process.science stellt neues Release vor
Anzeige
Der Process Mining Tool-Anbieter process.science stellt ein neues Release vor
process.science, Spezialist in der Entwicklung von Process Mining Plugins für BI-Systeme, stellt seine überarbeitet Version ihres Produkts ps4pbi vor. Dem erweiterten Plugin für Microsoft Power BI spendiert process.science die folgenden Verbesserungen, welche in Kürze auch für ps4qlk, dem entsprechenden Plugin für Qlik Sense verfügbar sein werden:
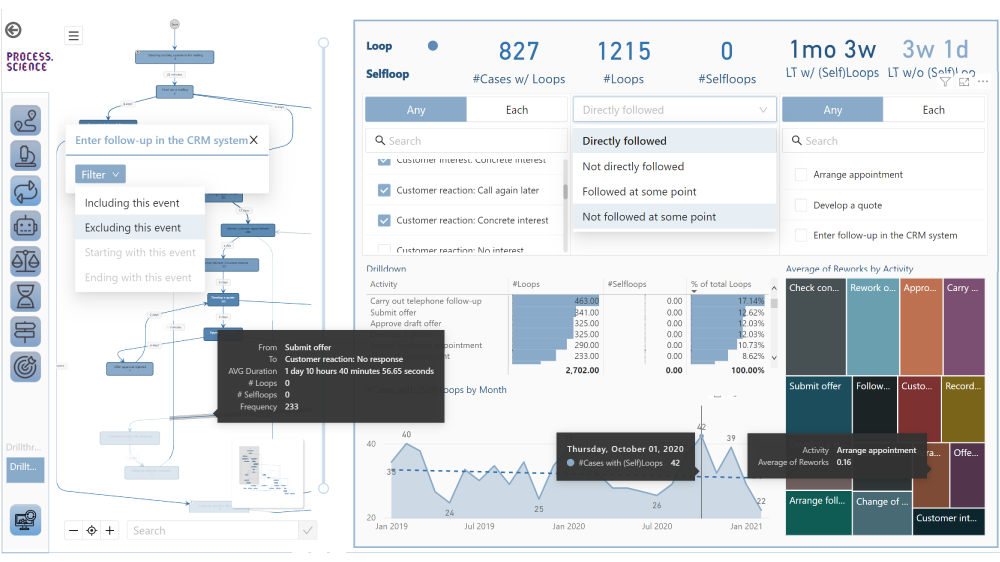
- 3x schnellere Performance: Durch die Verbesserung der Graph-Bibliothek wurde die Geschwindigkeit des Graph-Aufbaus um ca. 300% gesteigert. Das macht sich insbesondere bei komplexen Prozessen bemerkbar
- Navigator-Fenster: Für eine bessere Übersicht in komplexen Graphen wurde ein Übersichtsfenster hinzugefügt, in welchem immer der gesamte Graph und die jeweilige Position des betrachteten Bereichs innerhalb des Gesamtprozesses angezeigt wird
- Aktivitäten Legende: Hiermit lassen sich Aktivitäten bestimmten Kategorien zuordnen und farblich unterschiedlich markieren, beispielsweise in welchem Quellsystem eine Aktivität ausgeführt wurde
- Activity Drillthrough: Damit ist es möglich, gesetzte Filter auf gewählte Aktivitäten mit in andere Dashboards zu nehmen
- Value Color Scale: Aktivitätenwerte können farblich markiert freiwählbaren Gruppierungen zugeordnet werden, was die Übersicht auf den ersten Blick erleichtert
process.science Process Mining | Power BI Plugin
Process Mining ist eine Technik zur Geschäftsdatenanalyse. Die dazu eingesetzte Software birgt die ohnehin in den Quellsystemen vorhanden Daten und visualisiert sie zu einem Prozessgraphen. Ziel ist es ein kontinuierliches Monitoring in Echtzeit zu gewährleisten, um so Optimierungsmaßnahmen für Prozesse zu identifizieren, diese zu simulieren und nach der Implementierung kontinuierlich bewerten zu können.
Die Process Mining Werkzeuge von process.science werden direkt in Microsoft Power BI und Qlik Sense integriert. Ein entsprechendes Plugin für Tableau ist bereits in Entwicklung. Es handelt sich also nicht um eine komplizierte Insellösung, die zusätzlich zu bestehenden Systemen eingerichtet werden muss und das vorhandene Know-how zu dem im Unternehmen bereits implementierten BI-System sowie der bestehenden Infrastrukturrahmen können mit adaptiert werden.
Die Implementierung in die BI-Systeme hat keinerlei Einfluss auf das Tagesgeschäft und birgt absolut kein Risiko von Systemausfällen, da process.science nicht in die Programme und die Warenwirtschaft eingreift, sondern das jeweilige Business Intelligence Tool um die Prozessperspektive mit diversen Funktionalitäten erweitert.
Ansprechpartner für Anfragen:
process.science GmbH & Co. KG
process.science stellt neues Release vor
Tel.: + 49 (231) 5869 2868
E-Mail: ga@process.science
https://de.process.science/





