Aus der Datenflut das Beste machen – Zertifikatskurs „Data Science“ in Brandenburg
Die Aufbereitung von Daten, ihre Analyse und Darstellung sind mittlerweile zu einer Wissenschaft für sich geworden – „Data Science“. Unternehmen sehen sich heute unabhängig von ihrer Größe von einer Vielzahl unterschiedlicher Daten herausgefordert: Neben klassischen Transaktionsdaten stehen heute z.B. Daten aus der Logistik (RFID, GIS), aus sozialen Medien, dem Internet der Dinge oder öffentlichen Quellen (Open Data / Public Data) zur Verfügung. Ein neuer Zertifikatskurs Data Science ermöglicht jetzt eine wissenschaftliche Weiterbildung zur Nutzung von Daten als „Rohstoff des 21. Jahrhunderts“.
Die Agentur für wissenschaftliche Weiterbildung und Wissenstransfer (AWW e.V.) bietet in Kooperation mit der Fachhochschule Brandenburg den berufsbegleitenden Zertifikatskurs mit nur wenigen Präsenzphasen ab Oktober an. Die wissenschaftliche Leitung hat Dr. Peter Lauf übernommen, ein erfahrener Praktiker, der zurzeit noch eine Professur für Quantitative Methoden und Data Mining an der Hochschule für Technik und Wirtschaft Berlin vertritt. Zertifiziert wird der Abschluss Data Scientist (FH).
Die Weiterbildung hat nur wenige Präsenzphasen an Freitagen und Samstagen und ist daher für Teilnehmer/innen aus dem ganzen Bundesgebiet geeignet – So kommen einige Teilnehmer auch aus Frankfurt am Main und München.
Wer sich schnell entscheidet, kann bis 16. Juli 2015 vom Frühbucherrabatt profitieren!
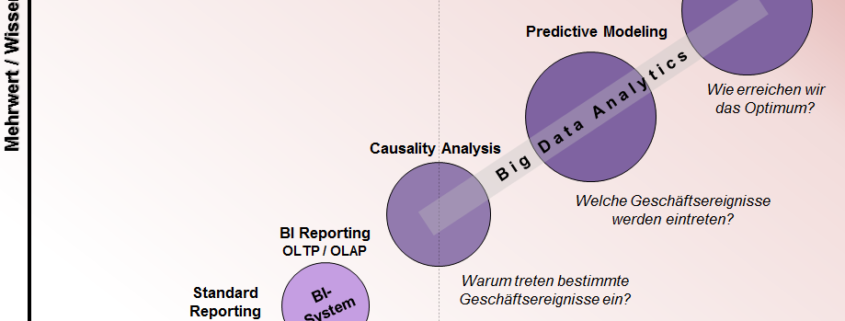
Der Inhalt des Kurses orientiert sich an einer bekannten Einteilung des amerikanischen Wirtschaftswissenschaftlers und Google-Chefökonomen Hal Varian: Ihm zufolge setzt sich die spezifische Wertschöpfungskette von Daten aus Zugriff, Verständnis, Verarbeitung, Analyse und Ergebniskommunikation zusammen. Data Science umfasst deshalb die Module Data Engineering (Zugriff, Verständnis, Verarbeitung), Quantitative Methoden und Data Mining (Analyse) sowie Storytelling: Kommunikation und Visualisierung der Ergebnisse (Ergebniskommunikation).
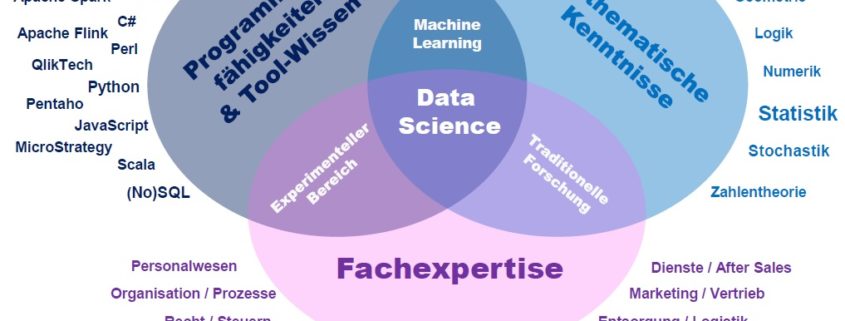
Die Weiterbildung vereinigt damit Fachwissen aus der Informatik mit quantitativen Methoden und Aspekten des Informations- und Kommunikationsdesigns. Wichtige Werkzeuge im Kurs sind die Statistiksprache R und Power Business Intelligence Tools. Auch auf Azure Machine Learning wird mit konkreten Beispielen Bezug genommen. Im Ergebnis sollen die Teilnehmer verschiedene Techniken zur Nutzung von Daten beherrschen und einen Überblick über die Voraussetzungen und möglichen Lösungsansätze im Bereich datengetriebener Projekte erhalten. Lernziel ist die reibungslose Kommunikation zwischen Management, Engineering und Administration.
Weitere Auskünfte erteilt Katja Kersten (Tel. 03381 – 355 754, E-Mail: katja.kersten@fh-brandenburg.de). Nähere Informationen im Internet sind unter www.aww-brandenburg.de erhältlich.