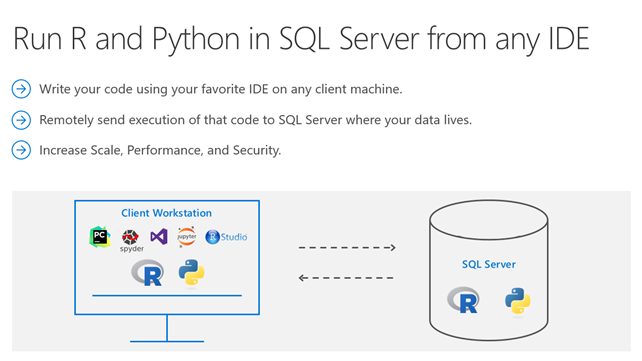
Für Unternehmen sind Markenbekanntheit und Werbeerinnerung wichtige Zielgrößen, denn anhand dieser lässt sich ableiten, ob Konsumenten ein Produkt einer Marke kaufen werden oder nicht. Zielgrößen wie diese werden von Marktforschungsinstituten über Befragungen ermittelt. Dafür wird in regelmäßigen Zeitabständen eine gleichbleibende Anzahl an Personen befragt, ob diese sich an Marken einer bestimmten Branche erinnern oder sich an Werbung erinnern. Die Personen füllen dafür in der Regel einen Onlinefragebogen aus.
Die Ergebnisse der Befragung liegen in einer Datenmatrix (siehe Tabelle) vor und müssen zur Auswertung zunächst bearbeitet werden.
| Laufende Nummer |
Marke 1 |
Marke 2 |
Marke 3 |
Marke 4 |
| 1 |
ING-Diba |
Citigroup |
Sparkasse |
|
| 2 |
Sparkasse |
Consorsbank |
|
|
| 3 |
Commerbank |
Deutsche Bank |
Sparkasse |
ING-DiBa |
| 4 |
Sparkasse |
Targobank |
|
|
Ziel ist es aus diesen Daten folgende 0/1 codierte Matrix zu generieren. Wenn eine Marke bekannt ist, wird in die zur Marke gehörende Spalte eine Eins eingetragen, ansonsten eine Null.
| Alle Marken |
ING-Diba |
Citigroup |
Sparkasse |
Targobank |
| ING-Diba, Citigroup, Sparkasse |
1 |
1 |
1 |
0 |
| Sparkasse, Consorsbank |
0 |
0 |
1 |
0 |
| Commerzbank, Deutsche Bank, Sparkasse, ING-Diba |
1 |
0 |
0 |
0 |
| Sparkasse, Targobank |
0 |
0 |
1 |
1 |
Der Workflow um diese Datentransformation durchzuführen ist oftmals mittels eines Teilstrings einer Marke zu suchen ob diese in einem über alle Nennungen hinweg zusammengeführten String vorkommt oder nicht (z.B. „argo“ bei Targobank). Das Problem dieser Herangehensweise ist, dass viele falsch geschriebenen Wörter so nicht erfasst werden und die Erfahrung zeigt, dass falsch geschriebene Marken in vielfältigster Weise auftreten. Hier mussten in der Vergangenheit Mitarbeiter sich in stundenlangem Kampf durch die Ergebnisse wühlen und falsch zugeordnete oder nicht zugeordnete Marken händisch korrigieren und alle Variationen der Wörter notieren, um für die nächste Befragung das Suchpattern zu optimieren.
Eine Alternative diesen aufwändigen Workflow stellt die Ermittlung von falsch geschriebenen Wörtern mittels des Jaro-Winkler-Scores dar. Dafür muss zunächst die Jaro-Winkler-Distanz zwischen zwei Strings berechnet werden. Diese berechnet sich wie folgt:

- m: Anzahl der übereinstimmenden Buchstaben
- s: Länge des Strings
- t: Hälfte der Anzahl der Umstellungen der Buchstaben die nötig sind, damit Strings identisch sind. („Ta“ und „gobank“ befinden sich bereits in der korrekten Reihenfolge, somit gilt: t = 0)
Aus dem Ergebnis lässt sich der Jaro-Winkler Score berechnen:

ist dabei die Jaro-Winkler-Distanz, l die Länge der übereinstimmenden Buchstaben von Beginn des Wortes bis zum maximal vierten Buchstaben und p ein konstanter Faktor von 0,1.
Für die Strings „Targobank“ und „Tangobank“ ergibt sich die Jaro-Winkler-Distanz:

Daraus wird im nächsten Schritt der Jaro-Winkler Score berechnet:

Bisherige Erfahrungen haben gezeigt, dass sich Scores ab 0,8 bzw. 0,9 am besten zur Suche von ähnlichen Wörtern eignen. Ein Schwellenwert darunter findet sehr viele Wörter, die sich z.B. auch anderen Wörtern zuordnen lassen. Ein Schwellenwert über 0,9 identifiziert falsch geschriebene Wörter oftmals nicht mehr.
Nach diesem theoretischen Exkurs möchte ich nun zeigen, wie sich das Ganze praktisch anwenden lässt. Da sich das Ganze um ein fiktives Beispiel handelt, werden zur Demonstration der Praxistauglichkeit Fakedaten mit folgendem Code erzeugt. Dabei wird angenommen, dass Personen unterschiedlich viele Banken kennen und diese mit einer bestimmten Wahrscheinlichkeit falsch schreiben.
# Erstellung von Fakeantworten
set.seed(1234)
library(stringi)
library(tidyr)
library(RecordLinkage)
library(xlsx)
library(tm)
library(qdap)
library(stringr)
library(openxlsx)
konsonant <- c("r", "n", "g", "h", "b")
vokal <- c("a", "e", "o", "i", "u")
# Funktion, die mit einer zu bestimmenden Wahrscheinlichkeit, einen zufälligen Buchstaben erzeugt.
generate_wrong_words <- function(x, p, k = TRUE) {
if(runif(1, 0, 1) > p) { # Zufallswert zwischen 0 und 1
if(k == TRUE) { # Konsonant oder Vokal erzeugen
string <- konsonant[sample.int(5, 1)] # Zufallszahl, die Index des Konsonnanten-Vektors bestimmt.
} else {
string <- vokal[sample.int(5, 1)] # Zufallszahl, die Index eines Vokal-Vecktors bestimmt.
}
} else {
string <- x
}
return(string)
}
randombank <- function(x) {
random_num <- runif(1, 0, 1)
if(random_num > x) { ## Wahrscheinlichkeit, dass Person keine Bank kennt.
number <- sample.int(7, 1)
if(number == 1) {
bank <- paste0("Ta", generate_wrong_words(x = "r", p = 0.7), "gob", generate_wrong_words(x = "a", p = 0.9), "nk")
} else if (number == 2) {
bank <- paste0("Ing-di", generate_wrong_words(x = "b", p = 0.6), "a")
} else if (number == 3) {
bank <- paste0("com", generate_wrong_words(x = "m", p = 0.7), "erzb", generate_wrong_words(x = "a", p = 0.8), "nk")
} else if (number == 4){
bank <- paste0("Deutsch", generate_wrong_words(x = "e", p = 0.6, k = FALSE), " Ban", generate_wrong_words(x = "k", p = 0.8))
} else if (number == 5) {
bank <- paste0("Spark", generate_wrong_words(x = "a", p = 0.7, k = FALSE), "sse")
} else if (number == 6) {
bank <- paste0("Cons", generate_wrong_words(x = "o", p = 0.7, k = FALSE), "rsbank")
} else {
bank <- paste0("Cit", generate_wrong_words(x = "i", p = 0.7, k = FALSE), "gro", generate_wrong_words(x = "u", p = 0.9, k = FALSE), "p")
}
} else {
bank <- "" # Leerer String, wenn keine Bank bekannt.
}
return(bank)
}
# DataFrame erzeugen, in dem Werte gespeichert werden.
df_raw <- data.frame(matrix(ncol = 8, nrow = 2500))
# Erzeugen von richtig und falsch geschrieben Banken mit einer durch bestimmten Variabilität an Banken, welche die Personen kennen.
for(i in 1:2500) {
df_raw [i, 1] <- i # Laufende Nummer des Befragten
df_raw [i, 2] <- randombank(x = 0.05)
if(df_raw [i, 2] == "") { df_raw [i, 3] <- "" } else {df_raw [i, 3] <- randombank(x = 0.1)}
if(df_raw [i, 3] == "") { df_raw [i, 4] <- "" } else {df_raw [i, 4] <- randombank(x = 0.1)}
if(df_raw [i, 4] == "") { df_raw [i, 5] <- "" } else {df_raw [i, 5] <- randombank(x = 0.15)}
if(df_raw [i, 5] == "") { df_raw [i, 6] <- "" } else {df_raw [i, 6] <- randombank(x = 0.15)}
if(df_raw [i, 6] == "") { df_raw [i, 7] <- "" } else {df_raw [i, 7] <- randombank(x = 0.2)}
if(df_raw [i, 7] == "") { df_raw [i, 8] <- "" } else {df_raw [i, 8] <- randombank(x = 0.2)}
}
colnames(df_raw)[1] <- "lfdn"
Ausführen:
head(df_raw)
Nun werden die Inhalte der Spalten in eine einzige Spalte zusammengefasst und jede Marke per Komma getrennt.
df <- unite(df_raw, united, c(2:ncol(df_raw)), sep = ",")
colnames(df)[2] <- "text"
# Gesuchte Banken (nur korrekt geschrieben)
startliste <- c("Targobank", "Ing-DiBa", "Commerzbank", "Deutsche Bank", "Sparkasse", "Consorsbank", "Citigroup")
Damit Sonderzeichen, Leerzeichen oder Groß- und Kleinschreibung keine Rolle spielen, werden alle Strings vereinheitlicht und störende Zeichen entfernt.
df text)
df
text)
df text)
df
text)
df text)
df
text)
df![text <- gsub("[?]", "", df](https://data-science-blog.com/en/wp-content/ql-cache/quicklatex.com-38fed1fb58d128d49fbdd72abf8c73c5_l3.png "Rendered by QuickLaTeX.com") text)
df
text)
df![text <- gsub("[-]", "", df](https://data-science-blog.com/en/wp-content/ql-cache/quicklatex.com-cc0a203eecd598f182c7c73809dce62b_l3.png "Rendered by QuickLaTeX.com") text)
df
text)
df![text <- gsub("[_]", "", df](https://data-science-blog.com/en/wp-content/ql-cache/quicklatex.com-f2f057a5760933989510f8fa3997fd0c_l3.png "Rendered by QuickLaTeX.com") text)
startliste <- tolower(startliste)
startliste <- str_trim(startliste)
startliste <- gsub(" ", "", startliste)
startliste <- gsub("[?]", "", startliste)
startliste <- gsub("[-]", "", startliste)
startliste <- gsub("[_]", "", startliste)
text)
startliste <- tolower(startliste)
startliste <- str_trim(startliste)
startliste <- gsub(" ", "", startliste)
startliste <- gsub("[?]", "", startliste)
startliste <- gsub("[-]", "", startliste)
startliste <- gsub("[_]", "", startliste)
Im nächsten Schritt wird geprüft welche Schreibweisen überhaupt existieren. Dafür eignet sich eine Word-Frequency-Matrix, mit der alle einzigartigen Wörter und deren Häufigkeiten in einem Vektor gezählt wird.
words <- as.data.frame(wfm(df![text)) # Jedes einzigartige Wort und dazugehörige Häufigkeiten. words <- rownames(words) # wfm zählt Häufigkeiten jedes Wortes und schreibt Wörter in rownames, wir brauchen jedoch das Wort selbst. </pre> Danach wird eine leere Liste erstellt, in der iterativ für jedes Element des Suchvektors ein Charactervektor erzeugt wird, der Wörter enthält, die einen Jaro-Winker Score von 0,9 oder höher besitzen. <pre class="theme:github lang:r decode:true ">for(i in 1:length(startliste)) { finalewortliste[[i]] <- words[which(jarowinkler(startliste[[i]], words) > 0.9)] } </pre> Jetzt wird ein leerer DataFrame erzeugt, der die Zeilenlänge des originalen DataFrames besitzt sowie die Anzahl der Marken als Spaltenlänge. <pre class="theme:github lang:r decode:true ">finaldf <- data.frame(matrix(nrow = nrow(df), ncol = length(startliste))) colnames(finaldf) <- startliste </pre> Im nächsten Schritt wird nun aus den ähnlichen Wörtern mit einer oder-Verknüpfung einen String erzeugt, der alle durch den Jaro-Winkler-Score identifizierten Wörter beinhaltet. Wenn ein Treffer gefunden wird, wird in der Suchspalte eine Eins eingetragen, ansonsten eine Null. <pre class="theme:github lang:r decode:true ">for(i in 1:ncol(finaldf)) { finaldf[i] <- ifelse(str_detect(df](https://data-science-blog.com/en/wp-content/ql-cache/quicklatex.com-4c818216532cfcfb704402489fc62a58_l3.png "Rendered by QuickLaTeX.com") text, paste(finalewortliste[[i]], collapse = "|")) == TRUE, 1, 0)
}
text, paste(finalewortliste[[i]], collapse = "|")) == TRUE, 1, 0)
}
Zuletzt wird eine Spalte erzeugt, in die eine Eins geschrieben wird, wenn keine der Marken gefunden wurde.
finaldf text, finaldf)
colnames(finaldf)[1] <- "text"
# Ergebnisse in eine .xlsx Datei schreiben.
wb <- createWorkbook()
addWorksheet(wb, "Ergebnisse")
writeData(wb, "Ergebnisse", anteil, startCol = 2, startRow = 1, rowNames = FALSE)
writeData(wb, "Ergebnisse", finaldf, startCol = 1, startRow = 4, rowNames = FALSE)
saveWorkbook(wb, paste0("C:/Users/User/Desktop/Results_", Sys.Date(), ".xlsx"), overwrite = TRUE)
text, finaldf)
colnames(finaldf)[1] <- "text"
# Ergebnisse in eine .xlsx Datei schreiben.
wb <- createWorkbook()
addWorksheet(wb, "Ergebnisse")
writeData(wb, "Ergebnisse", anteil, startCol = 2, startRow = 1, rowNames = FALSE)
writeData(wb, "Ergebnisse", finaldf, startCol = 1, startRow = 4, rowNames = FALSE)
saveWorkbook(wb, paste0("C:/Users/User/Desktop/Results_", Sys.Date(), ".xlsx"), overwrite = TRUE)
Dieses Vorgehen kann natürlich nicht verhindern, dass sich jemand mit kritischem Auge die Daten anschauen muss. In mehreren Tests ergaben sich bei einer Fallzahl von ~10.000 Antworten Genauigkeiten zwischen 95% und 100%, was bisherige Ansätze um ein Vielfaches übertrifft.9407407