Moderne Business Intelligence in der Microsoft Azure Cloud
Google, Amazon und Microsoft sind die drei großen Player im Bereich Cloud Computing. Die Cloud kommt für nahezu alle möglichen Anwendungsszenarien infrage, beispielsweise dem Hosting von Unternehmenssoftware, Web-Anwendungen sowie Applikationen für mobile Endgeräte. Neben diesen Klassikern spielt die Cloud jedoch auch für Internet of Things, Blockchain oder Künstliche Intelligenz eine wichtige Rolle als Enabler. In diesem Artikel beleuchten wir den Cloud-Anbieter Microsoft Azure mit Blick auf die Möglichkeiten des Aufbaues eines modernen Business Intelligence oder Data Platform für Unternehmen.
Eine Frage der Architektur
Bei der Konzeptionierung der Architektur stellen sich viele Fragen:
- Welche Datenbank wird für das Data Warehouse genutzt?
- Wie sollten ETL-Pipelines erstellt und orchestriert werden?
- Welches BI-Reporting-Tool soll zum Einsatz kommen?
- Müssen Daten in nahezu Echtzeit bereitgestellt werden?
- Soll Self-Service-BI zum Einsatz kommen?
- … und viele weitere Fragen.
1 Die Referenzmodelle für Business Intelligence Architekturen von Microsoft Azure
Die vielen Dienste von Microsoft Azure erlauben unzählige Einsatzmöglichkeiten und sind selbst für Cloud-Experten nur schwer in aller Vollständigkeit zu überblicken. Microsoft schlägt daher verschiedene Referenzmodelle für Datenplattformen oder Business Intelligence Systeme mit unterschiedlichen Ausrichtungen vor. Einige davon wollen wir in diesem Artikel kurz besprechen und diskutieren.
1a Automatisierte Enterprise BI-Instanz
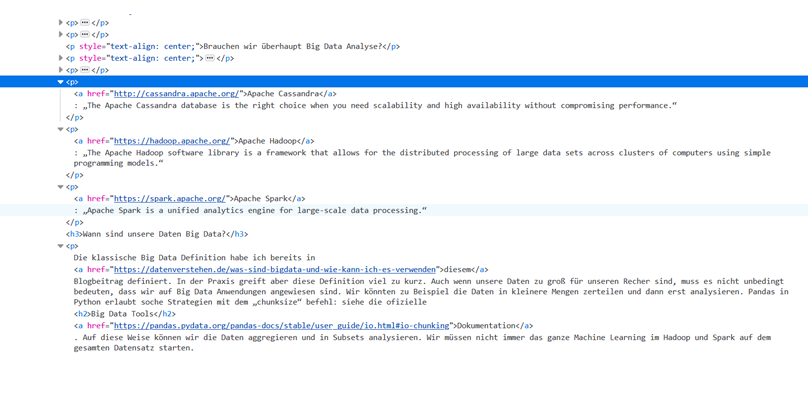
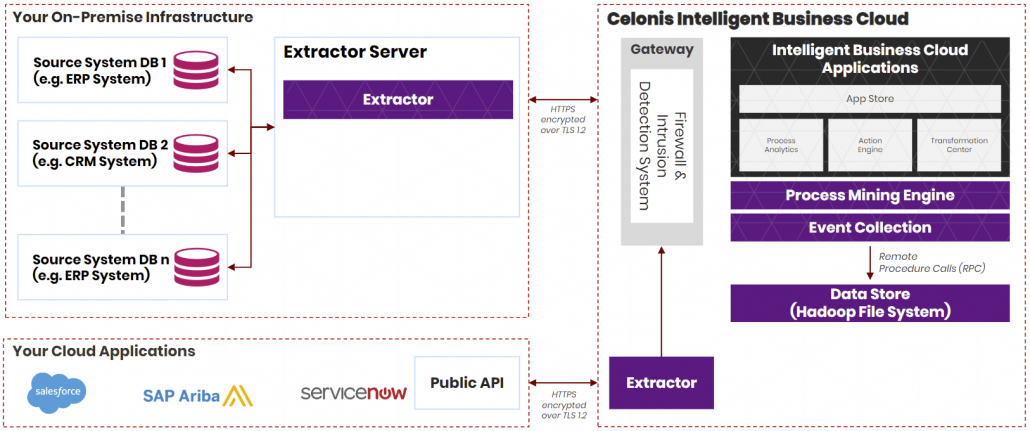
Diese Referenzarchitektur für automatisierte und eher klassische BI veranschaulicht die Vorgehensweise für inkrementelles Laden in einer ELT-Pipeline mit dem Tool Data Factory. Data Factory ist der Cloud-Nachfolger des on-premise ETL-Tools SSIS (SQL Server Integration Services) und dient nicht nur zur Erstellung der Pipelines, sondern auch zur Orchestrierung (Trigger-/Zeitplan der automatisierten Ausführung und Fehler-Behandlung). Über Pipelines in Data Factory werden die jeweils neuesten OLTP-Daten inkrementell aus einer lokalen SQL Server-Datenbank (on-premise) in Azure Synapse geladen, die Transaktionsdaten dann in ein tabellarisches Modell für die Analyse transformiert, dazu wird MS Azure Analysis Services (früher SSAS on-premis) verwendet. Als Tool für die Visualisierung der Daten wird von Microsoft hier und in allen anderen Referenzmodellen MS PowerBI vorgeschlagen. MS Azure Active Directory verbindet die Tools on Azure über einheitliche User im Active Directory Verzeichnis in der Azure-Cloud.
 https://docs.microsoft.com/en-us/azure/architecture/reference-architectures/data/enterprise-bi-adfQuelle:
https://docs.microsoft.com/en-us/azure/architecture/reference-architectures/data/enterprise-bi-adfQuelle: Einige Diskussionspunkte zur BI-Referenzarchitektur von MS Azure
Der von Microsoft vorgeschlagenen Referenzarchitektur zu folgen kann eine gute Idee sein, ist jedoch tatsächlich nur als Vorschlag – eher noch als Kaufvorschlag – zu betrachten. Denn Unternehmens-BI ist hochgradig individuell und Bedarf einiger Diskussion vor der Festlegung der Architektur.
Azure Data Factory als ETL-Tool
Azure Data Factory wird in dieser Referenzarchitektur als ETL-Tool vorgeschlagen. In der Tat ist dieses sehr mächtig und rein über Mausklicks bedienbar. Darüber hinaus bietet es die Möglichkeit z. B. über Python oder Powershell orchestriert und pipeline-modelliert zu werden. Der Clue für diese Referenzarchitektur ist der Hinweis auf die On-Premise-Datenquellen. Sollte zuvor SSIS eingesetzt werden sollen, können die SSIS-Packages zu Data Factory migriert werden.
Die Auswahl der Datenbanken
Der Vorteil dieser Referenzarchitektur ist ohne Zweifel die gute Aufstellung der Architektur im Hinblick auf vielseitige Einsatzmöglichkeiten, so werden externe Daten (in der Annahme, dass diese un- oder semi-strukturiert vorliegen) zuerst in den Azure Blob Storage oder in den auf dem Blob Storage beruhenden Azure Data Lake zwischen gespeichert, bevor sie via Data Factory in eine für Azure Synapse taugliche Struktur transformiert werden können. Möglicherweise könnte auf den Blob Storage jedoch auch gut verzichtet werden, solange nur Daten aus bekannten, strukturierten Datenbanken der Vorsysteme verarbeitet werden. Als Staging-Layer und für Datenhistorisierung sind der Azure Blob Storage oder der Azure Data Lake jedoch gute Möglichkeiten, da pro Dateneinheit besonders preisgünstig.
Azure Synapse ist eine mächtige Datenbank mindestens auf Augenhöhe mit zeilen- und spaltenorientierten, verteilten In-Memory-Datenbanken wie Amazon Redshift, Google BigQuery oder SAP Hana. Azure Synapse bietet viele etablierte Funktionen eines modernen Data Warehouses und jährlich neue Funktionen, die zuerst als Preview veröffentlicht werden, beispielsweise der Einsatz von Machine Learning direkt auf der Datenbank.
Zur Diskussion steht jedoch, ob diese Funktionen und die hohe Geschwindigkeit (bei richtiger Nutzung) von Azure Synapse die vergleichsweise hohen Kosten rechtfertigen. Alternativ können MySQL-/MariaDB oder auch PostgreSQL-Datenbanken bei MS Azure eingesetzt werden. Diese sind jedoch mit Vorsicht zu nutzen bzw. erst unter genauer Abwägung einzusetzen, da sie nicht vollständig von Azure Data Factory in der Pipeline-Gestaltung unterstützt werden. Ein guter Kompromiss kann der Einsatz von Azure SQL Database sein, der eigentliche Nachfolger der on-premise Lösung MS SQL Server. MS Azure Snypase bleibt dabei jedoch tatsächlich die Referenz, denn diese Datenbank wurde speziell für den Einsatz als Data Warehouse entwickelt.
Zentrale Cube-Generierung durch Azure Analysis Services
Zur weiteren Diskussion stehen könnte MS Azure Analysis Sevice als Cube-Engine. Diese Cube-Engine, die ursprünglich on-premise als SQL Server Analysis Service (SSAS) bekannt war, nun als Analysis Service in der Azure Cloud verfügbar ist, beruhte früher noch als SSAS auf der Sprache MDX (Multi-Dimensional Expressions), eine stark an SQL angelehnte Sprache zum Anlegen von schnellen Berechnungsformeln für Kennzahlen im Cube-Datenmodellen, die grundlegendes Verständnis für multidimensionale Abfragen mit Tupeln und Sets voraussetzt. Heute wird statt MDX die Sprache DAX (Data Analysis Expression) verwendet, die eher an Excel-Formeln erinnert (diesen aber keinesfalls entspricht), sie ist umfangreicher als MDX, jedoch für den abitionierten Anwender leichter verständlich und daher für Self-Service-BI geeignet.
Punkt der Diskussion ist, dass der Cube über den Analysis-Service selbst keine Möglichkeiten eine Self-Service-BI nicht ermöglicht, da die Bearbeitung des Cubes mit DAX nur über spezielle Entwicklungsumgebungen möglich ist (z. B. Visual Studio). MS Power BI selbst ist ebenfalls eine Instanz des Analysis Service, denn im Kern von Power BI steckt dieselbe Engine auf Basis von DAX. Power BI bietet dazu eine nutzerfreundliche UI und direkt mit mausklickbaren Elementen Daten zu analysieren und Kennzahlen mit DAX anzulegen oder zu bearbeiten. Wird im Unternehmen absehbar mit Power BI als alleiniges Analyse-Werkzeug gearbeitet, ist eine separate vorgeschaltete Instanz des Azure Analysis Services nicht notwendig. Der zur Abwägung stehende Vorteil des Analysis Service ist die Nutzung des Cubes in Microsoft Excel durch die User über Power Pivot. Dies wiederum ist eine eigene Form des sehr flexiblen Self-Service-BIs.
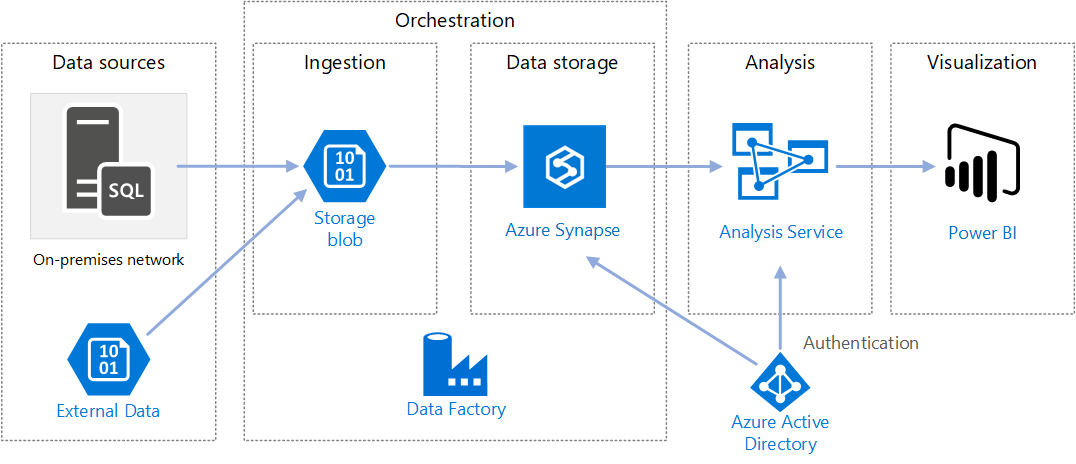
1b Enterprise Data Warehouse-Architektur
Eine weitere Referenz-Architektur von Microsoft auf Azure ist jene für den Einsatz als Data Warehouse, bei der Microsoft Azure Synapse den dominanten Part von der Datenintegration über die Datenspeicherung und Vor-Analyse übernimmt.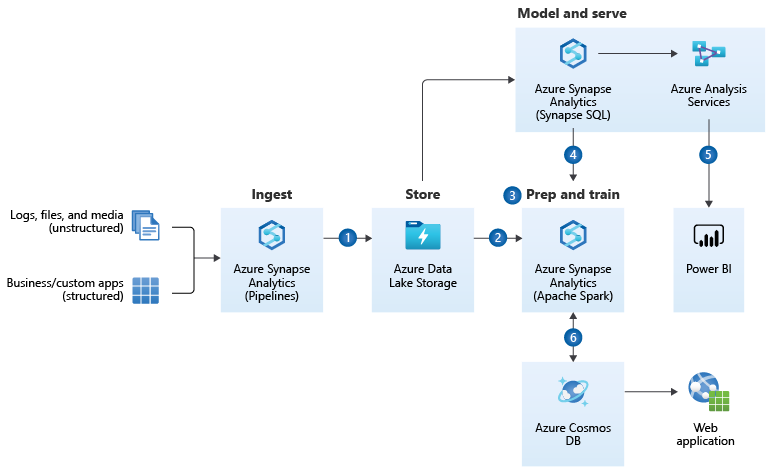 https://docs.microsoft.com/en-us/azure/architecture/solution-ideas/articles/enterprise-data-warehouseQuelle:
https://docs.microsoft.com/en-us/azure/architecture/solution-ideas/articles/enterprise-data-warehouseQuelle:
Diskussionspunkte zum Referenzmodell der Enterprise Data Warehouse Architecture
Auch diese Referenzarchitektur ist nur für bestimmte Einsatzzwecke in dieser Form sinnvoll.
Azure Synapse als ETL-Tool
Im Unterschied zum vorherigen Referenzmodell wird hier statt auf Azure Data Factory auf Azure Synapse als ETL-Tool gesetzt. Azure Synapse hat die Datenintegrationsfunktionalitäten teilweise von Azure Data Factory geerbt, wenn gleich Data Factory heute noch als das mächtigere ETL-Tool gilt. Azure Synapse entfernt sich weiter von der alten SSIS-Logik und bietet auch keine Integration von SSIS-Paketen an, zudem sind einige Anbindungen zwischen Data Factory und Synapse unterschiedlich.
Auswahl der Datenbanken
Auch in dieser Referenzarchitektur kommt der Azure Blob Storage als Zwischenspeicher bzw. Staging-Layer zum Einsatz, jedoch im Mantel des Azure Data Lakes, der den reinen Speicher um eine Benutzerebene erweitert und die Verwaltung des Speichers vereinfacht. Als Staging-Layer oder zur Datenhistorisierung ist der Blob Storage eine kosteneffiziente Methode, darf dennoch über individuelle Betrachtung in der Notwendigkeit diskutiert werden.
Azure Synapse erscheint in dieser Referenzarchitektur als die sinnvolle Lösung, da nicht nur die Pipelines von Synapse, sondern auch die SQL-Engine sowie die Spark-Engine (über Python-Notebooks) für die Anwendung von Machine Learning (z. B. für Recommender-Systeme) eingesetzt werden können. Hier spielt Azure Synpase die Möglichkeiten als Kern einer modernen, intelligentisierbaren Data Warehouse Architektur voll aus.
Azure Analysis Service
Auch hier wird der Azure Analysis Service als Cube-generierende Maschinerie von Microsoft vorgeschlagen. Hier gilt das zuvor gesagte: Für den reinen Einsatz mit Power BI ist der Analysis Service unnötig, sollen Nutzer jedoch in MS Excel komplexe, vorgerechnete Analysen durchführen können, dann zahlt sich der Analysis Service aus.
Azure Cosmos DB
Die Azure Cosmos DB ist am nächsten vergleichbar mit der MongoDB Atlas (die Cloud-Version der eigentlich on-premise zu hostenden MongoDB). Es ist eine NoSQL-Datenbank, die über Datendokumente im JSON-File-Format auch besonders große Datenmengen in sehr hoher Geschwindigkeit abfragen kann. Sie gilt als die zurzeit schnellste Datenbank in Sachen Lesezugriff und spielt dabei alle Vorteile aus, wenn es um die massenweise Bereitstellung von Daten in andere Applikationen geht. Unternehmen, die ihren Kunden mobile Anwendungen bereitstellen, die Millionen parallele Datenzugriffe benötigen, setzen auf Cosmos DB.
1c Referenzarchitektur für Realtime-Analytics
Die Referenzarchitektur von Microsoft Azure für Realtime-Analytics wird die Referenzarchitektur für Enterprise Data Warehousing ergänzt um die Aufnahme von Data Streaming.
Diskussionspunkte zum Referenzmodell für Realtime-Analytics
Diese Referenzarchitektur ist nur für Einsatzszenarios sinnvoll, in denen Data Streaming eine zentrale Rolle spielt. Bei Data Streaming handelt es sich, vereinfacht gesagt, um viele kleine, ereignis-getriggerte inkrementelle Datenlade-Vorgänge bzw. -Bedarfe (Events), die dadurch nahezu in Echtzeit ausgeführt werden können. Dies kann über Webshops und mobile Anwendungen von hoher Bedeutung sein, wenn z. B. Angebote für Kunden hochgrade-individualisiert angezeigt werden sollen oder wenn Marktdaten angezeigt und mit ihnen interagiert werden sollen (z. B. Trading von Wertpapieren). Streaming-Tools bündeln eben solche Events (bzw. deren Datenhäppchen) in Data-Streaming-Kanäle (Partitionen), die dann von vielen Diensten (Consumergruppen / Receiver) aufgegriffen werden können. Data Streaming ist insbesondere auch dann ein notwendiges Setup, wenn ein Unternehmen über eine Microservices-Architektur verfügt, in der viele kleine Dienste (meistens als Docker-Container) als dezentrale Gesamtstruktur dienen. Jeder Dienst kann über Apache Kafka als Sender- und/oder Empfänger in Erscheinung treten. Der Azure Event-Hub dient dazu, die Zwischenspeicherung und Verwaltung der Datenströme von den Event-Sendern in den Azure Blob Storage bzw. Data Lake oder in Azure Synapse zu laden und dort weiter zu reichen oder für tiefere Analysen zu speichern.
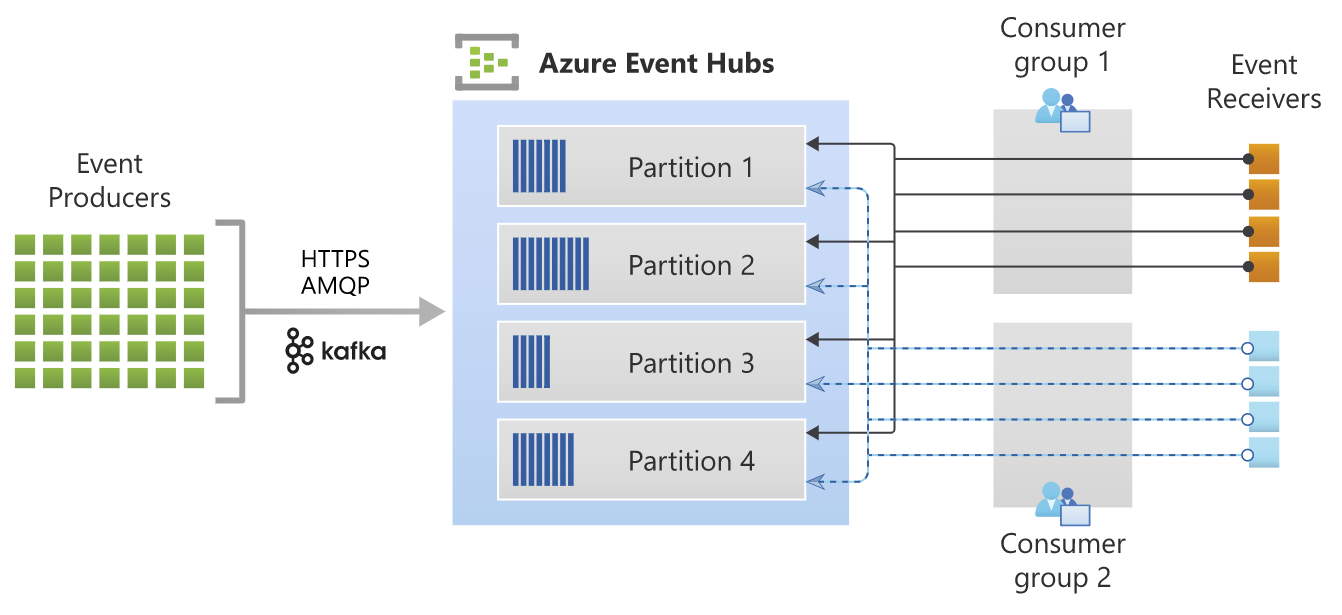 Quelle: https://docs.microsoft.com/de-de/azure/event-hubs/event-hubs-about
Quelle: https://docs.microsoft.com/de-de/azure/event-hubs/event-hubs-about
Für die Datenverarbeitung in nahezu Realtime sind der Azure Data Lake und Azure Synapse derzeitig relativ alternativlos. Günstigere Datenbank-Instanzen von MariaDB/MySQL, PostgreSQL oder auch die Azure SQL Database wären hier ein Bottleneck.
2 Fazit zu den Referenzarchitekturen
Die Referenzarchitekturen sind exakt als das zu verstehen: Als Referenz. Keinesfalls sollte diese Architektur unreflektiert für ein Unternehmen übernommen werden, sondern vorher in Einklang mit der Datenstrategie gebracht werden, dabei sollten mindestens diese Fragen geklärt werden:
- Welche Datenquellen sind vorhanden und werden zukünftig absehbar vorhanden sein?
- Welche Anwendungsfälle (Use Cases) habe ich für die Business Intelligence bzw. Datenplattform?
- Über welche finanziellen und fachlichen Ressourcen darf verfügt werden?
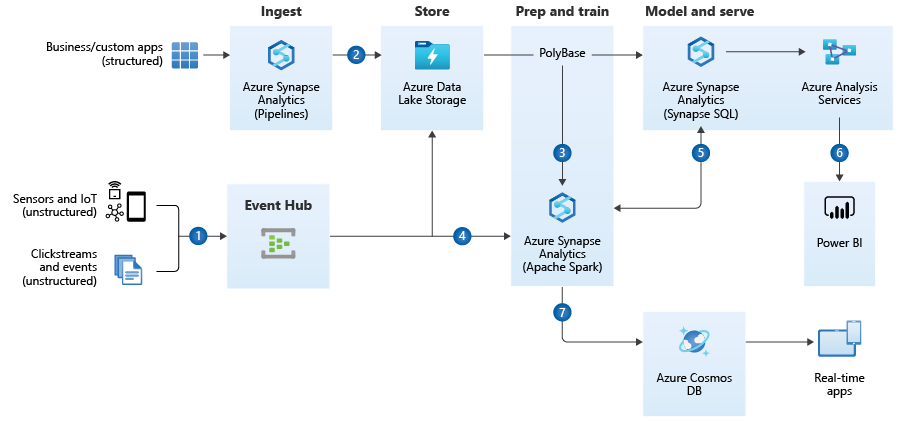
Darüber hinaus sollten sich die Architekten bewusst sein, dass, anders als noch in der trägeren On-Premise-Welt, die Could-Dienste schnelllebig sind. So sah die Referenzarchitektur 2019/2020 noch etwas anders aus, in der Databricks on Azure als System für Advanced Analytics inkludiert wurde, heute scheint diese Position im Referenzmodell komplett durch Azure Synapse ersetzt worden zu sein.
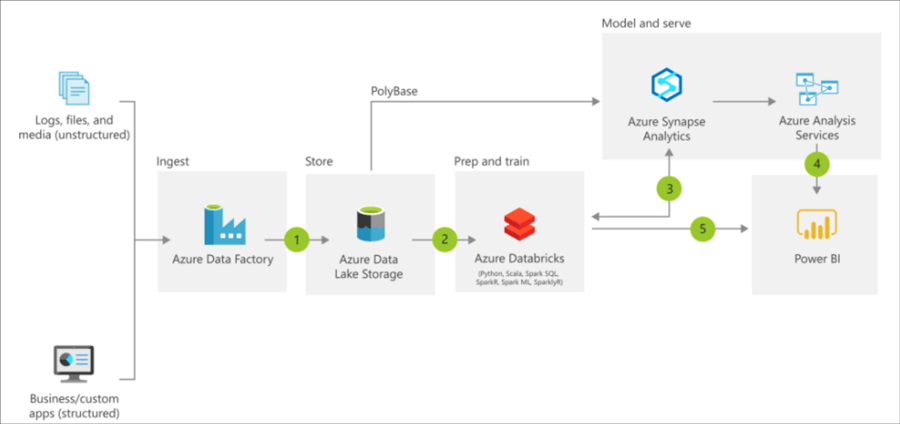
Azure Reference Architecture – with Databricks, old image source: https://docs.microsoft.com/en-us/azure/architecture/solution-ideas/articles/modern-data-warehouse
Hinweis zu den Kosten und der Administration
Die Kosten für Cloud Computing statt für IT-Infrastruktur On-Premise sind ein zweischneidiges Schwert. Der günstige Einstieg in de Azure Cloud ist möglich, jedoch bedingt ein kosteneffizienter Betrieb viel Know-How im Umgang mit den Diensten und Konfigurationsmöglichkeiten der Azure Cloud oder des jeweiligen alternativen Anbieters. Beispielsweise können über Azure Data Factory Datenbanken über Pipelines automatisiert hochskaliert und nach nur Minuten wieder runterskaliert werden. Nur wer diese dynamischen Skaliermöglichkeiten nutzt, arbeitet effizient in der Cloud.
Ferner sind Kosten nur schwer einschätzbar, da diese mehr noch von der Nutzung (Datenmenge, CPU, RAM) als von der zeitlichen Nutzung (Lifetime) abhängig sind. Preisrechner ermöglichen zumindest eine Kosteneinschätzung: https://azure.com/e/96162a623bda4911bb8f631e317affc6

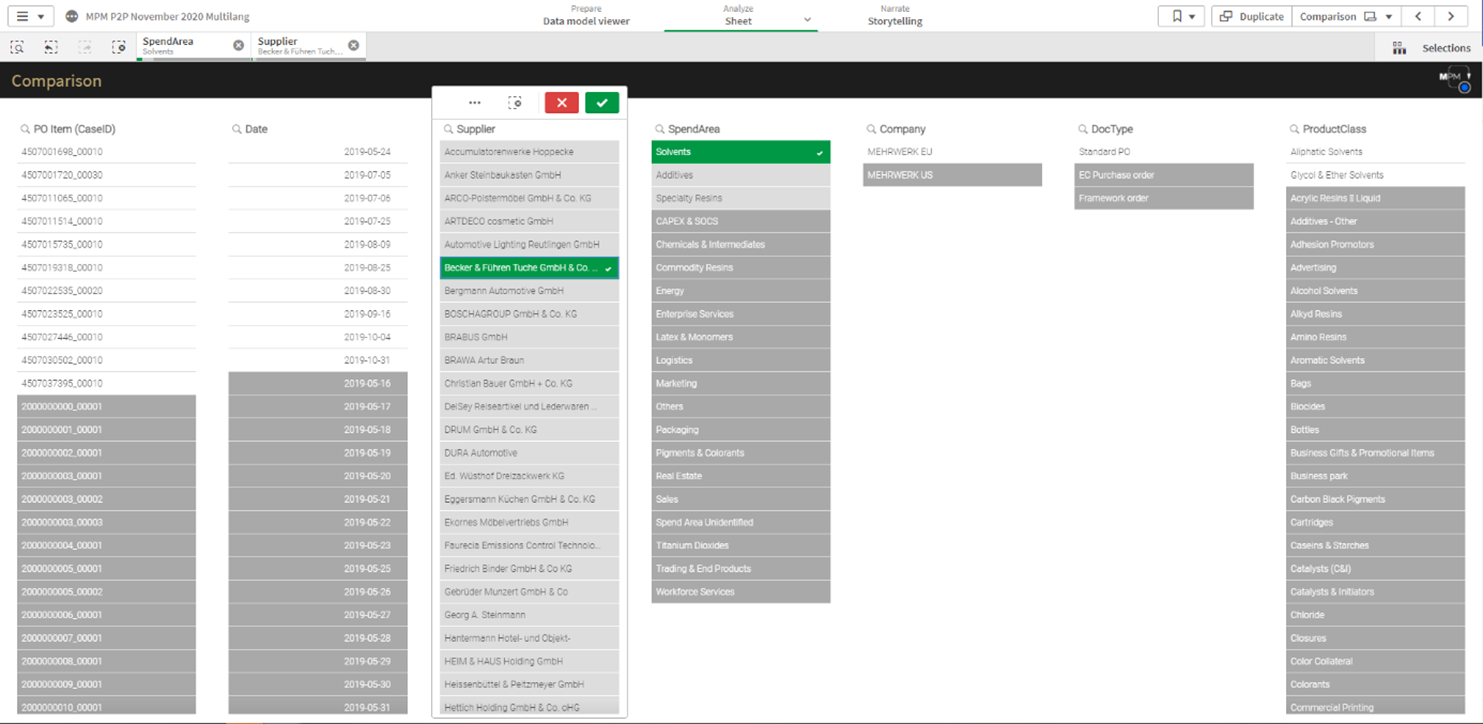
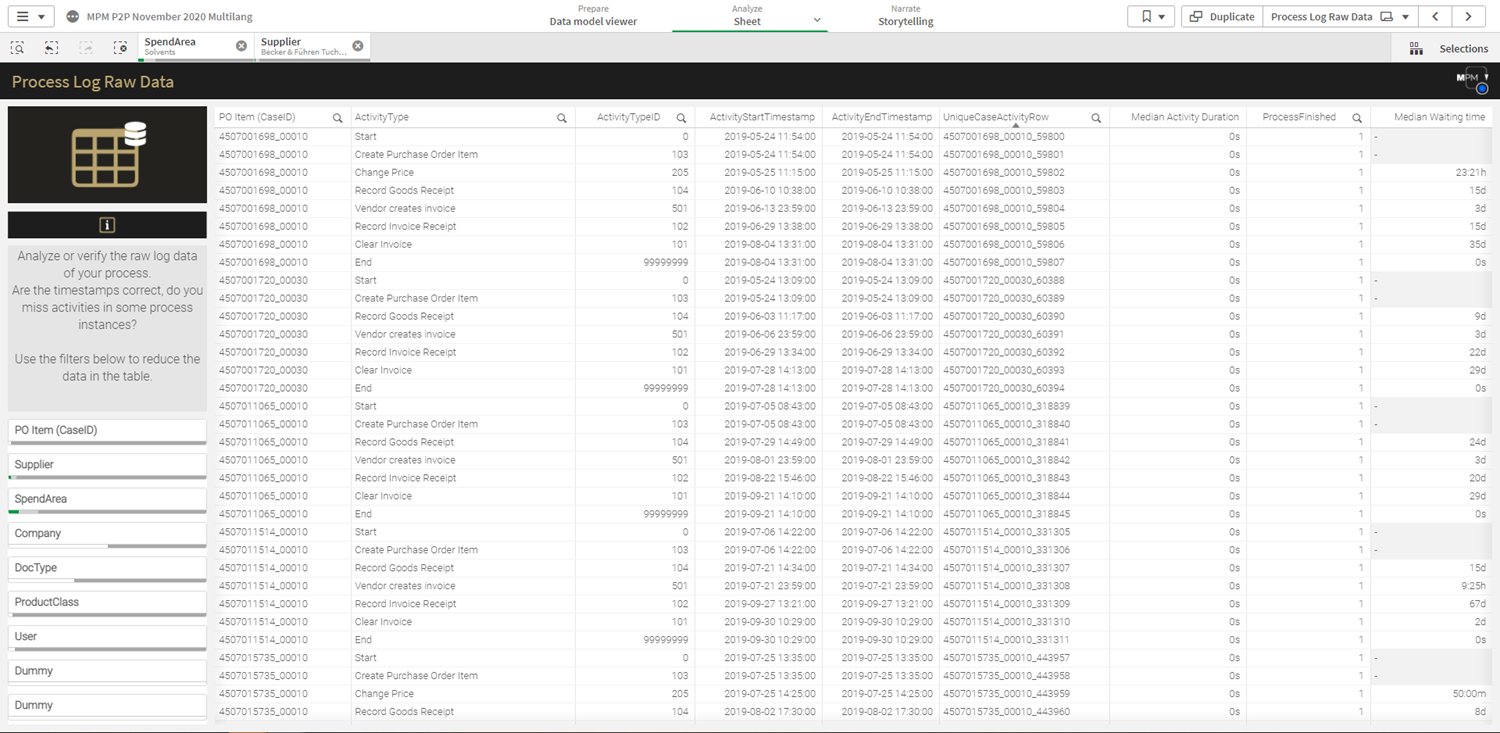

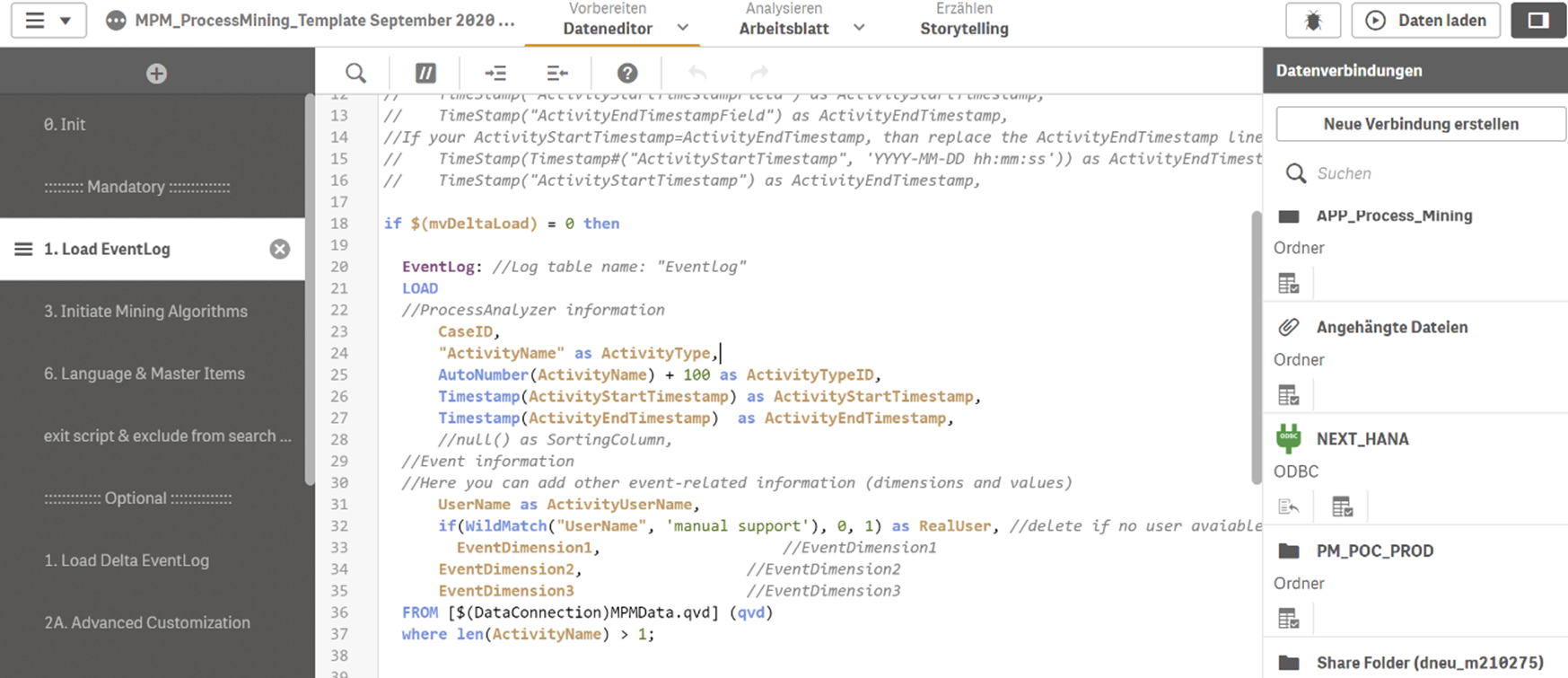

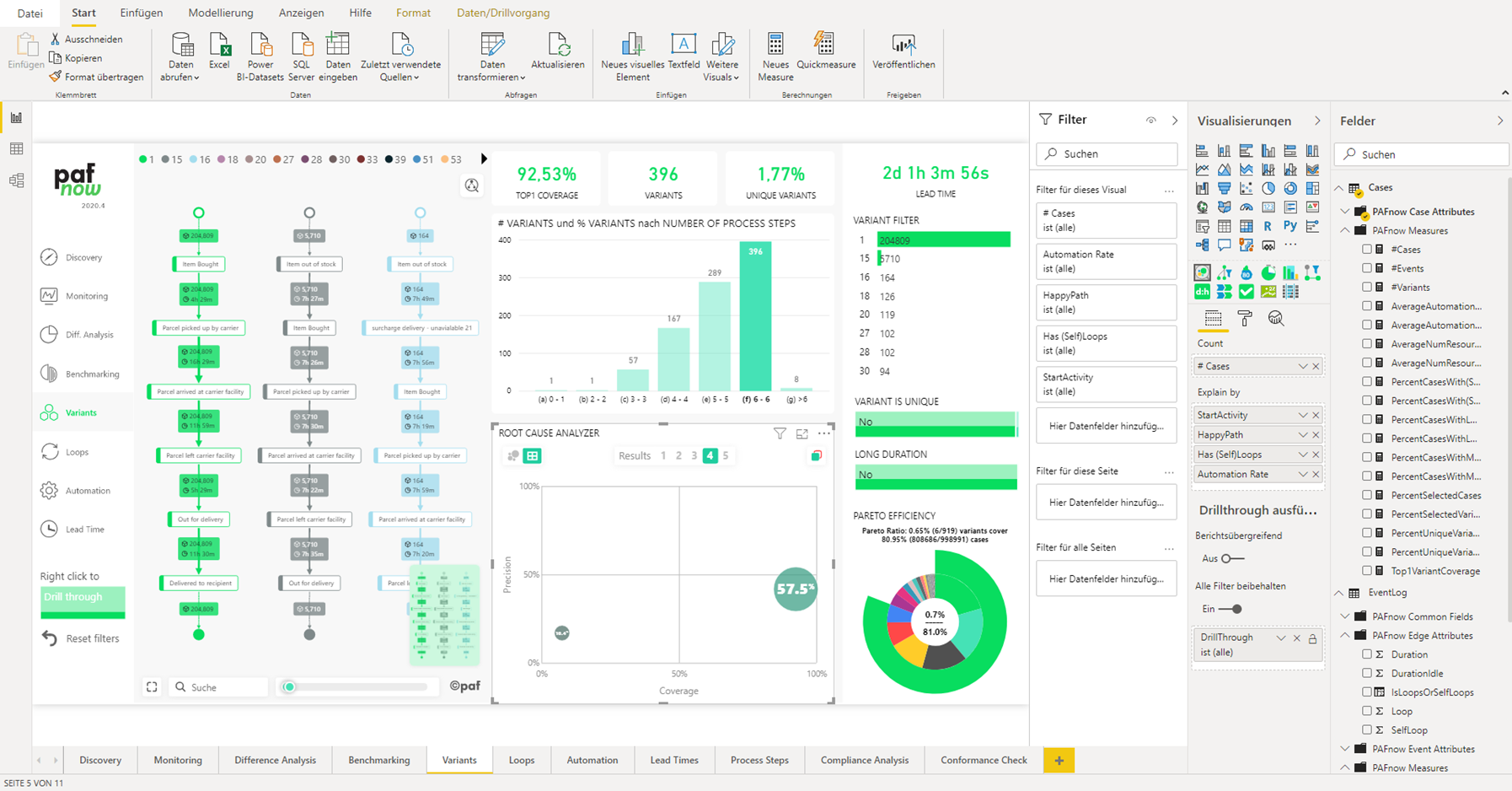
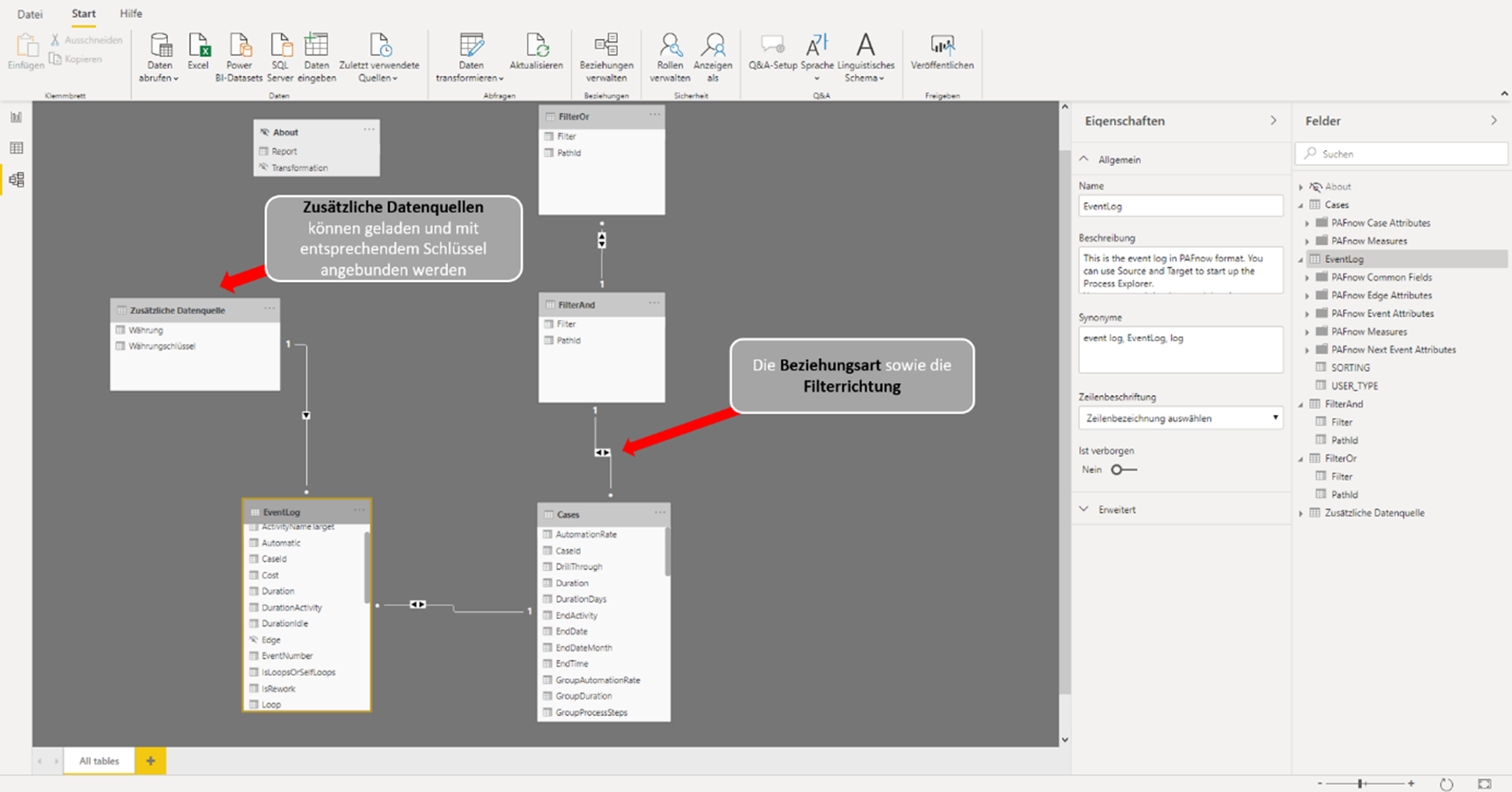

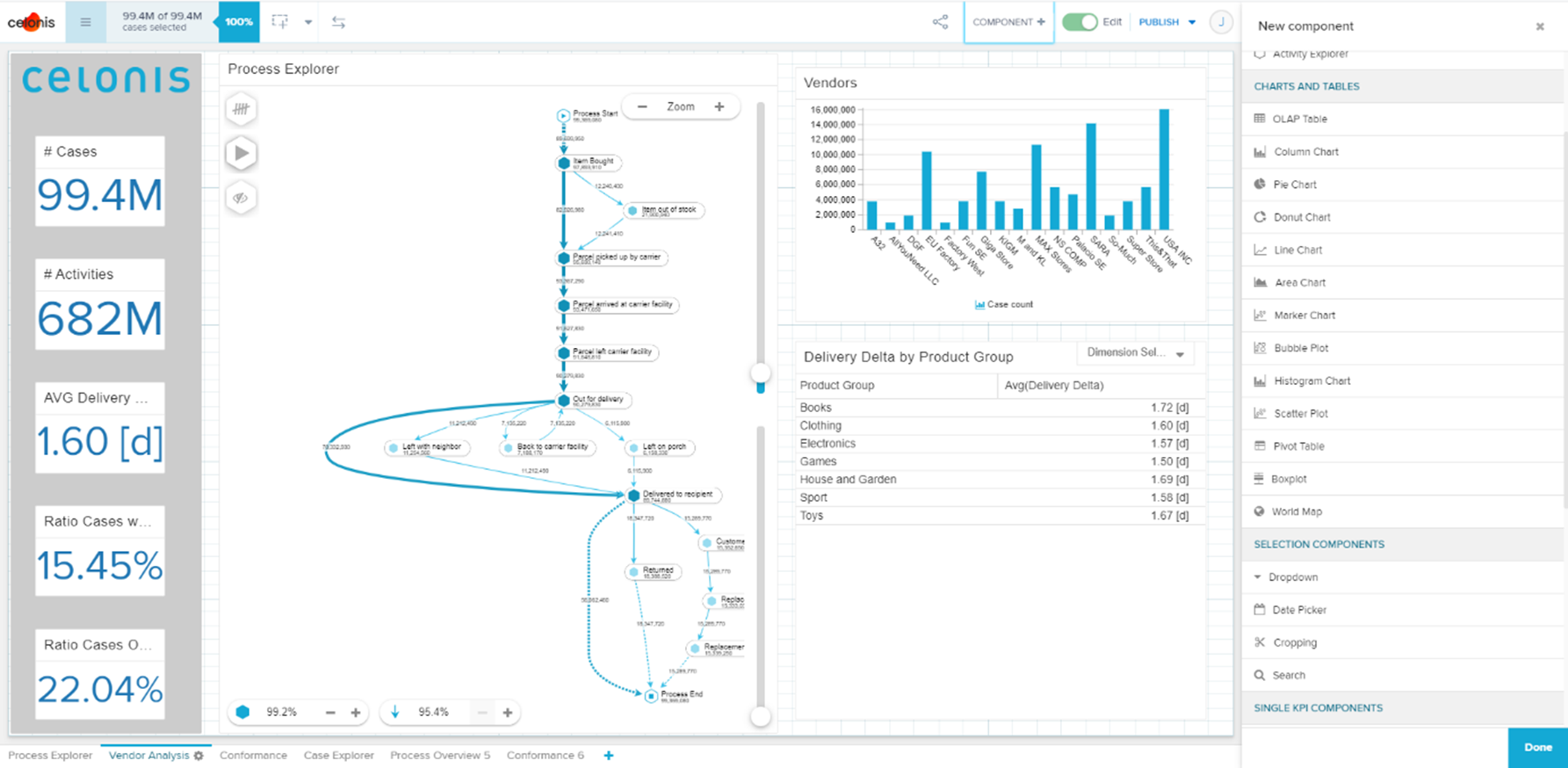
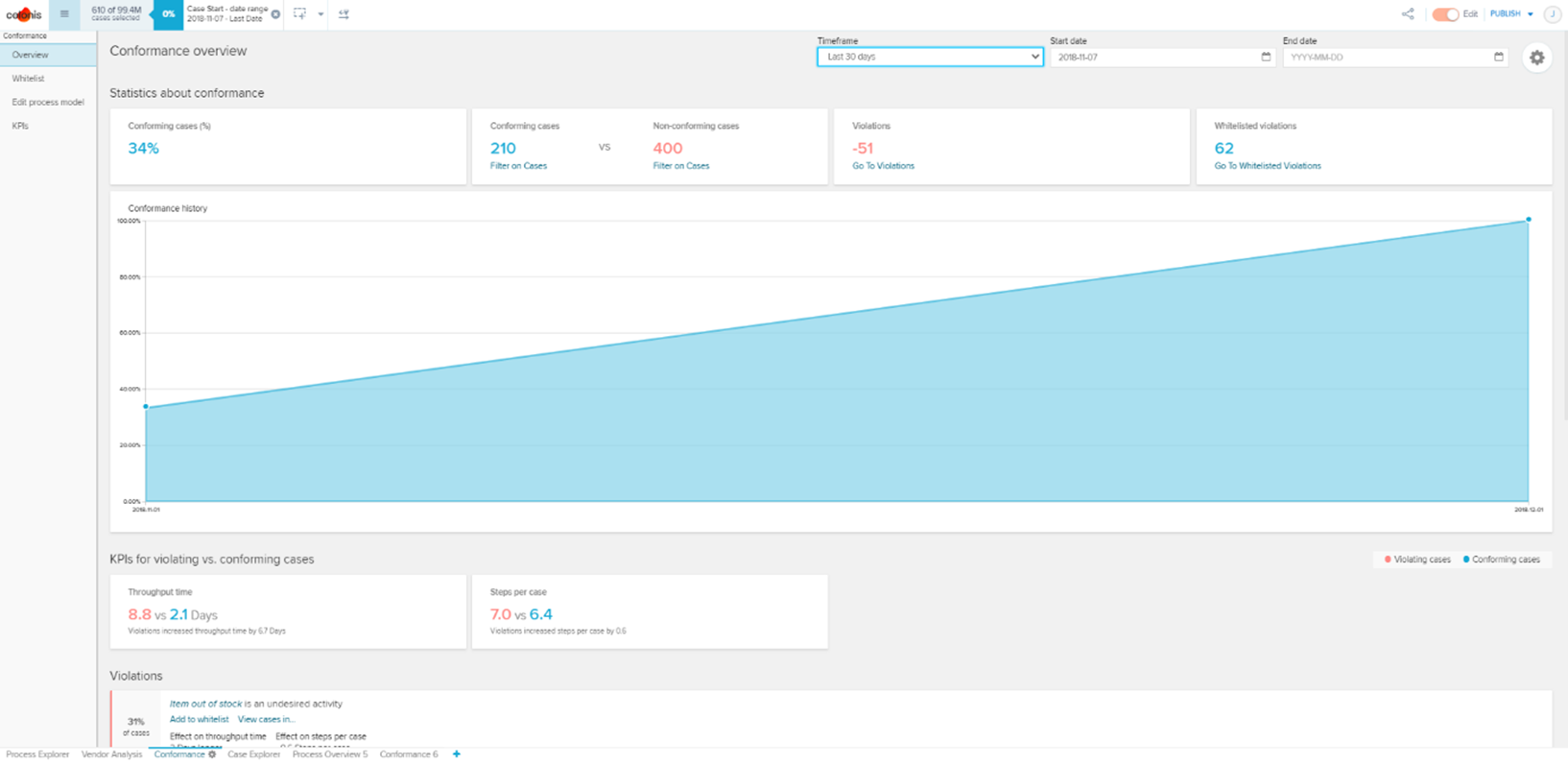
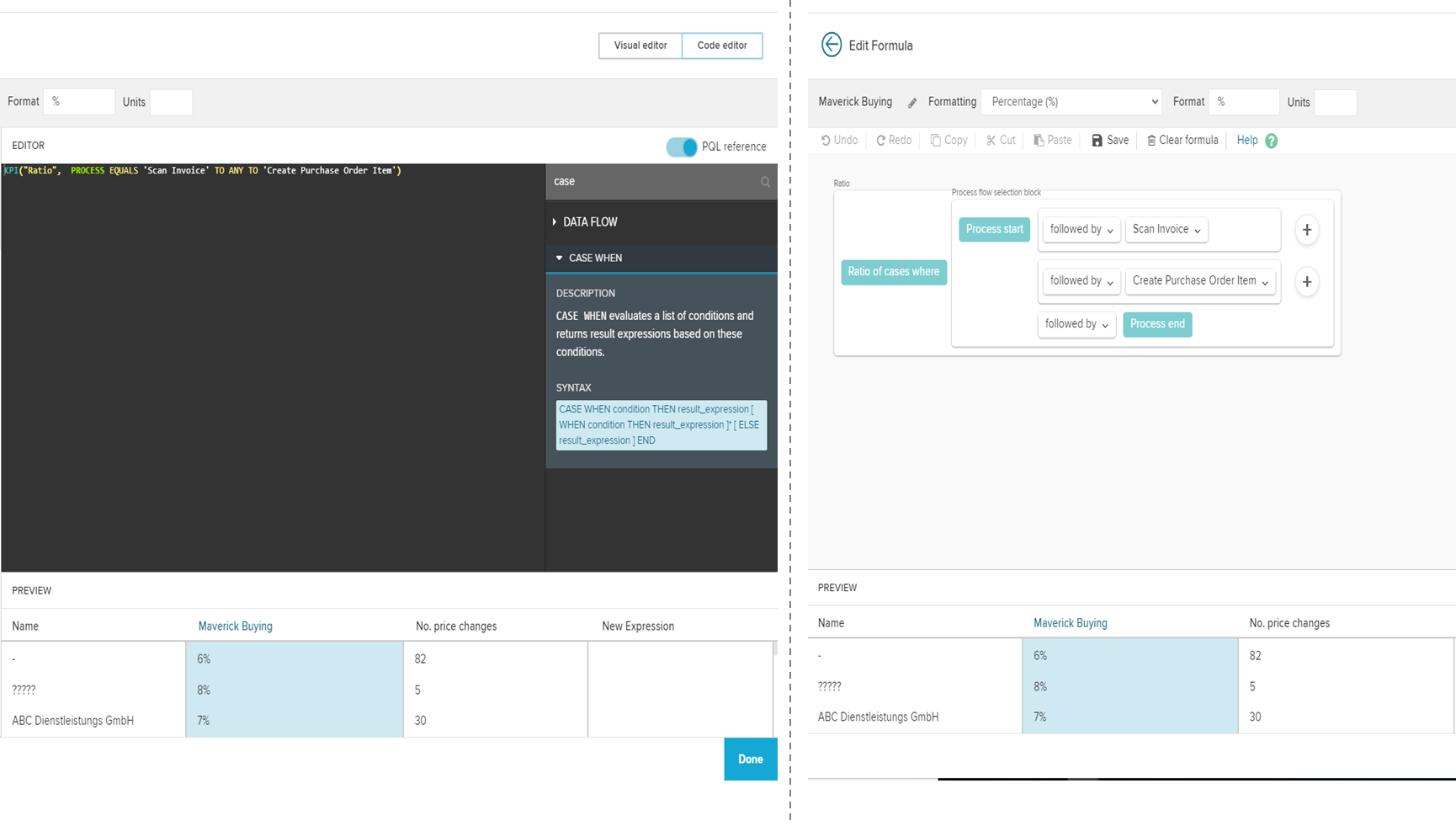



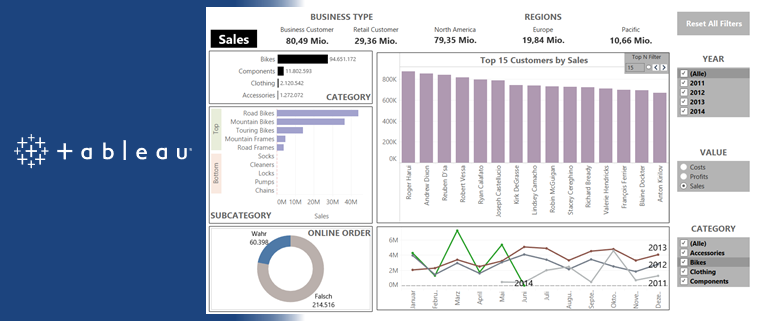
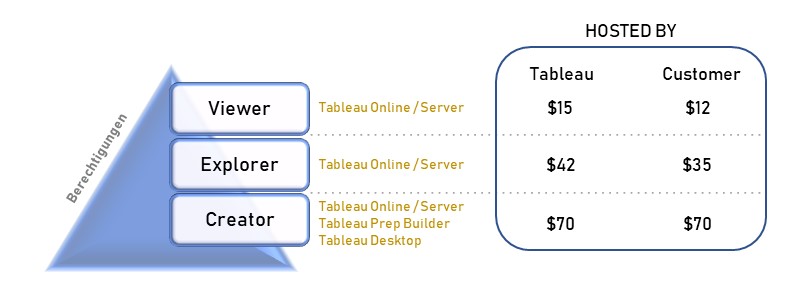 Der Creator ist befähigt, alle Funktionen von Tableau zu nutzen, sofern ein Unternehmen die angebotenen Add-ons hinzukauft. Die Lizenz Explorer ermöglicht es dem User, durch den Creator vordefinierte Datasets in Eigenregie zu analysieren und zu visualisieren. Demnach obliegt dem Creator, und somit einer kleinen Personengruppe, die Datenbereitstellung, womit eine Single Source of Truth garantiert werden soll. Der Viewer hat nur die Möglichkeit Berichte zu konsumieren, zu teilen und herunterzuladen. Wobei in Bezug auf Letzteres der Viewer limitiert ist, da dieser nicht die kompletten zugrundeliegenden Daten herunterladen kann. Lediglich eine Aggregation, auf welcher die Visualisierung beruht, kann heruntergeladen werden. Ein
Der Creator ist befähigt, alle Funktionen von Tableau zu nutzen, sofern ein Unternehmen die angebotenen Add-ons hinzukauft. Die Lizenz Explorer ermöglicht es dem User, durch den Creator vordefinierte Datasets in Eigenregie zu analysieren und zu visualisieren. Demnach obliegt dem Creator, und somit einer kleinen Personengruppe, die Datenbereitstellung, womit eine Single Source of Truth garantiert werden soll. Der Viewer hat nur die Möglichkeit Berichte zu konsumieren, zu teilen und herunterzuladen. Wobei in Bezug auf Letzteres der Viewer limitiert ist, da dieser nicht die kompletten zugrundeliegenden Daten herunterladen kann. Lediglich eine Aggregation, auf welcher die Visualisierung beruht, kann heruntergeladen werden. Ein