Self Service Data Preparation mit Microsoft Excel
Get & Transform (vormals Power Query), eine kurze Einführung
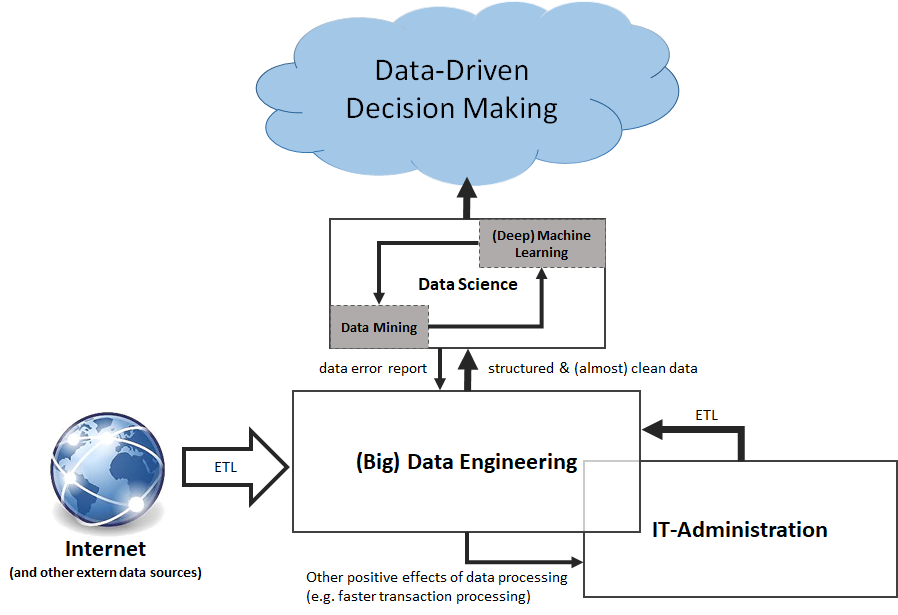
Unter Data Preparation versteht man sinngemäß einen Prozeß der Vorbereitung / Aufbereitung von Rohdaten aus meistens unterschiedlichen Datenquellen und -formaten, verbunden mit dem Ziel, diese effektiv für verschiedene Geschäftszwecke / Analysen (Business Fragen) weiterverwenden/bereitstellen zu können. Rohdaten müssen oft vor ihrem bestimmungsgemäßen Gebrauch transformiert (Datentypen), integriert (Datenkonsistenz, referentielle Integrität), sowie zugeordnet (mapping; Quell- zu Zieldaten) werden.
An diesem neuralgischen Punkt werden bereits die Weichen für Datenqualität gestellt.
Unter Datenqualität soll hier die Beschaffenheit / Geeignetheit von Daten verstanden werden, um konkrete Fragestestellungen beantworten zu können (fitness for use):
Kriterien Datenqualität
- Eindeutigkeit
- Vollständigkeit
- Widerspruchsfreiheit / Konsistenz
- Aktualität
- Genauigkeit
- Verfügbarkeit
Datenqualität bestimmt im Wesentlichen die weitere zielgerichtete Verwendung der Daten in Analysen (Modelle) und Berichten (Reporting). Daten werden in entscheidungsrelevante Kennzahlen (Informationen) überführt. Eine Kennzahl ist gegenüber der Datenqualität immer blind, ihre Aussagekraft (Validität) hängt -neben der Definition – in sehr starkem Maße davon ab:
Gütekriterien von Kennzahlen
- Objektivität := ist die Interpretation unabhängig vom Beobachter / Verwender?
- Reliabilität := kann das Ergebnis unter sonst gleichen Bedingungen reproduziert werden ?
- Validität := sagt die Kennzahl das aus, was sie vorgibt, auszusagen ?
Business Fragen entstehen naturgemäß in den Fachbereichen.Daher ist es nur folgerichtig, Data Preparation als einen ersten Analyseschritt innerhalb des Fachbereichs anzusiedeln (Self Service Data Preparation). Dadurch erhält der Fachbereich einen Teil seiner Autonomie zurück. Welche Teilmenge der Daten relevant für Fragestellungen ist, kann nur der Fachbereich beurteilen; der Anforderer von entscheidungsrelevanten Informationen sollte idealerweiseTeil der Entstehung wertiger Daten sein, das fördert zum einen die Akzeptanz des Ergebnisses, zum anderen wirkt es einem „not-invented-here“ Syndrom frühzeitig entgegen.
Im Folgenden wird anhand 4 Schritten skizziert, wie Microsoft Excel bei dem Thema (Self Service) Data Preparation vor allem den Fachbereich unterstützen kann. Eine Beispieldatei können Sie hier (google drive) einsehen. Sie finden die hierfür verwendete Funktionalität (Get & Transform) in Excel 2016 unter:
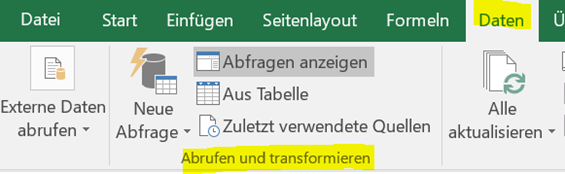
Reiter Daten -> Abrufen und Transformieren.
Dem interessierten Leser werden im Text vertiefende Informationen über links zu einzelnen typischen Aufgabenstellungen und Lösungswegen angeboten. Eine kurze Einführung in das Thema finden Sie in diesem Blog Beitrag.
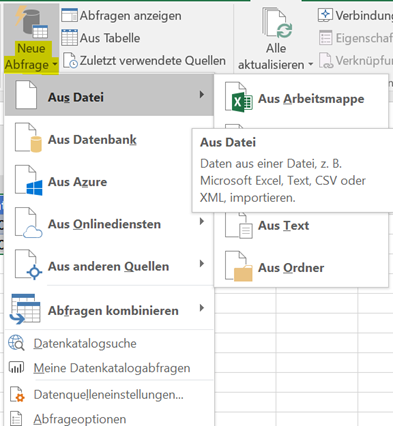
1 Einlesen
Datenquellen anbinden (externe, interne)

Dank der neuen Funktionsgruppe „Abrufen und Transformieren“ ist es in Microsoft Excel möglich, verschiedene externe Datenquellen /-formate anzubinden. Zusätzlich können natürlich auch Tabellen der aktiven / offenen Excel Arbeitsmappe als Datenquelle dienen (interne Datenquellen). Diese Datenquellen werden anschließend als sogenannte Arbeitsmappenabfragen abgebildet.
Praxisbeispiele:
Anbindung mehrerer Dateien, welche in einem Ordner bereitgestellt werden
2 Transformieren
Daten transformieren (Datentypen, Struktur)

Datentypen (Text, Zahl) können anschließend je Arbeitsmappenabfrage und Spalte(n) geändert werden.
Dies ist zB immer dann notwendig, wenn Abfragen über Schlüsselspalten in Beziehung gesetzt werden sollen (siehe Punkt 3). Gleicher Datentyp (Primär- und Fremdschlüssel) in beiden Tabellen ist hier notwendige Voraussetzung.
Des Weiteren wird in dieser Phase typischerweise festgelegt, welche Zeile der Abfrage die Spaltenbeschriftungen enthält.
Praxisbeispiele:
Umgang mit wechselnden Spaltenbeschriftungen
3 Zusammenführen / Anreichern
Daten zusammenführen (SVERWEIS mal anders)
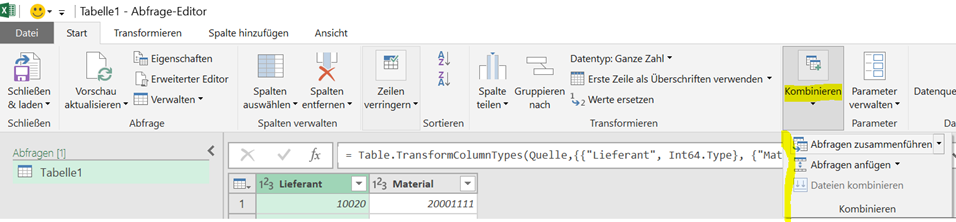
Um unterschiedliche Tabellen / Abfragen über gemeinsame Schlüsselspalten zusammenzuführen, stellt der Excel Abfrage Editor eine Reihe von JOIN-Operatoren zur Verfügung, welche ohne SQL-Kenntnisse nur durch Anklicken ausgewählt werden können.
Praxisbeispiele
JOIN als Alternative zu Excel Formel SVERWEIS()
Daten anreichern (benutzerdefinierte Spalte anfügen)

Bei Bedarf können weitere Daten, welche sich nicht in der originären Struktur der Datenquelle befinden, abgeleitet werden. Die Sprache Language M stellt einen umfangreichen Katalog an Funktionen zur Verfügung. Wie Sie eine Übersicht über die verfügbaren Funktionen erhalten können erfahren Sie hier.
Praxisbeispiele
Geschäftsjahr aus Datum ableiten
Extraktion Textteil aus Text (Trunkation)
Mehrfache Fallunterscheidung, Datenbereinigung /-harmonisierung
4 Laden
Daten laden

Die einzelnen Arbeitsmappenabfragen können abschließend in eine Exceltabelle, eine Verbindung und / oder in das Power Pivot Datemodell zur weiteren Bearbeitung (Modellierung, Kennzahlenbildung) geladen werden.
Praxisbeispiele