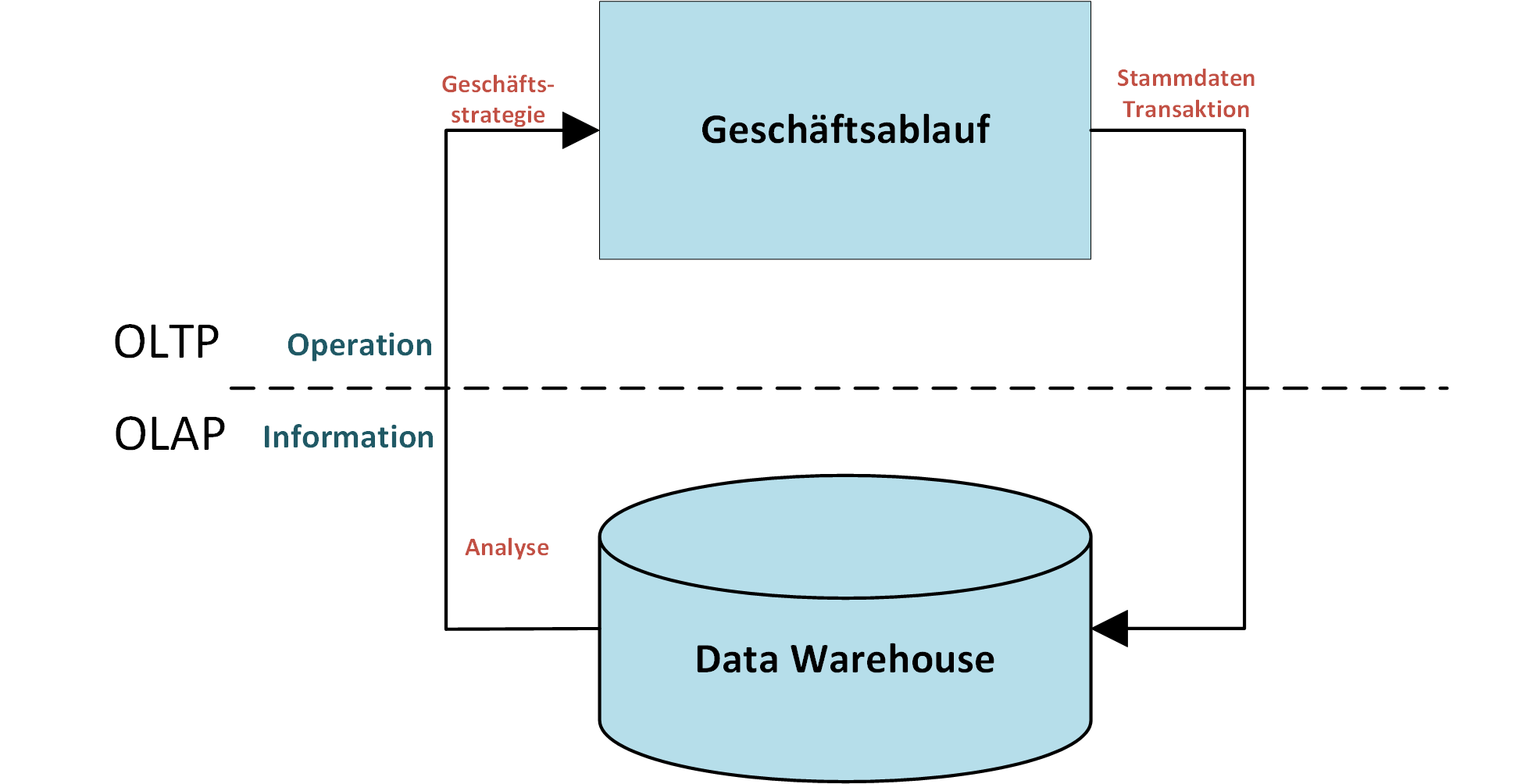
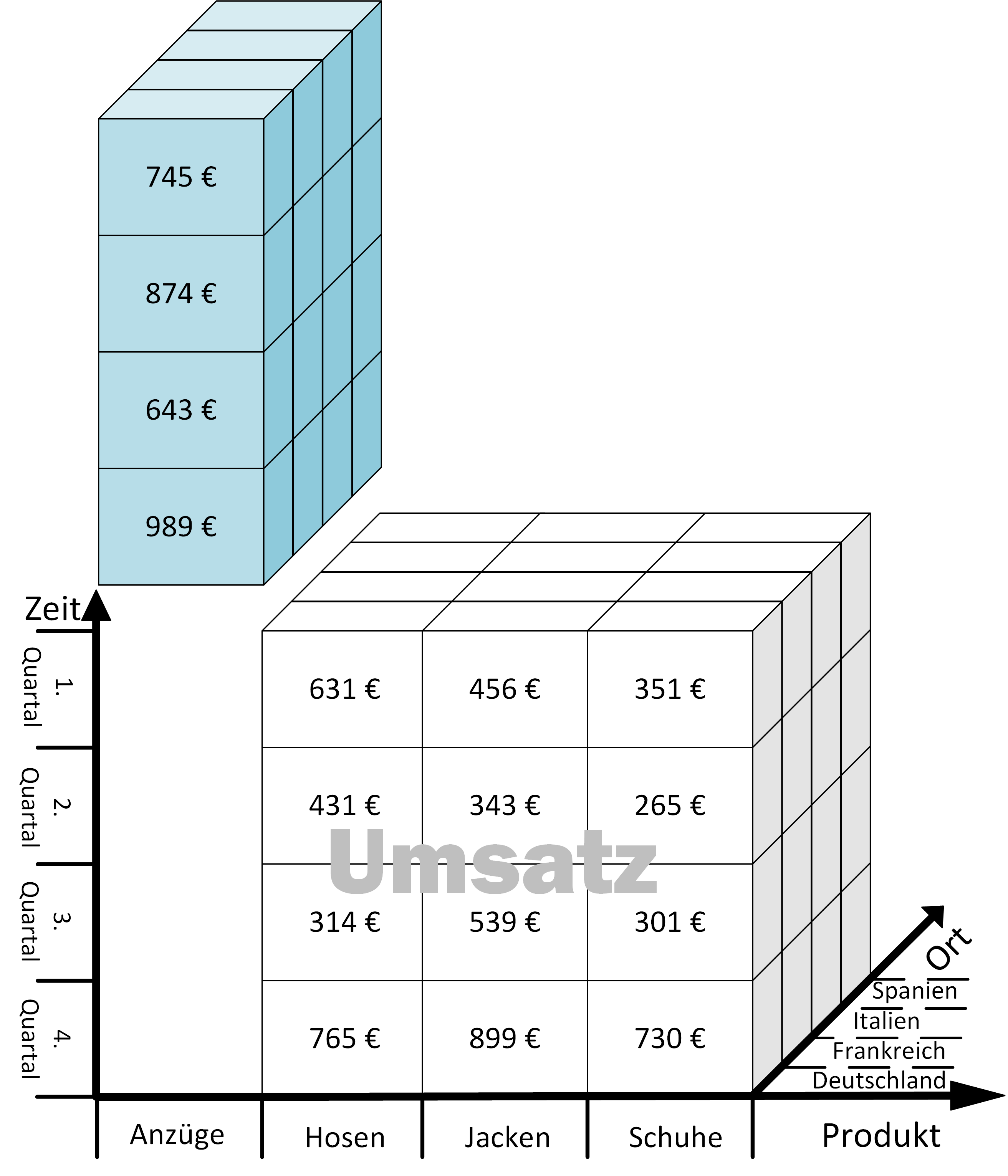
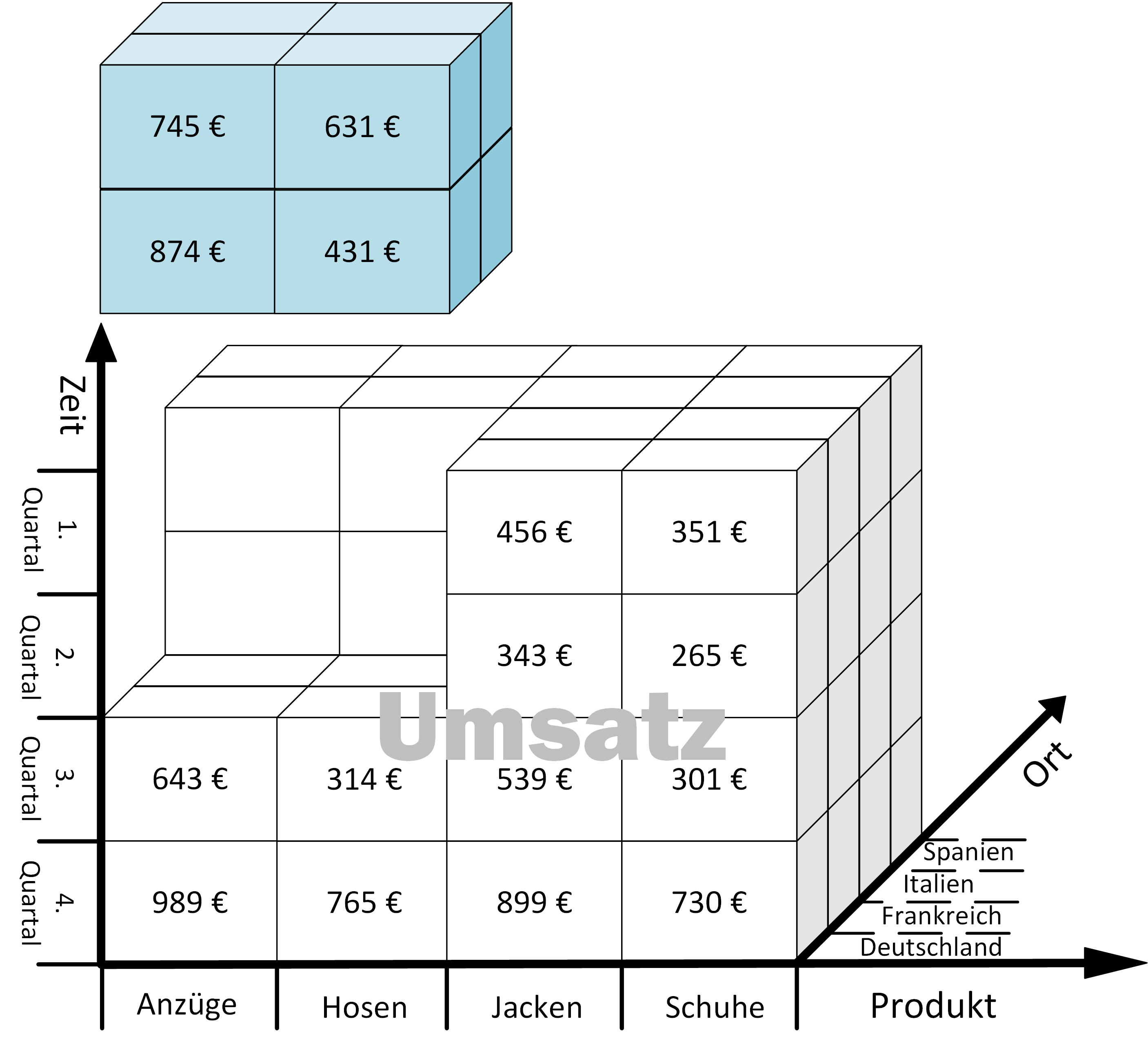
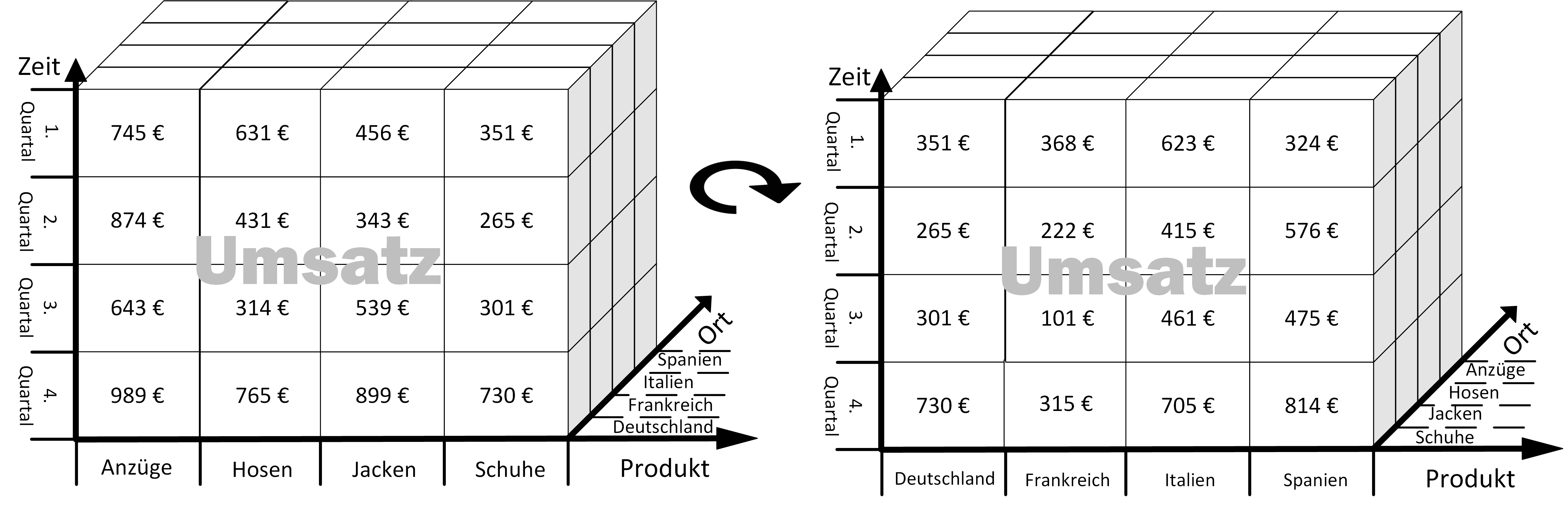
Von BI zu PI: Der nächste Schritt auf dem Weg zu datengetriebenen Entscheidungen
„Alles ist stetig und fortlaufend im Wandel.“ „Das Tempo der Veränderungen nimmt zu.“ „Die Welt wird immer komplexer und Unternehmen müssen Schritt halten.“ Unternehmen jeder Art und Größe haben diese Sätze schon oft gehört – vielleicht zu oft! Und dennoch ist es für den Erfolg eines Unternehmens von entscheidender Bedeutung, sich den Veränderungen anzupassen.
![]() Read this article in English:
Read this article in English:
“From BI to PI: The Next Step in the Evolution of Data-Driven Decisions”
Sie müssen die zugrunde liegenden organisatorischen Bausteine verstehen, um sicherzustellen, dass die von Ihnen getroffenen Entscheidungen sich auch in die richtige Richtung entwickeln. Es geht sozusagen um die DNA Ihres Unternehmens: die Geschäftsprozesse, auf denen Ihre Arbeitsweise basiert, und die alles zu einer harmonischen Einheit miteinander verbinden. Zu verstehen, wie diese Prozesse verlaufen und an welcher Stelle es Verbesserungsmöglichkeiten gibt, kann den Unterschied zwischen Erfolg und Misserfolg ausmachen.
Unternehmen, die ihren Fokus auf Wachstum gesetzt haben, haben dies bereits erkannt. In der Vergangenheit wurde Business Intelligence als die Lösung für diese Herausforderung betrachtet. In jüngerer Zeit sehen sich zukunftsorientierte Unternehmen damit konfrontiert, Lösungen zu überwachen, die mit dem heutigen Tempo der Veränderungen Schritt halten können. Gleichzeitig erkennen diese Unternehmen, dass die zunehmende Komplexität der Geschäftsprozesse dazu führt, dass herkömmliche Methoden nicht mehr ausreichen.
Anpassung an ein sich änderndes Umfeld? Die Herausforderungen von BI
Business Intelligence ist nicht notwendigerweise überholt oder unnötig. In einer schnelllebigen und sich ständig verändernden Welt stehen die BI-Tools und -Lösungen jedoch vor einer Reihe von Herausforderungen. Hierzu können zählen:
- Hohe Datenlatenz – Die Datenlatenz gibt an, wie lange ein Benutzer benötigt, um Daten beispielsweise über ein Business-Intelligence-Dashboard abzurufen. In vielen Fällen kann dies mehr als 24 Stunden dauern. Ein geschäftskritischer Zeitraum, da Unternehmen Geschäftschancen für sich nutzen möchten, die möglicherweise ein begrenztes Zeitfenster haben.
- Unvollständige Datensätze – Business Intelligence verfolgt einen breiten Ansatz, sodass Prüfungen möglicherweise zwar umfassend, aber nicht tief greifend sind. Dies erhöht die Wahrscheinlichkeit, dass Daten übersehen werden; insbesondere in Fällen, in denen die Prüfungsparameter durch die Tools selbst nur schwer geändert werden können.
- Erkennung statt Analyse – Business-Intelligence-Tools sind in erster Linie darauf ausgelegt, Daten zu finden. Der Fokus hierbei liegt vor allem auf Daten, die für ihre Benutzer nützlich sein können. An dieser Stelle endet jedoch häufig die Leistungsfähigkeit der Tools, da sie Benutzern keine einfachen Optionen bieten, die Daten tatsächlich zu analysieren. Die Möglichkeit, umsetzbare Erkenntnisse zu gewinnen, verringert sich somit.
- Eingeschränkte Skalierbarkeit – Im Allgemeinen bleibt Business Intelligence ein Bereich für Spezialisten und Experten mit dem entsprechenden Know-how, über das Mitarbeiter im operativen Bereich oftmals nicht verfügen. Ohne umfangreiches Verständnis für die geschäftlichen Prozesse und deren Analyse innerhalb des Unternehmens bleibt die optimierte Anwendung eines bestimmten Business-Intelligence-Tools aber eingeschränkt.
- Nicht nachvollziehbare Metriken – Werden Metriken verwendet, die nicht mit den Geschäftsprozessen verknüpft sind, kann Business Intelligence kaum positive Veränderungen innerhalb eines Unternehmens unterstützen. Für Benutzer ist es schwierig, Ergebnisse richtig auszuwerten und zu verstehen und diese Ergebnisse zweckdienlich zu nutzen.
Process Intelligence: der nächste wegweisende Schritt
Es bedarf einer effektiveren Methode zur Prozessanalyse, um eine effiziente Arbeitsweise und fundierte Entscheidungsfindung sicherzustellen. An dieser Stelle kommt Process Intelligence (PI) ins Spiel. PI bietet die entscheidenden Hintergrundinformationen für die Beantwortung von Fragen, die mit Business-Intelligence-Tools unbeantwortet bleiben.
Process Intelligence ermöglicht die durchgehende Visualisierung von Prozessabläufen mithilfe von Rohdaten. Mit dem richtigen Process-Intelligence-Tool können diese Rohdaten sofort analysiert werden, sodass Prozesse präzise angezeigt werden. Der Endbenutzer kann diese Informationen nach Bedarf einsehen und bearbeiten, ohne eine Vorauswahl für die Analyse treffen zu müssen.
Zum Vergleich: Da Business Intelligence vordefinierte Analysekriterien benötigt, kann BI nur dann wirklich nützlich sein, wenn diese Kriterien auch definiert sind. Unternehmen können verzögerte Analysen vermeiden, indem sie Process Intelligence zur Ermittlung der Hauptursache von Prozessproblemen nutzen, und dann die richtigen Kriterien zur Bestimmung des Analyserahmens auswählen.
Anschließend können Sie Ihre Systemprozesse analysieren und erkennen die Diskrepanzen und Varianten zwischen dem angestrebten Geschäftsprozess und dem tatsächlichen Verlauf Ihrer Prozesse. Und je schneller Sie Echtzeit-Einblicke in Ihre Prozesse gewinnen, desto schneller können Sie in Ihrem Unternehmen positive Veränderungen auf den Weg bringen.
Kurz gesagt: Business Intelligence eignet sich dafür, ein breites Verständnis über die Abläufe in einem Unternehmen zu gewinnen. Für einige Unternehmen kann dies ausreichend sein. Für andere hingegen ist ein Überblick nicht genug.
Sie suchen nach einer Möglichkeit um festzustellen, wie jeder Prozess in Ihrer Organisation tatsächlich funktioniert? Die Antwort hierauf lautet Software. Software, die Prozesserkennung, Prozessanalyse und Konformitätsprüfung miteinander kombiniert.
Mit den richtigen Process-Intelligence-Tools können Sie nicht nur Daten aus den verschiedenen IT-Systemen in Ihrem Unternehmen gewinnen, sondern auch Ihre End-to-End-Prozesse kontinuierlich überwachen. So erhalten Sie Erkenntnisse über mögliche Risiken und Verbesserungspotenziale. PI steht für einen kollaborativen Ansatz zur Prozessverbesserung, der zu einem bahnbrechenden Verständnis über die Abläufe in Ihrem Unternehmen führt, und wie diese optimiert werden können.
Erhöhtes Potenzial mit Signavio Process Intelligence
Mit Signavio Process Intelligence erhalten Sie wegweisende Erkenntnisse über Ihre Prozesse, auf deren Basis Sie bessere Geschäftsentscheidungen treffen können. Erlangen Sie eine vollständige Sicht auf Ihre Abläufe und ein Verständnis dafür, was in Ihrer Organisation tatsächlich geschieht.
Als Teil der Signavio Business Transformation Suite lässt sich Signavio Process Intelligence perfekt mit der Prozessmodellierung und -automatisierung kombinieren. Als eine vollständig cloudbasierte Process-Mining-Lösung erleichtert es die Software, organisationsweit zusammenzuarbeiten und Wissen zu teilen.
Generieren Sie neue Ideen, sparen Sie Aufwand und Kosten ein und optimieren Sie Ihre Prozesse. Erfahren Sie mehr über Signavio Process Intelligence.