
Introduction to Recommendation Engines
This is the second article of article series Getting started with the top eCommerce use cases. If you are interested in reading the first article you can find it here.
What are Recommendation Engines?
Recommendation engines are the automated systems which helps select out similar things whenever a user selects something online. Be it Netflix, Amazon, Spotify, Facebook or YouTube etc. All of these companies are now using some sort of recommendation engine to improve their user experience. A recommendation engine not only helps to predict if a user prefers an item or not but also helps to increase sales, ,helps to understand customer behavior, increase number of registered users and helps a user to do better time management. For instance Netflix will suggest what movie you would want to watch or Amazon will suggest what kind of other products you might want to buy. All the mentioned platforms operates using the same basic algorithm in the background and in this article we are going to discuss the idea behind it.
What are the techniques?
There are two fundamental algorithms that comes into play when there’s a need to generate recommendations. In next section these techniques are discussed in detail.
Content-Based Filtering
The idea behind content based filtering is to analyse a set of features which will provide a similarity between items themselves i.e. between two movies, two products or two songs etc. These set of features once compared gives a similarity score at the end which can be used as a reference for the recommendations.
There are several steps involved to get to this similarity score and the first step is to construct a profile for each item by representing some of the important features of that item. In other terms, this steps requires to define a set of characteristics that are discovered easily. For instance, consider that there’s an article which a user has already read and once you know that this user likes this article you may want to show him recommendations of similar articles. Now, using content based filtering technique you could find the similar articles. The easiest way to do that is to set some features for this article like publisher, genre, author etc. Based on these features similar articles can be recommended to the user (as illustrated in Figure 1). There are three main similarity measures one could use to find the similar articles mentioned below.
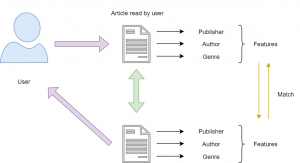
Figure 1: Content-Based Filtering
Minkowski distance
Minkowski distance between two variables can be calculated as:

Cosine Similarity
Cosine similarity between two variables can be calculated as :

Jaccard Similarity

These measures can be used to create a matrix which will give you the similarity between each movie and then a function can be defined to return the top 10 similar articles.
Collaborative filtering
This filtering method focuses on finding how similar two users or two products are by analyzing user behavior or preferences rather than focusing on the content of the items. For instance consider that there are three users A,B and C. We want to recommend some movies to user A, our first approach would be to find similar users and compare which movies user A has not yet watched and recommend those movies to user A. This approach where we try to find similar users is called as User-User Collaborative Filtering.
The other approach that could be used here is when you try to find similar movies based on the ratings given by others, this type is called as Item-Item Collaborative Filtering. The research shows that item-item collaborative filtering works better than user-user collaborative filtering as user behavior is really dynamic and changes over time. Also, there are a lot more users and increasing everyday but on the other side item characteristics remains the same. To calculate the similarities we can use Cosine distance.
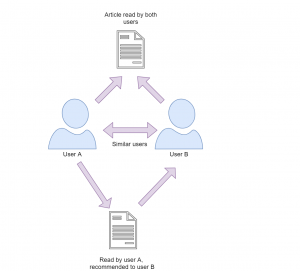
Figure 2: Collaborative Filtering
Recently some companies have started to take advantage of both content based and collaborative filtering techniques to make a hybrid recommendation engine. The results from both models are combined into one hybrid model which provides more accurate recommendations. Five steps are involved to make a recommendation engine work which are collection of data, storing of data, analyzing the data, filtering the data and providing recommendations. There are a lot of attributes that are involved in order to collect user data including browsing history, page views, search logs, order history, marketing channel touch points etc. which requires a strong data architecture. The collection of data is pretty straightforward but it can be overwhelming to analyze this amount of data. Storing this data could get tricky on the other hand as you need a scalable database for this kind of data. With the rise of graph databases this area is also improving for many use cases including recommendation engines. Graph databases like Neo4j can also help to analyze and find similar users and relationship among them. Analyzing the data can be carried in different ways, depending on how strong and scalable your architecture you can run real time, batch or near real time analysis. The fourth step involves the filtering of the data and here you can use any of the above mentioned approach to find similarities to finally provide the recommendations.
Having a good recommendation engine can be time consuming initially but it is definitely beneficial in the longer run. It not only helps to generate revenue but also helps to to improve your product catalog and customer service.


Leave a Reply
Want to join the discussion?Feel free to contribute!