Data Science im Vertrieb – Praxisbeispiel
Wie Sie mit einer automatisierten Lead-Priorisierung zu erfolgreichen Geschäftsabschlüssen kommen.
Die Fragestellung:
Ein Softwareunternehmen generierte durch Marketing- und Sales-Aktivitäten eine große Anzahl potenzieller Leads, die nicht alle gleichzeitig bearbeitet werden konnten. Die zentrale Frage war nun: Wie kann eine Priorisierung der Leads erfolgen, sodass erfolgsversprechende Leads zuerst bearbeitet werden können?
Definition: Ein Lead bezeichnet einen Kontakt zu einem/einer potenziellen Kund:in, die/der sich für ein Produkt oder eine Dienstleistung eines Unternehmens interessiert und deren/dessen Kontaktdaten dem Unternehmen vorliegen. Solche Leads können durch Online- und Offline-Werbemaßnahmen gewonnen werden.
In der Vergangenheit beruhte die Priorisierung und somit auch die Bearbeitung der Leads in dem Unternehmen häufig auf der persönlichen Erfahrung der zuständigen Vertriebsmitarbeiter:innen. Diese Vorgehensweise ist jedoch sehr ressourcenintensiv und stark abhängig von der Erfahrung einzelner Vertriebsmitarbeiter:innen.
Aus diesem Grund beschloss das Unternehmen, ein KI-gestütztes System zu entwickeln, welches zum einen erfolgsversprechende Leads datenbasiert priorisiert und zum anderen Handlungsempfehlungen für die Vertriebsmitarbeiter:innen bereitstellt.
Das Vorgehen:
Grundlage dieses Projektes waren bereits vorhandene Daten zu früheren Leads sowie CRM-Daten zu bereits geschlossenen Aufträgen und Deals mit diesen früheren Leads. Dazu gehörten beispielsweise:
- Firma des Leads
- Firmengröße des Leads
- Branche des Leads
- Akquisekanal, über den der Lead generiert wurde
- Dauer bis Antwort durch Vertriebsmitarbeiter:in
- Wochentag der Antwort
- Kanal der Antwort
Diese Daten aus der Vergangenheit konnten zunächst einer explorativen Datenanalyse unterzogen werden, bei der untersucht wurde, inwiefern die Eigenschaften der Leads und das Verhalten der Vertriebsmitarbeiter:innen in der Vergangenheit einen Einfluss darauf hatten, ob es mit einem Lead zu einem Geschäftsabschluss kam oder nicht.
Diese Erkenntnisse aus den vergangenen Leads sollten jedoch nun auch auf aktuelle bzw. zukünftige Leads und die damit verbundenen Vertriebsaktivitäten übertragen werden. Deshalb ergaben sich aus der explorativen Datenanalyse zwei weiterführende Fragen:
- Durch welche Merkmale zeichnen sich Leads aus, die mit einer hohen Wahrscheinlichkeit zu einem Geschäftsabschluss führen?
- Welche Aktivitäten der Vertriebsmitarbeiter:innen führen zu einem Geschäftsabschluss?
Leads priorisieren
Durch die explorative Datenanalyse konnte das Unternehmen bereits erste Einblicke in die verschiedenen Eigenschaften der Leads erlangen. Bei einigen dieser Eigenschaften ist anzunehmen, dass sie die Wahrscheinlichkeit erhöhen, dass ein:e potenzielle:r Kund:in Interesse am Produkt des Unternehmens zeigt. Es gibt mehrere Wege, um die Erkenntnisse aus der explorativen Datenanalyse nun für zukünftiges Verhalten der Vertriebsmitarbeiter:innen zu nutzen.
Regelbasiertes Vorgehen
Auf Grundlage der explorativen Datenanalyse und der dort gewonnenen Erkenntnisse könnte das Unternehmen, z. B. dessen Vertriebsleitung, bestimmte Regeln oder Kriterien definieren, wie beispielsweise die Unternehmensgröße des Kunden oder die Branche. So könnte die Vertriebsleitung anordnen, dass Leads aus größeren Unternehmen oder aus Unternehmen aus dem Energiesektor priorisiert behandelt werden sollten, weil diese Leads auch in der Vergangenheit zu erfolgreichen Geschäftsabschlüssen geführt haben.
Der Vorteil eines solchen regelbasierten Vorgehens ist, dass es einfach zu definieren und schnell umzusetzen ist.
Der Nachteil ist jedoch, dass die hier definierten Regeln sehr starr sind und dass Menschen meist nicht in der Lage sind, mehr als zwei oder drei der Eigenschaften gleichzeitig zu betrachten. Obwohl sich die Regeln dann zwar grundsätzlich an den Erkenntnissen aus den Daten orientieren, hängen sie doch immer noch stark vom Bauchgefühl der Vertriebsleitung ab.
Clustering
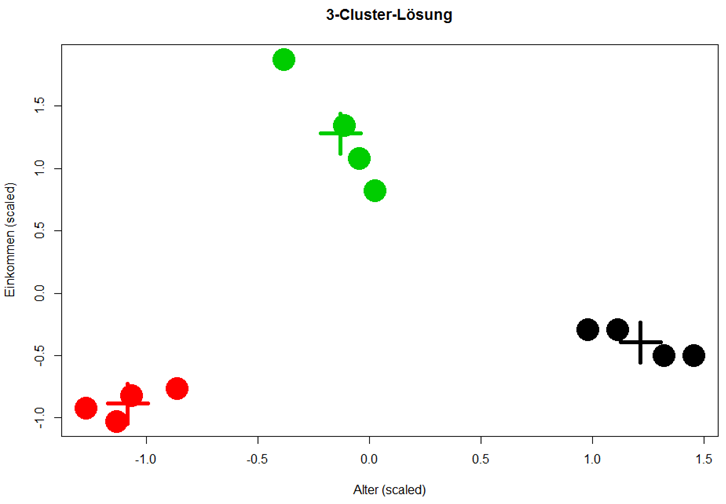
Ein besserer Ansatz war es, die vergangenen Leads anhand aller verfügbaren Eigenschaften in Gruppen einzuteilen, innerhalb derer die Leads sich einander stark ähneln. Hierfür kommt ein maschinelles Lernverfahren namens Clustering zum Einsatz, welches genau dieses Ziel verfolgt: Beim Clustering werden Datenpunkte, also in diesem Falle die Leads, anhand ihrer Eigenschaften, also beispielsweise die Unternehmensgröße oder die Branche, aber auch ob es zu einem Geschäftsabschluss kam oder nicht, zusammengefasst.
Beispiel: Leads aus Unternehmen zwischen 500 und 999 Mitarbeitern aus der Energiebranche kauften 250 Lizenzen der Software A.
Kommt nun ein neuer Lead hinzu, kann er anhand seiner bereits bekannten Eigenschaften einem Cluster zugeordnet werden. Anschließend können die Vertriebsmitarbeiter:innen jene Leads priorisieren, die einem Cluster zugeordnet worden sind, in dem in der Vergangenheit bereits häufig erfolgreich Geschäfte abgeschlossen worden sind.
Der Vorteil eines solchen datenbasierten Vorgehens ist, dass eine Vielzahl an Kriterien gleichzeitig in die Priorisierung einbezogen werden kann.
Erfolgsführende Aktivitäten identifizieren
Process Mining
Im zweiten Schritt wurde eine weitere Frage gestellt: Welche Aktivitäten der Vertriebsmitarbeiter:innen führen zu einem erfolgreichen Geschäftsabschluss mit einem Lead? Dabei standen nicht nur die Leistungen einzelner Mitarbeiter:innen im Fokus, sondern auch die übergreifenden Muster, die beim Vergleich der verschiedenen Mitarbeiter:innen deutlich wurden. Mithilfe von Process Mining konnte festgestellt werden, welche Maßnahmen und Aktivitäten der Vertriebler:innen im Umgang mit einem Lead zum Erfolg bzw. zu einem Misserfolg geführt hatten. Weniger erfolgsversprechende Maßnahmen konnten somit in der Zukunft vermieden werden.
Vor allem zeitliche Aspekte spielten hierbei eine Rolle: Parameter, die aussagten, wie schnell oder an welchem Wochentag Leads eine Antwort erhielten, waren entscheidend für erfolgreiche Geschäftsabschlüsse. Diese Erkenntnisse konnte das Unternehmen dann in zukünftige Sales Trainings sowie die Sales-Strategie einfließen lassen.
Die Ergebnisse
In diesem Projekt konnte die Sales-Abteilung des Softwareunternehmens durch zwei verschiedene Ansätze die Priorisierung der Leads und damit die Geschäftsabschlüsse deutlich verbessern:
- Priorisierung der Leads
Mithilfe des Clustering war es möglich, Leads in Gruppen einzuteilen, die sich in ihren Eigenschaften ähneln, u.a. auch in der Eigenschaft, ob es zu einem Geschäftsabschluss kommt oder nicht. Neue Leads wurden den verschiedenen Clustern zuordnen. Leads, die einem Cluster mit hoher Erfolgswahrscheinlichkeit zugeordnet wurden, konnten nun priorisiert bearbeitet werden.
- Erfolgsversprechende Aktivitäten identifizieren
Mithilfe von Process Mining wurden erfolgsversprechende Aktivitäten der Sales-Mitarbeiter:innen identifiziert und skaliert. Umgekehrt wurden wenig erfolgsversprechende Aktivitäten erkannt und eliminiert, um Ressourcen zu sparen.
Infolgedessen konnte das Softwareunternehmen Leads erfolgreicher bearbeiten und höhere Umsätze erzielen.


 Alter)
Daten
Alter)
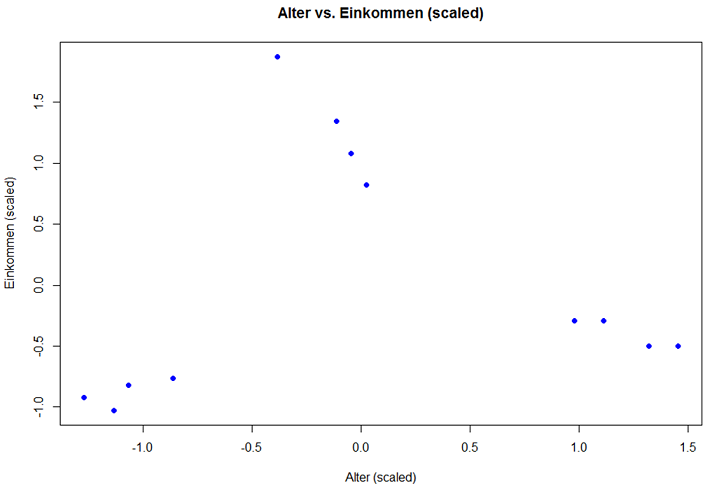
Daten Einkommen)
Einkommen) Einkommen, col = "blue", pch = 19,
xlab = "Alter (scaled)",
ylab = "Einkommen (scaled)",
main = "Alter vs. Einkommen (scaled)")
Einkommen, col = "blue", pch = 19,
xlab = "Alter (scaled)",
ylab = "Einkommen (scaled)",
main = "Alter vs. Einkommen (scaled)")
 totss # Between Cluster Sums of Suqares (BSS)
> KmeansObj
totss # Between Cluster Sums of Suqares (BSS)
> KmeansObj![withinss # Within Cluster Sums of Squares (WSS) [1] 0.7056937 0.1281607 0.1792432 > KmeansObj](https://data-science-blog.com/de/wp-content/ql-cache/quicklatex.com-196c943163c35fd088d838c65700d56c_l3.png "Rendered by QuickLaTeX.com") totss # Between Cluster Sums of Suqares (BSS)
[1] 22
totss # Between Cluster Sums of Suqares (BSS)
[1] 22 totss
}
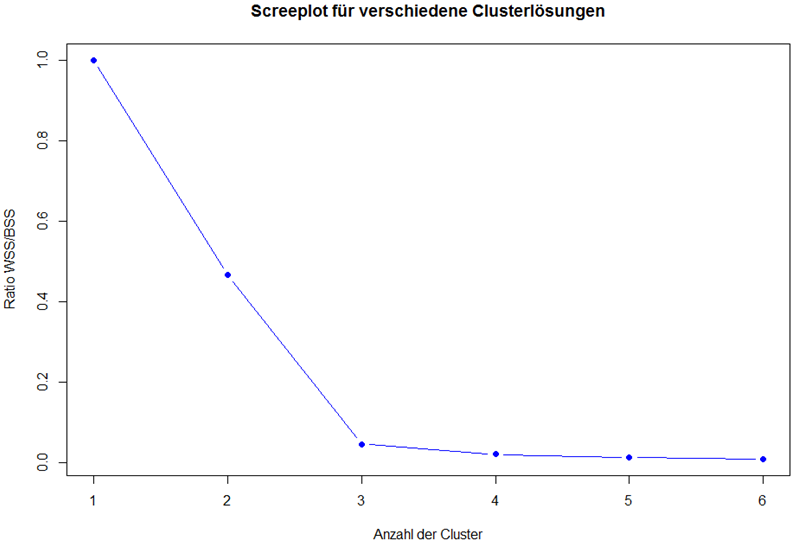
plot(ratio, type = "b",
xlab = "Anzahl der Cluster",
ylab = "Ratio WSS/BSS",
main = "Screeplot für verschiedene Clusterlösungen",
col = "blue", pch = 19)
totss
}
plot(ratio, type = "b",
xlab = "Anzahl der Cluster",
ylab = "Ratio WSS/BSS",
main = "Screeplot für verschiedene Clusterlösungen",
col = "blue", pch = 19)
 centers, col = 1:3, pch = 3, cex = 5, lwd = 5)
centers, col = 1:3, pch = 3, cex = 5, lwd = 5)