Was bitte soll Data Science bedeuten? Diese Frage bekomme ich häufig von meinen Kunden (überwiegend kaufmännische Leiter größerer Wirtschaftsunternehmen) gestellt. Und überraschenderweise können auch viele IT-affine Professionals, die sich beispielsweise schon mit Business Intelligence auseinandergesetzt haben, noch nichts mit dieser Bezeichnung anfangen.
Data Science ist eine recht neue Bezeichnung und entstammt – wie nicht anders zu vermuten – aus dem angelsächsischen Sprachraum, genau wie auch Business Intelligence und Big Data Analytics. Da bei ist meiner Meinung nach Data Science ein vergleichsweise sehr treffender Name (wesentlich besser als etwa der irreführende Begriff Big Data). Zwar besagt ein Blick auf Wikipedia zum Thema, dass Data Science als Begriff schon fast ein halbes Jahrhundert existiert, aber so richtig in Verwendung ist es eigentlich erst seit einem halben Jahrzehnt, bestenfalls.
bei ist meiner Meinung nach Data Science ein vergleichsweise sehr treffender Name (wesentlich besser als etwa der irreführende Begriff Big Data). Zwar besagt ein Blick auf Wikipedia zum Thema, dass Data Science als Begriff schon fast ein halbes Jahrhundert existiert, aber so richtig in Verwendung ist es eigentlich erst seit einem halben Jahrzehnt, bestenfalls.
Data Science als angewandte Wissenschaft
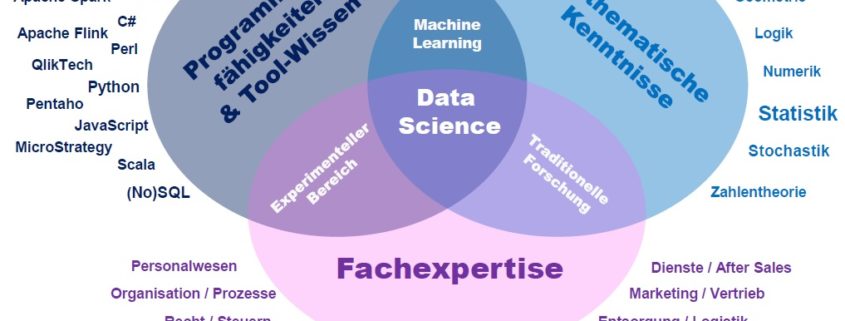
Das Science in Data Science deutet ganz klar auf Wissenschaft hin, auch wenn – meiner Meinung nach – der Begriff wissenschaftlich im Deutschen etwas strenger verwendet wird als Science im Englischen. Data Science hat seinen Ursprung tatsächlich in der Wissenschaft und ist z. B. in der Astronomie, Biologie, Medizin sowie den verschiedensten Sozialwissenschaften längst nicht mehr wegzudenken, hat jedoch auch den Weg in die Geschäftswelt gefunden. Die Data Science Methoden kommen aus der Informatik bzw. Mathematik und werden im Rahmen von universitären Forschungsprojekten weiterentwickelt. Die Methoden können mit etwas Hintergrundverständnis quasi von jedermann angewendet werden. Data Science ist vor allem eine angewandte Wissenschaft, in die jeder Anwender beliebig tief eintauchen kann.
Data Science und die Interdisziplinarität
Eine wichtige Disziplin im Data Science ist die Mathematik, davon insbesondere die Stochastik (Wahrscheinlichkeitstheorie und Statistik). Die Grundlagen der Datenanalyse zur Beschreibung von Sachverhalten erfolgt dabei mit den Methoden der deskriptiven Statistik. Bei der Generierung von neuen Erkenntnissen direkt aus Datenmengen heraus (Data Mining bzw. explorative Datenanalyse), wird von der explorativen Statistik ermöglicht. Die induktive Statistik geht noch einen Schritt weiter und ermöglicht Schätzverfahren bzw. Prognosen über zukünftige Ereignisse (Predictive Analytics). Neben den stochastischen Methoden spielen aber auch andere Bereiche der Mathematik eine Rolle, wie etwa die lineare Optimierung oder Systeme der künstlichen Intelligenz.
Mathematik ist jedoch längst nicht alles, was im Data Science eine Rolle spielt, denn mindestens ebenso wichtig ist Wissen über Datenverarbeitung (früher als EDV bekannt). Um Daten analysieren zu können, muss auf diese erstmal zugegriffen werden können, ggf. müssen diese auch überhaupt erstmal gesammelt werden. Zum Data Science gehören mindestens Grundkenntnisse über relationale Datenbanken und die Structured Query Language (SQL) auf jeden Fall dazu. Insbesondere im aktuellen Big Data Kontext, spielen aber vermehrt auch andersartige Datenbanken (sogenannte NoSQL-Datenbanken) eine wichtige Rolle, denn diese Datenbanken eignen sich zur Speicherung von besonders großen und/oder unstrukturierten Datenmengen.
Die besten Erkenntnisse bringen oftmals Datenanalysen über Daten aus unterschiedlichsten Datenquellen, welche über Extract-Transform-Load-Strecken (ETL) zusammen geführt werden. Die eigentlichen Analysen können mit verschiedensten Tools durchgeführt werden oder aber über dutzende Programmiersprachen. Wissen um Tools rund um ETL und Datenanalysen beschleunigen den Arbeitsalltag, stoßen jedoch schnell an gewisse Grenzen, bei denen man mit Programmiersprachen ansetzen muss. Im Data Science spielt Software Engineering grundsätzlich keine Rolle. Ein Data Scientist muss sich also für gewöhnlich keine Gedanken über eine Software-Architektur oder GUI-Entwürfe machen, auch spielt für Ihn Software-Sicherheit oder -Ergonomie keine entscheidende Rolle. Im Data Science kommen überwiegend Script-Sprachen (z. B. R, Perl oder Python) zum Einsatz. Sauberer Quellcode jedoch, ist auch im Data Science wichtig, da die Analyse und somit auch die Ergebnisse reproduzierbar bleiben müssen.
Neben der Mathematik und dem Wissen um IT, gibt es jedoch noch einen dritten Bereich, der im Data Science eine wirklich wichtige Rolle spielt: Die eigentliche Substanzwissenschaft. Es versteht sich von selbst, dass z. B. Datenanalyse für medizinische Zwecke nur effektiv nur von jemanden durchgeführt werden können, der über eine entsprechende medizinische Kompetenz verfügt. Genauso gut aber, ist Wissen über die Betriebswirtschaft und das aktuelle Geschäftsgeschehen von entscheidender Bedeutung, wenn es um Datenanalyse zum Zwecke der Geschäftsoptimierung (Business Analytics) geht.