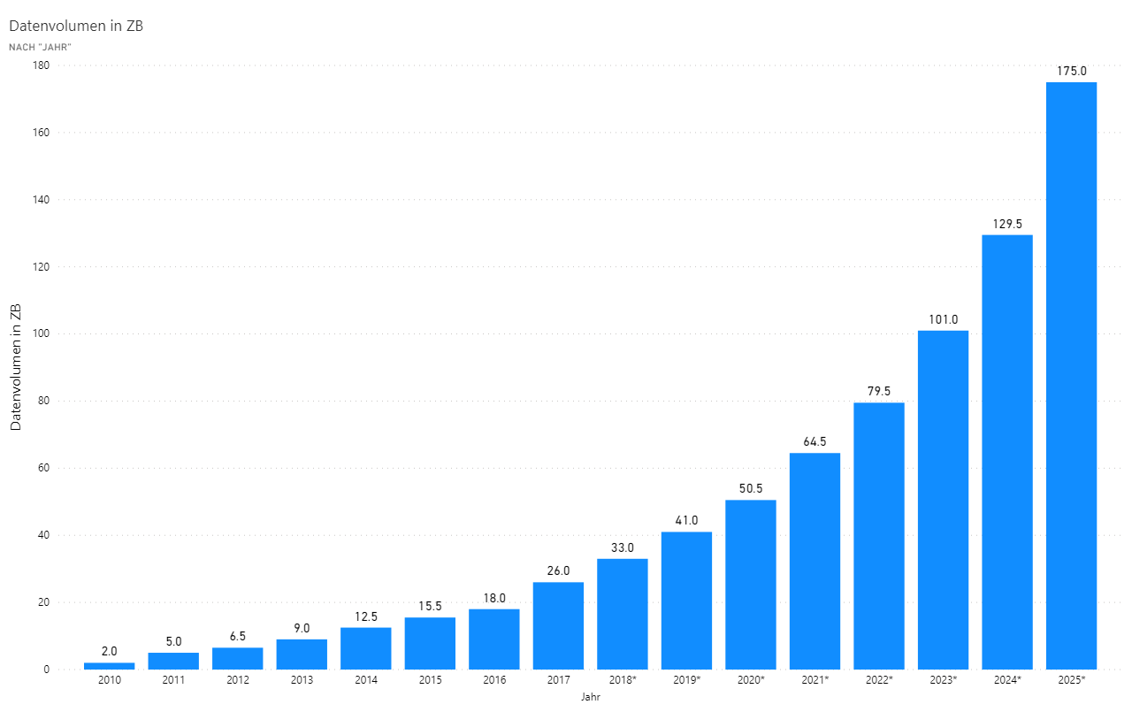
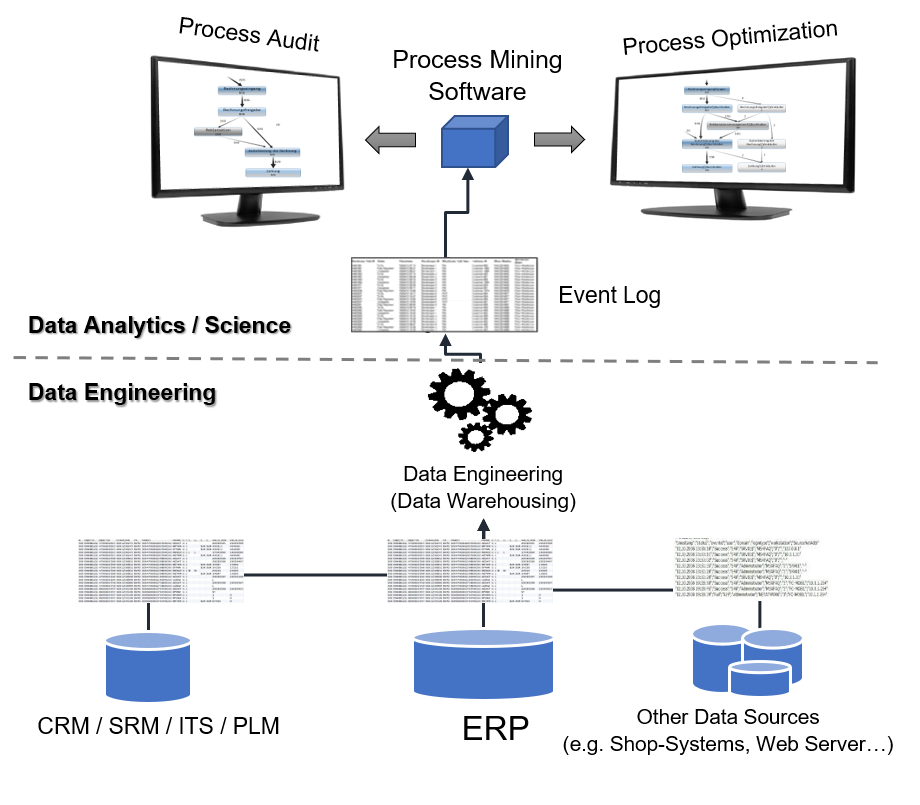
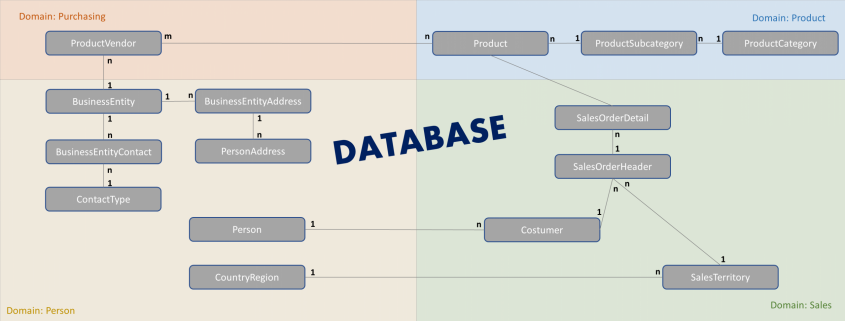
ERP, CRM, FiBu – täglich durchlaufen unzählige Geschäftsprozesse die IT-Systeme von Unternehmen. Es entstehen Ströme aus Massendaten, die am Ende in der Finanzbuchhaltung münden und dort automatisch auf Konten erfasst werden.

Mit auditbee können Wirtschaftsprüfer diese Datenströme wirtschaftlich und einfach analysieren. auditbee integriert die Datenanalyse in den gesamten Prüfungsverlauf und macht Schluss mit ausgedruckten Kontenblättern, komplizierten Datenabfragen sowie dem Zufall bei der Fehlersuche.

Wirtschaftsprüfer und die Nadel im Heuhaufen
Die Finanzdaten von Unternehmen sind wichtig für viele Adressaten – Gesellschafter, Banken, Kunden, etc. Deswegen ist es die gesetzliche Aufgabe des Wirtschaftsprüfers, wesentliche Fehler in der Buchhaltung und dem Jahresabschluss aufzudecken. Dazu überprüft er einzelne Sachverhalte mit hohem Fehlerrisiko und Prozesse, bei denen systematische Fehler in Summe von Bedeutung für den Abschluss sein können (IDW PS 261 n.F.).
Die Prüfung gleicht jedoch der Suche nach der Nadel im Heuhaufen!
Fehler sind menschlich und können passieren. Das Problem ist, dass sie im gesamten Datenhaufen gut verborgen sein können – und je größer dieser ist, desto schwieriger wird die Suche. Neben Irrtümern können Fehler auch durch absichtliche Falschdarstellungen und bewusste Täuschungen entstehen. Um solche dolosen Handlungen festzustellen, hat der Prüfer häufig tief im Datenhaufen zu graben, weil sie gut versteckt sind. Deswegen sind auch nach international anerkannten Prüfungsgrundsätzen die Journalbuchungen zu analysieren (ISA 240.32).
Die Suche nach dem Fehler
Noch vor einigen Jahren bestand die Prüfung hauptsächlich darin, eine Vielzahl an bewusst ausgewählten Belegen als Stichprobe in Papier einzusehen und mit den Angaben in der Buchhaltung abzustimmen – analog mit Stift und Textmarker auf ausgedruckten Kontenblättern. Dafür mussten Unmengen Belege kopiert und Kontenblätter ausgedruckt werden. Das hat nicht nur Papier verschwendet, sondern auch sehr viel der begrenzten Zeit gekostet. Zu allen Übels mussten die so entstandenen Prüfungsakten noch Kistenweise zum Mandanten hin- und wieder zurück transportiert werden. Es gab keine digitale Alternative.
Heute haben viele Unternehmen ihre Belege digitalisiert und setzen Dokumentenmanagement-systeme ein. Eine enorme Arbeitserleichterung für den Prüfer, der jetzt alle Belege digital einsehen kann. Weil der Datenhaufen jedoch gleichzeitig immer weiter wächst, entstehen neue Herausforderungen. Die Datenmenge als Grundgesamtheit wirkt sich beispielsweise auf den Umfang einer Stichprobe aus. Um Massendaten aus automatisierten Geschäftsprozessen wirtschaftlich überprüfen zu können, sind daher Datenanalysen unerlässlich.
Mit dem BMF-Schreiben „Grundsätze zum Datenzugriff und zur Prüfbarkeit digitaler Unterlagen – GDPdU“ wurde im Jahr 2001 der Grundstein für die Datenanalyse in der Prüfung gelegt. Der Nachfolger „Grundsätze zur ordnungsmäßigen Führung und Aufbewahrung von Büchern, Aufzeichnungen und Unterlagen in elektronischer Form sowie zum Datenzugriff – GoBD“ wurde 2014 veröffentlicht. Mit den BMF-Schreiben hat eine gewisse Normierung der steuerlich relevanten Daten (GDPdU/GoBD-Daten) durch die Finanzverwaltung stattgefunden. Diese lassen sich aus jeder Buchhaltungssoftware extrahieren und umfassen sämtliche Journalbuchungen.
Mit Datenanalysen kann der Prüfer nicht nur das Unternehmen und dessen Entwicklung besser verstehen. Dank der GDPdU/GoBD-Daten können Fehler mit auditbee viel leichter gefunden werden, weil sich der Prüfer jeden Halm im Datenhaufen ganz genau ansehen, Auffälligkeiten erkennen und hinterfragen kann. Mit der Analyse und Risikobeurteilung wird zudem die Belegprüfung deutlich reduziert, weil sich der Prüfer bei der Auswahl auf auffällige und risikobehaftete Daten beschränken kann.
Integration der Datenanalyse in die Prüfung – Spezialisten oder Self-Service
Das Tagesgeschäft des Wirtschaftsprüfers ist sehr vielfältig – Prüfung, Unternehmensbewertung, Steuerberatung. Deshalb erfolgt die Datenanalyse regelmäßig durch Spezialisten. Das sind IT-affine Mitarbeiter innerhalb der Kanzlei, die sich im Rahmen von Projekten selbständig weitergebildet oder eine Qualifikation als CISA bzw. IT Auditor haben.
Der Spezialist überprüft die Journalbuchungen (Journal Entry Tests) mit Excel oder einer Analysesoftware für Prüfer (DATEV Datenanalyse, IDEA, ACL). Oft ist er aber nicht mehr an der weiteren Prüfung beteiligt. Stattdessen führt der Prüfer mit seinen Assistenten als Team vor Ort die Hauptprüfung durch. Dabei werden häufig Konten erneut für die Belegauswahl in Excel gezogen. Das führt nicht nur zu Medienbrüchen, sondern erhöht auch die Wahrscheinlichkeit für Doppelarbeit, Fehler und Missverständnisse.
Neben alten Gewohnheiten und Zeitdruck ist die Analysesoftware oft selbst ein Grund, weshalb die Datenanalyse in der Praxis selten in die Prüfung integriert ist. Schließlich erfordern die Softwarelösungen einiges an IT-Kenntnis in der Einrichtung und Bedienung. Zudem ist die Interpretation von überwiegend in Tabellen dargestellten Daten schwierig und umständlich.
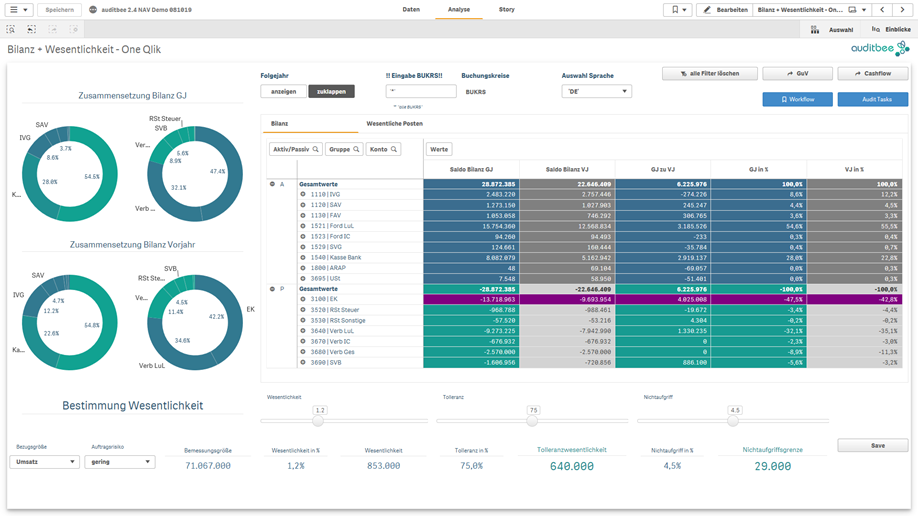
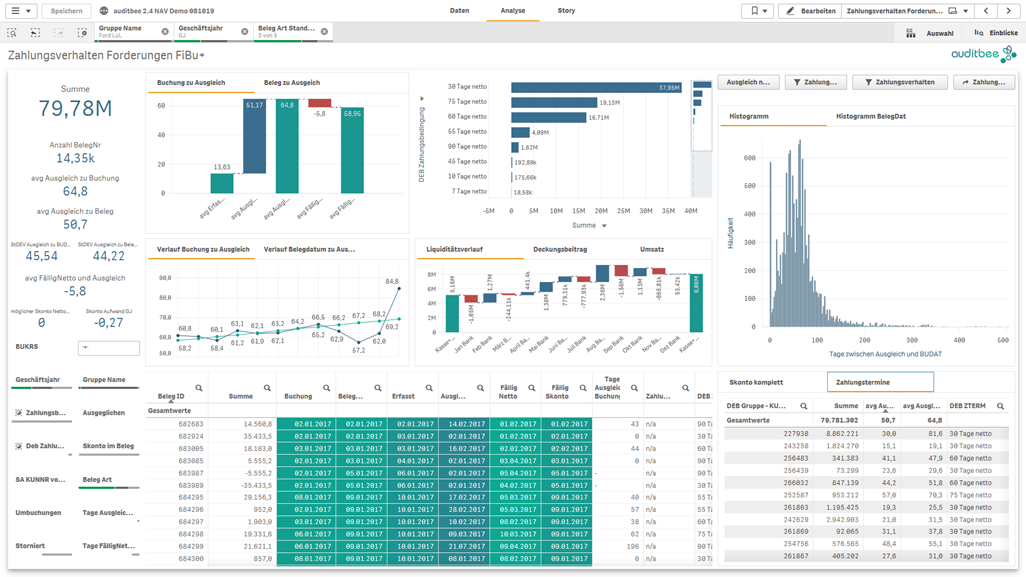
Mit auditbee als vorbereitete Dashboard Lösung auf Basis von Qlik Sense kann jeder im Team seine Daten selbst analysieren. Damit wird die Datenanalyse in die Prüfung integriert und kann ihr volles Potential entfalten.
auditbee als Self-Service BI-Lösung lässt sich so einfach bedienen, dass das Prüfungsteam nicht mehr von einzelnen Spezialisten abhängig ist. Damit aber nicht jeder bei 0 anfängt, werden die Daten bereits vom auditbee Team als Service in die BI-Software Qlik Sense geladen und abgestimmt. Zudem sind bereits verschiedene Dashboards zur Analyse eingerichtet. Der einzelne Anwender kann sich mit auditbee Daten und Kennzahlen ansehen, ohne eine einzige Formel eingeben zu müssen. Die Navigation und das dynamische Filtern der Daten im gesamten Dashboard erfolgt mit der Maus und das nahezu in Echtzeit. Anstatt von Abfragen mit langen Ladezeiten und Duplizierung der Daten können diese sofort im gesamten auditbee Modell nach unterschiedlichen Dimensionen (mehrdimensional) analysiert werden.
Mit auditbee zur strukturierten Belegauswahl
Bei der traditionellen bewussten Auswahl sucht sich der Prüfer Belege nach eigenem Ermessen anhand der Informationen auf dem Kontoblatt aus. Das sind regelmäßig Betrag, Buchungsdatum oder Buchungstext. Diese Methode ist relativ einseitig, eindimensional und vorhersehbar, weil vom Prüfer eher größere Beträge oder auffällige Texte ausgewählt werden. Dadurch kann es sein, dass absichtliche Falschdarstellungen und Irrtümer bei betragsmäßig kleineren Belegen nicht in die Stichprobe einbezogen werden und somit ungeprüft bleiben.
Zufalls- sowie statistische Auswahlverfahren (u.a. Monetary Unit Sampling) können wegen der Schwächen der traditionellen Methode eine Alternative sein. Doch auch sie haben einen relevanten Nachteil. Der Umfang der Stichprobe ist oftmals sehr hoch, um ein hinreichendes Signifikanzniveau (Alpha 0,05) zu erreichen. Ein Grund für den Prüfer, sich möglicherweise doch für die bewusste Auswahl zu entscheiden, um die Zeit für Belegabstimmungen zu verkürzen.
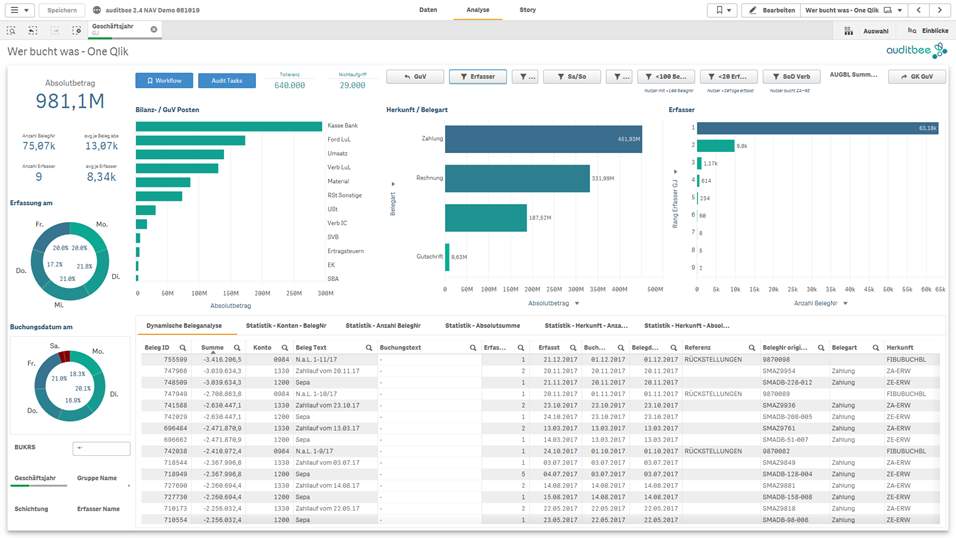
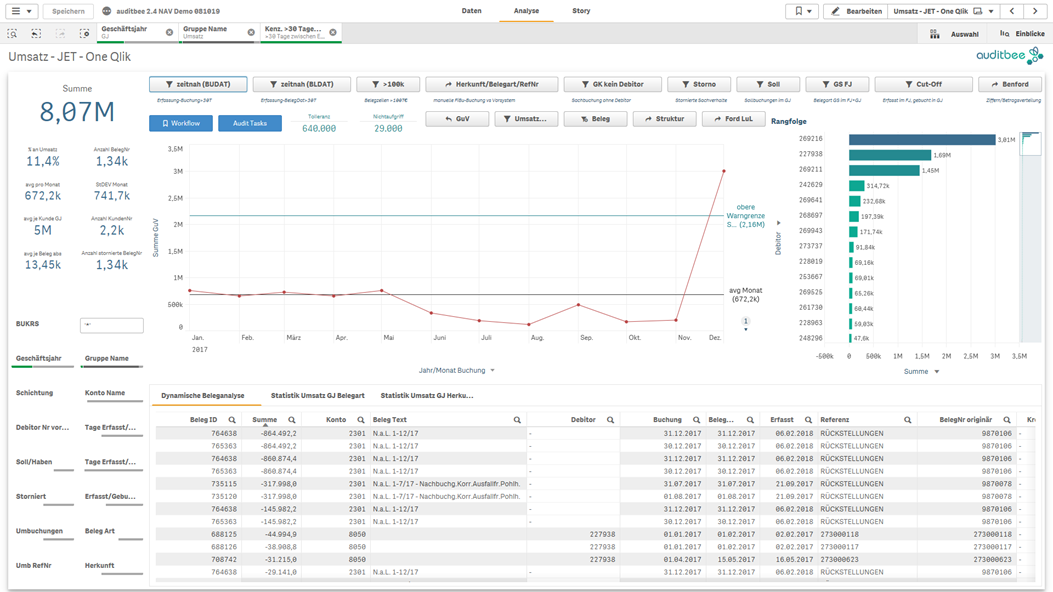
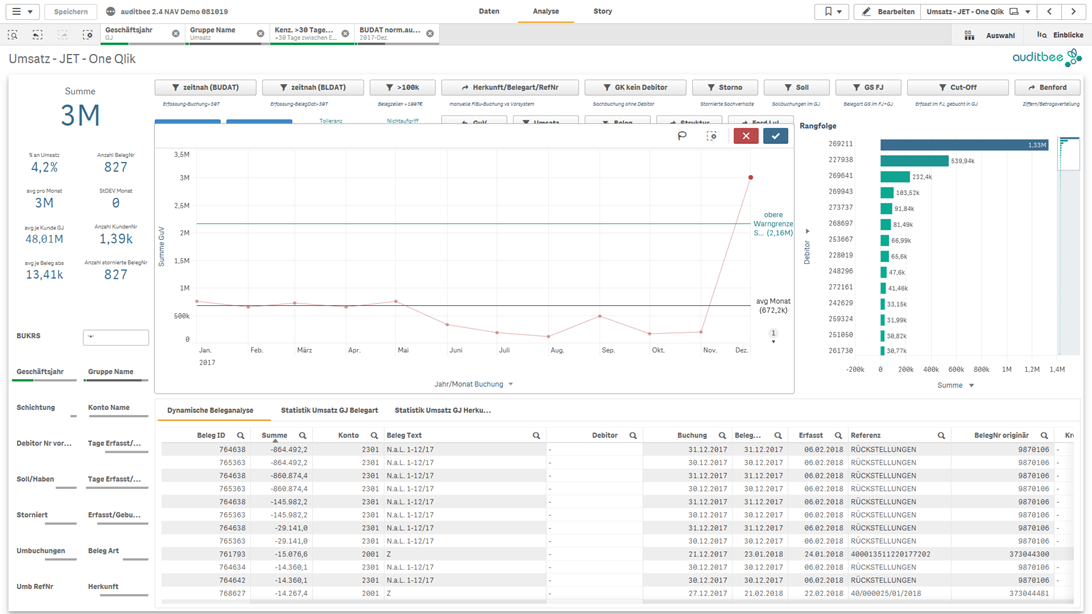
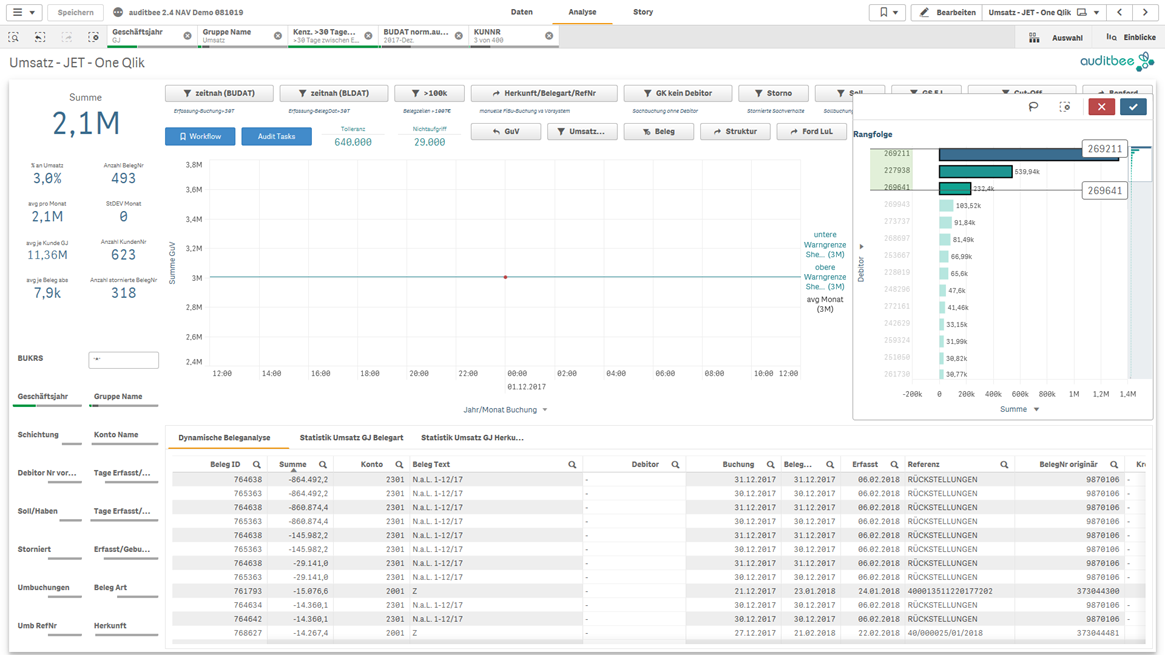
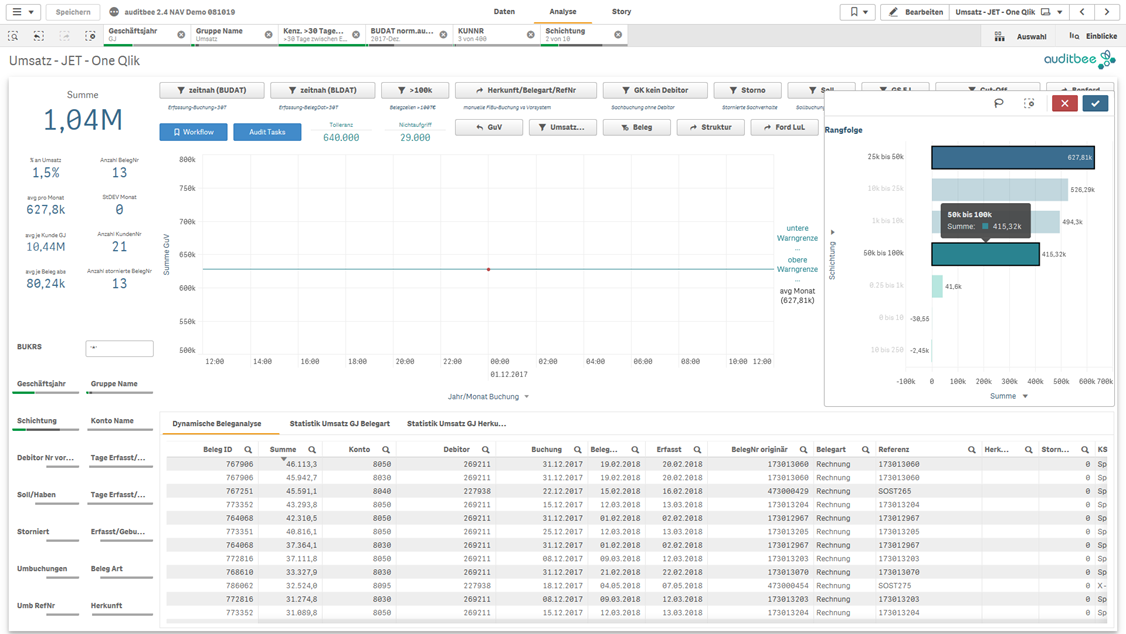
Durch die Verbindung sämtlicher FiBu-Daten und der Darstellung weiterer Dimensionen – Referenz, Beleg Art, Erfassungsdatum, Debitor, etc. – ermöglicht auditbee dem Prüfer eine dritte Methode. Bei der strukturierten Belegauswahl fokussiert sich der Prüfer auf Auffälligkeiten und wählt seine Stichprobe aus einer deutlich kleineren Zahl an Belegen bewusst oder per Zufall aus.
Der Prüfer analysiert nicht alles auf einmal, sondern betrachtet nur solche Daten, die aus Sicht des Themas und der zu prüfenden Frage relevant sind. Beispiel: Es werden nur die Daten im Umsatzbereich betrachtet, die das Merkmal „nicht zeitnah erfasst“ aufweisen. Ausgehend von der Frage kategorisiert der Prüfer die Daten nach der Höhe des Fehlerrisikos (Risikobeurteilung nach IDW PS 261 n.F.). Beispielsweise können automatisierte Buchungen ein geringes Fehlerrisiko aufweisen, Sachbuchungen oder Buchungen bestimmter Mitarbeiter dagegen ein höheres. Nur noch Belege mit höherem Risiko sowie andere Auffälligkeiten ergründet der Prüfer weiter im Detail. Hierzu filtert er die Daten anhand der auffälligen Dimensionen (Erfasser, Debitor, Monat, etc.). Am Ende bleiben nur noch wenige auffällige Datensätze übrig, aus der der Prüfer seine Stichprobe auswählt.
Bezogen auf die Nadel im Heuhaufen zeigen die 3 Methoden folgendes Bild.
Methode 1: Der Prüfer trägt nur die großen Strohalme von der Oberfläche ab, um zu sehen, ob darunter die Nadel verborgen ist (traditionelle Belegauswahl anhand des Kontoblattes).
Methode 2: Der Prüfer greift an verschiedenen Stellen in den Heuhaufen hinein, um per Zufall die Nadel zu finden (statistische Zufallsauswahlverfahren).
Methode 3: Der Prüfer sieht sich den Heuhaufen erst genau an, ob irgendwelche Stellen durchgewühlt aussehen (Auffälligkeiten), hier trägt er den Teil ab (Filtern der auffälligen Daten) und durchsucht systematisch den kleinen Haufen (strukturierte Auswahl).

Dies ist Teil 2/2 des Artikels, lesen Sie hier den zweiten Artikel Wie Wirtschaftsprüfer mit auditbee die Nadel im Heuhaufen finden – Teil 2/2.

 Direct link to the PDF: https://data-science-blog.com/de/wp-content/uploads/sites/5/2021/12/Infographic_Data_Visualization_Infographic_DATANOMIQ.pdf
Direct link to the PDF: https://data-science-blog.com/de/wp-content/uploads/sites/5/2021/12/Infographic_Data_Visualization_Infographic_DATANOMIQ.pdf