
Einstieg in das Maschinelle Lernen mit Python(x,y)
Python(x,y) ist eine Python-Distribution, die speziell für wissenschaftliche Arbeiten entwickelt wurde. Es umfasst neben der Programmiersprache auch die Entwicklungsumgebung Spyder und eine Reihe integrierter Python-Bibliotheken. Mithilfe von Python(x,y) kann eine Vielzahl von Interessensbereichen bearbeitet werden. Dazu zählen unter anderem Bildverarbeitung oder auch das maschinelle Lernen. Das All-in-One-Setup für Python(x,y) ist für alle gängigen Betriebssysteme online erhältlich.
Entwicklungsgrundlage
In diesem Tutorial steht vor allem die Python-Programmierung des Maschinellen Lernens im Vordergrund. Die explorative Analyse der Daten, die in der Praxis unverzichtbar ist, entfällt hier.
Als Grundlage dient die Datenbasis „Human Activity Recognition Using Smartphones“. Die Datenbasis beruht auf erfassten Sensordaten eines Smartphones während speziellen menschlichen Aktivitäten: Laufen, Treppen hinaufsteigen, Treppen herabsteigen, Sitzen, Stehen und Liegen. Auf den Aufzeichnungen von Gyroskop und Accelerometer wurden mehrere Merkmale erhoben. Die Datenmenge, alle zugehörigen Daten und die Beschreibung der Daten sind frei verfügbar.
(https://archive.ics.uci.edu/ml/datasets/Human+Activity+Recognition+Using+Smartphones)
Alle Daten liegen im Textformat vor. Für ein effizienteres Arbeiten mit der Datenbasis wurden diese im Vorfeld in das csv-Dateiformat überführt.
Python-Bibliotheken
Alle für das Data Mining relevanten Bibliotheken sind in Python(x,y) bereits enthalten. Für die Umsetzung werden folgende Bibliotheken genutzt:
import matplotlib.pyplot as plt import numpy as np import pandas as pd import time as tm from sklearn.cross_validation import cross_val_score from sklearn.ensemble import GradientBoostingClassifier, RandomForestClassifier from sklearn.linear_model import SGDClassifier from sklearn.metrics import confusion_matrix from sklearn.neighbors import KNeighborsClassifier from sklearn.svm import SVC
Die Bibliotheken NumPy und Pandas unterstützen die Arbeit mit verschiedenen Datenstrukturen, matplotlib bietet verschiedene Möglichkeiten der zweidimensionalen Visualisierung von Daten und scikit-learn umfasst alle Funktionen des maschinellen Lernens. Mit diesen 3 Bibliotheken kann der komplette Prozess automatisch umgesetzt werden.
Schritt 1 – Daten laden und Train-Test-Split
Die Trainingsdaten der Repository werden für die Modellerstellung und Bewertung genutzt, die Testdaten für die abschließende Prognose.
Um die Datenbasis (measures.csv) in das Modul zu laden bietet Pandas die read_csv-Methode an. Die Methode organisiert die csv-Daten innerhalb des Moduls als Data Frame. Die Einträge der ersten Zeile der Datei werden als Spaltenköpfe übernommen, die übrigen Zeilen bilden die Datensätze. Das Data Frame erlaubt den einfachen Zugriff auf einzelne Zeilen, Spalten oder Zellen. Der Zugriff erfolgt ähnlich wie bei Arrays mittels einfacher Indexierung. Einzelne Spalten werden mithilfe ihres Spaltenkopfes indexiert, Zeilen numerisch und einzelne Zellen durch eine kombinierte Indexierung.
data = pd.read_csv("data/measures.csv", sep = ';', decimal = ',')
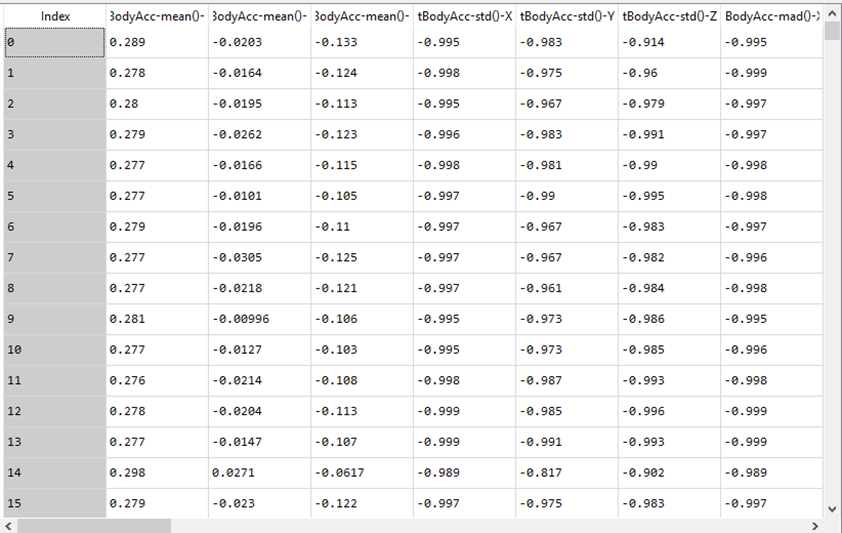
Da die Datenbasis bereits vollständig und standardisiert ist, sind hier keinerlei Vorverarbeitungsschritte notwendig. Die scikit-learn-Bibliothek bietet ansonsten auch hier verschiedene Ansätze: einen Imputer, um fehlende Daten zu ergänzen und verschiedene Scaler zur Anpassung der Datenverteilung (z.B. Normalisierung, Standardisierung).
Trainings- und Testdaten der Datenbasis besitzen verschiedene Klassen. Während die Trainingsdaten über String-Klassen verfügen, besitzen die Testdaten numerische Klassen-Werte. Die Pandas-Bibliothek bietet mit der replace-Methode die Möglichkeit die Klassenwerte zu ersetzen (Zuordnung von Text und Nummer der Klassen sind in der den Daten beiliegenden Beschreibung enthalten). Alternativ bietet scikit-learn einen Label Encoder an, der Klassenlabels in numerische Werte übersetzt. Allerdings werden die Klassen dabei alphabetisch sortiert nummeriert, was in der vorliegenden Datenmenge zu fehlerhaften Klassenbezeichnungen führen würde. Weiterhin wird die für die Klassifizierung irrelevante subject-Spalte mithilfe der drop-Methode für Data Frames entfernt.
# converting textual class labels to numeric classes like description
data = data.replace({'WALKING': 1, 'WALKING_UPSTAIRS': 2, 'WALKING_DOWNSTAIRS': 3,
'SITTING': 4, 'STANDING': 5, 'LAYING': 6})
# drop subject column
data = data.drop('subject', 1)
Die Aufteilung in Trainings- und Testdaten erfolgt durch Index-Slicing. An dieser Stelle wird eine Teilung in 70% Trainings- und 30% Testdaten vorgenommen. Dies entspricht einer Datenteilung nach dem 5147. Eintrag.
# splitting data into train and test set train_data = data[:5147] test_data = data[5147:] train_class = list(data['activity'][:5147]) test_class = list(data['activity'][5147:])
Mit der Pandas-Bibliothek kann an dieser Stelle eine Grafik über die Verteilung der einzelnen Klassen in beiden Datenmengen erstellt werden. Dafür werden die Klassenlabels in beiden Datensätzen gezählt und ihre Verteilungen in ein separates Data Frame übernommen. Ein Pandas Data Frame verfügt für die Visualisierung der Daten über eine integrierte plot-Funktion. Mit dieser kann beispielsweise ein Balkendiagramm generiert werden.
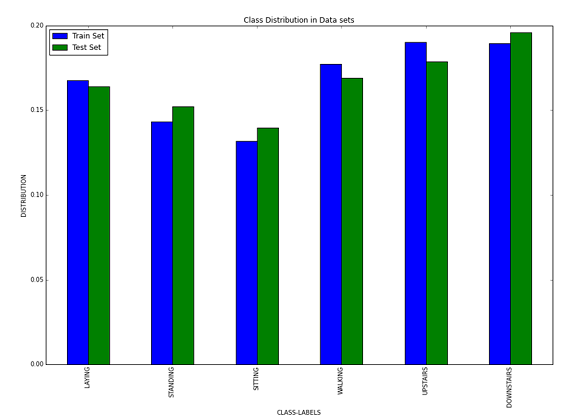
# compute class distribution
distribution_train = train_data['activity'].astype('str').value_counts(normalize = True)
distribution_test = test_data['activity'].astype('str').value_counts(normalize = True)
print "class distribution in train set:"
print distribution_train
print "class distribution in test set:"
print distribution_test
# data frames for distributions
train_frame = pd.DataFrame(distribution_train, columns = ["Train Set"])
test_frame = pd.DataFrame(distribution_test, columns = ["Test Set"])
plot_frame = pd.concat([train_frame, test_frame], join = 'outer', axis = 1)
# labels for distribution graphic
plot_frame.index = ["LAYING", "STANDING", "SITTING", "WALKING", "UPSTAIRS", "DOWNSTAIRS"]
# compute distribution graphic
print "plotting the class distribution in data sets..."
plot = plot_frame.plot(kind = 'bar', figsize = (15, 10), title = "Class Distribution in Data sets")
plot.set_xlabel("CLASS-LABELS")
plot.set_ylabel("DISTRIBUTION")
fig = plot.get_figure()
# save class distribution graphic
print "exporting and saving file with class distribution plot..."
fig.savefig("class_distribution.png")
Schritt 2 – Modellauswahl
Da man im Vorfeld der Klassifizierung nie wissen kann, welches Modell für die aktuelle Problematik am besten geeignet ist, ist es sinnvoll mehrere Modelle zu betrachten und zu testen. Die scikit-learn-Bibliothek bietet eine Vielzahl von Klassifikatoren. In diesem Beispiel werden fünf Klassifikatoren betrachtet, die für die Kreuzvalidierung in einer Liste zusammengefasst werden. Weiterhin wird eine Liste über die Namen der Modelle erzeugt und beide Listen werden zu einem Dictionary zusammengefasst. Später kann so der Zugriff auf die Modelle anhand ihrer Namen erfolgen.
# data for cross-validation
cvX = train_data
cvY = np.array(train_class)
# initialize all classifiers to be tested
print "initializing of all classifiers for cv-test.."
rfc = RandomForestClassifier(n_estimators = 350, criterion = 'entropy', max_depth = 4)
svc = SVC(C = 1.0, kernel = 'poly', degree = 5, shrinking = True)
sgd = SGDClassifier(loss = 'hinge', n_iter = 8, shuffle = True)
knn = KNeighborsClassifier(n_neighbors = 3, weights = 'distance', algorithm = 'auto')
gbc = GradientBoostingClassifier(loss = 'deviance', n_estimators = 400, max_depth = 3)
# create list containing all classifiers
classifiers = [rfc, svc, sgd, knn, gbc]
classifier_names = ["RFC", "SVC", "SGD", "KNN", "GBC"]
clf_dict = dict(zip(classifier_names, classifiers))
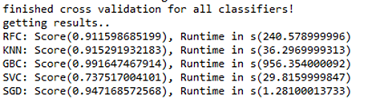
Für die Bewertung der Modelle wird eine dreifache Kreuzvalidierung genutzt. Dabei werden die Trainingsdaten in drei gleich große Blöcke unterteilt. In jedem Durchgang dient genau ein Block als Testdatensatz, die jeweils übrigen zwei als Trainingsdaten. Der Klassifikator wird jeweils mit den Trainingsdaten trainiert und auf die Testdaten angewandt. Mithilfe der cross_val_score-Methode aus dem scikit-learn-Paket wird eine Liste über die Erfolgsraten jeden Durchlaufs generiert. Um den Klassifikator final zu bewerten wird die mittlere Erfolgsrate der Kreuzvalidierung mit der mean-Methode des NumPy-Pakets berechnet. Zusätzlich wird die Laufzeit der Kreuzvalidierung für jeden Klassifikator bestimmt.
cv_scores = []
cv_times = []
print str(len(classifiers)) + " classifiers waiting for testing.."
# for all classifiers --> fit, determine cv-score and runtime
for i in range(len(classifiers)):
print "testing classifier number " + str(i + 1) + ": "+ classifier_names[i]
time = tm.time()
clf = classifiers[i]
print classifier_names[i] + " started cv-training.."
cv_score = cross_val_score(clf, cvX, cvY, cv = 3)
cv_score = np.mean(cv_score)
print "mean score of three cv-turns was successfully calculated.."
cv_scores.append(cv_score)
time = tm.time() - time
cv_times.append(time)
print classifier_names[i] + " finished training.."
print "next classifier is loading.."
print "finished cross validation for all classifiers!"
Für die Darstellung der Ergebnisse werden Dictionaries erstellt, die die Namen der Modelle als Schlüssel für die jeweilige Erfolgsrate bzw. der jeweiligen Laufzeit nutzen. Die matplotlib-Bibliothek bietet die Möglichkeit die Ergebnisse in einem Scatterplot zu visualisieren.
# mapping of classifiers with its cv-scores and runtimes
clf_accuracy = dict(zip(classifier_names, cv_scores))
clf_runtime = dict(zip(classifier_names, cv_times))
print "getting results.."
for key, val in clf_accuracy.iteritems():
print str(key) + ": Score(" + str(val) + "), Runtime in s(" + str(clf_runtime[key]) + ")"
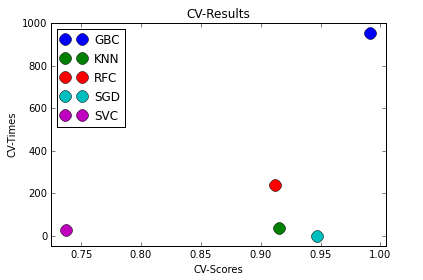
# generate scatter plot over all classifiers
groups = result_frame.groupby('Classifier')
fig, ax = plt.subplots()
ax.margins(0.05)
for name, group in groups:
ax.plot(group.scores, group.runtime, marker = 'o', linestyle = '', ms = 12, label = name)
ax.legend(loc = 0)
plt.ylabel('CV-Times')
plt.xlabel('CV-Scores')
plt.title('CV-Results')
# export and save scatterplot
print "exporting and saving scatterplot.."
plt.savefig("image\cv-score-clf.png")val) + "), Runtime in s(" + str(clf_runtime[key]) + ")"
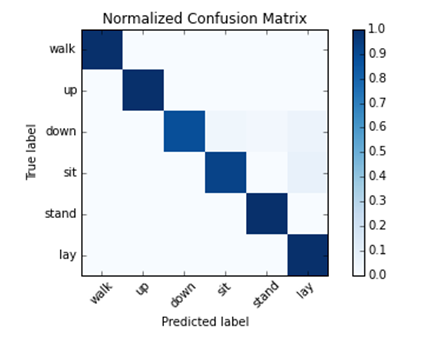
Das Dictionary mit den Erfolgsraten wird für die Auswahl des besten Modells genutzt. Dabei wird das Modell mit dem höchsten mittleren Erfolgswert ausgewählt. Auf dem besten Modell kann nun die allgemeine Erfolgsrate auf den Testdaten berechnet werden. Dafür werden der score-Methode eines scikit-learn-Klassifikators die Testdaten und die Testklassen übergeben. Das gewählte Modell erzielt hier eine Erfolgsrate von 97%. Dieser Wert gibt einen ersten Eindruck, wie akkurat das gewählte Modell arbeitet. Die scikit-learn-Bibliothek bietet zusätzlich die Möglichkeit die Konfusionsmatrix zu erstellen. Diese gibt einen Überblick über Missklassifizierungen zwischen den vorhergesagten und echten Klassen. Mit matplotlib wird die Konfusionsmatrix wieder visualisiert. Aufgrund der sehr hohen Modellgüte sticht ausschließlich die wichtige Hauptdiagonale hervor.
# output of best classifier best_clf = [key for key, value in clf_accuracy.iteritems() if value == (np.max(clf_accuracy.values()))][0] print "And finally the Winner is: " + str(best_clf) + " with a score of " + str(clf_accuracy[best_clf]) # choice of best classifier select_clf = clf_dict[best_clf] print "Select the winning classifier: " + str(select_clf) # train the selected classifier print "fitting the model..." clf_test = select_clf.fit(train_data, train_class) test_score = clf_test.score(test_data, test_class) print "selecting model scores an mean accuracy of " + str(test_score) + " on test data" # prediction of the test set print "predict the test classes..." test_data_prediction = clf_test.predict(test_data)
# generate normalized confusion matrix
print "generate the normalized confusion matrix"
conm = confusion_matrix(test_class, test_data_prediction)
# labels for confusion matrix
matrix_labels = ["walk","up","down","sit","stand","lay"]
# export the graphic for the conm
print "saving the confusion matrix in file..."
np.set_printoptions(precision = 2)
conm = conm.astype('float') / conm.sum(axis=1)[:, np.newaxis]
plt.figure()
plt.imshow(conm, interpolation='nearest', cmap=plt.cm.Blues)
plt.title('Normalized Confusion Matrix')
plt.colorbar()
tick_marks = np.arange(len(matrix_labels))
plt.xticks(tick_marks, matrix_labels, rotation=45)
plt.yticks(tick_marks, matrix_labels)
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
plt.tight_layout()
plt.savefig('image/confusion_matrix.png')
Schritt 3 – 100% Modell und Prognose
Für die Bewertung der unklassifizierten Datenmenge wird das 100%-Modell erstellt. Das 100%-Modell entsteht durch das Training des Klassifikators mit allen bisherigen Daten. Analog zum Beginn wird die zu prognostizierende Datenmenge (to_predict.csv) mittels Pandas in das Modul geladen. Auch hier muss die irrelevante subject-Spalte aus dem Data Frame entfernt werden. Da die Klassenlabels für die zu bewertende Datenmenge ebenfalls im Repository liegen (true_labels.csv), können diese ebenfalls geladen werden, um die abschließende Bewertung durchzuführen. Dafür wird erneut die score-Funktion des Klassifikators genutzt. Für die abschließende Prognose wird so eine Erfolgsrate von 93,99% ermittelt.
# fitting the 100% model
final_model = select_clf.fit(data.ix[:, :-1], data['activity'])
# read data to predict, read true class labels for data to predict
to_predict = pd.read_csv("data/to_predict.csv", sep = ';', decimal = ',')
to_predict = to_predict.drop("subject", 1)
true_classes_csv = pd.read_csv("data/true_labels.csv", sep = ';', decimal = ',')
true_classes = np.array(true_classes_csv['class'])
# predict the class labels for unknownn data
pred_acc = final_model.score(to_predict, true_classes)
print "100 percent model scores final prediction accuracy of " + str(pred_acc)
Anmerkung: Dieses Minimal-Beispiel dient der Vorstellung der Python-Distribution Python(x,y) für die Nutzung im Data Mining. Die bereits vollständige und vorverarbeitete Datenmenge in diesem Beispiel ermöglicht einen Direkteinstieg für dieses Tutorial. In der Praxis kommen im Data Mining weitere essentiell wichtige Bearbeitungsschritte hinzu, u.a. Datenaufbereitung, Datenvervollständigung, explorative Analysen und Merkmalsselektion.







Leave a Reply
Want to join the discussion?Feel free to contribute!