Es gibt immer wieder Skriptsprachen, die neu am IT-Horizont geboren um Anwender werben. Der IT-Manager muß also stets entscheiden, ob er auf einen neuen Zug aufspringt oder sein bisheriges Programmierwerkzeug aktuellen Anforderungen standhält. Mein Skriptsprachenkompass wurde über frühere Autoren kalibriert, an die hier erinnert werden soll, da sie grundsätzliche Orientierungshilfen für Projektplanungen gaben.
Im Projektmanagement geht es stets um aufwandsbezogene Terminplanung, im CAFM-Projektmanagement z. B. konkret um die Analyse und Schätzung geplanter und ungeplanter Maßnahmen, wie geplante Wartungen oder zufällige technische Störungen im Gebäudemanagement, um Wahrscheinlichkeiten.
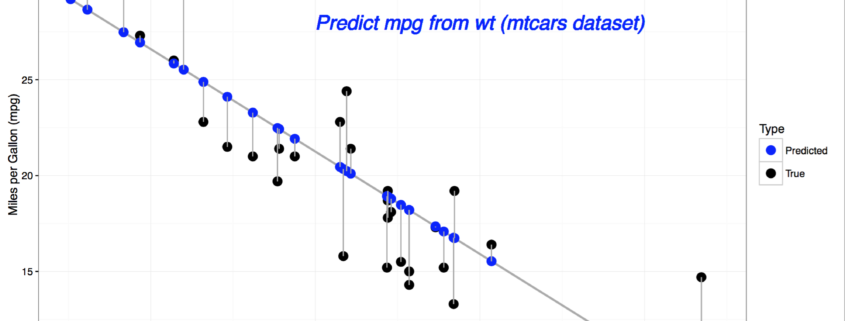
Warum löst R die Terminplanung strategisch und praktisch besser als Python, Perl, Java oder etc.? Weil sich geschätzte Ereignisse in Zeitfenstern normalverteilt als so genannte Gaußsche Glockenkurve abbilden, einer statistischen Schätzung entsprechen.
Hier zwei Beispielgrafiken zum Thema Terminschätzung aus aktueller Literatur.
1. Standardnormalverteilung
Praxishandbuch Projektmanagement – inkl. Arbeitshilfen online von Günter Drews, Norbert Hillebrand, Martin Kärner, Sabine Peipe, Uwe Rohrschneider
Haufe-Lexware GmbH & Co. KG, Freiburg, 1. Auflage 2014 – Siehe z. B. Seite 241, Abb. 14 Normalverteilung als Basis von PERT (Link zu Google Books)


Praxishandbuch Projektmanagement – inkl. Arbeitshilfen online
2. Betaverteilung
Projektmanagement für Ingenieure: Ein praxisnahes Lehrbuch für den systematischen Projekterfolg von Walter Jakoby, Hochschule Trier
Springer Vieweg, Springer Fachmedien Wiesbaden 2015, 3, Auflage – Siehe z. B. Seite 215, Abb. 7.13 Beta-Verteilung (Link zu Google Books).


Projektmanagement für Ingenieure: Ein praxisnahes Lehrbuch für den systematischen Projekterfolg
Eine objektorientierte Statistikprogrammiersprache mit über 7.000 Paketen weltweit lädt ein, nicht jede Funktion neu erfinden zu wollen und macht glaubhaft, dass kein Unternehmen der Welt über derart Programmierwissen und Kapazität verfügt, es besser zu können. Für statistische Berechnungen empfiehlt sich seit Jahren R, für mich spätestens seit 2003. Früheren Autoren war das grundlegend klar, daß deterministische Terminplanungen immer am Mangel stochastischer Methoden kranken. In meiner Studienzeit kursierte an der Martin Luther Universität Halle an der Saale der Witz, es gibt zwei Witze an der landwirtschaftlichen Fakultät, den Badewitz und den Howitz. Doch das Buch vom Badewitz halte ich bis heute. Im Kapitel 5.3 Elemente der Zeitplanung fand ich dort in Abbildung 5.7 auf Seite 140 erstmals die Wahrscheinlichkeitsverteilung einer Vorgangsdauer als normalverteilte Grafik.
Vgl. Zur Anwendung ökonomisch-mathematischer Methoden der Operationsforschung, federführend Dr. sc. agr. Siegfried Badewitz, 1. Auflage 1981, erschienen im VEB Deutscher Landwirtschaftsverlag Berlin. Ein Grafikkünstler zur schnellen Visualisierung von Funktionen und Dichteverteilungen ist seit Jahren R. Zur R-Umsetzung empfehle ich gern meine R-Beispielbibel bei Xing.
Wer zur Statistik der Terminschätzung tiefer greifen will, kommt an Autoren wie Golenko u. a. nicht vorbei. Badewitz verwies z.B. auf Golenko’s Statistische Methoden der Netzplantechnik in seinem o.g. Buch (Link zu Google Books).


Statistische Methoden der NetzplantechnikHier empfehle ich zum Einstieg das Vorwort, das 2015 gelesen, aktuell noch immer gilt, nicht das Jahr seiner Niederschrift 1968 preisgibt:
Gegenwärtig beobachtet man häufig Situationen, in denen bei der Untersuchung von zufallsbeeinflußten Systemen die in ihnen auftretenden Zufallsparameter durch feste Werte (z. B. den Erwartungswert) ersetzt werden, wonach dann ein deterministisches Modell untersucht wird.
Und hier noch ein Beispiel von Seite 203:
Praktisch kann jede komplizierte logische Beziehung auf eine Kombination elementarer stochastischer Teilgraphen zurückgeführt werden.
Meine Empfehlung für Process Mining und Projektmanagement lautet daher – intelligente Stochstik statt altbackenem Determinismus.