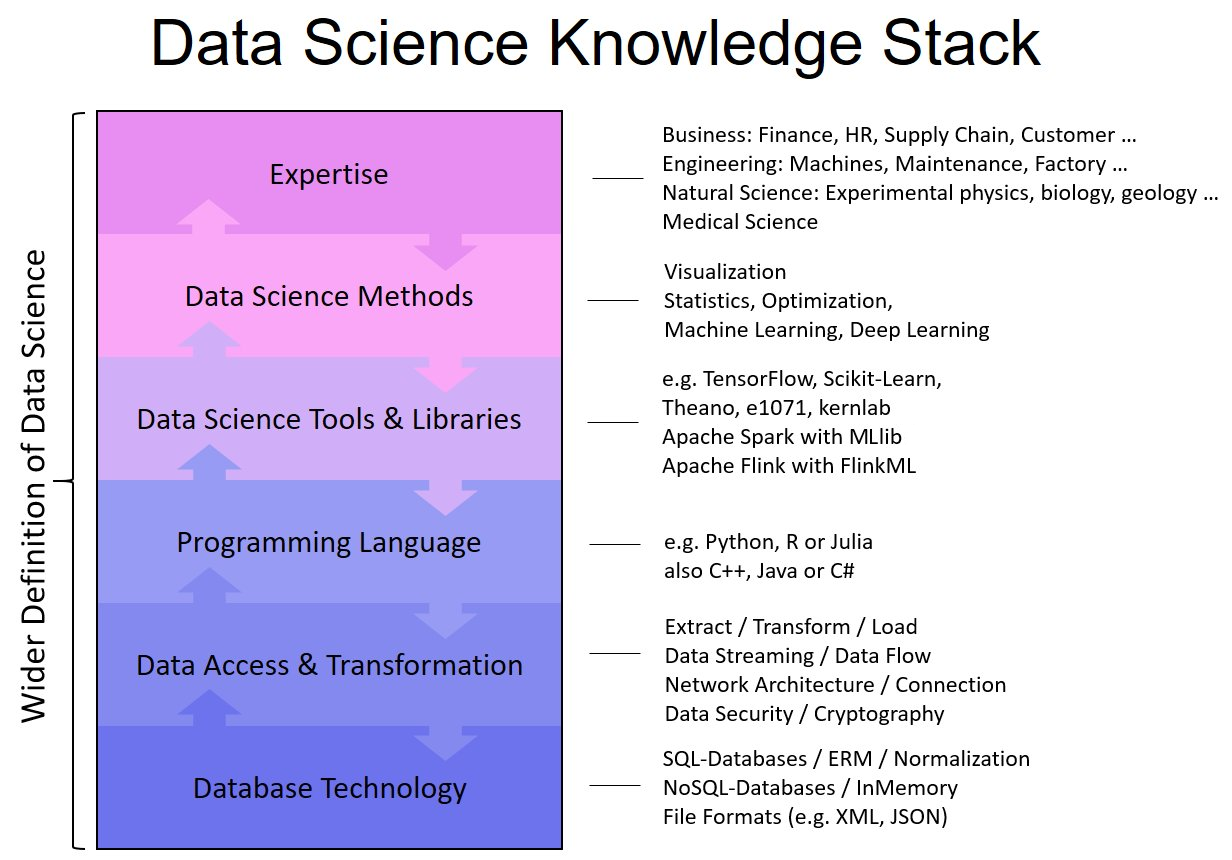
Der Data Science Knowledge Stack besteht aus sechs Schichten:
Database Technology Knowledge
Ein Data Scientist arbeitet im Schwerpunkt mit Daten und die liegen selten direkt in einer CSV-Datei strukturiert vor, sondern in der Regel in einer oder in mehreren Datenbanken, die ihren eigenen Regeln unterliegen. Insbesondere Geschäftsdaten, beispielsweise aus dem ERP- oder CRM-System, liegen in relationalen Datenbanken vor, oftmals von Microsoft, Oracle, SAP oder eine Open-Source-Alternative. Ein guter Data Scientist beherrscht nicht nur die Structured Query Language (SQL), sondern ist sich auch der Bedeutung relationaler Beziehungen bewusst, kennt also auch das Prinzip der Normalisierung.
Andere Arten von Datenbanken, sogenannte NoSQL-Datenbanken (Not only SQL) beruhen auf Dateiformaten, einer Spalten- oder einer Graphenorientiertheit, wie beispielsweise MongoDB, Cassandra oder GraphDB. Einige dieser Datenbanken verwenden zum Datenzugriff eigene Programmiersprachen (z. B. JavaScript bei MongoDB oder die graphenorientierte Datenbank Neo4J hat eine eigene Sprache namens Cypher). Manche dieser Datenbanken bieten einen alternativen Zugriff über SQL (z. B. Hive für Hadoop).
Ein Data Scientist muss mit unterschiedlichen Datenbanksystemen zurechtkommen und mindestens SQL – den Quasi-Standard für Datenverarbeitung – sehr gut beherrschen.
Data Access & Transformation Knowledge
Liegen Daten in einer Datenbank vor, können Data Scientists einfache (und auch nicht so einfache) Analysen bereits direkt auf der Datenbank ausführen. Doch wie bekommen wir die Daten in unsere speziellen Analyse-Tools? Hierfür muss ein Data Scientist wissen, wie Daten aus der Datenbank exportiert werden können. Für einmalige Aktionen kann ein Export als CSV-Datei reichen, doch welche Trennzeichen und Textqualifier können verwendet werden? Eventuell ist der Export zu groß, so dass die Datei gesplittet werden muss.
Soll eine direkte und synchrone Datenanbindung zwischen dem Analyse-Tool und der Datenbank bestehen, kommen Schnittstellen wie REST, ODBC oder JDBC ins Spiel. Manchmal muss auch eine Socket-Verbindung hergestellt werden und das Prinzip einer Client-Server-Architektur sollte bekannt sein. Auch mit synchronen und asynchronen Verschlüsselungsverfahren sollte ein Data Scientist vertraut sein, denn nicht selten wird mit vertraulichen Daten gearbeitet und ein Mindeststandard an Sicherheit ist zumindest bei geschäftlichen Anwendungen stets einzuhalten.
Viele Daten liegen nicht strukturiert in einer Datenbank vor, sondern sind sogenannte unstrukturierte oder semi-strukturierte Daten aus Dokumenten oder aus Internetquellen. Auch hier haben wir es mit Schnittstellen zutun, ein häufiger Einstieg für Data Scientists stellt beispielsweise die Twitter-API dar. Manchmal wollen wir Daten in nahezu Echtzeit streamen, beispielsweise Maschinendaten. Dies kann recht anspruchsvoll sein, so das Data Streaming beinahe eine eigene Disziplin darstellt, mit der ein Data Scientist schnell in Berührung kommen kann.
Programming Language Knowledge
Programmiersprachen sind für Data Scientists Werkzeuge, um Daten zu verarbeiten und die Verarbeitung zu automatisieren. Data Scientists sind in der Regel keine richtigen Software-Entwickler, sie müssen sich nicht um Software-Sicherheit oder -Ergonomie kümmern. Ein gewisses Basiswissen über Software-Architekturen hilft jedoch oftmals, denn immerhin sollen manche Data Science Programme in eine IT-Landschaft integriert werden. Unverzichtbar ist hingegen das Verständnis für objektorientierte Programmierung und die gute Kenntnis der Syntax der ausgewählten Programmiersprachen, zumal nicht jede Programmiersprache für alle Vorhaben die sinnvollste ist.
Auf dem Level der Programmiersprache gibt es beim Arbeitsalltag eines Data Scientists bereits viele Fallstricke, die in der Programmiersprache selbst begründet sind, denn jede hat ihre eigenen Tücken und Details entscheiden darüber, ob eine Analyse richtig oder falsch abläuft: Beispielsweise ob Datenobjekte als Kopie oder als Referenz übergeben oder wie NULL-Werte behandelt werden.
Data Science Tool & Library Knowledge
Hat ein Data Scientist seine Daten erstmal in sein favorisiertes Tool geladen, beispielsweise in eines von IBM, SAS oder in eine Open-Source-Alternative wie Octave, fängt seine Kernarbeit gerade erst an. Diese Tools sind allerdings eher nicht selbsterklärend und auch deshalb gibt es ein vielfältiges Zertifizierungsangebot für diverse Data Science Tools. Viele (wenn nicht die meisten) Data Scientists arbeiten überwiegend direkt mit einer Programmiersprache, doch reicht diese alleine nicht aus, um effektiv statistische Datenanalysen oder Machine Learning zu betreiben: Wir verwenden Data Science Bibliotheken, also Pakete (Packages), die uns Datenstrukturen und Methoden als Vorgabe bereitstellen und die Programmiersprache somit erweitern, damit allerdings oftmals auch neue Tücken erzeugen. Eine solche Bibliothek, beispielsweise Scikit-Learn für Python, ist eine in der Programmiersprache umgesetzte Methodensammlung und somit ein Data Science Tool. Die Verwendung derartiger Bibliotheken will jedoch gelernt sein und erfordert für die zuverlässige Anwendung daher Einarbeitung und Praxiserfahrung.
Geht es um Big Data Analytics, also die Analyse von besonders großen Daten, betreten wir das Feld von Distributed Computing (Verteiltes Rechnen). Tools (bzw. Frameworks) wie Apache Hadoop, Apache Spark oder Apache Flink ermöglichen es, Daten zeitlich parallel auf mehren Servern zu verarbeiten und auszuwerten. Auch stellen diese Tools wiederum eigene Bibliotheken bereit, für Machine Learning z. B. Mahout, MLlib und FlinkML.
Data Science Method Knowledge
Ein Data Scientist ist nicht einfach nur ein Bediener von Tools, sondern er nutzt die Tools, um seine Analyse-Methoden auf Daten anzuwenden, die er für die festgelegten Ziele ausgewählt hat. Diese Analyse-Methoden sind beispielweise Auswertungen der beschreibenden Statistik, Schätzverfahren oder Hypothesen-Tests. Etwas mathematischer sind Verfahren des maschinellen Lernens zum Data Mining, beispielsweise Clusterung oder Dimensionsreduktion oder mehr in Richtung automatisierter Entscheidungsfindung durch Klassifikation oder Regression.
Maschinelle Lernverfahren funktionieren in der Regel nicht auf Anhieb, sie müssen unter Einsatz von Optimierungsverfahren, wie der Gradientenmethode, verbessert werden. Ein Data Scientist muss Unter- und Überanpassung erkennen können und er muss beweisen, dass die Vorhersageergebnisse für den geplanten Einsatz akkurat genug sind.
Spezielle Anwendungen bedingen spezielles Wissen, was beispielsweise für die Themengebiete der Bilderkennung (Visual Computing) oder der Verarbeitung von menschlicher Sprache (Natural Language Processiong) zutrifft. Spätestens an dieser Stelle öffnen wir die Tür zum Deep Learning.
Fachexpertise
Data Science ist kein Selbstzweck, sondern eine Disziplin, die Fragen aus anderen Fachgebieten mit Daten beantworten möchte. Aus diesem Grund ist Data Science so vielfältig. Betriebswirtschaftler brauchen Data Scientists, um Finanztransaktionen zu analysieren, beispielsweise um Betrugsszenarien zu erkennen oder um die Kundenbedürfnisse besser zu verstehen oder aber, um Lieferketten zu optimieren. Naturwissenschaftler wie Geologen, Biologen oder Experimental-Physiker nutzen ebenfalls Data Science, um ihre Beobachtungen mit dem Ziel der Erkenntnisgewinnung zu machen. Ingenieure möchten die Situation und Zusammenhänge von Maschinenanlagen oder Fahrzeugen besser verstehen und Mediziner interessieren sich für die bessere Diagnostik und Medikation bei ihren Patienten.
Damit ein Data Scientist einen bestimmten Fachbereich mit seinem Wissen über Daten, Tools und Analyse-Methoden ergebnisorientiert unterstützen kann, benötigt er selbst ein Mindestmaß an der entsprechenden Fachexpertise. Wer Analysen für Kaufleute, Ingenieure, Naturwissenschaftler, Mediziner, Juristen oder andere Interessenten machen möchte, muss eben jene Leute auch fachlich verstehen können.
Engere Data Science Definition
Während die Data Science Pioniere längst hochgradig spezialisierte Teams aufgebaut haben, suchen beispielsweise kleinere Unternehmen eher den Data Science Allrounder, der vom Zugriff auf die Datenbank bis hin zur Implementierung der analytischen Anwendung das volle Aufgabenspektrum unter Abstrichen beim Spezialwissen übernehmen kann. Unternehmen mit spezialisierten Daten-Experten unterscheiden jedoch längst in Data Scientists, Data Engineers und Business Analysts. Die Definition für Data Science und die Abgrenzung der Fähigkeiten, die ein Data Scientist haben sollte, schwankt daher zwischen der breiteren und einer engeren Abgrenzung.
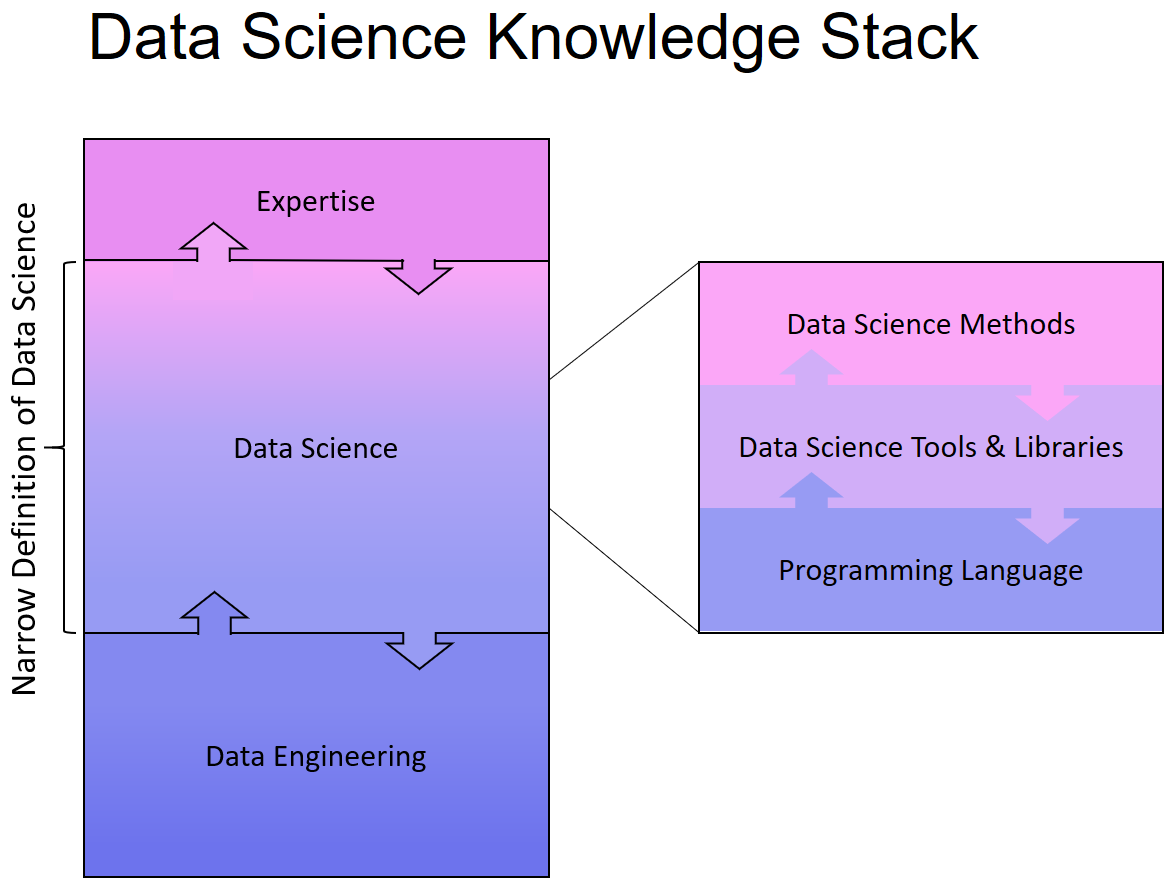
Die engere Betrachtung sieht vor, dass ein Data Engineer die Datenbereitstellung übernimmt, der Data Scientist diese in seine Tools lädt und gemeinsam mit den Kollegen aus dem Fachbereich die Datenanalyse betreibt. Demnach bräuchte ein Data Scientist kein Wissen über Datenbanken oder APIs und auch die Fachexpertise wäre nicht notwendig…
In der beruflichen Praxis sieht Data Science meiner Erfahrung nach so nicht aus, das Aufgabenspektrum umfasst mehr als nur den Kernbereich. Dieser Irrtum entsteht in Data Science Kursen und auch in Seminaren – würde ich nicht oft genug auf das Gesamtbild hinweisen. In Kursen und Seminaren, die Data Science als Disziplin vermitteln wollen, wird sich selbstverständlich auf den Kernbereich fokussiert: Programmierung, Tools und Methoden aus der Mathematik & Statistik.




 Herr Dr. Florian Neukart ist Principal Data Scientist der
Herr Dr. Florian Neukart ist Principal Data Scientist der 



 Herr Dr. Helmut Linde ist Head of Data Science bei SAP Custom Development. Der studierte Physiker und Mathematiker promovierte im Jahre 2006 und war seitdem für den Softwarekonzern mit Hauptsitz in Walldorf tätig. Dort baute Linde das Geschäft mit Dienstleistungen und kundenspezifischer Entwicklung rund um die Themen Prognose- und Optimierungsalgorithmen mit auf und leitet heute eine globale Data Science Practice.
Herr Dr. Helmut Linde ist Head of Data Science bei SAP Custom Development. Der studierte Physiker und Mathematiker promovierte im Jahre 2006 und war seitdem für den Softwarekonzern mit Hauptsitz in Walldorf tätig. Dort baute Linde das Geschäft mit Dienstleistungen und kundenspezifischer Entwicklung rund um die Themen Prognose- und Optimierungsalgorithmen mit auf und leitet heute eine globale Data Science Practice. 

 Dr. Dirk Hecker ist Geschäftsführer der »Fraunhofer-Allianz Big Data«, einem Verbund von 28 Fraunhofer-Instituten zur branchenübergreifenden Forschung und Technologieentwicklung im Bereich Big Data. Außerdem leitet Dr. Hecker die Abteilung »Knowledge Discovery« am Fraunhofer-Institut für Intelligente Analyse- und Informationssysteme IAIS. Die Forschungsschwerpunkte der Abteilung liegen im Data Mining und Machine Learning. Darüber hinaus verantwortet Dr. Hecker das Data-Scientist-Qualifizierungsprogramm bei Fraunhofer und leitet die Arbeitsgruppe »Smart Cities« im »Smart Data Innovation Lab«. Herr Hecker ist in Mitglied der »Networked European Software and Services Initiative (NESSI)« und hat langjährige Erfahrung in der Leitung von Forschungs- und Industrieprojekten. Seine aktuellen Arbeitsschwerpunkte liegen in den Bereichen Big Data Analytics, Predictive Analytics und Deep Learning.
Dr. Dirk Hecker ist Geschäftsführer der »Fraunhofer-Allianz Big Data«, einem Verbund von 28 Fraunhofer-Instituten zur branchenübergreifenden Forschung und Technologieentwicklung im Bereich Big Data. Außerdem leitet Dr. Hecker die Abteilung »Knowledge Discovery« am Fraunhofer-Institut für Intelligente Analyse- und Informationssysteme IAIS. Die Forschungsschwerpunkte der Abteilung liegen im Data Mining und Machine Learning. Darüber hinaus verantwortet Dr. Hecker das Data-Scientist-Qualifizierungsprogramm bei Fraunhofer und leitet die Arbeitsgruppe »Smart Cities« im »Smart Data Innovation Lab«. Herr Hecker ist in Mitglied der »Networked European Software and Services Initiative (NESSI)« und hat langjährige Erfahrung in der Leitung von Forschungs- und Industrieprojekten. Seine aktuellen Arbeitsschwerpunkte liegen in den Bereichen Big Data Analytics, Predictive Analytics und Deep Learning.