
Machine Learning vs Deep Learning – Wo liegt der Unterschied?
Machine Learning gehört zu den Industrie-Trends dieser Jahre, da besteht kein Zweifel. Oder war es Deep Learning? Oder Artificial Intelligence? Worin liegt da eigentlich der Unterschied? Dies ist Artikel 1 von 6 der Artikelserie –Einstieg in Deep Learning.
Machine Learning
Maschinelles Lernen (ML) ist eine Sammlung von mathematischen Methoden der Mustererkennung. Diese Methoden erkennen Muster beispielsweise durch bestmögliche, auf eine bestmögliche Entropie gerichtete, Zerlegung von Datenbeständen in hierarchische Strukturen (Entscheidungsbäume). Oder über Vektoren werden Ähnlichkeiten zwischen Datensätzen ermittelt und daraus trainiert (z. B. k-nearest-Neighbour, nachfolgend einfach kurz: k-nN) oder untrainiert (z.B. k-Means) Muster erschlossen.
Algorithmen des maschinellen Lernens sind tatsächlich dazu in der Lage, viele alltägliche oder auch sehr spezielle Probleme zu lösen. In der Praxis eines Entwicklers für Machine Learning stellen sich jedoch häufig Probleme, wenn es entweder zu wenige Daten gibt oder wenn es zu viele Dimensionen der Daten gibt. Entropie-getriebene Lern-Algorithmen wie Entscheidungsbäume werden bei vielen Dimensionen zu komplex, und auf Vektorräumen basierende Algorithmen wie der k-nächste-Nachbarn-Algorithmus sind durch den Fluch der Dimensionalität in ihrer Leistung eingeschränkt.
Der Fluch der Dimensionalität
Datenpunkte sind in einem zwei-dimensionalen Raum gut vorstellbar und auch ist es vorstellbar, das wir einen solchen Raum (z. B. ein DIN-A5-Papierblatt) mit vielen Datenpunkten vollschreiben. Belassen wir es bei der Anzahl an Datenpunkten, nehmen jedoch weitere Dimensionen hinzu (zumindest die 3. Dimension können wir uns noch gut vorstellen), werden die Abstände zwischen den Punkten größer. n-dimensionale Räume können gewaltig groß sein, so dass Algorithmen wie der k-nN nicht mehr gut funktionieren (der n-dimensionale Raum ist einfach zu leer).
Auch wenn es einige Konzepte zum besseren Umgang mit vielen Dimensionen gibt (z. B. einige Ideen des Ensemble Learnings)
Feature Engineering
Um die Anzahl an Dimensionen zu reduzieren, bedienen sich Machine Learning Entwickler statistischer Methoden, um viele Dimensionen auf die (wahrscheinlich) nützlichsten zu reduzieren: sogenannte Features. Dieser Auswahlprozess nennt sich Feature Engineering und bedingt den sicheren Umgang mit Statistik sowie idealerweise auch etwas Fachkenntnisse des zu untersuchenden Fachgebiets.
 Bei der Entwicklung von Machine Learning für den produktiven Einsatz arbeiten Data Scientists den Großteil ihrer Arbeitszeit nicht an der Feinjustierung ihrer Algorithmen des maschinellen Lernens, sondern mit der Auswahl passender Features.
Bei der Entwicklung von Machine Learning für den produktiven Einsatz arbeiten Data Scientists den Großteil ihrer Arbeitszeit nicht an der Feinjustierung ihrer Algorithmen des maschinellen Lernens, sondern mit der Auswahl passender Features.
Deep Learning
Deep Learning (DL) ist eine Disziplin des maschinellen Lernes unter Einsatz von künstlichen neuronalen Netzen. Während die Ideen für Entscheidungsbäume, k-nN oder k-Means aus einer gewissen mathematischen Logik heraus entwickelt wurden, gibt es für künstliche neuronale Netze ein Vorbild aus der Natur: Biologische neuronale Netze.
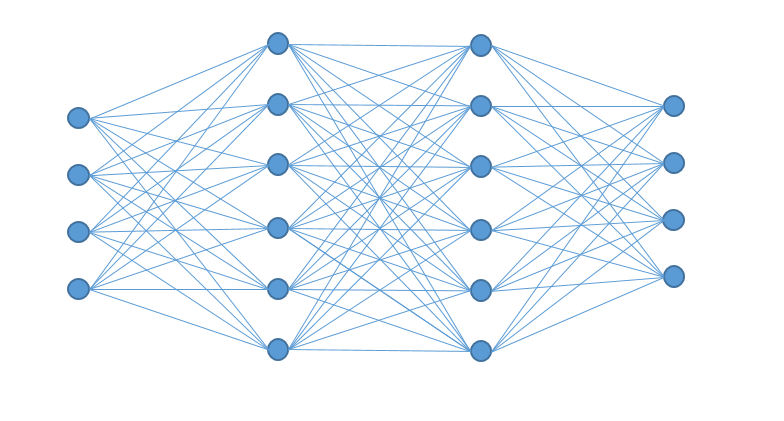
Prinzip-Darstellung eines künstlichen neuronalen Netzes mit zwei Hidden-Layern zwischen einer Eingabe- und Ausgabe-Schicht.
Wie künstliche neuronale Netze im Detail funktionieren, erläutern wir in den nächsten zwei Artikeln dieser Artikelserie, jedoch vorab schon mal so viel: Ein Eingabe-Vektor (eine Reihe von Dimensionen) stellt eine erste Schicht dar, die über weitere Schichten mit sogenannten Neuronen erweitert oder reduziert und über Gewichtungen abstrahiert wird, bis eine Ausgabeschicht erreicht wird, die einen Ausgabe-Vektor erzeugt (im Grunde ein Ergebnis-Schlüssel, der beispielsweise eine bestimmte Klasse ausweist: z. B. Katze oder Hund). Durch ein Training werden die Gewichte zwischen den Neuronen so angepasst, dass bestimmte Eingabe-Muster (z. B. Fotos von Haustieren) immer zu einem bestimmten Ausgabe-Muster führen (z. B. “Das Foto zeigt eine Katze”).
Der Vorteil von künstlichen neuronalen Netzen ist die sehr tiefgehende Abstraktion von Zusammenhängen zwischen Eingabe-Daten und zwischen den abstrahierten Neuronen-Werten mit den Ausgabe-Daten. Dies geschieht über mehrere Schichten (Layer) der Netze, die sehr spezielle Probleme lösen können. Aus diesen Tatsachen leitet sich der übergeordnete Name ab: Deep Learning
Deep Learning kommt dann zum Einsatz, wenn andere maschinelle Lernverfahren an Grenzen stoßen und auch dann, wenn auf ein separates Feature Engineering verzichtet werden muss, denn neuronale Netze können über mehrere Schichten viele Eingabe-Dimensionen von selbst auf die Features reduzieren, die für die korrekte Bestimmung der Ausgabe notwendig sind.
Convolutional Neuronal Network
Convolutional Neuronal Networks (CNN) sind neuronale Netze, die vor allem für die Klassifikation von Bilddaten verwendet werden. Sie sind im Kern klassische neuronale Netze, die jedoch eine Faltungs- und eine Pooling-Schicht vorgeschaltet haben. Die Faltungsschicht ließt den Daten-Input (z. B. ein Foto) mehrfach hintereinander, doch jeweils immer nur einen Ausschnitt daraus (bei Fotos dann einen Sektor des Fotos), die Pooling-Schicht reduzierte die Ausschnittsdaten (bei Fotos: Pixel) auf reduzierte Informationen. Daraufhin folgt das eigentliche neuronale Netz.
CNNs sind im Grunde eine spezialisierte Form von künstlichen neuronalen Netzen, die das Feature-Engineering noch geschickter handhaben.
Deep Autoencoder
Gegenwärtig sind die meisten künstlichen neuronalen Netze ein Algorithmen-Modell für das überwachte maschinelle Lernen (Klassifikation oder Regression), jedoch kommen sie auch zum unüberwachten Lernen (Clustering oder Dimensionsreduktion) zum Einsatz, die sogenannten Deep Autoencoder.
Deep Autoencoder sind neuronale Netze, die im ersten Schritt eine große Menge an Eingabe-Dimensionen auf vergleichsweise wenige Dimensionen reduzieren. Die Reduktion (Encoder) erfolgt nicht abrupt, sondern schrittweise über mehrere Schichten, die reduzierten Dimensionen werden zum Feature-Vektor. Daraufhin kommt der zweite Teil des neuronalen Netzes zum Einsatz: Die reduzierten Dimensionen werden über weitere Schichten wieder erweitert, die ursprünglichen Dimensionen als abstrakteres Modell wieder rekonstruiert (Decoder). Der Sinn von Deep Autoencodern sind abstrakte Ähnlichkeitsmodelle zu erstellen. Ein häufiges Einsatzgebiet sind beispielsweise das maschinelle Identifizieren von ähnlichen Bildern, Texten oder akkustischen Signalmustern.
Artificial Intelligence
Artificial Intelligence (AI) oder künstliche Intelligenz (KI) ist ein wissenschaftlicher Bereich, der das maschinelle Lernen beinhaltet, jedoch noch weitere Bereiche kennt, die für den Aufbau einer KI von Nöten sind. Eine künstliche Intelligenz muss nicht nur Lernen, sie muss auch Wissen effizient abspeichern, einordnen bzw. sortieren und abrufen können. Sie muss ferner über eine Logik verfügen, wie sie das Wissen und das Gelernte einsetzen muss. Denken wir an biologische Intelligenzen, ist es etwa nicht so, dass jegliche Fähigkeiten erlernt wurden, einige sind mit der Geburt bereits ausgebildet oder liegen als sogenannter Instinkt vor.
Ein einzelner Machine Learning Algorithmus würde wohl kaum einen Turing-Test bestehen oder einen Roboter komplexe Aufgaben bewältigen lassen. Daher muss eine künstliche Intelligenz weit mehr können, als bestimmte Dinge zu erlernen. Zum wissenschaftlichen Gebiet der künstlichen Intelligenz gehören zumindest:
- Machine Learning (inkl. Deep Learning und Ensemble Learning)
- Mathematische Logik
- Aussagenlogik
- Prädikatenlogik
- Default-Logik
- Modal-Logik
- Wissensbasierte Systeme
- relationale Algebra
- Graphentheorie
- Such- und Optimierungsverfahren:
- Gradientenverfahren
- Breitensuche & Tiefensuche

AI(ML(DL))










Trackbacks & Pingbacks
[…] Deep Autoencoder sind neuronale Netze, die im ersten Schritt eine große Menge an Eingabe-Dimensionen auf vergleichsweise wenige Dimensionen reduzieren. Die Reduktion (Encoder) erfolgt nicht abrupt, sondern schrittweise über mehrere Schichten, die reduzierten Dimensionen werden zum Feature-Vektor. Daraufhin kommt der zweite Teil des neuronalen Netzes zum Einsatz: Die reduzierten Dimensionen werden über weitere Schichten wieder erweitert, die ursprünglichen Dimensionen als abstrakteres Modell wieder rekonstruiert (Decoder). Der Sinn von Deep Autoencodern sind abstrakte Ähnlichkeitsmodelle zu erstellen. Ein häufiges Einsatzgebiet sind beispielsweise das maschinelle Identifizieren von ähnlichen Bildern, Texten oder akkustischen Signalmustern — Weiterlesen data-science-blog.com/de/blog/2018/05/14/machine-learning-vs-deep-learning-wo-liegt-der-unterschied/ […]
[…] data-science-blog.com/de/blog/2018/05/14/machine-learning-vs-deep-learning-wo-liegt-der-unterschied/ […]
Leave a Reply
Want to join the discussion?Feel free to contribute!