
Graphendatenbank Neo4j 5 Release veröffentlicht
Die neue Version der nativen Graphdatenbank bietet uneingeschränkte Skalierbarkeit, hohe Performance sowie diverse Verbesserungen in der Abfragesprache Cypher und im Index-Handling
München, 9. November 2022 – Neo4j, führender Anbieter von Graphtechnologie, stellt das Release Neo4j 5 vor. Mit der neuen Version setzt sich die native Graphdatenbank hinsichtlich ihrer Performance weiter von herkömmlichen, relationalen Datenbanksystemen ab.
Im Mittelpunkt von Neo4j 5 steht die Optimierung des Betriebs der Graphdatenbank. Dazu gehört eine uneingeschränkte Skalierbarkeit sowie eine hohe Performance für schnellere Abfragen – unabhängig von der Größe oder der Aufteilung des Datenbestands (Sharding). Diverse Verbesserungen in der Syntax der Abfragesprache Cypher, im Index-Handling, im Abfrage Planer und in der Implementierung ermöglichen es, Abfragen über mehrere Knoten hinweg deutlich einfacher auszudrücken und schneller Antworten zu erhalten.
Wie bereits frühere Versionen ist auch Neo4j 5 als Cloud Service verfügbar (Neo4j AuraDB und Neo4j AuraDS). Anwender können das neue Release ab sofort im Download-Center von Neo4j oder über die Cloud-Marktplätze von AWS, Azure und GCP beziehen.
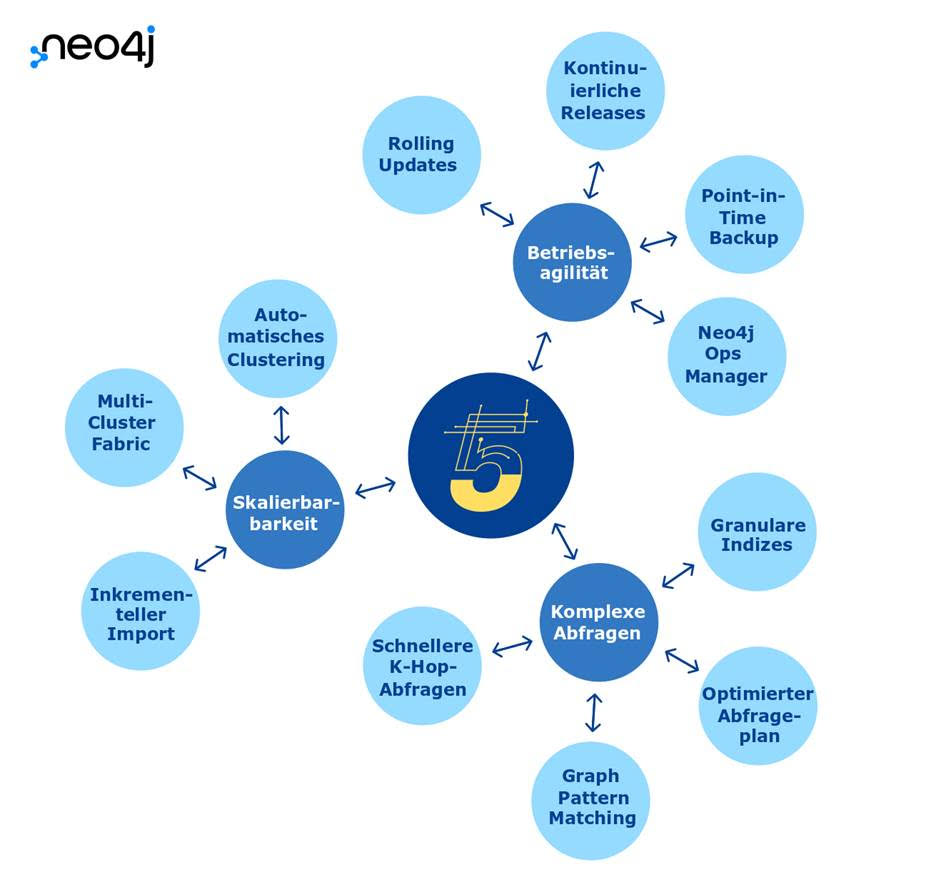
Die wichtigsten Funktionen von Neo4j 5 im Überblick
- Automatisches Clustering: Neo4j 5 bietet eine Cloud-fähige Architektur für globale Cluster, mit der sich Daten sowie Datenbanken skalieren lassen, ohne die Cluster selbst skalieren zu müssen. Die Platzierung von primären und sekundären Kopien auf dem Server im Cluster erfolgt dabei automatisch. Das reduziert nicht nur den manuellen Aufwand für Anwender, sondern stellt auch eine optimale Auslastung der Infrastruktur sicher.
- Multi-Cluster Fabric: Mit Neo4j Fabric lassen sich individuelle Abfragen wieder zusammenführen und als Ganzes analysieren. In Neo4j 5 können Anwender nun via Cypher Kommandos Fabric Konfigurationen schneller erstellen und Abfragen sowohl innerhalb eines lokalen als auch entfernter Cluster durchführen. Separate Fabric-Proxys sind dafür nicht erforderlich.
- Inkrementeller Import: Neo4j 5 ermöglicht es, große Datenmengen inkrementell in eine bestehende Datenbank einzubringen. Damit lässt sich die Datenladezeit drastisch reduzieren und eine höhere Flexibilität beim Laden großer Datensets erreichen.
- Schnellere K-Hop-Abfragen. K-Hop ist eine Form von Deep Query, die eine große und variable Anzahl (K) von Hops beinhaltet, um alle eindeutigen Knoten im Umkreis des Startpunkts in einem Graphen zu finden. In der Regel wird diese Abfrage in Kombination mit Aggregationsfunktionen zum Zählen von Eigenschaften verwendet. In Neo4j 5 wurden K-Hop-Abfragen optimiert und die Antwortzeiten für 8-Hop-Abfragen um das 1000-fache verbessert.
- Verbesserungen beim Graph Pattern Matching und optimierte Query Planung: Am Pfad gesetzte Filter für Beziehungen sowie differenzierte Label-Ausdrücke ermöglichen es Anwendern, MATCH-Klauseln einfacher zu schreiben und zu lesen. Darüber hinaus wurde die Query Planung für Cypher-Abfragen optimiert und ihre Ausführung damit beschleunigt.
- Verbesserte Indizes: Indizes sind entscheidend, um möglichst schnell den besten Ausgangspunkt (z. B. Knoten, Kanten) für eine Abfrage zu finden. In Neo4j 5 wurde die Abgleichsmöglichkeiten von Indizes erweitert:
FULLTEXT indiziert nun Listen und Arrays von Strings, um die Qualität der Textsuchergebnisse zu verbessern.
RANGE ermöglicht die Angabe oder den Vergleich von Werten (z. B. Rezensionen 3-5 von Nutzern im PLZ-Bereich 8-9).
Mit POINT, der häufig bei Routing- und Lieferkettenanalysen verwendet wird, lassen sich nun auch geospatiale Daten wie Längen- und Breitengrade finden und vergleichen. - Neo4j Ops Manager: Das Backend-Admin-Tool bietet ein intuitives Dashboard, mit dem Datenbankadministratoren Neo4j-Implementierungen (z. B. Datenbank, Instanz oder Cluster) monitoren und managen können.
- Rolling Updates: Neo4j 5 beinhaltet kontinuierliche Updates für alle Implementierungen der Graphdatenbank ohne Ausfallzeiten – egal ob On-Premise, in der Cloud oder in hybriden Umgebungen. Zudem garantiert das neue Release eine durchgehende Kompatibilität zwischen selbst verwalteten und von Neo4j verwalteten Aura-Workloads.
- Backup und Wiederherstellung: Optimierungen der Backup-Engine erlauben mehr Kontrolle und eine schnellere und einfachere Datensicherung. Dazu verfügt Neo4j 5 über ein differentielles Backup einschließlich eines einzelnen komprimierten Dateiarchivs, Point-in-Time-Wiederherstellung, APIs zur Überprüfung und Verwaltung von Sicherungsdateien sowie die Aktivierung einer Konsistenzprüfung.
„Der Einsatz von Graphdatenbanken ist in den letzten Jahren regelrecht explodiert. Unternehmen nutzen die Technologie, um ihre Daten sowie die Datenverbindungen im vollen Umfang zu analysieren und in der Praxis zu nutzen – sei es, um Prozesse weiter zu automatisieren, Risiken proaktiv zu bewerten oder datengestützte bzw. KI-basierte Entscheidungen zu treffen“, erklärt Emil Eifrem, CEO und Mitbegründer von Neo4j. „Neo4j 5 wurde mit diesen Zielen vor Augen weiter ausgebaut. Das neue Release bietet höhere Skalierbarkeit, Agilität und Performance, um Unternehmen in Sachen Datenmanagement und Data Analytics auf das nächste Level zu verhelfen.“
Mehr über das Neo4j 5 Release erfahren Sie auf der Neo4j Webseite sowie im Blog „Scale New Heights with Neo4j 5 Graph Database“. Melden Sie sich außerdem zur kostenlosen virtuellen Entwicklerkonferenz NODES 2022 (16. – 17. November) an, um an den Neo4j 5 Sessions „What’s New in Neo4j 5 and Aura 5 for Developers” und „Introducing Neo4j 5 for Administrators” teilzunehmen.
Bildmaterial zum Download (Quelle: Neo4j): Features in Neo4j 5

{kind=link}