
Big Data – Das Versprechen wurde eingelöst
Big Data tauchte als Buzzword meiner Recherche nach erstmals um das Jahr 2011 relevant in den Medien auf. Big Data wurde zum Business-Sprech der darauffolgenden Jahre. In der Parallelwelt der ITler wurde das Tool und Ökosystem Apache Hadoop quasi mit Big Data beinahe synonym gesetzt. Der Guardian verlieh Apache Hadoop mit seinem Konzept des Distributed Computing mit MapReduce im März 2011 bei den MediaGuardian Innovation Awards die Auszeichnung “Innovator of the Year”. Im Jahr 2015 erlebte der Begriff Big Data in der allgemeinen Geschäftswelt seine Euphorie-Phase mit vielen Konferenzen und Vorträgen weltweit, die sich mit dem Thema auseinandersetzten. Dann etwa im Jahr 2018 flachte der Hype um Big Data wieder ab, die Euphorie änderte sich in eine Ernüchterung, zumindest für den deutschen Mittelstand. Die große Verarbeitung von Datenmassen fand nur in ganz bestimmten Bereichen statt, die US-amerikanischen Tech-Riesen wie Google oder Facebook hingegen wurden zu Daten-Monopolisten erklärt, denen niemand das Wasser reichen könne. Big Data wurde für viele Unternehmen der traditionellen Industrie zur Enttäuschung, zum falschen Versprechen.
Von Big Data über Data Science zu AI
Einer der Gründe, warum Big Data insbesondere nach der Euphorie wieder aus der Diskussion verschwand, war der Leitspruch “Shit in, shit out” und die Kernaussage, dass Daten in großen Mengen nicht viel wert seien, wenn die Datenqualität nicht stimme. Datenqualität hingegen, wurde zum wichtigen Faktor jeder Unternehmensbewertung, was Themen wie Reporting, Data Governance und schließlich dann das Data Engineering mehr noch anschob als die Data Science.
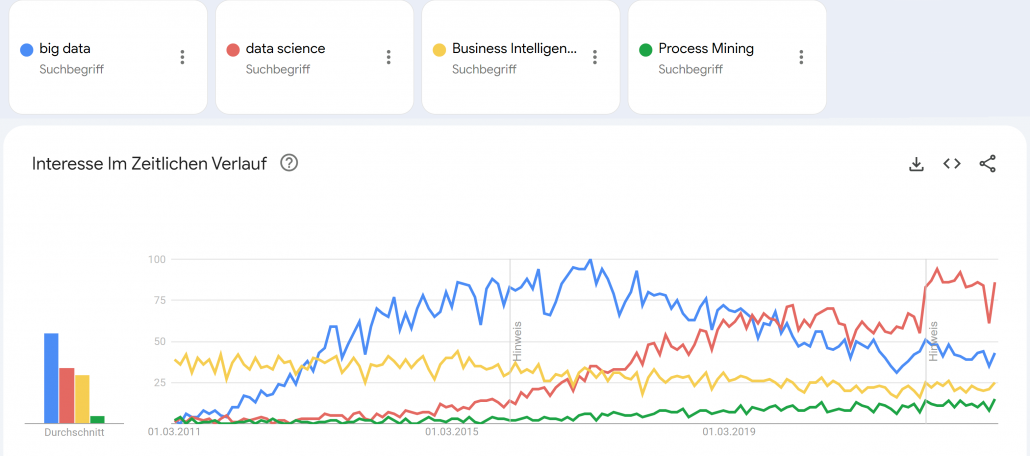
Google Trends – Big Data (blue), Data Science (red), Business Intelligence (yellow) und Process Mining (green). Quelle: https://trends.google.de/trends/explore?date=2011-03-01%202023-01-03&geo=DE&q=big%20data,data%20science,Business%20Intelligence,Process%20Mining&hl=de
Small Data wurde zum Fokus für die deutsche Industrie, denn “Big Data is messy!”1 und galt als nur schwer und teuer zu verarbeiten. Cloud Computing, erst mit den Infrastructure as a Service (IaaS) Angeboten von Amazon, Microsoft und Google, wurde zum Enabler für schnelle, flexible Big Data Architekturen. Zwischenzeitlich wurde die Business Intelligence mit Tools wie Qlik Sense, Tableau, Power BI und Looker (und vielen anderen) weiter im Markt ausgebaut, die recht neue Disziplin Process Mining (vor allem durch das deutsche Unicorn Celonis) etabliert und Data Science schloss als Hype nahtlos an Big Data etwa ab 2017 an, wurde dann ungefähr im Jahr 2021 von AI als Hype ersetzt. Von Data Science spricht auf Konferenzen heute kaum noch jemand und wurde hype-technisch komplett durch Machine Learning bzw. Artificial Intelligence (AI) ersetzt. AI wiederum scheint spätestens mit ChatGPT 2022/2023 eine neue Euphorie-Phase erreicht zu haben, mit noch ungewissem Ausgang.
Big Data Analytics erreicht die nötige Reife
Der Begriff Big Data war schon immer etwas schwammig und wurde von vielen Unternehmen und Experten schnell auch im Kontext kleinerer Datenmengen verwendet.2 Denn heute spielt die Definition darüber, was Big Data eigentlich genau ist, wirklich keine Rolle mehr. Alle zuvor genannten Hypes sind selbst Erben des Hypes um Big Data.
Während vor Jahren noch kleine Datenanalysen reichen mussten, können heute dank Data Lakes oder gar Data Lakehouse Architekturen, auf Apache Spark (dem quasi-Nachfolger von Hadoop) basierende Datenbank- und Analysesysteme, strukturierte Datentabellen über semi-strukturierte bis komplett unstrukturierte Daten umfassend und versioniert gespeichert, fusioniert, verknüpft und ausgewertet werden. Das funktioniert heute problemlos in der Cloud, notfalls jedoch auch in einem eigenen Rechenzentrum On-Premise. Während in der Anfangszeit Apache Spark noch selbst auf einem Hardware-Cluster aufgesetzt werden musste, kommen heute eher die managed Cloud-Varianten wie Microsoft Azure Synapse oder die agnostische Alternative Databricks zum Einsatz, die auf Spark aufbauen.
Die vollautomatisierte Analyse von textlicher Sprache, von Fotos oder Videomaterial war 2015 noch Nische, gehört heute jedoch zum Alltag hinzu. Während 2015 noch von neuen Geschäftsmodellen mit Big Data geträumt wurde, sind Data as a Service und AI as a Service heute längst Realität!
ChatGPT und GPT 4 sind King of Big Data
ChatGPT erschien Ende 2022 und war prinzipiell nichts Neues, keine neue Invention (Erfindung), jedoch eine große Innovation (Marktdurchdringung), die großes öffentliches Interesse vor allem auch deswegen erhielt, weil es als kostenloses Angebot für einen eigentlich sehr kostenintensiven Service veröffentlicht und für jeden erreichbar wurde. ChatGPT basiert auf GPT-3, die dritte Version des Generative Pre-Trained Transformer Modells. Transformer sind neuronale Netze, sie ihre Input-Parameter nicht nur zu Klasseneinschätzungen verdichten (z. B. ein Bild zeigt einen Hund, eine Katze oder eine andere Klasse), sondern wieder selbst Daten in ähnliche Gestalt und Größe erstellen. So wird aus einem gegeben Bild ein neues Bild, aus einem gegeben Text, ein neuer Text oder eine sinnvolle Ergänzung (Antwort) des Textes. GPT-3 ist jedoch noch komplizierter, basiert nicht nur auf Supervised Deep Learning, sondern auch auf Reinforcement Learning.
GPT-3 wurde mit mehr als 100 Milliarden Wörter trainiert, das parametrisierte Machine Learning Modell selbst wiegt 800 GB (quasi nur die Neuronen!)3.

ChatGPT basiert auf GPT-3.5 und wurde in 3 Schritten trainiert. Neben Supervised Learning kam auch Reinforcement Learning zum Einsatz. Quelle: openai.com
GPT-3 von openai.com war 2021 mit 175 Milliarden Parametern das weltweit größte Neuronale Netz der Welt.4
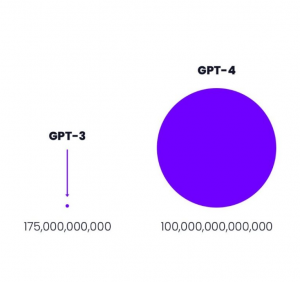
Größenvergleich: Parameteranzahl GPT-3 vs GPT-4 Quelle: openai.com
Der davor existierende Platzhirsch unter den Modellen kam von Microsoft mit “nur” 10 Milliarden Parametern und damit um den Faktor 17 kleiner. Das nun neue Modell GPT-4 ist mit 100 Billionen Parametern nochmal 570 mal so “groß” wie GPT-3. Dies bedeutet keinesfalls, dass GPT-4 entsprechend 570 mal so fähig sein wird wie GPT-3, jedoch wird der Faktor immer noch deutlich und spürbar sein und sicher eine Erweiterung der Fähigkeiten bedeuten.
Was Big Data & Analytics heute für Unternehmen erreicht
Auf Big Data basierende Systeme wie ChatGPT sollte es – der zuvor genannten Logik folgend – jedoch eigentlich gar nicht geben dürfen, denn die rohen Datenmassen, die für das Training verwendet wurden, konnten nicht im Detail auf ihre Qualität überprüft werden. Zum Einen mittelt die Masse an Daten die in ihnen zu findenden Fehler weitgehend raus, zum Anderen filtert Deep Learning selbst relevante Muster und unliebsame Ausreißer aus den Datenmassen heraus. Neuronale Netze, der Kern des Deep Learning, können durchaus als große Filter verstanden und erklärt werden.
Davon abgesehen, dass die neuen ChatBot-APIs von den Cloud-Providern Microsoft, Google und auch Amazon genutzt werden können, um Arbeitsprozesse und Kommunikation zu automatisieren, wird Big Data heute in vielen Unternehmen dazu eingesetzt, um Unternehmens-/Finanzkennzahlen auszuwerten und vorherzusagen, um Produktionsqualität zu überwachen, um Maschinen-Sensordaten mit den Geschäftsdaten aus ERP-, MES- und CRM-Systemen zu verheiraten, um operative Prozesse über mehrere IT-Systeme hinweg zu rekonstruieren und auf Schwachstellen hin zu untersuchen und um Schlussendlich auch den weiteren Datenhunger zu stillen, z. B. über Text-Extraktion aus Webseiten (Intelligence Gathering), die mit NLP und Computer Vision mächtiger wird als je zuvor.
Big Data hält sein Versprechen dank AI
Die frühere Enttäuschung aus Big Data resultierte aus dem fehlenden Vermittler zwischen Big Data (passive Daten) und den Applikationen (z. B. Industrie 4.0). Dieser Vermittler ist der aktive Part, die AI und weiterführende Datenverarbeitung (z. B. Lakehousing) und Analysemethodik (z. B. Process Mining). Davon abgesehen, dass mit AI über Big Data bereits in Medizin und im Verkehrswesen Menschenleben gerettet wurden, ist Big Data & AI längst auch in gewöhnlichen Unternehmen angekommen. Big Data hält sein Versprechen für Unternehmen doch noch ein und revolutioniert Geschäftsmodelle und Geschäftsprozesse, sichert so Wettbewerbsfähigkeit. Zumindest, wenn Unternehmen sich auf diesen Weg tatsächlich einlassen.
Quellen:
- Edd Dumbill: What is big data? An introduction to the big data landscape. (Memento vom 23. April 2014 im Internet Archive) auf: strata.oreilly.com.
↑ - Fergus Gloster: Von Big Data reden aber Small Data meinen. Computerwoche, 1. Oktober 2014↑
- Bussler, Frederik (July 21, 2020). “Will GPT-3 Kill Coding?”. Towards Data Science. Retrieved August 1, 2020.2022↑
- developer.nvidia.com, 1. Oktober 2014↑







Leave a Reply
Want to join the discussion?Feel free to contribute!