Sentiment Analysis using Python
One of the applications of text mining is sentiment analysis. Most of the data is getting generated in textual format and in the past few years, people are talking more about NLP. Improvement is a continuous process and many product based companies leverage these text mining techniques to examine the sentiments of the customers to find about what they can improve in the product. This information also helps them to understand the trend and demand of the end user which results in Customer satisfaction.
As text mining is a vast concept, the article is divided into two subchapters. The main focus of this article will be calculating two scores: sentiment polarity and subjectivity using python. The range of polarity is from -1 to 1(negative to positive) and will tell us if the text contains positive or negative feedback. Most companies prefer to stop their analysis here but in our second article, we will try to extend our analysis by creating some labels out of these scores. Finally, a multi-label multi-class classifier can be trained to predict future reviews.
Without any delay let’s deep dive into the code and mine some knowledge from textual data.
There are a few NLP libraries existing in Python such as Spacy, NLTK, gensim, TextBlob, etc. For this particular article, we will be using NLTK for pre-processing and TextBlob to calculate sentiment polarity and subjectivity.
import pandas as pd import matplotlib.pyplot as plt %matplotlib inline import nltk from nltk import word_tokenize, sent_tokenize from nltk.corpus import stopwords from nltk.stem import LancasterStemmer, WordNetLemmatizer, PorterStemmer from wordcloud import WordCloud, STOPWORDS from textblob import TextBlob
The dataset is available here for download and we will be using pandas read_csv function to import the dataset. I would like to share an additional information here which I came to know about recently. Those who have already used python and pandas before they probably know that read_csv is by far one of the most used function. However, it can take a while to upload a big file. Some folks from RISELab at UC Berkeley created Modin or Pandas on Ray which is a library that speeds up this process by changing a single line of code.
amz_reviews = pd.read_csv("1429_1.csv")
After importing the dataset it is recommended to understand it first and study the structure of the dataset. At this point we are interested to know how many columns are there and what are these columns so I am going to check the shape of the data frame and go through each column name to see if we need them or not.
amz_reviews.shape
(34660, 21)
amz_reviews.columns
Index(['id', 'name', 'asins', 'brand', 'categories', 'keys', 'manufacturer',
'reviews.date', 'reviews.dateAdded', 'reviews.dateSeen',
'reviews.didPurchase', 'reviews.doRecommend', 'reviews.id',
'reviews.numHelpful', 'reviews.rating', 'reviews.sourceURLs',
'reviews.text', 'reviews.title', 'reviews.userCity',
'reviews.userProvince', 'reviews.username'],
dtype='object')
There are so many columns which are not useful for our sentiment analysis and it’s better to remove these columns. There are many ways to do that: either just select the columns which you want to keep or select the columns you want to remove and then use the drop function to remove it from the data frame. I prefer the second option as it allows me to look at each column one more time so I don’t miss any important variable for the analysis.
columns = ['id','name','keys','manufacturer','reviews.dateAdded', 'reviews.date','reviews.didPurchase',
'reviews.userCity', 'reviews.userProvince', 'reviews.dateSeen', 'reviews.doRecommend','asins',
'reviews.id', 'reviews.numHelpful', 'reviews.sourceURLs', 'reviews.title']
df = pd.DataFrame(amz_reviews.drop(columns,axis=1,inplace=False))
Now let’s dive deep into the data and try to mine some knowledge from the remaining columns. The first step we would want to follow here is just to look at the distribution of the variables and try to make some notes. First, let’s look at the distribution of the ratings.
df['reviews.rating'].value_counts().plot(kind='bar')
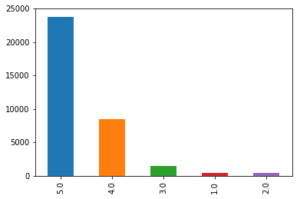
Graphs are powerful and at this point, just by looking at the above bar graph we can conclude that most people are somehow satisfied with the products offered at Amazon. The reason I am saying ‘at’ Amazon is because it is just a platform where anyone can sell their products and the user are giving ratings to the product and not to Amazon. However, if the user is satisfied with the products it also means that Amazon has a lower return rate and lower fraud case (from seller side). The job of a Data Scientist relies not only on how good a model is but also on how useful it is for the business and that’s why these business insights are really important.
Data pre-processing for textual variables
Lowercasing
Before we move forward to calculate the sentiment scores for each review it is important to pre-process the textual data. Lowercasing helps in the process of normalization which is an important step to keep the words in a uniform manner (Welbers, et al., 2017, pp. 245-265).
## Change the reviews type to string df['reviews.text'] = df['reviews.text'].astype(str) ## Before lowercasing df['reviews.text'][2] 'Inexpensive tablet for him to use and learn on, step up from the NABI. He was thrilled with it, learn how to Skype on it already...' ## Lowercase all reviews df['reviews.text'] = df['reviews.text'].apply(lambda x: " ".join(x.lower() for x in x.split())) df['reviews.text'][2] ## to see the difference 'inexpensive tablet for him to use and learn on, step up from the nabi. he was thrilled with it, learn how to skype on it already...'
Special characters
Special characters are non-alphabetic and non-numeric values such as {!,@#$%^ *()~;:/<>|+_-[]?}. Dealing with numbers is straightforward but special characters can be sometimes tricky. During tokenization, special characters create their own tokens and again not helpful for any algorithm, likewise, numbers.
## remove punctuation
df['reviews.text'] = df['reviews.text'].str.replace('[^ws]','')
df['reviews.text'][2]
'inexpensive tablet for him to use and learn on step up from the nabi he was thrilled with it learn how to skype on it already'
Stopwords
Stop-words being most commonly used in the English language; however, these words have no predictive power in reality. Words such as I, me, myself, he, she, they, our, mine, you, yours etc.
stop = stopwords.words('english')
df['reviews.text'] = df['reviews.text'].apply(lambda x: " ".join(x for x in x.split() if x not in stop))
df['reviews.text'][2]
'inexpensive tablet use learn step nabi thrilled learn skype already'
Stemming
Stemming algorithm is very useful in the field of text mining and helps to gain relevant information as it reduces all words with the same roots to a common form by removing suffixes such as -action, ing, -es and -ses. However, there can be problematic where there are spelling errors.
st = PorterStemmer() df['reviews.text'] = df['reviews.text'].apply(lambda x: " ".join([st.stem(word) for word in x.split()])) df['reviews.text'][2] 'inexpens tablet use learn step nabi thrill learn skype alreadi'
This step is extremely useful for pre-processing textual data but it also depends on your goal. Here our goal is to calculate sentiment scores and if you look closely to the above code words like ‘inexpensive’ and ‘thrilled’ became ‘inexpens’ and ‘thrill’ after applying this technique. This will help us in text classification to deal with the curse of dimensionality but to calculate the sentiment score this process is not useful.
Sentiment Score
It is now time to calculate sentiment scores of each review and check how these scores look like.
## Define a function which can be applied to calculate the score for the whole dataset
def senti(x):
return TextBlob(x).sentiment
df['senti_score'] = df['reviews.text'].apply(senti)
df.senti_score.head()
0 (0.3, 0.8)
1 (0.65, 0.675)
2 (0.0, 0.0)
3 (0.29545454545454547, 0.6492424242424243)
4 (0.5, 0.5827777777777777)
Name: senti_score, dtype: object
As it can be observed there are two scores: the first score is sentiment polarity which tells if the sentiment is positive or negative and the second score is subjectivity score to tell how subjective is the text. The whole code is available here.
In my next article, we will extend this analysis by creating labels based on these scores and finally we will train a classification model.

 Alice Albrecht is a research engineer at
Alice Albrecht is a research engineer at