
Text Mining mit R
R ist nicht nur ein mächtiges Werkzeug zur Analyse strukturierter Daten, sondern eignet sich durchaus auch für erste Analysen von Daten, die lediglich in textueller und somit unstrukturierter Form vorliegen. Im Folgenden zeige ich, welche typischen Vorverarbeitungs- und Analyseschritte auf Textdaten leicht durchzuführen sind. Um uns das Leben etwas leichter zu machen, verwenden wir dafür die eine oder andere zusätzliche R-Library.
Die gezeigten Schritte zeigen natürlich nur einen kleinen Ausschnitt dessen, was man mit Textdaten machen kann. Der Link zum kompletten R-Code (.RMD) findet sich am Ende des Artikels.
Sentimentanalyse
Wir verwenden das Anwendungsgebiet der Sentimentanalyse für diese Demonstration. Mittels der Sentimentanalyse versucht man, Stimmungen zu analysieren. Im Prinzip geht es darum, zu erkennen, ob ein Autor mit einer Aussage eine positive oder negative Stimmung oder Meinung ausdrückt. Je nach Anwendung werden auch neutrale Aussagen betrachtet.
Daten einlesen
Datenquelle: ‘From Group to Individual Labels using Deep Features’, Kotzias et. al,. KDD 2015
Die Daten liegen als cvs vor: Die erste Spalte enhält jeweils einen englischen Satz, gefolgt von einem Tab, gefolgt von einer 0 für negatives Sentiment und einer 1 für positives Sentiment. Nicht alle Sätze in den vorgegebenen Daten sind vorklassifiziert.
Wir lesen 3 Dateien ein, fügen eine Spalte mit der Angabe der Quelle hinzu und teilen die Daten dann in zwei Datensätze auf. Der Datensatz labelled enthält alle vorklassifizierten Sätze während alle anderen Sätze in unlabelled gespeichert werden.
## 'readSentiment' liest csv ein, benennt die Spalten und konvertiert die Spalte 'sentiment' zu einem Faktor
amazon <-readSentiment("amazon_cells_labelled.txt")
amazon$source <- "amazon"
imdb <-readSentiment("imdb_labelled.txt")
imdb$source <- "imdb"
yelp <-readSentiment("yelp_labelled.txt")
yelp$source <- "yelp"
allText <- rbindlist(list(amazon, imdb, yelp), use.names=TRUE)
allText$source <- as.factor(allText$source)
unlabelled <- allText[is.na(allText$sentiment), ]
labelled <- allText[!is.na(allText$sentiment), ]
Wir haben nun 3000 vorklassifizierte Sätze, die entweder ein positives oder ein negatives Sentiment ausdrücken:
text sentiment source Length:3000 0:1500 amazon:1000 Class :character 1:1500 imdb :1000 Mode :character yelp :1000
Textkorpus anlegen
Zuerst konvertieren wir den Datensatz in einen Korpus der R-Package tm:
library(tm)
corpus <- Corpus(DataframeSource(data.frame(labelled$text)))
# meta data an Korpus anfügen:
meta(corpus, tag = "sentiment", type="indexed") <- labelled$sentiment
meta(corpus, tag = "source", type="indexed") <- labelled$source
myTDM <- TermDocumentMatrix(corpus, control = list(minWordLength = 1))
## verschieden Möglichkeiten, den Korpus bzw die TermDocumentMatrix zu inspizieren:
#inspect(corpus[5:10])
#meta(corpus[1:10])
#inspect(myTDM[25:30, 1])
# Indices aller Dokumente, die das Wort "good" enthalten:
idxWithGood <- unlist(lapply(corpus, function(t) {grepl("good", as.character(t))}))
# Indices aller Dokumente mit negativem Sentiment, die das Wort "good" enthalten:
negIdsWithGood <- idxWithGood & meta(corpus, "sentiment") == '0'
Wir können uns nun einen Eindruck über die Texte verschaffen, bevor wir erste Vorverarbeitungs- und Säuberungsschritte durchführen:
- Fünf Dokumente mit negativem Sentiment, die das Wort “good” enthalten: Not a good bargain., Not a good item.. It worked for a while then started having problems in my auto reverse tape player., Not good when wearing a hat or sunglasses., If you are looking for a good quality Motorola Headset keep looking, this isn’t it., However, BT headsets are currently not good for real time games like first-person shooters since the audio delay messes me up.
- Liste der meist verwendeten Worte im Text: all, and, are, but, film, for, from, good, great, had, have, it’s, just, like, movie, not, one, phone, that, the, this, very, was, were, with, you
- Anzahl der Worte, die nur einmal verwendet werden: 4820, wie z.B.: ‘film’, ‘ive, ’must’, ‘so, ’stagey’, ’titta
- Histogramm mit Wortfrequenzen:
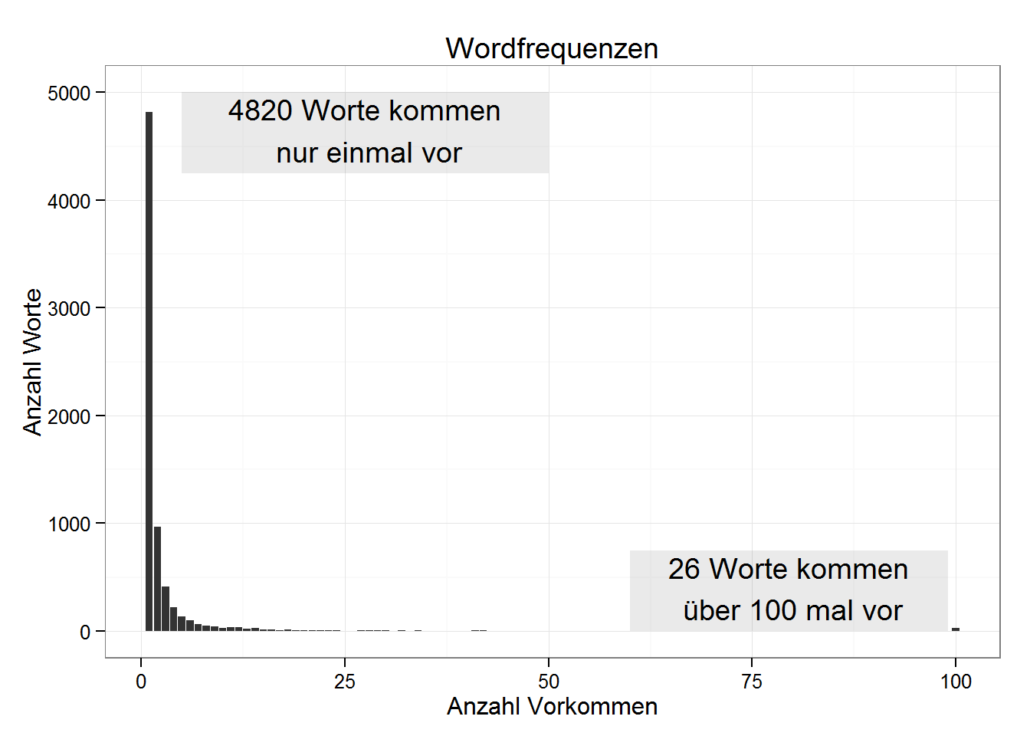
Plotten wir, wie oft die häufigsten Worte verwendet werden:
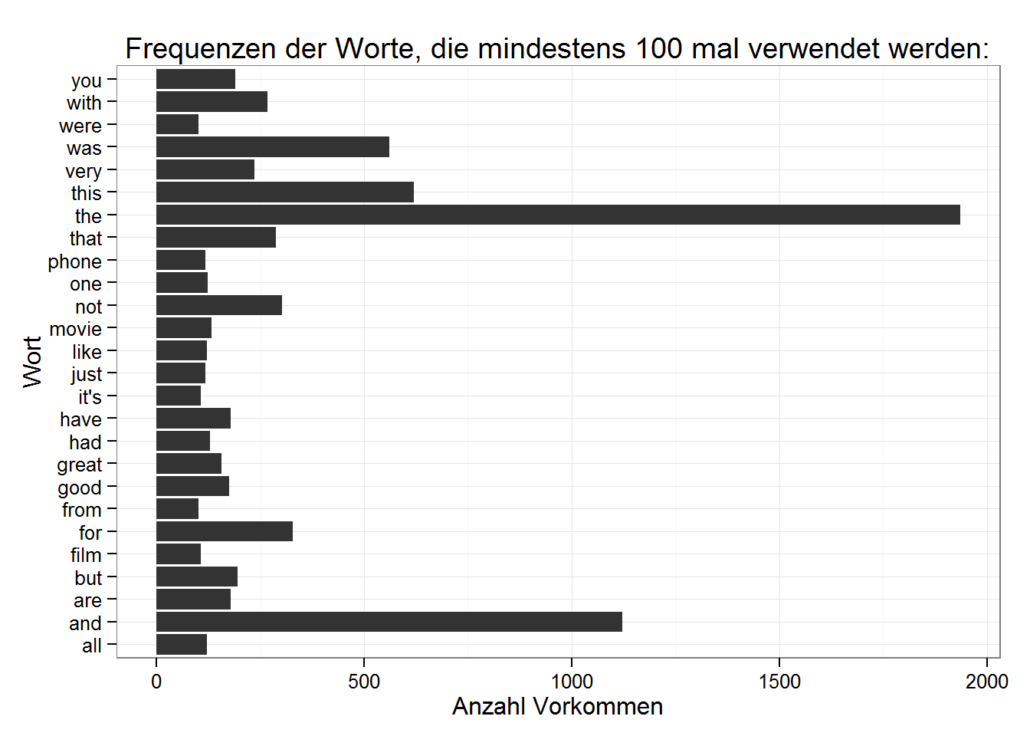
Vorverarbeitung
Es ist leicht zu erkennen, dass sogenannte Stoppworte wie z.B. “the”, “that” und “you” die Statistiken dominieren. Der Informationsgehalt solcher Stopp- oder Füllworte ist oft gering und daher werden sie oft vom Korpus entfernt. Allerdings sollte man dabei Vorsicht walten lassen: not ist zwar ein Stoppwort, könnte aber z.B. bei der Sentimentanalyse durchaus von Bedeutung sein.
Ein paar rudimentäre Vorverarbeitungen:
Wir konvertieren den gesamten Text zu Kleinbuchstaben und entfernen die Stoppworte unter Verwendung der mitgelieferten R-Stoppwortliste für Englisch (stopwords(“english”)). Eine weitere Standardoperation ist Stemming, das wir heute auslassen. Zusätzlich entfernen wir alle Sonderzeichen und Zahlen und behalten nur die Buchstaben a bis z:
replaceSpecialChars <- function(d) {
## normalerweise würde man nicht alle Sonderzeichen entfernen
gsub("[^a-z]", " ", d)
}
# tolower ist eine built-in function
corpus <- tm_map(corpus, content_transformer(tolower))
# replaceSpecialChars ist eine selbst geschriebene Funktion:
corpus <- tm_map(corpus, content_transformer(replaceSpecialChars))
corpus <- tm_map(corpus, stripWhitespace)
englishStopWordsWithoutNot <- stopwords("en")[ - which(stopwords("en") %in% "not")]
corpus <- tm_map(corpus, removeWords, englishStopWordsWithoutNot)
## corpus <- tm_map(corpus, stemDocument, language="english")
myTDM.without.stop.words <- TermDocumentMatrix(corpus,
control = list(minWordLength = 1))
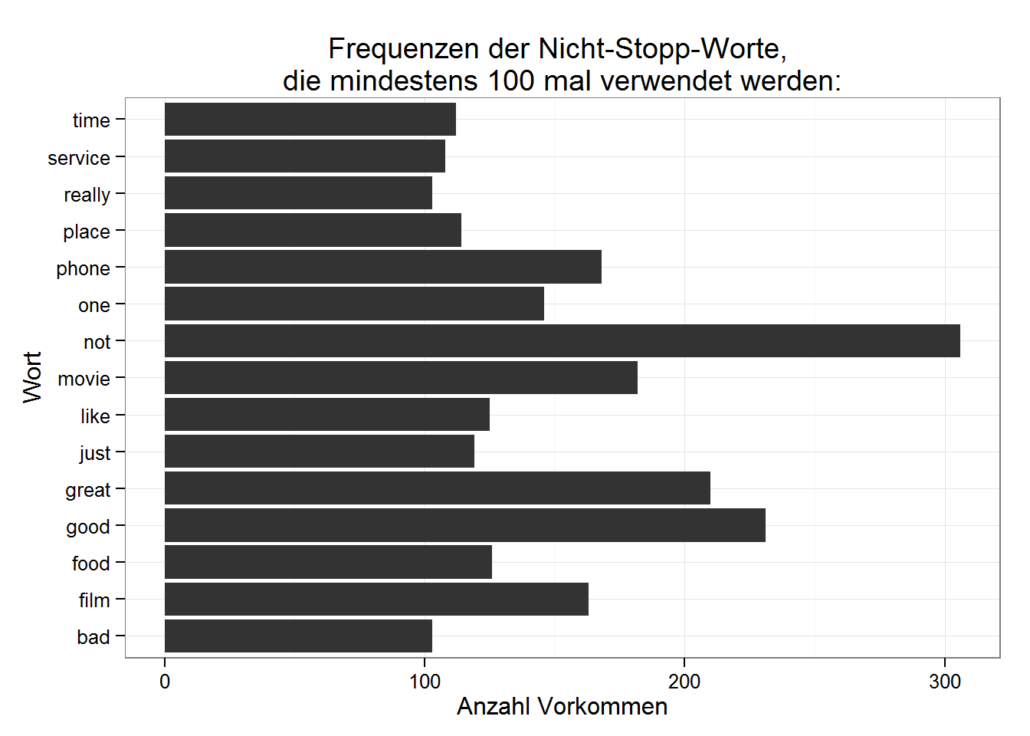
Schlagwortwolke bzw Tag Cloud
Schließlich erzeugen wir eine Tag-Cloud aller Worte, die mindestens 25 mal im Text verwendet werden. Tag-Clouds eignen sich hervorragend zur visuellen Inspektion von Texten, allerdings lassen sich daraus nur bedingt direkte Handlungsanweisungen ableiten:
wordfreq <- findFreqTerms(myTDM.without.stop.words, lowfreq=25) termFrequency <- rowSums(as.matrix(myTDM.without.stop.words[wordfreq,])) # eine Alternative ist 'tagcloud' library(wordcloud) wordcloud(words=names(termFrequency),freq=termFrequency,min.freq=5,max.words=50,random.order=F,colors="red")

Word-Assoziationen
Wir können uns für bestimmte Worte anzeigen lassen, wie oft sie gemeinsam mit anderen Worten im gleichen Text verwendet werden:
- Worte, die häufig gemeinsam mit movie verwendet werden:
findAssocs(myTDM.without.stop.words, "movie", 0.13)
## $movie ## beginning duet fascinating june angel astronaut ## 0.17 0.15 0.15 0.15 0.14 0.14 ## bec coach columbo considers curtain dodge ## 0.14 0.14 0.14 0.14 0.14 0.14 ## edition endearing funniest girolamo hes ive ## 0.14 0.14 0.14 0.14 0.14 0.14 ## latched lid makers peaking planned restrained ## 0.14 0.14 0.14 0.14 0.14 0.14 ## scamp shelves stratus titta ussr vision ## 0.14 0.14 0.14 0.14 0.14 0.14 ## yelps ## 0.14
- Worte, die häufig gemeinsam mit product verwendet werden:
findAssocs(myTDM.without.stop.words, "product", 0.12)
## $product ## allot avoiding beats cellphones center ## 0.13 0.13 0.13 0.13 0.13 ## clearer contacting copier dollar equipment ## 0.13 0.13 0.13 0.13 0.13 ## fingers greater humming ideal learned ## 0.13 0.13 0.13 0.13 0.13 ## lesson motor murky negatively oem ## 0.13 0.13 0.13 0.13 0.13 ## official online owning pens petroleum ## 0.13 0.13 0.13 0.13 0.13 ## planning related replacementr sensitive shipment ## 0.13 0.13 0.13 0.13 0.13 ## steer voltage waaay whose worthless ## 0.13 0.13 0.13 0.13 0.13
Text-Mining
Wir erzeugen einen Entscheidungsbaum zur Vorhersage des Sentiments. Entscheidungsbäume sind nicht unbedingt das Werkzeug der Wahl für Text-Mining aber für einen ersten Eindruck lassen sie sich bei kleinen Datensätzen durchaus gewinnbringend einsetzen:
trainingData <- data.frame(as.matrix(myDTM))
trainingData$sentiment <- labelled$sentiment
trainingData$source <- labelled$source
formula <- sentiment ~ .
if (rerun) {
tree <- rpart(formula, data = trainingData)
save(tree, file=sprintf("%s-tree.RData", prefix))
} else {
load(file=sprintf("c:/tmp/%s-tree.RData", prefix))
}
myPredictTree(tree)
## isPosSentiment
## sentiment FALSE TRUE
## 0 1393 107
## 1 780 720Eine Fehlerrate von über 50% auf den Trainingsdaten für positive Sentiments ist natürlich nicht berauschend und daher testen wir zum Schluß noch Support Vector Machines:
library(e1071)
if (rerun) {
svmModel <- svm(formula, data = trainingData)
save(svmModel, file=sprintf("%s-svm.RData", prefix))
} else {
load(file=sprintf("c:/tmp/%s-svm.RData", prefix))
}
myPredictSVM <- function(model) {
predictions <- predict(model, trainingData)
trainPerf <- data.frame(trainingData$sentiment, predictions, trainingData$source)
names(trainPerf) <- c("sentiment", "isPosSentiment", "source")
with(trainPerf, {
table(sentiment, isPosSentiment, deparse.level = 2)
})
}
myPredictSVM(svmModel)
## isPosSentiment ## sentiment FALSE TRUE ## 0 1456 44 ## 1 23 1477
Die Ergebnisse sehen deutlich besser aus, müssten aber natürlich noch auf unabhängigen Daten verifiziert werden, um z. B. ein Overfittung zu vermeiden.
Download-Link zum kompletten R-Code für dieses Text-Mining-Beispiel: https://www.data-science-blog.com/download/textMiningTeaser.rmd





Leave a Reply
Want to join the discussion?Feel free to contribute!