Die Abschätzung von Pi mit Apache Spark
Auf den Berliner Data Science/Big Data/Data Analytics/…-Meetups auf denen ich in letzter Zeit des Öfteren zugegen war, tauchte immer wieder der Begriff Spark auf. Ich wollte wissen was es hiermit auf sich hat. Nachdem ich Spark 1.5.1 lokal auf meinem Mac installiert hatte, fing ich an Wörter in frei verfügbaren Texten zu zählen. Da es mir aber zu aufwändig schien, extrem lange Texte im Internet zu suchen und ich ein Gefühl für die Leistungsfähigkeit von Spark bekommen wollte, widmete ich mich einem skalierbaren Problem: der Abschätzung von Pi mit der Monte Carlo-Methode.
1000 Zufallspunkte lokal auf Mac

Dies war wie zu erwarten keine Herausforderung für meine Hardware. Was passiert bei 10^6/ 10^7/ 10^8/ 10^9… Zufallspunkten?

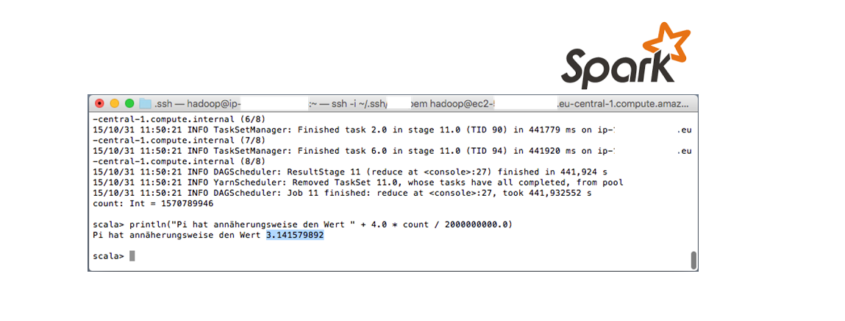
An dieser Stelle stieß ich auf ein “Integer-Problem“. Weil 3*10^9 > 2^31 – 1, kann in diesem Fall nicht mehr der Datentyp Integer verwendet werden, sondern man müsste „long Integer“ (64 bit) nehmen. Was mich nun jedoch viel mehr interessierte als mit Zufallspunkten > 2^31 – 1 zu experimentieren, war eine Spark-Installation auf AWS und die entsprechenden Berechnungszeiten. Ich installierte Spark 1.5.0 (auf Hadoop 2.6.0 YARN) auf einem AWS-Cluster (2 Core/1 Master x m3.xlarge). Zu meiner Überraschung ergab sich Folgendes:

Warum war mein Mac schneller als ein AWS-Cluster? Eine m3.xlarge-Instanz hat 4 Kerne und 15 GB Arbeitsspeicher, mein Mac ziemlich genau die Hälfte… Gut, dann probieren wir das Ganze mal mit einem 4 Core/1 Master x m3.xlarge-Cluster.

Es ergibt sich kein signifikanter Unterschied. Erst die Verwendung von einem 3 Core/1 Master x r3.2xlarge-Cluster brachte eine Beschleunigung. Wo ist der Flaschenhals? Um Netzwerkeffekte zu prüfen, habe ich schließlich eine 0 Core/1 Master-AWS-Installation getestet.

Dieser letzte Test skalierte zu meinen vorherigen Tests auf dem AWS-System, und er wies darauf hin, dass der Flaschenhals kein Netzwerkeffekt war.
Bei heise Developer fand ich einen sehr interessanten Artikel, welcher sich dem Thema „optimale Konfiguration der virtualisierten Cloud-Hardware für den jeweiligen Anwendungsfall finden“ widmet: Benchmarking Spark: Wie sich unterschiedliche Hardware-Parameter auf Big-Data-Anwendungen auswirken
Für heute belasse ich es bei dem vorgestellten Experiment.
To be continued…,