Eine Hadoop Architektur mit Enterprise Sicherheitsniveau
Dies ist Teil 2 von 3 der Artikelserie zum Thema Eine Hadoop-Architektur mit Enterprise Sicherheitsniveau.
Der aktuelle Stand der Technologie
Zum Glück ist Hadoop heutzutage ein bisschen reifer, als es noch vor zehn Jahren war. Es gibt viele Tools, einige davon OpenSource und einige lizenziert, die den Sicherheitsmangel im Hadoop zu lösen versuchen. Die Tabelle unten zeigt eine Auswahl der am meisten genutzten Sicherheitstools. Da jedes Tool von einer anderen Hadoop Distribution bevorzugt wird, habe ich diese Parameter mit berücksichtigt.
Es ist zu beachten, dass die zwei populärsten Hadoop Distributions (Hortonworks und Cloudera) kaum Unterschiede aufweisen, wenn man sie auf funktionaler Ebene vergleicht. Der größte Unterschied besteht darin, dass Hortonworks ein Open Source und Cloudera ein kommerzielles Produkt ist. Abgesehen davon hat jeder Vendor den einen oder anderen Vorteil, ein ausführlicher Vergleich würde jedoch den Rahmen dieses Artikels sprengen.

Hadoop kommt von der Stange ohne aktivierte Authentisierung. Die Hadoop Dienste vertrauen jedem User, egal als was er oder sie sich ausgibt. Das sieht folgendermaßen aus:
Angenommen Mike arbeitet an einer Maschine, die ihm Zugriff auf den Hadoop Cluster erlaubt und Sudo-Rechte gibt. Aber Mike hat das Passwort für den hdfs Superuser nicht. Er kann sich jetzt einfach als der hdfs User ausgeben, indem er die folgenden Kommandos ausführt. Dabei bekommt er fatalerweise alle Rechten des hdfs Superusers und ist in der Lage das gesamte HDFS Filesystem zu löschen. Es würde sogar bereits der Environment variabel USER ausreichen, um einen anderen User umzuwandeln.

Kerberos ist im Moment der einzige Weg um Authentisierung im Hadoop zu gewährleisten. Kein Weg führt daran vorbei, es sei denn, man ist verrückt genug, um ein hochkompliziertes System auf Linux basierter ACLs auf jeder Maschine zu installieren und zu verwalten, um User daran zu hindern sich falsch zu authentifizieren. Es ist zudem wichtig zu beachten, dass Kerberos als einziges Sicherheitsmerkmal zur Authentifizierung dient, aber ohne richtige Authentisierung gibt es auch keine richtige Autorisierung. Wenn User jetzt selbst in der Lage sind, sich beliebig als jemand anderes auszugeben, können sie so selbst zu den sensibelsten Daten unbefugten Zugriff erlangen.
Apache Ranger oder Sentry erlauben die Definition und Verwaltung von Access Control Lists (ACLs). Diese Listen legen fest, welche User Zugriff auf welchen Bereich des HDFS Filesystems haben Der gleiche Effekt kann auch ohne diese Tools, durch einfache Hadoop ACLs erreicht werden, die den normalen Linux ACLs ähneln. Es empfiehlt sich jedoch die neuesten Tools zu benutzen, wegen a) ihrer Benutzerfreundlichkeit, b) ihrer ausgearbeiteten APIs, die einem Administrator erlauben die Listen ohne GUI zu verwalten und beim Programmieren sogar zu automatisieren, und c) wegen ihrer Auditingfähigkeiten, die das Nachverfolgen von Zugriffen und Aktionen ermöglichen.
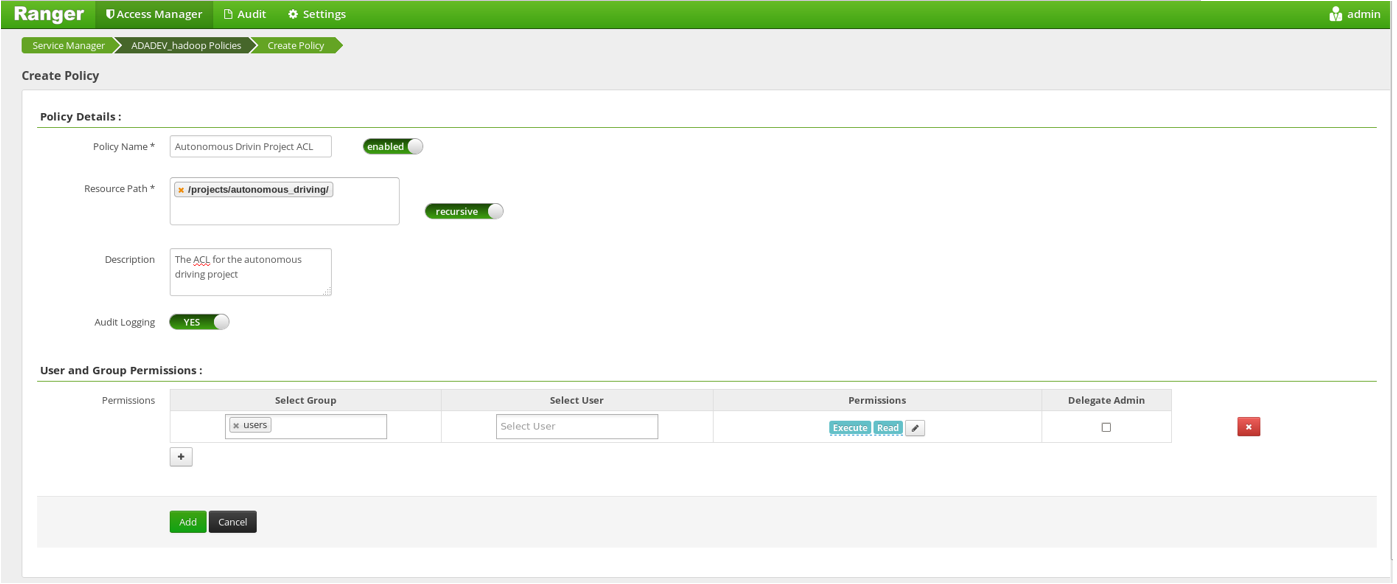
Anbei ist das Bild einer Ranger Policy, die der Gruppe der User rekursiv Lese- und Ausführungsrechte auf das Verzeichnis /projects/autonomous_driving gibt.
Alle einzelne Stücke des Puzzles kommen zusammen
Nachdem wir ermittelt haben, welche Technologien es gibt, die uns zu einem sicheren Cluster verhelfen, müssen diese im nächsten Schritt zusammengesetzt werden. Zum Glück hat jeder Vendor seine eigene Technologie, um Tools aus dem Hadoop Ecosystem zu integrieren und zu verwalten. Cloudera beispielsweise bietet den sehr wirksamen Cloudera Manager und Hortonworks das Apache Ambari an. Die beiden Tools kümmern sich um das Anlegung der technischen Hadoop User (hdfs, hadoop, hive, ranger, e.t.c.) und der entsprechenden Kerberos Keytabs, die den technischen Usern erlauben, sich gegenüber Hadoop zu authentisieren. Am Ende der Installation hat man sämtliche Konfigurationen zentral platziert und kann neue personalisierte Accounts anlegen. Man kann sich dann im Ranger oder Sentry Web UI anmelden und ACLs für die User und Gruppen definieren.
Das ist allerdings nicht der Idealzustand. Jedes Unternehmen verwaltet ihre User bereits in bestimmten Verwaltungssystemen, die sich innerhalb der IT Infrastruktur befinden. Diese Systeme (oder auch Identity Management Systems) sind ein wichtiges vertikales, abteilungsübergreifendes Element der unternehmerischen IT Architektur. Jedes EDS Tool im Unternehmen ist an ein Identity Management System, wie Active Directory oder LDAP, gekoppelt und muss damit die User nicht selbst verwalten.
Der Stellenwert solcher Tools wird sofort erkennbar, wenn man die strengen Sicherheitsregeln eines modernen Unternehmens betrachtet: Passwörter müssen bestimmte Kriterien erfüllen und alle 30 Tagen gewechselt werden. Außerdem darf niemand eins seiner letzten zehn Passwörter benutzen.
Eine IT Architektur, die die Implementierung solcher unternehmensbreiten Anforderungen in jeder einzelne Applikation fördert ist der Alptraum jedes Applikationsentwicklers und zeigt das Versagen des IT-Architekten.
Aber lassen Sie uns zurück zu unserem Hauptthema kommen. Wie können wir ein System wie Active Directory oder LDAP in Hadoop integrieren? Der nächste Abschnitt gibt die Antwort auf diese Frage.
Weiter zu Teil 3 von 3 – Eine Einterprise Hadoop Architektur für beste Sicherheit
Zurück zu Teil 1 von 3 – Motivation und Anforderungen einer Data Science Plattform