Process Mining mit MEHRWERK – Artikelserie
Dieser Artikel der Artikelserie Process Mining Tools beschäftigt sich mit dem Anbieter MEHRWERK. Das im Jahr 2008 gegründete Unternehmen, heute geführt durch drei Geschäftsführer, bietet Business Intelligence als Beratung und Dienstleistung rund um die Produkte des BI-Software-Anbieters QlikTech an. Rund zehn Jahre später, 2018, stieg das Unternehmen auch als Teil-Software-Anbieter in Process Mining ein. MEHRWERK ProcessMining, kurz MPM, ist einen Process Mining Lösung auf der Basis des weit verbreiteten BI-Tools Qlik Sense.
| Lösungspakete: | Standard-Lizenz |
| Zielgruppe: | Für mittel- und große Unternehmen |
| Datenquellen: | Beliebig über Standard-Konnektoren von Qlik Sense |
| Datenvolumen: | Unlimitierte Datenmengen |
| Architektur: | On-Premise, Cloud oder Multi-Cloud |
Für den Einsatz von MEHRWERK ProcessMining wird Qlik Sense Enterprise benötigt, welches sowohl On-Premise auf unternehmenseigenen Windows-Servern direkt installiert werden kann, über Kubernetes via Container ebenfalls On-Premise oder in sowie auch noch einfacher direkt in der Qlik Cloud oder aus Datenschutzgründen in Verbindung mit der Hochskalierbarkeit der Cloud als hybrides Deployment.
Bedienbarkeit und Anpassungsfähigkeit der Analysen
Die Beurteilung der Bedienbarkeit ist nahezu vollständig abhängig von der Einschätzung zur Bedienbarkeit von Qlik Sense, da MPM auf diesem gängigen BI-Tool basiert. Im Wording von Qlik Sense arbeiten Developer in einem Hub und erstellen Apps, die ein oder mehrere Worksheets (Arbeitsblätter) umfassen können, welche horizontal durchgeblättert werden können. Die Qlik-Technologie ermöglicht es dabei übrigens auch, neben Story-Telling-Boards ganze Dashboards oder einzelne Visualisierungen über Mashups in Webseiten einzubetten.
Jede App kann in einem bestimmten Stream veröffentlicht werden. Über die Apps und die Streams wird der Zugriff durch die Nutzer erweitert, beschränkt oder anderweitig organisiert. Die Zugriffe auf Apps können über Security Rules gesteuert und beschränkt werden, was für die Data Governance eines Unternehmens wichtig ist und die Lösung auch mandantenfähig macht.
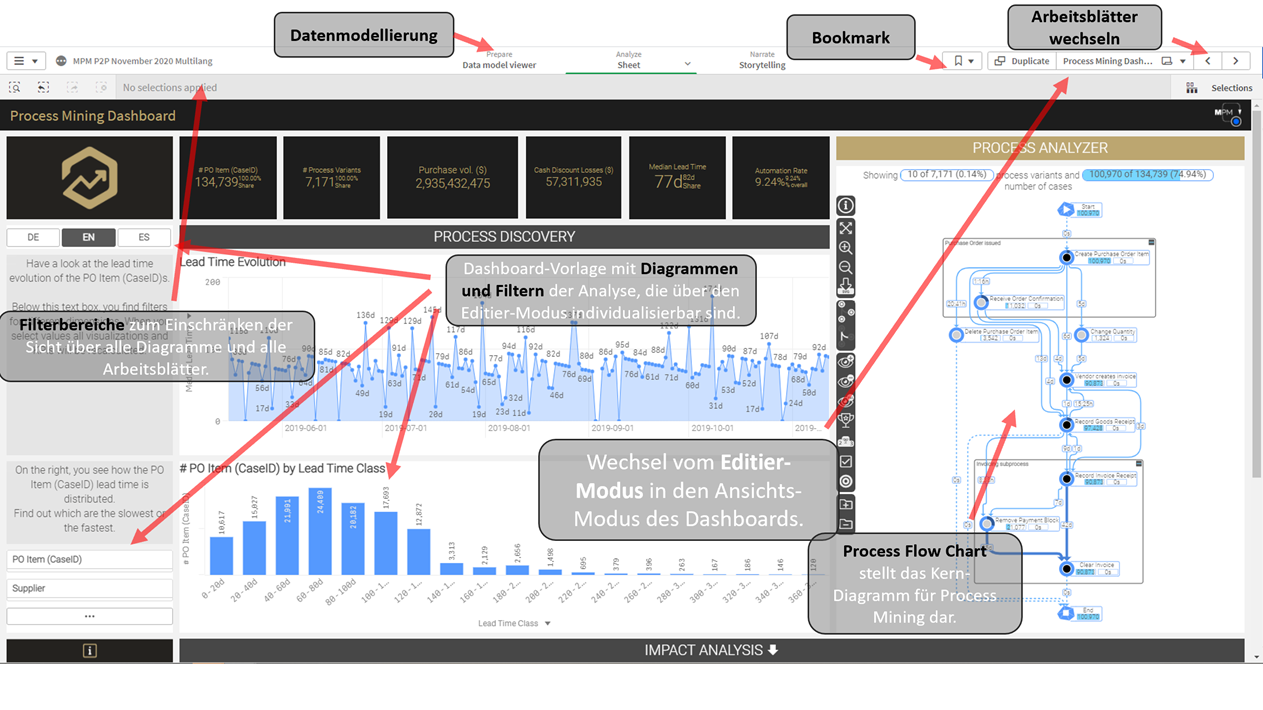
Figure 1 – Übersicht über die wichtigsten Schaltflächen einer Qlik Sense-App
Wer mit Qlik Sense als BI-Tool bereits vertraut ist, wird sich hier sofort zurechtfinden und kann direkt in Process Mining als Analyseform, die immer mehr zum festen Bestandteil leistungsstarker BI-Systeme wird, einsteigen. Standardmäßig startet jede App im Ansichtsmodus. Die Qlik Sense-User-Role „Analyzer User“ ist nur für diese Ansicht berechtigt und kann Apps nur lesend verwenden. Die App ist jedoch interaktiv nutzbar, so dass alle in der App verfügbaren Dimensionen anklickbar und als Filter nutzbar sind. Die Besonderheit ist hier das assoziative Datenmodell, welches durch Qlik’s inMemory Engine bereitgestellt wird. Diese überwindet die Einschränkungen relationaler Datenbanken und SQL-Abfragen. Bei diesem traditionellen Ansatz müssen Datenquellen mit SQL-Join-Befehlen kombiniert werden, und es müssen im Voraus Annahmen über die Art der Fragen getroffen werden, die die Anwender stellen werden. Wenn ein Benutzer eine Analyse durchführen möchte, die nicht geplant war, müssen die Daten neu aufgebaut werden, was die Ausführung komplexer Abfragen zur Folge hat und eine gewisse Wartezeit verursacht. Die assoziative Engine hingegen ermöglicht “on the fly”-Berechnungen und Aggregationen, die sofortige Erkenntnisse über die betrachteten Prozesse liefern.
Für Anwender, die mit den Filtermöglichkeiten nicht so vertraut sind, bietet Qlik auch die assoziative Suche an. Diese ermöglicht es, Suchbegriffe, ähnlich wie bei Google, einzugeben. Die Assoziative Engine ermittelt dann mögliche Treffer und Verbindungen in den Daten, welche daraufhin entsprechend gefiltert werden.
Die User-Role „Professional User“ kann jede veröffentlichte App zudem im Editier-Modus öffnen und eigene Arbeitsblätter und Analysen auf Basis zentral definierter Masteritems (Kennzahlen und Dimensionen) erstellen. Ebenfalls können bestehende Dashboards dupliziert werden, um diese für den eigenen Bedarf anzupassen, z. B. um Tabellen und Diagrammen anzupassen oder zu löschen. Dabei erfolgt jedoch keine Datenduplizierung, da Qlik Sense einen sogenannten Server Side Authoring Ansatz verfolgt. Durch das Konzept der Master Items wird zusätzlich sichergestellt, dass die Data Governance erhalten bleibt. Die erstellen Arbeitsblätter können durch die Professional User wiederrum veröffentlicht werden. Dabei ist sichergestellt, dass alle anderen Anwender diese „Community Sheets“ nur mit den Daten ihres Berechtigungskontexts sehen.
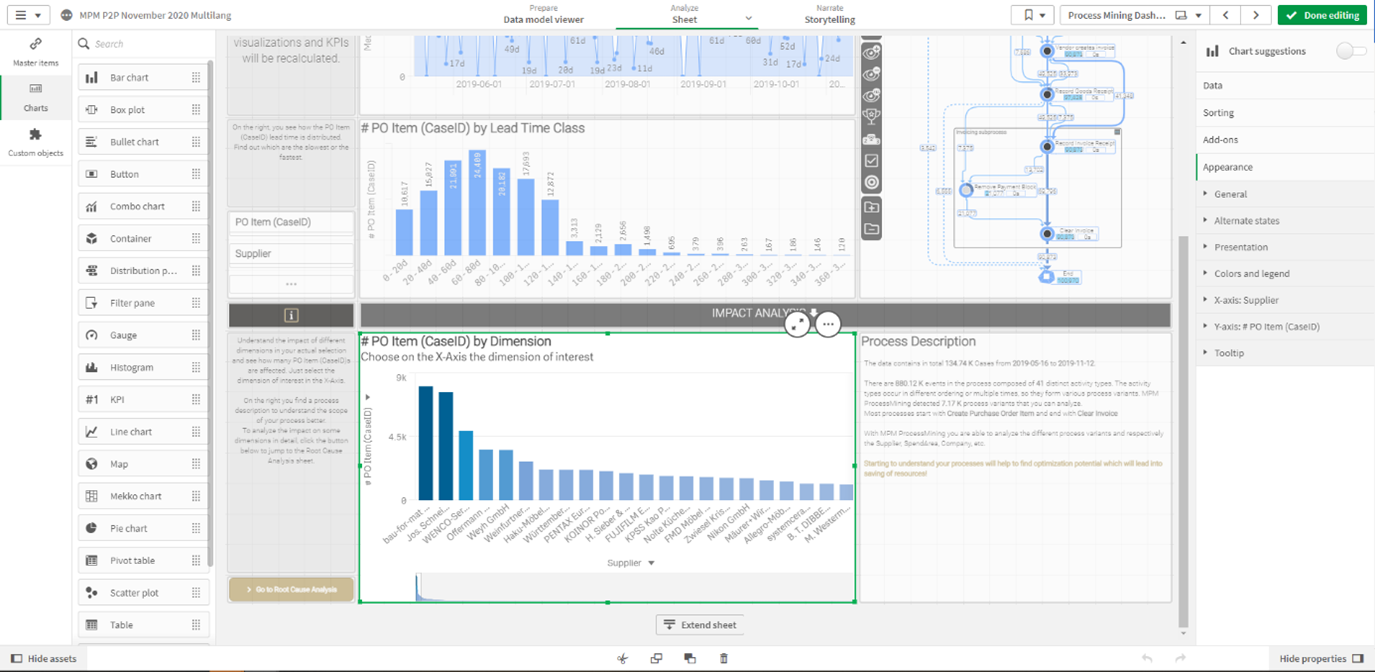
Figure 2 – Eine QlikSense App im Edit-Modus für “Professional User”.
Jede Seite der App kann beliebig gestaltet werden, auch so, dass Read-Only-Nutzer über die Standard-Lizenz viele Möglichkeiten des Ablesens und der Filterung von Daten erhalten.
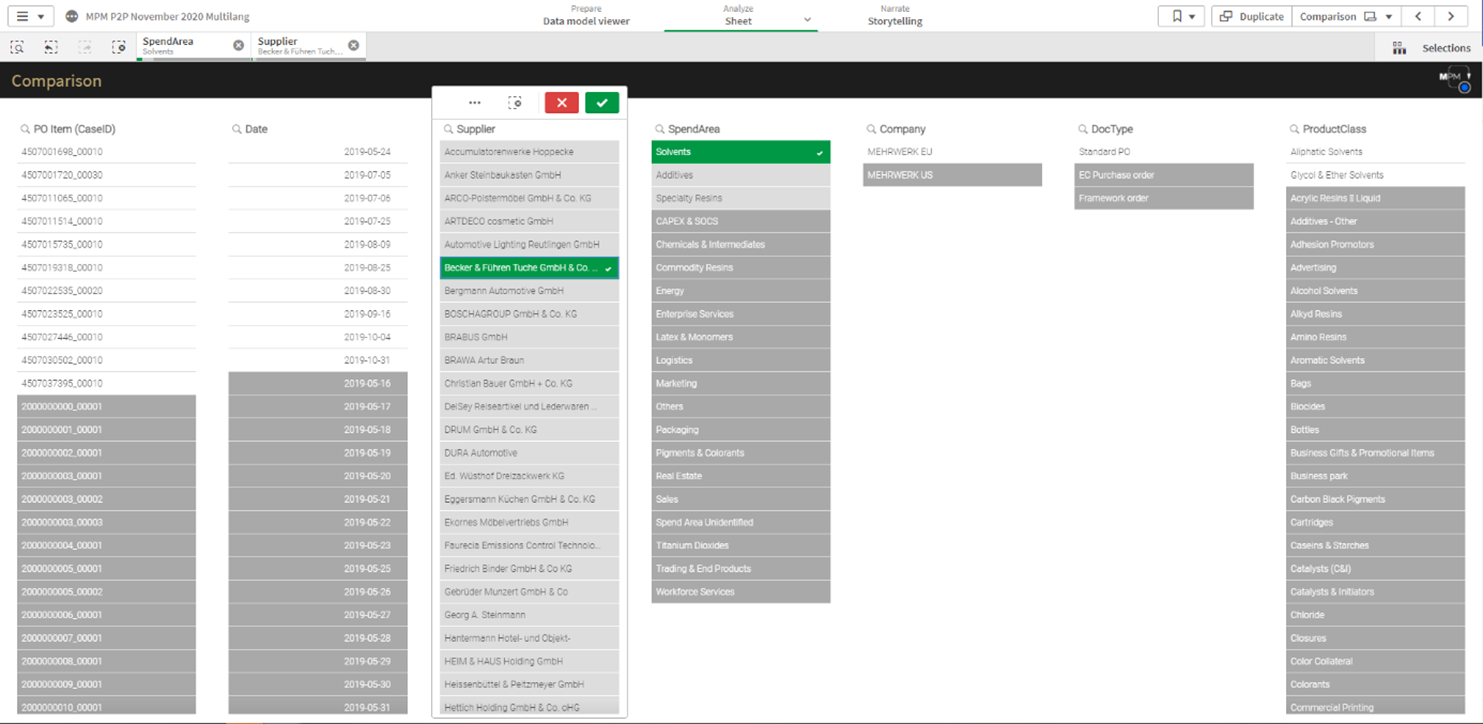
Figure 3 – Hier eine Seite der App, die nur zur Filterung von Dimensionen gestaltet ist: Die Filterung von Prozessnetzen nach Vorgangsnummern, Produkten und/oder Prozess-Varianten
MEHRWERK ProcessMining liefert Vorlagen als Standard-App, die typische Analyse-Szenarien wie das Prozess-Flussdiagramm und Filter für Durchlaufzeiten, Frequenzen und Varianten bereits vorgeben und somit den Einstieg erleichtern. Die Template App liefert außerdem sehr umfangreiche Process Mining Funktionen wie Conformance Checking, automatisierte Ursachenanalysen, Prozessmusterabfragen oder kontinuierliches Process Monitoring gleich mit aus. Außerdem können u.a. Schichten, Prozesshierarchien oder Sollprozesse konfiguriert werden.
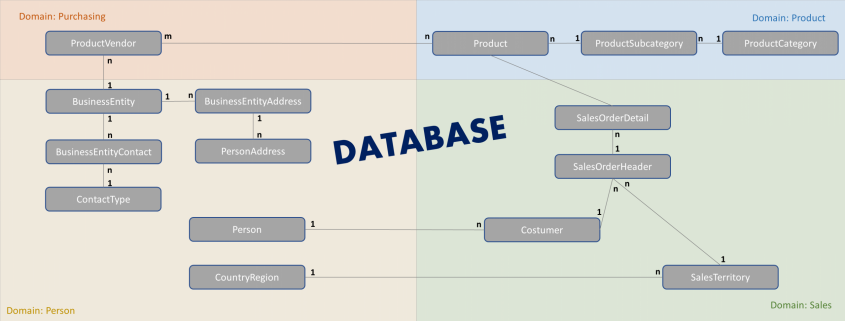
Nur User mit der Qlik Sense „Professional User“ Lizenz können dazu im Editier-Modus auch die Datenmodelle einsehen, erstellen und anpassen. So wie auch in der klassischen Business Intelligence sind im Process Mining Datenmodelle in Form sogenannter Event-Logs entscheidend für die Analyse und die Vorbedingung auch für die MPM App.
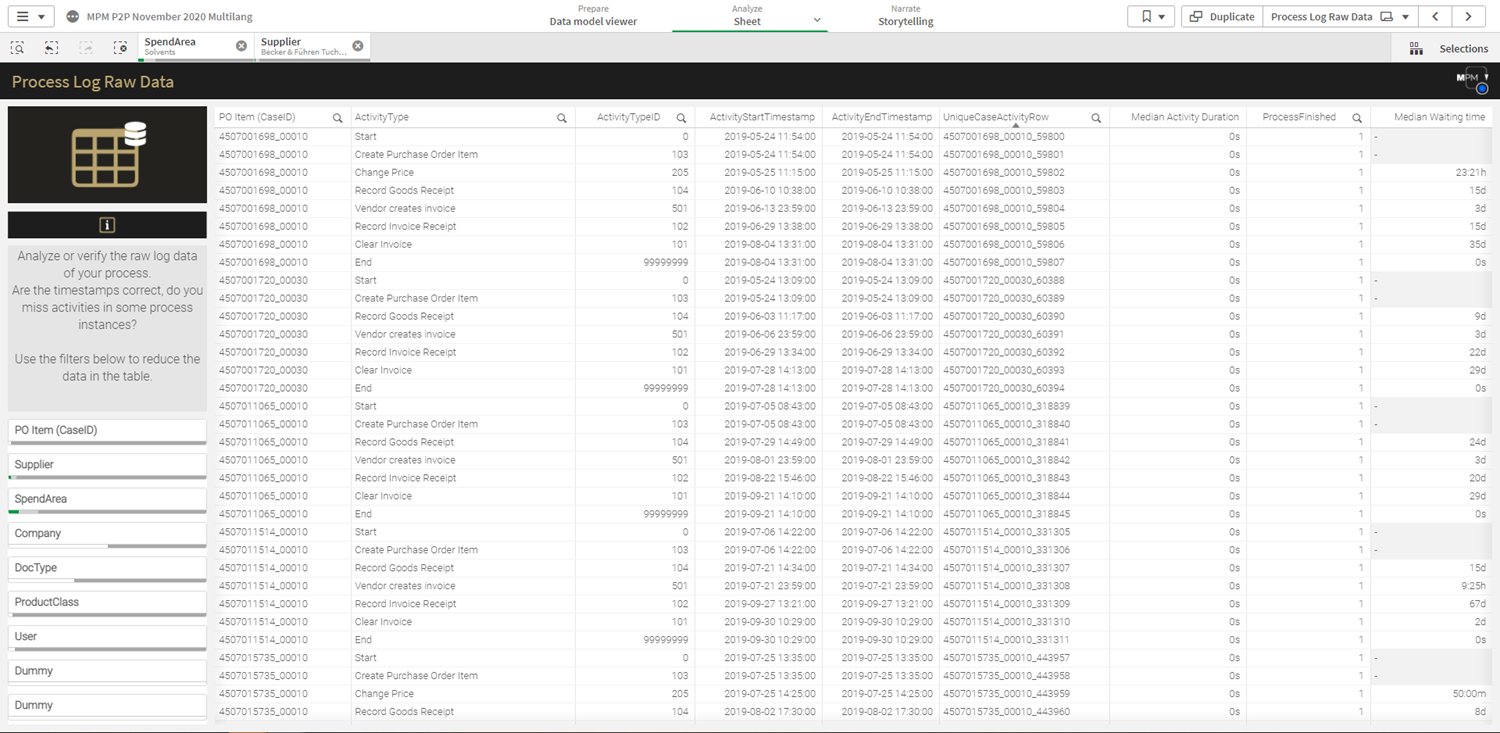
Figure 4 – Beispielhaftes Event Log aus der Beispielvorlage-App von MEHRWERK.
Das Event Log kann und sollte neben den drei Must-Haves für Process Mining (Case-ID, Activity Description & Timestamp) noch beliebig viele weitere hilfreiche Informationen in weiteren Spalten aufführen. Denn nur so können Abweichungen, Anomalien oder andere Auffälligkeiten im Prozess in einen Kontext gesetzt werden, um gezielte Maßnahmen treffen zu können.
Integrationsfähigkeit
Die Frage, wie gut und leicht sich MEHRWERK ProcessMining in die Unternehmens-IT einfügen lässt, stellt sich mit der Frage, ob Qlik Sense bereits Teil der IT-Infrastruktur ist oder beispielsweise als Cloud-Lösung eingesetzt wird. Unternehmen, die bisher nicht auf Qlik Sense setzten, müssten hier die grundsätzliche Frage der Voraussetzungen des Tools von QlikTech stellen. Vollständigerweise sei jedoch angemerkt, dass laut Aussage von MEHRWERK ca. 40% ihrer Kunden vorher kein Qlik Sense im Einsatz hatten und die Installation von Qlik Sense keine große Hürde darstellt.
Ein wesentlicher Aspekt der Integrationsfähigkeit ist jedoch nicht nur die Integration der Software in die IT-Infrastruktur, sondern auch, wie leicht sich Daten in das benötigte Datenformat (Event Log) überführen lässt. Es ist zwar möglich, Qlik Sense mit MPM ausschließlich für die Datenanalyse/-visualisierung zu verwenden, und die Datenmodellierung dann mit anderen Tools (Datenbanken, ETL) durchzuführen. Allerdings bringt Qlik Sense selbst eine Menge an Konnektoren zu vielen Datenquellen mit. Wie mit jedem Process Mining Tool ist gibt es dabei zwei Konzepte der Datenaufbereitung. Die eine Möglichkeit ist das Laden, Konsolidieren und Vorbereiten der Datenbank für ein Data Warehouse (DWH), das die Daten bereits in Event Logs transformiert. In diesem Fall kann MPM die Daten über einen Standard-Konnektor von Qlik Sense importieren, in ein MPM-spezifisches Event Log nachbereiten und dann direkt mit der Analyse starten. Dabei benötigt Qlik Sense keine eigene Datenbank für die Datenhaltung sondern verabeitet die Daten hochkomprimiert in der eigenen, patentierten InMemory-Engine.

Figure 5 – Qlik Sense Standard Connectors
Das andere Konzept der Datenaufbereitung ist die Nutzung von Qlik Sense auch als Tool für das Datenmanagement. Hierfür werden die Standard-Konnektoren genutzt, um Daten möglichst direkt an Qlik Sense anzubinden. In diesem Fall muss die Bildung des anwendungsfallspezifischen Event Logs als prozessprotokollartiges Datenmodell in Qlik Sense erfolgen. Dies lässt sich in einem prozeduralen Skript mit der Qlik-eigenen Skriptsprache, die an die Sprache DAX von Microsoft sowie an SQL erinnert, umsetzen. Dabei kann das Skript in mehrere Segmente unterteilt und die Ausführung automatisiert und ge-timed werden. MEHRWERK ProcessMining bietet hierfür standardisierte ETL-Best-Practices an, die erlauben mit Hilfe von Regelwerken die Eventloggenerierung stark zu vereinfachen. Ein großer Vorteil ist die Verzahnung von Process Mining Funktionalitäten während des ETL-Prozesses. Dies erlaubt frühzeitiges und visuelles Validieren schon bei der Beladung.
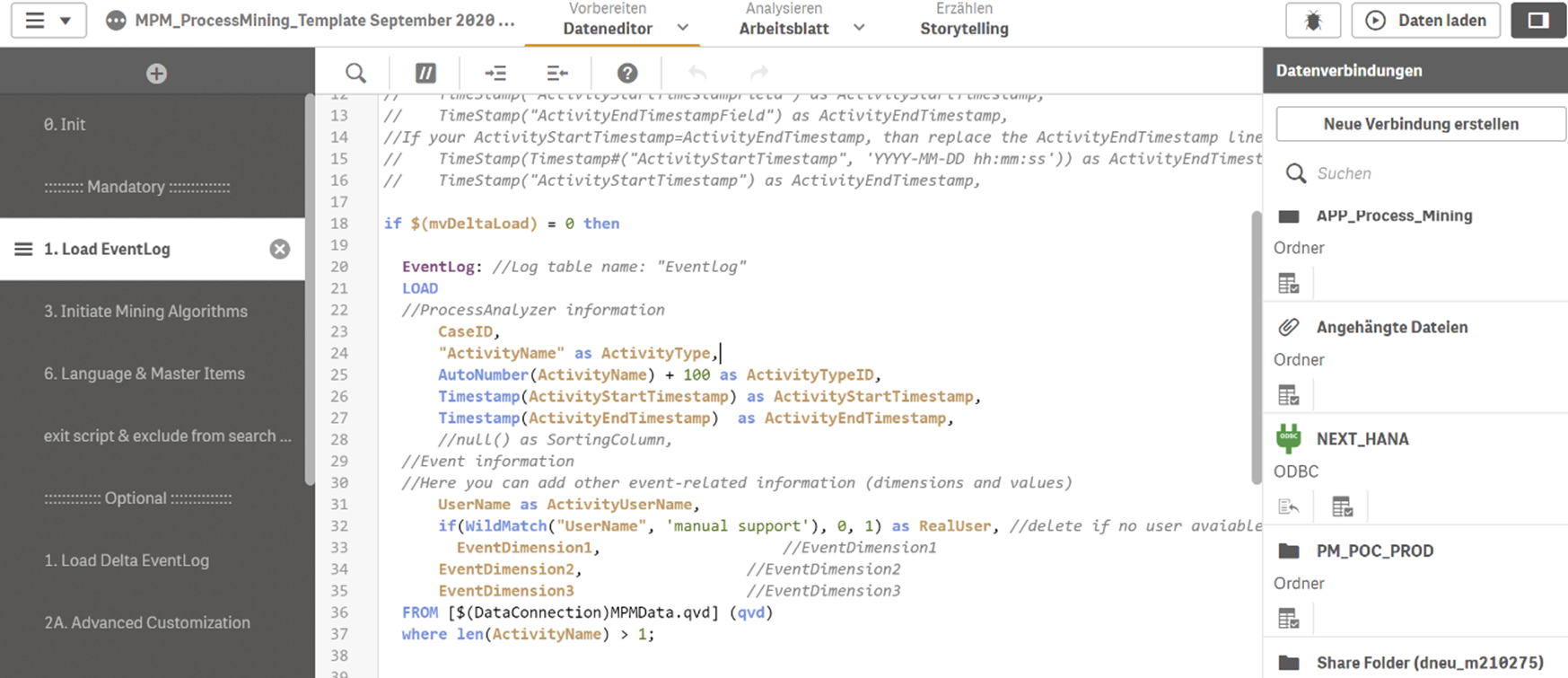
Figure 6 – Das Laden und Modellieren von Daten kann eingeschränkt visuell mit klickbaren Oberflächen erfolgen. Mehr Möglichkeiten bietet jedoch der Qlik Script Editor.
Skalierbarkeit
Klassischerweise wurde Qlik Sense Server On-Premise in der eigenen IT-Infrastruktur installiert. Die Software Qlik Sense ist nur als Server-Version verfügbar. Qlik Sense setzt auf eine patentierte In-Memory-Technologie. Technisch ist Qlik Sense in Sachen Performance nur durch die Hardware begrenzt.
Heute kann Qlik Sense Server auch direkt über die Qlik Cloud genutzt oder über Kubernetes auf eigene Server oder in die Multi-Cloud ausgeliefert werden. Ein Betrieb bei typischen Cloud-Anbietern wie von Amazon, Google oder Microsoft ist problemlos möglich und somit technisch auch beliebig skalierbar.
Zukunftsfähigkeit
Die Zukunftsfähigkeit von MPM liegt in erster Linie in der Weiterentwicklung von Qlik Sense durch QlikTech. Im Magic Quadrant von Gartner 2020 für BI- und Analytics-Tools zählt Qlik zu den top drei Anführern nach Tableau und Microsoft.
Auf Grund der großen Qlik-Community und der weiten Verbreitung als BI-Tool zählt die Lösung von MEHRWERK vermutlich zu einer sehr zukunftssicheren mit vielen Weiterentwicklungsmöglichkeiten. Aus der Community und von anderen BI-Unternehmen gibt es viele Erweiterungen für Qlik Sense, die den Funktionsumfang von der Konnektivität zu anderen Tools bis hin zur einfacheren oder visuell attraktiveren Analyse verbessern. Für Qlik Sense gibt es viele weitere Anbieter für diverse Erweiterungen sowie Qlik-eigene und kompatible Co-Lösungen für Master Data Management und Data Governance. Auch die Integration von Data Science Tools via Programmiersprachen wie Python oder R ist möglich und erweitert diese Plattform in Richtung Advanced Analytics.
Die Weiterentwicklung der Process Mining Lösung erfolgt unabhängig davon auch durch MEHRWERK selbst, so wird Machine Learning vermehrt dazu eingesetzt, Process Anomalien zu erkennen sowie Durchlaufzeiten von Prozessen zu prognostizieren.
Preisgestaltung
Die Preisgestaltung wird von MEHRWERK nicht transparent kommuniziert und liegt im Vergleich zu anderen Process Mining Tools erfahrungsgemäß im Mittelfeld. Neben den MPM spezifischen Kosten werden darüber hinaus auch User-Lizenzen für Qlik Sense fällig. Weitere mögliche Kosten hängen auch von der Wahl ab, ob die Qlik Cloud, eine andere Cloud-Plattform oder die On-Premise-Installation geplant wird.
Fazit
MPM ProcessMining ist für Unternehmen, die voll und ganz auf QlikSense als BI-Tool setzen, eine echte Option für den schnellen und leistungsstarken Einstieg in diese spezielle Analysemethodik. Mitarbeiter, die Qlik Sense bereits kennen, finden sich hier beinahe sofort zurecht und können direkt starten, sofern Event-Logs vorliegen. Die Gestaltung von Event-Logs in Qlik Sense bedingt jedoch etwas Erfahrung mit der Datenaufbereitung und -modellierung in Qlik Sense und Kenntnisse in Qlik Script.