
Data Science für Smart Home im familiengeführten Unternehmen Miele
 Dr. Florian Nielsen ist Principal for AI und Data Science bei Miele im Bereich Smart Home und zuständig für die Entwicklung daten-getriebener digitaler Produkte und Produkterweiterungen. Der studierte Informatiker promovierte an der Universität Ulm zum Thema multimodale kognitive technische Systeme.
Dr. Florian Nielsen ist Principal for AI und Data Science bei Miele im Bereich Smart Home und zuständig für die Entwicklung daten-getriebener digitaler Produkte und Produkterweiterungen. Der studierte Informatiker promovierte an der Universität Ulm zum Thema multimodale kognitive technische Systeme.
Data Science Blog: Herr Dr. Nielsen, viele Unternehmen und Anwender reden heute schon von Smart Home, haben jedoch eher ein Remote Home. Wie machen Sie daraus tatsächlich ein Smart Home?
Tatsächlich entspricht das auch meiner Wahrnehmung. Die bloße Steuerung vernetzter Produkte über digitale Endgeräte macht aus einem vernetzten Produkt nicht gleich ein „smartes“. Allerdings ist diese Remotefunktion ein notwendiges Puzzlestück in der Entwicklung von einem nicht vernetzten Produkt, über ein intelligentes, vernetztes Produkt hin zu einem Ökosystem von sich ergänzenden smarten Produkten und Services. Vernetzte Produkte, selbst wenn sie nur aus der Ferne gesteuert werden können, erzeugen Daten und ermöglichen uns die Personalisierung, Optimierung oder gar Automatisierung von Produktfunktionen basierend auf diesen Daten voran zu treiben. „Smart“ wird für mich ein Produkt, wenn es sich beispielsweise besser den Bedürfnissen des Nutzers anpasst oder über Assistenzfunktionen eine Arbeitserleichterung im Alltag bietet.
Data Science Blog: Smart Home wiederum ist ein großer Begriff, der weit mehr als Geräte für Küchen und Badezimmer betrifft. Wie weit werden Sie hier ins Smart Home vordringen können?
Smart Home ist für mich schon fast ein verbrannter Begriff. Der Nutzer assoziiert hiermit doch vor allem die Steuerung von Heizung und Rollladen. Im Prinzip geht es doch um eine Vision in der sich smarte, vernetzte Produkt in ein kontextbasiertes Ökosystem einbetten um den jeweiligen Nutzer in seinem Alltag, nicht nur in seinem Zuhause, Mehrwert mit intelligenten Produkten und Services zu bieten. Für uns fängt das beispielsweise nicht erst beim Starten des Kochprozesses mit Miele-Geräten an, sondern deckt potenziell die komplette „User Journey“ rund um Ernährung (z. B. Inspiration, Einkaufen, Vorratshaltung) und Kochen ab. Natürlich überlegen wir verstärkt, wie Produkte und Services unser existierendes Produktportfolio ergänzen bzw. dem Nutzer zugänglicher machen könnten, beschränken uns aber hierauf nicht. Ein zusätzlicher für uns als Miele essenzieller Aspekt ist allerdings auch die Privatsphäre des Kunden. Bei der Bewertung potenzieller Use-Cases spielt die Privatsphäre unserer Kunden immer eine wichtige Rolle.
Data Science Blog: Die meisten Data-Science-Abteilungen befassen sich eher mit Prozessen, z. B. der Qualitätsüberwachung oder Prozessoptimierung in der Produktion. Sie jedoch nutzen Data Science als Komponente für Produkte. Was gibt es dabei zu beachten?
Kundenbedürfnisse. Wir glauben an nutzerorientierte Produktentwicklung und dementsprechend fängt alles bei uns bei der Identifikation von Bedürfnissen und potenziellen Lösungen hierfür an. Meist starten wir mit „Design Thinking“ um die Themen zu identifizieren, die für den Kunden einen echten Mehrwert bieten. Wenn dann noch Data Science Teil der abgeleiteten Lösung ist, kommen wir verstärkt ins Spiel. Eine wesentliche Herausforderung ist, dass wir oft nicht auf der grünen Wiese starten können. Zumindest wenn es um ein zusätzliches Produktfeature geht, das mit bestehender Gerätehardware, Vernetzungsarchitektur und der daraus resultierenden Datengrundlage zurechtkommen muss. Zwar sind unsere neuen Produktgenerationen „Remote Update“-fähig, aber auch das hilft uns manchmal nur bedingt. Dementsprechend ist die Antizipation von Geräteanforderungen essenziell. Etwas besser sieht es natürlich bei Umsetzungen von cloud-basierten Use-Cases aus.
Data Science Blog: Es heißt häufig, dass Data Scientists kaum zu finden sind. Ist Recruiting für Sie tatsächlich noch ein Thema?
Data Scientists, hier mal nicht interpretiert als Mythos „Unicorn“ oder „Full-Stack“ sind natürlich wichtig, und auch nicht leicht zu bekommen in einer Region wie Gütersloh. Aber Engineers, egal ob Data, ML, Cloud oder Software generell, sind der viel wesentlichere Baustein für uns. Für die Umsetzung von Ideen braucht es nun mal viel Engineering. Es ist mittlerweile hinlänglich bekannt, dass Data Science einen zwar sehr wichtigen, aber auch kleineren Teil des daten-getriebenen Produkts ausmacht. Mal abgesehen davon habe ich den Eindruck, dass immer mehr „Data Science“- Studiengänge aufgesetzt werden, die uns einerseits die Suche nach Personal erleichtern und andererseits ermöglichen Fachkräfte einzustellen die nicht, wie früher einen PhD haben (müssen).
Data Science Blog: Sie haben bereits einige Analysen erfolgreich in Ihre Produkte integriert. Welche Herausforderungen mussten dabei überwunden werden? Und welche haben Sie heute noch vor sich?
Wir sind, wie viele Data-Science-Abteilungen, noch ein relativ junger Bereich. Bei den meisten unserer smarten Produkte und Services stecken wir momentan in der MVP-Entwicklung, deshalb gibt es einige Herausforderungen, die wir aktuell hautnah erfahren. Dies fängt, wie oben erwähnt, bei der Berücksichtigung von bereits vorhandenen Gerätevoraussetzungen an, geht über mitunter heterogene, inkonsistente Datengrundlagen, bis hin zur Etablierung von Data-Science- Infrastruktur und Deploymentprozessen. Aus meiner Sicht stehen zudem viele Unternehmen vor der Herausforderung die Weiterentwicklung und den Betrieb von AI bzw. Data- Science- Produkten sicherzustellen. Verglichen mit einem „fire-and-forget“ Mindset nach Start der Serienproduktion früherer Zeiten muss ein Umdenken stattfinden. Daten-getriebene Produkte und Services „leben“ und müssen dementsprechend anders behandelt und umsorgt werden – mit mehr Aufwand aber auch mit der Chance „immer besser“ zu werden. Deshalb werden wir Buzzwords wie „MLOps“ vermehrt in den üblichen Beraterlektüren finden, wenn es um die nachhaltige Generierung von Mehrwert von AI und Data Science für Unternehmen geht. Und das zu Recht.
Data Science Blog: Data Driven Thinking wird heute sowohl von Mitarbeitern in den Fachbereichen als auch vom Management verlangt. Gerade für ein Traditionsunternehmen wie Miele sicherlich eine Herausforderung. Wie könnten Sie diese Denkweise im Unternehmen fördern?
Data Driven Thinking kann nur etabliert werden, wenn überhaupt der Zugriff auf Daten und darauf aufbauende Analysen gegeben ist. Deshalb ist Daten-Demokratisierung der wichtigste erste Schritt. Aus meiner Perspektive geht es darum initial die Potenziale aufzuzeigen, um dann mithilfe von Daten Unsicherheiten zu reduzieren. Wir haben die Erfahrung gemacht, dass viele Fachbereiche echtes Interesse an einer daten-getriebenen Analyse ihrer Hypothesen haben und dankbar für eine daten-getriebene Unterstützung sind. Miele war und ist ein sehr innovatives Unternehmen, dass „immer besser“ werden will. Deshalb erfahren wir momentan große Unterstützung von ganz oben und sind sehr positiv gestimmt. Wir denken, dass ein Schritt in die richtige Richtung bereits getan ist und mit zunehmender Zahl an Multiplikatoren ein „Data Driven Thinking“ sich im gesamten Unternehmen etablieren kann.
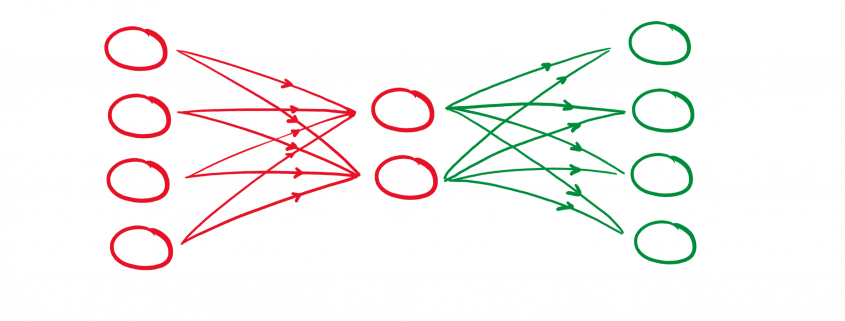
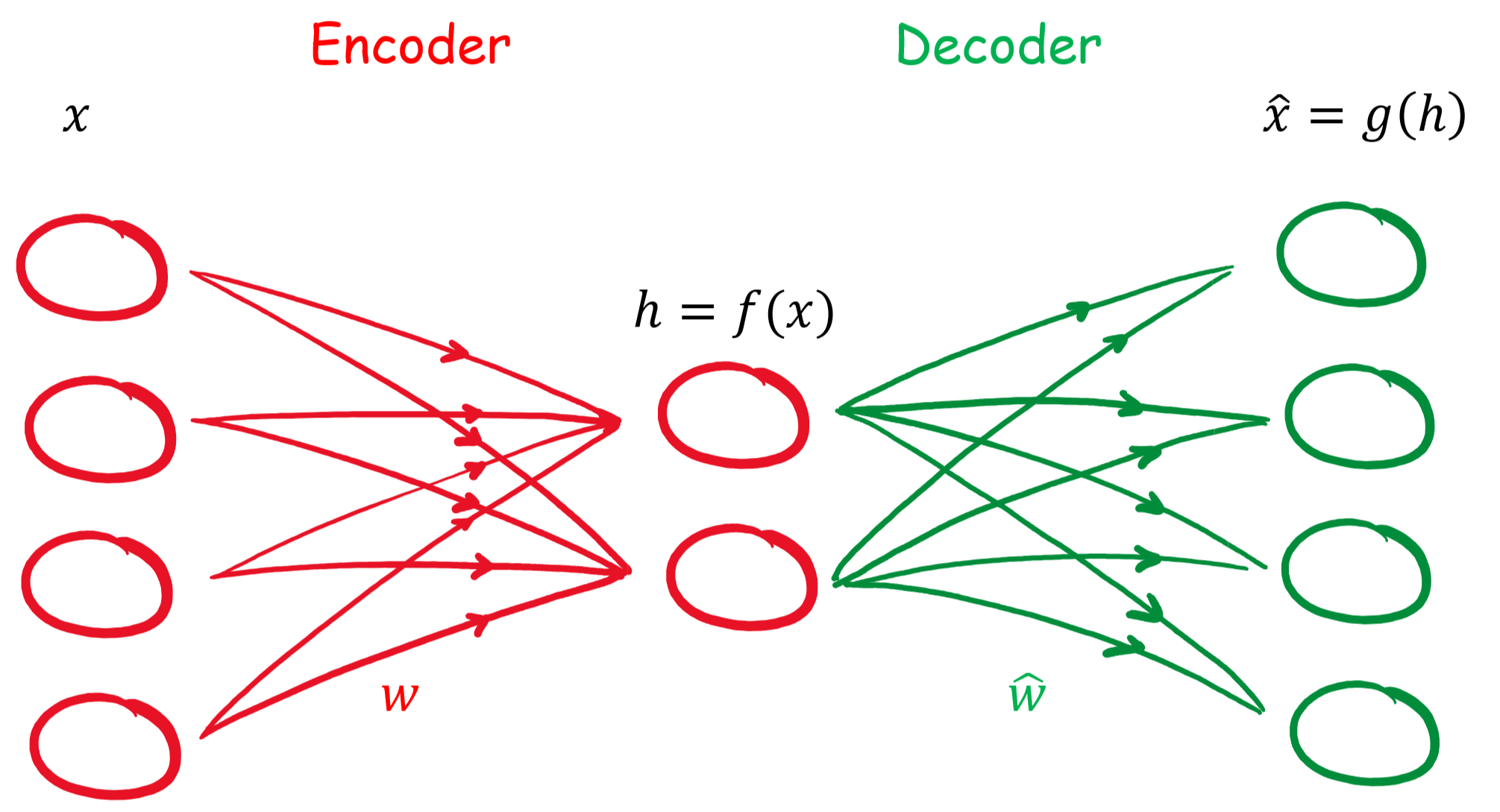






 gekennzeichnet werden. Damit besteht der Zusammenhang:
gekennzeichnet werden. Damit besteht der Zusammenhang:![\begin{align*} \mathbf{h} &= f(\mathbf{x}) = \sigma(\mathbf{W}\mathbf{x} + \mathbf{B}) \\ \hat{\mathbf{x}} &= g(\mathbf{h}) = \hat{\sigma}(\hat{\mathbf{W}} \mathbf{h} + \hat{\mathbf{B}}) \\ \hat{\mathbf{x}} &= \hat{\sigma} \{ \hat{\mathbf{W}} \left[\sigma ( \mathbf{W}\mathbf{x} + \mathbf{B} )\right] + \hat{\mathbf{B}} \}\\ \end{align*}](https://data-science-blog.com/de/wp-content/ql-cache/quicklatex.com-96b9128bd26ff4d2975a372d338e15c4_l3.png "Rendered by QuickLaTeX.com")
![\begin{align*} L(\mathbf{x}, \hat{\mathbf{x}}) &= \mathbf{MSE}(\mathbf{x}, \hat{\mathbf{x}}) = \| \mathbf{x} - \hat{\mathbf{x}} \| ^2 &= \| \mathbf{x} - \hat{\sigma} \{ \hat{\mathbf{W}} \left[\sigma ( \mathbf{W}\mathbf{x} + \mathbf{B} )\right] + \hat{\mathbf{B}} \} \| ^2 \end{align*}](https://data-science-blog.com/de/wp-content/ql-cache/quicklatex.com-2afadab2e44942274d566bd163b513cf_l3.png "Rendered by QuickLaTeX.com")
![\begin{align*} [1, 0, 0, 0] \ \widehat{=} \ 0 \\ [0, 1, 0, 0] \ \widehat{=} \ 1 \\ [0, 0, 1, 0] \ \widehat{=} \ 2 \\ [0, 0, 0, 1] \ \widehat{=} \ 3\\ \end{align*}](https://data-science-blog.com/de/wp-content/ql-cache/quicklatex.com-072135e2e36d72e0e3bf860c5308e03a_l3.png "Rendered by QuickLaTeX.com")
![\begin{align*} [1, 0, 0, 0] \ \widehat{=} \ 0 \ \widehat{=} \ [0, 0] \\ [0, 1, 0, 0] \ \widehat{=} \ 1 \ \widehat{=} \ [0, 1] \\ [0, 0, 1, 0] \ \widehat{=} \ 2 \ \widehat{=} \ [1, 0] \\ [0, 0, 0, 1] \ \widehat{=} \ 3 \ \widehat{=} \ [1, 1] \\ \end{align*}](https://data-science-blog.com/de/wp-content/ql-cache/quicklatex.com-17422530a780bd436a53fc45b2a523aa_l3.png "Rendered by QuickLaTeX.com")



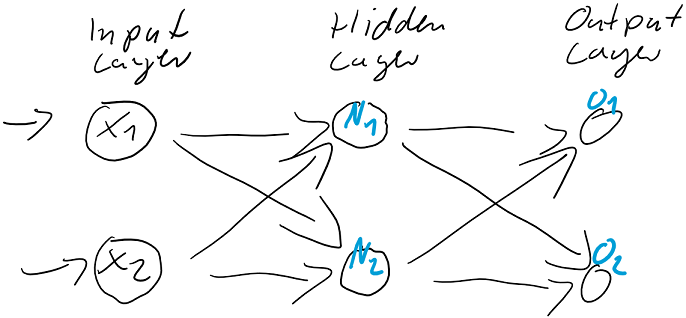
 berechnen…
berechnen…


 werden dann als Berechnungsgrundlage für die Ausgaben der Ausgabeschicht
werden dann als Berechnungsgrundlage für die Ausgaben der Ausgabeschicht  verwendet. Auch die Ausgabe-Neuronen berechnen ihre jeweilige Nettoeingabe
verwendet. Auch die Ausgabe-Neuronen berechnen ihre jeweilige Nettoeingabe 
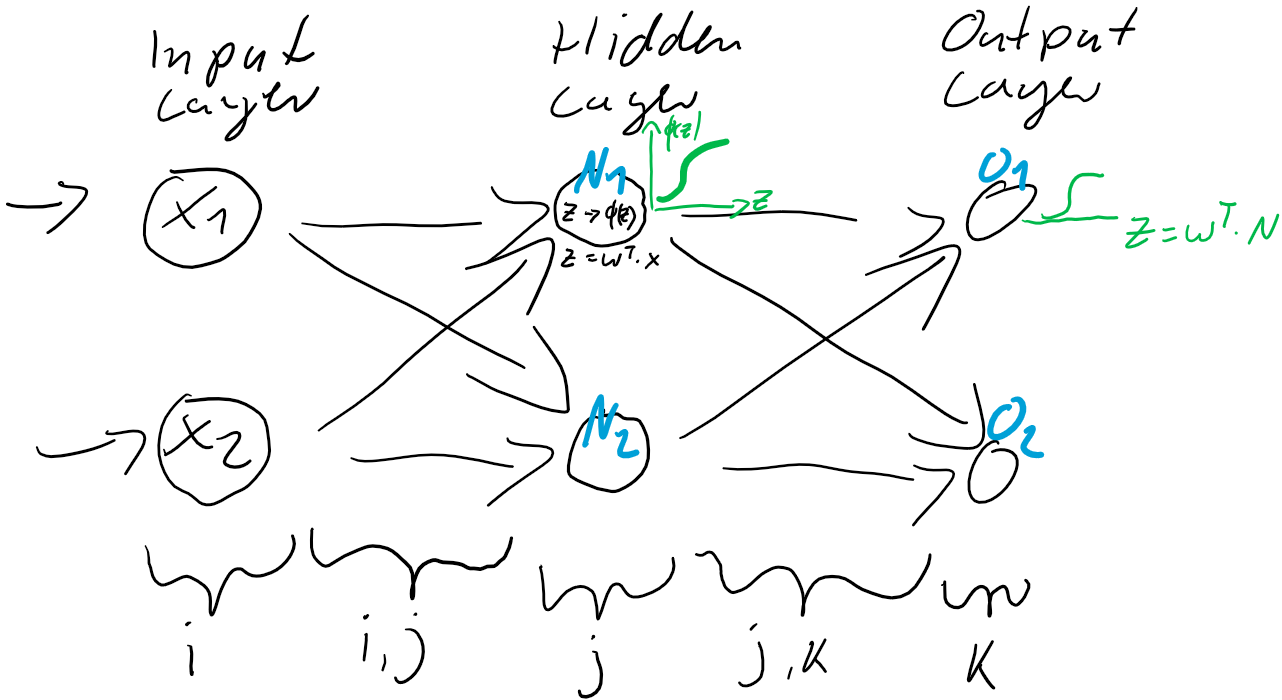
 ) und der Prädiktion (Ausgabe
) und der Prädiktion (Ausgabe 
 ist also einfach der Unterschied zwischen dem Ziel-Wert und der Prädiktion. Jedes Training ist eine Wiederholung von Prädiktion (Forward) und Gewichtsanpassung (Back). Im ersten Schritt werden üblicherweise die Gewichtungen zufällig gesetzt, jede Gewichtung unterschiedlich nach Zufallszahl. So ist die Wahrscheinlichkeit, gleich zu Beginn die “richtigen” Gewichtungen gefunden zu haben auch bei kleinen neuronalen Netzen verschwindend gering. Der Fehler wird also groß sein und kann über den Gradientenabstieg durch Gewichtsanpassung verkleinert werden.
ist also einfach der Unterschied zwischen dem Ziel-Wert und der Prädiktion. Jedes Training ist eine Wiederholung von Prädiktion (Forward) und Gewichtsanpassung (Back). Im ersten Schritt werden üblicherweise die Gewichtungen zufällig gesetzt, jede Gewichtung unterschiedlich nach Zufallszahl. So ist die Wahrscheinlichkeit, gleich zu Beginn die “richtigen” Gewichtungen gefunden zu haben auch bei kleinen neuronalen Netzen verschwindend gering. Der Fehler wird also groß sein und kann über den Gradientenabstieg durch Gewichtsanpassung verkleinert werden. und
und  und passen danach die Gewichte
und passen danach die Gewichte  (
( &
&  und
und  &
&  ) der Schicht zwischen dem Hidden-Layer
) der Schicht zwischen dem Hidden-Layer 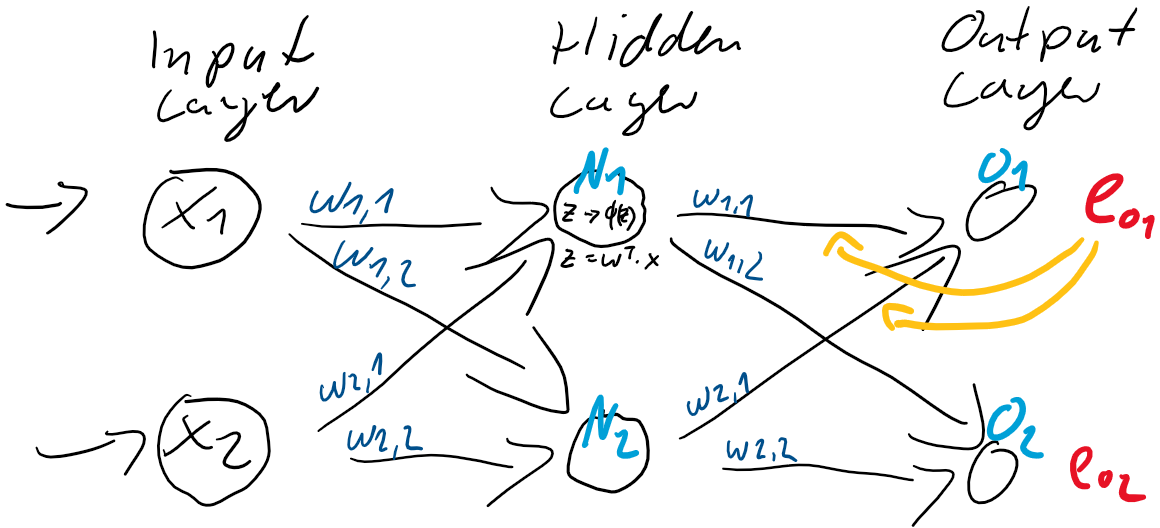
 und dem Hidden-Layer
und dem Hidden-Layer  und
und  . Dieser Anteil am Fehler der jeweiligen Neuronen ergibt sich direkt aus den Gewichtungen
. Dieser Anteil am Fehler der jeweiligen Neuronen ergibt sich direkt aus den Gewichtungen 

![\[ e_{N} = \left(\begin{array}{rr} \frac{w_{1,1}}{w_{1,1} + w_{1,2}} & \frac{w_{1,2}}{w_{1,1} + w_{1,2}} \\ \frac{w_{2,1}}{w_{2,1} + w_{2,2}} & \frac{w_{2,2}}{w_{2,1} + w_{2,2}} \end{array}\right) \cdot \left(\begin{array}{c} e_{1} \\ e_{2} \end{array}\right) \qquad \]](https://data-science-blog.com/de/wp-content/ql-cache/quicklatex.com-6fadfe69caec8e8c351788824875138a_l3.png "Rendered by QuickLaTeX.com")
![\[ e_{N} = \left(\begin{array}{rr} w_{1,1} & w_{1,2} \\ w_{2,1} & w_{2,2} \end{array}\right) \cdot \left(\begin{array}{c} e_{1} \\ e_{2} \end{array}\right) \qquad \]](https://data-science-blog.com/de/wp-content/ql-cache/quicklatex.com-7dee7d02ac1aba606a45895afe90a837_l3.png "Rendered by QuickLaTeX.com")

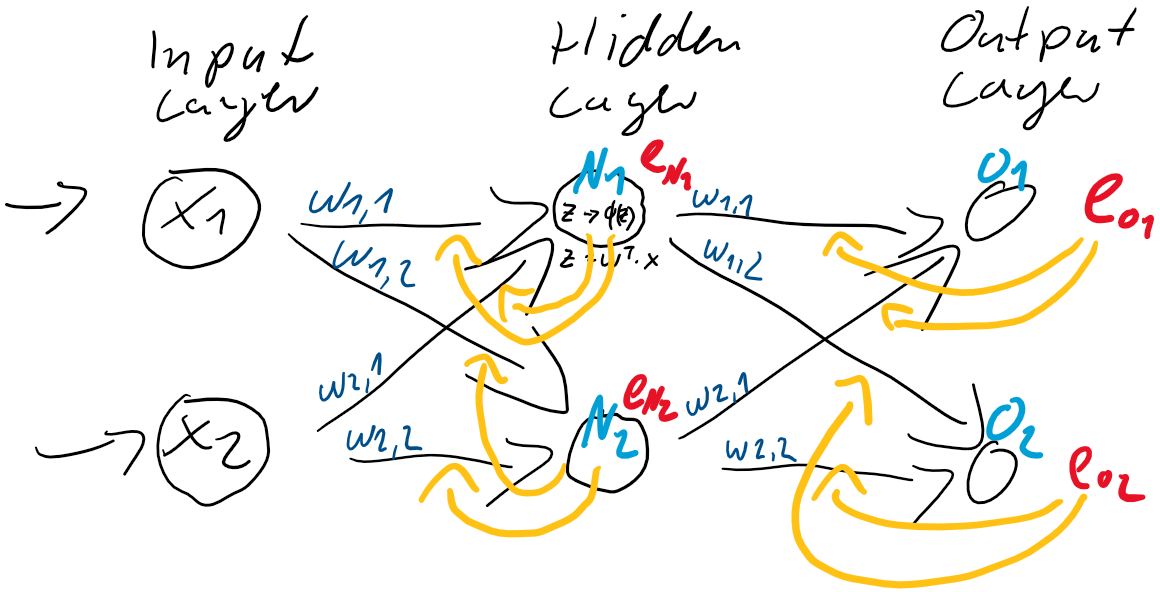
 zwischen der Eingabe-Schicht
zwischen der Eingabe-Schicht  und der verborgenden Schicht
und der verborgenden Schicht  .
.

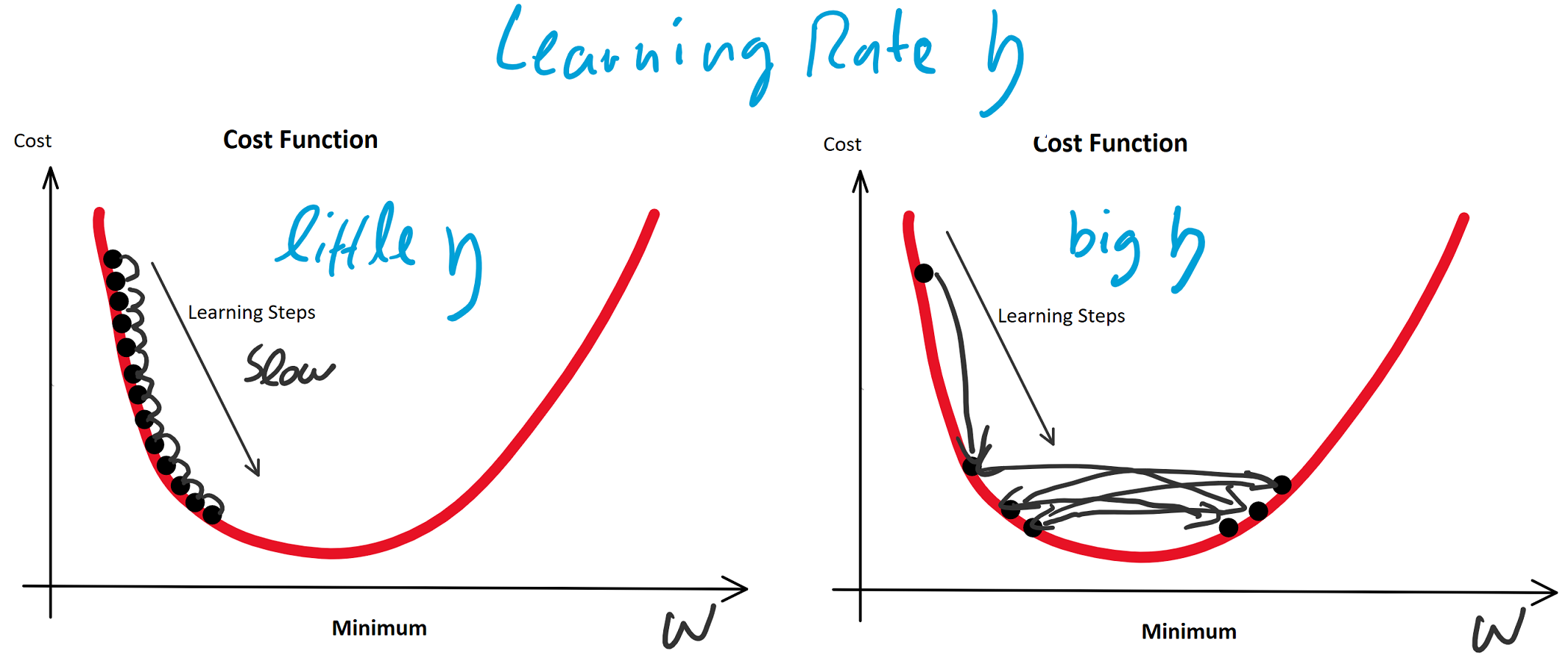
 (Random Initialization). Wir berechnen die Ausgabe (Forwardpropogation) und vergleichen sie über eine Verlustfunktion (z. B. über die Funktion Mean Squared Error) mit dem tatsächlich korrekten Wert. Auf Grund der zufälligen Initialisierung haben wir eine nahe zu garantierte Falschheit der Ergebnisse und somit einen Verlust. Für die Verlustfunktion berechnen wir den Gradienten für gegebene Eingabewerte. Voraussetzung dafür ist, dass die Funktion ableitbar ist. Wir bewegen uns entgegen des Gradienten in Richtung Minimum der Verlustfunktion. Ist dieses Minimum (fast) gefunden, spricht man auch davon, dass der Lernalgorithmus konvergiert.
(Random Initialization). Wir berechnen die Ausgabe (Forwardpropogation) und vergleichen sie über eine Verlustfunktion (z. B. über die Funktion Mean Squared Error) mit dem tatsächlich korrekten Wert. Auf Grund der zufälligen Initialisierung haben wir eine nahe zu garantierte Falschheit der Ergebnisse und somit einen Verlust. Für die Verlustfunktion berechnen wir den Gradienten für gegebene Eingabewerte. Voraussetzung dafür ist, dass die Funktion ableitbar ist. Wir bewegen uns entgegen des Gradienten in Richtung Minimum der Verlustfunktion. Ist dieses Minimum (fast) gefunden, spricht man auch davon, dass der Lernalgorithmus konvergiert.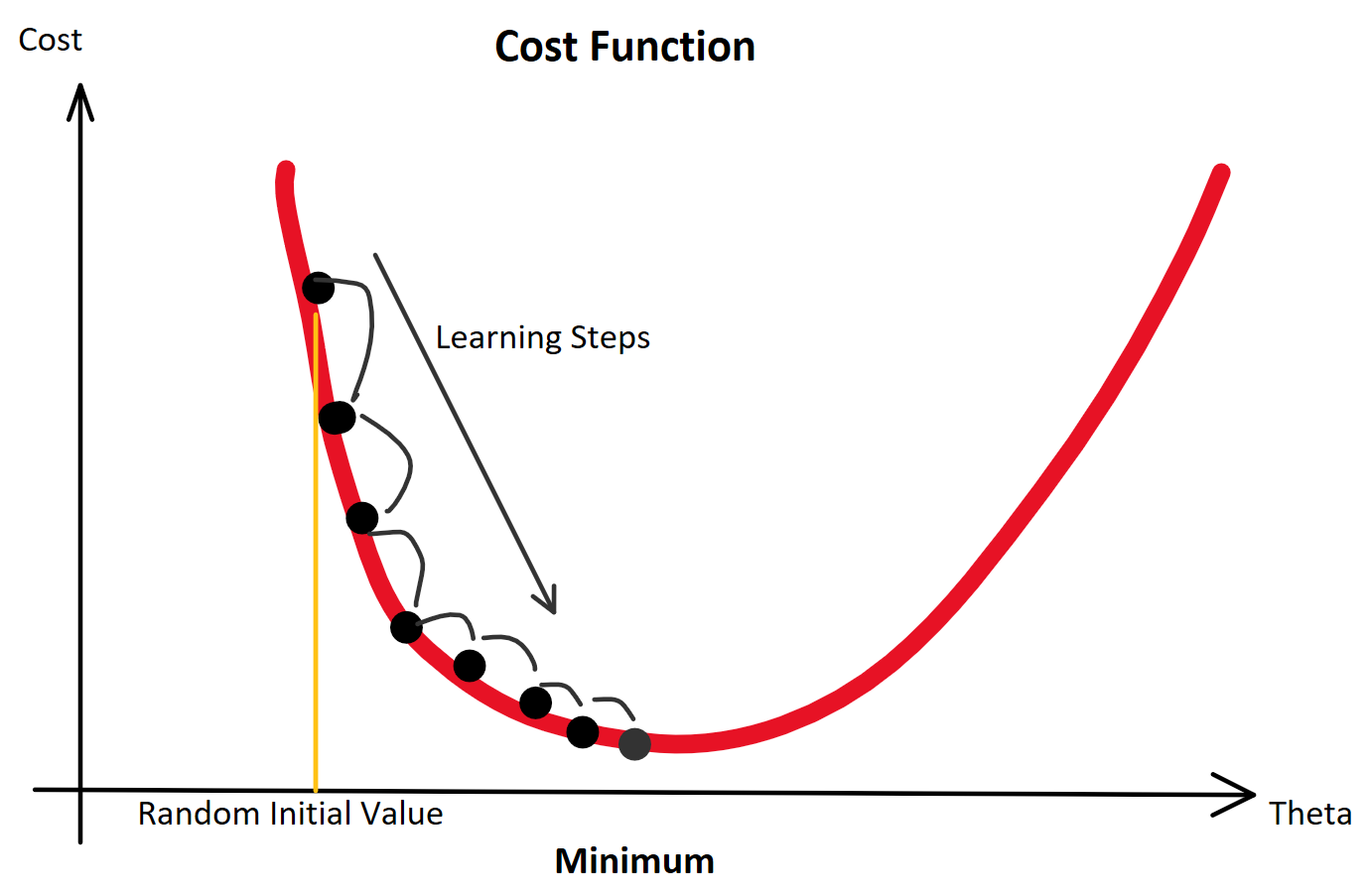
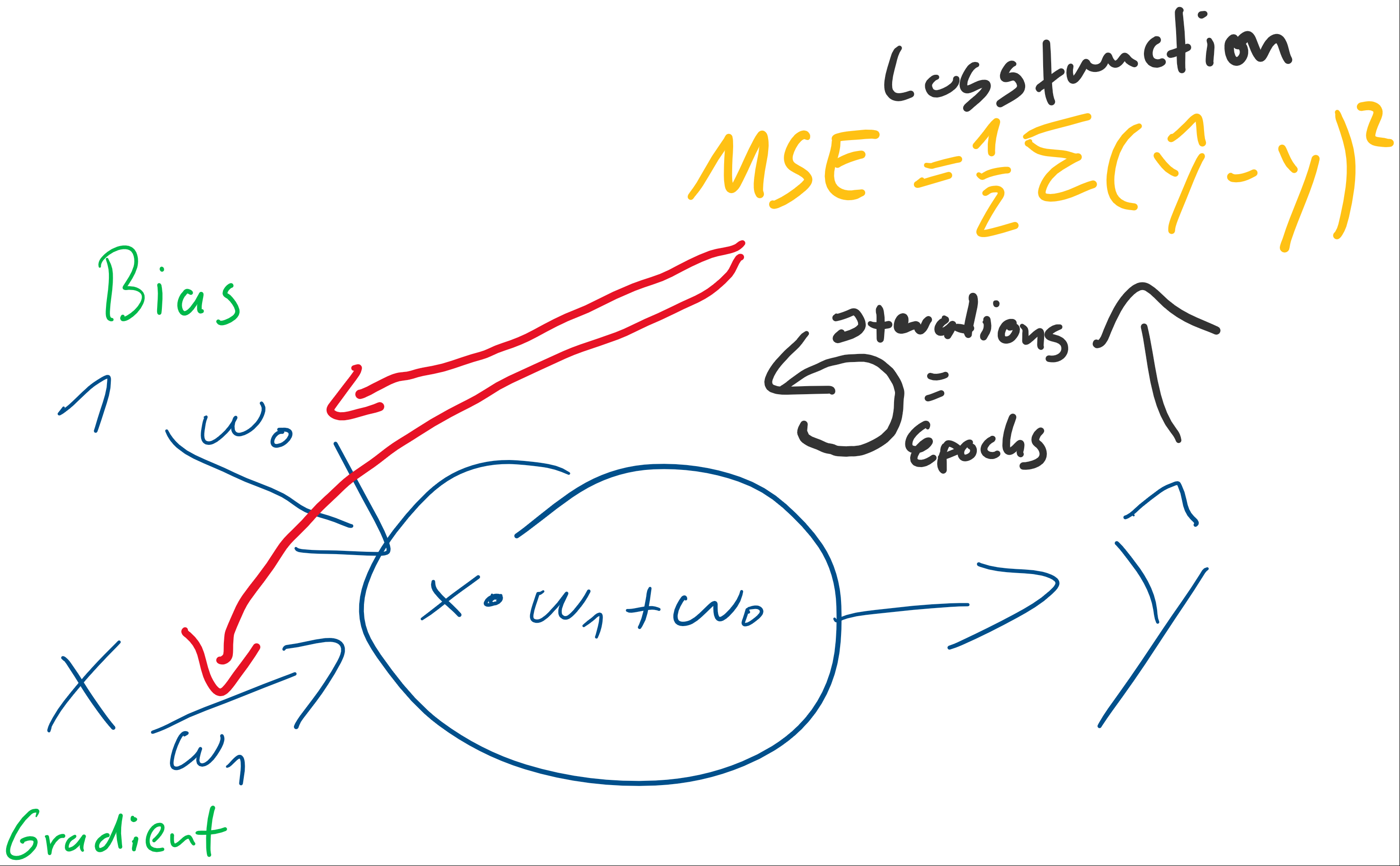
 ) der stets mit einer Eingangskonstante multipliziert und somit als Wert erhalten bleibt. Der Bias ist das Alpha
) der stets mit einer Eingangskonstante multipliziert und somit als Wert erhalten bleibt. Der Bias ist das Alpha  in einer Schulmathe-tauglichen Formel wie
in einer Schulmathe-tauglichen Formel wie  .
. ist die Steigung, der Gradient, der Funktion.
ist die Steigung, der Gradient, der Funktion. und den darauffolgenden Abgleich mit dem tatsächlichen
und den darauffolgenden Abgleich mit dem tatsächlichen  herauszufinden. Anfangs behaupten wir beispielsweise einfach, sowohl
herauszufinden. Anfangs behaupten wir beispielsweise einfach, sowohl  . Folglich wird
. Folglich wird 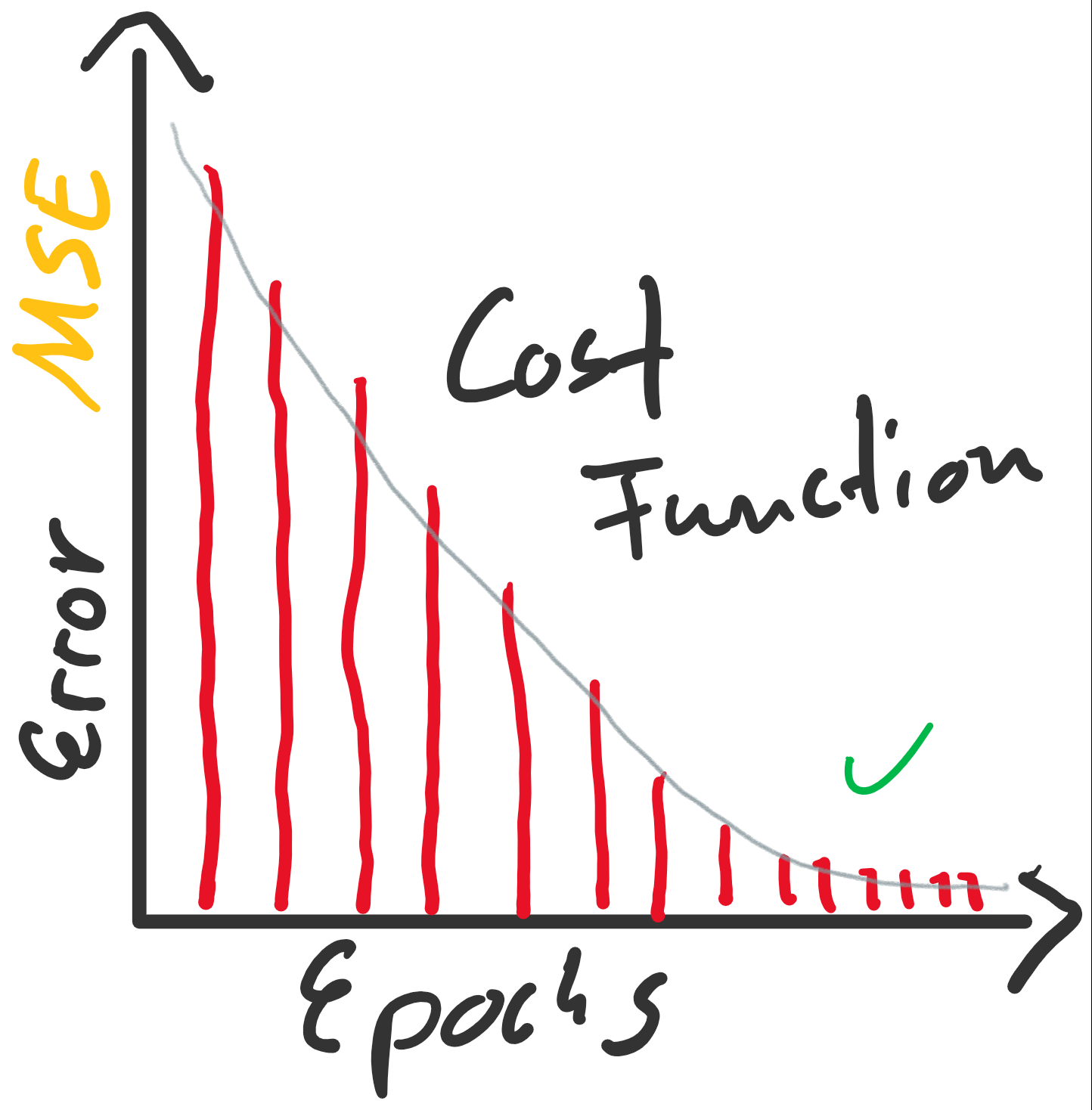



 bzw. partiell nach jedem vorhandenen
bzw. partiell nach jedem vorhandenen  :
:


 am Ende her haben? Das ergibt sie aus der Kettenregel: Die äußere Funktion wurde abgeleitet, so wurde aus
am Ende her haben? Das ergibt sie aus der Kettenregel: Die äußere Funktion wurde abgeleitet, so wurde aus  dann
dann  . Jedoch muss im Sinne eben dieser Kettenregel auch die innere Funktion abgeleitet werden. Da wir nach
. Jedoch muss im Sinne eben dieser Kettenregel auch die innere Funktion abgeleitet werden. Da wir nach  erhalten.
erhalten.
 ist der Gradient der Funktion!)
ist der Gradient der Funktion!)
 (eta) bezeichnet:
(eta) bezeichnet:
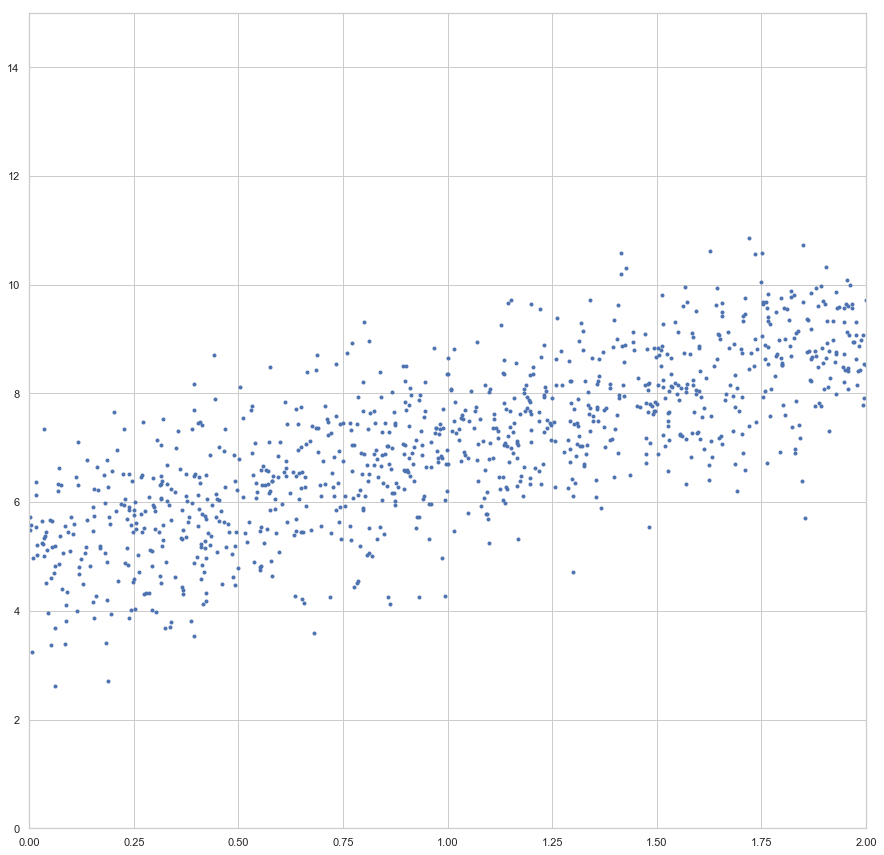
 enthalten sind. Der Fehler ist dann aber sehr groß (sollte maximal sein, im Vergleich zu zukünftigen Epochen). Die Gewichte werden also angepasst, die Gerade somit besser in die Punktwolke platziert. Mit jeder Epoche wird die Gerade erneut in die Punktwolke gelegt, der Gesamtfehler (über alle
enthalten sind. Der Fehler ist dann aber sehr groß (sollte maximal sein, im Vergleich zu zukünftigen Epochen). Die Gewichte werden also angepasst, die Gerade somit besser in die Punktwolke platziert. Mit jeder Epoche wird die Gerade erneut in die Punktwolke gelegt, der Gesamtfehler (über alle 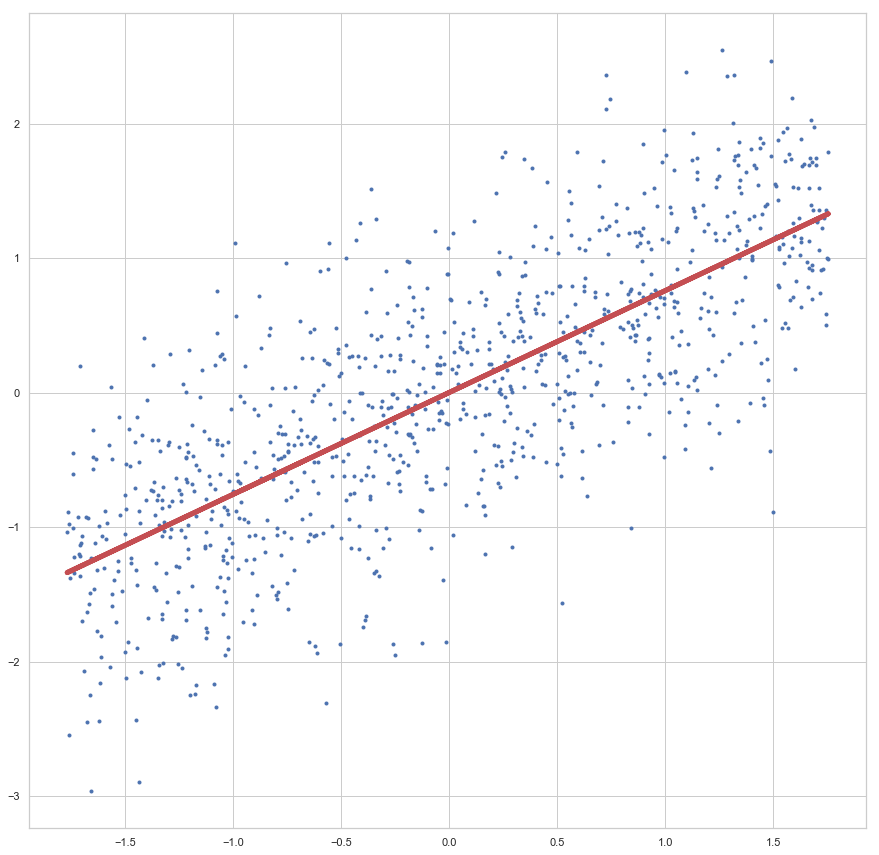
 konvergiert:
konvergiert: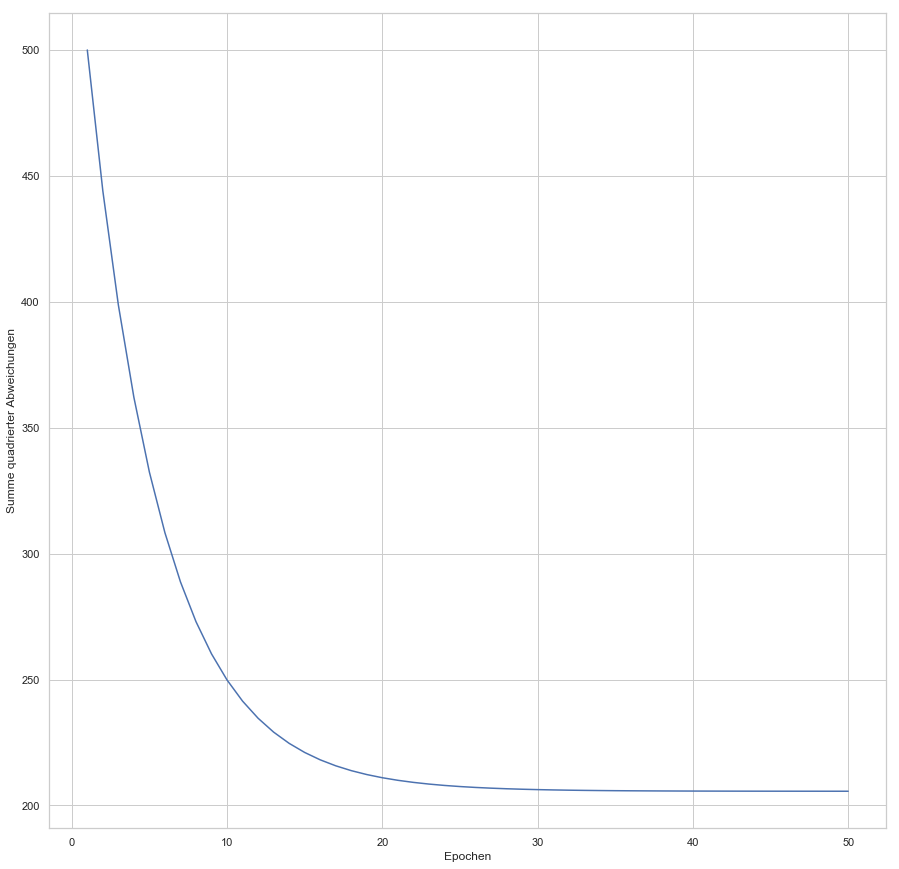






 Prof. Dr. Klaus Jung studierte Physik an der TU Berlin, wo er im Bereich der Mathematischen Physik promovierte. Bis 2008 arbeitete er als Leiter F&E bei der Firma LuraTech im Bereich der Dokumentenverarbeitung und Langzeitarchivierung. In der JPEG-Gruppe leitete er die deutsche Delegation bei der Standardisierung von JPEG2000. Seit 2008 ist er Professor für Medieninformatik an der HTW Berlin mit dem Schwerpunkt „Visual Computing“.
Prof. Dr. Klaus Jung studierte Physik an der TU Berlin, wo er im Bereich der Mathematischen Physik promovierte. Bis 2008 arbeitete er als Leiter F&E bei der Firma LuraTech im Bereich der Dokumentenverarbeitung und Langzeitarchivierung. In der JPEG-Gruppe leitete er die deutsche Delegation bei der Standardisierung von JPEG2000. Seit 2008 ist er Professor für Medieninformatik an der HTW Berlin mit dem Schwerpunkt „Visual Computing“.

